- Динамические частотные характеристики слов для описания разнородных лингвистических объектов

Содержание
- 2. Два определения для метода, базирующегося на сопоставлении частотных характеристик: Глобальная частота встречаемости – абсолютная частота встречаемости
- 3. В теории информационного поиска признано ранжирование весов слов по классическому критерию Солтона TF IDF [1], где
- 4. В [3] исследовалась зависимость особенности соотношения локальной и глобальной популярности сообщений электронных СМИ. При этом было
- 5. Предлагаемый подход позволяет анализировать структуры самых разных текстовых объектов: от единичного текста до политематической коллекции текстов.
- 6. Исследовалась зависимость локальной частоты встречаемости слов от глобальной с тремя значениями окна анализа (K=100, K=500 и
- 7. Цель исследовала состояла в том, чтобы на основании сопоставления частот встречаемости слов выделить основные единицы анализа
- 8. Семантической структурой называем структуру, характеризующую прежде всего стилевые характеристики. Информационной структурой – структуру, характеризующую тематику, предметную
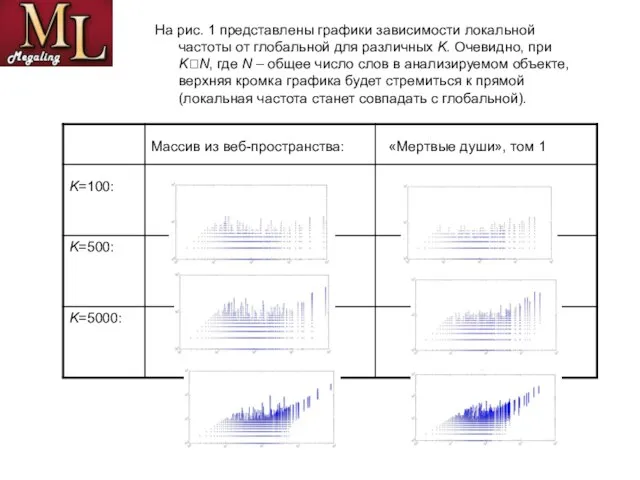
- 9. На рис. 1 представлены графики зависимости локальной частоты от глобальной для различных K. Очевидно, при K?N,
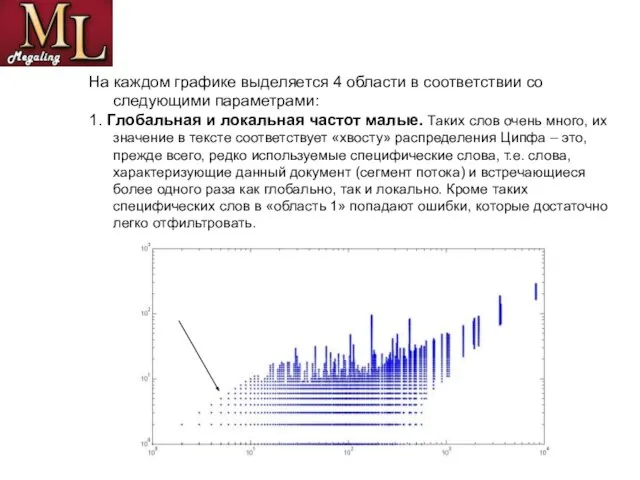
