- Prezentatsia

Содержание
- 2. Области применения многопроцессорных систем 1 Обработка транзакций в режиме реального времени (OLTP, online transaction processing) Создание
- 3. Архитектура многопроцессорных вычислительных систем 2
- 4. Многопроцессорные системы с общей памятью 3 ЦП ЦП ЦП ОБЩАЯ ФИЗИЧЕСКАЯ ПАМЯТЬ I/O подсистема
- 5. Многопроцессорные системы с раздельной памятью 4 ЦП ОП ЦП ОП I/O подсистема R1 R1
- 6. Многопроцессорные системы гибридного типа 5, Память Проц Проц Проц Проц Память Проц Проц Проц Проц Память
- 7. Кластерные вычислительные системы ЦП ЦП ЦП ЦП ЦП ЦП
- 8. Компьютерные сети ПК Маршрутизатор ПК Маршрутизатор Канал связи Линия связи Линия связи Линия связи
- 9. Коммуникационные среды В самом общем смысле архитектуру компьютера можно определить как способ соединения компьютеров между собой,
- 10. Транспьютеры
- 11. Специализированные языки параллельного программирования
- 12. Библиотеки и системы программирования для высокоуровневых языков
- 13. Принципы построения параллельных алгоритмов. Основные методы построения параллельных программ Основные типы параллелизма, используемые для построения параллельных
- 14. Алгоритмический параллелизм Алгоритмическим параллелизмом называется параллелизм, который выявляется путем выделения в данном алгоритме тех фрагментов, которые
- 15. Геометрический параллелизм Геометрический параллелизм допускает разбиение данных на части по числу процессоров, при котором обработку каждой
- 16. Конвейерный параллелизм Первый каменщик (процессор) укладывает первый ряд кирпичей, второй каменщик - второй ряд, и т.д.
- 17. Параллелизм типа «коллективное решение» Метод предполагает, что неизвестно, с какой скоростью какие процессоры работают. Существует один
- 18. Статическая и динамическая балансировка загрузки процессоров Статическая балансировка выполняется до начала выполнения параллельного приложения. Алгоритм динамической
- 19. Проблема тупиков Тупик - ситуация, в которой один или несколько процессов ожидают какого-либо события, которое никогда
- 20. Недетерминированность параллельных программ Недетерминированность процессов происходит от того, что они обмениваются данными в непредсказуемые моменты времени.
- 21. Эффективность, ускорение параллельных программ. Ускорением параллельного алгоритма (Sp), называют отношение времени выполнения алгоритма на одном процессоре
- 22. Оценка времени выполнения алгоритма Степенью параллелизма алгоритма называют число действий алгоритма, которые могут выполняться одновременно, каждое
- 23. Внутренний параллелизм Внутренние свойства алгоритма, не зависящие от вида и особенностей вычислительных систем. На разных этапах
- 24. Закон Амдаля Закон Амдаля характеризует одну из самых серьезных проблем в области параллельного программирования - алгоритмов
- 25. Параллельная программа как ансамбль взаимодействующих последовательных процессов Поскольку параллельная программа — это множество взаимодействующих последовательных процессов,
- 26. Основные методы синхронизации 27
- 27. Синхронизация с помощью передачи сообщений 28
- 28. Виды каналов передачи данных 29
- 29. Синхронный и асинхронный обмен сообщениями 30
- 30. Защита разделяемых данных Для организации разделения ресурсов между несколькими потоками необходимо иметь возможность: определения доступности запрашиваемых
- 31. Семафор. Реализация семафора с помощью традиционных операций. Семафоры были введены в эксплуатацию Эдсжером Дейкстрой в 1965
- 32. Критическая секция. Монитор, Очереди заданий. Критическая секция — объект синхронизации потоков, позволяющий предотвратить одновременное выполнение некоторого
- 33. Описание поля процессоров 34 Структура микрокоманды Соответствие между адресами РЗУ и регистрами микропроцессора Значения полей MA
- 34. Описание поля процессоров 34 Поле SRC Поле SH Поле ALU Поле CCX
- 35. Описание поля процессоров 34 Поле DST Поле WM Поле CC Поле CHA
- 36. Виртуальные и реальные процессоры Виртуальным процессором называется процесс сервера баз данных. Виртуальный процессор можно сравнить с
