«Зачем», «что» и «как» в исследовании коллокаций. Вопросы и возможные ответы Размышления на тему Елены Ягуновой & Co [email protected]
- «Зачем», «что» и «как» в исследовании коллокаций. Вопросы и возможные ответы Размышления на тему Елены Ягуновой & Co [email protected]

Содержание
- 2. место доклада в миниконференции В рамках мини-конференции «Коллокации и сочетаемостные особенности: методы исследования» мой доклад взаимосвязан
- 3. Что -1 (у других) чаще всего – коллокации как несвободные сочетания, не относящиеся к идиомам: ключевое
- 4. Что -2 (у нас) Коллокации: неслучайное сочетание двух и более лексических единиц, характерное как для языка
- 5. Зачем??? Исследование характеристик единиц языка, и/или характеристик текстов и их структурных составляющих
- 6. Что-1? Зачем-1 рассматриваются большие массивы текстов изучаются характеристики языка, исследуемые единицы можно перечислить в виде закрытого
- 7. Что-1? Зачем-1 (примеры) Корпусной словарь неоднословных лексических единиц (оборотов) http://ruscorpora.ru/obgrams.html При каждом обороте указано количество употреблений
- 8. Корпусной словарь неоднословных лексических единиц (оборотов). Плюсы и минусы Есть закрытый список коллокаций (по словарям), требуется
- 9. Что-1? Зачем-1 (примеры) на http://dict.ruslang.ru/ Г. И. Кустова СЛОВАРЬ РУССКОЙ ИДИОМАТИКИ (выход на запрос в НКРЯ)
- 10. Пример алфавитного списка всех сочетаний слов со значением высокой степени абсолютная анархия абсолютная бездарность абсолютная безопасность
- 11. Что-1? Зачем-1 (примеры) О. Л. Бирюк, В. Ю. Гусев, Е. Ю. Калинина СЛОВАРЬ ГЛАГОЛЬНОЙ СОЧЕТАЕМОСТИ НЕПРЕДМЕТНЫХ
- 12. Пример списка (параметры не выбраны), выход на запрос в НКРЯ (не) ведать стыда действие (не) видеть
- 13. особенности этого подхода Заданность списка анализируемых коллокаций (частичная или по параметрам) Отношение к текстовым коллекциям работает
- 14. Что-2? Зачем-2 рассматриваются большие массивы текстов тексты разных функциональных стилей и предметных областей, список потенциальных коллокаций
- 15. разные ФС текстов и различие списков коллокаций http://corpus.leeds.ac.uk/ruscorpora.html A query to Russian corpora Выбор: Russian National
- 16. разные ФС текстов, разные стат. меры и различие списков коллокаций A query to Russian corpora Collocation
- 17. Зачем-2 и Что-2 и Как-2? Если коллокации не заданы списком, если коллокации не заданы правилами, то
- 18. Текст и коллокации текст есть структурированная последовательность единиц разных уровней, Коллокации как сложносоставные подструктуры текста –
- 19. Текстовые коллекции и коллокации Мы не привязаны к заданной коллекции или Корпусу На коллекциях разных текстов
- 20. Что мы можем получить, на разных коллекциях-корпусах? Варьируя коллекции, мы можем организовать систему вложенных друг в
- 21. Что мы можем получить, на разных коллокциях-корпусах? Например, вложенные друг в друга: научные тексты, лингвистические научные
- 22. Что мы можем получить, используя разные статистические меры (напр., MI, t-score, LL), а может где-то и
- 23. используя разные параметры, Мы получаем разные типы коллокаций = типы структурных составляющих текста: неоднословных номинаций в
- 24. используя разные параметры, (продолжение) Мы получаем еще другие типы коллокаций = типы структурных составляющих текста: составные
- 25. статистические меры (напр., MI vs. t-score)-1 Новостные тексты (напр., на материале lenta.ru за 2009) мера MI
- 26. статистические меры (напр., MI vs. t-score)-2 Научные тексты (напр., на материале «Диалог 2003-2009» и «Корпусная лингвистика»
- 27. Таблица 1. Биграммы (MI-score), выделяющиеся и для лексем, и для словоформ. Материал конференции «Диалог» (из доклада
- 28. Биграммы (MI-score), выделяющиеся и для лексем, и для словоформ. Табл. 1 и 2а. Пояснения Пороги для
- 29. Таблица 2а. Терминологические биграммы (MI-score), выделяющиеся и для лексем, и для словоформ. Материал конференции «Корпусная лингвистика»
- 30. Биграммы (MI-score), выделяющиеся и для лексем, и для словоформ. Почему мы выбрали этот список? В список
- 31. Статистические меры (напр., MI vs. t-score)-3. Дельта. Порог Новостные тексты (напр., на материале lenta.ru), в которых
- 32. Выделении основных тем новостной коллекции. Мера. Дельта. Порог Гипотеза об иерархии используемых мер (с учетом дельт
- 33. Дополнительная проверка гипотезы. Дельта. Порог Еще раз про гипотезу: t-score Дельта нужда для увеличения тематической однородности
- 34. зачем? что? как? Сейчас мы не ставим перед собой задачу практически востребованного метода напр., извлечения всех
- 35. Зачем-2 и Что-2 и Как-2? продолжение… на будущее что задано для списка потенциальных коллокаций ?? не
- 36. Литература Бирюк О. Л., Гусев В. Ю., Калинина Е. Ю. Словарь глагольной сочетаемости непредметных имен русского
- 37. Литература (продолжение) Пивоварова Л.М., Ягунова Е.В. Извлечение и классификация терминологических коллокаций на материале лингвистических научных текстов.
- 39. Скачать презентацию
Слайд 2место доклада в миниконференции
В рамках мини-конференции «Коллокации и сочетаемостные особенности: методы исследования» мой
место доклада в миниконференции
В рамках мини-конференции «Коллокации и сочетаемостные особенности: методы исследования» мой

