Автоматизация разработки параллельных программ для современных высокопроизводительных ЭВМВ.А. КрюковФакультет ВМК МГУ,Инсти
- Автоматизация разработки параллельных программ для современных высокопроизводительных ЭВМВ.А. КрюковФакультет ВМК МГУ,Инсти

Содержание
- 2. План изложения Модели и языки программирования с явным параллелизмом (абстрактная и целевая машина, уровень, компилятор/библиотека, новый
- 3. Модели и языки программирования с явным параллелизмом абстрактная параллельная машина и целевая ЭВМ: многоядерный кластер с
- 4. Модели и языки с явным параллелизмом
- 5. Алгоритм Якоби на языке Fortran PROGRAM JACOB_SEQ PARAMETER (L=8, ITMAX=20) REAL A(L,L), B(L,L) PRINT *, '**********
- 6. Distribution of array A [8][8]
- 7. PROGRAM JACOB_MPI include 'mpif.h' integer me, nprocs PARAMETER (L=4096, ITMAX=100, LC=2, LR=2) REAL A(0:L/LR+1,0:L/LC+1), B(L/LR,L/LC) C
- 8. C rows of matrix I have to process srow = (coords(1) * L) / dim(1) lrow
- 9. call MPI_Irecv(A(1,0),nrow,MPI_DOUBLE_PRECISION, * pleft, 1235, MPI_COMM_WORLD, req(1), ierr) call MPI_Isend(A(1,ncol),nrow,MPI_DOUBLE_PRECISION, * pright, 1235, MPI_COMM_WORLD,req(2), ierr) call
- 10. PROGRAM JACOB_OpenMP PARAMETER (L=4096, ITMAX=100) REAL A(L,L), B(L,L) PRINT *, '********** TEST_JACOBI **********' !$OMP PARALLEL DO
- 11. module jac_cuda contains attributes(global) subroutine arr_copy(a, b, k) real, device, dimension(k, k) :: a, b integer,
- 12. program JACOB_CUDA use cudafor use jac_cuda parameter (k=4096, itmax = 100, block_dim = 16) real, device,
- 13. PROGRAM JACOB_PGI_APM PARAMETER (L=4096, ITMAX=100) REAL A(L,L), B(L,L) PRINT *, '********** TEST_JACOBI **********‘ !$acc data region
- 14. Автоматическое распараллеливание Для распределенных систем проблематично в силу следующих причин: вычислительная работа должна распределяться между процессорами
- 15. Модель параллелизма по данным отсутствует понятие процесса и, как следствие, явная передача сообщений или явная синхронизация
- 16. HPF (High Performance Fortran) HPF (1993 год) - расширение языка Фортран 90 HPF-2 (1997 год) -
- 17. PROGRAM JAC_HPF PARAMETER (L=8, ITMAX=20) REAL A(L,L), B(L,L) !HPF$ PROCESSORS P(3,3) !HPF$ DISTRIBUTE ( BLOCK, BLOCK)
- 18. PROGRAM JACOB_DVM PARAMETER (L=4096, ITMAX=100) REAL A(L,L), B(L,L) CDVM$ DISTRIBUTE ( BLOCK, BLOCK) :: A CDVM$
- 19. Новые языки параллельного программирования (PGAS) PGAS – Partitioned Global Address Space (не DSM !) CAF (Co-Array
- 20. Coarray Fortran PROGRAM Jac_CoArray PARAMETER (L=8, ITMAX=20, LR=2, LC=2) PARAMETER (NROW=L/LR, NCOL=L/LC) INTEGER ME, I, J,
- 21. DO IT = 1, ITMAX CALL SYNC_ALL ( ) DO J = 1, NCOL DO I
- 22. Развитие языков (PGAS=>APGAS) Добавление асинхронности в CAF и UPC CAF 2.0: подгруппы процессов, топологии, новые средства
- 23. SEQ – последовательная программа, MPI –параллельная MPI-программа DVM – параллельная DVM-программа, CAF – параллельная CoArray Fortran
- 24. Создаваемые языки параллельного программирования (HPCS) DARPA – High Productivity Computing Systems 2002-2010 (эффективность, программируемость, переносимость ПО,
- 25. Цели разработки Chapel (Cray) Снизить трудоемкость программирования - написание программы, ее изменение, тюнинг, портирование, сопровождение Эффективность
- 26. Основные черты языка Chapel Полнота поддержки параллелизма - параллелизм по данным, параллелизм задач, вложенный параллелизм -
- 27. Основные отличия X10 (IBM) Является расширением языка Java Отличие доступа к локальным и удаленным данным (как
- 28. PROGRAM JACOB_DVM_OpenMP PARAMETER (L=4096, ITMAX=100) REAL A(L,L), B(L,L) CDVM$ DISTRIBUTE ( BLOCK, BLOCK) :: A CDVM$
- 29. PROGRAM JACOB_DVMH PARAMETER (L=4096, ITMAX=100) REAL A(L,L), B(L,L) CDVM$ DISTRIBUTE ( BLOCK, BLOCK) :: A CDVM$
- 30. Времена выполнения программы JACRED_DVMH (сек) на кластере K-100
- 31. План изложения Модели и языки программирования с явным параллелизмом (абстрактная и целевая машина, уровень, компилятор/библиотека, новый
- 32. Автоматизация параллельного программирования Два новых (2005 г.) направления автоматизации в системе DVM: дисциплина написания на языках
- 33. Автоматизация разработки параллельных программ для кластеров Программа на последовательном языке S Задание на отладку Распараллеливающий компилятор
- 34. Формирование вариантов распределения данных (ВРД) Анализ последовательной программы Для каждого ВРД формирование схем распараллеливания - добавление
- 35. Анализ последовательной программы Статический анализ – указатели, косвенная индексация, параметры…. Динамический анализ – ресурсы времени и
