- Отбор признаков в задачах анализа данных

Содержание
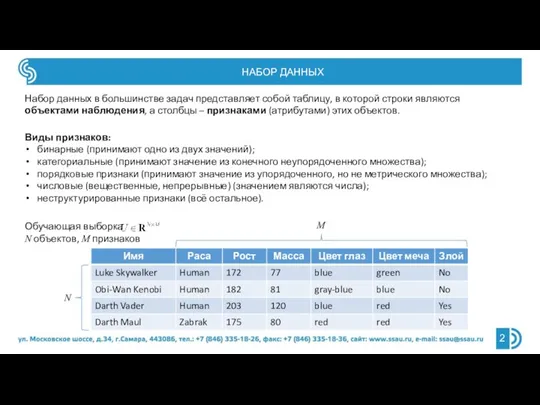
- 2. НАБОР ДАННЫХ Набор данных в большинстве задач представляет собой таблицу, в которой строки являются объектами наблюдения,
- 3. ЗАДАЧА КЛАССИФИКАЦИИ Всё множество объектов наблюдения Ω разделено на L классов {Ωl}, так что классы не
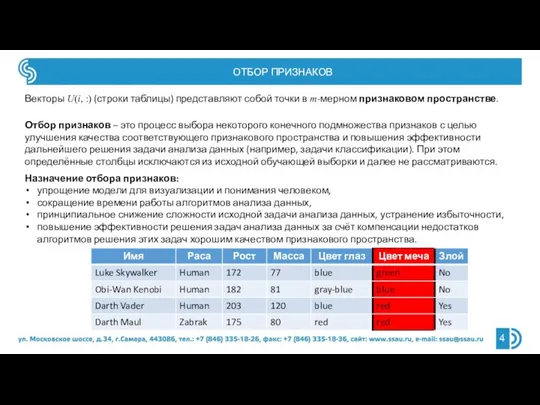
- 4. ОТБОР ПРИЗНАКОВ Векторы U(i, :) (строки таблицы) представляют собой точки в m-мерном признаковом пространстве. Отбор признаков
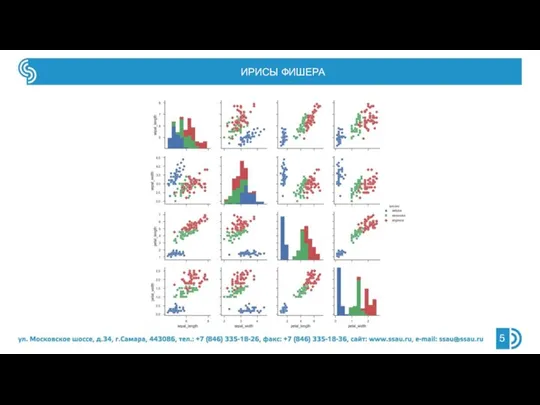
- 5. ИРИСЫ ФИШЕРА
- 6. ПОСТАНОВКА ЗАДАЧИ ОТБОРА ПРИЗНАКОВ Решить задачу отбора признаков – значит выбрать множество признаков так чтобы некоторый
- 7. КЛАССИФИКАЦИЯ АЛГОРИТМОВ ОТБОРА ПРИЗНАКОВ По характеру показателя качества признакового пространства J: Обёртки (wrappers) – методы отбора
- 8. ПОКАЗАТЕЛИ КАЧЕСТВА КЛАССИФИКАЦИИ Матрица ошибок (Confusion Matrix) Достоверность классификации (accuracy): – контрольная выборка Чувствительность (sensitivity, recall):
- 9. ПОКАЗАТЕЛИ КАЧЕСТВА ПРИЗНАКОВОГО ПРОСТРАНСТВА Матрица рассеяния внутри класса l: где – часть обучающей выборки из класса
- 10. ПОКАЗАТЕЛИ КАЧЕСТВА ПРИЗНАКОВОГО ПРОСТРАНСТВА Критерии дискриминантного анализа: Другие способы выбора внутриклассовой матрицы рассеяния: Другие способы выбора
- 11. ПОКАЗАТЕЛИ КАЧЕСТВА ПРИЗНАКОВОГО ПРОСТРАНСТВА Взаимная информация (mutual information): X – признаки случайного объекта, Y – класс
- 12. КЛАССИФИКАЦИЯ АЛГОРИТМОВ ОТБОРА ПРИЗНАКОВ По способу перебора подмножеств признаков: Жадные алгоритмы отбора признаков Упорядочение и отбор
- 13. УПОРЯДОЧЕНИЕ И ОТБОР ПРИЗНАКОВ Входные данные: количество признаков k, обучающая выборка U, показатель качества J Выходные
- 14. ЖАДНЫЕ АЛГОРИТМЫ ОТБОРА ПРИЗНАКОВ Входные данные: количество признаков k, обучающая выборка U, показатель качества J Выходные
- 15. ЖАДНЫЕ АЛГОРИТМЫ ОТБОРА ПРИЗНАКОВ Модификации жадных алгоритмов могут быть основаны на их комбинировании. – шаг вперёд
- 16. КЛАСТЕРИЗАЦИЯ Кластеризация (clustering) – это процедура разбиения множества векторов признаков в метрическом признаковом пространстве на непересекающиеся
- 17. КЛАСТЕРИЗАЦИЯ ПРИЗНАКОВ Входные данные: количество признаков k, обучающая выборка U, расстояние между признаками ρ Выходные данные:
- 18. ГЕНЕТИЧЕСКИЙ АЛГОРИТМ Генетический алгоритм (genetic algorithm) – это эвристический алгоритм оптимизации, основанный на использовании таких механизмов
- 19. ГЕНЕТИЧЕСКИЙ АЛГОРИТМ ОТБОРА ПРИЗНАКОВ Входные данные: количество признаков k, обучающая выборка U, показатель качества J Выходные
- 20. ОТБОР ПРИЗНАКОВ И ТЕОРИЯ ГРАФОВ Рассмотрим граф: вершины – подмножества признаков, рёбра – близкие между собой
- 21. СПИСОК ЛИТЕРАТУРЫ Guyon, I. An Introduction to Variable and Feature Selection / I. Guyon, A. Elisseeff
- 22. ЗАКЛЮЧЕНИЕ Когда подбор параметров классификатора уже не помогает повысить эффективность классификации, отбор признаков в некоторых случаях
- 24. Скачать презентацию
Слайд 3ЗАДАЧА КЛАССИФИКАЦИИ
Всё множество объектов наблюдения Ω разделено на L классов {Ωl}, так
ЗАДАЧА КЛАССИФИКАЦИИ
Всё множество объектов наблюдения Ω разделено на L классов {Ωl}, так
Слайд 4ОТБОР ПРИЗНАКОВ
Векторы U(i, :) (строки таблицы) представляют собой точки в m-мерном признаковом
ОТБОР ПРИЗНАКОВ
Векторы U(i, :) (строки таблицы) представляют собой точки в m-мерном признаковом
Слайд 5ИРИСЫ ФИШЕРА
ИРИСЫ ФИШЕРА
Слайд 6ПОСТАНОВКА ЗАДАЧИ ОТБОРА ПРИЗНАКОВ
Решить задачу отбора признаков – значит выбрать множество признаков
так
ПОСТАНОВКА ЗАДАЧИ ОТБОРА ПРИЗНАКОВ
Решить задачу отбора признаков – значит выбрать множество признаков
так

