- Учебный курс Введение в параллельные алгоритмы

Содержание
- 2. Вычислить с точностью ε значение определенного интеграла Пусть на отрезке [A,B] задана равномерная сетка, содержащая n+1
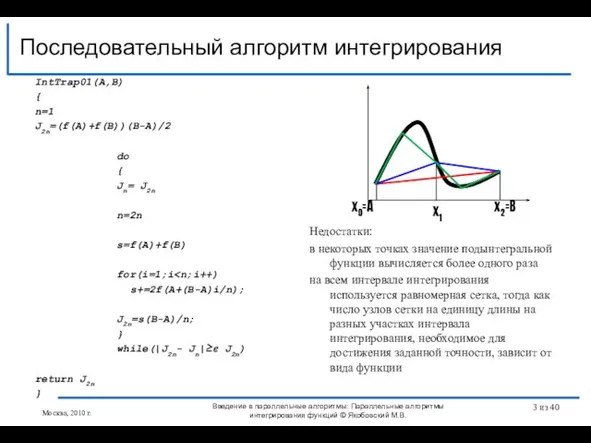
- 3. IntTrap01(A,B) { n=1 J2n=(f(A)+f(B))(B-A)/2 do { Jn= J2n n=2n s=f(A)+f(B) for(i=1;i s+=2f(A+(B-A)i/n); J2n=s(B-A)/n; } while(|J2n- Jn|≥ε
- 4. Пример функции Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В. Результаты вычисления интеграла
- 5. main() { J= IntTrap03( A, B, f(A),f(B) ) } Адаптивный алгоритм Введение в параллельные алгоритмы: Параллельные
- 6. IntTrap04(A,B) { J=0 fA=f(A) fB=f(B) sAB=(fA+fB)*(B-A)/2 while(1) { Тело цикла } return J } Метод локального
- 7. // данные, описывающие стек // указатель вершины стека sp=0 // массив структур в которых // хранятся
- 8. Тестирование показало, что при расчете с помощью алгоритма локального стека IntTrap04 время работы было меньше, примерно
- 9. Метод геометрического параллелизма? Метод коллективного решения? ? Параллельный алгоритм интегрирования Введение в параллельные алгоритмы: Параллельные алгоритмы
- 10. Метод геометрического параллелизма Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В. main() {
- 11. Расчет интеграла на разных отрезках Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В.
- 12. main() { // Порождение p параллельных процессов, // каждый из которых выполняет процедуру slave for(k=0;k StartParallel(slave
- 13. Практически непригодны для решения поставленной задачи методы геометрического параллелизма (статическая балансировка) и коллективного решения (динамическая балансировка)
- 14. Метод геометрического параллелизма? Метод коллективного решения? ? Параллельный алгоритм интегрирования Введение в параллельные алгоритмы: Параллельные алгоритмы
- 15. Вычислительные системы с общей памятью Динамическая балансировка загрузки Отсутствие централизованного управления Метод глобального стека Введение в
- 16. Пусть есть доступный всем параллельным процессам список отрезков интегрирования, организованный в виде стека. Назовем его глобальным
- 17. Глобальный стек Локальные стеки Стеки алгоритма Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
- 18. Глобальный стек Локальные стеки Стеки алгоритма Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
