- Извлечение метаинформации и библиографических ссылок из текстов русскоязычных научных статей

Содержание
- 2. Постановка задачи Задача: в автоматическом режиме из текста статьи, представленного в виде PDF-файла, извлечь метаданные и
- 3. Рассматриваемая задача актуальна для построения графа взаимного цитирования. Автоматическое построение графа взаимного цитирования состоит из двух
- 4. Особенности задачи Авторы не снабжают тексты статей метаинформацией в удобной для автоматического разбора форме => требуется
- 5. Особенности задачи (2) Извлечение библиографических ссылок Самусев С. Шамина О. ВМиК МГУ {sam,sincere}@lvk.cs.msu.su Аннотация В данной
- 6. Существующие подходы Методы, применявшиеся для англоязычных статей Методы, основанные на правилах: Метод, основанный на регулярных выражениях
- 7. Цель работы Цель работы: исследование применимости существующих методов, разработанных для англоязычных статей, для извлечения метаинформации и
- 8. Этапы решения задачи Этап 1: преобразование текста статьи в формате PDF в промежуточное текстовое представление с
- 9. Метод, основанный на регулярных выражениях Из промежуточного представления текста статьи извлекается первая страница или текст до
- 10. Методы машинного обучения: предобработка Упрощенный вариант метода Rule-Based Word Clustering (Giles, 2005): Слова в тексте статьи
- 11. Методы машинного обучения: предобработка (2) Использование интеллектуальных сетевых роботов для построения тематических коллекций Романова E.В., Некрестьянов
- 12. Методы машинного обучения: метод, основанный на СММ Состояния соответствуют элементам метаинформации. Наблюдаемая цепочка – последовательность признаков
- 13. Методы машинного обучения: метод , основанный на классификации Задача извлечения метаинформации рассматривается как задача классификации строк
- 14. Методы машинного обучения: метод, основанный на классификации (2) Осуществляется второй шаг классификации - контекстно-зависимая классификация: Строка
- 15. Методы машинного обучения: метод, основанный на классификации (3) 95% строк принадлежат к одному классу, остальные –
- 16. Экспериментальное исследование Цель: сравнение точности методов. Наборы данных: - англоязычный (McCallum, 935 заголовков, 500 библиографических ссылок).
- 17. Экспериментальное исследование
- 18. Выводы Экспериментальное исследование показало, что все три метода обеспечивают точность порядка 70-80%, что является пригодным для
- 19. Планы дальнейшего развития Повышение точности рассмотренных методов машинного обучения за счет учета разметки. Использование условных случайных
- 21. Скачать презентацию
Слайд 2Постановка задачи
Задача: в автоматическом режиме из текста статьи, представленного в виде PDF-файла,
Постановка задачи
Задача: в автоматическом режиме из текста статьи, представленного в виде PDF-файла,

Слайд 3 Рассматриваемая задача актуальна для построения графа взаимного цитирования.
Автоматическое построение графа взаимного цитирования
Рассматриваемая задача актуальна для построения графа взаимного цитирования.
Автоматическое построение графа взаимного цитирования

Слайд 4Особенности задачи
Авторы не снабжают тексты статей метаинформацией в удобной для автоматического разбора
Особенности задачи
Авторы не снабжают тексты статей метаинформацией в удобной для автоматического разбора

Слайд 5Особенности задачи (2)
Извлечение библиографических ссылок
Самусев С. Шамина О.
ВМиК МГУ {sam,sincere}@lvk.cs.msu.su
Аннотация
В
Особенности задачи (2)
Извлечение библиографических ссылок
Самусев С. Шамина О.
ВМиК МГУ {sam,sincere}@lvk.cs.msu.su
Аннотация
В

Слайд 6Существующие подходы
Методы, применявшиеся для англоязычных статей
Методы, основанные на правилах:
Метод, основанный на регулярных
Существующие подходы
Методы, применявшиеся для англоязычных статей
Методы, основанные на правилах:
Метод, основанный на регулярных

Слайд 7Цель работы
Цель работы:
исследование применимости существующих методов, разработанных для англоязычных статей, для извлечения
Цель работы
Цель работы:
исследование применимости существующих методов, разработанных для англоязычных статей, для извлечения

Слайд 8Этапы решения задачи
Этап 1: преобразование текста статьи в формате PDF в промежуточное
Этапы решения задачи
Этап 1: преобразование текста статьи в формате PDF в промежуточное

Слайд 9Метод, основанный на регулярных выражениях
Из промежуточного представления текста статьи извлекается первая страница
Метод, основанный на регулярных выражениях
Из промежуточного представления текста статьи извлекается первая страница

Слайд 10Методы машинного обучения: предобработка
Упрощенный вариант метода Rule-Based Word Clustering (Giles, 2005):
Слова в
Методы машинного обучения: предобработка
Упрощенный вариант метода Rule-Based Word Clustering (Giles, 2005):
Слова в

Слайд 11Методы машинного обучения: предобработка (2)
Использование интеллектуальных сетевых роботов для построения тематических коллекций
Методы машинного обучения: предобработка (2)
Использование интеллектуальных сетевых роботов для построения тематических коллекций

