- Кластеризация документов

Содержание
- 2. Введение Кластеризация документов – это процесс обнаружения естественных групп в коллекции документов. Кластеризацию может служить как
- 3. Содержание Оценка качества кластеризации Применение векторной модели в кластеризации Иерархическая кластеризация «Разделяющая» кластеризация Генеративные алгоритмы Спектральная
- 4. Оценка качества кластеризации Не существует единого (общепризнанного, применимого во всех случаях) метода оценки Оценка предполагает, что
- 5. Матрица несоответствий - способ примитивный, зато наглядный
- 6. Метрики заимствованные из информационного поиска Полнота (recall): R = tp / (tp+fn) Точность (presicion): P =
- 7. Применительно к кластеризации i – классы, j – кластеры, n – общее число документов, ni –
- 8. Чистота i – классы, j – кластеры, n – общее число документов, nj – число документов
- 9. Энтропия i – классы, j – кластеры, n – общее число документов, nj – число документов
- 10. Взаимная информация Чистота и энтропия хороши тогда, когда число классов и кластеров совпадает. В других случаях
- 11. Стабильность С помощью взаимной информации можно считать стабильность, т.е. степень пересечения кластеризации при разных прогонах одного
- 12. Содержание Оценка качества кластеризации Применение векторной модели в кластеризации Иерархическая кластеризация «Разделяющая» кластеризация Генеративные алгоритмы Спектральная
- 13. Векторная модель Коллекция из n документов и m различных терминов представляется в виде матрицы mxn, где
- 14. Предобработка Фильтрация (удаление спецсимволов и пунктуации) Токенизация (разбиваем текст на термины – слова или словосочетания) Стемминг
- 15. Содержание Оценка качества кластеризации Применение векторной модели в кластеризации Иерархическая кластеризация «Разделяющая» кластеризация Генеративные алгоритмы Спектральная
- 16. Иерархическая кластеризация На начальной стадии каждый документ – сам себе кластер. На каждом шаге документы объединяются
- 17. Содержание Оценка качества кластеризации Применение векторной модели в кластеризации Иерархическая кластеризация «Разделяющая» кластеризация Генеративные алгоритмы Спектральная
- 18. «Разделяющая» кластеризация Классический пример - kmeans: Выбирается k случайных документов, которые считаются центроидами кластеров, все остальные
- 19. Недостатки kmeans Результаты могут быть различными в зависимости от инициализации. Может останавливаться на субоптимальном локальном минимуме
- 20. Содержание Оценка качества кластеризации Применение векторной модели в кластеризации Иерархическая кластеризация «Разделяющая» кластеризация Генеративные алгоритмы Спектральная
- 21. Генеративные алгоритмы Дискриминативные алгоритмы, которые основаны на попарной близости документов, имеют сложность O(n2) по определению. Генеративные
- 22. Гауссова модель Предполагается, что распределение документов в векторном пространстве – это набор Гауссовых распределений; каждый кластер
- 23. Гауссова модель Вероятность того, что документ d принадлежит кластеру θ из набора Θ: P(d| θ) -
- 24. Expectation maximization (EM-алгоритм) Итеративная процедура для нахождения максимального правдоподобия параметров модели. Две стадии: E(xpectation) – вывод
- 25. EM-алгоритм Большое число свободных параметров может приводить к переобучению. Сокращение размерности: выбор дискриминирующих свойств для каждого
- 26. Модель фон Мисес-Фишера На самом деле, распределение текстов по кластерам гауссианами описывается плохо. Было доказано, что
- 27. Содержание Оценка качества кластеризации Применение векторной модели в кластеризации Иерархическая кластеризация «Разделяющая» кластеризация Генеративные алгоритмы Спектральная
- 28. Спектральная кластеризация Основная гипотеза: термины, которые часто встречаются вместе, описывают близкие понятия. Поэтому важна группировка не
- 29. Алгоритм divide & merge Нахождение оптимального разбиения в графе – NP-полная задача (на практике означает, что
- 30. Алгоритм divide & merge
- 31. Нечеткая совместная корреляция Кластеризуются сразу и термины, и документы Границы между кластерами нечеткие - термин или
- 32. Содержание Оценка качества кластеризации Применение векторной модели в кластеризации Иерархическая кластеризация «Разделяющая» кластеризация Генеративные алгоритмы Спектральная
- 33. Снижение размерности Матрица термин документ А аппроксимируется матрицей меньшего ранга k Ak. Принятая мера качества такой
- 34. Метод главных компонентов (PCA) Главные компоненты – ортогональные (независимые) проекции, которые вместе описывают максимальное разнообразие в
- 35. Метод главных компонентов + В результате получается оптимальная аппроксимация + Различие в расстояниях внутри кластеров и
- 36. Неотрицательная факторизация (NMF) Цель: получить аппроксимацию, которая содержит только дискриминирующие факторы Исходная матрица аппроксимируется произведением: A
- 37. Мягкая спектральная кластеризация Из редуцированного пространства трудно породить нечеткую кластеризацию, потому что усечение матрицы приводит к
- 38. Мягкая спектральная кластеризация Пространство редуцируется методом главных компонентов Проводится кластеризация методом kmeans (или другим) Для этих
- 39. Lingo “description comes first” Сокращается размерность пространства Базисные вектора полученной редуцированной матрицы воспринимаются как метки кластеров
- 40. Содержание Оценка качества кластеризации Применение векторной модели в кластеризации Иерархическая кластеризация «Разделяющая» кластеризация Генеративные алгоритмы Спектральная
- 41. Модели с учетом порядка слов Маша любит Васю, Вася любит Машу – векторная модель не учитывает
- 42. Кластеризация на основе суффиксных деревьев Суффикс – несколько слов с конца предложения (вплоть до предложения целиком)
- 43. Кластеризация на основе суффиксных деревьев Кластеры включают не все документы (документ может иметь суффикс, которые не
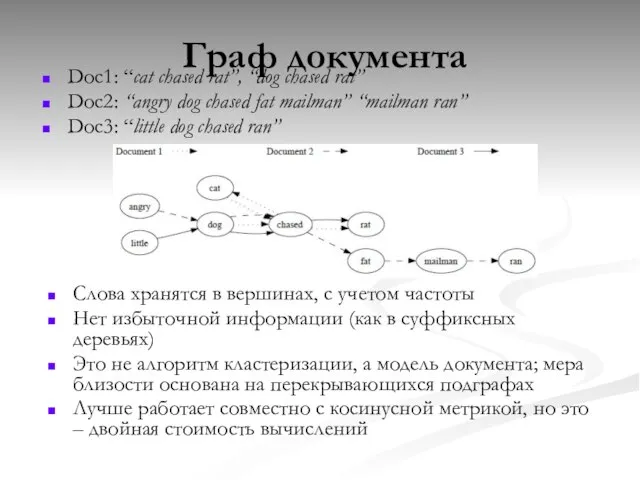
- 44. Граф документа Doc1: “cat chased rat”, “dog chased rat” Doc2: “angry dog chased fat mailman” “mailman
- 45. Заключение Качество кластеризации определяется по стандартным мерам, при этом итоговая кластеризация не всегда выглядит «естественно» Проблема
- 47. Скачать презентацию
Слайд 2Введение
Кластеризация документов – это процесс обнаружения естественных групп в коллекции документов.
Кластеризацию может
Введение
Кластеризация документов – это процесс обнаружения естественных групп в коллекции документов.
Кластеризацию может

