- Оценка качества прочтений NGS

Содержание
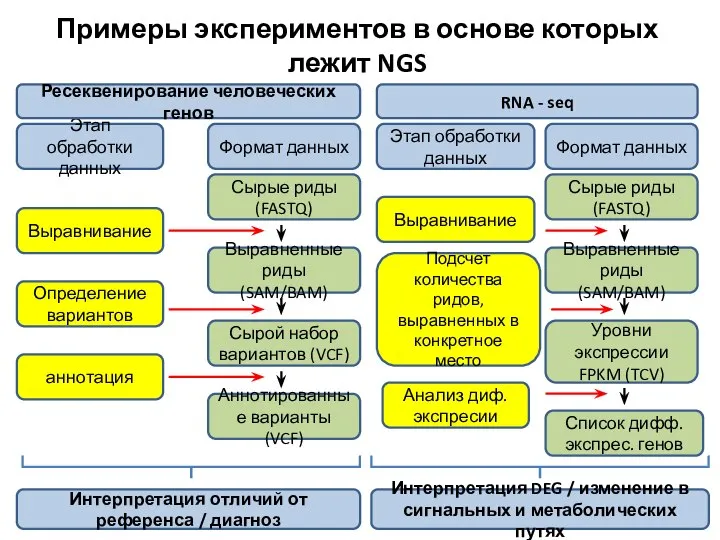
- 2. Примеры экспериментов в основе которых лежит NGS Этап обработки данных Формат данных Ресеквенирование человеческих генов RNA
- 3. Сырые данные на выходе у секвенатора Этап обработки данных Формат данных Ресеквенирование человеческих генов RNA -
- 4. Контроль качества обязательный этап Этап обработки данных Формат данных Ресеквенирование человеческих генов RNA - seq Формат
- 5. А на кой черт оно собственно надо?
- 6. А на кой черт оно собственно надо? Сырые данные, полученные в ходе работы секвенатора. Их вы
- 7. А на кой черт оно собственно надо? Сырые данные, полученные в ходе работы секвенатора. Их вы
- 8. А на кой черт оно собственно надо? Сырые данные, полученные в ходе работы секвенатора. Их вы
- 9. А на кой черт оно собственно надо? Сырые данные, полученные в ходе работы секвенатора. Их вы
- 10. А на кой черт оно собственно надо? Сырые данные, полученные в ходе работы секвенатора. Их вы
- 11. FASTQ формат @cluster_2:UMI_ATTCCG TTTCCGGGGCACATAATCTTCAGCCGGGCGC + 9C;=;= 9:67AA 65 591
- 12. FASTQ формат @cluster_2:UMI_ATTCCG TTTCCGGGGCACATAATCTTCAGCCGGGCGC + 9C;=;= 9:67AA 65 591 Идентификатор последовательности с необязательным описанием. Начинается с
- 13. FASTQ формат @cluster_2:UMI_ATTCCG TTTCCGGGGCACATAATCTTCAGCCGGGCGC + 9C;=;= 9:67AA 65 591 Идентификатор последовательности с необязательным описанием. Начинается с
- 14. FASTQ формат @cluster_2:UMI_ATTCCG TTTCCGGGGCACATAATCTTCAGCCGGGCGC + 9C;=;= 9:67AA 65 591 Идентификатор последовательности с необязательным описанием. Начинается с
- 15. FASTQ формат @cluster_2:UMI_ATTCCG TTTCCGGGGCACATAATCTTCAGCCGGGCGC + 9C;=;= 9:67AA 65 591 Идентификатор последовательности с необязательным описанием. Начинается с
- 16. FASTQ формат @cluster_2:UMI_ATTCCG TTTCCGGGGCACATAATCTTCAGCCGGGCGC + 9C;=;= 9:67AA 65 591 Идентификатор последовательности с необязательным описанием. Начинается с
- 17. Q score кодируется символами ASKII
- 18. FastQC FastQC – инструмент, позволяющий проводить контроль качества сырых ридов. В настоящее время по сути стал
- 19. Quality score по основаниям в ридах Красная линия – медианное значе ние Qscore в данной позиции
- 20. Ухудшение качества прочтения к концу ридов
- 21. Quality score целых последовательностей Этот график позволяет увидеть часть ваших последовательностей, имеющих более низкое среднее качество,
- 22. Содержание нуклеотидов по позициям в ридах График показывает пропорцию по нуклеотидам в конкретной позиции ридов. В