- 36. Алгоритм Якоби на языке Fortran PROGRAM JACOB_SEQ PARAMETER (L=8, ITMAX=20) REAL A(L,L), B(L,L) PRINT *, '**********
- 37. Поиск наилучшей схемы распараллеливания Логическая сложность алгоритмов построения и оценки схем распараллеливания (мало зависит от выходного
- 38. Блоки компилятора АРК-DVM Анализатор 1 Описание ЭВМ Фортран программа База данных Эксперт 1 Фортран-DVM программа Анализатор
- 39. Работа компилятора проверена на: тестах NAS LU, BT, SP (3D Навье-Стокс) - класс С и А
- 40. Характеристики программ
- 41. Времена выполнения (сек) на МВС-100К DVM-программ класса С
- 42. План изложения Модели и языки программирования с явным параллелизмом (абстрактная и целевая машина, уровень, компилятор/библиотека, новый
- 43. Автоматизированное распараллеливание последовательных программ Диалог с пользователем для: Исследования результатов анализа и задания характеристик программы, недоступных
- 45. САПФОР: анализ программы и прогноз эффективности ее параллельного выполнения Скорректированная исходная программа FDVMH-компилятор FDVMH-программа Программа на
- 46. Принципиальные решения DVM-подход: Программист принимает основные решения по распараллеливанию, а компилятор и система поддержки обеспечивают их
- 47. План изложения Модели и языки программирования с явным параллелизмом Языки программирования с неявным параллелизмом + автоматическое
- 48. Автоматизация функциональной отладки параллельных программ Автоматизированное сравнение поведения и промежуточных результатов разных версий последовательной программы Динамический
- 49. Функциональная отладка DVM-программ Используется следующая методика поэтапной отладки программ: На первом этапе программа отлаживается на рабочей
- 50. Типы ошибок Синтаксические ошибки в DVM-указаниях и нарушение статической семантики Неправильная последовательность выполнения DVM-указаний или неправильные
- 51. Динамический контроль Чтение неинициализированных переменных Выход за пределы массива Необъявленная зависимость по данным в параллельной конструкции
- 52. Сравнение результатов Где и что сравнивать Две трассы, одна трасса, без трасс – на лету Получение
- 53. Автоматизация отладки эффективности параллельных программ Прогноз характеристик эффективности каждого варианта распараллеливания для разных конфигураций интересующих пользователя
- 54. Эффективность выполнения параллельной программы Эффективность выполнения параллельной программы выражается в ускорении вычислений, что может привести: к
- 55. Критерии эффективности выполнения параллельных программ Ускорение Sn = T1 / Tn, где Tn — время исполнения
- 56. Критерии эффективности выполнения параллельных программ Если ускорение линейно от n, то говорят, что такая программа обладает
- 57. Факторы, определяющие эффективность выполнения параллельных программ степень распараллеливания программы - доля параллельных вычислений в общем объеме
- 58. Характеристики эффективности параллельных программ Пользователь может получить следующие характеристики эффективности программы и отдельных ее частей: execution
- 59. Характеристики эффективности параллельных программ Компоненты lost time: insufficient parallelism - потери из-за выполнения последовательных частей программы
- 60. Характеристики эффективности параллельных программ Кроме того, выдаются характеристики: load imbalance - возможные потери из-за разной загрузки
- 61. Подходы к вычислению и выдаче характеристик Как собирать трассировка (для каждого процессора, каждой нити) статистика количество
- 62. Проблема – нестабильность характеристик Нестабильность коммуникаций Изменение состава процессоров при неоднородности коммуникационной среды Загрузка коммуникационной среды
- 63. Нестабильность производительности процессоров Попадание на медленные процессоры (появляется разбалансировка, можно запрашивать лишние процессоры и отключать медленные)
- 64. Предсказатель эффективности DVM-программ получает характеристики выполнения DVM-программы на рабочей станции и использует их для предсказания эффективности
- 65. Принципиальные трудности предсказания эффективности Для современных процессоров трудно прогнозировать время выполнения разных фрагментов программы (кэш-память и
- 66. Предсказатель – инструмент отладки эффективности Он может довольно точно оценить влияние основных факторов: степень распараллеливания программы
- 67. Предсказатель – инструмент отладки эффективности На современных процессорах эффективность вычислений может отличаться в 3-7 раз в
- 68. Выводы Отладка эффективности параллельных программ – процесс очень сложный и трудоемкий Развитые средства анализа эффективности могут
- 69. Вопросы, замечания? СПАСИБО !
- 71. Скачать презентацию

