- OLTP и OLAP

Содержание
- 2. Задачи OLTP-системы – это быстрый сбор и оптимальное размещение данных в БД, а также обеспечение их
- 3. Традиционный процесс принятия решений в российской компании, использующей информационную систему, построенную на OLTP-технологии: Менеджер дает задание
- 4. Недостатки такой схемы принятия решений: используется малое количество данных; процесс занимает длительное время; требуется повторение цикла
- 5. Выход из этой ситуации – исходная информация должна быть доступна ее непосредственному потребителю – аналитику (Билл
- 6. Основы OLAP OLAP – технологии интерактивной аналитической обработки данных в системах БД, предназначенные для поддержки принятия
- 7. В качестве источников данных часто используют хранилища данных. Обеспечивает многомерный анализ данных (с т. зр. их
- 8. OLAP (On-Line Analytical Processing) OLAP – это совокупность концепций, принципов и требований, лежащих в основе программных
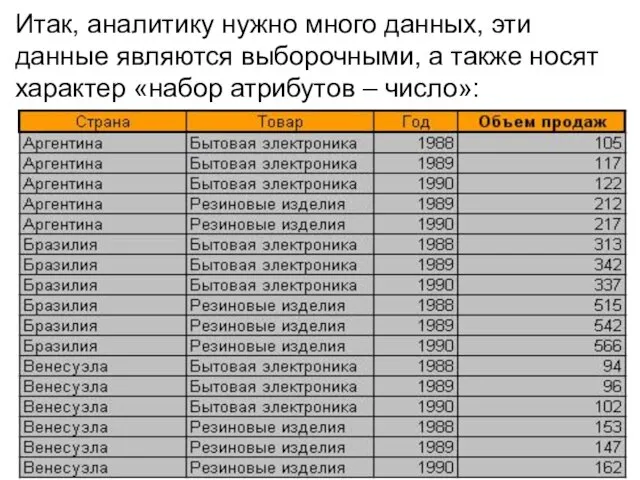
- 9. Итак, аналитику нужно много данных, эти данные являются выборочными, а также носят характер «набор атрибутов –
- 10. В общем случае куб может быть многомерным (~ до 20 измерений) – «система координат» В принципе,
- 11. Измерения OLAP-кубов (например: страна, товар, год) состоят из т.н. меток или членов (members). Например: измерение "Страна"
- 12. Куб сам по себе не пригоден для восприятия и анализа человеком (нельзя адекватно представить более 3-х
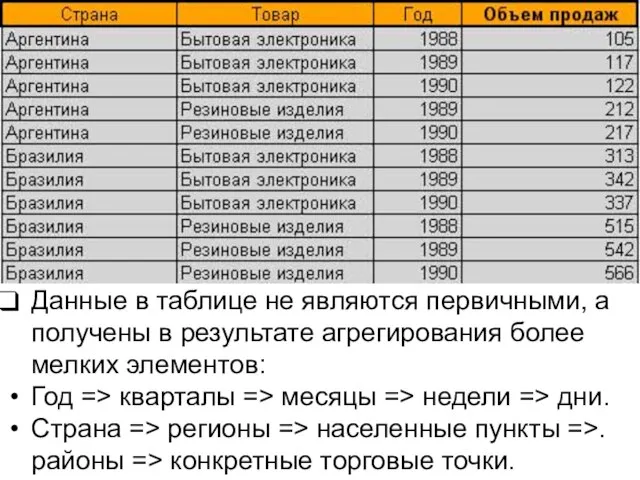
- 13. Данные в таблице не являются первичными, а получены в результате агрегирования более мелких элементов: Год =>
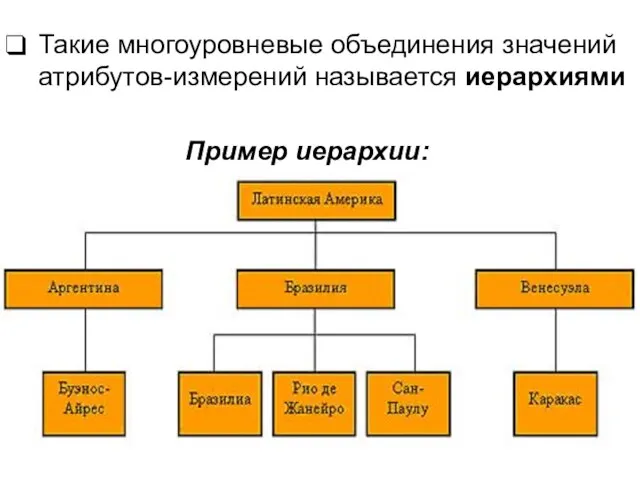
- 14. Такие многоуровневые объединения значений атрибутов-измерений называется иерархиями Пример иерархии:
- 15. Исходные данные берутся из нижних уровней иерархий, а затем суммируются для получения значений более высоких уровней.
- 16. Средства OLAP позволяют значительно повысить эффективность работы аналитика с данными по сравнению с OLTP-системами. Аналитик непосредственно
- 17. Тест FASMI (требования к продуктам OLAP): Fast (Быстрый) - время доступа к аналитическим данным - порядка
- 18. Хранилища данных (Data Warehouse) Хранилище данных (ХД) и OLAP - две разные технологии. Однако, в комплексных
- 19. Понятие хранилища данных: Хранилище данных — система, содержащая непротиворечивую интегрированную предметно-ориентированную совокупность исторических данных крупной корпорации
- 20. Билл Инмон («отец» хранилищ данных): Хранилища данных - "предметно ориентированные, интегрированные, неизменчивые, поддерживающие хронологию наборы данных,
- 21. Предметная ориентация – данные объединены в категории и сохраняются соответственно областям, которые они описывают, а не
- 22. Привязка ко времени – хранилище можно рассматривать как совокупность "исторических" данных: возможно восстановление данных на любой
- 23. В дополнение к единому ХД могут создаваться т.н. витрины данных Витрина данных (Data Mart) – хранилище
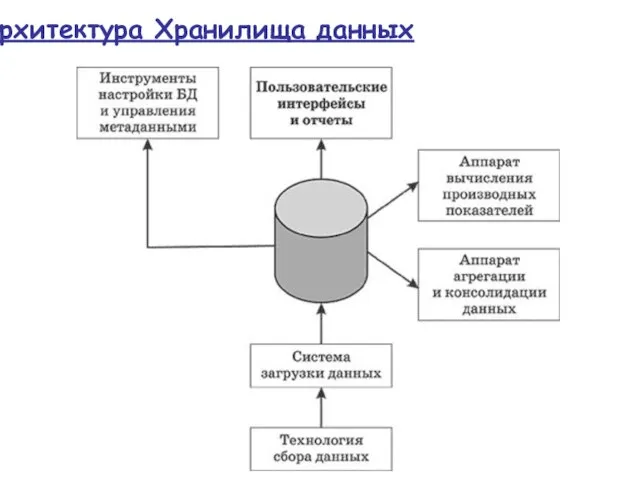
- 24. Архитектура Хранилища данных
- 25. Хранилище данных (OLAP, Data Mining) OLTP DB сбор, очистка, загрузка OLTP DB OLTP DB Витрина данных
- 26. Контрольные вопросы: Сущность и назначение операции разрезания (slice) куба OLAP Сущность и назначение иерархий значений в
- 27. Data Mining Корпоративная БД любого современного предприятия обычно содержит набор таблиц, хранящих записи о тех или
- 28. Примеры сведений, которые могут быть получены на основе анализа больших объемов накопленных данных: как зависят продажи
- 29. Григорий Пиатецкий-Шапиро (один из основателей направления): Data Mining – это процесс обнаружения в сырых данных ранее
- 30. Неочевидных – найденные закономерности не обнаруживаются стандартными методами обработки информации или экспертным путем. Объективных – обнаруженные
- 31. Data Mining – это процесс, цель которого - обнаружить новые значимые корреляции, образцы и тенденции в
- 32. Сравнительные примеры вопросов:
- 33. Типы закономерностей, выявляемых методами Data Mining: Ассоциация — высокая вероятность связи событий друг с другом (например,
- 34. Классификация — имеются признаки, характеризующие группу, к которой принадлежит то или иное событие или объект Кластеризация
- 35. Методы исследования данных в Data Mining: регрессионный, дисперсионный и корреляционный анализ; нейросетевые алгоритмы; выбор близкого аналога
- 36. Хранилище данных (OLAP, Data Mining) OLTP DB сбор, очистка, загрузка OLTP DB OLTP DB Витрина данных
- 37. Агентство Gartner Group в 1980-х годах ввело термин "Business Intelligence" (BI) – деловой интеллект или бизнес-интеллект.
- 38. Понятие BI объединяет в себе различные средства и технологии анализа и обработки данных масштаба предприятия. На
- 39. По Gartner Group к системам Business Intelligence относятся программные продукты следующих классов: средства построения хранилищ данных
- 40. Экспертные системы (ЭС) Характеристика и назначение: Основная идея состоит в отчуждении и сохранении знаний и опыта
- 41. Экспертная система — компьютерная программа, способная заменить специалиста-эксперта в решении проблемной ситуации. Экспертная система — это
- 42. Экспертная система – компьютерная система, использующая знания одного или нескольких экспертов (представленные в некотором формальном виде),
- 43. Основные характеристики ЭС: Используют эвристические, субъективные знания экспертов в определенной ПрО. Знания отделены от данных. Предназначены
- 44. Решения ЭС обладают "прозрачностью", т.е. могут быть объяснены пользователю на качественном уровне (способны объяснить, как было
- 45. Преимущества ЭС перед человеком-экспертом: у них нет предубеждений и они устойчивы к различным помехам; они не
- 46. База знаний Интерфейс пользователя Подсистема логического вывода Подсистема объяснений Подсистема приобретения знаний База данных (раб. память)
