- Основы параллельного программирования с использованием MPI Лекция 5

Содержание
- 2. Лекция 5 2008 Аннотация В лекции рассматриваются коллективные обмены. Среди них – широковещательная рассылка. Обсуждаются операции
- 3. План лекции 2008 Особенности коллективных обменов. Широковещательная рассылка. Операции распределения и сбора данных. Операции приведения. Синхронизация.
- 4. Коллективные обмены 2008
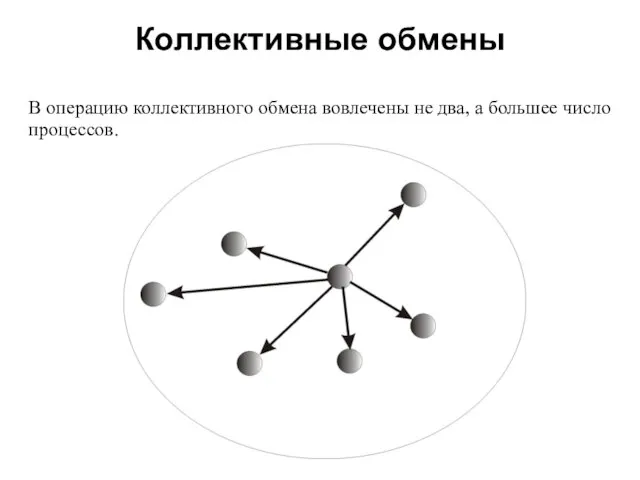
- 5. Коллективные обмены 2008 В операцию коллективного обмена вовлечены не два, а большее число процессов.
- 6. Коллективные обмены 2008 Общая характеристика коллективных обменов: коллективные обмены не могут взаимодействовать с двухточечными. Коллективная передача
- 7. Коллективные обмены 2008 Виды коллективных обменов: широковещательная передача - выполняется от одного процесса ко всем; распределение
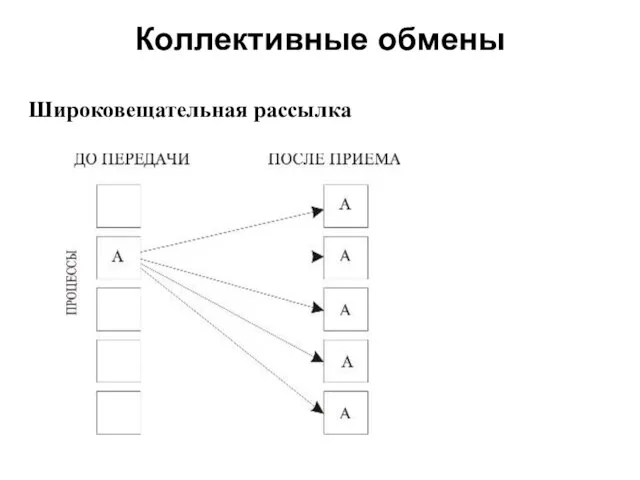
- 8. Коллективные обмены 2008 Широковещательная рассылка
- 9. Коллективные обмены 2008 Широковещательная рассылка выполняется подпрограммой: int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root,
- 10. Коллективные обмены 2008 Пример 1 использования широковещательной рассылки #include "mpi.h" #include int main(int argc,char *argv[]) {
- 11. Коллективные обмены 2008 MPI_Bcast(&data, count, MPI_BYTE, 0, MPI_COMM_WORLD); printf("received: %s\n", data); } MPI_Finalize(); return 0; }
- 12. Коллективные обмены 2008 Пример 2 использования широковещательной пересылки #include "mpi.h" #include int main(int argc, char *argv[])
- 13. Коллективные обмены 2008 printf("Enter a, b, n\n"); scanf("%f %f %i", &a, &b, &n); MPI_Bcast(&a, count, MPI_FLOAT,
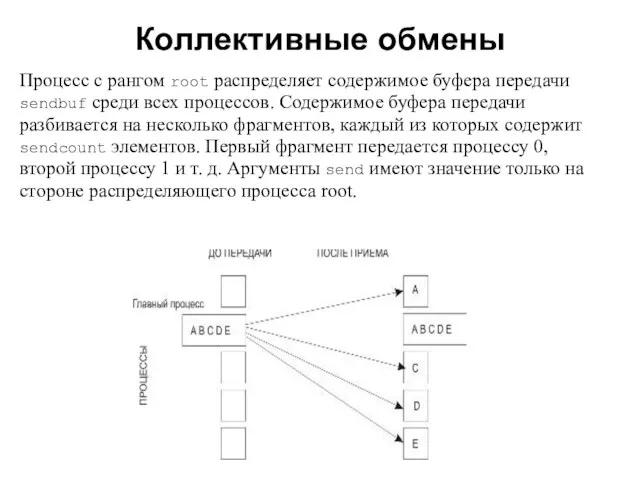
- 14. Коллективные обмены 2008 Распределение данных int MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *rcvbuf, int rcvcount,
- 15. Коллективные обмены 2008 Процесс с рангом root распределяет содержимое буфера передачи sendbuf среди всех процессов. Содержимое
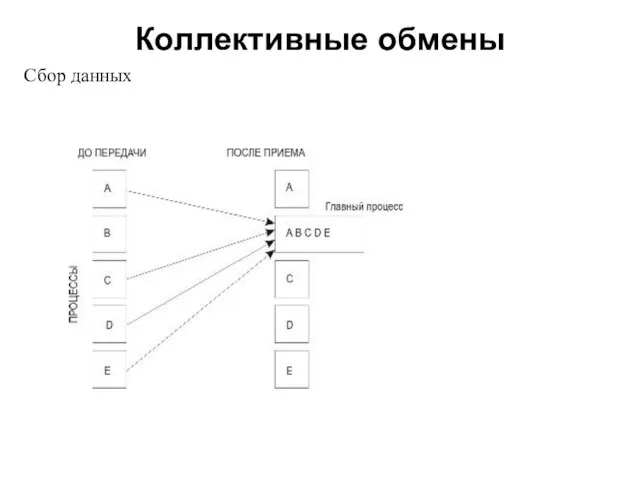
- 16. Коллективные обмены 2008 Сбор данных Сбор данных от остальных процессов в буфер главной задачи выполняется подпрограммой:
