- Lekciya4_1IT

Содержание
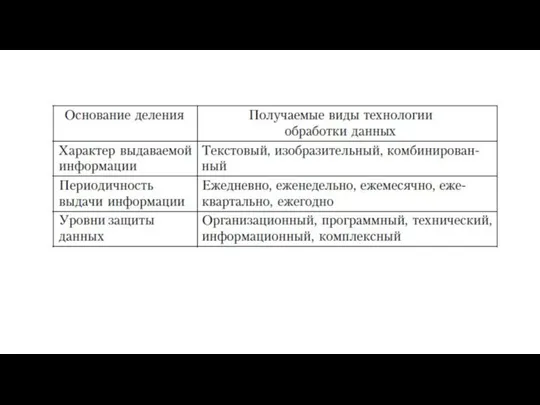
- 2. Видовая гамма технологии обработки данных определяется, прежде всего, совокупностью тех свойств, тех признаков, которые отображают содержательную
- 5. Путем сочетания выделенных классов можно строить различные схемы технологических процессов обработки данных от простых до сложных.
- 6. содержание решаемых задач; периодичность решения задач; масштаб производства предприятия; топология предприятия; профессиональный уровень специалистов и др.
- 7. Существует множество методов обработки информации, но в большинстве случаев они сводятся к обработке текстовых, числовых и
- 8. Обработка текстовых данных. В зависимости от формы представления для обработки текстовых сообщений используют разнообразные ИТ. Чаще
- 9. Обработка табличных данных Пользователям в процессе работы часто приходится иметь дело с табличными данными в процессе
- 10. Режимы обработки данных В ТПОД могут применяться следующие основные режимы обработки данных: пакетный, мультипрограммный и диалоговый.
- 11. Пакетная обработка данных это последовательная обработка данных по задачам пользователя в порядке их очередности. По каждой
- 12. Сущность пакетного режима состоит в последовательном выполнении имеющейся совокупности программ обработки данных. При этом достигается уменьшение
- 13. Выполнение задания в режиме пакетной обработки характеризуется типовой очередностью процедур обработки данных, включающих: логическое преобразование исходных
- 14. С целью сокращения времени на обработку данных и рационализации вычислительных ресурсов применяется мультипрограммный режим обработки данных.
- 15. Позднее появился диалоговый, или интерактивный, режим обработки данных. Диалоговый режим обработки данных — это вид обработки
- 16. При глобальном диалоге с помощью меню задается последовательность программ, характеризующих функциональные возможности программной системы. Локальный диалог
- 17. В диалоговом режиме пользователь занимает активную позицию по отношению к технологии обработки данных. В интерактивном режиме
- 18. Технологический процесс обработки и защиты данных Технология создания информации заключается в организации и формировании данных, информации
- 19. Технологический процесс обработки данных это логическая последовательность этапов обработки данных и выдачи информации пользователю путем реализации
- 20. Технологический процесс обработки данных в общем случае включает следующие основные этапы: прием и комплектование первичных документов
- 21. этап ТПОД — это совокупность взаимосвязанных процедур, реализующих определенную функцию технологического процесса. Процедурой могут быть распечатка
- 22. Процедура ТПОД — это совокупность технологических операций, обеспечивающая реализацию логической части этапа ТПОД. Элементарной единицей технологического
- 26. Схема ТПОД включает два контура: А и В. Контур А отображает этапы (блоки) технологического процесса обработки,
- 27. Затем на этапе 4 подготовленный документ контролируется на правильность в соответствии с инструкцией в режиме «Есть
- 28. На этапе 6 проводится аналитико-синтетическая переработка документа (АСПД). Это комплекс логических операций, например предметизация, классификация, кодирование,
- 29. На этапе 8 происходит контроль правильности содержательной и формальной частей документов. Если ошибка обнаружена, то проводятся
- 30. После исправления ошибок на этапе 9 проводится ввод документов (ВВД) в ЭВМ. В расширенном понимании ввод
- 31. Выбор устройства определяется характером документов и соответствующей экономической задачи. Так, необходимость оперативного ввода данных вызывает применение
- 32. В зависимости от характера задачи, объемов обрабатываемой информации и технологического времени ЭВМ во время обработки на
- 33. На этапе 18 проводится финишный контроль результатов обработки данных по решению задачи. Если ошибки обнаружены, например
- 34. В блоке 15 проводится обработка данных по решению задач АСОД и (или) АСУ. В рамках задач