- 47. База знаний (БЗ) предназначена для хранения экспертных знаний о ПрО, используемых при решении задач экспертной системой.
- 48. Организация БЗ на основе системы продукций (если…, то…): БЗ – совокупность правил («клише»), позволяющих на основе
- 49. База данных часто используется для временного хранения фактов или гипотез, являющихся промежуточными решениями или результатом общения
- 50. Интерфейс пользователя служит для ведения диалога с пользователем, в ходе которого ЭС запрашивает у пользователя необходимые
- 51. Подсистема приобретения знаний служит для корректировки и пополнения базы знаний. В простейшем случае это - интеллектуальный
- 52. Среди инструментальных средств для создания ЭС наиболее популярны такие языки программирования, как LISP и PROLOG, а
- 53. Основные классы задач, решаемых экспертными системами: диагностика, прогнозирование, идентификация, управление (в том числе - ТП), проектирование,
- 54. Области деятельности, где используются экспертные системы: медицина, вычислительная техника, военное дело, микроэлектроника, радиоэлектроника, юриспруденция, экономика, экология,
- 55. Примеры широко известных ЭС: DENDRAL – разработана в Стэндфордском ун-те в сер. 60-х годов для распознавания
- 56. MYCIN - разработана в Стэндфордском университете в середине 70-х годов для диагностики и лечения инфекционных заболеваний
- 57. Контрольные вопросы: Сущность и назначение Data Mining. Основные отличия Data Mining от OLAP. Сущность и назначение
- 58. Технологии управления знаниями Понятие «управление знаниями» (УЗ) появилось в середине 90-х годов в крупных корпорациях, для
- 59. «Управление знаниями» можно рассматривать и как новое направление в менеджменте, и как направление в информатике для
- 60. Двойственность понятия «управление знаниями»
- 61. Новизна концепции УЗ заключается в принципиально новой задаче – копить не только разрозненную информацию, бумаги, графики,
- 62. Понятие «знания» трактуется в УЗ очень широко. Под знаниями скорее понимаются информационно-знаниевые ресурсы. Знания м.б. явными
- 63. Ключ к УЗ - доставка нужных знаний нужным людям в нужное для эффективной реализации бизнес-процессов время.
- 64. Для преодоления перечисленных барьеров и достижения целей УЗ предназначены корпоративные системы управления знаниями (СУЗ), к-рые должны
- 65. широкий спектр средств (среду) для профессионального общения и обмена знаниями между специалистами, экспертами, командами, проектными группами
- 66. В СУЗ интегрируются разнообразные технологии: электронная почта и Интернет-ресурсы; системы управления базами данных (СУБД) и сами
- 67. СУЗ существенно отличается от ИС организации: Предназначение ИС – эффективное хранение, обработка и предоставление пользователям по
- 68. Ввиду относительной новизны проблематики, представления о структуре и составе элементов СУЗ не являются устоявшимся. По одной
- 69. Концептуальная архитектура системы SEAL
- 70. Модели представления знаний Существует множество обстоятельств, которые затрудняют распространение и обмен знаниями между людьми. Дело не
- 72. Например, много неструктурированных и полуструктурированных информационных источников доступно в сети Web и на различных корпоративных порталах,
- 73. Описанием знаний уже давно занимается дисциплина «Искусственный интеллект» (ИИ), (такие ее разделы, как «Представление знаний» и
- 74. Целью УЗ является организация эффективной работы со знаниями (повышение эффективности процессов преобразования знаний на предприятии, создание,
- 75. В настоящее время существуют и развиваются разные методы представления и описания знаний, такие, как: продукционные модели,
- 76. Продукционная модель или модель, основанная на правилах, позволяет представлять знания в виде предположения типа «if -
- 77. Семантическая сеть («смысловая» сеть) Семантика - это наука, устанавливающая отношения между символами и объектами, которые они
- 78. Следует различать понятия «Семантическая сеть» (англ. Semantic Network) и «Семантическая паутина» (англ. Semantic Web). Компьютерные семантические
- 79. Чаще всего в семантических сетях используются следующие отношения: Родо-видовое отношение (транспортное средство – автомобиль) Часть —
- 80. пространственные (далеко от, близко от, за, под, над…); временные (раньше, позже, в течение…); атрибутивные (иметь свойство,
- 81. СС, отражающая взаимоотношения между атрибутами птицы и самолета
- 82. Классификации семантических сетей (по Гавриловой) По количеству типов отношений: Однородные (с единственным типом отношений). Неоднородные (с
- 83. Семантическая паутина (Semantic Web) Концепция организации гипертекста напоминает однородную бинарную СС (страницы – узлы, а гиперссылки
- 84. Фрейм (от англ. frame - каркас, рамка) Это абстрактный образ для представления некоторого стереотипа восприятия. По
- 85. Модель фрейма является достаточно универсальной, поскольку позволяет отобразить все многообразие знаний о мире через: фреймы-структуры, использующиеся
- 86. В качестве значения слота может выступать имя другого фрейма, так образуются сети фреймов. Существует несколько способов
- 87. Важнейшим свойством теории фреймов является наследование свойств (из СС). Наследование происходит по АКО-связям (A-Kind-Of = это)
- 88. Онтология В последние десятилетия онтологии рассматриваются в качестве наиболее перспективной модели представления знаний Термин заимствован из
- 89. Онтология – это формальное, явное, точное определение (спецификация) совместно используемой концептуализации (Gruber T.A., 1995) Концептуализация –
- 90. Рабочее и более приближенное к УЗ определение [Гаврилова Т.А., Хорошевский]: Онтологии - это базы знаний специального
- 91. Формальная модель онтологии Под формальной моделью онтологии О будем понимать упорядоченную тройку вида: О = ,
- 92. Некоторые граничные случаи: Пусть R = Ø и F = Ø => онтология О трансформируется в
- 94. Скачать презентацию