- 23. Содержание нуклеотидов по позициям в ридах График показывает пропорцию по нуклеотидам в конкретной позиции ридов. В
- 24. Содержание GC по позициям в ридах В случаной библиотеке вы ожидает увидеть незначительную разницу по содержанию
- 25. Содержание GC в целых последовательностях Вы ожидаете увидеть похожее на нормальное распределение с одним пиком. Наличие
- 26. Содержание N по позиции в ридах Наличие небольшого количество N (неопределенных нуклеотидов) в ридах, полученных секвенатором
- 27. Распределение длин прочтений
- 28. Распределение длин прочтений
- 29. Дуплицированные последовательности В полностью рандомизированной библиотеке большинство сиквенсов встречаются в ридах только 1 раз. Небольшой количество
- 30. Сверхпредставленные последовательности Обычно библиотека для NGS содержит разнообразный набор последовательностей, без единственной последовательности, составляющая существенную часть
- 31. Сверхпредставленные последовательности
- 32. Содержание адаптеров
- 34. Скачать презентацию
Слайд 2Примеры экспериментов в основе которых лежит NGS
Этап обработки данных
Формат данных
Ресеквенирование человеческих
Примеры экспериментов в основе которых лежит NGS
Этап обработки данных
Формат данных
Ресеквенирование человеческих
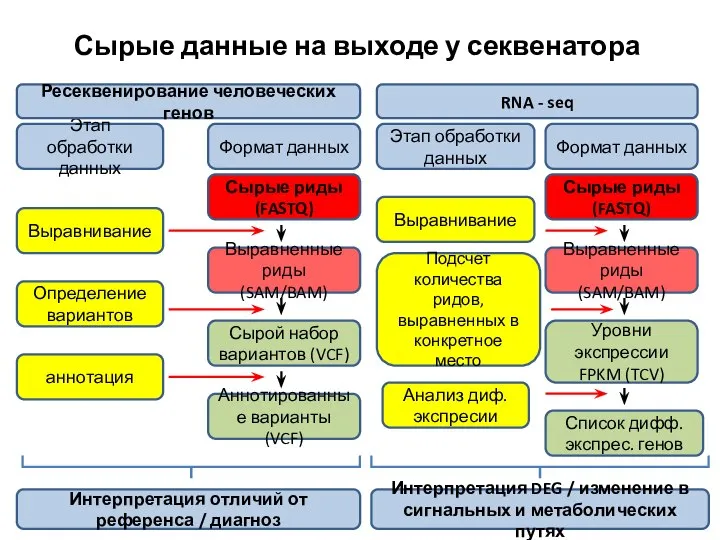
Слайд 3Сырые данные на выходе у секвенатора
Этап обработки данных
Формат данных
Ресеквенирование человеческих генов
RNA -
Сырые данные на выходе у секвенатора
Этап обработки данных
Формат данных
Ресеквенирование человеческих генов
RNA -
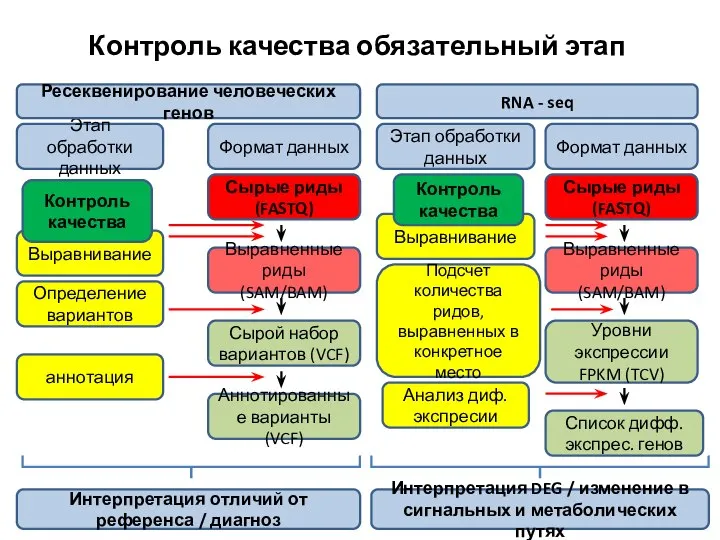
Слайд 4Контроль качества обязательный этап
Этап обработки данных
Формат данных
Ресеквенирование человеческих генов
RNA - seq
Формат данных
Этап
Контроль качества обязательный этап
Этап обработки данных
Формат данных
Ресеквенирование человеческих генов
RNA - seq
Формат данных
Этап
Слайд 5А на кой черт оно собственно надо?
А на кой черт оно собственно надо?

Слайд 6А на кой черт оно собственно надо?
Сырые данные, полученные в ходе работы
А на кой черт оно собственно надо?
Сырые данные, полученные в ходе работы
Слайд 7А на кой черт оно собственно надо?
Сырые данные, полученные в ходе работы
А на кой черт оно собственно надо?
Сырые данные, полученные в ходе работы
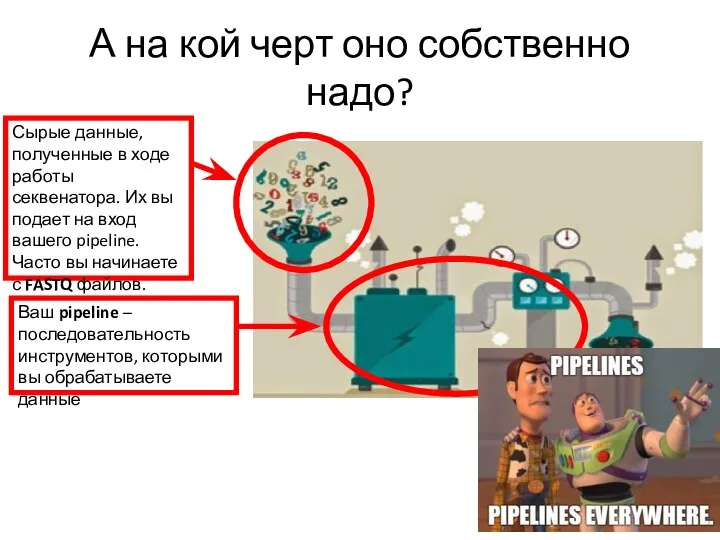
Слайд 8А на кой черт оно собственно надо?
Сырые данные, полученные в ходе работы
А на кой черт оно собственно надо?
Сырые данные, полученные в ходе работы
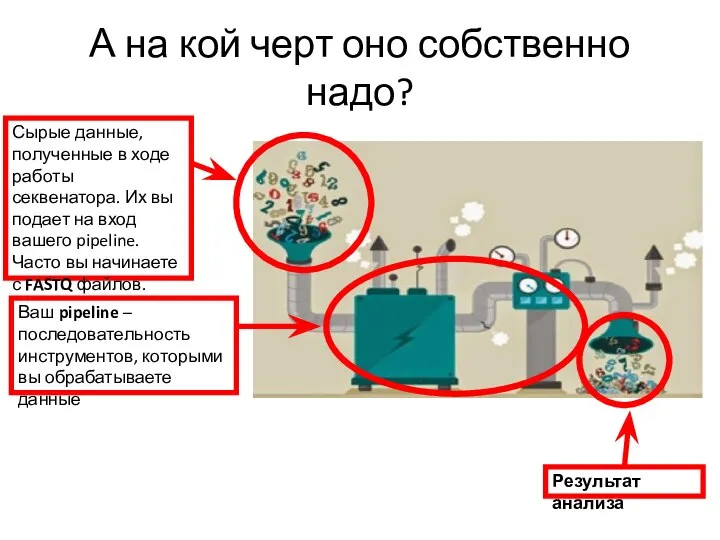
Слайд 9А на кой черт оно собственно надо?