- 17. Коллективные обмены 2008 Порядок склейки определяется рангами процессов, то есть в результирующем наборе после данных от
- 18. Коллективные обмены 2008 Сбор данных
- 19. Коллективные обмены 2008 Сбор данных от всех процессов и распределение их всем процессам: int MPI_Allgather(void *sendbuf,
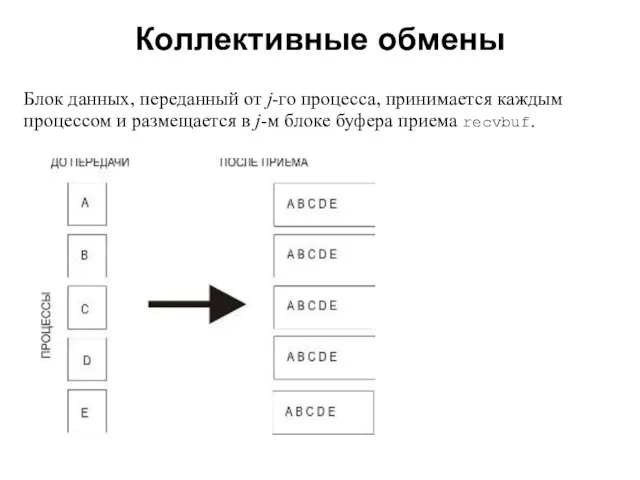
- 20. Коллективные обмены 2008 Блок данных, переданный от j-го процесса, принимается каждым процессом и размещается в j-м
- 21. Коллективные обмены 2008 Операция приведения Операция приведения, результат которой передается одному процессу int MPI_Reduce(void *buf, void
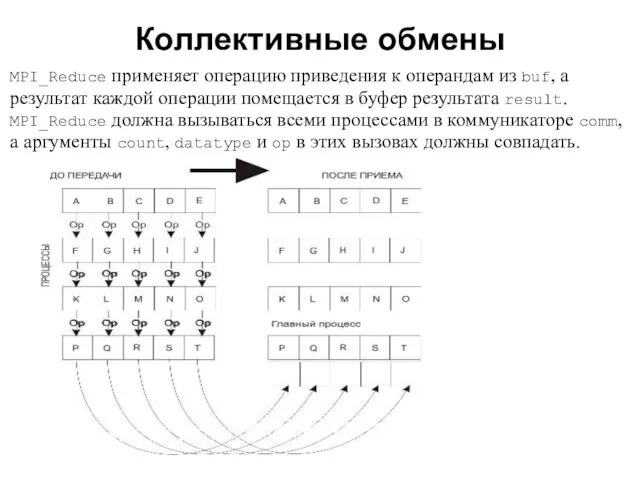
- 22. Коллективные обмены 2008 MPI_Reduce применяет операцию приведения к операндам из buf, а результат каждой операции помещается
- 23. Коллективные обмены 2008 Пример 1 использования операции редукции В этой программе сначала создается подгруппа, состоящая из
- 24. Коллективные обмены 2008 #include "mpi.h" #include int main(int argc,char *argv[]) { int myrank, i; int count
- 25. Коллективные обмены 2008 if(myrank != MPI_UNDEFINED) { MPI_Reduce(&sendbuf, &recvbuf, count, MPI_INT, MPI_SUM, root, subcomm); if(myrank ==
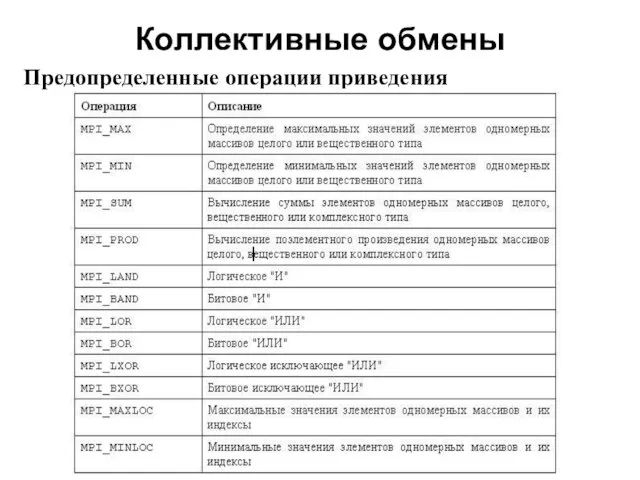
- 26. Коллективные обмены 2008 Предопределенные операции приведения
- 27. Коллективные обмены 2008 Допускается определение собственных операций приведения. Для этого используется подпрограмма: int MPI_Op_create(MPI_User_function *function, int
- 28. Коллективные обмены 2008 Описание типа пользовательской функции выглядит следующим образом: typedef void (MPI_User_function)(void *a, void *b,
- 29. Коллективные обмены 2008 После завершения операций приведения пользовательская функция должна быть удалена. Удаление пользовательской функции выполняется
- 30. Коллективные обмены 2008 Пример использования операции приведения: вычисление числа π методом Монте-Карло. Два файла pi_compute.c и
- 31. Коллективные обмены 2008 srandom (mytid); avepi = 0; for (i = 0; i homepi = dboard(trials);
- 32. Коллективные обмены 2008 #include #define sqr(x) ((x)*(x)) float mc_trials(int trials) { double x_coord, y_coord, pi, r;