Слайд 3Традиционный процесс принятия решений в российской компании, использующей информационную систему, построенную на
Традиционный процесс принятия решений в российской компании, использующей информационную систему, построенную на

Слайд 4Недостатки такой схемы принятия решений:
используется малое количество данных;
процесс занимает длительное время;
требуется повторение
Недостатки такой схемы принятия решений:
используется малое количество данных;
процесс занимает длительное время;
требуется повторение

Слайд 5Выход из этой ситуации – исходная информация должна быть доступна ее непосредственному
Выход из этой ситуации – исходная информация должна быть доступна ее непосредственному

Слайд 6Основы OLAP
OLAP – технологии интерактивной аналитической обработки данных в системах БД, предназначенные
Основы OLAP
OLAP – технологии интерактивной аналитической обработки данных в системах БД, предназначенные

Слайд 7В качестве источников данных часто используют хранилища данных.
Обеспечивает многомерный анализ данных (с
В качестве источников данных часто используют хранилища данных.
Обеспечивает многомерный анализ данных (с

Слайд 8OLAP (On-Line Analytical Processing)
OLAP – это совокупность концепций, принципов и требований, лежащих
OLAP (On-Line Analytical Processing)
OLAP – это совокупность концепций, принципов и требований, лежащих

Слайд 9Итак, аналитику нужно много данных, эти данные являются выборочными, а также носят
Итак, аналитику нужно много данных, эти данные являются выборочными, а также носят
Слайд 10В общем случае куб может быть многомерным (~ до 20 измерений) –
В общем случае куб может быть многомерным (~ до 20 измерений) –

Слайд 11Измерения OLAP-кубов (например: страна, товар, год) состоят из т.н. меток или членов
Измерения OLAP-кубов (например: страна, товар, год) состоят из т.н. меток или членов

Слайд 12Куб сам по себе не пригоден для восприятия и анализа человеком (нельзя
Куб сам по себе не пригоден для восприятия и анализа человеком (нельзя