- 10. На каждом графике выделяется 4 области в соответствии со следующими параметрами: 1. Глобальная и локальная частот
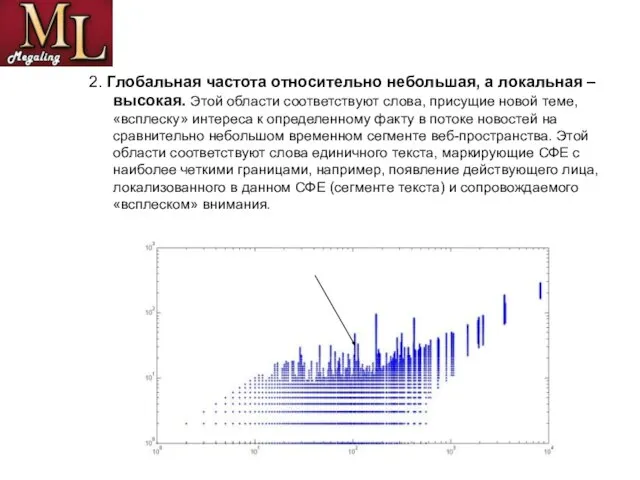
- 11. 2. Глобальная частота относительно небольшая, а локальная – высокая. Этой области соответствуют слова, присущие новой теме,
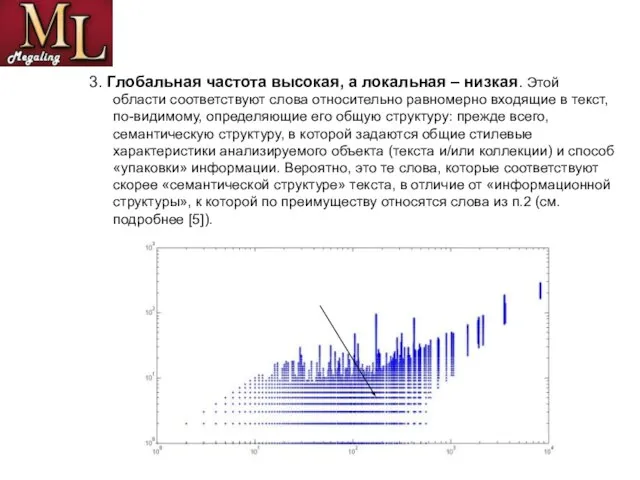
- 12. 3. Глобальная частота высокая, а локальная – низкая. Этой области соответствуют слова относительно равномерно входящие в
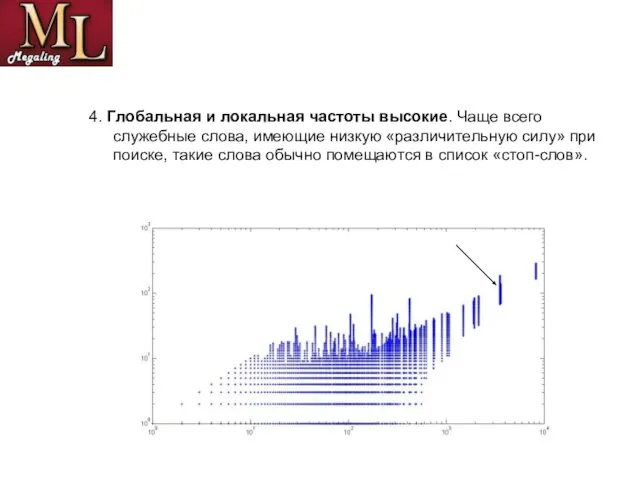
- 13. 4. Глобальная и локальная частоты высокие. Чаще всего служебные слова, имеющие низкую «различительную силу» при поиске,
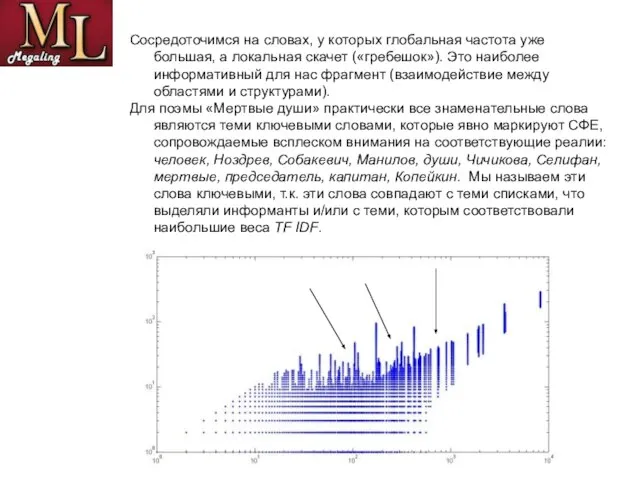
- 14. Сосредоточимся на словах, у которых глобальная частота уже большая, а локальная скачет («гребешок»). Это наиболее информативный
- 15. На материале новостной коллекции слова – ключевые – ведут себя еще более явным образом, их доля
- 16. Можно ли назвать сегменты новостного потока, выделенные благодаря локальным всплескам, аналогами СФЕ? Да, безусловно. Каждый из
- 17. В заключение подчеркнем, что современная лингвистика ориентирована на разнообразие лингвистических объектов: от традиционного объекта, эквивалентного единичному
- 19. Скачать презентацию
Слайд 2Два определения для метода, базирующегося на сопоставлении частотных характеристик:
Глобальная частота встречаемости –
Глобальная частота встречаемости –

