- Описательная статистика

Содержание
- 2. Математическая статистика Математическая статистика - область науки, изучающая случайные явления, разрабатывающая математические методы систематизации, обработки и
- 3. Переменные Данные (data) представляют собой результаты наблюдений, испытаний, накапливаемые с целью последующего изучения и анализа. Переменная,
- 4. Определения Генеральная совокупность (population) - вся интересующая исследователя совокупность изучаемых объектов. Выборка, выборочная совокупность (sample) -
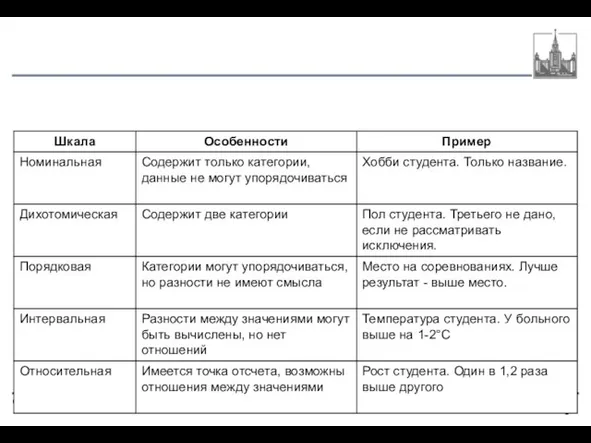
- 5. Измерение явлений Измерение (measurement) означает присвоение чисел характеристикам изучаемых объектов, явлений согласно некоторому правилу. Шкала (scale)
- 6. Типы данных Дискретные данные (discrete data) представляют собой отдельные значения признака, общее число которых конечно либо
- 7. Измерительные шкалы (С. Стивенс) номинативная, или номинальная, или шкала наименований (в том числе дихотомическая) порядковая, или
- 9. 3.1. Измерение центральной тенденции Мода Медиана Среднее
- 10. Постановка задачи Измерение центральной тенденции (measure of central tendency) состоит в выборе одного числа, которое наилучшим
- 11. Мода Мода – наиболее часто встречающееся значение в выборке, наборе данных. Обозначается Мо. Выборка: 5,4 1,2
- 12. Одна ли мода? Если наибольшую частоту имеет два несоседних значения выборки, выборочное распределение называется бимодальным. Если
- 13. Свойства моды 1. Наличие одного или двух крайних значений, сильно отличающихся от остальных, не влияет на
- 14. Вариационный ряд Вариационный ряд - упорядоченные данные, расположенные в порядке возрастания значения признака, либо в порядке
- 15. Ранжирование Ранжирование означает присвоение числам рангов. Ранжирование данных производится после упорядочения. Ранги присваиваются от 1 до
- 16. Медиана Медиана есть значение серединного элемента для набора данных. Обозначается Me. Для нахождения медианы требуется составить
- 17. Пример вычисления медианы Для набора данных из семи чисел: 6 1 3 7 1 7 3
- 18. Свойства медианы 1. Сильно отличающиеся от остальных данных крайние значения не влияют на величину медианы. 2.
- 19. Среднее значение Выборочное среднее будем называть среднее арифметическое выборки, то есть сумму всех значений выборки, деленную
- 20. Пример вычисления среднего Среднее значение является «точкой равновесия». Вычислим среднее для выборки из семи значений: 1
- 21. Свойства среднего 1. Вычисляется только в числовых шкалах. 2. При ее вычислении необходимо использовать все данные.
- 22. Среднее для сгруппированных данных Среднее для сгруппированных данных вычисляется по формуле: где = сумма всех значений
- 23. Пример вычисления среднего Имеются результаты экзамена. Найти среднее значение. xi fi xi·fi 0 1 0 1
- 24. Среднее - еще не значит «лучшее» Пример. В деревне 50 жителей. Среди них 49 человек –
- 25. Три меры и тип шкалы Три меры меры центральной тенденции накладывают ограничения на тип шкалы, в
- 26. Среднее для дихотомической шкалы Среднее может также применяться и для переменной, измеренной в дихотомической шкале. Если
- 27. Какое типическое значение наилучшее? «Наилучшее значение» - это такое значение, что для случайно взятого элемента выборки
- 28. * 3.2. Измерение вариации Размах Дисперсия Стандартное отклонение
- 29. Постановка задачи Рассмотрим три вариационных ряда: а) 999, 1000, 1001 б) 900, 1000, 1100 в) 1,
- 30. Размах (Range) Размах – разность между наибольшим значением набора данных и наименьшим. Пример: Для набора данных
- 31. Подсчет дисперсии в таблице Дисперсию удобно рассчитывать при помощи таблицы. В первом столбце выборка. Второй и
- 32. Вторая формула для дисперсии Дисперсия вычисляет также по равносильной формуле: Считается, что эта формула более пригодна
- 33. Подсчет дисперсии в таблице Пример вычисления дисперсии по второй формуле. В таблице рассчитываются лишь квадраты значений.
- 34. Дисперсия для сгруппированных данных Дисперсия для сгруппированных данных вычисляется по формуле: Вычисления удобно проводить при помощи
- 35. Пример вычисления дисперсии Рассчитаем дисперсию для сгруппированных данных, используя таблицу. В первом столбце – возраст службы,
- 36. Стандартное отклонение Стандартное отклонение вычисляется как корень из дисперсии: Стандартное отклонение имеет исключительную важность для описания
- 37. Интерпретация стандартного отклонения На интервале с границами содержится, по крайней мере, 3/4 всех данных (75%). На
- 38. Стандартное отклонение для нормального закона 68,3% 95,4% 99,7% 13,5%
- 39. Коэффициент вариации Коэффициент вариации вычисляется как отношение стандартного отклонения к среднему: Коэффициент вариации полезен, если: 1.
- 40. Пример для коэффициента вариации Какие данные имеют большую вариацию: имеющие стандартное отклонение 20 при среднем 200
- 42. Скачать презентацию
Слайд 2Математическая статистика
Математическая статистика - область науки, изучающая случайные явления, разрабатывающая математические методы
Математическая статистика
Математическая статистика - область науки, изучающая случайные явления, разрабатывающая математические методы