- 19. Глобальный стек Локальные стеки Стеки алгоритма Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
- 20. какую часть отрезков следует перемещать из локального стека в глобальный стек? в какой момент интеграл вычислен?
- 21. slave_thr() { // цикла обработки стека отрезков while(sdat.ntask>0) { // чтение одного интервала из списка интервалов
- 22. main() { . Sem_init(sdat.sem_sum,1) //доступ к глобальной сумме открыт . } slave_thr() { … // Начало
- 23. slave_thr() { // цикла обработки стека отрезков while(sdat.ntask>0) { // чтение одного интервала из списка интервалов
- 24. Схема интегрирования отрезка Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В. while(1) //
- 25. Схема интегрирования отрезка Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В. c=(a+b)/2; fc=f(c)
- 26. Схема интегрирования отрезка Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В. if(!BreakCond(sacb,sab)) {
- 27. Схема интегрирования отрезка Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В. if((sp>SPK) &&
- 28. while(1) { // Начало критической секции чтения из глобального // стека очередного интервала интегрирования sem_wait(sdat.sem_list) if(sdat.ntask≤0)
- 29. Условие выхода из цикла обработки стека интервалов выбрано неудачно Интегрирующие процессы не должны заканчивать работу до
- 30. Отрезок интегрирования может находиться в нескольких состояниях: - находится в глобальном стеке интервалов; - обрабатывается некоторым
- 31. Необходимые данные Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В. из 40 Москва,
- 32. int slave_thr() { // все переменные, начинающиеся с sdat. являются глобальными, // к ним имеет доступ
- 33. Инициализация Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В. int slave_thr() { //
- 34. Начало обработки глобального стека Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В. //
- 35. Запись терминальных отрезков Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В. // Начало
- 36. какую часть отрезков следует перемещать из локального стека в глобальный стек? в какой момент интеграл вычислен?
- 37. Время выполнения Ускорение Эффективность Результаты тестирования Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