Слайд 3Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели
Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели

Слайд 4Оценка качества кластеризации
Не существует единого (общепризнанного, применимого во всех случаях) метода оценки
Оценка
Оценка качества кластеризации
Не существует единого (общепризнанного, применимого во всех случаях) метода оценки
Оценка

Слайд 5Матрица несоответствий
- способ примитивный, зато наглядный
Матрица несоответствий
- способ примитивный, зато наглядный

Слайд 6Метрики заимствованные из информационного поиска
Полнота (recall):
R = tp / (tp+fn)
Точность (presicion):
P =
Метрики заимствованные из информационного поиска
Полнота (recall):
R = tp / (tp+fn)
Точность (presicion):
P =

Слайд 7Применительно к кластеризации
i – классы, j – кластеры, n – общее
Применительно к кластеризации
i – классы, j – кластеры, n – общее

Слайд 8Чистота
i – классы, j – кластеры, n – общее число документов, nj
Чистота
i – классы, j – кластеры, n – общее число документов, nj

Слайд 9Энтропия
i – классы, j – кластеры, n – общее число документов, nj
Энтропия
i – классы, j – кластеры, n – общее число документов, nj

Слайд 10Взаимная информация
Чистота и энтропия хороши тогда, когда число классов и кластеров совпадает.
Взаимная информация
Чистота и энтропия хороши тогда, когда число классов и кластеров совпадает.