Слайд 7КЛАССИФИКАЦИЯ АЛГОРИТМОВ ОТБОРА ПРИЗНАКОВ
По характеру показателя качества признакового пространства J:
Обёртки (wrappers) –
КЛАССИФИКАЦИЯ АЛГОРИТМОВ ОТБОРА ПРИЗНАКОВ
По характеру показателя качества признакового пространства J:
Обёртки (wrappers) –

Слайд 8ПОКАЗАТЕЛИ КАЧЕСТВА КЛАССИФИКАЦИИ
Матрица ошибок
(Confusion Matrix)
Достоверность классификации (accuracy):
– контрольная выборка
Чувствительность (sensitivity, recall):
Специфичность (specificity,
ПОКАЗАТЕЛИ КАЧЕСТВА КЛАССИФИКАЦИИ
Матрица ошибок
(Confusion Matrix)
Достоверность классификации (accuracy):
– контрольная выборка
Чувствительность (sensitivity, recall):
Специфичность (specificity,

Слайд 9ПОКАЗАТЕЛИ КАЧЕСТВА ПРИЗНАКОВОГО ПРОСТРАНСТВА
Матрица рассеяния внутри класса l:
где
– часть обучающей выборки из
ПОКАЗАТЕЛИ КАЧЕСТВА ПРИЗНАКОВОГО ПРОСТРАНСТВА
Матрица рассеяния внутри класса l:
где
– часть обучающей выборки из

Слайд 10ПОКАЗАТЕЛИ КАЧЕСТВА ПРИЗНАКОВОГО ПРОСТРАНСТВА
Критерии дискриминантного анализа:
Другие способы выбора внутриклассовой матрицы рассеяния:
Другие способы
ПОКАЗАТЕЛИ КАЧЕСТВА ПРИЗНАКОВОГО ПРОСТРАНСТВА
Критерии дискриминантного анализа:
Другие способы выбора внутриклассовой матрицы рассеяния:
Другие способы

