- От Fork/Join к Stream API

Содержание
- 2. Этап размышления и поиск возможного пути оптимизации расчета (1) Исходные данные 1. Таблицы с данными
- 3. Этап размышления и поиск возможного пути оптимизации расчета (1) Исходные данные 1. Таблицы с данными 2.
- 4. Этап размышления и поиск возможного пути оптимизации расчета (1) Исходные данные 1. Таблицы с данными 2.
- 5. Этап размышления и поиск возможного пути оптимизации расчета (2) Решения на поверхности 1. На основе исходных
- 6. Этап размышления и поиск возможного пути оптимизации расчета (2) Решения на поверхности 1. На основе исходных
- 7. Этап размышления и поиск возможного пути оптимизации расчета (2) Решения на поверхности 1. На основе исходных
- 8. Был найден вариант работы с Fork/Join Возникшие вопросы Подойдет ли концепция Fork/Join для вычислений?
- 9. Был найден вариант работы с Fork/Join Возникшие вопросы Подойдет ли концепция Fork/Join для вычислений? Насколько легко
- 10. Был найден вариант работы с Fork/Join Возникшие вопросы Подойдет ли концепция Fork/Join для вычислений? Насколько легко
- 11. Был найден вариант работы с Fork/Join Возникшие вопросы Подойдет ли концепция Fork/Join для вычислений? Насколько легко
- 12. Информация о Fork/Join (1) Fork/Join Framework появился в Java SE 7. С его помощью можно довольно
- 13. Информация о Fork/Join (1) Fork/Join Framework появился в Java SE 7. С его помощью можно довольно
- 14. Информация о Fork/Join (1) Fork/Join Framework появился в Java SE 7. С его помощью можно довольно
- 15. Информация о Fork/Join (2) Threshold Далее для понимания возможностей Fork/Join будем оперировать понятием «threshold» В переводе
- 16. Примерный вид работы Fork/Join (в рамках RecursiveAction) public class Example extends RecursiveAction { @Override protected void
- 17. Написание примера (1) Запуск (1) import java.util.concurrent.ForkJoinPool; public class Start { public static void main(String[] args)
- 18. import java.util.concurrent.ForkJoinPool; public class Start { public static void main(String[] args) { // расчеты до 7
- 19. import java.util.concurrent.RecursiveAction; public class Example extends RecursiveAction { int cuntPr = Runtime.getRuntime().availableProcessors(); // условный threshold (предел)
- 20. Какой будет результат в примере? А) NO ERROR Time =……………… Б) =split= Time = …………….. NO
- 21. Особенности реализации import java.util.concurrent.ForkJoinPool; public class Start { public static void main(String[] args) { int componentValue
- 22. Выбор предела (1) Threshold можно определить по-разному в зависимости от вашей задачи Например, умножим N (количество
- 23. Выбор предела (2) Threshold можно определить по-разному в зависимости от вашей задачи Например, умножим N (количество
- 24. Результат Вариант №1 (threshold = 3 000 000) значение = 7 000 000 threshold = 3
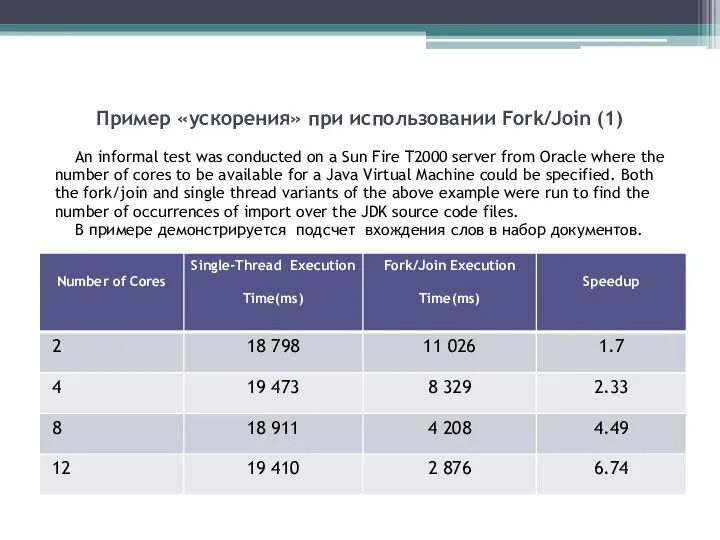