Сырые данные, полученные в ходе работы
А на кой черт оно собственно надо?
Сырые данные, полученные в ходе работы
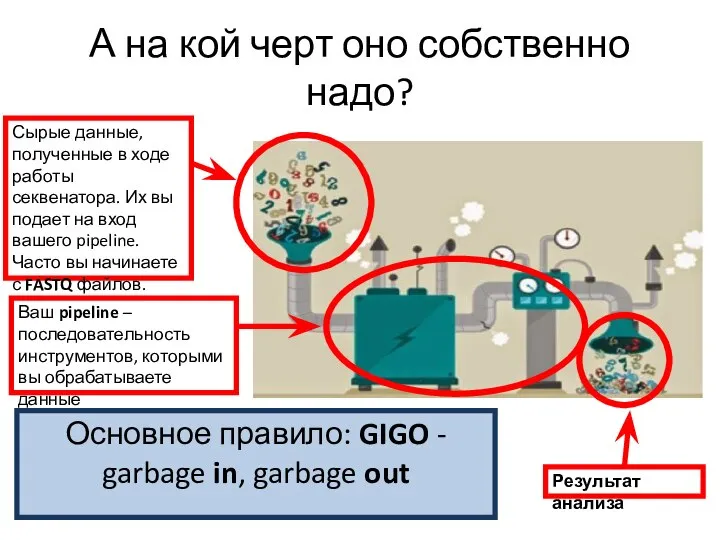
Слайд 10А на кой черт оно собственно надо?
Сырые данные, полученные в ходе работы
А на кой черт оно собственно надо?
Сырые данные, полученные в ходе работы
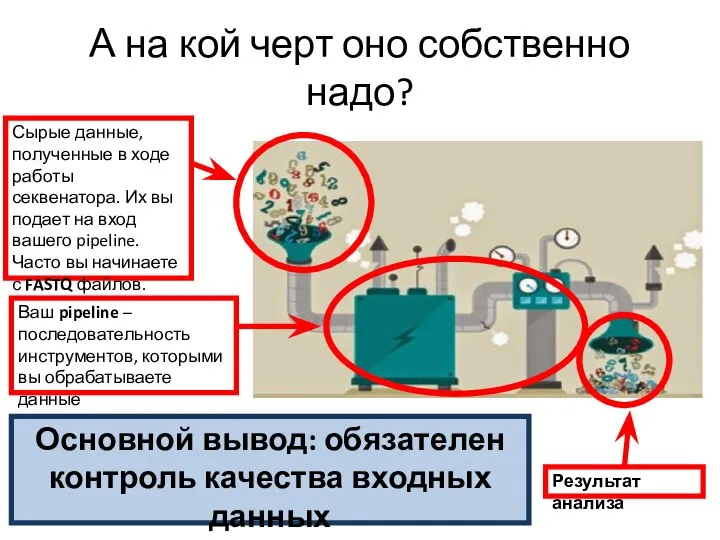
Слайд 11FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591
FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591

Слайд 12FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591
Идентификатор последовательности с необязательным описанием. Начинается с символа @
FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591
Идентификатор последовательности с необязательным описанием. Начинается с символа @
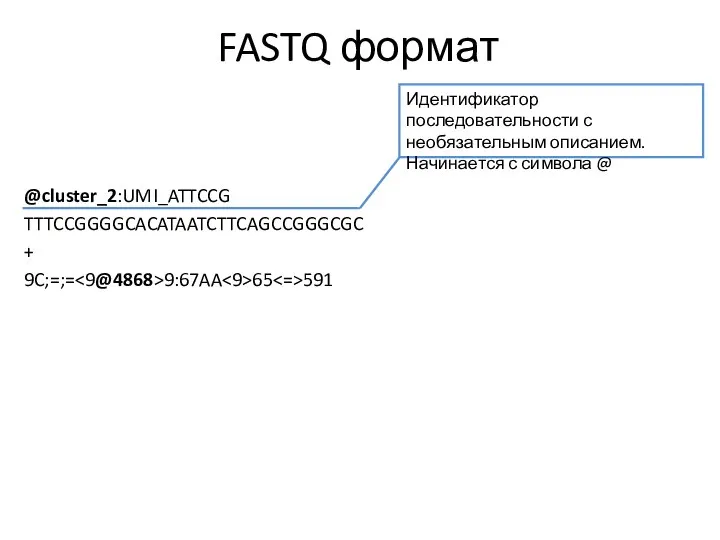
Слайд 13FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591
Идентификатор последовательности с необязательным описанием. Начинается с символа @
Последовательность
FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591
Идентификатор последовательности с необязательным описанием. Начинается с символа @
Последовательность
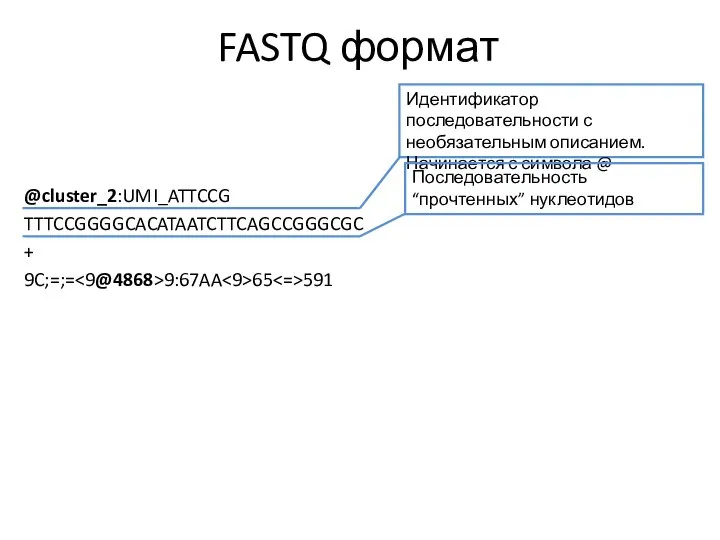
Слайд 14FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591
Идентификатор последовательности с необязательным описанием. Начинается с символа @