- 38. Рассмотрен ряд методов вычисления интегралов на многопроцессорных системах, проанализированы их преимущества и недостатки Показано, что методы
- 39. Якобовский М.В., Кулькова Е.Ю. Решение задач на многопроцессорных вычислительных системах с разделяемой памятью. - М.: СТАНКИН,
- 41. Скачать презентацию
Слайд 2Вычислить с точностью ε значение определенного интеграла
Пусть на отрезке [A,B] задана равномерная
Вычислить с точностью ε значение определенного интеграла
Пусть на отрезке [A,B] задана равномерная
![Вычислить с точностью ε значение определенного интеграла Пусть на отрезке [A,B] задана](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/449023/slide-1.jpg)
Слайд 3IntTrap01(A,B)
{
n=1
J2n=(f(A)+f(B))(B-A)/2
do
{
Jn= J2n
n=2n
s=f(A)+f(B)
for(i=1;i s+=2f(A+(B-A)i/n);
J2n=s(B-A)/n;
}
while(|J2n- Jn|≥ε J2n)
return J2n
}
Последовательный алгоритм интегрирования
Введение в параллельные алгоритмы: Параллельные алгоритмы
IntTrap01(A,B) Последовательный алгоритм интегрирования Введение в параллельные алгоритмы: Параллельные алгоритмы
{
n=1
J2n=(f(A)+f(B))(B-A)/2
do
{
Jn= J2n
n=2n
s=f(A)+f(B)
for(i=1;i
J2n=s(B-A)/n;
}
while(|J2n- Jn|≥ε J2n)
return J2n
}
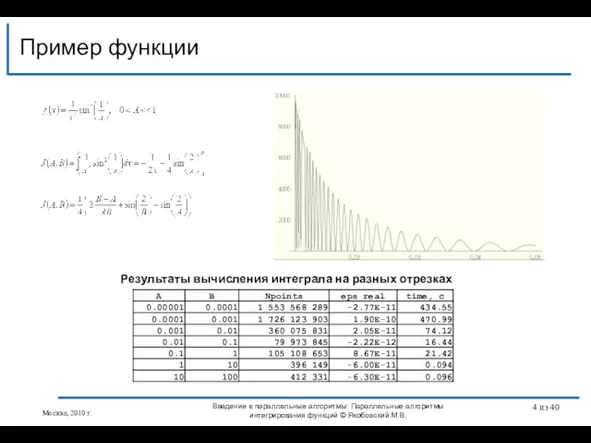
Слайд 4Пример функции
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В.
Результаты
Пример функции
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В.
Результаты
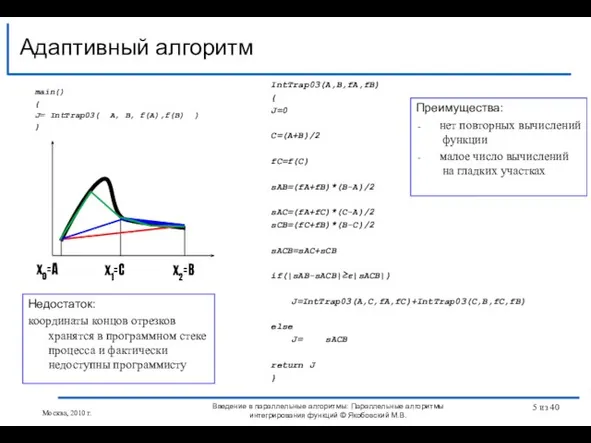
Слайд 5main()
{
J= IntTrap03( A, B, f(A),f(B) )
}
Адаптивный алгоритм
Введение в параллельные алгоритмы: Параллельные алгоритмы
main()
{
J= IntTrap03( A, B, f(A),f(B) )
}
Адаптивный алгоритм
Введение в параллельные алгоритмы: Параллельные алгоритмы
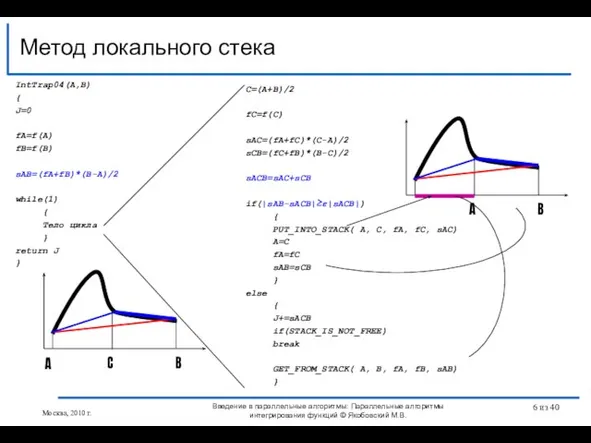
Слайд 6IntTrap04(A,B)
{
J=0
fA=f(A)
fB=f(B)
sAB=(fA+fB)*(B-A)/2
while(1)
{
Тело цикла
}
return J
}
Метод локального стека
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций
IntTrap04(A,B)
{
J=0
fA=f(A)
fB=f(B)
sAB=(fA+fB)*(B-A)/2
while(1)
{
Тело цикла
}
return J
}
Метод локального стека
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций
Слайд 7// данные, описывающие стек
// указатель вершины стека
sp=0
// массив структур в которых
// данные, описывающие стек
// указатель вершины стека
sp=0
// массив структур в которых