- 33. Коллективные обмены 2008 pi = 4.0 * (double)score/(double)trials; return(pi); }
- 34. Коллективные обмены 2008 Операция сканирования Операции сканирования (частичной редукции) выполняются следующей подпрограммой: int MPI_Scan(void *sendbuf, void
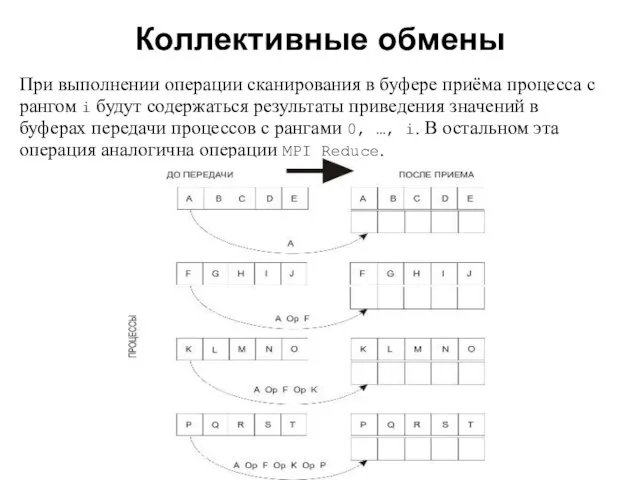
- 35. Коллективные обмены 2008 При выполнении операции сканирования в буфере приёма процесса с рангом i будут содержаться
- 36. Коллективные обмены 2008 Векторная операция распределения данных Векторная подпрограмма распределения данных: int MPI_Scatterv(void *sendbuf, int *sendcounts,
- 37. Коллективные обмены 2008 Входные параметры: displs - целочисленный массив, длина которого равна количеству процессов в коммуникаторе.
- 38. Коллективные обмены 2008 Векторная операция сбора данных Сбор данных от всех процессов в заданном коммуникаторе и
- 39. Коллективные обмены 2008 Пересылка данных по схеме «каждый - всем» int MPI_Alltoall(void *sendbuf, int sendcount, MPI_Datatype
- 40. Коллективные обмены 2008 Векторными версиями MPI_Allgather и MPI_Alltoall являются подпрограммы MPI_Allgatherv и MPI_Alltoallv. Векторные операции позволяют
- 41. Коллективные обмены 2008 Синхронизация Синхронизация с помощью «барьера» выполняется с помощью подпрограммы: int MPI_Barrier(MPI_Comm comm) MPI_Barrier(comm,
- 42. 2008 В этой лекции мы рассмотрели: особенности и свойства коллективных обменов; различные операции коллективного обмена –
- 43. 2008 Задания для самостоятельной работы Решения следует высылать по электронной почте: [email protected]
- 44. 2008 Задания для самостоятельной работы Составьте алгоритм и напишите параллельную программу вычисления произведения матрицы на вектор.
- 45. 2008 Задания для самостоятельной работы Напишите параллельную программу вычисления произведения матрицы на матрицу. Используйте ленточную декомпозицию
- 47. Скачать презентацию
Слайд 2Лекция 5
2008
Аннотация
В лекции рассматриваются коллективные обмены. Среди них – широковещательная рассылка. Обсуждаются операции
Лекция 5
2008
Аннотация
В лекции рассматриваются коллективные обмены. Среди них – широковещательная рассылка. Обсуждаются операции