- 37. Параллельное и конкурентное выполнение процессов 36
- 38. Физические и виртуальные каналы Виртуальные каналы — это устойчивые пути следования трафика, создаваемые в сети с
- 39. Физические и виртуальные топологии В MPI топология представляет собой механизм сопоставления процессам, принадлежащим группе, альтернативных по
- 40. Режимы передачи данных Режим передачи (transmissionmode) определяет возможные направления передачи сигналов между узлами сети. Существуют три
- 41. 40 Измерение времени На время выполнения программы влияют следующие факторы: Ввод исходной информации в программу. Качество
- 42. 41 Отладка программы Отладка — этап разработки компьютерной программы, на котором обнаруживают, локализуют и устраняют ошибки.
- 43. 42 Выполнение процессов на общей памяти (треды) Поток выполнения / тред — наименьшая единица обработки, исполнение
- 44. 43 Использование семафоров для синхронизации тредов Семафоры традиционно использовались для синхронизации процессов, обращающихся к разделяемым данным.
- 45. 44 Примеры математических моделей применение которых требуют суперкомпьютерных вычислений Кратко разработку и программную реализацию моделирования задач
- 46. 45 Кинетически согласованные разностные схемы Многие из проблем, связанных с использованием многопроцессорных вычислительных систем для решения
- 47. 46 Компиляция и выполнение параллельных программ под управлением PARIX Для компиляции программных модулей используется команда: px
- 48. 47 Уровни оптимизации выполняемого программного кода Решение проблемы быстрой и недорогой разработки эффективного программного обеспечения для
- 49. 48 Заголовочные файлы и библиотеки передачи данных, порождения процессов и доступа к семафорам Send, Recv –
- 50. 49 Запуск и прекращение выполнения программы. Утилита nrm. Сервер epxd Для запуска PARIX-приложения используется команда run.
- 51. 50 Анализ результатов выполнения параллельной программы. Распределение и освобождение разделов Команда run занимает указанный раздел, так
- 52. 51 Заголовочные файлы и библиотеке MPI. Версии MPI: lam, mpich. Версии Mpi для Unix. Версия Mpi
- 53. 52 Мониторинг выполнения параллельной программы Обычно для целей трассировки в исследуемую программу встраиваются "профилировочные" вызовы, которые
- 54. 53 Некоторые средства Unix (rsh, ssh, bash, ping, scp) их использование для подготовки, выполнения и отладки
- 55. Работа в режиме удаленного доступа 54 Клиент Сервер БД База мета-данных Файловые команды Блоки данных Модель
- 56. Работа в режиме удаленного доступа 54 Клиент Сервер БД и БМД SQL запросы Результаты запросов Модель
- 57. Статическая и динамическая балансировка нагрузки 55
- 58. Диффузная балансировка нагрузки 56 Диффузная балансировка нагрузки является методом динамической балансировки загрузки процессоров, где перераспределение вычислительной
- 59. Централизованное и децентрализованное управление вычислениями 57
- 60. Построение алгоритмов динамической балансировки загрузки на основе технологии «клиент-сервер» Нагрузка на объединенные между собой серверы распределяется
- 61. Особенности обеспечения балансировки загрузки процессоров при использовании неструктурированных сеток Проблема балансировки загрузки при решении задач на
- 62. Спектральная матрица графа. Вектора Фидлера 60
- 63. Иерархические алгоритмы разбиения больших графов Алгоритм Кернигана-Лина: Формирование множества пар вершин для перестановки. Построение новых вариантов
- 64. Методы визуализации двух и трехмерных сеточных данных Под двухмерной визуализацией понимается отображение данных на плоскости в
- 65. 63 Сжатие сеточных данных, заданных на структурированных и неструктурированных сетках. Работоспособность системы распределенной визуализации трехмерных скалярных
- 67. Скачать презентацию
Слайд 2Области применения многопроцессорных систем
1
Обработка транзакций в режиме реального времени (OLTP, online transaction
Области применения многопроцессорных систем
1
Обработка транзакций в режиме реального времени (OLTP, online transaction