- 35. Контроль информации в ТПОД Основной особенностью технологии обработки данных является то, что в ее рамках обычно
- 36. Как правило, разработчики коробочного ПО ИТ мало заботятся о программном контроле обнаружения и исправлении ошибок в
- 37. В различных ситуациях приходится контролировать обработку данных почти на всех этапах ТПОД. С этой целью широко
- 38. Задача обеспечения требуемого уровня достоверности вызывает необходимость применения процедур контроля на всех основных этапах технологического процесса
- 39. Достоверность и полнота информации обеспечиваются различными методами защиты: аппаратными, программными, организационными, комбинированными и др. По уровню
- 40. В значительной части систем организационного управления ввод информации в ЭВМ производится в форме документов. С целью
- 41. Анализ работ по контролю достоверности данных показывает, что имеющиеся методы и программы контроля достоверности и полноты
- 42. С целью определения основных требований к методам и средствам повышения уровня достоверности более детально рассмотрим принципиальную
- 43. Методы контроля данных по характеру возникновения ошибок можно подразделить на ошибки человеческого и аппаратного факторов. Ошибки
- 44. В процедурном отношении последовательность программного обнаружения ошибок и последующего их исправления можно отобразить схемой корректировки ошибок
- 46. Обозначения: ВДЭВМ — ввод документов в ЭВМ, ЕО? — есть ошибки?, РДВН — размещение документа на
- 47. Схема состоит из контура 1 — блоки, выполняемые посредством ЭВМ, и контура 2 — блоки, выполняемые
- 48. В блоке 7 происходит определение и (или) вычисление достоверного значения показателя документа. Ошибки в документах могут
- 49. Корректировочный бланк
- 50. Затем информация с корректировочного бланка вводится в ЭВМ и контролируется теми же методами. Корректировка прекращается в
- 51. В настоящее время сравнительно широко для обработки информации различного класса и назначения применяются системы управления базами
- 52. Методы программного контроля информации
- 54. Лексический контроль данных это проверка правильности формата значений реквизитов (полей), допустимого класса информации, соответствия лексем входного
- 55. С целью повышения достоверности информации в классификаторах и кодификаторах технико-экономической информации каждый код снабжается контрольным разрядом.
- 56. Эти весовые коэффициенты могут использоваться при вычислении контрольного разряда:
- 57. Синтаксический контроль данных это проверка наличия регламентированного количества элементов в форматах и порядка их расположения. Например,
- 58. Логический контроль данных это проверка содержательной взаимосвязи отдельных значений единиц информации. На основе свойств значений показателей
- 59. Распространенным методом контроля является арифметический (счетный) контроль данных — это проверка равенства контрольного значения определенного группового
- 60. При балансовом контроле значения показателей по документо-строкам или документо-графам проверяются отдельно. Шахматный контроль по сравнению с
- 61. Следует отметить, что реализация методов контроля, как правило, влечет за собой необходимость введения в процессы обработки
- 62. Необходимость обеспечения контроля как можно большего набора параметров входных документов вызывает увеличение числа соответствующих программных модулей.
- 63. Исходя из принципов контроля ИТ, максимального перевода функций контроля на ЭВМ, наиболее рациональным представляется способ, который
- 64. Алгоритм и программа автоматического обнаружения ошибок и восстановления достоверности значений показателей документов обеспечивают:
- 65. повышение уровня достоверности и полноты информации; снижение объемов временных, трудовых, материальных и финансовых ресурсов, используемых в
- 67. Скачать презентацию
Слайд 2Видовая гамма технологии обработки данных определяется, прежде всего, совокупностью тех свойств, тех
Видовая гамма технологии обработки данных определяется, прежде всего, совокупностью тех свойств, тех