- 25. Пример «ускорения» при использовании Fork/Join (1) An informal test was conducted on a Sun Fire T2000
- 26. Пример «ускорения» при использовании Fork/Join (2) Пример нахождения максимального элемента в массиве из 500 000 элементов
- 27. Итоги по использованию Fork/Join 1. Уменьшение времени расчета
- 28. Итоги по использованию Fork/Join 1. Уменьшение времени расчета 2. Расчет не зависит от БД
- 29. Итоги по использованию Fork/Join 1. Уменьшение времени расчета 2. Расчет не зависит от БД 3. В
- 30. Итоги по использованию Fork/Join 1. Уменьшение времени расчета 2. Расчет не зависит от БД 3. В
- 31. Итоги по использованию Fork/Join 1. Уменьшение времени расчета 2. Расчет не зависит от БД 3. В
- 32. Итоги по использованию Fork/Join 1. Уменьшение времени расчета 2. Расчет не зависит от БД 3. В
- 33. А были ли проблемы?
- 34. А были ли проблемы? 1. Проблема выбора или нахождения оптимального порогового значения (threshold) Решается перебором возможных
- 35. А были ли проблемы? 1. Проблема выбора или нахождения оптимального порогового значения (threshold) 2. Проблема контроля
- 36. А были ли проблемы? 1. Проблема выбора или нахождения оптимального порогового значения (threshold) 2. Проблема контроля
- 37. А были ли проблемы? 1. Проблема выбора или нахождения оптимального порогового значения (threshold) 2. Проблема контроля
- 38. А были ли проблемы? 1. Проблема выбора или нахождения оптимального порогового значения (threshold) 2. Проблема контроля
- 39. А были ли проблемы? 1. Проблема выбора или нахождения оптимального порогового значения (threshold) 2. Проблема контроля
- 40. Второй этап реализации – это совершенствование (1) Вынести повторяющийся код Повторно использовать полученные данные Получить часть
- 41. Второй этап реализации – это совершенствование (2) Вынести повторяющийся код Повторно использовать полученные данные Получить часть
- 42. Stream API & ForkJoinPool Рассмотрим параллельные «вычисления» в Stream API для Collection Для использования parallelStream() нужно
- 43. Doug Lea (1) Вопрос The java.util.streams framework supports data-driven operations on collections and other sources. Most
- 44. Doug Lea (2) Вопрос читателя Основной смысл вопроса читателя сводится к желанию понять, когда можно безболезненно
- 45. Java 8 Lambdas. Functional Programming for the Masses (1) Ричард Уорбэртон в своей книге говорит о
- 46. Java 8 Lambdas. Functional Programming for the Masses (2) Пример «6.1» public int serialArraySum() { return
- 47. Еще немного про Stream API Темой Stream API активно занимается Тагир Валеев. В сети можно найти
- 48. Спасибо Время вопросов
- 50. Скачать презентацию
Слайд 3Этап размышления и поиск возможного пути оптимизации расчета (1)
Исходные данные
1. Таблицы с
Этап размышления и поиск возможного пути оптимизации расчета (1)
Исходные данные
1. Таблицы с