Слайд 3Что -1 (у других)
чаще всего – коллокации как несвободные сочетания, не относящиеся
Что -1 (у других)
чаще всего – коллокации как несвободные сочетания, не относящиеся

Слайд 4Что -2 (у нас)
Коллокации: неслучайное сочетание двух и более лексических единиц, характерное
Что -2 (у нас)
Коллокации: неслучайное сочетание двух и более лексических единиц, характерное

Слайд 5Зачем???
Исследование
характеристик единиц языка,
и/или
характеристик текстов и их структурных составляющих
Зачем???
Исследование
характеристик единиц языка,
и/или
характеристик текстов и их структурных составляющих

Слайд 6Что-1? Зачем-1
рассматриваются большие массивы текстов
изучаются характеристики языка,
исследуемые единицы можно перечислить в виде
Что-1? Зачем-1
рассматриваются большие массивы текстов
изучаются характеристики языка,
исследуемые единицы можно перечислить в виде

Слайд 7Что-1? Зачем-1 (примеры)
Корпусной словарь неоднословных лексических единиц (оборотов) http://ruscorpora.ru/obgrams.html
При каждом обороте
Что-1? Зачем-1 (примеры)
Корпусной словарь неоднословных лексических единиц (оборотов) http://ruscorpora.ru/obgrams.html
При каждом обороте

Слайд 8Корпусной словарь неоднословных лексических единиц (оборотов). Плюсы и минусы
Есть закрытый список коллокаций
Корпусной словарь неоднословных лексических единиц (оборотов). Плюсы и минусы
Есть закрытый список коллокаций

Слайд 9Что-1? Зачем-1 (примеры)
на http://dict.ruslang.ru/
Г. И. Кустова СЛОВАРЬ РУССКОЙ ИДИОМАТИКИ (выход на
Что-1? Зачем-1 (примеры)
на http://dict.ruslang.ru/
Г. И. Кустова СЛОВАРЬ РУССКОЙ ИДИОМАТИКИ (выход на

Слайд 10Пример алфавитного списка всех сочетаний слов со значением высокой степени
абсолютная анархия
абсолютная
Пример алфавитного списка всех сочетаний слов со значением высокой степени
абсолютная анархия абсолютная

Слайд 11Что-1? Зачем-1 (примеры)
О. Л. Бирюк, В. Ю. Гусев, Е. Ю. Калинина СЛОВАРЬ
Что-1? Зачем-1 (примеры)
О. Л. Бирюк, В. Ю. Гусев, Е. Ю. Калинина СЛОВАРЬ

Слайд 12Пример списка (параметры не выбраны), выход на запрос в НКРЯ
(не) ведать стыда
Пример списка (параметры не выбраны), выход на запрос в НКРЯ
(не) ведать стыда

Слайд 13особенности этого подхода
Заданность списка анализируемых коллокаций (частичная или по параметрам)
Отношение к текстовым
особенности этого подхода
Заданность списка анализируемых коллокаций (частичная или по параметрам)
Отношение к текстовым

Слайд 14Что-2? Зачем-2
рассматриваются большие массивы текстов
тексты разных функциональных стилей и предметных областей,
Что-2? Зачем-2
рассматриваются большие массивы текстов
тексты разных функциональных стилей и предметных областей,