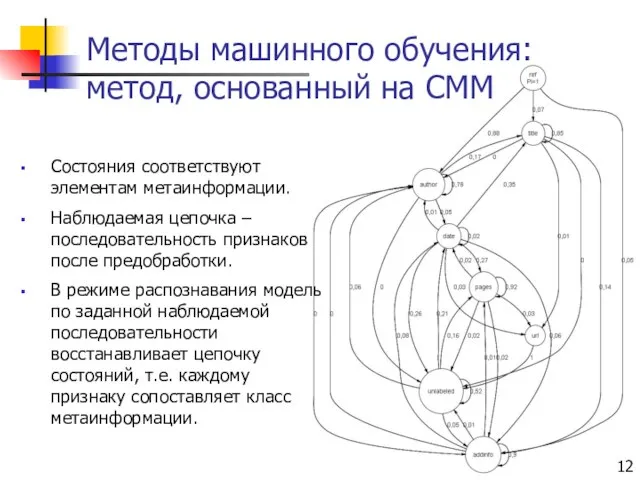
Слайд 12Методы машинного обучения: метод, основанный на СММ
Состояния соответствуют элементам метаинформации.
Наблюдаемая цепочка –
Методы машинного обучения: метод, основанный на СММ
Состояния соответствуют элементам метаинформации.
Наблюдаемая цепочка –
Слайд 13Методы машинного обучения:
метод , основанный на классификации
Задача извлечения метаинформации рассматривается как
Методы машинного обучения:
метод , основанный на классификации
Задача извлечения метаинформации рассматривается как

Слайд 14Методы машинного обучения:
метод, основанный на классификации (2)
Осуществляется второй шаг классификации -
Методы машинного обучения:
метод, основанный на классификации (2)
Осуществляется второй шаг классификации -

Слайд 15Методы машинного обучения:
метод, основанный на классификации (3)
95% строк принадлежат к одному
Методы машинного обучения:
метод, основанный на классификации (3)
95% строк принадлежат к одному

Слайд 16Экспериментальное исследование
Цель: сравнение точности методов.
Наборы данных:
- англоязычный (McCallum, 935 заголовков, 500
Экспериментальное исследование
Цель: сравнение точности методов.
Наборы данных:
- англоязычный (McCallum, 935 заголовков, 500

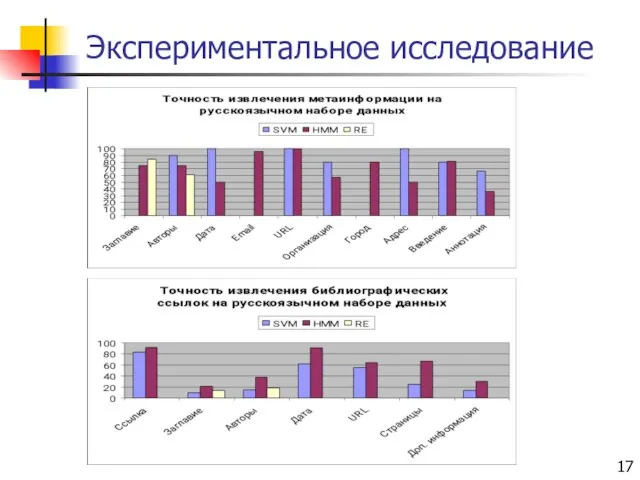
Слайд 17Экспериментальное исследование
Экспериментальное исследование
Слайд 18Выводы
Экспериментальное исследование показало, что все три метода обеспечивают точность порядка 70-80%, что
Выводы
Экспериментальное исследование показало, что все три метода обеспечивают точность порядка 70-80%, что

Слайд 19Планы дальнейшего развития
Повышение точности рассмотренных методов машинного обучения за счет учета разметки.
Использование
Планы дальнейшего развития
Повышение точности рассмотренных методов машинного обучения за счет учета разметки.
Использование

 ПРОЕКТ : Модифицирование стали Гадфильда (110Г13) при производстве крупных отливок (стрелочные переводы, зубья и передние стенки ков
ПРОЕКТ : Модифицирование стали Гадфильда (110Г13) при производстве крупных отливок (стрелочные переводы, зубья и передние стенки ков Разумная и обоснованная стоимость ремонта – страхование КАСКО морских судов.
Разумная и обоснованная стоимость ремонта – страхование КАСКО морских судов. Методологический аппарат исследования
Методологический аппарат исследования Презентация на тему Безопасность детей в интернете
Презентация на тему Безопасность детей в интернете Bazovye_ponyatia_informatiki
Bazovye_ponyatia_informatiki Исследование статической устойчивости асинхронной нагрузки при питании их от шин бесконечной мощности
Исследование статической устойчивости асинхронной нагрузки при питании их от шин бесконечной мощности Учебные курсы Microsoft для средней школы
Учебные курсы Microsoft для средней школы Здоровьесберегающие технологии на уроках русского языка
Здоровьесберегающие технологии на уроках русского языка Власть. Типы (системы) политического господства
Власть. Типы (системы) политического господства Prezentatsia1
Prezentatsia1 Как Достичь Успеха Когда ты уже Успешен или Был УспешнымСессия №4
Как Достичь Успеха Когда ты уже Успешен или Был УспешнымСессия №4 Москва 4 июня 2008 г.
Москва 4 июня 2008 г. Особенности крупного бизнеса
Особенности крупного бизнеса Boeing Business Jet
Boeing Business Jet 0006d06c-2b7ab0fb
0006d06c-2b7ab0fb Роль рекламы в обществе
Роль рекламы в обществе Буквица
Буквица Ищем достойного хозяина!
Ищем достойного хозяина! Мужская половая система
Мужская половая система контент-план
контент-план Реализация Закона Краснодарского края № 1539 от 21 июля 2008 года «О мерах по профилактике безнадзорности и правонарушений среди несо
Реализация Закона Краснодарского края № 1539 от 21 июля 2008 года «О мерах по профилактике безнадзорности и правонарушений среди несо Календарно-тематическое планирование
Календарно-тематическое планирование Гражданин РФ
Гражданин РФ Производство магния
Производство магния Формулы квадрата суммы и квадрата разности двух выражений
Формулы квадрата суммы и квадрата разности двух выражений право
право Автоматизация звука Р в словах
Автоматизация звука Р в словах Networking в стиле Бутерброд
Networking в стиле Бутерброд