Слайд 3Переменные
Данные (data) представляют собой результаты наблюдений, испытаний, накапливаемые с целью последующего
Переменные
Данные (data) представляют собой результаты наблюдений, испытаний, накапливаемые с целью последующего

Слайд 4Определения
Генеральная совокупность (population) - вся интересующая исследователя совокупность изучаемых объектов.
Выборка,
Определения
Генеральная совокупность (population) - вся интересующая исследователя совокупность изучаемых объектов.
Выборка,

Слайд 5Измерение явлений
Измерение (measurement) означает присвоение чисел характеристикам изучаемых объектов, явлений согласно некоторому
Измерение явлений
Измерение (measurement) означает присвоение чисел характеристикам изучаемых объектов, явлений согласно некоторому

Слайд 6Типы данных
Дискретные данные (discrete data) представляют собой отдельные значения признака, общее число
Типы данных
Дискретные данные (discrete data) представляют собой отдельные значения признака, общее число

Слайд 7Измерительные шкалы (С. Стивенс)
номинативная, или номинальная, или шкала наименований (в том числе
Измерительные шкалы (С. Стивенс)
номинативная, или номинальная, или шкала наименований (в том числе

Слайд 93.1. Измерение центральной тенденции
Мода
Медиана
Среднее
3.1. Измерение центральной тенденции
Мода
Медиана
Среднее

Слайд 10Постановка задачи
Измерение центральной тенденции (measure of central tendency) состоит в выборе одного
Постановка задачи
Измерение центральной тенденции (measure of central tendency) состоит в выборе одного

Слайд 11Мода
Мода – наиболее часто встречающееся значение в выборке, наборе данных. Обозначается Мо.
Выборка:
Мода
Мода – наиболее часто встречающееся значение в выборке, наборе данных. Обозначается Мо.
Выборка:

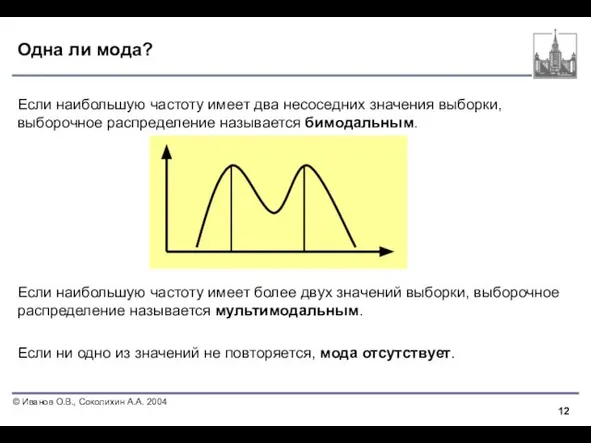
Слайд 12Одна ли мода?
Если наибольшую частоту имеет два несоседних значения выборки, выборочное распределение
Одна ли мода?
Если наибольшую частоту имеет два несоседних значения выборки, выборочное распределение
Слайд 13Свойства моды
1. Наличие одного или двух крайних значений, сильно отличающихся от остальных,
Свойства моды
1. Наличие одного или двух крайних значений, сильно отличающихся от остальных,