Слайд 3План лекции
2008
Особенности коллективных обменов.
Широковещательная рассылка.
Операции распределения и сбора
План лекции
2008
Особенности коллективных обменов.
Широковещательная рассылка.
Операции распределения и сбора

Слайд 4Коллективные обмены
2008
Коллективные обмены
2008

Слайд 5Коллективные обмены
2008
В операцию коллективного обмена вовлечены не два, а большее число процессов.
Коллективные обмены
2008
В операцию коллективного обмена вовлечены не два, а большее число процессов.
Слайд 6Коллективные обмены
2008
Общая характеристика коллективных обменов:
коллективные обмены не могут взаимодействовать с
Коллективные обмены
2008
Общая характеристика коллективных обменов:
коллективные обмены не могут взаимодействовать с

Слайд 7Коллективные обмены
2008
Виды коллективных обменов:
широковещательная передача - выполняется от одного процесса
Коллективные обмены
2008
Виды коллективных обменов:
широковещательная передача - выполняется от одного процесса

Слайд 8Коллективные обмены
2008
Широковещательная рассылка
Коллективные обмены
2008
Широковещательная рассылка
Слайд 9Коллективные обмены
2008
Широковещательная рассылка выполняется подпрограммой:
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int
Коллективные обмены
2008
Широковещательная рассылка выполняется подпрограммой:
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int

Слайд 10Коллективные обмены
2008
Пример 1 использования широковещательной рассылки
#include "mpi.h"
#include
int main(int argc,char *argv[])
{
char
Коллективные обмены
2008
Пример 1 использования широковещательной рассылки
#include "mpi.h"
#include
int main(int argc,char *argv[])
{
char

Слайд 11Коллективные обмены
2008
MPI_Bcast(&data, count, MPI_BYTE, 0, MPI_COMM_WORLD);
printf("received: %s\n", data);
}
MPI_Finalize();
return
Коллективные обмены
2008
MPI_Bcast(&data, count, MPI_BYTE, 0, MPI_COMM_WORLD);
printf("received: %s\n", data);
}
MPI_Finalize();
return

Слайд 12Коллективные обмены
2008
Пример 2 использования широковещательной пересылки
#include "mpi.h"
#include
int main(int argc, char *argv[])
{
Коллективные обмены
2008
Пример 2 использования широковещательной пересылки
#include "mpi.h"
#include
int main(int argc, char *argv[])
{