Слайд 11Стабильность
С помощью взаимной информации можно считать стабильность, т.е. степень пересечения кластеризации при
Стабильность
С помощью взаимной информации можно считать стабильность, т.е. степень пересечения кластеризации при

Слайд 12Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели
Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели

Слайд 13Векторная модель
Коллекция из n документов и m различных терминов представляется в виде
Векторная модель
Коллекция из n документов и m различных терминов представляется в виде

Слайд 14Предобработка
Фильтрация (удаление спецсимволов и пунктуации)
Токенизация (разбиваем текст на термины – слова
Предобработка
Фильтрация (удаление спецсимволов и пунктуации)
Токенизация (разбиваем текст на термины – слова
Слайд 15Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели
Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели

Слайд 16Иерархическая кластеризация
На начальной стадии каждый документ – сам себе кластер.
На каждом
Иерархическая кластеризация
На начальной стадии каждый документ – сам себе кластер.
На каждом

Слайд 17Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели
Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели

Слайд 18«Разделяющая» кластеризация
Классический пример - kmeans:
Выбирается k случайных документов, которые считаются центроидами кластеров,
«Разделяющая» кластеризация
Классический пример - kmeans:
Выбирается k случайных документов, которые считаются центроидами кластеров,

Слайд 19Недостатки kmeans
Результаты могут быть различными в зависимости от инициализации.
Может останавливаться на субоптимальном
Недостатки kmeans
Результаты могут быть различными в зависимости от инициализации.
Может останавливаться на субоптимальном

Слайд 20Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели
Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели

Слайд 21Генеративные алгоритмы
Дискриминативные алгоритмы, которые основаны на попарной близости документов, имеют сложность O(n2)
Генеративные алгоритмы
Дискриминативные алгоритмы, которые основаны на попарной близости документов, имеют сложность O(n2)

Слайд 22Гауссова модель
Предполагается, что распределение документов в векторном пространстве – это набор Гауссовых
Гауссова модель
Предполагается, что распределение документов в векторном пространстве – это набор Гауссовых

Слайд 23Гауссова модель
Вероятность того, что документ d принадлежит кластеру θ из набора Θ:
P(d|
Гауссова модель
Вероятность того, что документ d принадлежит кластеру θ из набора Θ:
P(d|

Слайд 24Expectation maximization
(EM-алгоритм)
Итеративная процедура для нахождения максимального правдоподобия параметров модели.
Две стадии:
E(xpectation)
Expectation maximization
(EM-алгоритм)
Итеративная процедура для нахождения максимального правдоподобия параметров модели.
Две стадии:
E(xpectation)

Слайд 25EM-алгоритм
Большое число свободных параметров может приводить к переобучению.
Сокращение размерности: выбор дискриминирующих
EM-алгоритм
Большое число свободных параметров может приводить к переобучению.
Сокращение размерности: выбор дискриминирующих

Слайд 26Модель фон Мисес-Фишера
На самом деле, распределение текстов по кластерам гауссианами описывается плохо.
Модель фон Мисес-Фишера
На самом деле, распределение текстов по кластерам гауссианами описывается плохо.

Слайд 27Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели
Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели

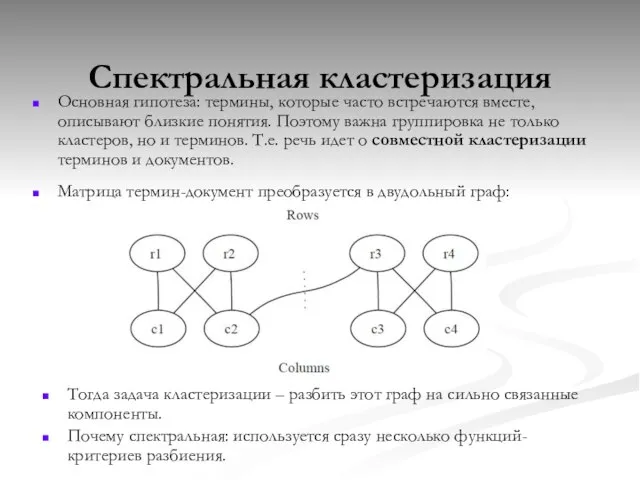
Слайд 28Спектральная кластеризация
Основная гипотеза: термины, которые часто встречаются вместе, описывают близкие понятия. Поэтому
Спектральная кластеризация
Основная гипотеза: термины, которые часто встречаются вместе, описывают близкие понятия. Поэтому
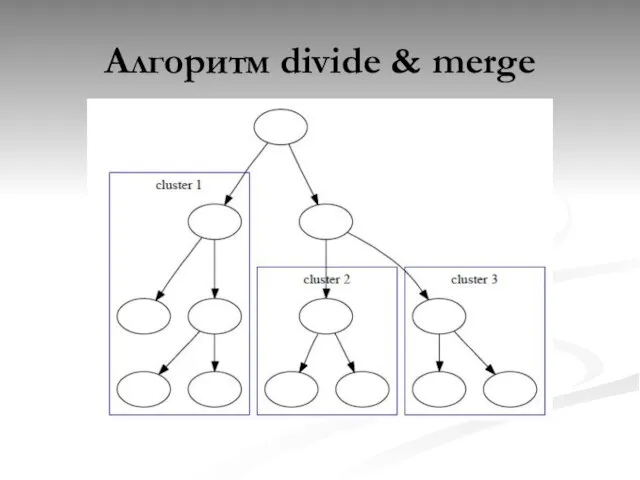
Слайд 29Алгоритм divide & merge
Нахождение оптимального разбиения в графе – NP-полная задача (на
Алгоритм divide & merge
Нахождение оптимального разбиения в графе – NP-полная задача (на

Слайд 30Алгоритм divide & merge
Алгоритм divide & merge
Слайд 31Нечеткая совместная корреляция
Кластеризуются сразу и термины, и документы
Границы между кластерами нечеткие -
Нечеткая совместная корреляция
Кластеризуются сразу и термины, и документы
Границы между кластерами нечеткие -

Слайд 32Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели
Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели

Слайд 33Снижение размерности
Матрица термин документ А аппроксимируется матрицей меньшего ранга k Ak.
Принятая
Снижение размерности
Матрица термин документ А аппроксимируется матрицей меньшего ранга k Ak.
Принятая

Слайд 34Метод главных компонентов (PCA)
Главные компоненты – ортогональные (независимые) проекции, которые вместе описывают
Метод главных компонентов (PCA)
Главные компоненты – ортогональные (независимые) проекции, которые вместе описывают

Слайд 35Метод главных компонентов
+ В результате получается оптимальная аппроксимация
+ Различие в расстояниях
Метод главных компонентов
+ В результате получается оптимальная аппроксимация
+ Различие в расстояниях

Слайд 36Неотрицательная факторизация (NMF)
Цель: получить аппроксимацию, которая содержит только дискриминирующие факторы
Исходная матрица аппроксимируется
Неотрицательная факторизация (NMF)
Цель: получить аппроксимацию, которая содержит только дискриминирующие факторы
Исходная матрица аппроксимируется

Слайд 37Мягкая спектральная кластеризация
Из редуцированного пространства трудно породить нечеткую кластеризацию, потому что усечение
Мягкая спектральная кластеризация
Из редуцированного пространства трудно породить нечеткую кластеризацию, потому что усечение

Слайд 38Мягкая спектральная кластеризация
Пространство редуцируется методом главных компонентов
Проводится кластеризация методом kmeans (или другим)
Для
Мягкая спектральная кластеризация
Пространство редуцируется методом главных компонентов
Проводится кластеризация методом kmeans (или другим)
Для

Слайд 39Lingo
“description comes first”
Сокращается размерность пространства
Базисные вектора полученной редуцированной матрицы воспринимаются как метки
Lingo
“description comes first”
Сокращается размерность пространства
Базисные вектора полученной редуцированной матрицы воспринимаются как метки

Слайд 40Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели
Содержание
Оценка качества кластеризации
Применение векторной модели в кластеризации
Иерархическая кластеризация
«Разделяющая» кластеризация
Генеративные алгоритмы
Спектральная кластеризация
Снижение размерности
Модели

Слайд 41Модели с учетом порядка слов
Маша любит Васю, Вася любит Машу – векторная
Модели с учетом порядка слов
Маша любит Васю, Вася любит Машу – векторная