Последовательность
FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591
Идентификатор последовательности с необязательным описанием. Начинается с символа @
Последовательность
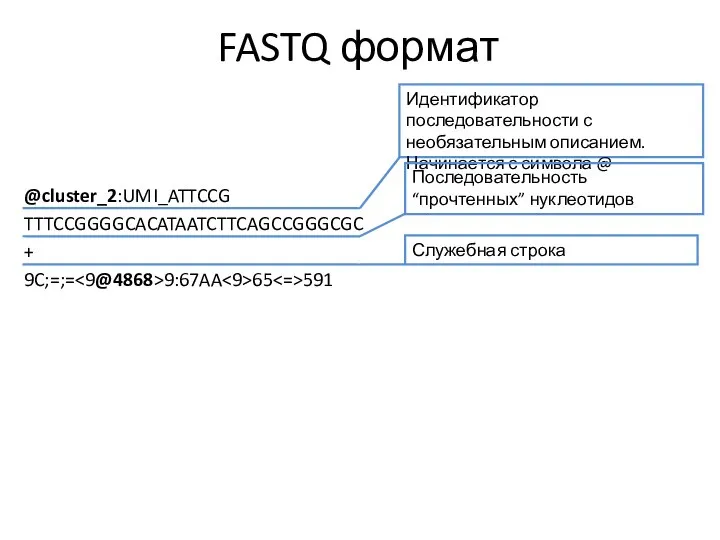
Слайд 15FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591
Идентификатор последовательности с необязательным описанием. Начинается с символа @
Последовательность
FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591
Идентификатор последовательности с необязательным описанием. Начинается с символа @
Последовательность
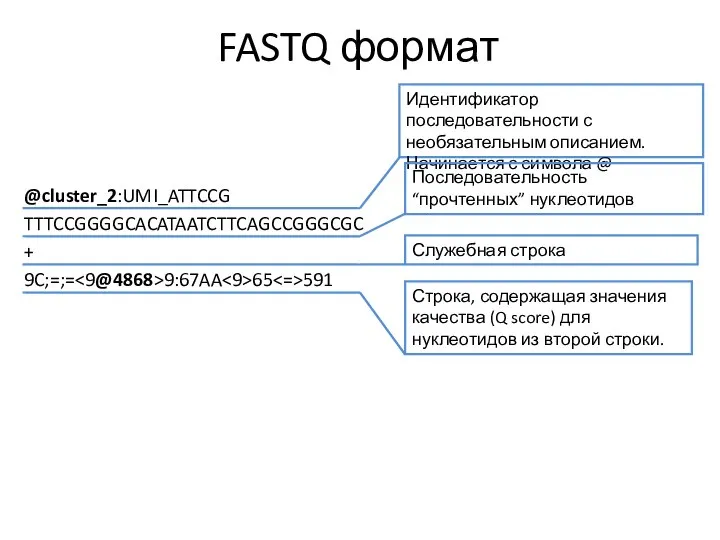
Слайд 16FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591
Идентификатор последовательности с необязательным описанием. Начинается с символа @
Последовательность
FASTQ формат
@cluster_2:UMI_ATTCCG
TTTCCGGGGCACATAATCTTCAGCCGGGCGC
+
9C;=;=<9@4868>9:67AA<9>65<=>591
Идентификатор последовательности с необязательным описанием. Начинается с символа @
Последовательность
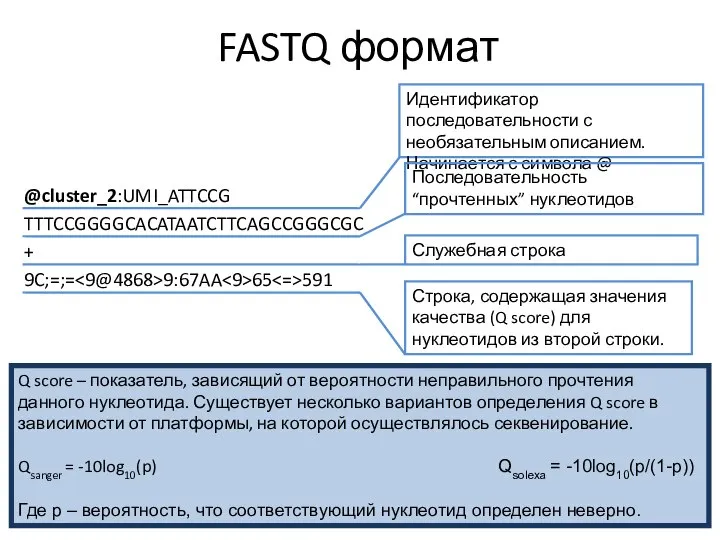
Слайд 17Q score кодируется символами ASKII
Q score кодируется символами ASKII
Слайд 18FastQC
FastQC – инструмент, позволяющий проводить контроль качества сырых ридов.
В настоящее время
FastQC
FastQC – инструмент, позволяющий проводить контроль качества сырых ридов.