Слайд 3Архитектура многопроцессорных вычислительных систем
2
Архитектура многопроцессорных вычислительных систем
2

Слайд 4Многопроцессорные системы с общей памятью
3
ЦП
ЦП
ЦП
ОБЩАЯ ФИЗИЧЕСКАЯ ПАМЯТЬ
I/O
подсистема
Многопроцессорные системы с общей памятью
3
ЦП
ЦП
ЦП
ОБЩАЯ ФИЗИЧЕСКАЯ ПАМЯТЬ
I/O
подсистема
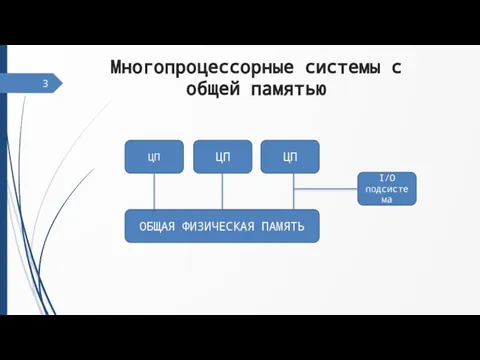
Слайд 5Многопроцессорные системы с раздельной памятью
4
ЦП
ОП
ЦП
ОП
I/O подсистема
R1
R1
Многопроцессорные системы с раздельной памятью
4
ЦП
ОП
ЦП
ОП
I/O подсистема
R1
R1
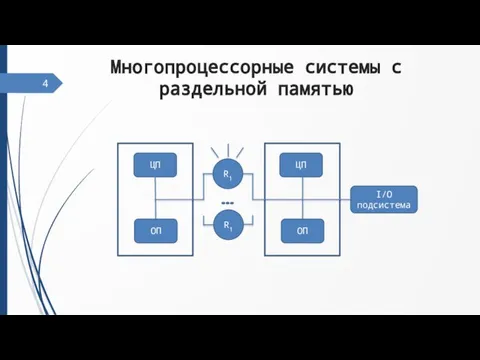
Слайд 6Многопроцессорные системы гибридного типа
5,
Память
Проц
Проц
Проц
Проц
Память
Проц
Проц
Проц
Проц
Память
Проц
Проц
Проц
Проц
Коммуникационная сеть
Переферия
Многопроцессорные системы гибридного типа
5,
Память
Проц
Проц
Проц
Проц
Память
Проц
Проц
Проц
Проц
Память
Проц
Проц
Проц
Проц
Коммуникационная сеть
Переферия
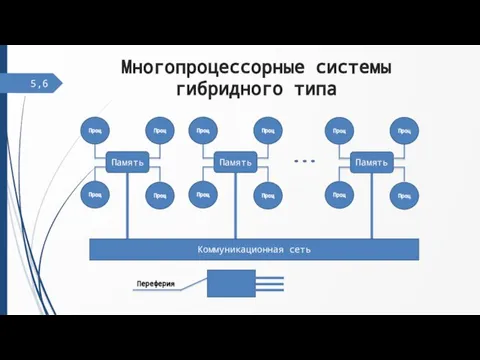
Слайд 7Кластерные вычислительные системы
ЦП
ЦП
ЦП
ЦП
ЦП
ЦП
Кластерные вычислительные системы
ЦП
ЦП
ЦП
ЦП
ЦП
ЦП
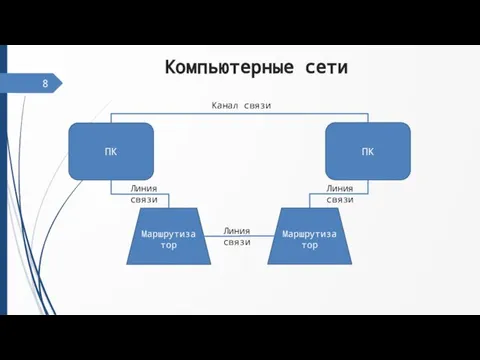
Слайд 8Компьютерные сети
ПК
Маршрутизатор
ПК
Маршрутизатор
Канал связи
Линия связи
Линия связи
Линия связи
Компьютерные сети
ПК
Маршрутизатор
ПК
Маршрутизатор
Канал связи
Линия связи
Линия связи
Линия связи
Слайд 9Коммуникационные среды
В самом общем смысле архитектуру компьютера можно определить как способ соединения
Коммуникационные среды
В самом общем смысле архитектуру компьютера можно определить как способ соединения

Слайд 10Транспьютеры
Транспьютеры

Слайд 11Специализированные языки параллельного программирования
Специализированные языки параллельного программирования

Слайд 12Библиотеки и системы программирования для высокоуровневых языков
Библиотеки и системы программирования для высокоуровневых языков