Слайд 13Данные в таблице не являются первичными, а получены в результате агрегирования более
Данные в таблице не являются первичными, а получены в результате агрегирования более
Слайд 14Такие многоуровневые объединения значений атрибутов-измерений называется иерархиями
Пример иерархии:
Такие многоуровневые объединения значений атрибутов-измерений называется иерархиями
Пример иерархии:
Слайд 15Исходные данные берутся из нижних уровней иерархий, а затем суммируются для получения
Исходные данные берутся из нижних уровней иерархий, а затем суммируются для получения

Слайд 16Средства OLAP позволяют значительно повысить эффективность работы аналитика с данными по сравнению
Средства OLAP позволяют значительно повысить эффективность работы аналитика с данными по сравнению

Слайд 17Тест FASMI (требования к продуктам OLAP):
Fast (Быстрый) - время доступа к аналитическим
Тест FASMI (требования к продуктам OLAP):
Fast (Быстрый) - время доступа к аналитическим

Слайд 18Хранилища данных (Data Warehouse)
Хранилище данных (ХД) и OLAP - две разные технологии.
Хранилища данных (Data Warehouse)
Хранилище данных (ХД) и OLAP - две разные технологии.

Слайд 19Понятие хранилища данных:
Хранилище данных — система, содержащая непротиворечивую интегрированную предметно-ориентированную совокупность исторических
Понятие хранилища данных:
Хранилище данных — система, содержащая непротиворечивую интегрированную предметно-ориентированную совокупность исторических

Слайд 20Билл Инмон («отец» хранилищ данных):
Хранилища данных - "предметно ориентированные, интегрированные, неизменчивые,
Билл Инмон («отец» хранилищ данных):
Хранилища данных - "предметно ориентированные, интегрированные, неизменчивые,

Слайд 21Предметная ориентация – данные объединены в категории и сохраняются соответственно областям, которые
Предметная ориентация – данные объединены в категории и сохраняются соответственно областям, которые

Слайд 22Привязка ко времени – хранилище можно рассматривать как совокупность "исторических" данных: возможно
Привязка ко времени – хранилище можно рассматривать как совокупность "исторических" данных: возможно

Слайд 23В дополнение к единому ХД могут создаваться т.н. витрины данных
Витрина данных (Data
В дополнение к единому ХД могут создаваться т.н. витрины данных
Витрина данных (Data

Слайд 24Архитектура Хранилища данных
Архитектура Хранилища данных
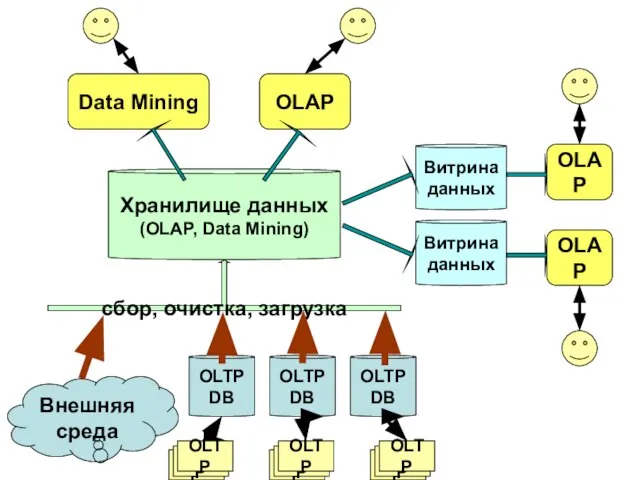
Слайд 25Хранилище данных
(OLAP, Data Mining)
OLTP DB
сбор, очистка, загрузка
OLTP DB
OLTP DB
Витрина данных
Внешняя среда
Витрина данных
Data
Хранилище данных
(OLAP, Data Mining)
OLTP DB
сбор, очистка, загрузка
OLTP DB
OLTP DB
Витрина данных
Внешняя среда
Витрина данных
Data
Слайд 26Контрольные вопросы:
Сущность и назначение операции разрезания (slice) куба OLAP
Сущность и назначение иерархий
Контрольные вопросы:
Сущность и назначение операции разрезания (slice) куба OLAP
Сущность и назначение иерархий

Слайд 27Data Mining
Корпоративная БД любого современного предприятия обычно содержит набор таблиц, хранящих
Data Mining
Корпоративная БД любого современного предприятия обычно содержит набор таблиц, хранящих

Слайд 28Примеры сведений, которые могут быть получены на основе анализа больших объемов накопленных
Примеры сведений, которые могут быть получены на основе анализа больших объемов накопленных

Слайд 29Григорий Пиатецкий-Шапиро (один из основателей направления):
Data Mining – это процесс обнаружения в
Григорий Пиатецкий-Шапиро (один из основателей направления):
Data Mining – это процесс обнаружения в

Слайд 30Неочевидных – найденные закономерности не обнаруживаются стандартными методами обработки информации или экспертным
Неочевидных – найденные закономерности не обнаруживаются стандартными методами обработки информации или экспертным

Слайд 31Data Mining – это процесс, цель которого - обнаружить новые значимые корреляции,
Data Mining – это процесс, цель которого - обнаружить новые значимые корреляции,

Слайд 32Сравнительные примеры вопросов:
Сравнительные примеры вопросов:

Слайд 33Типы закономерностей, выявляемых методами Data Mining:
Ассоциация — высокая вероятность связи событий друг
Типы закономерностей, выявляемых методами Data Mining:
Ассоциация — высокая вероятность связи событий друг

Слайд 34Классификация — имеются признаки, характеризующие группу, к которой принадлежит то или иное
Классификация — имеются признаки, характеризующие группу, к которой принадлежит то или иное

Слайд 35Методы исследования данных в Data Mining:
регрессионный, дисперсионный и корреляционный анализ;
нейросетевые алгоритмы;
выбор близкого
Методы исследования данных в Data Mining:
регрессионный, дисперсионный и корреляционный анализ;
нейросетевые алгоритмы;
выбор близкого