Слайд 8Тестирование показало, что при расчете с помощью алгоритма локального стека IntTrap04 время
Тестирование показало, что при расчете с помощью алгоритма локального стека IntTrap04 время

Слайд 9Метод геометрического параллелизма?
Метод коллективного решения?
?
Параллельный алгоритм интегрирования
Введение в параллельные алгоритмы: Параллельные алгоритмы
Метод геометрического параллелизма?
Метод коллективного решения?
?
Параллельный алгоритм интегрирования
Введение в параллельные алгоритмы: Параллельные алгоритмы

Слайд 10Метод геометрического параллелизма
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
Метод геометрического параллелизма
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский

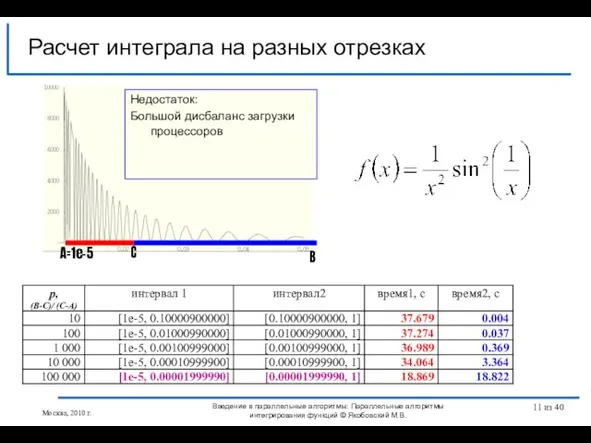
Слайд 11Расчет интеграла на разных отрезках
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций
Расчет интеграла на разных отрезках
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций
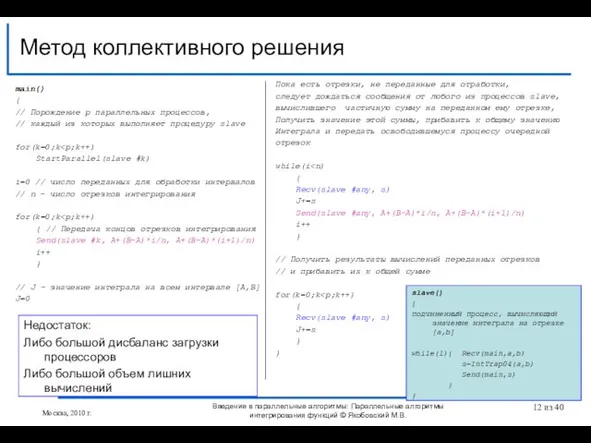
Слайд 12main()
{
// Порождение p параллельных процессов,
// каждый из которых выполняет процедуру slave
for(k=0;k StartParallel(slave
main()
{
// Порождение p параллельных процессов,
// каждый из которых выполняет процедуру slave
for(k=0;k
Слайд 13Практически непригодны для решения поставленной задачи методы
геометрического параллелизма
(статическая балансировка)
и
Практически непригодны для решения поставленной задачи методы
геометрического параллелизма
(статическая балансировка)
и

Слайд 14Метод геометрического параллелизма?
Метод коллективного решения?
?
Параллельный алгоритм интегрирования
Введение в параллельные алгоритмы: Параллельные алгоритмы
Метод геометрического параллелизма?
Метод коллективного решения?
?
Параллельный алгоритм интегрирования
Введение в параллельные алгоритмы: Параллельные алгоритмы

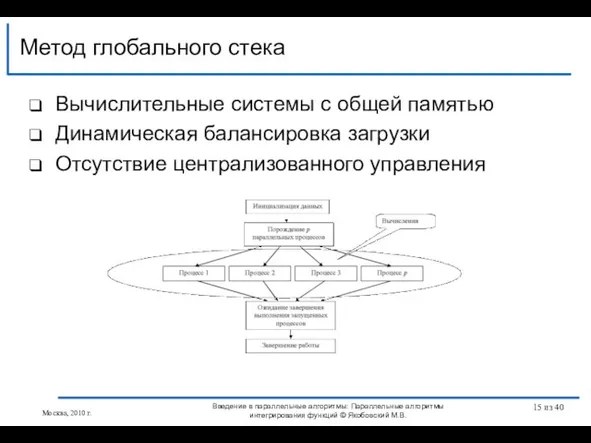
Слайд 15Вычислительные системы с общей памятью
Динамическая балансировка загрузки
Отсутствие централизованного управления
Метод глобального стека
Введение в
Вычислительные системы с общей памятью
Динамическая балансировка загрузки
Отсутствие централизованного управления
Метод глобального стека
Введение в
Слайд 16Пусть есть доступный всем параллельным процессам список отрезков интегрирования, организованный в виде
Пусть есть доступный всем параллельным процессам список отрезков интегрирования, организованный в виде

