- Теорія ймовірностей і математична статистика: описові статистичні показники

Содержание
- 2. Перевірка статистичних гіпотез Статистичні висновки – це висновки про ВСЮ генеральну сукупність зроблені на основі вибіркових
- 3. Вступ : типи даних Кількісні дані: дискретні, неперервні. Денна кількість відвідувачів: 23, 34, 25, 30, 45.
- 4. Вступ : типи даних Просторів дані та часові ряди. Просторові дані – дані зібрані в один
- 5. Зображення даних: гістограма Гістограма: Графічне зображення даних, що на осі Х визначає самі значення даних, чи
- 6. Гістограма – як групувати? Групування полегшує розуміння великих масивів даних, але зменшує їх інформативність. В залежності
- 7. Показники середнього (типового значення) Середнє значення: Середнє зважене: Середнє геометричне: Медіана – значення, що має порядковий
- 8. Показники середнього - який використовувати? Для нормально розподілених даних (симетричних) найкращою мірою буде середнє значення, причому,в
- 9. Показники розкиду даних K-тий персентиль – це значення, що відділяє k% даних від решти. 0-ий персентиль
- 10. Показники варіації даних Стандартне відхилення (середньоквадратичне відхилення): В Excel – це функція СТОТКЛОН чи STDEV. Дисперсія
- 11. Стандартне відхилення при нормальному розподілі При нормальному розподілі фактично всі дані лежать в проміжку середнє +/-
- 12. Показники зв’язку: коваріація Коваріація – це показник зв’язку між двома змінними: Якщо X та Y рухаються
- 13. Показники зв’язку: коефіцієнт кореляції Коефіцієт кореляції: Якщо X та Y рухаються в одному напрямку і мають
- 15. Скачать презентацию
Слайд 2Перевірка статистичних гіпотез
Статистичні висновки – це висновки про ВСЮ генеральну сукупність
Перевірка статистичних гіпотез
Статистичні висновки – це висновки про ВСЮ генеральну сукупність
Слайд 3Вступ : типи даних
Кількісні дані: дискретні, неперервні.
Денна кількість відвідувачів: 23, 34,
Вступ : типи даних
Кількісні дані: дискретні, неперервні.
Денна кількість відвідувачів: 23, 34,

Слайд 4Вступ : типи даних
Просторів дані та часові ряди.
Просторові дані –
Вступ : типи даних
Просторів дані та часові ряди.
Просторові дані –

Слайд 5Зображення даних: гістограма
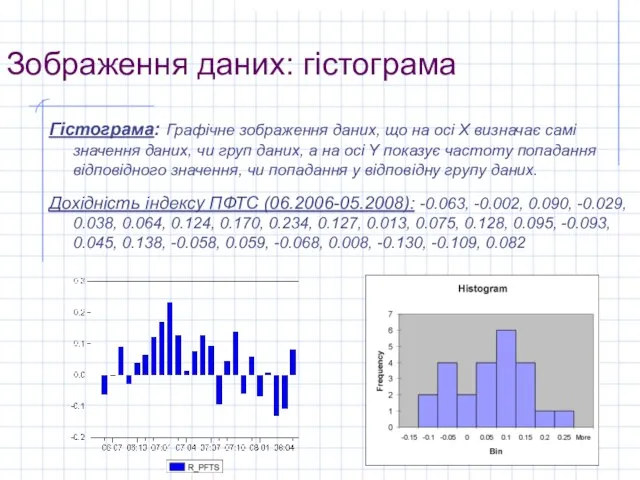
Гістограма: Графічне зображення даних, що на осі Х визначає
Зображення даних: гістограма
Гістограма: Графічне зображення даних, що на осі Х визначає
Слайд 6Гістограма – як групувати?
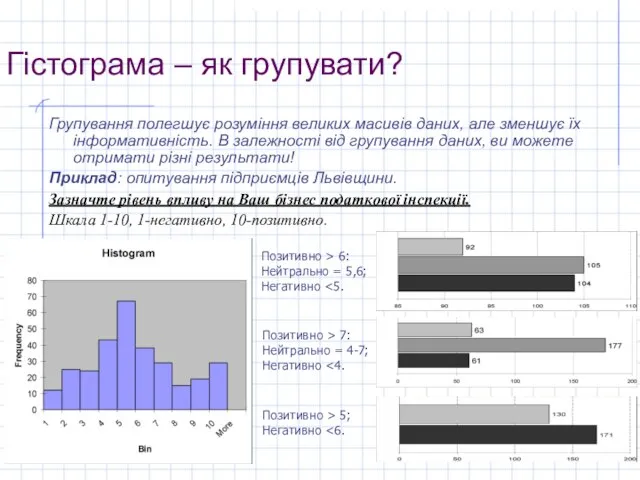
Групування полегшує розуміння великих масивів даних, але зменшує
Гістограма – як групувати?
Групування полегшує розуміння великих масивів даних, але зменшує
Слайд 7Показники середнього (типового значення)
Середнє значення:
Середнє зважене:
Середнє геометричне:
Медіана – значення, що має порядковий
Показники середнього (типового значення)
Середнє значення:
Середнє зважене:
Середнє геометричне:
Медіана – значення, що має порядковий