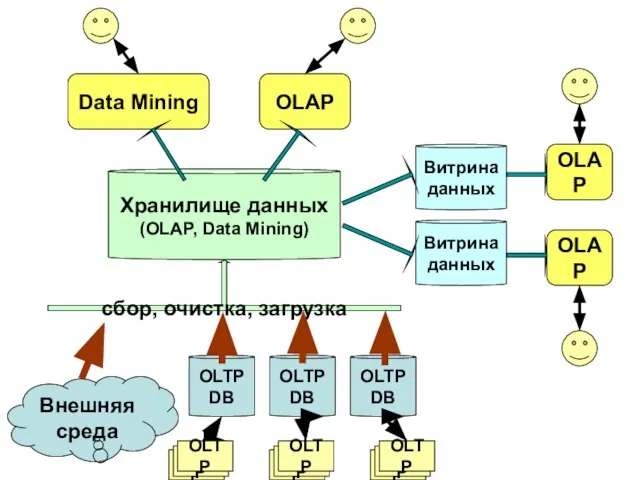
Слайд 36Хранилище данных
(OLAP, Data Mining)
OLTP DB
сбор, очистка, загрузка
OLTP DB
OLTP DB
Витрина данных
Внешняя среда
Витрина данных
Data
Хранилище данных
(OLAP, Data Mining)
OLTP DB
сбор, очистка, загрузка
OLTP DB
OLTP DB
Витрина данных
Внешняя среда
Витрина данных
Data
Слайд 37Агентство Gartner Group в 1980-х годах ввело термин "Business Intelligence" (BI) –
Агентство Gartner Group в 1980-х годах ввело термин "Business Intelligence" (BI) –

Слайд 38Понятие BI объединяет в себе различные средства и технологии анализа и обработки
Понятие BI объединяет в себе различные средства и технологии анализа и обработки

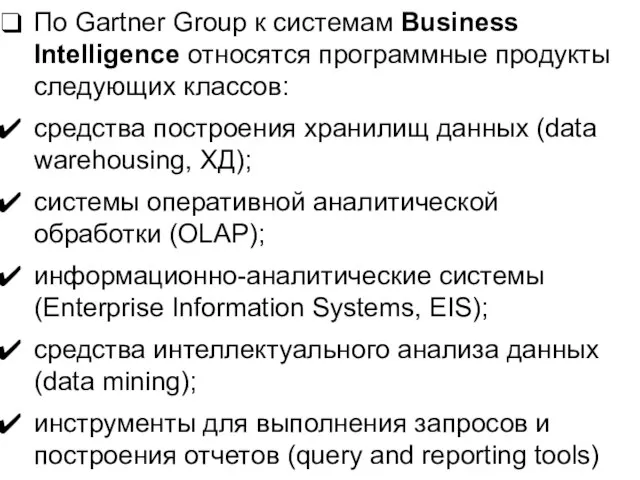
Слайд 39По Gartner Group к системам Business Intelligence относятся программные продукты следующих классов:
средства
По Gartner Group к системам Business Intelligence относятся программные продукты следующих классов:
средства
Слайд 40Экспертные системы (ЭС)
Характеристика и назначение:
Основная идея состоит в отчуждении и сохранении знаний
Экспертные системы (ЭС)
Характеристика и назначение:
Основная идея состоит в отчуждении и сохранении знаний

Слайд 41Экспертная система — компьютерная программа, способная заменить специалиста-эксперта в решении проблемной ситуации.
Экспертная
Экспертная система — компьютерная программа, способная заменить специалиста-эксперта в решении проблемной ситуации.
Экспертная

Слайд 42Экспертная система – компьютерная система, использующая знания одного или нескольких экспертов (представленные
Экспертная система – компьютерная система, использующая знания одного или нескольких экспертов (представленные

Слайд 43Основные характеристики ЭС:
Используют эвристические, субъективные знания экспертов в определенной ПрО. Знания отделены
Основные характеристики ЭС:
Используют эвристические, субъективные знания экспертов в определенной ПрО. Знания отделены

Слайд 44Решения ЭС обладают "прозрачностью", т.е. могут быть объяснены пользователю на качественном уровне
Решения ЭС обладают "прозрачностью", т.е. могут быть объяснены пользователю на качественном уровне

Слайд 45Преимущества ЭС перед человеком-экспертом:
у них нет предубеждений и они устойчивы к
Преимущества ЭС перед человеком-экспертом:
у них нет предубеждений и они устойчивы к

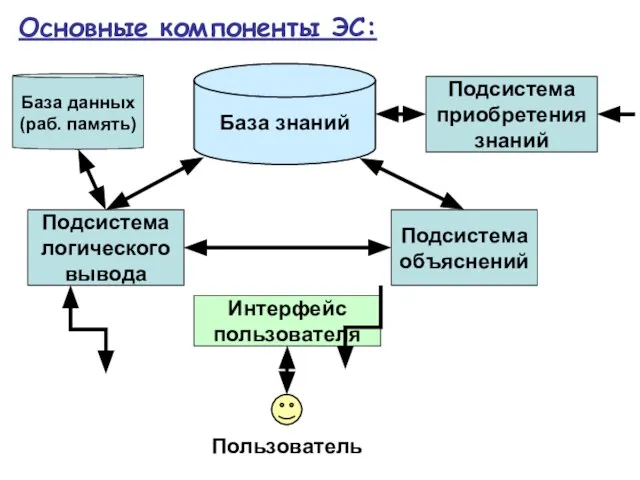
Слайд 46База знаний
Интерфейс пользователя
Подсистема логического вывода
Подсистема объяснений
Подсистема приобретения знаний
База данных (раб. память)
Основные компоненты
База знаний
Интерфейс пользователя
Подсистема логического вывода
Подсистема объяснений
Подсистема приобретения знаний
База данных (раб. память)
Основные компоненты
Слайд 47База знаний (БЗ) предназначена для хранения экспертных знаний о ПрО, используемых при
База знаний (БЗ) предназначена для хранения экспертных знаний о ПрО, используемых при

Слайд 48Организация БЗ на основе системы продукций (если…, то…):
БЗ – совокупность правил («клише»),
Организация БЗ на основе системы продукций (если…, то…):
БЗ – совокупность правил («клише»),