Слайд 13Принципы построения параллельных алгоритмов. Основные методы построения параллельных программ
Основные типы параллелизма, используемые
Принципы построения параллельных алгоритмов. Основные методы построения параллельных программ
Основные типы параллелизма, используемые

Слайд 14Алгоритмический параллелизм
Алгоритмическим параллелизмом называется параллелизм, который выявляется путем выделения в данном алгоритме
Алгоритмический параллелизм
Алгоритмическим параллелизмом называется параллелизм, который выявляется путем выделения в данном алгоритме

Слайд 15Геометрический параллелизм
Геометрический параллелизм допускает разбиение данных на части по числу процессоров, при
Геометрический параллелизм
Геометрический параллелизм допускает разбиение данных на части по числу процессоров, при

Слайд 16Конвейерный параллелизм
Первый каменщик (процессор) укладывает первый ряд кирпичей, второй каменщик - второй
Конвейерный параллелизм
Первый каменщик (процессор) укладывает первый ряд кирпичей, второй каменщик - второй

Слайд 17Параллелизм типа «коллективное решение»
Метод предполагает, что неизвестно, с какой скоростью какие процессоры
Параллелизм типа «коллективное решение»
Метод предполагает, что неизвестно, с какой скоростью какие процессоры

Слайд 18Статическая и динамическая балансировка загрузки процессоров
Статическая балансировка выполняется до начала выполнения параллельного
Статическая и динамическая балансировка загрузки процессоров
Статическая балансировка выполняется до начала выполнения параллельного

Слайд 19Проблема тупиков
Тупик - ситуация, в которой один или несколько процессов ожидают какого-либо
Проблема тупиков
Тупик - ситуация, в которой один или несколько процессов ожидают какого-либо

Слайд 20Недетерминированность параллельных программ
Недетерминированность процессов происходит от того, что они обмениваются данными в
Недетерминированность параллельных программ
Недетерминированность процессов происходит от того, что они обмениваются данными в

Слайд 21Эффективность, ускорение параллельных программ.
Ускорением параллельного алгоритма (Sp), называют отношение времени
Эффективность, ускорение параллельных программ.
Ускорением параллельного алгоритма (Sp), называют отношение времени

Слайд 22Оценка времени выполнения алгоритма
Степенью параллелизма алгоритма называют число действий алгоритма, которые могут
Оценка времени выполнения алгоритма
Степенью параллелизма алгоритма называют число действий алгоритма, которые могут

Слайд 23Внутренний параллелизм
Внутренние свойства алгоритма, не зависящие от вида и особенностей вычислительных систем.
На
Внутренний параллелизм
Внутренние свойства алгоритма, не зависящие от вида и особенностей вычислительных систем.
На

Слайд 24Закон Амдаля
Закон Амдаля характеризует одну из самых серьезных проблем в области параллельного
Закон Амдаля
Закон Амдаля характеризует одну из самых серьезных проблем в области параллельного

Слайд 25Параллельная программа как ансамбль взаимодействующих последовательных процессов
Поскольку параллельная программа — это множество
Параллельная программа как ансамбль взаимодействующих последовательных процессов
Поскольку параллельная программа — это множество

Слайд 26Основные методы синхронизации
27
Основные методы синхронизации
27

Слайд 27Синхронизация с помощью передачи сообщений
28
Синхронизация с помощью передачи сообщений
28

Слайд 28Виды каналов передачи данных
29
Виды каналов передачи данных
29

Слайд 29Синхронный и асинхронный обмен сообщениями
30
Синхронный и асинхронный обмен сообщениями
30

Слайд 30Защита разделяемых данных
Для организации разделения ресурсов между несколькими потоками необходимо иметь возможность:
определения
Защита разделяемых данных
Для организации разделения ресурсов между несколькими потоками необходимо иметь возможность:
определения

Слайд 31Семафор. Реализация семафора с помощью традиционных операций.
Семафоры были введены в эксплуатацию Эдсжером
Семафор. Реализация семафора с помощью традиционных операций.
Семафоры были введены в эксплуатацию Эдсжером

Слайд 32Критическая секция. Монитор, Очереди заданий.
Критическая секция — объект синхронизации потоков, позволяющий предотвратить
Критическая секция. Монитор, Очереди заданий.
Критическая секция — объект синхронизации потоков, позволяющий предотвратить