Слайд 8Показники середнього - який використовувати?
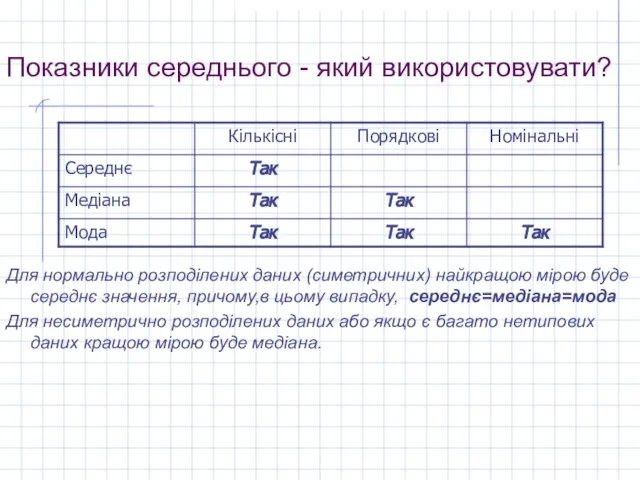
Для нормально розподілених даних (симетричних) найкращою мірою буде
Показники середнього - який використовувати?
Для нормально розподілених даних (симетричних) найкращою мірою буде
Слайд 9Показники розкиду даних
K-тий персентиль – це значення, що відділяє k% даних від
Показники розкиду даних
K-тий персентиль – це значення, що відділяє k% даних від

Слайд 10Показники варіації даних
Стандартне відхилення (середньоквадратичне відхилення):
В Excel – це функція СТОТКЛОН чи
Показники варіації даних
Стандартне відхилення (середньоквадратичне відхилення):
В Excel – це функція СТОТКЛОН чи