Слайд 3Модели и языки программирования с явным параллелизмом
абстрактная параллельная машина и целевая ЭВМ:
Модели и языки программирования с явным параллелизмом
абстрактная параллельная машина и целевая ЭВМ:

Слайд 4Модели и языки с явным параллелизмом
Модели и языки с явным параллелизмом

Слайд 5Алгоритм Якоби на языке Fortran
PROGRAM JACOB_SEQ
PARAMETER (L=8, ITMAX=20)
REAL
Алгоритм Якоби на языке Fortran
PROGRAM JACOB_SEQ
PARAMETER (L=8, ITMAX=20)
REAL

Слайд 6Distribution of array A [8][8]
Distribution of array A [8][8]
![Distribution of array A [8][8]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/386519/slide-5.jpg)
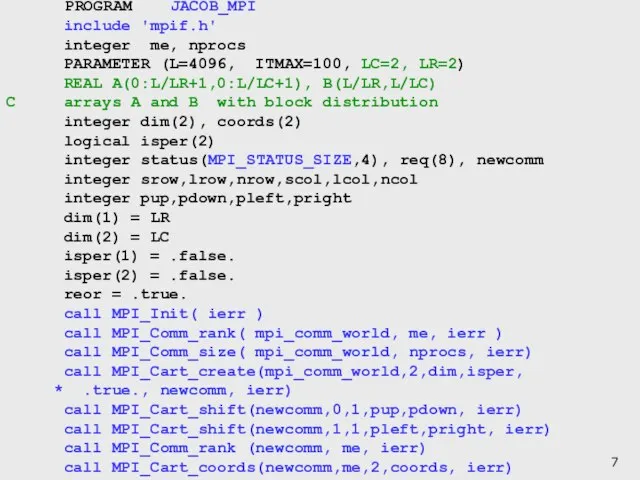
Слайд 7 PROGRAM JACOB_MPI
include 'mpif.h'
integer me, nprocs
PARAMETER (L=4096, ITMAX=100, LC=2,
PROGRAM JACOB_MPI
include 'mpif.h'
integer me, nprocs
PARAMETER (L=4096, ITMAX=100, LC=2,
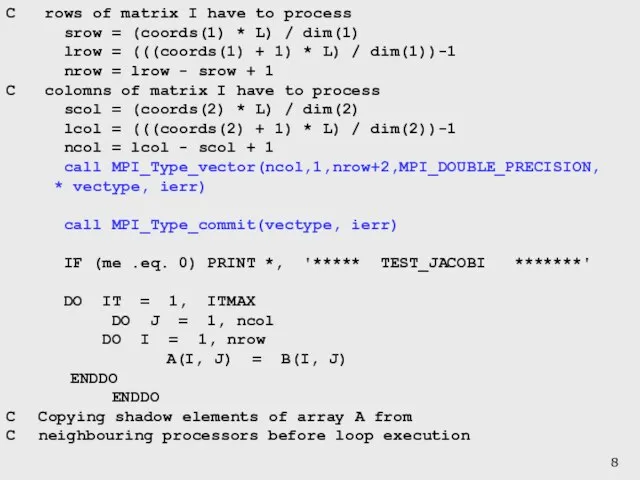
Слайд 8C rows of matrix I have to process
srow = (coords(1) *
C rows of matrix I have to process
srow = (coords(1) *
Слайд 9 call MPI_Irecv(A(1,0),nrow,MPI_DOUBLE_PRECISION,
* pleft, 1235, MPI_COMM_WORLD, req(1), ierr)
call MPI_Isend(A(1,ncol),nrow,MPI_DOUBLE_PRECISION,
*
call MPI_Irecv(A(1,0),nrow,MPI_DOUBLE_PRECISION,
* pleft, 1235, MPI_COMM_WORLD, req(1), ierr)
call MPI_Isend(A(1,ncol),nrow,MPI_DOUBLE_PRECISION,
*

Слайд 10 PROGRAM JACOB_OpenMP
PARAMETER (L=4096, ITMAX=100)
REAL A(L,L), B(L,L)
PRINT *, '**********
PROGRAM JACOB_OpenMP
PARAMETER (L=4096, ITMAX=100)
REAL A(L,L), B(L,L)
PRINT *, '**********

Слайд 11 module jac_cuda
contains
attributes(global) subroutine arr_copy(a, b, k)
real, device, dimension(k, k) :: a,
module jac_cuda
contains
attributes(global) subroutine arr_copy(a, b, k)
real, device, dimension(k, k) :: a,

Слайд 12 program JACOB_CUDA
use cudafor
use jac_cuda
parameter (k=4096, itmax = 100, block_dim = 16)
real,
program JACOB_CUDA
use cudafor
use jac_cuda
parameter (k=4096, itmax = 100, block_dim = 16)
real,

Слайд 13 PROGRAM JACOB_PGI_APM
PARAMETER (L=4096, ITMAX=100)
REAL A(L,L), B(L,L)
PRINT *, '**********
PROGRAM JACOB_PGI_APM
PARAMETER (L=4096, ITMAX=100)
REAL A(L,L), B(L,L)
PRINT *, '**********

Слайд 14Автоматическое распараллеливание
Для распределенных систем проблематично в силу следующих причин:
вычислительная работа должна
Автоматическое распараллеливание
Для распределенных систем проблематично в силу следующих причин:
вычислительная работа должна

Слайд 15Модель параллелизма по данным
отсутствует понятие процесса и, как следствие, явная передача
Модель параллелизма по данным
отсутствует понятие процесса и, как следствие, явная передача

Слайд 16HPF (High Performance Fortran)
HPF (1993 год) - расширение языка Фортран 90
HPF-2 (1997
HPF (High Performance Fortran)
HPF (1993 год) - расширение языка Фортран 90
HPF-2 (1997