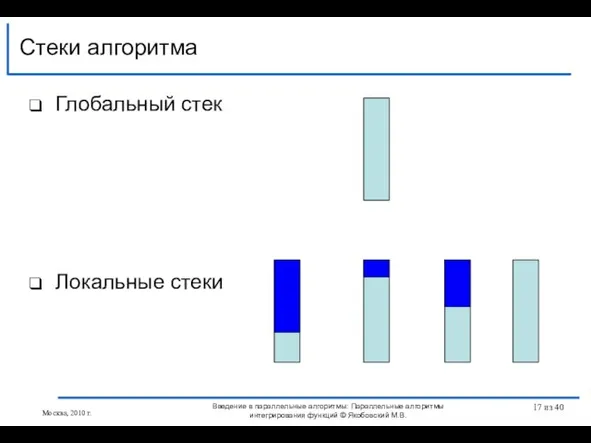
Слайд 17Глобальный стек
Локальные стеки
Стеки алгоритма
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций ©
Глобальный стек
Локальные стеки
Стеки алгоритма
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций ©
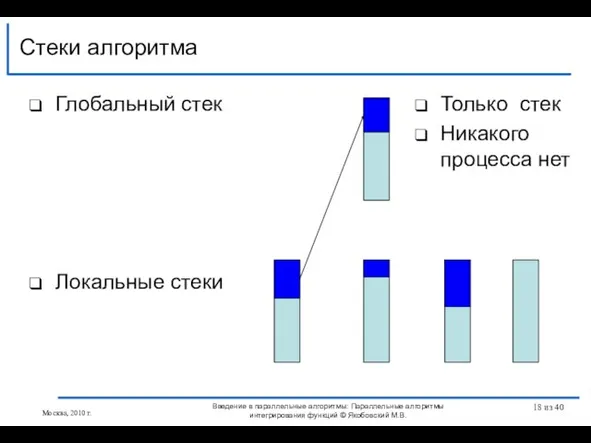
Слайд 18Глобальный стек
Локальные стеки
Стеки алгоритма
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций ©
Глобальный стек
Локальные стеки
Стеки алгоритма
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций ©
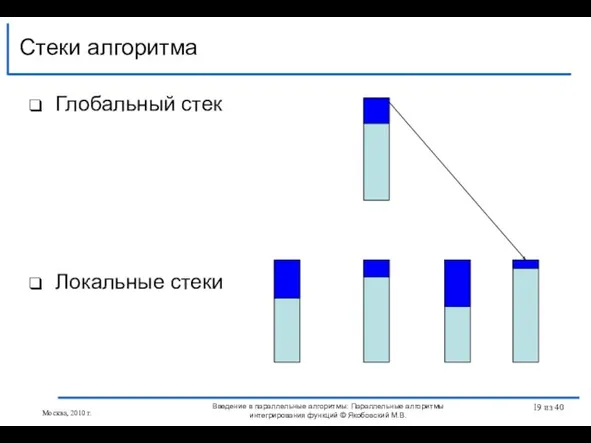
Слайд 19Глобальный стек
Локальные стеки
Стеки алгоритма
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций ©
Глобальный стек
Локальные стеки
Стеки алгоритма
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций ©
Слайд 20какую часть отрезков следует перемещать из локального стека в глобальный стек?
в какой
какую часть отрезков следует перемещать из локального стека в глобальный стек?
в какой

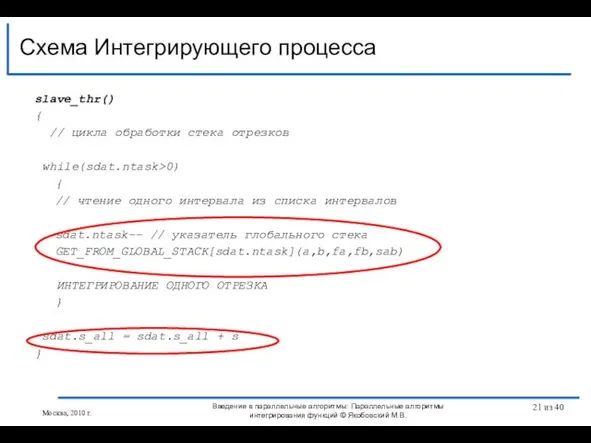
Слайд 21slave_thr()
{
// цикла обработки стека отрезков
while(sdat.ntask>0)
{
// чтение одного интервала из списка
slave_thr()
{
// цикла обработки стека отрезков
while(sdat.ntask>0)
{
// чтение одного интервала из списка
Слайд 22main()
{
.
Sem_init(sdat.sem_sum,1) //доступ к глобальной сумме открыт
.
}
slave_thr()
{
…
// Начало критической секции сложения частичных
main()
{
.
Sem_init(sdat.sem_sum,1) //доступ к глобальной сумме открыт
.
}
slave_thr()
{
…
// Начало критической секции сложения частичных