Слайд 11ПОКАЗАТЕЛИ КАЧЕСТВА ПРИЗНАКОВОГО ПРОСТРАНСТВА
Взаимная информация (mutual information):
X – признаки случайного объекта, Y
ПОКАЗАТЕЛИ КАЧЕСТВА ПРИЗНАКОВОГО ПРОСТРАНСТВА
Взаимная информация (mutual information):
X – признаки случайного объекта, Y

Слайд 12КЛАССИФИКАЦИЯ АЛГОРИТМОВ ОТБОРА ПРИЗНАКОВ
По способу перебора подмножеств признаков:
Жадные алгоритмы отбора признаков
Упорядочение и
КЛАССИФИКАЦИЯ АЛГОРИТМОВ ОТБОРА ПРИЗНАКОВ
По способу перебора подмножеств признаков:
Жадные алгоритмы отбора признаков
Упорядочение и

Слайд 13УПОРЯДОЧЕНИЕ И ОТБОР ПРИЗНАКОВ
Входные данные: количество признаков k, обучающая выборка U, показатель
УПОРЯДОЧЕНИЕ И ОТБОР ПРИЗНАКОВ
Входные данные: количество признаков k, обучающая выборка U, показатель

Слайд 14ЖАДНЫЕ АЛГОРИТМЫ ОТБОРА ПРИЗНАКОВ
Входные данные: количество признаков k, обучающая выборка U, показатель
ЖАДНЫЕ АЛГОРИТМЫ ОТБОРА ПРИЗНАКОВ
Входные данные: количество признаков k, обучающая выборка U, показатель

Слайд 15ЖАДНЫЕ АЛГОРИТМЫ ОТБОРА ПРИЗНАКОВ
Модификации жадных алгоритмов могут быть основаны на их комбинировании.
–
ЖАДНЫЕ АЛГОРИТМЫ ОТБОРА ПРИЗНАКОВ
Модификации жадных алгоритмов могут быть основаны на их комбинировании.
–

Слайд 16КЛАСТЕРИЗАЦИЯ
Кластеризация (clustering) – это процедура разбиения множества векторов признаков в метрическом признаковом
КЛАСТЕРИЗАЦИЯ
Кластеризация (clustering) – это процедура разбиения множества векторов признаков в метрическом признаковом
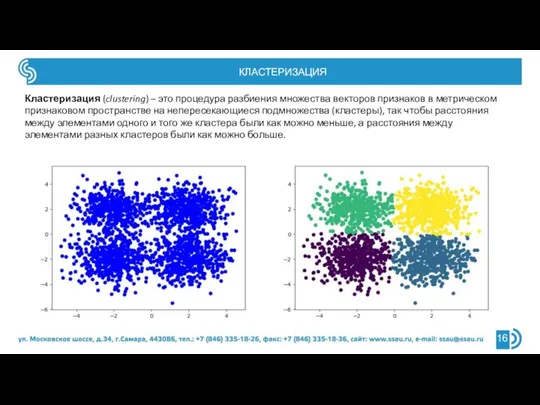
Слайд 17КЛАСТЕРИЗАЦИЯ ПРИЗНАКОВ
Входные данные: количество признаков k, обучающая выборка U, расстояние между признаками
КЛАСТЕРИЗАЦИЯ ПРИЗНАКОВ
Входные данные: количество признаков k, обучающая выборка U, расстояние между признаками

