- 1666246426895__a84q6r

Содержание
- 2. Ключевые слова текстовая информация кодирование кодовые таблицы
- 4. … 64 65 66 67 68 … 01000000 01000001 01000010 01000011 01000100 Компьютерное представление текстовой информации
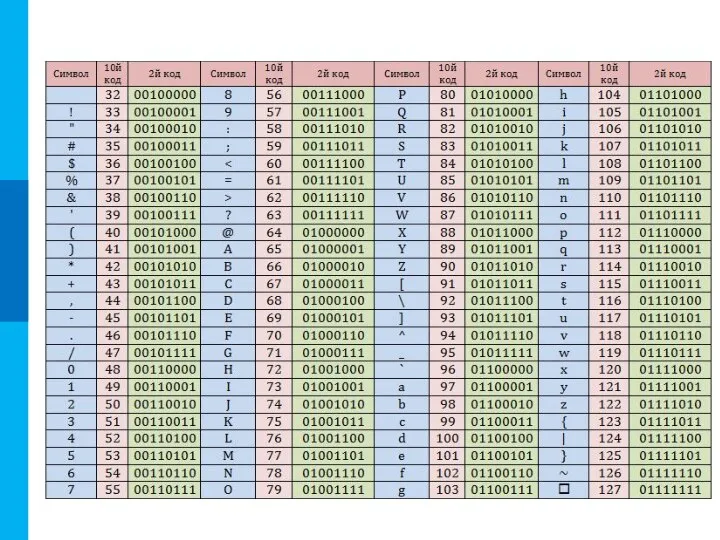
- 9. Кодировка ASCII American Standard Code for Information Interchange – американский стандартный код для обмена информацией, разработанный
- 10. Расширение кодировки ASCII Стандартная часть кода (0 … 127) Расширение ASCII (128 … 255) (буквы национального
- 11. Расширение кодировки ASCII
- 15. Стандарт Unicode Unicode — это «уникальный код для любого символа, независимо от платформы, независимо от программы,
- 16. Клавиатуры некоторых стран мира
- 17. Кодировки стандарта Unicode Для представления символов в памяти компьютера в стандарте Unicode имеется несколько кодировок. Кодировка
- 18. Информационный объем сообщения Информационным объёмом текстового сообще-ния называется количество бит (байт, килобайт, мегабайт и т. д.),
- 19. Вопросы и задания В Советском энциклопедическом словаре (1983 года издания) 1600 страниц. На одной странице размещается
- 20. Самое главное Текстовая информация по своей природе дискретна, так как представляется последовательностью отдельных символов. В памяти
- 21. Самое главное В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode (Юникод), позволяющий
- 23. Вопросы и задания Задание 1. Представьте в кодировке ASCII текст Happy New Year! а) шестнадцатеричным кодом
- 24. Вопросы и задания Задание 3. В 15-м издании энциклопедии Britannica 32 тома, в каждом из которых
- 25. Практическая работа Стр. 206 № 6 устно № 7 практическая работа № 2,3 самостоятельная работа
- 27. Скачать презентацию


Слайд 4…
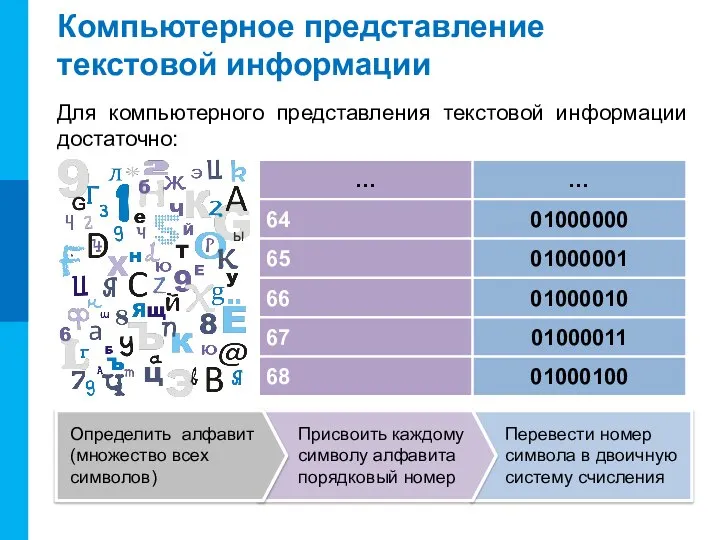
64
65
66
67
68
…
01000000
01000001
01000010
01000011
01000100
Компьютерное представление текстовой информации
Для компьютерного представления текстовой информации достаточно:
…
64
65
66
67
68
…
01000000
01000001
01000010
01000011
01000100
Компьютерное представление текстовой информации
Для компьютерного представления текстовой информации достаточно:

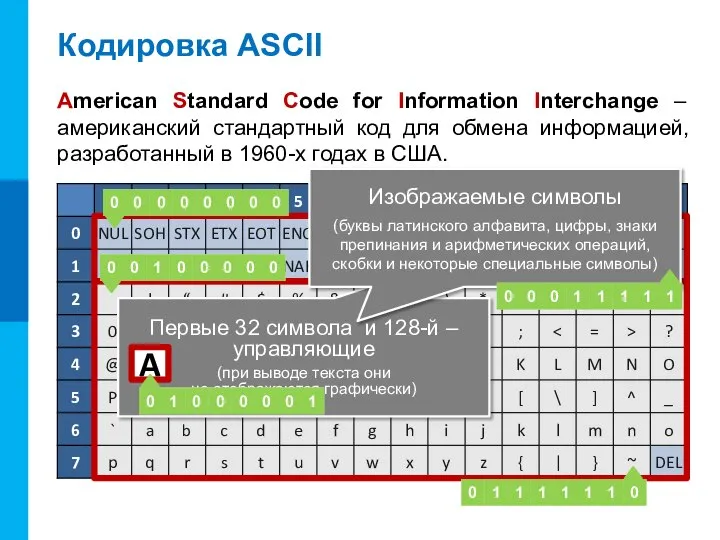
Слайд 9Кодировка ASCII
American Standard Code for Information Interchange – американский стандартный код для
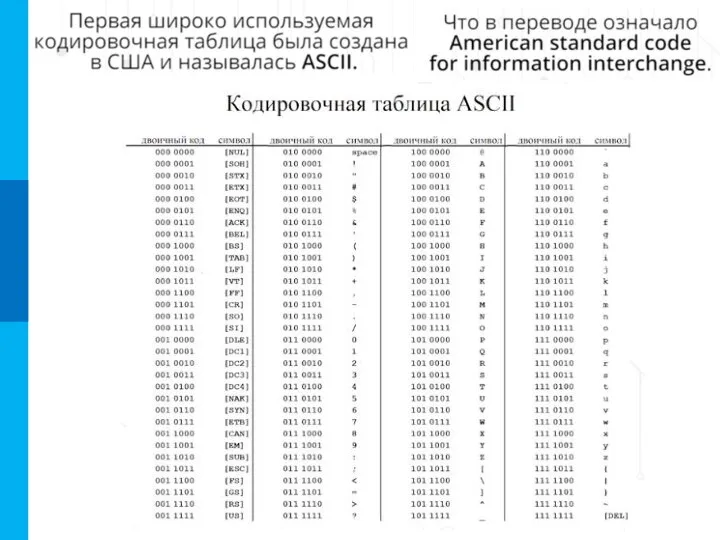
Кодировка ASCII
American Standard Code for Information Interchange – американский стандартный код для
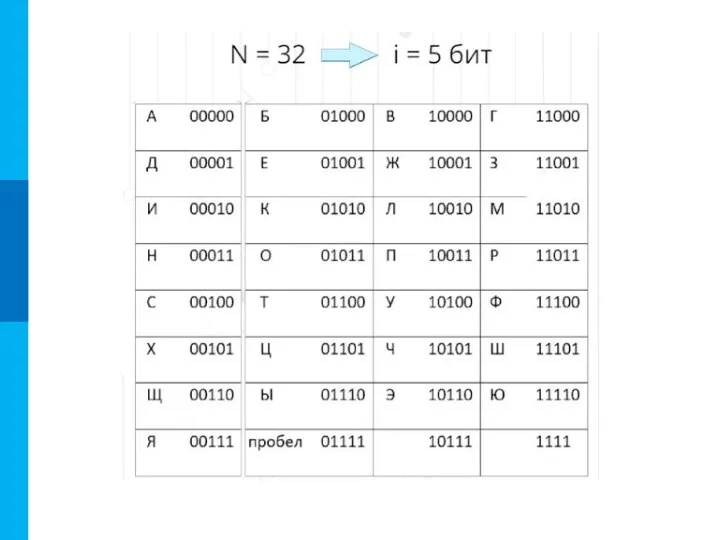
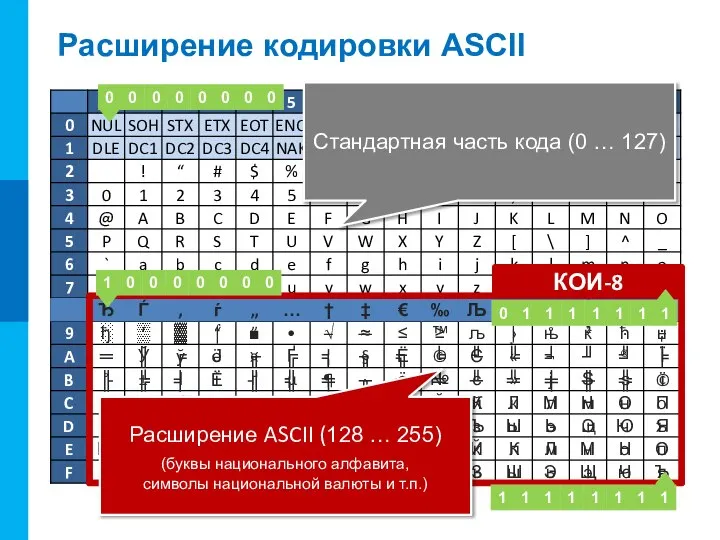
Слайд 10Расширение кодировки ASCII
Стандартная часть кода (0 … 127)
Расширение ASCII (128 … 255)
(буквы
Расширение кодировки ASCII
Стандартная часть кода (0 … 127)
Расширение ASCII (128 … 255)
(буквы
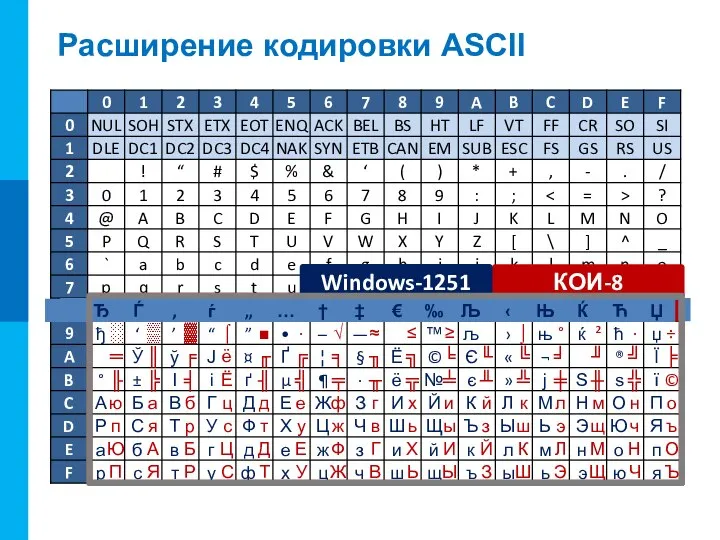
Слайд 11Расширение кодировки ASCII
Расширение кодировки ASCII