Слайд 14Вариационный ряд
Вариационный ряд - упорядоченные данные, расположенные в порядке возрастания значения признака,
Вариационный ряд
Вариационный ряд - упорядоченные данные, расположенные в порядке возрастания значения признака,

Слайд 15Ранжирование
Ранжирование означает присвоение числам рангов. Ранжирование данных производится после упорядочения. Ранги присваиваются
Ранжирование
Ранжирование означает присвоение числам рангов. Ранжирование данных производится после упорядочения. Ранги присваиваются

Слайд 16Медиана
Медиана есть значение серединного элемента для набора данных. Обозначается Me. Для нахождения
Медиана
Медиана есть значение серединного элемента для набора данных. Обозначается Me. Для нахождения

Слайд 17Пример вычисления медианы
Для набора данных из семи чисел:
6 1 3 7 1
Пример вычисления медианы
Для набора данных из семи чисел:
6 1 3 7 1

Слайд 18Свойства медианы
1. Сильно отличающиеся от остальных данных крайние значения не влияют на
Свойства медианы
1. Сильно отличающиеся от остальных данных крайние значения не влияют на

Слайд 19Среднее значение
Выборочное среднее будем называть среднее арифметическое выборки, то есть сумму всех
Среднее значение
Выборочное среднее будем называть среднее арифметическое выборки, то есть сумму всех

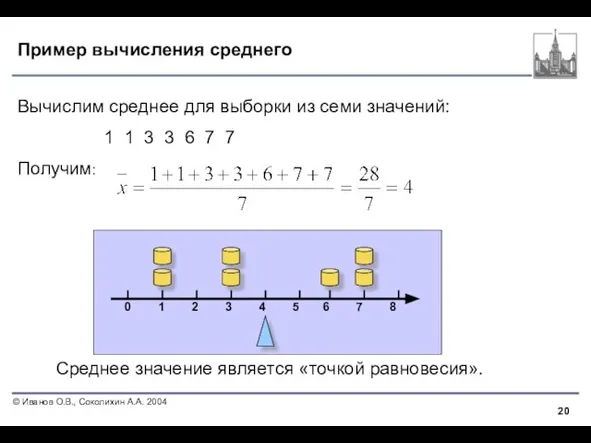
Слайд 20Пример вычисления среднего
Среднее значение является «точкой равновесия».
Вычислим среднее для выборки из семи
Пример вычисления среднего
Среднее значение является «точкой равновесия».
Вычислим среднее для выборки из семи
Слайд 21Свойства среднего
1. Вычисляется только в числовых шкалах.
2. При ее вычислении необходимо использовать
Свойства среднего
1. Вычисляется только в числовых шкалах.
2. При ее вычислении необходимо использовать

Слайд 22Среднее для сгруппированных данных
Среднее для сгруппированных данных вычисляется по формуле:
где = сумма
Среднее для сгруппированных данных
Среднее для сгруппированных данных вычисляется по формуле:
где = сумма

Слайд 23Пример вычисления среднего
Имеются результаты экзамена. Найти среднее значение.
xi fi xi·fi
0 1 0
1 2 2
2 6 12
3 12 36
4 3 12
5 1 5
25 67
Пример вычисления среднего
Имеются результаты экзамена. Найти среднее значение.
xi fi xi·fi
0 1 0
1 2 2
2 6 12
3 12 36
4 3 12
5 1 5
25 67

Слайд 24Среднее - еще не значит «лучшее»
Пример. В деревне 50 жителей. Среди них
Среднее - еще не значит «лучшее»
Пример. В деревне 50 жителей. Среди них

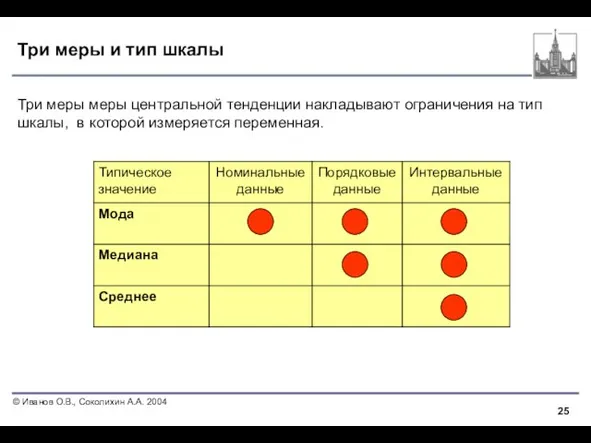
Слайд 25Три меры и тип шкалы
Три меры меры центральной тенденции накладывают ограничения
Три меры и тип шкалы
Три меры меры центральной тенденции накладывают ограничения
Слайд 26Среднее для дихотомической шкалы
Среднее может также применяться и для переменной, измеренной в
Среднее для дихотомической шкалы
Среднее может также применяться и для переменной, измеренной в