Слайд 15разные ФС текстов и различие списков коллокаций
http://corpus.leeds.ac.uk/ruscorpora.html
A query to Russian corpora
Выбор:
разные ФС текстов и различие списков коллокаций
http://corpus.leeds.ac.uk/ruscorpora.html
A query to Russian corpora
Выбор:

Слайд 16разные ФС текстов, разные стат. меры и различие списков коллокаций
A query to
разные ФС текстов, разные стат. меры и различие списков коллокаций
A query to

Слайд 17Зачем-2 и Что-2 и Как-2?
Если коллокации не заданы списком,
если коллокации не заданы
Зачем-2 и Что-2 и Как-2?
Если коллокации не заданы списком,
если коллокации не заданы

Слайд 18Текст и коллокации
текст есть структурированная последовательность единиц разных уровней,
Коллокации как сложносоставные
Текст и коллокации
текст есть структурированная последовательность единиц разных уровней,
Коллокации как сложносоставные

Слайд 19Текстовые коллекции и коллокации
Мы не привязаны к заданной коллекции или Корпусу
На коллекциях
Текстовые коллекции и коллокации
Мы не привязаны к заданной коллекции или Корпусу
На коллекциях

Слайд 20Что мы можем получить, на разных коллекциях-корпусах?
Варьируя коллекции, мы можем организовать систему
Что мы можем получить, на разных коллекциях-корпусах?
Варьируя коллекции, мы можем организовать систему

Слайд 21Что мы можем получить, на разных коллокциях-корпусах?
Например, вложенные друг в друга:
научные тексты,
Что мы можем получить, на разных коллокциях-корпусах?
Например, вложенные друг в друга:
научные тексты,

Слайд 22Что мы можем получить,
используя разные
статистические меры (напр., MI, t-score, LL),
а может где-то
Что мы можем получить,
используя разные
статистические меры (напр., MI, t-score, LL),
а может где-то

Слайд 23используя разные параметры,
Мы получаем разные типы коллокаций = типы структурных составляющих текста:
неоднословных
используя разные параметры,
Мы получаем разные типы коллокаций = типы структурных составляющих текста:
неоднословных

Слайд 24используя разные параметры,
(продолжение)
Мы получаем еще другие типы коллокаций = типы структурных составляющих
используя разные параметры,
(продолжение)
Мы получаем еще другие типы коллокаций = типы структурных составляющих

Слайд 25статистические меры (напр., MI vs. t-score)-1
Новостные тексты (напр., на материале lenta.ru за
статистические меры (напр., MI vs. t-score)-1
Новостные тексты (напр., на материале lenta.ru за

Слайд 26статистические меры (напр., MI vs. t-score)-2
Научные тексты (напр., на материале «Диалог 2003-2009»
статистические меры (напр., MI vs. t-score)-2
Научные тексты (напр., на материале «Диалог 2003-2009»

Слайд 27Таблица 1. Биграммы (MI-score), выделяющиеся и для лексем, и для словоформ. Материал
Таблица 1. Биграммы (MI-score), выделяющиеся и для лексем, и для словоформ. Материал

Слайд 28Биграммы (MI-score), выделяющиеся и для лексем, и для словоформ. Табл. 1 и
Биграммы (MI-score), выделяющиеся и для лексем, и для словоформ. Табл. 1 и

Слайд 29Таблица 2а. Терминологические биграммы (MI-score), выделяющиеся и для лексем, и для словоформ.
Таблица 2а. Терминологические биграммы (MI-score), выделяющиеся и для лексем, и для словоформ.
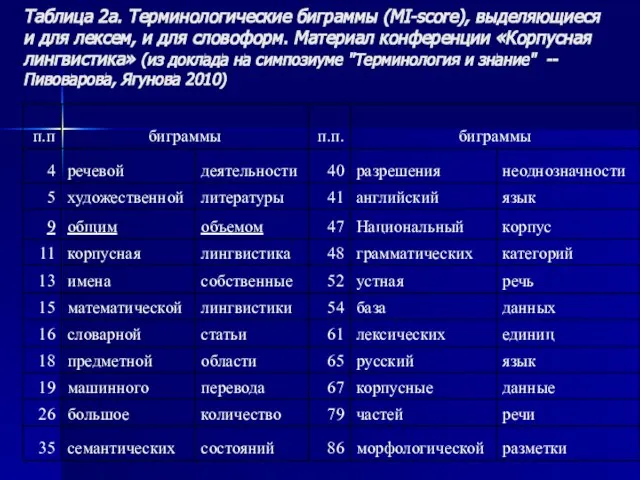
Слайд 30Биграммы (MI-score), выделяющиеся и для лексем, и для словоформ. Почему мы выбрали
Биграммы (MI-score), выделяющиеся и для лексем, и для словоформ. Почему мы выбрали