Слайд 4Этап размышления и поиск возможного пути оптимизации расчета (1)
Исходные данные
1. Таблицы с
Этап размышления и поиск возможного пути оптимизации расчета (1)
Исходные данные
1. Таблицы с
Слайд 5Этап размышления и поиск возможного пути оптимизации расчета (2)
Решения на поверхности
1.
Этап размышления и поиск возможного пути оптимизации расчета (2)
Решения на поверхности
1.
Слайд 6Этап размышления и поиск возможного пути оптимизации расчета (2)
Решения на поверхности
1.
Этап размышления и поиск возможного пути оптимизации расчета (2)
Решения на поверхности
1.

Слайд 7Этап размышления и поиск возможного пути оптимизации расчета (2)
Решения на поверхности
1.
Этап размышления и поиск возможного пути оптимизации расчета (2)
Решения на поверхности
1.

Слайд 8 Был найден вариант работы с Fork/Join
Возникшие вопросы
Подойдет ли концепция Fork/Join
Был найден вариант работы с Fork/Join
Возникшие вопросы
Подойдет ли концепция Fork/Join

Слайд 9Был найден вариант работы с Fork/Join
Возникшие вопросы
Подойдет ли концепция Fork/Join для
Был найден вариант работы с Fork/Join
Возникшие вопросы
Подойдет ли концепция Fork/Join для

Слайд 10Был найден вариант работы с Fork/Join Возникшие вопросы
Подойдет ли концепция Fork/Join для
Был найден вариант работы с Fork/Join Возникшие вопросы
Подойдет ли концепция Fork/Join для

Слайд 11Был найден вариант работы с Fork/Join Возникшие вопросы
Подойдет ли концепция Fork/Join для
Был найден вариант работы с Fork/Join Возникшие вопросы
Подойдет ли концепция Fork/Join для

Слайд 12Информация о Fork/Join (1)
Fork/Join Framework появился в Java SE 7. С его
Информация о Fork/Join (1)
Fork/Join Framework появился в Java SE 7. С его

Слайд 13Информация о Fork/Join (1)
Fork/Join Framework появился в Java SE 7. С его
Информация о Fork/Join (1)
Fork/Join Framework появился в Java SE 7. С его

Слайд 14Информация о Fork/Join (1)
Fork/Join Framework появился в Java SE 7. С его
Информация о Fork/Join (1)
Fork/Join Framework появился в Java SE 7. С его

Слайд 15Информация о Fork/Join (2)
Threshold
Далее для понимания возможностей Fork/Join будем оперировать понятием «threshold»
В
Информация о Fork/Join (2)
Threshold
Далее для понимания возможностей Fork/Join будем оперировать понятием «threshold»
В

Слайд 16Примерный вид работы Fork/Join (в рамках RecursiveAction)
public class Example extends RecursiveAction {
@Override
Примерный вид работы Fork/Join (в рамках RecursiveAction)
public class Example extends RecursiveAction {
@Override

Слайд 17Написание примера (1)
Запуск (1)
import java.util.concurrent.ForkJoinPool;
public class Start {
public static void main(String[]
Написание примера (1)
Запуск (1)
import java.util.concurrent.ForkJoinPool;
public class Start {
public static void main(String[]

Слайд 18import java.util.concurrent.ForkJoinPool;
public class Start {
public static void main(String[] args) {
//
//
![import java.util.concurrent.ForkJoinPool; public class Start { public static void main(String[] args) {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1097978/slide-17.jpg)
Слайд 19import java.util.concurrent.RecursiveAction;
public class Example extends RecursiveAction {
int cuntPr = Runtime.getRuntime().availableProcessors();
//
public class Example extends RecursiveAction { int cuntPr = Runtime.getRuntime().availableProcessors();
//

Слайд 20Какой будет результат в примере?
А)
NO ERROR
Time =………………
Б)
=split=
Time = ……………..
NO ERROR
=split=
Time = ……………..
NO
Какой будет результат в примере?
А)
NO ERROR
Time =………………
Б)
=split=
Time = ……………..
NO ERROR
=split=
Time = ……………..
NO

Слайд 21Особенности реализации
import java.util.concurrent.ForkJoinPool;
public class Start {
public static void main(String[] args) {
int componentValue
Особенности реализации
import java.util.concurrent.ForkJoinPool;
public class Start {
public static void main(String[] args) {
int componentValue
![Особенности реализации import java.util.concurrent.ForkJoinPool; public class Start { public static void main(String[]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1097978/slide-20.jpg)
Слайд 22Выбор предела (1)
Threshold можно определить по-разному в зависимости от вашей задачи
Например,
Выбор предела (1)
Threshold можно определить по-разному в зависимости от вашей задачи
Например,

Слайд 23Выбор предела (2)
Threshold можно определить по-разному в зависимости от вашей задачи
Например,
Выбор предела (2)
Threshold можно определить по-разному в зависимости от вашей задачи
Например,

Слайд 24Результат
Вариант №1 (threshold = 3 000 000)
значение = 7 000 000
threshold =
Результат
Вариант №1 (threshold = 3 000 000)
значение = 7 000 000
threshold =