Слайд 5Путем сочетания выделенных классов можно строить различные схемы технологических процессов обработки данных
Путем сочетания выделенных классов можно строить различные схемы технологических процессов обработки данных

Слайд 6содержание решаемых задач;
периодичность решения задач;
масштаб производства предприятия;
топология предприятия;
профессиональный уровень специалистов и др.
содержание решаемых задач;
периодичность решения задач;
масштаб производства предприятия;
топология предприятия;
профессиональный уровень специалистов и др.

Слайд 7Существует множество методов обработки информации, но в большинстве случаев они сводятся к
Существует множество методов обработки информации, но в большинстве случаев они сводятся к

Слайд 8Обработка текстовых данных.
В зависимости от формы представления для обработки текстовых сообщений используют
Обработка текстовых данных.
В зависимости от формы представления для обработки текстовых сообщений используют

Слайд 9Обработка табличных данных
Пользователям в процессе работы часто приходится иметь дело с табличными
Обработка табличных данных
Пользователям в процессе работы часто приходится иметь дело с табличными

Слайд 10Режимы обработки данных
В ТПОД могут применяться следующие основные режимы обработки данных: пакетный,
Режимы обработки данных
В ТПОД могут применяться следующие основные режимы обработки данных: пакетный,

Слайд 11Пакетная обработка данных
это последовательная обработка данных по задачам пользователя в порядке их
Пакетная обработка данных
это последовательная обработка данных по задачам пользователя в порядке их

Слайд 12Сущность пакетного режима состоит в последовательном выполнении имеющейся совокупности программ обработки данных.
Сущность пакетного режима состоит в последовательном выполнении имеющейся совокупности программ обработки данных.

Слайд 13Выполнение задания в режиме пакетной обработки характеризуется типовой очередностью процедур обработки данных,
Выполнение задания в режиме пакетной обработки характеризуется типовой очередностью процедур обработки данных,

Слайд 14С целью сокращения времени на обработку данных и рационализации вычислительных ресурсов применяется
С целью сокращения времени на обработку данных и рационализации вычислительных ресурсов применяется

Слайд 15Позднее появился диалоговый, или интерактивный, режим обработки данных. Диалоговый режим обработки данных
Позднее появился диалоговый, или интерактивный, режим обработки данных. Диалоговый режим обработки данных

Слайд 16При глобальном диалоге с помощью меню задается последовательность программ, характеризующих функциональные возможности
При глобальном диалоге с помощью меню задается последовательность программ, характеризующих функциональные возможности

Слайд 17В диалоговом режиме пользователь занимает активную позицию по отношению к технологии обработки
В диалоговом режиме пользователь занимает активную позицию по отношению к технологии обработки

Слайд 18Технологический процесс обработки и защиты данных
Технология создания информации заключается в организации и
Технологический процесс обработки и защиты данных
Технология создания информации заключается в организации и

Слайд 19Технологический процесс обработки данных
это логическая последовательность этапов обработки данных и выдачи информации
Технологический процесс обработки данных
это логическая последовательность этапов обработки данных и выдачи информации

Слайд 20Технологический процесс обработки данных в общем случае включает следующие основные этапы:
прием и
Технологический процесс обработки данных в общем случае включает следующие основные этапы:
прием и

Слайд 21этап ТПОД — это совокупность взаимосвязанных процедур, реализующих определенную функцию технологического процесса.
этап ТПОД — это совокупность взаимосвязанных процедур, реализующих определенную функцию технологического процесса.

Слайд 22Процедура ТПОД — это совокупность технологических операций, обеспечивающая реализацию логической части этапа
Процедура ТПОД — это совокупность технологических операций, обеспечивающая реализацию логической части этапа

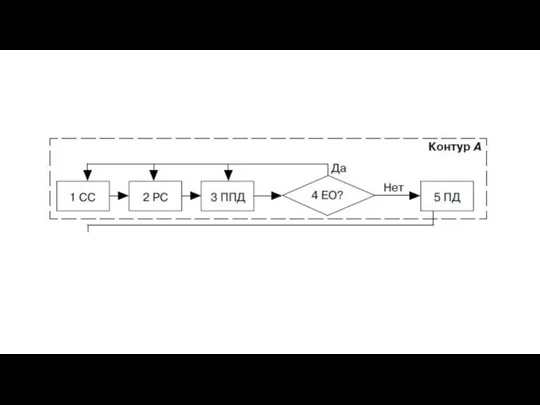
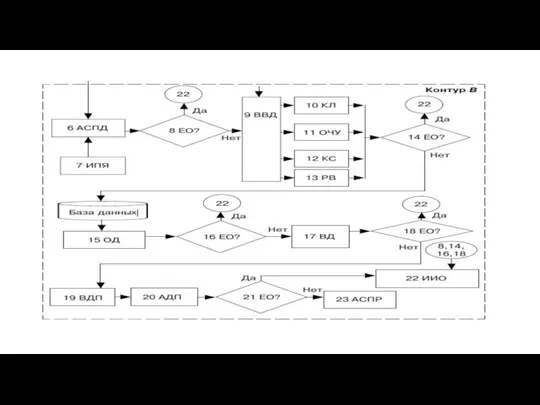