В настоящее время

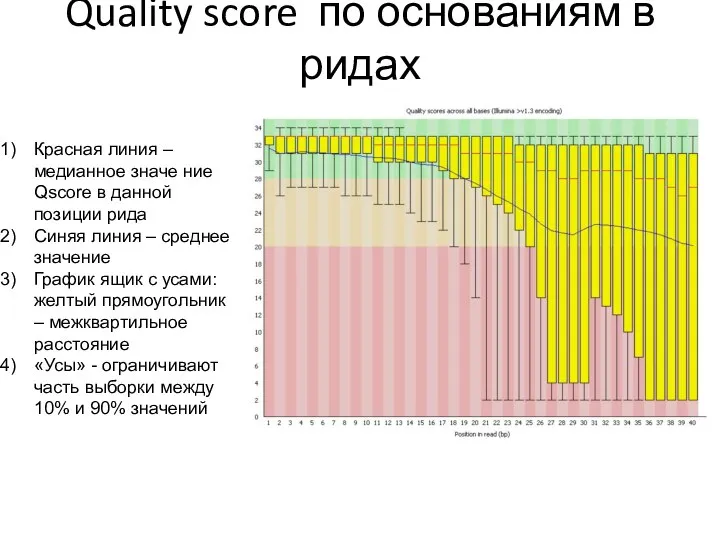
Слайд 19Quality score по основаниям в ридах
Красная линия – медианное значе ние Qscore
Quality score по основаниям в ридах
Красная линия – медианное значе ние Qscore
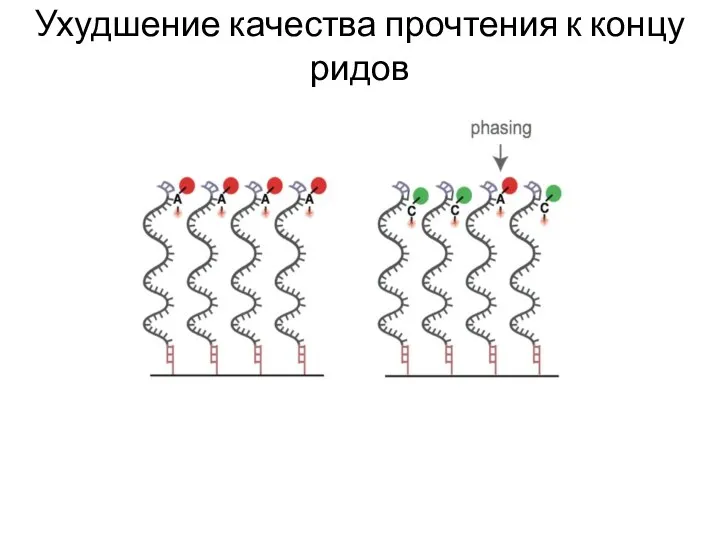
Слайд 20Ухудшение качества прочтения к концу ридов
Ухудшение качества прочтения к концу ридов
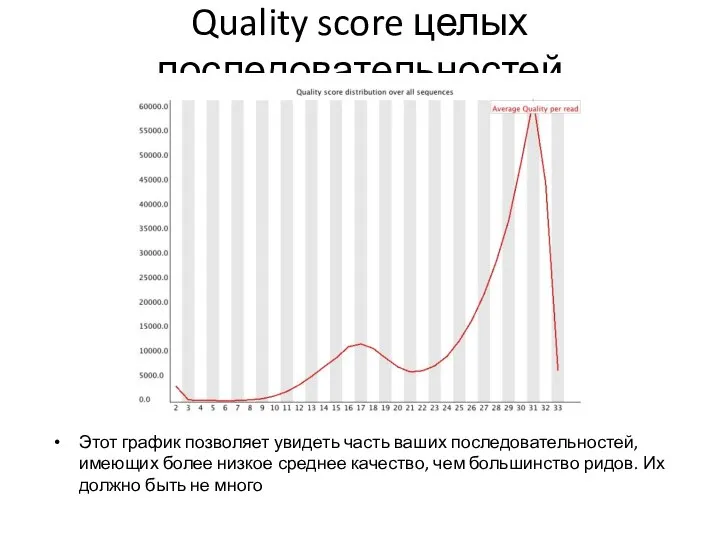
Слайд 21Quality score целых последовательностей
Этот график позволяет увидеть часть ваших последовательностей, имеющих более
Quality score целых последовательностей
Этот график позволяет увидеть часть ваших последовательностей, имеющих более
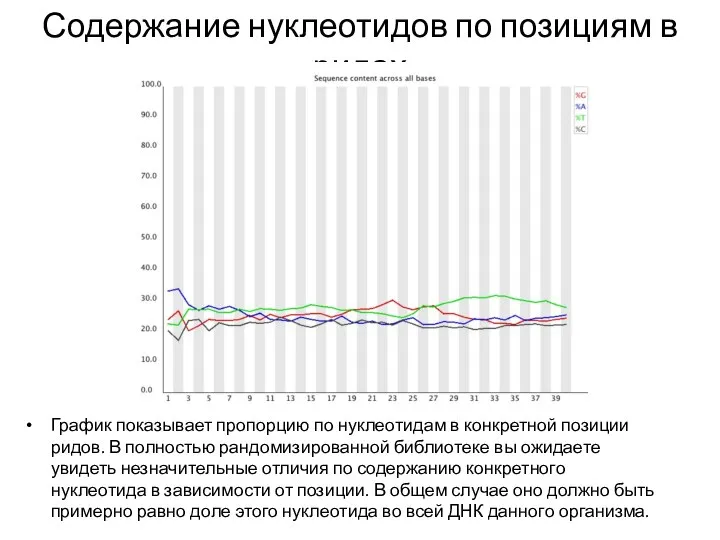
Слайд 22Содержание нуклеотидов по позициям в ридах
График показывает пропорцию по нуклеотидам в конкретной
Содержание нуклеотидов по позициям в ридах
График показывает пропорцию по нуклеотидам в конкретной
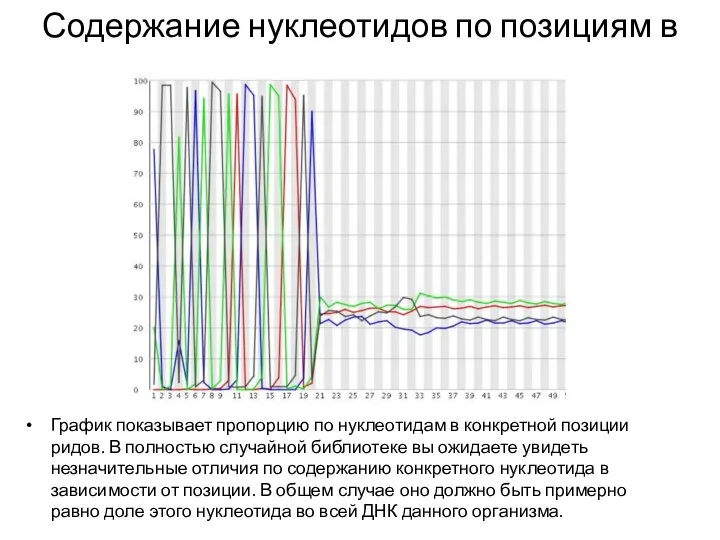
Слайд 23Содержание нуклеотидов по позициям в ридах
График показывает пропорцию по нуклеотидам в конкретной
Содержание нуклеотидов по позициям в ридах
График показывает пропорцию по нуклеотидам в конкретной
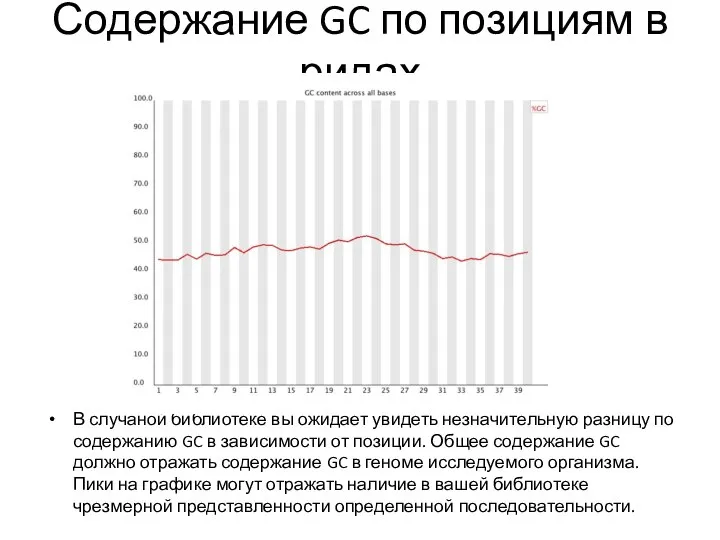