Слайд 27Какое типическое значение наилучшее?
«Наилучшее значение» - это такое значение, что для случайно
Какое типическое значение наилучшее?
«Наилучшее значение» - это такое значение, что для случайно

Слайд 28*
3.2. Измерение вариации
Размах
Дисперсия
Стандартное отклонение
*
3.2. Измерение вариации
Размах
Дисперсия
Стандартное отклонение

Слайд 29Постановка задачи
Рассмотрим три вариационных ряда:
а) 999, 1000, 1001
б) 900, 1000, 1100
в) 1,
Постановка задачи
Рассмотрим три вариационных ряда:
а) 999, 1000, 1001
б) 900, 1000, 1100
в) 1,

Слайд 30Размах (Range)
Размах – разность между наибольшим значением набора данных и наименьшим.
Размах (Range)
Размах – разность между наибольшим значением набора данных и наименьшим.

Слайд 31Подсчет дисперсии в таблице
Дисперсию удобно рассчитывать при помощи таблицы.
В первом столбце выборка.
Подсчет дисперсии в таблице
Дисперсию удобно рассчитывать при помощи таблицы.
В первом столбце выборка.

Слайд 32Вторая формула для дисперсии
Дисперсия вычисляет также по равносильной формуле:
Считается, что эта
Вторая формула для дисперсии
Дисперсия вычисляет также по равносильной формуле:
Считается, что эта

Слайд 33Подсчет дисперсии в таблице
Пример вычисления дисперсии по второй формуле. В таблице рассчитываются
Подсчет дисперсии в таблице
Пример вычисления дисперсии по второй формуле. В таблице рассчитываются

Слайд 34Дисперсия для сгруппированных данных
Дисперсия для сгруппированных данных вычисляется по формуле:
Вычисления удобно проводить
Дисперсия для сгруппированных данных
Дисперсия для сгруппированных данных вычисляется по формуле:
Вычисления удобно проводить

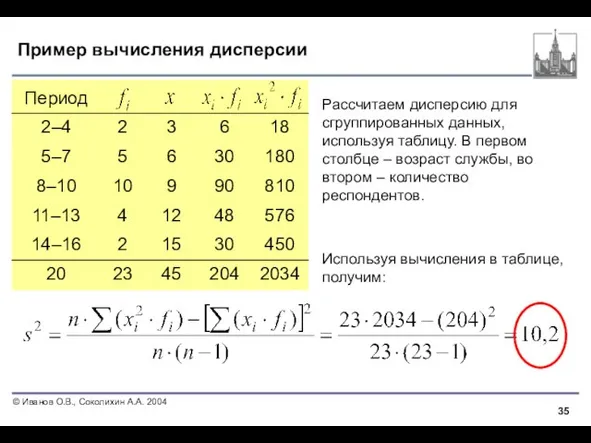
Слайд 35Пример вычисления дисперсии
Рассчитаем дисперсию для сгруппированных данных, используя таблицу. В первом
Пример вычисления дисперсии
Рассчитаем дисперсию для сгруппированных данных, используя таблицу. В первом
Слайд 36Стандартное отклонение
Стандартное отклонение вычисляется как корень из дисперсии:
Стандартное отклонение имеет исключительную важность
Стандартное отклонение
Стандартное отклонение вычисляется как корень из дисперсии:
Стандартное отклонение имеет исключительную важность

Слайд 37Интерпретация стандартного отклонения
На интервале с границами
содержится, по крайней мере, 3/4 всех данных
Интерпретация стандартного отклонения
На интервале с границами
содержится, по крайней мере, 3/4 всех данных