Слайд 15Стандарт Unicode
Unicode — это «уникальный код для любого символа, независимо от платформы,
Стандарт Unicode
Unicode — это «уникальный код для любого символа, независимо от платформы,

Слайд 16Клавиатуры некоторых стран мира
Клавиатуры некоторых стран мира

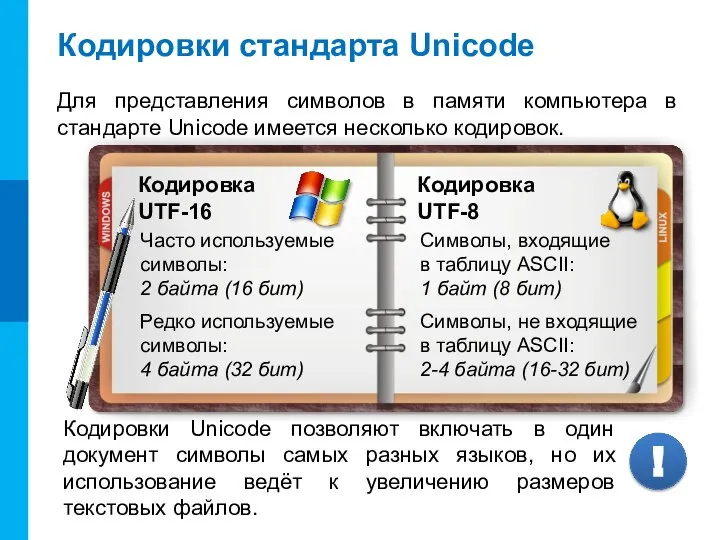
Слайд 17Кодировки стандарта Unicode
Для представления символов в памяти компьютера в стандарте Unicode имеется
Кодировки стандарта Unicode
Для представления символов в памяти компьютера в стандарте Unicode имеется
Слайд 18Информационный объем сообщения
Информационным объёмом текстового сообще-ния называется количество бит (байт, килобайт, мегабайт
Информационный объем сообщения
Информационным объёмом текстового сообще-ния называется количество бит (байт, килобайт, мегабайт

Слайд 19Вопросы и задания
В Советском энциклопедическом словаре (1983 года издания) 1600 страниц. На
Вопросы и задания
В Советском энциклопедическом словаре (1983 года издания) 1600 страниц. На