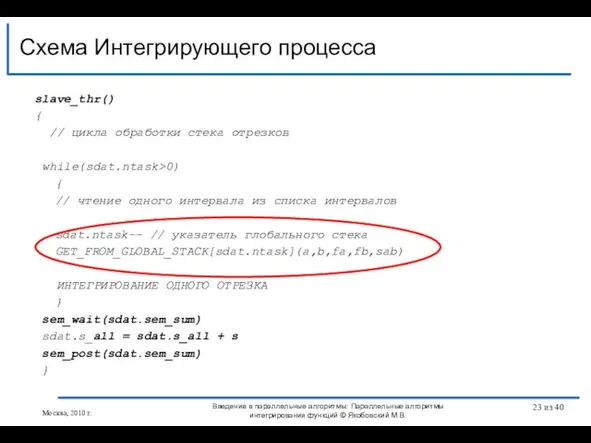
Слайд 23slave_thr()
{
// цикла обработки стека отрезков
while(sdat.ntask>0)
{
// чтение одного интервала из
slave_thr()
{
// цикла обработки стека отрезков
while(sdat.ntask>0)
{
// чтение одного интервала из
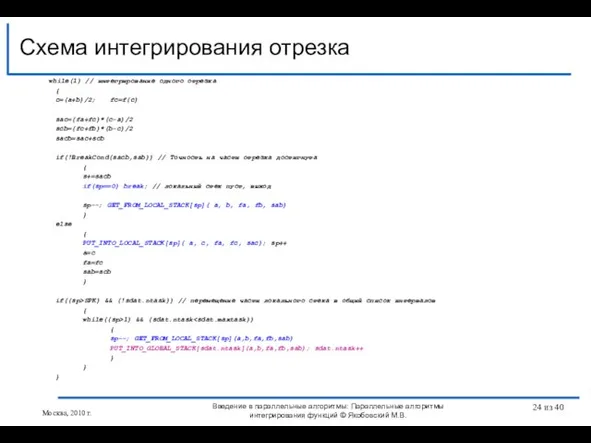
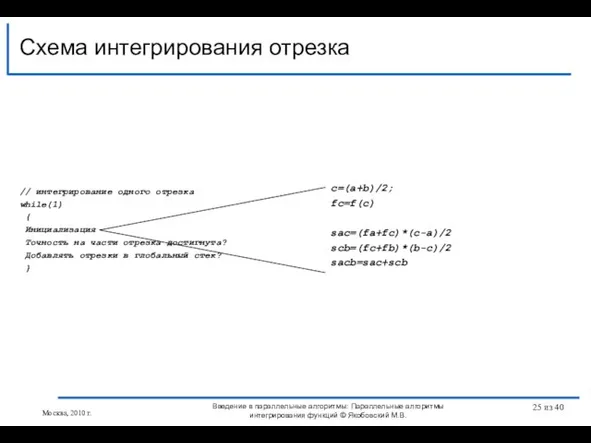
Слайд 24Схема интегрирования отрезка
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
Схема интегрирования отрезка
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
Слайд 25Схема интегрирования отрезка
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
Схема интегрирования отрезка
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
Слайд 26Схема интегрирования отрезка
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
Схема интегрирования отрезка
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский

Слайд 27Схема интегрирования отрезка
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
Схема интегрирования отрезка
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский

Слайд 28while(1)
{
// Начало критической секции чтения из глобального
// стека очередного
while(1)
{
// Начало критической секции чтения из глобального
// стека очередного

Слайд 29Условие выхода из цикла обработки стека интервалов выбрано неудачно
Интегрирующие процессы не должны
Условие выхода из цикла обработки стека интервалов выбрано неудачно
Интегрирующие процессы не должны

Слайд 30Отрезок интегрирования может находиться в нескольких состояниях:
- находится в глобальном стеке интервалов;
-
Отрезок интегрирования может находиться в нескольких состояниях:
- находится в глобальном стеке интервалов;
-

Слайд 31Необходимые данные
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В.
Необходимые данные
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В.