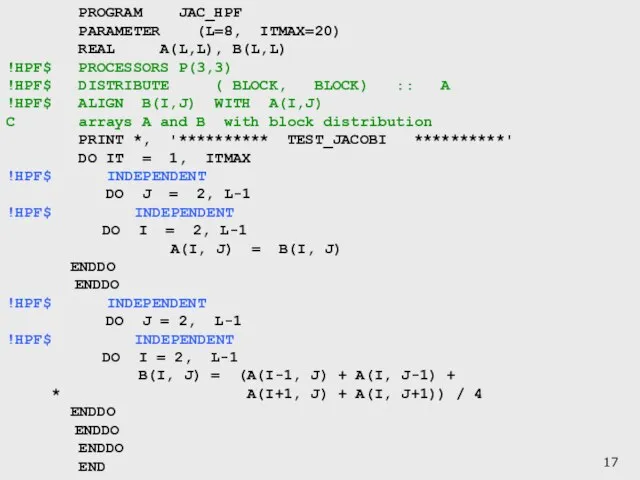
Слайд 17 PROGRAM JAC_HPF
PARAMETER (L=8, ITMAX=20)
REAL A(L,L), B(L,L)
!HPF$ PROCESSORS P(3,3)
!HPF$ DISTRIBUTE
PROGRAM JAC_HPF
PARAMETER (L=8, ITMAX=20)
REAL A(L,L), B(L,L)
!HPF$ PROCESSORS P(3,3)
!HPF$ DISTRIBUTE
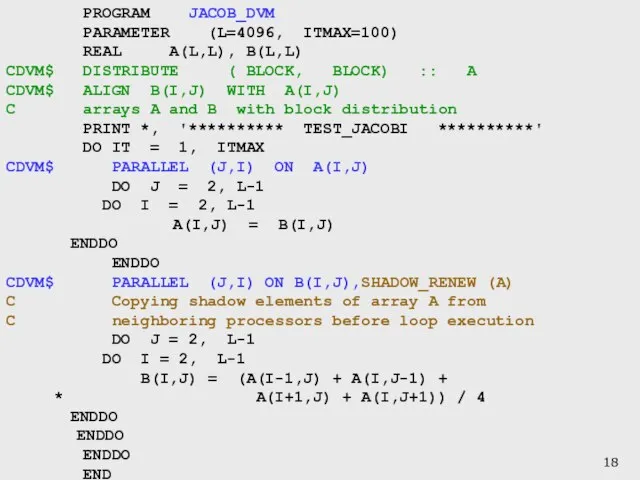
Слайд 18 PROGRAM JACOB_DVM
PARAMETER (L=4096, ITMAX=100)
REAL A(L,L), B(L,L)
CDVM$ DISTRIBUTE ( BLOCK,
PROGRAM JACOB_DVM
PARAMETER (L=4096, ITMAX=100)
REAL A(L,L), B(L,L)
CDVM$ DISTRIBUTE ( BLOCK,
Слайд 19Новые языки параллельного программирования (PGAS)
PGAS – Partitioned Global Address Space (не DSM
Новые языки параллельного программирования (PGAS)
PGAS – Partitioned Global Address Space (не DSM

Слайд 20Coarray Fortran
PROGRAM Jac_CoArray
PARAMETER (L=8, ITMAX=20, LR=2, LC=2)
PARAMETER (NROW=L/LR,
Coarray Fortran
PROGRAM Jac_CoArray
PARAMETER (L=8, ITMAX=20, LR=2, LC=2)
PARAMETER (NROW=L/LR,

Слайд 21DO IT = 1, ITMAX
CALL SYNC_ALL ( )
DO J =
CALL SYNC_ALL ( )
DO J =

Слайд 22Развитие языков (PGAS=>APGAS)
Добавление асинхронности в CAF и UPC
CAF 2.0:
подгруппы процессов,
топологии,
Развитие языков (PGAS=>APGAS)
Добавление асинхронности в CAF и UPC
CAF 2.0:
подгруппы процессов,
топологии,

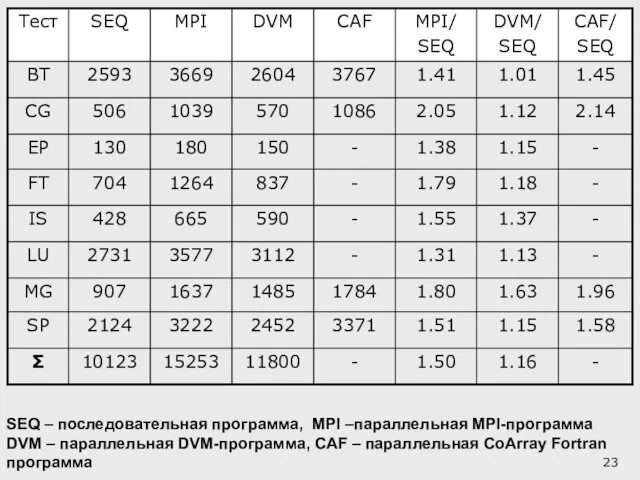
Слайд 23SEQ – последовательная программа, MPI –параллельная MPI-программа
DVM – параллельная DVM-программа, CAF –
SEQ – последовательная программа, MPI –параллельная MPI-программа
DVM – параллельная DVM-программа, CAF –
Слайд 24Создаваемые языки параллельного программирования (HPCS)
DARPA – High Productivity Computing Systems
2002-2010
(эффективность,
Создаваемые языки параллельного программирования (HPCS)
DARPA – High Productivity Computing Systems
2002-2010
(эффективность,