Слайд 33Описание поля процессоров
34
Структура микрокоманды
Соответствие между адресами РЗУ и регистрами микропроцессора
Значения полей MA
Описание поля процессоров
34
Структура микрокоманды
Соответствие между адресами РЗУ и регистрами микропроцессора
Значения полей MA

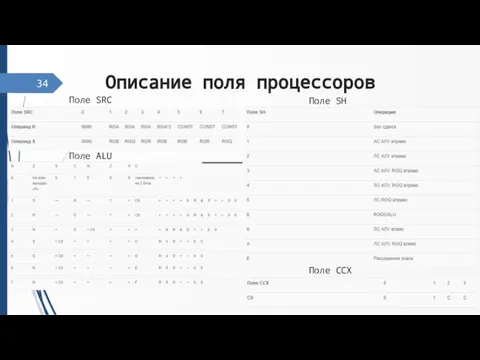
Слайд 34Описание поля процессоров
34
Поле SRC
Поле SH
Поле ALU
Поле CCX
Описание поля процессоров
34
Поле SRC
Поле SH
Поле ALU
Поле CCX
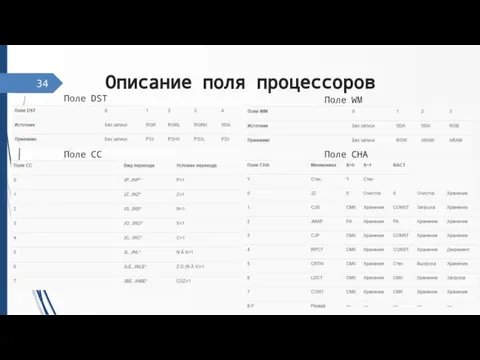
Слайд 35Описание поля процессоров
34
Поле DST
Поле WM
Поле CC
Поле CHA
Описание поля процессоров
34
Поле DST
Поле WM
Поле CC
Поле CHA
Слайд 36Виртуальные и реальные процессоры
Виртуальным процессором называется процесс сервера баз данных. Виртуальный процессор
Виртуальные и реальные процессоры
Виртуальным процессором называется процесс сервера баз данных. Виртуальный процессор

Слайд 37Параллельное и конкурентное выполнение процессов
36
Параллельное и конкурентное выполнение процессов
36

Слайд 38Физические и виртуальные каналы
Виртуальные каналы — это устойчивые пути следования трафика, создаваемые
Физические и виртуальные каналы
Виртуальные каналы — это устойчивые пути следования трафика, создаваемые

Слайд 39Физические и виртуальные топологии
В MPI топология представляет собой механизм сопоставления процессам, принадлежащим
Физические и виртуальные топологии
В MPI топология представляет собой механизм сопоставления процессам, принадлежащим

Слайд 40Режимы передачи данных
Режим передачи (transmissionmode) определяет возможные направления передачи сигналов между узлами
Режимы передачи данных
Режим передачи (transmissionmode) определяет возможные направления передачи сигналов между узлами

Слайд 4140
Измерение времени
На время выполнения программы влияют следующие факторы:
Ввод исходной информации в программу.
Качество
40
Измерение времени
На время выполнения программы влияют следующие факторы:
Ввод исходной информации в программу.
Качество

Слайд 4241
Отладка программы
Отладка — этап разработки компьютерной программы, на котором обнаруживают, локализуют и
41
Отладка программы
Отладка — этап разработки компьютерной программы, на котором обнаруживают, локализуют и

Слайд 4342
Выполнение процессов на общей памяти (треды)
Поток выполнения / тред — наименьшая единица
42
Выполнение процессов на общей памяти (треды)
Поток выполнения / тред — наименьшая единица

Слайд 4443
Использование семафоров для синхронизации тредов
Семафоры традиционно использовались для синхронизации процессов, обращающихся к
43
Использование семафоров для синхронизации тредов
Семафоры традиционно использовались для синхронизации процессов, обращающихся к

Слайд 4544
Примеры математических моделей применение которых требуют суперкомпьютерных вычислений
Кратко разработку и программную реализацию
44
Примеры математических моделей применение которых требуют суперкомпьютерных вычислений
Кратко разработку и программную реализацию

Слайд 4645
Кинетически согласованные разностные схемы
Многие из проблем, связанных с использованием многопроцессорных вычислительных систем
45
Кинетически согласованные разностные схемы
Многие из проблем, связанных с использованием многопроцессорных вычислительных систем