Слайд 49База данных часто используется для временного хранения фактов или гипотез, являющихся промежуточными
База данных часто используется для временного хранения фактов или гипотез, являющихся промежуточными

Слайд 50Интерфейс пользователя служит для ведения диалога с пользователем, в ходе которого ЭС
Интерфейс пользователя служит для ведения диалога с пользователем, в ходе которого ЭС

Слайд 51Подсистема приобретения знаний служит для корректировки и пополнения базы знаний. В простейшем
Подсистема приобретения знаний служит для корректировки и пополнения базы знаний. В простейшем

Слайд 52Среди инструментальных средств для создания ЭС наиболее популярны такие языки программирования, как
Среди инструментальных средств для создания ЭС наиболее популярны такие языки программирования, как

Слайд 53Основные классы задач, решаемых экспертными системами:
диагностика,
прогнозирование,
идентификация,
управление (в том числе - ТП),
проектирование,
мониторинг,
планирование,
обучение,
поддержка
Основные классы задач, решаемых экспертными системами:
диагностика,
прогнозирование,
идентификация,
управление (в том числе - ТП),
проектирование,
мониторинг,
планирование,
обучение,
поддержка

Слайд 54Области деятельности, где используются экспертные системы:
медицина,
вычислительная техника,
военное дело,
микроэлектроника,
Области деятельности, где используются экспертные системы:
медицина,
вычислительная техника,
военное дело,
микроэлектроника,

Слайд 55Примеры широко известных ЭС:
DENDRAL – разработана в Стэндфордском ун-те в сер. 60-х
Примеры широко известных ЭС:
DENDRAL – разработана в Стэндфордском ун-те в сер. 60-х

Слайд 56MYCIN - разработана в Стэндфордском университете в середине 70-х годов для диагностики
MYCIN - разработана в Стэндфордском университете в середине 70-х годов для диагностики

Слайд 57Контрольные вопросы:
Сущность и назначение Data Mining.
Основные отличия Data Mining от OLAP.
Сущность и
Контрольные вопросы:
Сущность и назначение Data Mining.
Основные отличия Data Mining от OLAP.
Сущность и

Слайд 58Технологии управления знаниями
Понятие «управление знаниями» (УЗ) появилось в середине 90-х годов в
Технологии управления знаниями
Понятие «управление знаниями» (УЗ) появилось в середине 90-х годов в

Слайд 59«Управление знаниями» можно рассматривать и как новое направление в менеджменте, и как
«Управление знаниями» можно рассматривать и как новое направление в менеджменте, и как

Слайд 60Двойственность понятия «управление знаниями»
Двойственность понятия «управление знаниями»
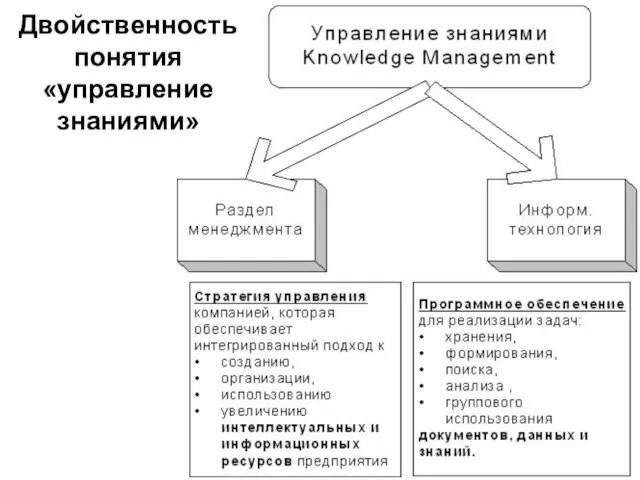
Слайд 61Новизна концепции УЗ заключается в принципиально новой задаче – копить не только
Новизна концепции УЗ заключается в принципиально новой задаче – копить не только

Слайд 62Понятие «знания» трактуется в УЗ очень широко. Под знаниями скорее понимаются информационно-знаниевые
Понятие «знания» трактуется в УЗ очень широко. Под знаниями скорее понимаются информационно-знаниевые

Слайд 63Ключ к УЗ - доставка нужных знаний нужным людям в нужное для
Ключ к УЗ - доставка нужных знаний нужным людям в нужное для
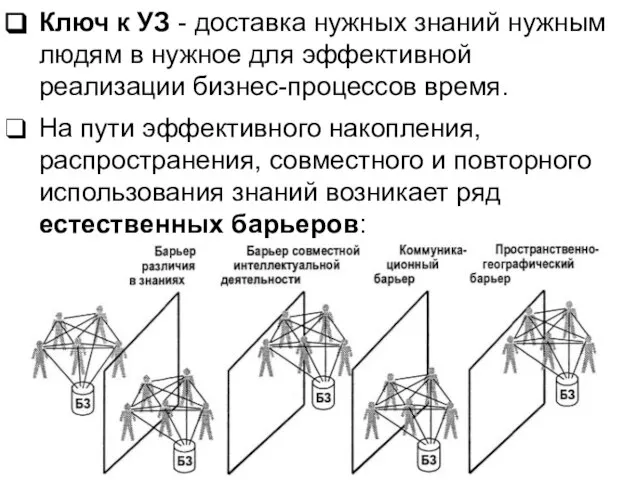
Слайд 64Для преодоления перечисленных барьеров и достижения целей УЗ предназначены корпоративные системы управления
Для преодоления перечисленных барьеров и достижения целей УЗ предназначены корпоративные системы управления

Слайд 65широкий спектр средств (среду) для профессионального общения и обмена знаниями между специалистами,
широкий спектр средств (среду) для профессионального общения и обмена знаниями между специалистами,

Слайд 66В СУЗ интегрируются разнообразные технологии:
электронная почта и Интернет-ресурсы;
системы управления базами данных (СУБД)
В СУЗ интегрируются разнообразные технологии:
электронная почта и Интернет-ресурсы;
системы управления базами данных (СУБД)