Слайд 20Самое главное
Текстовая информация по своей природе дискретна, так как представляется последовательностью отдельных
Самое главное
Текстовая информация по своей природе дискретна, так как представляется последовательностью отдельных

Слайд 21Самое главное
В 1991 году был разработан новый стандарт кодирования символов, получивший название
Самое главное
В 1991 году был разработан новый стандарт кодирования символов, получивший название

Слайд 23Вопросы и задания
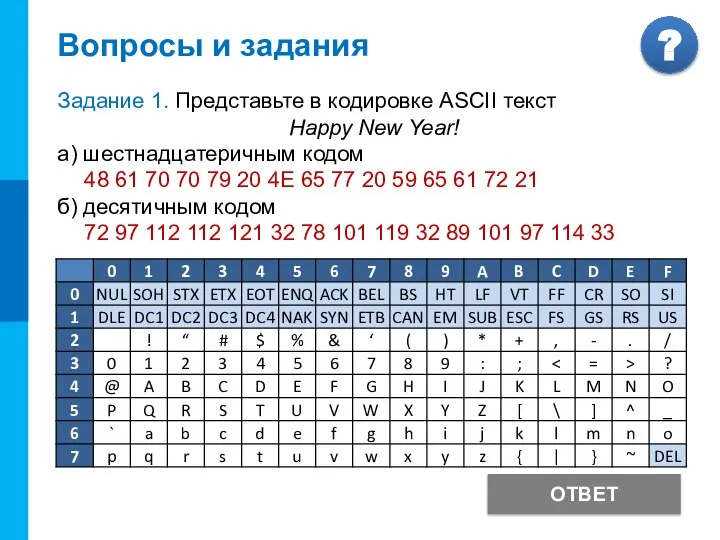
Задание 1. Представьте в кодировке ASCII текст
Happy New Year!
а) шестнадцатеричным
Вопросы и задания
Задание 1. Представьте в кодировке ASCII текст
Happy New Year!
а) шестнадцатеричным
Слайд 24Вопросы и задания
Задание 3. В 15-м издании энциклопедии Britannica 32 тома, в
Вопросы и задания
Задание 3. В 15-м издании энциклопедии Britannica 32 тома, в

Слайд 25Практическая работа
Стр. 206
№ 6 устно
№ 7 практическая работа
№ 2,3 самостоятельная работа
Практическая работа
Стр. 206
№ 6 устно
№ 7 практическая работа
№ 2,3 самостоятельная работа

 Алгоритмы разделения секрета
Алгоритмы разделения секрета Формульная зависимость в графическом виде
Формульная зависимость в графическом виде Группа R&D и облачной интеграции
Группа R&D и облачной интеграции О возможности выгодных путешествий
О возможности выгодных путешествий Программирование на языке Паскаль
Программирование на языке Паскаль Разработка веб-приложения для автоматизации обработки данных тестирования учащихся
Разработка веб-приложения для автоматизации обработки данных тестирования учащихся Креатив в Инстаграм
Креатив в Инстаграм Портал Zakupay.pro
Портал Zakupay.pro Информационные процессы. Обработка информации. 7 класс
Информационные процессы. Обработка информации. 7 класс Нумерация договоров и заказов в рамках ТО АМС
Нумерация договоров и заказов в рамках ТО АМС Решение задач с одномерным массивом
Решение задач с одномерным массивом Информационные технологии в индустрии полимеров. Практическое занятие 2
Информационные технологии в индустрии полимеров. Практическое занятие 2 Курсы по Blender в skullbox
Курсы по Blender в skullbox Шаблоны День Народного Единства
Шаблоны День Народного Единства Системы счисления
Системы счисления Анимация в GIMPг
Анимация в GIMPг Лидеры рунета: собственность и финансы
Лидеры рунета: собственность и финансы Компьютерные вирусы и их классификация
Компьютерные вирусы и их классификация HTML
HTML Информатика
Информатика Технология обработки подготовленных конфиденциальных документов. Практика 2. ЗиОДОД
Технология обработки подготовленных конфиденциальных документов. Практика 2. ЗиОДОД Работа с таблицами (10 класс)
Работа с таблицами (10 класс) Использование в работе учителя начальных классов информационно образовательной среды Учи.ру
Использование в работе учителя начальных классов информационно образовательной среды Учи.ру Лекция 11. Статические переменные. Динамическая информация о типах. Семантика перемещения
Лекция 11. Статические переменные. Динамическая информация о типах. Семантика перемещения 8-3-1
8-3-1 Алгоритмические языки и программирование
Алгоритмические языки и программирование Виртуальный тур
Виртуальный тур Модели и задачи Data Mining
Модели и задачи Data Mining