Слайд 25Пример «ускорения» при использовании Fork/Join (1)
An informal test was conducted on a
Пример «ускорения» при использовании Fork/Join (1)
An informal test was conducted on a
Слайд 26Пример «ускорения» при использовании Fork/Join (2)
Пример нахождения максимального элемента в массиве из
Пример «ускорения» при использовании Fork/Join (2)
Пример нахождения максимального элемента в массиве из
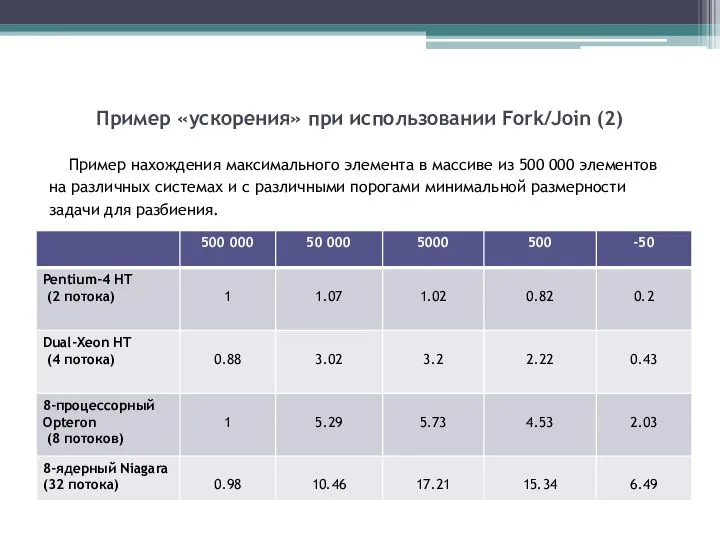
Слайд 27Итоги по использованию Fork/Join
1. Уменьшение времени расчета
Итоги по использованию Fork/Join
1. Уменьшение времени расчета
Слайд 28Итоги по использованию Fork/Join
1. Уменьшение времени расчета
2. Расчет не зависит от
Итоги по использованию Fork/Join
1. Уменьшение времени расчета
2. Расчет не зависит от
Слайд 29Итоги по использованию Fork/Join
1. Уменьшение времени расчета
2. Расчет не зависит от
Итоги по использованию Fork/Join
1. Уменьшение времени расчета
2. Расчет не зависит от
Слайд 30Итоги по использованию Fork/Join
1. Уменьшение времени расчета
2. Расчет не зависит от
Итоги по использованию Fork/Join
1. Уменьшение времени расчета
2. Расчет не зависит от
Слайд 31Итоги по использованию Fork/Join
1. Уменьшение времени расчета
2. Расчет не зависит от
Итоги по использованию Fork/Join
1. Уменьшение времени расчета
2. Расчет не зависит от
Слайд 32Итоги по использованию Fork/Join
1. Уменьшение времени расчета
2. Расчет не зависит от
Итоги по использованию Fork/Join
1. Уменьшение времени расчета
2. Расчет не зависит от
Слайд 33А были ли проблемы?
А были ли проблемы?

Слайд 34А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения
А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения

Слайд 35А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения
А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения

Слайд 36А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения
А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения

Слайд 37А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения
А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения

Слайд 38А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения
А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения

Слайд 39А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения
А были ли проблемы?
1. Проблема выбора или нахождения оптимального порогового значения

Слайд 40Второй этап реализации – это совершенствование (1)
Вынести повторяющийся код
Повторно использовать полученные данные
Получить
Второй этап реализации – это совершенствование (1)
Вынести повторяющийся код
Повторно использовать полученные данные
Получить

Слайд 41Второй этап реализации – это совершенствование (2)
Вынести повторяющийся код
Повторно использовать полученные данные
Получить
Второй этап реализации – это совершенствование (2)
Вынести повторяющийся код
Повторно использовать полученные данные
Получить

Слайд 42Stream API & ForkJoinPool
Рассмотрим параллельные «вычисления» в Stream API для Collection
Для
Stream API & ForkJoinPool
Рассмотрим параллельные «вычисления» в Stream API для Collection
Для

Слайд 43Doug Lea (1)
Вопрос
The java.util.streams framework
supports data-driven operations
on collections and other
Doug Lea (1)
Вопрос
The java.util.streams framework
supports data-driven operations
on collections and other

Слайд 44Doug Lea (2)
Вопрос читателя
Основной смысл вопроса читателя
сводится к желанию понять, когда
Doug Lea (2)
Вопрос читателя
Основной смысл вопроса читателя
сводится к желанию понять, когда