Слайд 67СУЗ существенно отличается от ИС организации:
Предназначение ИС – эффективное хранение, обработка и
СУЗ существенно отличается от ИС организации:
Предназначение ИС – эффективное хранение, обработка и

Слайд 68Ввиду относительной новизны проблематики, представления о структуре и составе элементов СУЗ не
Ввиду относительной новизны проблематики, представления о структуре и составе элементов СУЗ не

Слайд 69Концептуальная архитектура системы SEAL
Концептуальная архитектура системы SEAL
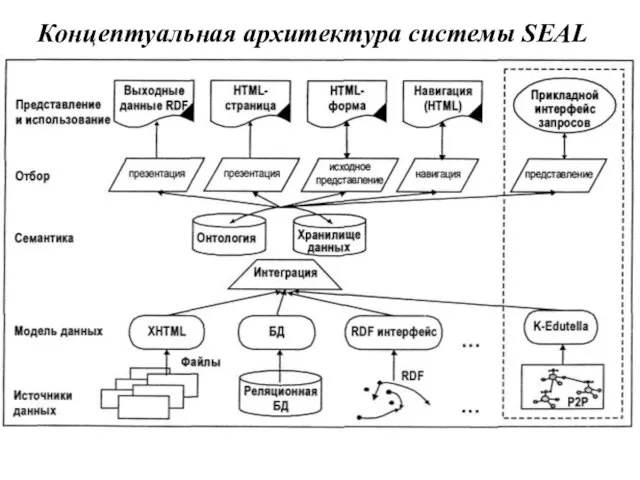
Слайд 70Модели представления знаний
Существует множество обстоятельств, которые затрудняют распространение и обмен знаниями между
Модели представления знаний
Существует множество обстоятельств, которые затрудняют распространение и обмен знаниями между

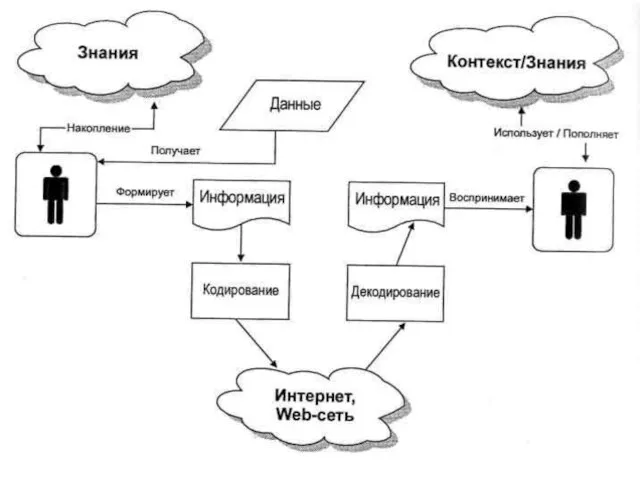
Слайд 72Например, много неструктурированных и полуструктурированных информационных источников доступно в сети Web и
Например, много неструктурированных и полуструктурированных информационных источников доступно в сети Web и

Слайд 73Описанием знаний уже давно занимается дисциплина «Искусственный интеллект» (ИИ), (такие ее разделы,
Описанием знаний уже давно занимается дисциплина «Искусственный интеллект» (ИИ), (такие ее разделы,

Слайд 74Целью УЗ является организация эффективной работы со знаниями (повышение эффективности процессов преобразования
Целью УЗ является организация эффективной работы со знаниями (повышение эффективности процессов преобразования

Слайд 75В настоящее время существуют и развиваются разные методы представления и описания знаний,
В настоящее время существуют и развиваются разные методы представления и описания знаний,

Слайд 76Продукционная модель или модель, основанная на правилах, позволяет представлять знания в виде
Продукционная модель или модель, основанная на правилах, позволяет представлять знания в виде

Слайд 77Семантическая сеть («смысловая» сеть)
Семантика - это наука, устанавливающая отношения между символами и
Семантическая сеть («смысловая» сеть)
Семантика - это наука, устанавливающая отношения между символами и

Слайд 78Следует различать понятия «Семантическая сеть» (англ. Semantic Network) и «Семантическая паутина» (англ.
Следует различать понятия «Семантическая сеть» (англ. Semantic Network) и «Семантическая паутина» (англ.

Слайд 79Чаще всего в семантических сетях используются следующие отношения:
Родо-видовое отношение (транспортное средство –
Чаще всего в семантических сетях используются следующие отношения:
Родо-видовое отношение (транспортное средство –

Слайд 80пространственные (далеко от, близко от, за, под, над…);
временные (раньше, позже, в течение…);
атрибутивные
пространственные (далеко от, близко от, за, под, над…);
временные (раньше, позже, в течение…);
атрибутивные

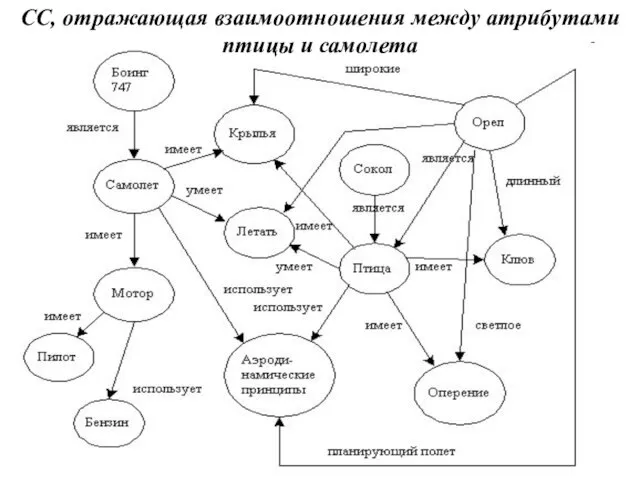
Слайд 81СС, отражающая взаимоотношения между атрибутами птицы и самолета
СС, отражающая взаимоотношения между атрибутами птицы и самолета
Слайд 82Классификации семантических сетей (по Гавриловой)
По количеству типов отношений:
Однородные (с единственным типом отношений).
Неоднородные
Классификации семантических сетей (по Гавриловой)
По количеству типов отношений:
Однородные (с единственным типом отношений).
Неоднородные