Слайд 31Статистические меры (напр., MI vs. t-score)-3. Дельта. Порог
Новостные тексты (напр., на материале
Статистические меры (напр., MI vs. t-score)-3. Дельта. Порог
Новостные тексты (напр., на материале

Слайд 32Выделении основных тем новостной коллекции. Мера. Дельта. Порог
Гипотеза об иерархии используемых мер
Выделении основных тем новостной коллекции. Мера. Дельта. Порог
Гипотеза об иерархии используемых мер

Слайд 33Дополнительная проверка гипотезы. Дельта. Порог
Еще раз про гипотезу: t-score < MI <
Дополнительная проверка гипотезы. Дельта. Порог
Еще раз про гипотезу: t-score < MI <

Слайд 34зачем? что? как?
Сейчас мы не ставим перед собой задачу практически востребованного метода
зачем? что? как?
Сейчас мы не ставим перед собой задачу практически востребованного метода

Слайд 35Зачем-2 и Что-2 и Как-2?
продолжение… на будущее
что задано для списка потенциальных коллокаций
Зачем-2 и Что-2 и Как-2?
продолжение… на будущее
что задано для списка потенциальных коллокаций

Слайд 36Литература
Бирюк О. Л., Гусев В. Ю., Калинина Е. Ю. Словарь глагольной сочетаемости
Литература
Бирюк О. Л., Гусев В. Ю., Калинина Е. Ю. Словарь глагольной сочетаемости

Слайд 37Литература (продолжение)
Пивоварова Л.М., Ягунова Е.В. Извлечение и классификация терминологических коллокаций на материале
Литература (продолжение)
Пивоварова Л.М., Ягунова Е.В. Извлечение и классификация терминологических коллокаций на материале

 Все о полиграфическом рынке
Все о полиграфическом рынке Компания Ракурс
Компания Ракурс Эмпирические социальные достижения
Эмпирические социальные достижения  Как возникло франкское государство
Как возникло франкское государство Сложение чисел с помощью координатной прямой
Сложение чисел с помощью координатной прямой Значение творчества В.А.Серова для развития отечественной живописи
Значение творчества В.А.Серова для развития отечественной живописи CIVIL LAW Concept and grounds
CIVIL LAW Concept and grounds Неополис - город будущего. Город на реке: бренд успешной столицы
Неополис - город будущего. Город на реке: бренд успешной столицы Магистральные модели
Магистральные модели Тонкослойная хроматография
Тонкослойная хроматография Презентация на тему Строение цветка
Презентация на тему Строение цветка  Основные устройства компьютера,их функции и взаимосвязь.
Основные устройства компьютера,их функции и взаимосвязь. Молекулярная эволюция и филогенетика
Молекулярная эволюция и филогенетика  КОНДИЦИОНЕРЫ Samsung 2009
КОНДИЦИОНЕРЫ Samsung 2009 Пришедшая выручка
Пришедшая выручка Первобытные люди 4 класс
Первобытные люди 4 класс Италия после второй мировой войны
Италия после второй мировой войны Магический кубик
Магический кубик Закон о воспитании: план действий дошкольной организации по реализации новых положений законодательства
Закон о воспитании: план действий дошкольной организации по реализации новых положений законодательства d4798d3f5a007823a7d4b1743d3eced2
d4798d3f5a007823a7d4b1743d3eced2 Армянский Петербург
Армянский Петербург НАЦИОНАЛЬНЫЙ ПЛАН УПРАВЛЕНИЯ ЗАСУХАМИ ПО ГРУЗИИ
НАЦИОНАЛЬНЫЙ ПЛАН УПРАВЛЕНИЯ ЗАСУХАМИ ПО ГРУЗИИ Презентация на тему Вакуумные приборы
Презентация на тему Вакуумные приборы  Тема лекции:«Электронная цифровая подпись»
Тема лекции:«Электронная цифровая подпись» Электронный дневник и электронный журнал в NetSchool как часть комплексной информационной системы (с) 2001-2011 ИРТех
Электронный дневник и электронный журнал в NetSchool как часть комплексной информационной системы (с) 2001-2011 ИРТех А.С. Пушкин Краткая биография в картинках
А.С. Пушкин Краткая биография в картинках Перейти Рубикон
Перейти Рубикон Презентация на тему A history about David Livingstone
Презентация на тему A history about David Livingstone