Слайд 24Содержание GC по позициям в ридах
В случаной библиотеке вы ожидает увидеть незначительную
Содержание GC по позициям в ридах
В случаной библиотеке вы ожидает увидеть незначительную
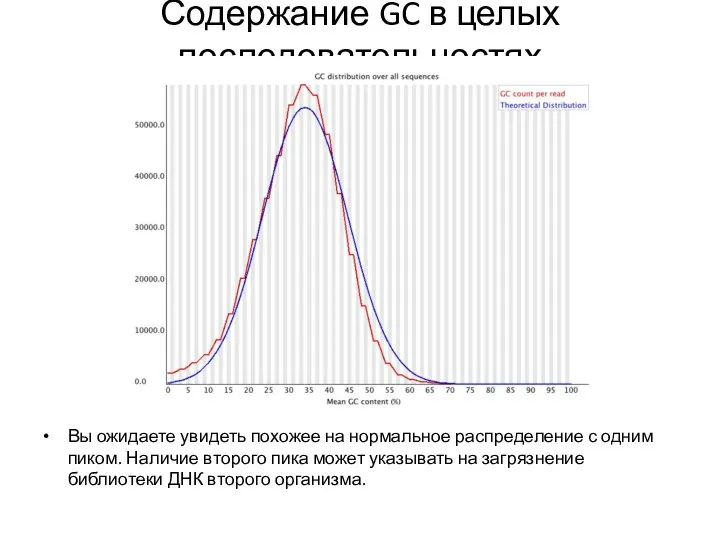
Слайд 25Содержание GC в целых последовательностях
Вы ожидаете увидеть похожее на нормальное распределение с
Содержание GC в целых последовательностях
Вы ожидаете увидеть похожее на нормальное распределение с
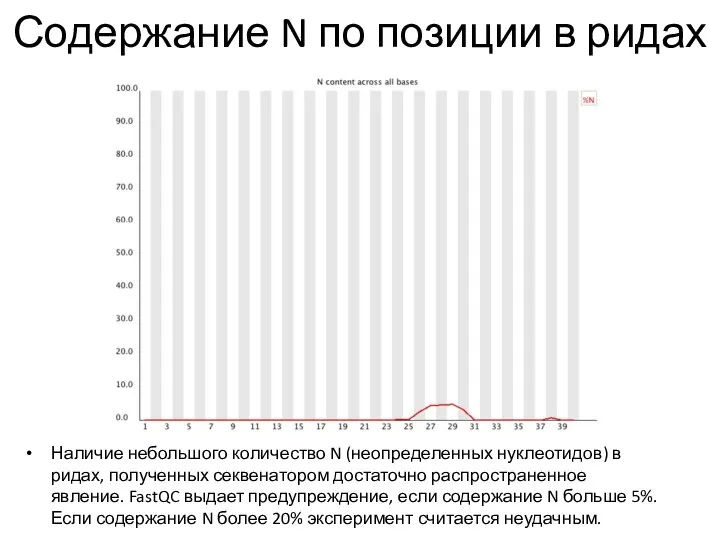
Слайд 26Содержание N по позиции в ридах
Наличие небольшого количество N (неопределенных нуклеотидов) в
Содержание N по позиции в ридах
Наличие небольшого количество N (неопределенных нуклеотидов) в
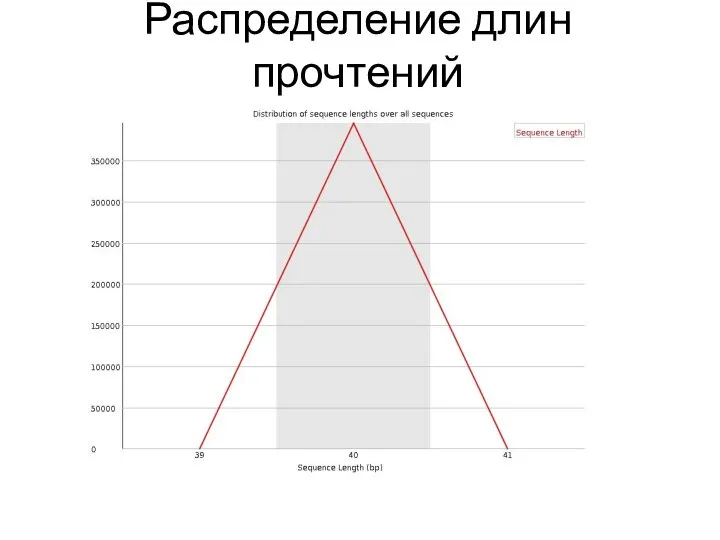
Слайд 27Распределение длин прочтений
Распределение длин прочтений
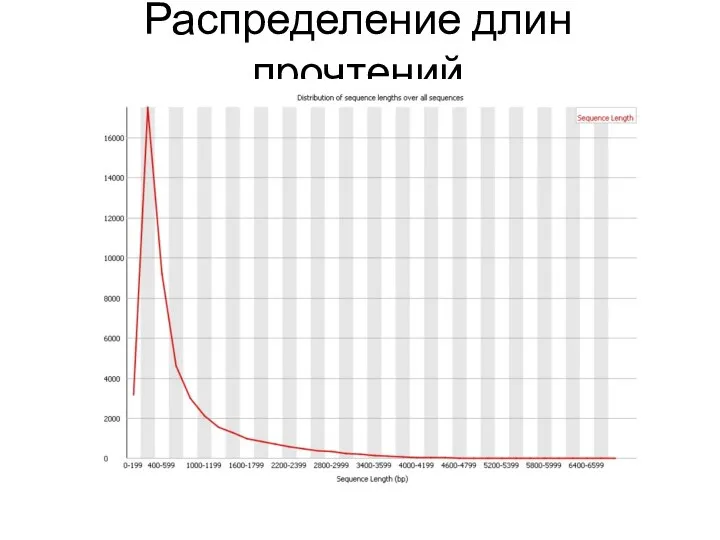
Слайд 28Распределение длин прочтений
Распределение длин прочтений
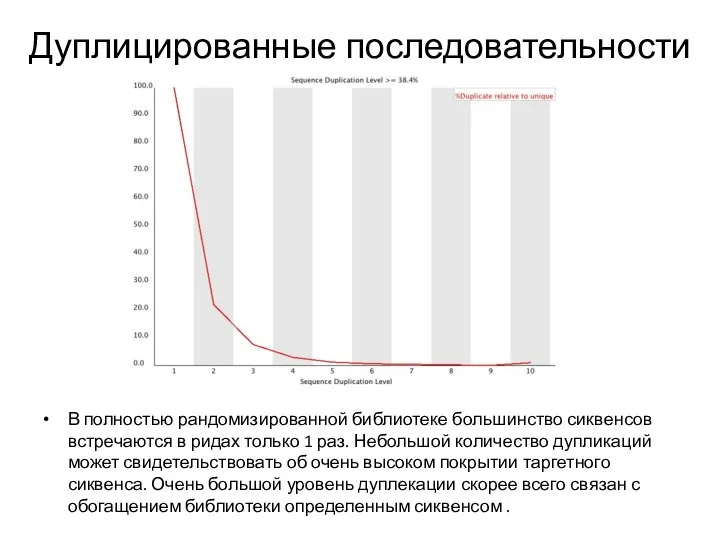
Слайд 29Дуплицированные последовательности
В полностью рандомизированной библиотеке большинство сиквенсов встречаются в ридах только 1
Дуплицированные последовательности
В полностью рандомизированной библиотеке большинство сиквенсов встречаются в ридах только 1
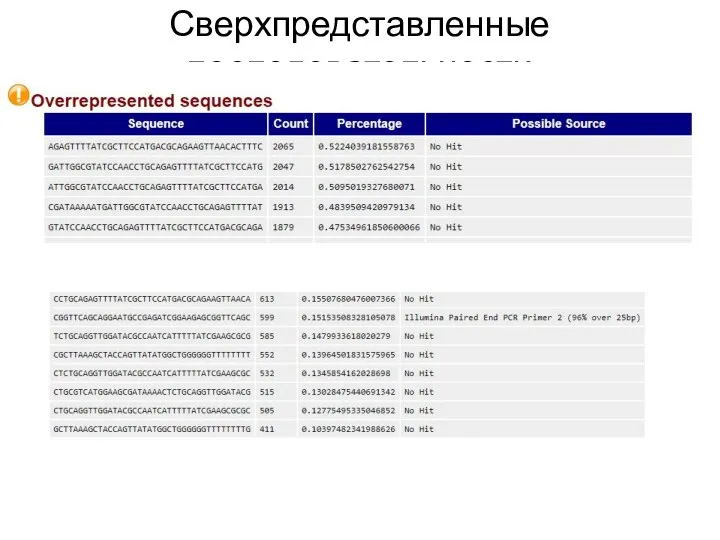