Слайд 26Схема ТПОД включает два контура: А и В. Контур А отображает этапы
Схема ТПОД включает два контура: А и В. Контур А отображает этапы

Слайд 27Затем на этапе 4 подготовленный документ контролируется на правильность в соответствии с
Затем на этапе 4 подготовленный документ контролируется на правильность в соответствии с

Слайд 28На этапе 6 проводится аналитико-синтетическая переработка документа (АСПД). Это комплекс логических операций,
На этапе 6 проводится аналитико-синтетическая переработка документа (АСПД). Это комплекс логических операций,

Слайд 29На этапе 8 происходит контроль правильности содержательной и формальной частей документов. Если
На этапе 8 происходит контроль правильности содержательной и формальной частей документов. Если

Слайд 30После исправления ошибок на этапе 9 проводится ввод документов (ВВД) в ЭВМ.
После исправления ошибок на этапе 9 проводится ввод документов (ВВД) в ЭВМ.

Слайд 31Выбор устройства определяется характером документов и соответствующей экономической задачи. Так, необходимость оперативного
Выбор устройства определяется характером документов и соответствующей экономической задачи. Так, необходимость оперативного

Слайд 32В зависимости от характера задачи, объемов обрабатываемой информации и технологического времени ЭВМ
В зависимости от характера задачи, объемов обрабатываемой информации и технологического времени ЭВМ

Слайд 33На этапе 18 проводится финишный контроль результатов обработки данных по решению задачи.
На этапе 18 проводится финишный контроль результатов обработки данных по решению задачи.

Слайд 34В блоке 15 проводится обработка данных по решению задач АСОД и (или)
В блоке 15 проводится обработка данных по решению задач АСОД и (или)

Слайд 35Контроль информации в ТПОД
Основной особенностью технологии обработки данных является то, что в
Контроль информации в ТПОД
Основной особенностью технологии обработки данных является то, что в

Слайд 36Как правило, разработчики коробочного ПО ИТ мало заботятся о программном контроле обнаружения
Как правило, разработчики коробочного ПО ИТ мало заботятся о программном контроле обнаружения

Слайд 37В различных ситуациях приходится контролировать обработку данных почти на всех этапах ТПОД.
В различных ситуациях приходится контролировать обработку данных почти на всех этапах ТПОД.

Слайд 38Задача обеспечения требуемого уровня достоверности вызывает необходимость применения процедур контроля на всех
Задача обеспечения требуемого уровня достоверности вызывает необходимость применения процедур контроля на всех

Слайд 39Достоверность и полнота информации обеспечиваются различными методами защиты: аппаратными, программными, организационными, комбинированными
Достоверность и полнота информации обеспечиваются различными методами защиты: аппаратными, программными, организационными, комбинированными

Слайд 40В значительной части систем организационного управления ввод информации в ЭВМ производится в
В значительной части систем организационного управления ввод информации в ЭВМ производится в

Слайд 41Анализ работ по контролю достоверности данных показывает, что имеющиеся методы и программы
Анализ работ по контролю достоверности данных показывает, что имеющиеся методы и программы

Слайд 42С целью определения основных требований к методам и средствам повышения уровня достоверности
С целью определения основных требований к методам и средствам повышения уровня достоверности

Слайд 43Методы контроля данных по характеру возникновения ошибок можно подразделить на ошибки человеческого
Методы контроля данных по характеру возникновения ошибок можно подразделить на ошибки человеческого

Слайд 44В процедурном отношении последовательность программного обнаружения ошибок и последующего их исправления можно
В процедурном отношении последовательность программного обнаружения ошибок и последующего их исправления можно