Слайд 25Цели разработки Chapel (Cray)
Снизить трудоемкость программирования
- написание программы, ее изменение, тюнинг, портирование,
Цели разработки Chapel (Cray)
Снизить трудоемкость программирования - написание программы, ее изменение, тюнинг, портирование,

Слайд 26Основные черты языка Chapel
Полнота поддержки параллелизма
- параллелизм по данным, параллелизм задач,
Основные черты языка Chapel
Полнота поддержки параллелизма - параллелизм по данным, параллелизм задач,

Слайд 27Основные отличия X10 (IBM)
Является расширением языка Java
Отличие доступа к локальным и удаленным
Основные отличия X10 (IBM)
Является расширением языка Java
Отличие доступа к локальным и удаленным

Слайд 28 PROGRAM JACOB_DVM_OpenMP
PARAMETER (L=4096, ITMAX=100)
REAL A(L,L), B(L,L)
CDVM$ DISTRIBUTE ( BLOCK,
PROGRAM JACOB_DVM_OpenMP
PARAMETER (L=4096, ITMAX=100)
REAL A(L,L), B(L,L)
CDVM$ DISTRIBUTE ( BLOCK,

Слайд 29 PROGRAM JACOB_DVMH
PARAMETER (L=4096, ITMAX=100)
REAL A(L,L), B(L,L)
CDVM$ DISTRIBUTE ( BLOCK,
PROGRAM JACOB_DVMH
PARAMETER (L=4096, ITMAX=100)
REAL A(L,L), B(L,L)
CDVM$ DISTRIBUTE ( BLOCK,

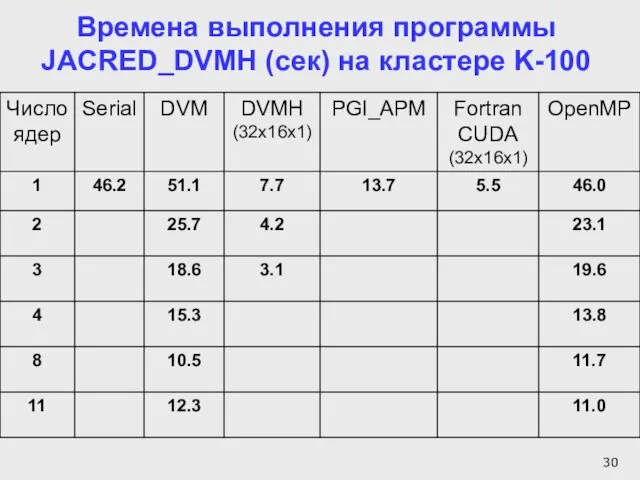
Слайд 30Времена выполнения программы JACRED_DVMH (сек) на кластере K-100
Времена выполнения программы JACRED_DVMH (сек) на кластере K-100
Слайд 31План изложения
Модели и языки программирования с явным параллелизмом (абстрактная и целевая машина,
План изложения
Модели и языки программирования с явным параллелизмом (абстрактная и целевая машина,

Слайд 32Автоматизация параллельного программирования
Два новых (2005 г.) направления автоматизации в системе DVM:
дисциплина
Автоматизация параллельного программирования
Два новых (2005 г.) направления автоматизации в системе DVM:
дисциплина

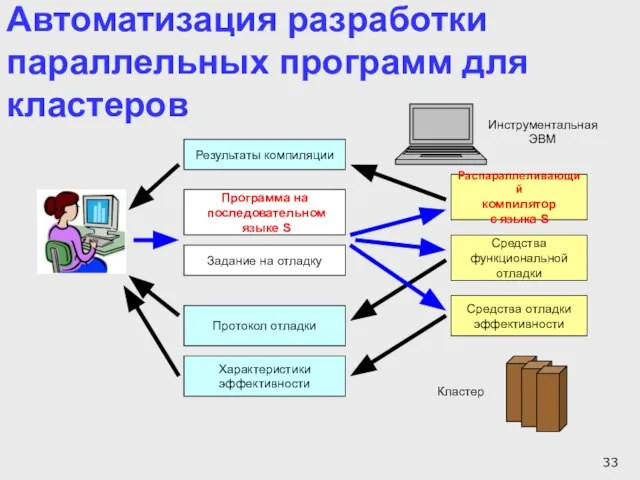
Слайд 33Автоматизация разработки параллельных программ для кластеров
Программа на
последовательном
языке S
Задание на отладку
Распараллеливающий
компилятор
с
Автоматизация разработки параллельных программ для кластеров
Программа на
последовательном
языке S
Задание на отладку
Распараллеливающий
компилятор
с
Слайд 34
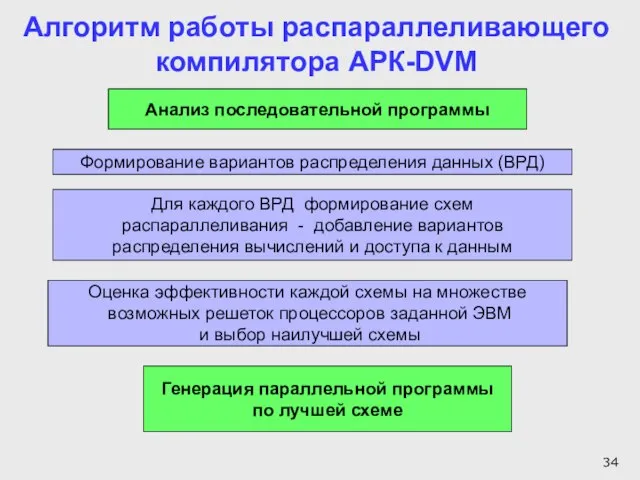
Формирование вариантов распределения данных (ВРД)
Анализ последовательной программы
Для каждого ВРД формирование схем
Формирование вариантов распределения данных (ВРД)
Анализ последовательной программы
Для каждого ВРД формирование схем
Слайд 35Анализ последовательной
программы
Статический анализ – указатели, косвенная индексация, параметры….
Динамический анализ – ресурсы
Анализ последовательной
программы
Статический анализ – указатели, косвенная индексация, параметры….
Динамический анализ – ресурсы