Слайд 13Коллективные обмены
2008
printf("Enter a, b, n\n");
scanf("%f %f %i", &a, &b, &n);
MPI_Bcast(&a, count, MPI_FLOAT,
Коллективные обмены
2008
printf("Enter a, b, n\n");
scanf("%f %f %i", &a, &b, &n);
MPI_Bcast(&a, count, MPI_FLOAT,

Слайд 14Коллективные обмены
2008
Распределение данных
int MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *rcvbuf, int
Коллективные обмены
2008
Распределение данных
int MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *rcvbuf, int

Слайд 15Коллективные обмены
2008
Процесс с рангом root распределяет содержимое буфера передачи sendbuf среди всех
Коллективные обмены
2008
Процесс с рангом root распределяет содержимое буфера передачи sendbuf среди всех
Слайд 16Коллективные обмены
2008
Сбор данных
Сбор данных от остальных процессов в буфер главной задачи выполняется
Коллективные обмены
2008
Сбор данных
Сбор данных от остальных процессов в буфер главной задачи выполняется

Слайд 17Коллективные обмены
2008
Порядок склейки определяется рангами процессов, то есть в результирующем наборе после
Коллективные обмены
2008
Порядок склейки определяется рангами процессов, то есть в результирующем наборе после

Слайд 18Коллективные обмены
2008
Сбор данных
Коллективные обмены
2008
Сбор данных
Слайд 19Коллективные обмены
2008
Сбор данных от всех процессов и распределение их всем процессам:
int MPI_Allgather(void
Коллективные обмены
2008
Сбор данных от всех процессов и распределение их всем процессам:
int MPI_Allgather(void

Слайд 20Коллективные обмены
2008
Блок данных, переданный от j-го процесса, принимается каждым процессом и размещается
Коллективные обмены
2008
Блок данных, переданный от j-го процесса, принимается каждым процессом и размещается
Слайд 21Коллективные обмены
2008
Операция приведения
Операция приведения, результат которой передается одному процессу
int MPI_Reduce(void *buf, void
Коллективные обмены
2008
Операция приведения
Операция приведения, результат которой передается одному процессу
int MPI_Reduce(void *buf, void

Слайд 22Коллективные обмены
2008
MPI_Reduce применяет операцию приведения к операндам из buf, а результат каждой
Коллективные обмены
2008
MPI_Reduce применяет операцию приведения к операндам из buf, а результат каждой
Слайд 23Коллективные обмены
2008
Пример 1 использования операции редукции
В этой программе сначала создается подгруппа, состоящая
Коллективные обмены
2008
Пример 1 использования операции редукции
В этой программе сначала создается подгруппа, состоящая

Слайд 24Коллективные обмены
2008
#include "mpi.h"
#include
int main(int argc,char *argv[])
{
int myrank, i;
int count
Коллективные обмены
2008
#include "mpi.h"
#include
int main(int argc,char *argv[])
{
int myrank, i;
int count
![Коллективные обмены 2008 #include "mpi.h" #include int main(int argc,char *argv[]) { int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/464286/slide-23.jpg)
Слайд 25Коллективные обмены
2008
if(myrank != MPI_UNDEFINED)
{
MPI_Reduce(&sendbuf, &recvbuf, count, MPI_INT, MPI_SUM, root, subcomm);
if(myrank == root)
Коллективные обмены
2008
if(myrank != MPI_UNDEFINED)
{
MPI_Reduce(&sendbuf, &recvbuf, count, MPI_INT, MPI_SUM, root, subcomm);
if(myrank == root)

Слайд 26Коллективные обмены
2008
Предопределенные операции приведения
Коллективные обмены
2008
Предопределенные операции приведения
Слайд 27Коллективные обмены
2008
Допускается определение собственных операций приведения. Для этого используется подпрограмма:
int MPI_Op_create(MPI_User_function *function,
Коллективные обмены
2008
Допускается определение собственных операций приведения. Для этого используется подпрограмма:
int MPI_Op_create(MPI_User_function *function,

Слайд 28Коллективные обмены
2008
Описание типа пользовательской функции выглядит следующим образом:
typedef void (MPI_User_function)(void *a, void
Коллективные обмены
2008
Описание типа пользовательской функции выглядит следующим образом:
typedef void (MPI_User_function)(void *a, void