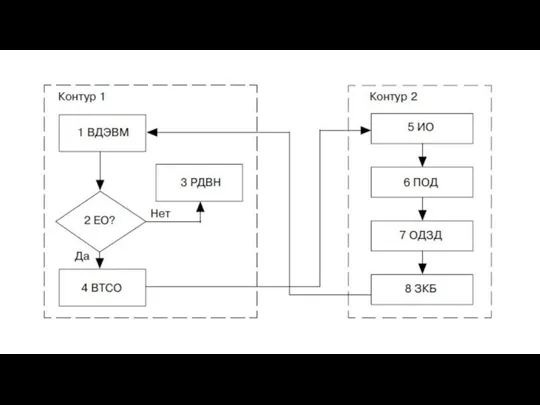
Слайд 46Обозначения: ВДЭВМ — ввод документов в ЭВМ, ЕО? — есть ошибки?, РДВН
Обозначения: ВДЭВМ — ввод документов в ЭВМ, ЕО? — есть ошибки?, РДВН

Слайд 47Схема состоит из контура 1 — блоки, выполняемые посредством ЭВМ, и контура
Схема состоит из контура 1 — блоки, выполняемые посредством ЭВМ, и контура

Слайд 48В блоке 7 происходит определение и (или) вычисление достоверного значения показателя документа.
В блоке 7 происходит определение и (или) вычисление достоверного значения показателя документа.

Слайд 49Корректировочный бланк
Корректировочный бланк

Слайд 50Затем информация с корректировочного бланка вводится в ЭВМ и контролируется теми же
Затем информация с корректировочного бланка вводится в ЭВМ и контролируется теми же

Слайд 51В настоящее время сравнительно широко для обработки информации различного класса и назначения
В настоящее время сравнительно широко для обработки информации различного класса и назначения

Слайд 52Методы программного контроля информации
Методы программного контроля информации


Слайд 54Лексический контроль данных
это проверка правильности формата значений реквизитов (полей), допустимого класса
Лексический контроль данных
это проверка правильности формата значений реквизитов (полей), допустимого класса

Слайд 55С целью повышения достоверности информации в классификаторах и кодификаторах технико-экономической информации каждый
С целью повышения достоверности информации в классификаторах и кодификаторах технико-экономической информации каждый

Слайд 56Эти весовые коэффициенты могут использоваться при вычислении контрольного разряда:
Эти весовые коэффициенты могут использоваться при вычислении контрольного разряда:

Слайд 57Синтаксический контроль данных
это проверка наличия регламентированного количества элементов в форматах и порядка
Синтаксический контроль данных
это проверка наличия регламентированного количества элементов в форматах и порядка

Слайд 58Логический контроль данных
это проверка содержательной взаимосвязи отдельных значений единиц информации. На основе
Логический контроль данных
это проверка содержательной взаимосвязи отдельных значений единиц информации. На основе

Слайд 59Распространенным методом контроля является арифметический (счетный) контроль данных — это проверка равенства
Распространенным методом контроля является арифметический (счетный) контроль данных — это проверка равенства

Слайд 60При балансовом контроле значения показателей по документо-строкам или документо-графам проверяются отдельно. Шахматный
При балансовом контроле значения показателей по документо-строкам или документо-графам проверяются отдельно. Шахматный

Слайд 61Следует отметить, что реализация методов контроля, как правило, влечет за собой необходимость
Следует отметить, что реализация методов контроля, как правило, влечет за собой необходимость

Слайд 62Необходимость обеспечения контроля как можно большего набора параметров входных документов вызывает увеличение
Необходимость обеспечения контроля как можно большего набора параметров входных документов вызывает увеличение

Слайд 63Исходя из принципов контроля ИТ, максимального перевода функций контроля на ЭВМ, наиболее
Исходя из принципов контроля ИТ, максимального перевода функций контроля на ЭВМ, наиболее

Слайд 64Алгоритм и программа автоматического обнаружения ошибок и восстановления достоверности значений показателей документов
Алгоритм и программа автоматического обнаружения ошибок и восстановления достоверности значений показателей документов

Слайд 65повышение уровня достоверности и полноты информации;
снижение объемов временных, трудовых, материальных и финансовых
повышение уровня достоверности и полноты информации;
снижение объемов временных, трудовых, материальных и финансовых