Слайд 4746
Компиляция и выполнение параллельных программ под
управлением PARIX
Для компиляции программных модулей используется команда:
px
46
Компиляция и выполнение параллельных программ под
управлением PARIX
Для компиляции программных модулей используется команда:
px

Слайд 4847
Уровни оптимизации выполняемого программного кода
Решение проблемы быстрой и недорогой разработки эффективного программного
47
Уровни оптимизации выполняемого программного кода
Решение проблемы быстрой и недорогой разработки эффективного программного

Слайд 4948
Заголовочные файлы и библиотеки передачи данных, порождения процессов и доступа к семафорам
Send,
48
Заголовочные файлы и библиотеки передачи данных, порождения процессов и доступа к семафорам
Send,

Слайд 5049
Запуск и прекращение выполнения программы. Утилита nrm. Сервер epxd
Для запуска PARIX-приложения используется
49
Запуск и прекращение выполнения программы. Утилита nrm. Сервер epxd
Для запуска PARIX-приложения используется

Слайд 5150
Анализ результатов выполнения параллельной программы. Распределение и освобождение разделов
Команда run занимает указанный
50
Анализ результатов выполнения параллельной программы. Распределение и освобождение разделов
Команда run занимает указанный

Слайд 5251
Заголовочные файлы и библиотеке MPI. Версии MPI: lam, mpich. Версии Mpi для
51
Заголовочные файлы и библиотеке MPI. Версии MPI: lam, mpich. Версии Mpi для

Слайд 5352
Мониторинг выполнения параллельной программы
Обычно для целей трассировки в исследуемую программу встраиваются "профилировочные"
52
Мониторинг выполнения параллельной программы
Обычно для целей трассировки в исследуемую программу встраиваются "профилировочные"

Слайд 5453
Некоторые средства Unix (rsh, ssh, bash, ping, scp) их использование для подготовки,
53
Некоторые средства Unix (rsh, ssh, bash, ping, scp) их использование для подготовки,

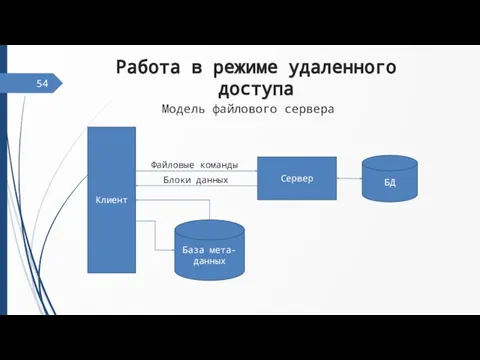
Слайд 55Работа в режиме удаленного доступа
54
Клиент
Сервер
БД
База мета-данных
Файловые команды
Блоки данных
Модель файлового сервера
Работа в режиме удаленного доступа
54
Клиент
Сервер
БД
База мета-данных
Файловые команды
Блоки данных
Модель файлового сервера
Слайд 56Работа в режиме удаленного доступа
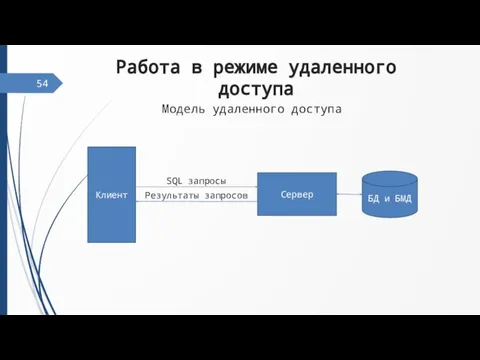
54
Клиент
Сервер
БД и БМД
SQL запросы
Результаты запросов
Модель удаленного доступа
Работа в режиме удаленного доступа
54
Клиент
Сервер
БД и БМД
SQL запросы
Результаты запросов
Модель удаленного доступа
Слайд 57Статическая и динамическая балансировка нагрузки
55
Статическая и динамическая балансировка нагрузки
55

Слайд 58Диффузная балансировка нагрузки
56
Диффузная балансировка нагрузки является методом динамической балансировки загрузки процессоров, где
Диффузная балансировка нагрузки
56
Диффузная балансировка нагрузки является методом динамической балансировки загрузки процессоров, где