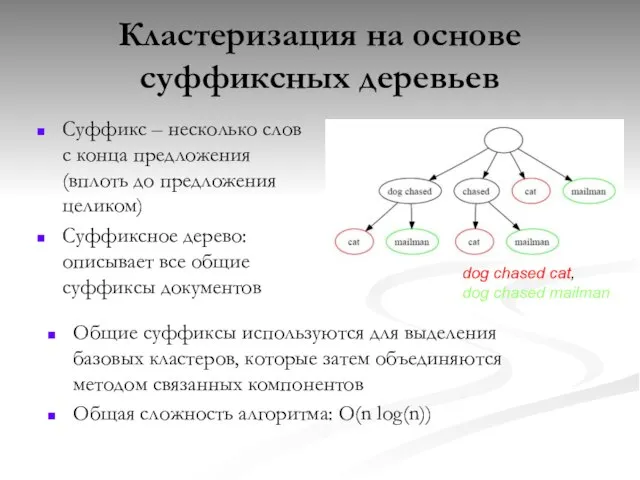
Слайд 42Кластеризация на основе суффиксных деревьев
Суффикс – несколько слов с конца предложения (вплоть
Кластеризация на основе суффиксных деревьев
Суффикс – несколько слов с конца предложения (вплоть
Слайд 43Кластеризация на основе суффиксных деревьев
Кластеры включают не все документы (документ может иметь
Кластеризация на основе суффиксных деревьев
Кластеры включают не все документы (документ может иметь

Слайд 44Граф документа
Doc1: “cat chased rat”, “dog chased rat”
Doc2: “angry dog chased fat
Граф документа
Doc1: “cat chased rat”, “dog chased rat”
Doc2: “angry dog chased fat
Слайд 45Заключение
Качество кластеризации определяется по стандартным мерам, при этом итоговая кластеризация не всегда
Заключение
Качество кластеризации определяется по стандартным мерам, при этом итоговая кластеризация не всегда

 Тестовые задания по окружающему миру
Тестовые задания по окружающему миру Презентация на тему Особенности изменения существительных на -ие, -ия, -ий
Презентация на тему Особенности изменения существительных на -ие, -ия, -ий  Операторы видеонаблюдения. Питеравто — холдинговая транспортная компания
Операторы видеонаблюдения. Питеравто — холдинговая транспортная компания Ваш личный имиджмейкер
Ваш личный имиджмейкер Какие бывают финансовые риски
Какие бывают финансовые риски Река Амазонка
Река Амазонка Почему до сих пор мы применяем в своей речи «крылатые» выражения древних греков? Объясни словосочетание.
Почему до сих пор мы применяем в своей речи «крылатые» выражения древних греков? Объясни словосочетание. Физическая культура
Физическая культура Презентация на тему Конструирование и моделирование плечевого изделия
Презентация на тему Конструирование и моделирование плечевого изделия  Тема урока: Признаки равенства треугольников.
Тема урока: Признаки равенства треугольников. Продукты Oxygen Assistance
Продукты Oxygen Assistance Планирование закупок
Планирование закупок Презентация на тему Склонение имен существительных
Презентация на тему Склонение имен существительных  Породы Собак
Породы Собак Спецрисунок и художественная графика. Рисунок головы
Спецрисунок и художественная графика. Рисунок головы Cultural regions of America
Cultural regions of America Советские деньги
Советские деньги Электроэнергетика
Электроэнергетика Динамика развития РММ в цифрах: выход из штопора, переход в устойчивый плюс
Динамика развития РММ в цифрах: выход из штопора, переход в устойчивый плюс Полное рекламное обслуживание Акционерного коммерческого банка «АК БАРС»
Полное рекламное обслуживание Акционерного коммерческого банка «АК БАРС» Презентация на тему Первая русская революция 1905-1907 гг.
Презентация на тему Первая русская революция 1905-1907 гг.  Школьная адаптация первоклассника, как психолого-педагогическая проблема обучения
Школьная адаптация первоклассника, как психолого-педагогическая проблема обучения Сочинение – описание животного. Моя собака Крош
Сочинение – описание животного. Моя собака Крош Пушкинская усадьба в Болдино
Пушкинская усадьба в Болдино Мониторинг удовлетворенности потребителей образовательных услуг ГБОУ ВПО Первый МГМУ им. И.М.Сеченова Минздравсоцразвития Росси
Мониторинг удовлетворенности потребителей образовательных услуг ГБОУ ВПО Первый МГМУ им. И.М.Сеченова Минздравсоцразвития Росси Презентация на тему Табличный процессор EXCEL
Презентация на тему Табличный процессор EXCEL Волшебные сказки
Волшебные сказки Божественные свойства и их именования
Божественные свойства и их именования