Слайд 36Алгоритм Якоби на языке Fortran
PROGRAM JACOB_SEQ
PARAMETER (L=8, ITMAX=20)
REAL
Алгоритм Якоби на языке Fortran
PROGRAM JACOB_SEQ
PARAMETER (L=8, ITMAX=20)
REAL

Слайд 37Поиск наилучшей схемы распараллеливания
Логическая сложность алгоритмов построения и оценки схем распараллеливания (мало
Поиск наилучшей схемы распараллеливания
Логическая сложность алгоритмов построения и оценки схем распараллеливания (мало

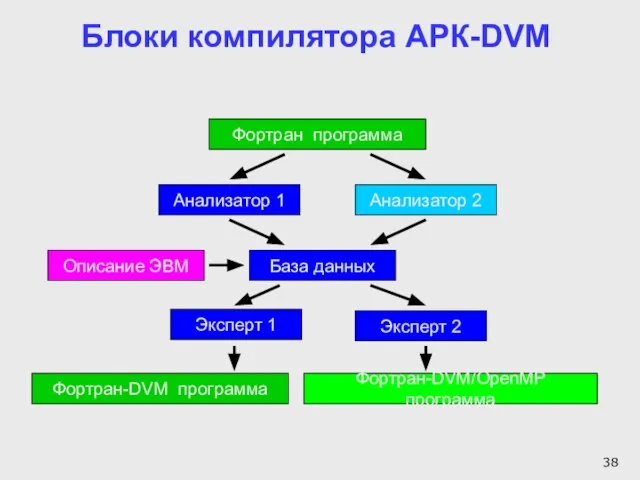
Слайд 38Блоки компилятора АРК-DVM
Анализатор 1
Описание ЭВМ
Фортран программа
База данных
Эксперт 1
Фортран-DVM программа
Анализатор 2
Эксперт
Блоки компилятора АРК-DVM
Анализатор 1
Описание ЭВМ
Фортран программа
База данных
Эксперт 1
Фортран-DVM программа
Анализатор 2
Эксперт
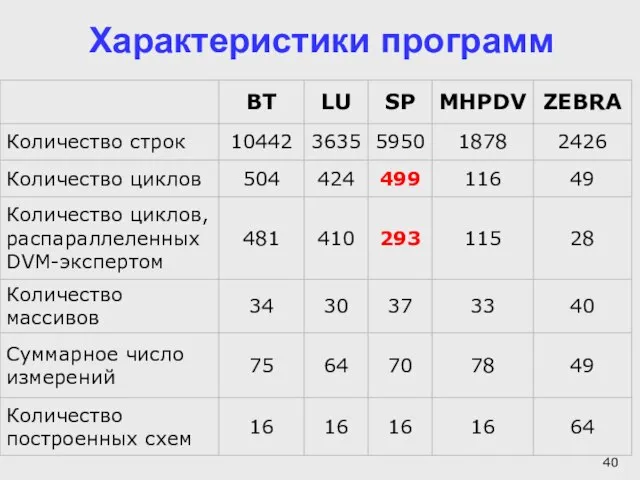
Слайд 39Работа компилятора проверена на:
тестах NAS LU, BT, SP (3D Навье-Стокс) - класс
Работа компилятора проверена на:
тестах NAS LU, BT, SP (3D Навье-Стокс) - класс

Слайд 40Характеристики программ
Характеристики программ
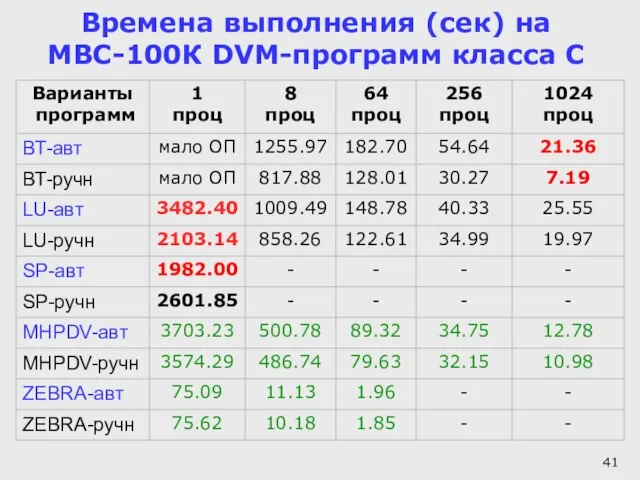
Слайд 41Времена выполнения (сек) на МВС-100К DVM-программ класса С
Времена выполнения (сек) на МВС-100К DVM-программ класса С
Слайд 42План изложения
Модели и языки программирования с явным параллелизмом (абстрактная и целевая машина,
План изложения
Модели и языки программирования с явным параллелизмом (абстрактная и целевая машина,