Слайд 83Семантическая паутина (Semantic Web)
Концепция организации гипертекста напоминает однородную бинарную СС (страницы –
Семантическая паутина (Semantic Web)
Концепция организации гипертекста напоминает однородную бинарную СС (страницы –

Слайд 84Фрейм (от англ. frame - каркас, рамка)
Это абстрактный образ для представления
Фрейм (от англ. frame - каркас, рамка)
Это абстрактный образ для представления

Слайд 85Модель фрейма является достаточно универсальной, поскольку позволяет отобразить все многообразие знаний о
Модель фрейма является достаточно универсальной, поскольку позволяет отобразить все многообразие знаний о

Слайд 86В качестве значения слота может выступать имя другого фрейма, так образуются сети
В качестве значения слота может выступать имя другого фрейма, так образуются сети

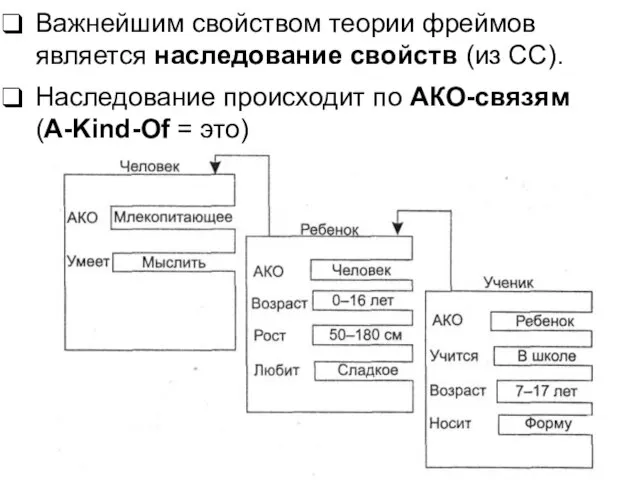
Слайд 87Важнейшим свойством теории фреймов является наследование свойств (из СС).
Наследование происходит по
Важнейшим свойством теории фреймов является наследование свойств (из СС).
Наследование происходит по
Слайд 88Онтология
В последние десятилетия онтологии рассматриваются в качестве наиболее перспективной модели представления знаний
Термин
Онтология
В последние десятилетия онтологии рассматриваются в качестве наиболее перспективной модели представления знаний
Термин

Слайд 89Онтология – это формальное, явное, точное определение (спецификация) совместно используемой концептуализации (Gruber
Онтология – это формальное, явное, точное определение (спецификация) совместно используемой концептуализации (Gruber

Слайд 90Рабочее и более приближенное к УЗ определение [Гаврилова Т.А., Хорошевский]:
Онтологии -
Рабочее и более приближенное к УЗ определение [Гаврилова Т.А., Хорошевский]:
Онтологии -
![Рабочее и более приближенное к УЗ определение [Гаврилова Т.А., Хорошевский]: Онтологии -](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/368741/slide-89.jpg)
Слайд 91Формальная модель онтологии
Под формальной моделью онтологии О будем понимать упорядоченную тройку вида:
О
Формальная модель онтологии
Под формальной моделью онтологии О будем понимать упорядоченную тройку вида:
О

Слайд 92Некоторые граничные случаи:
Пусть R = Ø и F = Ø => онтология
Некоторые граничные случаи:
Пусть R = Ø и F = Ø => онтология

 Презентация на тему Загрязнение водной среды
Презентация на тему Загрязнение водной среды Механизм реализации принципов КУ
Механизм реализации принципов КУ Кислород
Кислород Работа в программе Excel. Курсовая работа студентки 5 курса 3 группы Дмитриевой Анны.
Работа в программе Excel. Курсовая работа студентки 5 курса 3 группы Дмитриевой Анны. ЗНАКОМЬТЕСЬ: БЛУМ Фея и хранительница Огня Дракона. Принцесса планеты Домино. Самая отважная и знаменитая среди фей Winx. Огонь – ее
ЗНАКОМЬТЕСЬ: БЛУМ Фея и хранительница Огня Дракона. Принцесса планеты Домино. Самая отважная и знаменитая среди фей Winx. Огонь – ее  Организация соревнований по эстафетному бегу
Организация соревнований по эстафетному бегу Сентиментализм как литературное направление
Сентиментализм как литературное направление Смута: кризис общества и государства
Смута: кризис общества и государства Маршрутная сеть автобусов
Маршрутная сеть автобусов Политические идеологии
Политические идеологии Технология DITA: обзор возможностей и основные преимущества
Технология DITA: обзор возможностей и основные преимущества Людвиг ван Бетховен
Людвиг ван Бетховен Памятка молодому избирателю
Памятка молодому избирателю Транзисторы. Электронно-дырочная проводимость полупроводников
Транзисторы. Электронно-дырочная проводимость полупроводников Проект «Модернизация региональных систем общего образования на 2011-2013 годы»
Проект «Модернизация региональных систем общего образования на 2011-2013 годы» УЗИ
УЗИ Городской округ Верхняя Пышма
Городской округ Верхняя Пышма  Публичное выступление и презентация
Публичное выступление и презентация Презентация на тему Ультразвук и инфразвук
Презентация на тему Ультразвук и инфразвук Команда
Команда Мейоз
Мейоз Презентация на тему Постоянные магниты
Презентация на тему Постоянные магниты Информационные технологии
Информационные технологии Комбинаторика для начинающих
Комбинаторика для начинающих Презентация на тему Углеводороды
Презентация на тему Углеводороды ZIPTEH.RU
ZIPTEH.RU Мин татарча сөйләшәм
Мин татарча сөйләшәм Презентация на тему Число 6
Презентация на тему Число 6