Слайд 3В теории информационного поиска признано ранжирование весов слов по классическому критерию Солтона

Слайд 4 В [3] исследовалась зависимость особенности соотношения локальной и глобальной популярности сообщений
В [3] исследовалась зависимость особенности соотношения локальной и глобальной популярности сообщений
![В [3] исследовалась зависимость особенности соотношения локальной и глобальной популярности сообщений электронных](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/465878/slide-3.jpg)
Слайд 5 Предлагаемый подход позволяет анализировать структуры самых разных текстовых объектов: от единичного
Предлагаемый подход позволяет анализировать структуры самых разных текстовых объектов: от единичного

Слайд 6Исследовалась зависимость локальной частоты встречаемости слов от глобальной с тремя значениями окна
Исследовалась зависимость локальной частоты встречаемости слов от глобальной с тремя значениями окна

Слайд 7Цель исследовала состояла в том, чтобы на основании сопоставления частот встречаемости слов
Цель исследовала состояла в том, чтобы на основании сопоставления частот встречаемости слов

Слайд 8Семантической структурой называем структуру, характеризующую прежде всего стилевые характеристики.
Информационной структурой –
Семантической структурой называем структуру, характеризующую прежде всего стилевые характеристики.
Информационной структурой –

Слайд 9На рис. 1 представлены графики зависимости локальной частоты от глобальной для различных
На рис. 1 представлены графики зависимости локальной частоты от глобальной для различных
Слайд 10На каждом графике выделяется 4 области в соответствии со следующими параметрами:
1. Глобальная
На каждом графике выделяется 4 области в соответствии со следующими параметрами:
1. Глобальная
Слайд 112. Глобальная частота относительно небольшая, а локальная – высокая. Этой области соответствуют
2. Глобальная частота относительно небольшая, а локальная – высокая. Этой области соответствуют
Слайд 123. Глобальная частота высокая, а локальная – низкая. Этой области соответствуют слова
3. Глобальная частота высокая, а локальная – низкая. Этой области соответствуют слова
Слайд 134. Глобальная и локальная частоты высокие. Чаще всего служебные слова, имеющие низкую
4. Глобальная и локальная частоты высокие. Чаще всего служебные слова, имеющие низкую
Слайд 14Сосредоточимся на словах, у которых глобальная частота уже большая, а локальная скачет
Сосредоточимся на словах, у которых глобальная частота уже большая, а локальная скачет
Слайд 15На материале новостной коллекции слова – ключевые – ведут себя еще более
На материале новостной коллекции слова – ключевые – ведут себя еще более

Слайд 16Можно ли назвать сегменты новостного потока, выделенные благодаря локальным всплескам, аналогами СФЕ?
Можно ли назвать сегменты новостного потока, выделенные благодаря локальным всплескам, аналогами СФЕ?

Слайд 17В заключение подчеркнем, что современная лингвистика ориентирована на разнообразие лингвистических объектов: от
В заключение подчеркнем, что современная лингвистика ориентирована на разнообразие лингвистических объектов: от

 Кемеровская Региональная Общественная Организация
Кемеровская Региональная Общественная Организация Ароматы для средств по уходу за волосами
Ароматы для средств по уходу за волосами Вебинар для Руководителей Центров Avon
Вебинар для Руководителей Центров Avon Сон наяву или приключения в стране чудес
Сон наяву или приключения в стране чудес Цифровое телевидение
Цифровое телевидение Levels Up Club— это: Прогнозирование финансовых рынков, разработка алгоритмов торговых роботов
Levels Up Club— это: Прогнозирование финансовых рынков, разработка алгоритмов торговых роботов Черты сходства человека и человекообразных обезьян
Черты сходства человека и человекообразных обезьян Повышение профессиональной компетентности педагогов по вопросам развития речи дошкольников
Повышение профессиональной компетентности педагогов по вопросам развития речи дошкольников Презентация классного коллектива
Презентация классного коллектива Феномен Лапенко
Феномен Лапенко Энергосберегающие технологии транспорта газа
Энергосберегающие технологии транспорта газа Приказ Министерства образования и науки РФ № 209 от 24 марта 2010 г.
Приказ Министерства образования и науки РФ № 209 от 24 марта 2010 г. Формы взаимодействия адвоката и следователя на предварительном следствии. Содействие и противодействие
Формы взаимодействия адвоката и следователя на предварительном следствии. Содействие и противодействие Поклонюсь Тебя, я, о Боже Нету в целом мире дороже Воспою Тебе хвалу Бог мой я тебя ищу
Поклонюсь Тебя, я, о Боже Нету в целом мире дороже Воспою Тебе хвалу Бог мой я тебя ищу РОДИТЕЛЯМ О ПРАВИЛАХ ДОРОЖНОГО ДВИЖЕНИЯ.. Причиной дорожно- транспортных происшествий чаще всего являются сами дети. Приводит к эт
РОДИТЕЛЯМ О ПРАВИЛАХ ДОРОЖНОГО ДВИЖЕНИЯ.. Причиной дорожно- транспортных происшествий чаще всего являются сами дети. Приводит к эт Конкурс чтецов 1-4 классов в Выльгортской Школе №1
Конкурс чтецов 1-4 классов в Выльгортской Школе №1 Дроби
Дроби Презентация по английскому Areas of London Районы Лондона
Презентация по английскому Areas of London Районы Лондона Забастовка. Право на забастовку
Забастовка. Право на забастовку ТИПЫ КОСТРОВ
ТИПЫ КОСТРОВ Продление срока срока службы эпоксидных композитов
Продление срока срока службы эпоксидных композитов Юлианский Календарь.
Юлианский Календарь. Baroko aktualumas šiais laikais
Baroko aktualumas šiais laikais Презентация на тему Противоположные числа (6 класс)
Презентация на тему Противоположные числа (6 класс) Завтрак чемпиона
Завтрак чемпиона Филиппо Брунеллески
Филиппо Брунеллески Презентация1
Презентация1 Сравнительная таблица по уплате единого социального налога (ЕСН) и страховых взносов на обязательное социальное страхование на с
Сравнительная таблица по уплате единого социального налога (ЕСН) и страховых взносов на обязательное социальное страхование на с