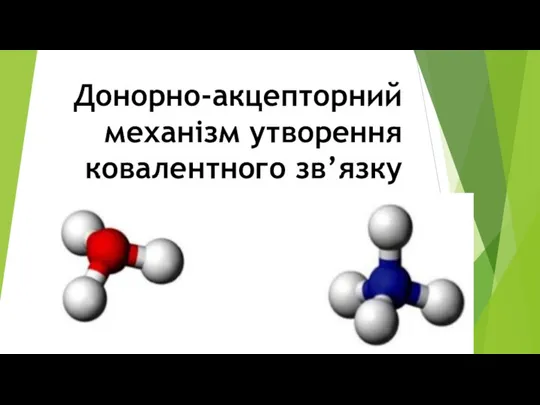 Донорно - акц. механізм
Донорно - акц. механізм ВОДА
ВОДА Моделирование
Моделирование Функциональная анатомия ствола головного мозга. Понятие о ретикулярной формации
Функциональная анатомия ствола головного мозга. Понятие о ретикулярной формации Изо – викторина (5 класс)
Изо – викторина (5 класс) Магнитное поле
Магнитное поле Компьютерная презентация команды id091тема: «Модели. Классификация моделей.»
Компьютерная презентация команды id091тема: «Модели. Классификация моделей.» Модернизм и новые направления культуры первой половины ХХ века
Модернизм и новые направления культуры первой половины ХХ века Появление и эволюция вредоносных программ. Основные направления развития. Методы противодействия.
Появление и эволюция вредоносных программ. Основные направления развития. Методы противодействия. Анализ показателей финансово-экономической деятельности ГБУЗ Городская больница
Анализ показателей финансово-экономической деятельности ГБУЗ Городская больница АНО СО Достойный Возраст
АНО СО Достойный Возраст Функции науки об управлении персоналом
Функции науки об управлении персоналом Food and healthy eating
Food and healthy eating  Презентация на тему Фольклор в музыке русских композиторов (5 класс)
Презентация на тему Фольклор в музыке русских композиторов (5 класс) Каплиев А.С., инициатор создания общественного движения «За право на достоинство и свободное развитие»
Каплиев А.С., инициатор создания общественного движения «За право на достоинство и свободное развитие» Маркетинг услуг по кадровому консалтингу
Маркетинг услуг по кадровому консалтингу Репрезентативная система и темперамент человекаПрактико-ориентированное занятие для педагогов Детской школы искусств
Репрезентативная система и темперамент человекаПрактико-ориентированное занятие для педагогов Детской школы искусств Тесты 7 – 8 класс
Тесты 7 – 8 класс Инертные газы
Инертные газы Дыхание
Дыхание Виды Москвы с Останкинской башни
Виды Москвы с Останкинской башни Что вчера было хорошо, может считаться таковым и завтра. Однако не должно. Остается понять, что должно измениться.
Что вчера было хорошо, может считаться таковым и завтра. Однако не должно. Остается понять, что должно измениться. Питер Брейгель Старший
Питер Брейгель Старший Отчет команды об участии в онлайн-конкурсе кулинарного искусства Мастер Шеф
Отчет команды об участии в онлайн-конкурсе кулинарного искусства Мастер Шеф ОСНОВИ НА ПРОЦЕСОТ НА ПЛАНИРАЊЕ НА КОМУНИЦИРАЊЕТО
ОСНОВИ НА ПРОЦЕСОТ НА ПЛАНИРАЊЕ НА КОМУНИЦИРАЊЕТО Технология изготовления изделия (руководство для школьников)
Технология изготовления изделия (руководство для школьников)  МЕТОДИЧЕСКОЕ ОБЪЕДИНЕНИЕ УЧИТЕЛЕЙ НАЧАЛЬНЫХ КЛАССОВМОУ СОШ №1
МЕТОДИЧЕСКОЕ ОБЪЕДИНЕНИЕ УЧИТЕЛЕЙ НАЧАЛЬНЫХ КЛАССОВМОУ СОШ №1 Система управления персоналом: приемы, методы, технологии, процедуры работы с кадрами
Система управления персоналом: приемы, методы, технологии, процедуры работы с кадрами