Слайд 43Автоматизированное распараллеливание последовательных программ
Диалог с пользователем для:
Исследования результатов анализа и задания характеристик
Автоматизированное распараллеливание последовательных программ
Диалог с пользователем для:
Исследования результатов анализа и задания характеристик

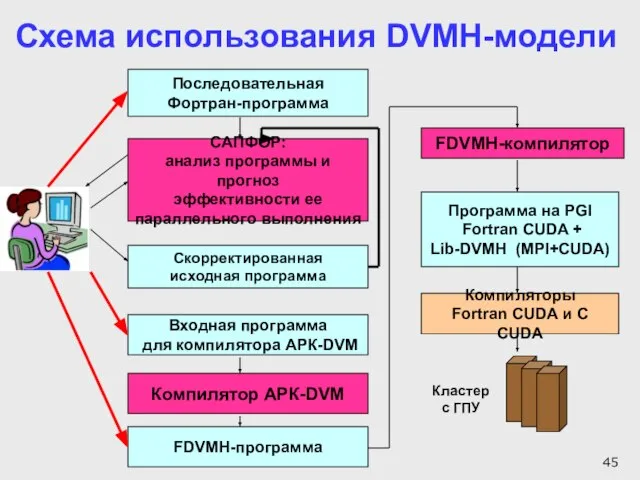
Слайд 45САПФОР:
анализ программы и прогноз
эффективности ее
параллельного выполнения
Скорректированная
исходная программа
FDVMH-компилятор
FDVMH-программа
Программа на PGI
Fortran CUDA
САПФОР:
анализ программы и прогноз
эффективности ее
параллельного выполнения
Скорректированная
исходная программа
FDVMH-компилятор
FDVMH-программа
Программа на PGI
Fortran CUDA
Слайд 46Принципиальные решения
DVM-подход:
Программист принимает основные решения по распараллеливанию, а компилятор и система поддержки
Принципиальные решения
DVM-подход:
Программист принимает основные решения по распараллеливанию, а компилятор и система поддержки

Слайд 47План изложения
Модели и языки программирования с явным параллелизмом
Языки программирования с неявным
План изложения
Модели и языки программирования с явным параллелизмом
Языки программирования с неявным

Слайд 48Автоматизация функциональной отладки параллельных программ
Автоматизированное сравнение поведения и промежуточных результатов разных версий
Автоматизация функциональной отладки параллельных программ
Автоматизированное сравнение поведения и промежуточных результатов разных версий

Слайд 49Функциональная отладка DVM-программ
Используется следующая методика поэтапной отладки программ:
На первом этапе программа
Функциональная отладка DVM-программ
Используется следующая методика поэтапной отладки программ:
На первом этапе программа

Слайд 50Типы ошибок
Синтаксические ошибки в DVM-указаниях и нарушение статической семантики
Неправильная последовательность выполнения
Типы ошибок
Синтаксические ошибки в DVM-указаниях и нарушение статической семантики
Неправильная последовательность выполнения

Слайд 51Динамический контроль
Чтение неинициализированных переменных
Выход за пределы массива
Необъявленная зависимость по данным в параллельной
Динамический контроль
Чтение неинициализированных переменных
Выход за пределы массива
Необъявленная зависимость по данным в параллельной

Слайд 52Сравнение результатов
Где и что сравнивать
Две трассы, одна трасса, без трасс – на
Сравнение результатов
Где и что сравнивать
Две трассы, одна трасса, без трасс – на

Слайд 53Автоматизация отладки эффективности параллельных программ
Прогноз характеристик эффективности каждого варианта распараллеливания для разных
Автоматизация отладки эффективности параллельных программ
Прогноз характеристик эффективности каждого варианта распараллеливания для разных

Слайд 54Эффективность выполнения параллельной программы
Эффективность выполнения параллельной программы выражается в ускорении вычислений, что
Эффективность выполнения параллельной программы
Эффективность выполнения параллельной программы выражается в ускорении вычислений, что

Слайд 55Критерии эффективности выполнения параллельных программ
Ускорение Sn = T1 / Tn,
где Tn
Критерии эффективности выполнения параллельных программ
Ускорение Sn = T1 / Tn, где Tn

Слайд 56Критерии эффективности выполнения параллельных программ
Если ускорение линейно от n, то говорят, что
Критерии эффективности выполнения параллельных программ
Если ускорение линейно от n, то говорят, что

Слайд 57Факторы, определяющие эффективность выполнения параллельных программ
степень распараллеливания программы - доля параллельных вычислений
Факторы, определяющие эффективность выполнения параллельных программ
степень распараллеливания программы - доля параллельных вычислений

Слайд 58Характеристики эффективности
параллельных программ
Пользователь может получить следующие характеристики эффективности программы и отдельных
Характеристики эффективности
параллельных программ
Пользователь может получить следующие характеристики эффективности программы и отдельных