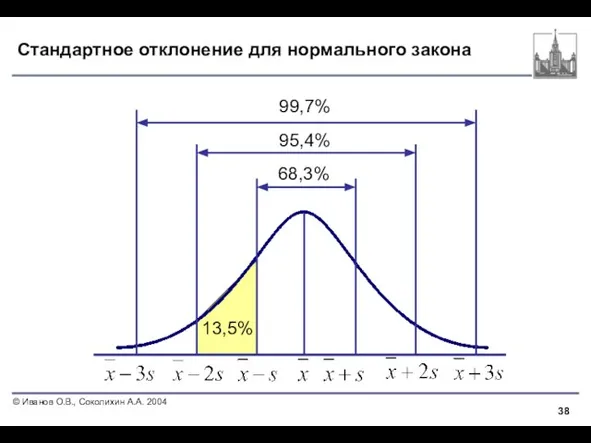
Слайд 38Стандартное отклонение для нормального закона
68,3%
95,4%
99,7%
13,5%
Стандартное отклонение для нормального закона
68,3%
95,4%
99,7%
13,5%
Слайд 39Коэффициент вариации
Коэффициент вариации вычисляется как отношение стандартного отклонения к среднему:
Коэффициент вариации полезен,
Коэффициент вариации
Коэффициент вариации вычисляется как отношение стандартного отклонения к среднему:
Коэффициент вариации полезен,

Слайд 40Пример для коэффициента вариации
Какие данные имеют большую вариацию:
имеющие стандартное отклонение 20
Пример для коэффициента вариации
Какие данные имеют большую вариацию:
имеющие стандартное отклонение 20

 Особенности инвестиционной банковской деятельности в РФ и за рубежом
Особенности инвестиционной банковской деятельности в РФ и за рубежом Исповедь души. Фредерик Шопен (1810-1849)
Исповедь души. Фредерик Шопен (1810-1849) Федеральный Центр Информационно- Образовательных Ресурсов Технико-экономическое обоснование проекта (основные положения)
Федеральный Центр Информационно- Образовательных Ресурсов Технико-экономическое обоснование проекта (основные положения) Понятие об идеале. Идеал человека в религиозном мире
Понятие об идеале. Идеал человека в религиозном мире Материки
Материки Реализация внеурочной деятельности в условиях введения ФГОС общего образования
Реализация внеурочной деятельности в условиях введения ФГОС общего образования Комиссия по развитию некоммерческого сектора и поддержке социально ориентированных НКО
Комиссия по развитию некоммерческого сектора и поддержке социально ориентированных НКО Ввод информации в память компьютера
Ввод информации в память компьютера Удмуртский народный костюм
Удмуртский народный костюм 我们去游泳好吗
我们去游泳好吗 НАИМЕНОВАНИЕ БИЗНЕС ПРОЕКТА СМСП – инициатор проекта
НАИМЕНОВАНИЕ БИЗНЕС ПРОЕКТА СМСП – инициатор проекта Автоматизация звук ш
Автоматизация звук ш Презентация на тему Химический элемент - водород
Презентация на тему Химический элемент - водород ТЕОРИЯ АГЕНТСКИХ ОТНОШЕНИЙ
ТЕОРИЯ АГЕНТСКИХ ОТНОШЕНИЙ Презентация на тему СТРУКТУРА ЭКОСИСТЕМЫ Биология 11 класс
Презентация на тему СТРУКТУРА ЭКОСИСТЕМЫ Биология 11 класс Trace test weapon. Техническое задание
Trace test weapon. Техническое задание Основные требования, предъявляемые к авиационному электрооборудованию
Основные требования, предъявляемые к авиационному электрооборудованию Реализация и применение права. Толкование правовых норм
Реализация и применение права. Толкование правовых норм Программа автоматической корректировки заработной платы
Программа автоматической корректировки заработной платы Презентация на тему Как отвечать на детские вопросы
Презентация на тему Как отвечать на детские вопросы Презентация на тему Стронций
Презентация на тему Стронций У птичьей кормушки
У птичьей кормушки 8 кл. – Максимова Елизавета 9 кл. - Калашникова Елена Смирнова Алина Смирнова Алина Ерофеева Екатерина Ерофеева Екатерина 10 кл. - Сел
8 кл. – Максимова Елизавета 9 кл. - Калашникова Елена Смирнова Алина Смирнова Алина Ерофеева Екатерина Ерофеева Екатерина 10 кл. - Сел ЕГЭ 2012 по физикеСтруктура КИМ ЕГЭ
ЕГЭ 2012 по физикеСтруктура КИМ ЕГЭ Опыт Австралии по привлечению населения к здоровому образу жизни
Опыт Австралии по привлечению населения к здоровому образу жизни Личностно-ориентированное обучение в начальной школе
Личностно-ориентированное обучение в начальной школе Презентация на тему Герои Древней Руси
Презентация на тему Герои Древней Руси Ivan_Constantinovich
Ivan_Constantinovich