Слайд 18ГЕНЕТИЧЕСКИЙ АЛГОРИТМ
Генетический алгоритм (genetic algorithm) – это эвристический алгоритм оптимизации, основанный на
ГЕНЕТИЧЕСКИЙ АЛГОРИТМ
Генетический алгоритм (genetic algorithm) – это эвристический алгоритм оптимизации, основанный на
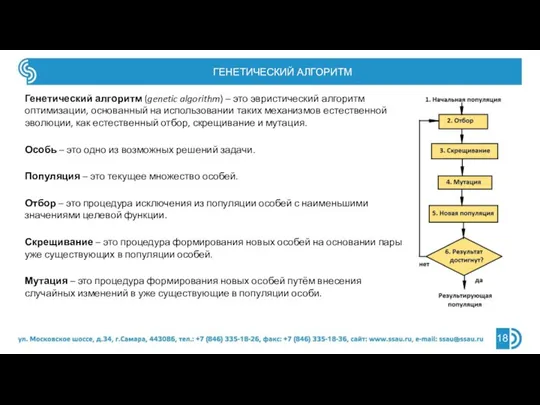
Слайд 19ГЕНЕТИЧЕСКИЙ АЛГОРИТМ ОТБОРА ПРИЗНАКОВ
Входные данные: количество признаков k, обучающая выборка U, показатель
ГЕНЕТИЧЕСКИЙ АЛГОРИТМ ОТБОРА ПРИЗНАКОВ
Входные данные: количество признаков k, обучающая выборка U, показатель
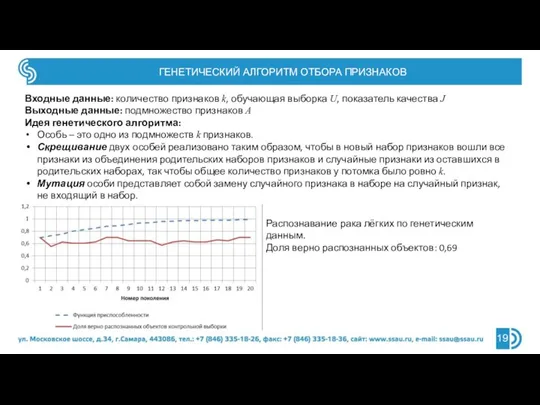
Слайд 20ОТБОР ПРИЗНАКОВ И ТЕОРИЯ ГРАФОВ
Рассмотрим граф:
вершины – подмножества признаков,
рёбра – близкие между
ОТБОР ПРИЗНАКОВ И ТЕОРИЯ ГРАФОВ
Рассмотрим граф:
вершины – подмножества признаков,
рёбра – близкие между

Слайд 21СПИСОК ЛИТЕРАТУРЫ
Guyon, I. An Introduction to Variable and Feature Selection / I.
СПИСОК ЛИТЕРАТУРЫ
Guyon, I. An Introduction to Variable and Feature Selection / I.

Слайд 22ЗАКЛЮЧЕНИЕ
Когда подбор параметров классификатора уже не помогает повысить эффективность классификации, отбор признаков
ЗАКЛЮЧЕНИЕ
Когда подбор параметров классификатора уже не помогает повысить эффективность классификации, отбор признаков

 Countdown 4 Poster Scheme
Countdown 4 Poster Scheme Продукты и сервисы Microsoft для студентов
Продукты и сервисы Microsoft для студентов Создание надежного протокола на основе криптосистемы Э.М. Габидулина
Создание надежного протокола на основе криптосистемы Э.М. Габидулина Динамическое создание объектов
Динамическое создание объектов шаг
шаг E-Invoicing и PayByClick – удобный способ принимать оплату в интернете
E-Invoicing и PayByClick – удобный способ принимать оплату в интернете Презентация на тему Создание кроссвордов в MS WORD
Презентация на тему Создание кроссвордов в MS WORD  Интернет-маркетинговое агентство Smartnet 24. Внедрение Битрикс24.CRM
Интернет-маркетинговое агентство Smartnet 24. Внедрение Битрикс24.CRM Алгоритмы. Классы алгоритмов
Алгоритмы. Классы алгоритмов Обработка текстовой информации
Обработка текстовой информации Измерение информации (алфавитный подход)
Измерение информации (алфавитный подход) MPLS
MPLS Эра космонавтики
Эра космонавтики Взаимодействие с базой данных в технологии интранет
Взаимодействие с базой данных в технологии интранет Сетикет
Сетикет Шаблон Презентации
Шаблон Презентации SketchUp. Основы проектирования. Самый простой способ рисовать в 3D. Урок 4
SketchUp. Основы проектирования. Самый простой способ рисовать в 3D. Урок 4 Структура html-документа
Структура html-документа Госслужащие и социальные сети
Госслужащие и социальные сети Что такое информатика
Что такое информатика Одномерные массивы целых чисел. Начала программирования. 9 класс
Одномерные массивы целых чисел. Начала программирования. 9 класс Стенд по изучению азбуки Морзе
Стенд по изучению азбуки Морзе Bedienung des Service Tool`s für OMRON Werkzeugmagazin
Bedienung des Service Tool`s für OMRON Werkzeugmagazin Подключение к е-Факторинг 3.0
Подключение к е-Факторинг 3.0 Медиа Азбука
Медиа Азбука Какие есть виды ферм
Какие есть виды ферм Разработка удаленной базы данных для программы автоматизации работы эксплуатационно-технического отдела ФГБОУ САМГМУ
Разработка удаленной базы данных для программы автоматизации работы эксплуатационно-технического отдела ФГБОУ САМГМУ Индивидуальный проект. От абака до компьютера
Индивидуальный проект. От абака до компьютера