Слайд 59Характеристики эффективности параллельных программ
Компоненты lost time:
insufficient parallelism - потери из-за выполнения
Характеристики эффективности параллельных программ
Компоненты lost time:
insufficient parallelism - потери из-за выполнения

Слайд 60Характеристики эффективности параллельных программ
Кроме того, выдаются характеристики:
load imbalance - возможные потери
Характеристики эффективности параллельных программ
Кроме того, выдаются характеристики:
load imbalance - возможные потери

Слайд 61Подходы к вычислению и выдаче характеристик
Как собирать
трассировка (для каждого процессора, каждой
Подходы к вычислению и выдаче характеристик
Как собирать
трассировка (для каждого процессора, каждой

Слайд 62Проблема – нестабильность характеристик
Нестабильность коммуникаций
Изменение состава процессоров при неоднородности коммуникационной среды
Загрузка коммуникационной
Проблема – нестабильность характеристик
Нестабильность коммуникаций
Изменение состава процессоров при неоднородности коммуникационной среды
Загрузка коммуникационной

Слайд 63Нестабильность производительности процессоров
Попадание на медленные процессоры (появляется разбалансировка, можно запрашивать лишние процессоры
Нестабильность производительности процессоров
Попадание на медленные процессоры (появляется разбалансировка, можно запрашивать лишние процессоры

Слайд 64Предсказатель эффективности DVM-программ
получает характеристики выполнения DVM-программы на рабочей станции
и использует их
Предсказатель эффективности DVM-программ
получает характеристики выполнения DVM-программы на рабочей станции и использует их

Слайд 65Принципиальные трудности предсказания эффективности
Для современных процессоров трудно прогнозировать время выполнения разных
Принципиальные трудности предсказания эффективности
Для современных процессоров трудно прогнозировать время выполнения разных

Слайд 66Предсказатель – инструмент отладки эффективности
Он может довольно точно оценить влияние основных факторов:
Предсказатель – инструмент отладки эффективности
Он может довольно точно оценить влияние основных факторов:

Слайд 67Предсказатель – инструмент отладки эффективности
На современных процессорах эффективность вычислений может отличаться в
Предсказатель – инструмент отладки эффективности
На современных процессорах эффективность вычислений может отличаться в

Слайд 68Выводы
Отладка эффективности параллельных программ – процесс очень сложный и трудоемкий
Развитые средства
Выводы
Отладка эффективности параллельных программ – процесс очень сложный и трудоемкий
Развитые средства

Слайд 69Вопросы, замечания?
СПАСИБО !
Вопросы, замечания?
СПАСИБО !

 Мультвикторина
Мультвикторина Ход лабораторной работы
Ход лабораторной работы САПР Система автоматизированного проектирования
САПР Система автоматизированного проектирования  Как стать лидером
Как стать лидером Презентация на тему Педагогическая стратегия развития одарённости
Презентация на тему Педагогическая стратегия развития одарённости Введение в демонологию
Введение в демонологию Э-01-текст. Практическая работа №1
Э-01-текст. Практическая работа №1 Презентация на тему Князья Киевской Руси
Презентация на тему Князья Киевской Руси Столбчатые диаграммыКомфортность школьной среды
Столбчатые диаграммыКомфортность школьной среды Текстовые задачи на проценты в заданиях ЕГЭ по математике
Текстовые задачи на проценты в заданиях ЕГЭ по математике ЧУВАШСТАТ
ЧУВАШСТАТ Цирк. Цирковые артисты
Цирк. Цирковые артисты Умножение трёхзначных чисел в столбик (3 класс)
Умножение трёхзначных чисел в столбик (3 класс) Истори школ Красночетайского района
Истори школ Красночетайского района Матч Украина-Латвия. Механизмы игры в футбол
Матч Украина-Латвия. Механизмы игры в футбол Анализ технического состояния привода роликов отводящего рольганга электросталеплавильного цеха ПАО ММК
Анализ технического состояния привода роликов отводящего рольганга электросталеплавильного цеха ПАО ММК Чума, оспа
Чума, оспа ACADEMY OF SCIENCE OF TURKMENISTAN
ACADEMY OF SCIENCE OF TURKMENISTAN Оперативное акушерство
Оперативное акушерство  Антарктида. Безмолвный, пустынный, загадочный, белый, материк
Антарктида. Безмолвный, пустынный, загадочный, белый, материк Презентация на тему Объемы геометрических тел
Презентация на тему Объемы геометрических тел АНАЛИТИЧЕСКАЯ СИСТЕМА УПРАВЛЕНИЯ БАНКОВСКИМИ РИСКАМИ (СУБР)
АНАЛИТИЧЕСКАЯ СИСТЕМА УПРАВЛЕНИЯ БАНКОВСКИМИ РИСКАМИ (СУБР) Склонение имен существительных
Склонение имен существительных Семинар-практикум «Методика расчета заработной платы всех категорий работников общеобразовательных учреждений в условиях оклад
Семинар-практикум «Методика расчета заработной платы всех категорий работников общеобразовательных учреждений в условиях оклад ЗАО «Метростандарт»
ЗАО «Метростандарт» Чайная посуда. 紫砂茶具带紫砂茶盘
Чайная посуда. 紫砂茶具带紫砂茶盘 Кижи
Кижи Бизнес-планирование. Оценка рисков в бизнес-проекте
Бизнес-планирование. Оценка рисков в бизнес-проекте