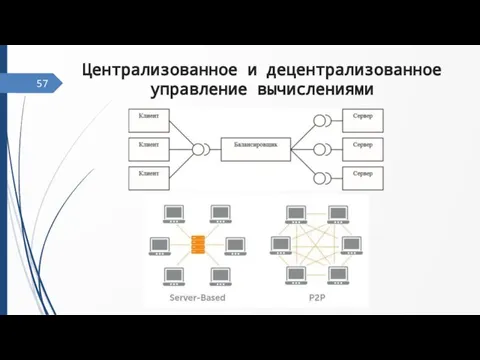
Слайд 59Централизованное и децентрализованное управление вычислениями
57
Централизованное и децентрализованное управление вычислениями
57
Слайд 60Построение алгоритмов динамической балансировки загрузки на основе технологии «клиент-сервер»
Нагрузка на объединенные между
Построение алгоритмов динамической балансировки загрузки на основе технологии «клиент-сервер»
Нагрузка на объединенные между

Слайд 61Особенности обеспечения балансировки загрузки процессоров при использовании неструктурированных сеток
Проблема балансировки загрузки при
Особенности обеспечения балансировки загрузки процессоров при использовании неструктурированных сеток
Проблема балансировки загрузки при

Слайд 62Спектральная матрица графа. Вектора Фидлера
60
Спектральная матрица графа. Вектора Фидлера
60

Слайд 63Иерархические алгоритмы разбиения больших графов
Алгоритм Кернигана-Лина:
Формирование множества пар вершин для перестановки.
Построение новых
Иерархические алгоритмы разбиения больших графов
Алгоритм Кернигана-Лина:
Формирование множества пар вершин для перестановки.
Построение новых

Слайд 64Методы визуализации двух и трехмерных сеточных данных
Под двухмерной визуализацией понимается отображение данных
Методы визуализации двух и трехмерных сеточных данных
Под двухмерной визуализацией понимается отображение данных

Слайд 6563
Сжатие сеточных данных, заданных на структурированных и неструктурированных сетках.
Работоспособность системы распределенной визуализации
63
Сжатие сеточных данных, заданных на структурированных и неструктурированных сетках.
Работоспособность системы распределенной визуализации

 Презентация на тему Итоговая аттестация по русскому языку
Презентация на тему Итоговая аттестация по русскому языку Презентация на тему Компас Строение компаса
Презентация на тему Компас Строение компаса  Фовизм
Фовизм Известные имена. Софья Ковалевская
Известные имена. Софья Ковалевская Автоматическое составление обзорных (сводных) рефератов новостных сюжетов
Автоматическое составление обзорных (сводных) рефератов новостных сюжетов Презентация на тему мое школьное расписание My school timetable
Презентация на тему мое школьное расписание My school timetable Surgical Instruments
Surgical Instruments Антивірусні програмні засоби
Антивірусні програмні засоби Как пополнить Ваш счет и вывести средства
Как пополнить Ваш счет и вывести средства Научно-исследовательская деятельность. Введение
Научно-исследовательская деятельность. Введение Оценка рисков финансовых транзакций в реальном времени
Оценка рисков финансовых транзакций в реальном времени Презентация на тему На севере Европы 3 (класс) Плешаков
Презентация на тему На севере Европы 3 (класс) Плешаков Федеральный эксперимент по апробации новой формы государственной (итоговой) аттестации обучающихся, освоивших образовательные п
Федеральный эксперимент по апробации новой формы государственной (итоговой) аттестации обучающихся, освоивших образовательные п Ульяновский государственный университет. Инженерно-физический факультет высоких технологий
Ульяновский государственный университет. Инженерно-физический факультет высоких технологий Галерея помещиков Мёртвые души
Галерея помещиков Мёртвые души Легендарный лабиринт Кносского дворца
Легендарный лабиринт Кносского дворца Viola
Viola Чистота русской разговорной речи
Чистота русской разговорной речи Suffixes in English
Suffixes in English  Личность и коллектив как объект управления
Личность и коллектив как объект управления Урок – игра «Парикмахер»
Урок – игра «Парикмахер» Правила работы в Google
Правила работы в Google Готический стиль в архитектуре
Готический стиль в архитектуре dao_pukha
dao_pukha Проектная технология
Проектная технология Архитектура XVI века
Архитектура XVI века Сувенирный бутик. Бизнес – проект
Сувенирный бутик. Бизнес – проект Франц Йозеф Галль (1758—1828)
Франц Йозеф Галль (1758—1828)