Слайд 32int slave_thr()
{
// все переменные, начинающиеся с sdat. являются глобальными,
// к
int slave_thr()
{
// все переменные, начинающиеся с sdat. являются глобальными,
// к

Слайд 33Инициализация
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В.
int slave_thr()
{
Инициализация
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский М.В.
int slave_thr()
{

Слайд 34Начало обработки глобального стека
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций ©
Начало обработки глобального стека
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций ©

Слайд 35Запись терминальных отрезков
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
Запись терминальных отрезков
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский

Слайд 36какую часть отрезков следует перемещать из локального стека в глобальный стек?
в какой
какую часть отрезков следует перемещать из локального стека в глобальный стек?
в какой

Слайд 37Время выполнения
Ускорение
Эффективность
Результаты тестирования
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский
Время выполнения
Ускорение
Эффективность
Результаты тестирования
Введение в параллельные алгоритмы: Параллельные алгоритмы интегрирования функций © Якобовский

Слайд 38Рассмотрен ряд методов вычисления интегралов на многопроцессорных системах, проанализированы их преимущества и
Рассмотрен ряд методов вычисления интегралов на многопроцессорных системах, проанализированы их преимущества и

Слайд 39Якобовский М.В., Кулькова Е.Ю. Решение задач на многопроцессорных вычислительных системах с разделяемой
Якобовский М.В., Кулькова Е.Ю. Решение задач на многопроцессорных вычислительных системах с разделяемой

 Убивал ли Иван Грозный сына_
Убивал ли Иван Грозный сына_ Reguli pentru oviață de calitate
Reguli pentru oviață de calitate 248435
248435 Каталог Искусственные ёлки
Каталог Искусственные ёлки Части тела
Части тела Политическая система и политический режим 11 класс
Политическая система и политический режим 11 класс Решение задач на составление уравнений. 6 класс
Решение задач на составление уравнений. 6 класс НАЦИНАЛЬНЫЙ ОПЕРАТОР ЭЛЕКТРОННЫХТОРГОВ
НАЦИНАЛЬНЫЙ ОПЕРАТОР ЭЛЕКТРОННЫХТОРГОВ Termit. Одежда детская
Termit. Одежда детская Презентация (1)
Презентация (1) «The purpose of my life is to make a woman beautiful» Aenne Burda Raisa Gorbachova and Aenne Burda in Moscow The first issue of «Burda Moden»
«The purpose of my life is to make a woman beautiful» Aenne Burda Raisa Gorbachova and Aenne Burda in Moscow The first issue of «Burda Moden» Пути улучшения привлекательности Волгоградской области
Пути улучшения привлекательности Волгоградской области Инновационность педагогических технологий и учебно-методических материалов для обучения иностранному языку в неязыковом вузе
Инновационность педагогических технологий и учебно-методических материалов для обучения иностранному языку в неязыковом вузе Способы мотивации педагогов к саморазвитию
Способы мотивации педагогов к саморазвитию Действия с дробями
Действия с дробями Перчатки нашего производства
Перчатки нашего производства Человек в космосе
Человек в космосе 10182_7807324_13
10182_7807324_13 Уровни общего образования в Российской Федерации
Уровни общего образования в Российской Федерации Let’s talk about Weddings
Let’s talk about Weddings Программа духовно-нравственного воспитания и развития обучающихся 10-11 классов на 2013-2016 учебные годы
Программа духовно-нравственного воспитания и развития обучающихся 10-11 классов на 2013-2016 учебные годы Требования к оформлению текста
Требования к оформлению текста Price Calculator
Price Calculator БП адамдардын дауыс санын олардын жагдайына байланысты
БП адамдардын дауыс санын олардын жагдайына байланысты Презентация на тему Строение растительной клетки
Презентация на тему Строение растительной клетки Спортивная викторина для младших школьников
Спортивная викторина для младших школьников Муниципальное общеобразовательное учреждение средняя общеобразовательная школа № 4г. Рассказово Тамбовской области
Муниципальное общеобразовательное учреждение средняя общеобразовательная школа № 4г. Рассказово Тамбовской области История приборостроения
История приборостроения