Слайд 29Коллективные обмены
2008
После завершения операций приведения пользовательская функция должна быть удалена.
Удаление пользовательской функции
Коллективные обмены
2008
После завершения операций приведения пользовательская функция должна быть удалена.
Удаление пользовательской функции

Слайд 30Коллективные обмены
2008
Пример использования операции приведения: вычисление числа π методом Монте-Карло. Два файла
Коллективные обмены
2008
Пример использования операции приведения: вычисление числа π методом Монте-Карло. Два файла

Слайд 31Коллективные обмены
2008
srandom (mytid);
avepi = 0;
for (i = 0; i < rounds; i++)
Коллективные обмены
2008
srandom (mytid);
avepi = 0;
for (i = 0; i < rounds; i++)

Слайд 32Коллективные обмены
2008
#include
#define sqr(x) ((x)*(x))
float mc_trials(int trials)
{
double x_coord, y_coord, pi, r;
Коллективные обмены
2008
#include
#define sqr(x) ((x)*(x))
float mc_trials(int trials)
{
double x_coord, y_coord, pi, r;

Слайд 33Коллективные обмены
2008
pi = 4.0 * (double)score/(double)trials;
return(pi);
}
Коллективные обмены
2008
pi = 4.0 * (double)score/(double)trials;
return(pi);
}

Слайд 34Коллективные обмены
2008
Операция сканирования
Операции сканирования (частичной редукции) выполняются следующей подпрограммой:
int MPI_Scan(void *sendbuf, void
Коллективные обмены
2008
Операция сканирования
Операции сканирования (частичной редукции) выполняются следующей подпрограммой:
int MPI_Scan(void *sendbuf, void

Слайд 35Коллективные обмены
2008
При выполнении операции сканирования в буфере приёма процесса с рангом i
Коллективные обмены
2008
При выполнении операции сканирования в буфере приёма процесса с рангом i
Слайд 36Коллективные обмены
2008
Векторная операция распределения данных
Векторная подпрограмма распределения данных:
int MPI_Scatterv(void *sendbuf, int *sendcounts,
Коллективные обмены
2008
Векторная операция распределения данных
Векторная подпрограмма распределения данных:
int MPI_Scatterv(void *sendbuf, int *sendcounts,

Слайд 37Коллективные обмены
2008
Входные параметры:
displs - целочисленный массив, длина которого равна количеству
процессов
Коллективные обмены
2008
Входные параметры:
displs - целочисленный массив, длина которого равна количеству
процессов

Слайд 38Коллективные обмены
2008
Векторная операция сбора данных
Сбор данных от всех процессов в заданном коммуникаторе
Коллективные обмены
2008
Векторная операция сбора данных
Сбор данных от всех процессов в заданном коммуникаторе

Слайд 39Коллективные обмены
2008
Пересылка данных по схеме «каждый - всем»
int MPI_Alltoall(void *sendbuf, int sendcount, MPI_Datatype
Коллективные обмены
2008
Пересылка данных по схеме «каждый - всем»
int MPI_Alltoall(void *sendbuf, int sendcount, MPI_Datatype

Слайд 40Коллективные обмены
2008
Векторными версиями MPI_Allgather и MPI_Alltoall являются подпрограммы MPI_Allgatherv и MPI_Alltoallv.
Векторные операции
Коллективные обмены
2008
Векторными версиями MPI_Allgather и MPI_Alltoall являются подпрограммы MPI_Allgatherv и MPI_Alltoallv.
Векторные операции

Слайд 41Коллективные обмены
2008
Синхронизация
Синхронизация с помощью «барьера» выполняется с помощью подпрограммы:
int MPI_Barrier(MPI_Comm comm)
MPI_Barrier(comm, ierr)
Синхронизация
Коллективные обмены
2008
Синхронизация
Синхронизация с помощью «барьера» выполняется с помощью подпрограммы:
int MPI_Barrier(MPI_Comm comm)
MPI_Barrier(comm, ierr)
Синхронизация

Слайд 422008
В этой лекции мы рассмотрели:
особенности и свойства коллективных обменов;
различные
2008
В этой лекции мы рассмотрели:
особенности и свойства коллективных обменов;
различные

Слайд 432008
Задания для самостоятельной работы
Решения следует высылать по электронной почте:
[email protected]
2008
Задания для самостоятельной работы
Решения следует высылать по электронной почте:
[email protected]