Слайд 30Сверхпредставленные последовательности
Обычно библиотека для NGS содержит разнообразный набор последовательностей, без единственной последовательности,
Сверхпредставленные последовательности
Обычно библиотека для NGS содержит разнообразный набор последовательностей, без единственной последовательности,

Слайд 31Сверхпредставленные последовательности
Сверхпредставленные последовательности
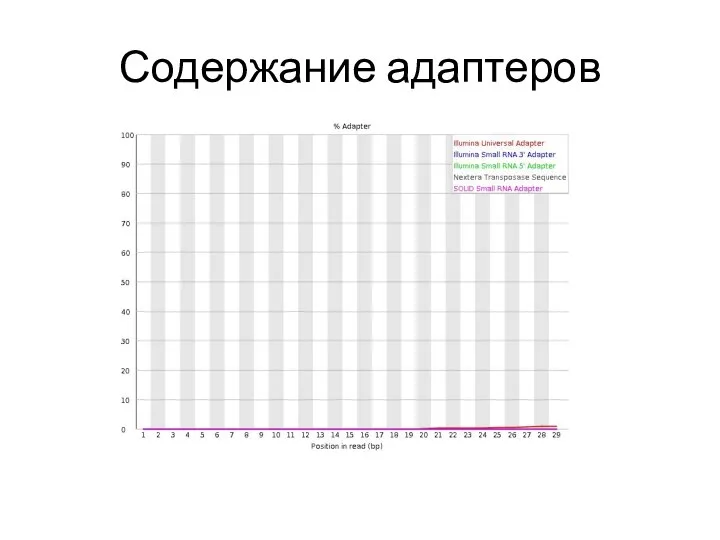
Слайд 32Содержание адаптеров
Содержание адаптеров
 Дигибридное скрещивание. Цитологические основы третьего закона Менделя
Дигибридное скрещивание. Цитологические основы третьего закона Менделя Анализаторы
Анализаторы Дзерены пришли
Дзерены пришли Цитология. Клеточная теория
Цитология. Клеточная теория Презентация на тему Покровы тела животных
Презентация на тему Покровы тела животных  Отдел формирования (древесные школы)
Отдел формирования (древесные школы) Типы деления клеток
Типы деления клеток Волны жизни
Волны жизни Регуляция кровообращения
Регуляция кровообращения Дикие предки коровы
Дикие предки коровы Промежуточный мозг. Строение и функции
Промежуточный мозг. Строение и функции Стресс, метаболизм и ликвидация активов