Слайд 45Java 8 Lambdas. Functional Programming for the Masses (1)
Ричард Уорбэртон в своей
Java 8 Lambdas. Functional Programming for the Masses (1)
Ричард Уорбэртон в своей

Слайд 46Java 8 Lambdas. Functional Programming for the Masses (2)
Пример «6.1»
public int
Java 8 Lambdas. Functional Programming for the Masses (2)
Пример «6.1»
public int

Слайд 47Еще немного про Stream API
Темой Stream API активно занимается
Тагир Валеев. В
Еще немного про Stream API
Темой Stream API активно занимается
Тагир Валеев. В

Слайд 48Спасибо
Время вопросов
Спасибо
Время вопросов

 Алгоритмы с разветвлениями для обработки величин
Алгоритмы с разветвлениями для обработки величин Табличный процессор Microsoft Excel
Табличный процессор Microsoft Excel Кодирование текстовой информации
Кодирование текстовой информации Ввод сз в действие
Ввод сз в действие Понятие физической среды передачи данных, типы линий связи
Понятие физической среды передачи данных, типы линий связи Гиперссылки. Способы и виды использования
Гиперссылки. Способы и виды использования AJAX
AJAX Операционные системы
Операционные системы Ведение страницы ТОДЮБ в социальных сетях, полезные советы
Ведение страницы ТОДЮБ в социальных сетях, полезные советы Электронный чек-лист. Способ оценивания
Электронный чек-лист. Способ оценивания ТРПО. Лекция 1
ТРПО. Лекция 1 Межкультурная коммуникация: введение в профессию
Межкультурная коммуникация: введение в профессию 7-1_Введение
7-1_Введение Управление информацией и данными в строительстве
Управление информацией и данными в строительстве 7-1-1
7-1-1 Синтез комбинационных схем. Типовые логические элементы и их обозначения на функциональных схемах
Синтез комбинационных схем. Типовые логические элементы и их обозначения на функциональных схемах Модели компьютерной графики
Модели компьютерной графики Презентация на тему Атрибуты тэгов
Презентация на тему Атрибуты тэгов  Язык программирования
Язык программирования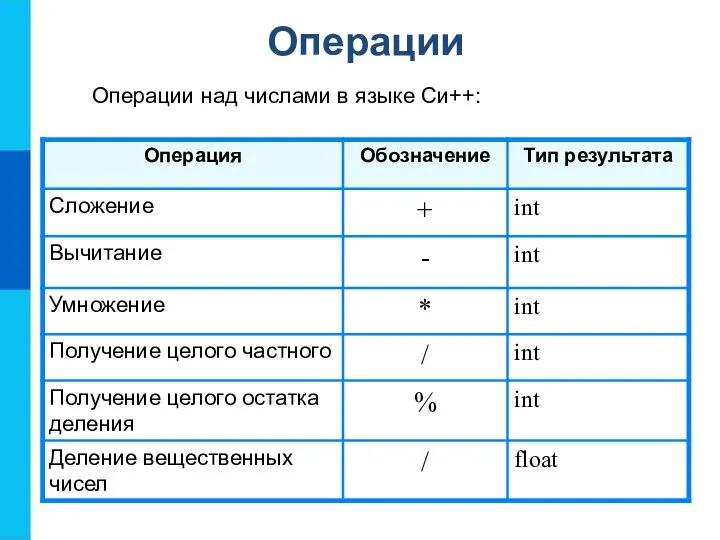 Операции над числами в языке Си++
Операции над числами в языке Си++ Тема урока: «Графические операторы языка Бейсик».
Тема урока: «Графические операторы языка Бейсик». Одномерные массивы целых чисел. Алгоритмизация и программирование
Одномерные массивы целых чисел. Алгоритмизация и программирование Знакомство с нейросетями и немного магии на JavaScript
Знакомство с нейросетями и немного магии на JavaScript Программная реализация задачи о рюкзаке
Программная реализация задачи о рюкзаке Роль интернета в жизни современного курсанта
Роль интернета в жизни современного курсанта Выставление на диспетчеризацию
Выставление на диспетчеризацию Презентация на тему Создание Web-сайта
Презентация на тему Создание Web-сайта  Повторный сброс-пин кода для электронных карт
Повторный сброс-пин кода для электронных карт