Слайд 442008
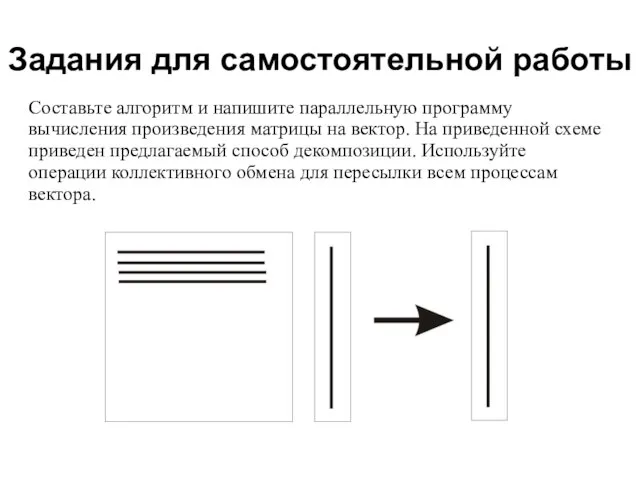
Задания для самостоятельной работы
Составьте алгоритм и напишите параллельную программу вычисления произведения матрицы
2008
Задания для самостоятельной работы
Составьте алгоритм и напишите параллельную программу вычисления произведения матрицы
Слайд 452008
Задания для самостоятельной работы
Напишите параллельную программу вычисления произведения матрицы на матрицу. Используйте
2008
Задания для самостоятельной работы
Напишите параллельную программу вычисления произведения матрицы на матрицу. Используйте

 История развития генетики
История развития генетики Основы дизайн-проектирования (оригами). Формообразование (пиксель арт в объеме). Работы учащихся
Основы дизайн-проектирования (оригами). Формообразование (пиксель арт в объеме). Работы учащихся Тема мини-проекта Авторы: Руководитель:
Тема мини-проекта Авторы: Руководитель: Химия и Жизнь
Химия и Жизнь Предварительная программа Предварительная программа 7 октября 2009 года, среда. 09:00 Вступительное заседание. 10:00 Кофе-брейк и открыти
Предварительная программа Предварительная программа 7 октября 2009 года, среда. 09:00 Вступительное заседание. 10:00 Кофе-брейк и открыти Презентация на тему Правила поведения пассажиров на остановке и в транспорте
Презентация на тему Правила поведения пассажиров на остановке и в транспорте Мои достижения
Мои достижения Orientierung in der Stadt
Orientierung in der Stadt  Клеточная стенка
Клеточная стенка Картофельная запеканка с курицей сыром и грибами
Картофельная запеканка с курицей сыром и грибами Тема 1. Металлы и сплавы
Тема 1. Металлы и сплавы Функции права
Функции права Презентация на тему Свойства арифметического корня П-ОЙ СТЕПЕНИ
Презентация на тему Свойства арифметического корня П-ОЙ СТЕПЕНИ  Полевые транзисторы с изолированным затвором
Полевые транзисторы с изолированным затвором На что способен наш мозг...
На что способен наш мозг... Effective business meetings
Effective business meetings  Железы внутренней секреции
Железы внутренней секреции Выпуск – 2004 (Самый поющий выпуск)
Выпуск – 2004 (Самый поющий выпуск) Расчёт количества теплоты, поглощаемого или выделяемого в различных процессах.
Расчёт количества теплоты, поглощаемого или выделяемого в различных процессах. Бородинский хлеб
Бородинский хлеб Права ребенка в школе: модели их защиты
Права ребенка в школе: модели их защиты Русский портрет XVIII века
Русский портрет XVIII века «Международное сотрудничество в сфере уголовного судопроизводства » _
«Международное сотрудничество в сфере уголовного судопроизводства » _ Тема: «Страницы истории 20-30 годов»
Тема: «Страницы истории 20-30 годов» НОРМАТИВНО-ПРАВОВАЯ БАЗА
НОРМАТИВНО-ПРАВОВАЯ БАЗА Презентация на тему City (Город)
Презентация на тему City (Город)  Материалы, конструкции и технологии ИЖД
Материалы, конструкции и технологии ИЖД Презентация образовательных программ МБУ ДО ЦЭКиТ 2018-2019 учебный год
Презентация образовательных программ МБУ ДО ЦЭКиТ 2018-2019 учебный год