Стресс, метаболизм и ликвидация активов Презентация на тему Кишечнополостные
Презентация на тему Кишечнополостные  Грегор Йоган Мендель
Грегор Йоган Мендель Многообразие живых организмов в различных экосистемах. 6 класс
Многообразие живых организмов в различных экосистемах. 6 класс Презентация на тему Национальный парк «Беловежская пуща»
Презентация на тему Национальный парк «Беловежская пуща» 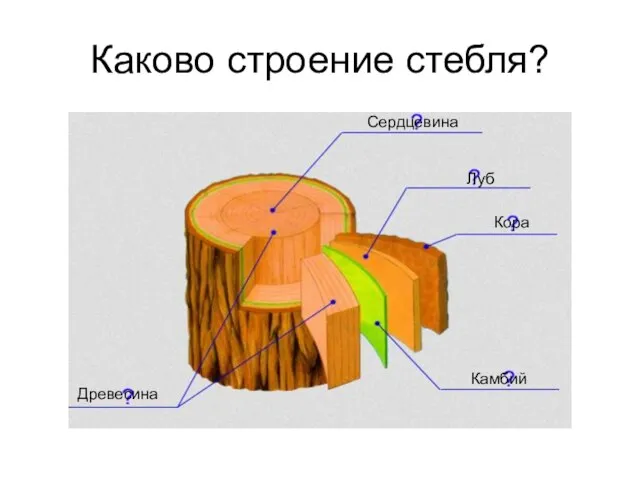 Внутреннее строение стебля. Лекция 3
Внутреннее строение стебля. Лекция 3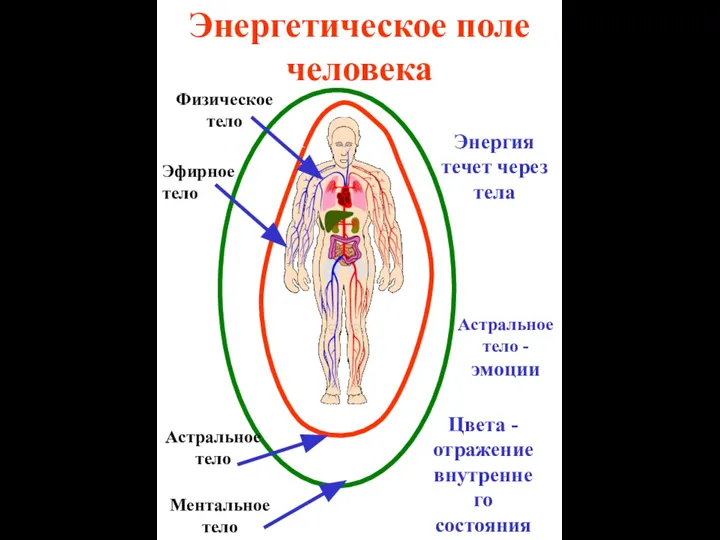 Энергетическое поле человека
Энергетическое поле человека Птицы нашего края
Птицы нашего края Малоизученные таксоны животных организмов
Малоизученные таксоны животных организмов Дыхательная система
Дыхательная система Иммунная система человека
Иммунная система человека Ярмарка знаний. Игра
Ярмарка знаний. Игра Биологическое ассорти
Биологическое ассорти Ребята о зверятах
Ребята о зверятах Антибіотики-аміноглікозиди
Антибіотики-аміноглікозиди Семя, его строение и значение
Семя, его строение и значение Класс Двустворчатые моллюски. Роль в биоценозах и практическое значение
Класс Двустворчатые моллюски. Роль в биоценозах и практическое значение