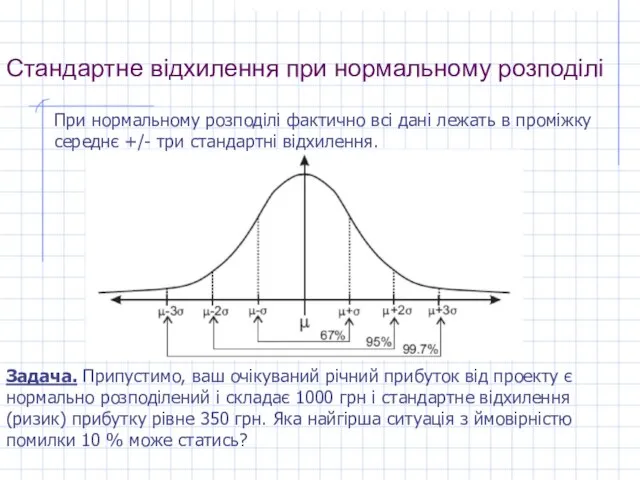
Слайд 11Стандартне відхилення при нормальному розподілі
При нормальному розподілі фактично всі дані лежать в
Стандартне відхилення при нормальному розподілі
При нормальному розподілі фактично всі дані лежать в
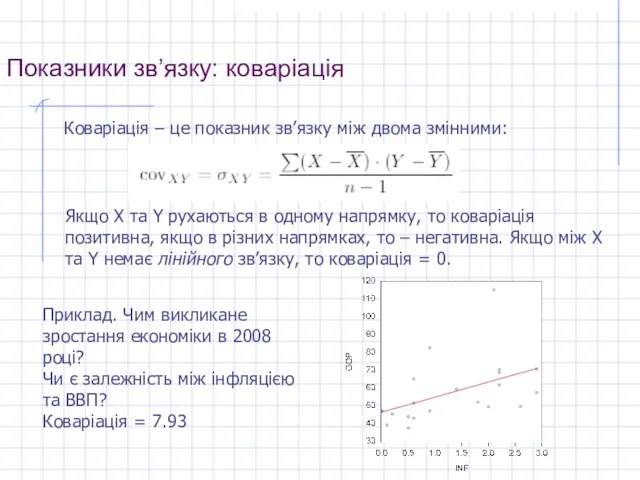
Слайд 12Показники зв’язку: коваріація
Коваріація – це показник зв’язку між двома змінними:
Якщо X
Показники зв’язку: коваріація
Коваріація – це показник зв’язку між двома змінними:
Якщо X
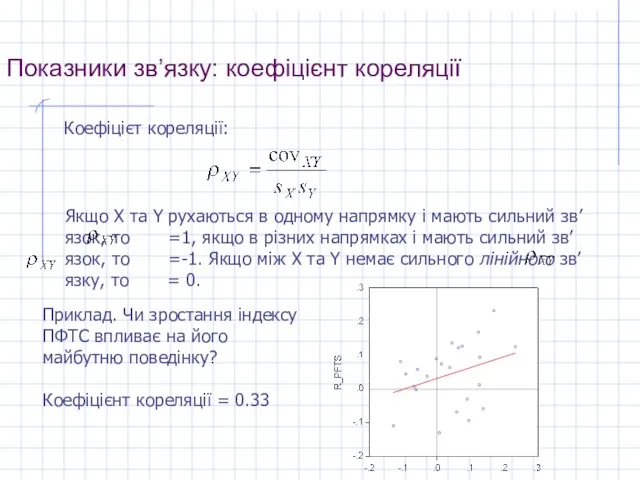
Слайд 13Показники зв’язку: коефіцієнт кореляції
Коефіцієт кореляції:
Якщо X та Y рухаються в одному
Показники зв’язку: коефіцієнт кореляції
Коефіцієт кореляції:
Якщо X та Y рухаються в одному
 Презентация на тему Глобальное потепление
Презентация на тему Глобальное потепление  Шкала электромагнитных излучений
Шкала электромагнитных излучений Нашествие с Востока на Русь
Нашествие с Востока на Русь Пример построения системы управления машиностроительным производством
Пример построения системы управления машиностроительным производством Государственная поддержка агрострахования и мелиорации земель
Государственная поддержка агрострахования и мелиорации земель 2012 год. Цементный рынок: как жить в эпоху дефицита?
2012 год. Цементный рынок: как жить в эпоху дефицита? ТЕМА: Пластик- удобно, выгодно, губительно!
ТЕМА: Пластик- удобно, выгодно, губительно! Технологическое нормирование эксплуатационной работы железных дорог
Технологическое нормирование эксплуатационной работы железных дорог Швидке читання - запорука успішного навчання
Швидке читання - запорука успішного навчання Презентация на тему Франция
Презентация на тему Франция МАФ из современных материалов для детских площадок
МАФ из современных материалов для детских площадок Материалы для подготовки к контрольной работе по теме Греция
Материалы для подготовки к контрольной работе по теме Греция Вредные привычки у детей. Консультация для родителей
Вредные привычки у детей. Консультация для родителей Анализ препятствий на пути расширения доступа к услугам по ДКТ и внедрения системы супервизии
Анализ препятствий на пути расширения доступа к услугам по ДКТ и внедрения системы супервизии БИОГРАФИЯ Лавриненкова Владимира Дмитриевича Родился 15 Мая 1919 года в деревне Птахино, Смоленской области, в семье крестьянина. В 1
БИОГРАФИЯ Лавриненкова Владимира Дмитриевича Родился 15 Мая 1919 года в деревне Птахино, Смоленской области, в семье крестьянина. В 1 Добыча полезных ископаемых на Луне из реголита
Добыча полезных ископаемых на Луне из реголита Социальная политика государства
Социальная политика государства 20161109_prezentatsiya_1
20161109_prezentatsiya_1 Презентация на тему Русской речи государь по прозванию Словарь
Презентация на тему Русской речи государь по прозванию Словарь Народная игрушка в развитии дошкольников
Народная игрушка в развитии дошкольников Информационный поиск в Интернете
Информационный поиск в Интернете Жисмоний шахс ер мулк соликлар
Жисмоний шахс ер мулк соликлар Жанры изобразительного искусства
Жанры изобразительного искусства Эффективное регулирование на конкурентных энергетических рынках обеспечивает доступность энергии Сергей Геннадьевич Новиков
Эффективное регулирование на конкурентных энергетических рынках обеспечивает доступность энергии Сергей Геннадьевич Новиков  Презентация на тему Школа будущего
Презентация на тему Школа будущего Рисованные объекты Действия над объектами
Рисованные объекты Действия над объектами Система диагностики и коррекции как снятие психолого-педагогических трудностей при обучении математике слабоуспевающего учени
Система диагностики и коррекции как снятие психолого-педагогических трудностей при обучении математике слабоуспевающего учени Вместе мы – сила!
Вместе мы – сила!