- 2_Семинар OMP

Содержание
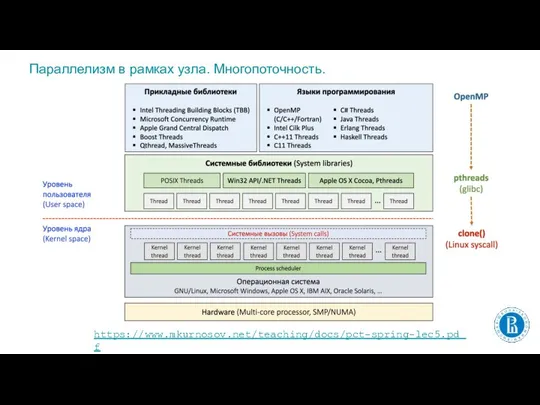
- 2. Параллелизм в рамках узла. Многопоточность. https://www.mkurnosov.net/teaching/docs/pct-spring-lec5.pdf
- 3. Системные вызовы. Разделение ресурсов. #include pid_t fork(void); Создание процессах-потомка посредством копирования с разделением ресурсов: Создание потомка
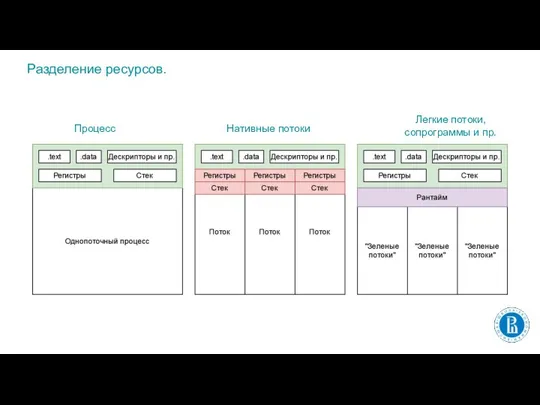
- 4. Разделение ресурсов. Процесс Нативные потоки Легкие потоки, сопрограммы и пр.
- 5. Потоки POSIX. pthread_t — идентификатор потока; pthread_attr_t — перечень атрибутов потока #include int pthread_create(pthread_t *thread, const
- 6. Поддержка многопоточности в современном C++.
- 7. #include #include // N N+1 N+2 ... M void thread_function(int N, int M, int64_t *sum) {
- 8. POSIX mutex pthread_mutex_t int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr); int pthread_mutex_destroy(pthread_mutex_t *mutex); int pthread_mutex_lock(pthread_mutex_t *mutex); int
- 9. OpenMP - высокоуровневый API для многопоточного программирования на C, C++ и Fortran OpenMP 1.0 - октябрь
- 10. Как это выглядит? распараллеливание осуществляется с помощью директив компилятора: #pragma omp область действия директивы - блок
- 11. (не)последовательность исполнения в OpenMP
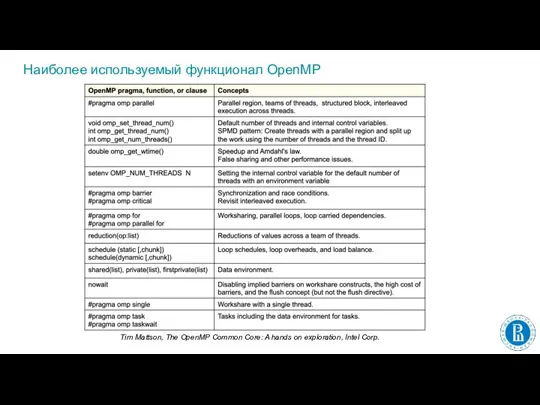
- 12. Наиболее используемый функционал OpenMP Tim Mattson, The OpenMP Common Core: A hands on exploration, Intel Corp.
- 13. Пример 1. Последовательная сумма массива (редукция).
- 14. Пример 2. Редукция с parallel for.
- 15. Пример 3. Редукция с parallel for и критической секцией.
- 16. Пример 4. Редукция с omp parallel for и reduction.
- 17. Сравнение производительности. Закон Амдала. Масштабируемость.
- 18. Домашнее Задание 1. Параллельное умножение матриц (DGEMM) Реализовать параллельную реализацию умножения матриц DGEMM (Double precision General
- 19. Домашнее Задание 1. Замечания. alpha = 1 и beta = 0; элементы A, B и C
- 20. Домашнее Задание 1. Замечания. ДЗ1 должно быть реализовано на языке C; код должен быть оформлен в
- 22. Скачать презентацию
Слайд 2Параллелизм в рамках узла. Многопоточность.
https://www.mkurnosov.net/teaching/docs/pct-spring-lec5.pdf
Параллелизм в рамках узла. Многопоточность.
https://www.mkurnosov.net/teaching/docs/pct-spring-lec5.pdf
Слайд 3Системные вызовы. Разделение ресурсов.
#include
pid_t fork(void);
Создание процессах-потомка посредством копирования с разделением
Системные вызовы. Разделение ресурсов.
#include Создание процессах-потомка посредством копирования с разделением

Слайд 4Разделение ресурсов.
Процесс
Нативные потоки
Легкие потоки, сопрограммы и пр.
Разделение ресурсов.
Процесс
Нативные потоки
Легкие потоки, сопрограммы и пр.
Слайд 5Потоки POSIX.
pthread_t — идентификатор потока;
pthread_attr_t — перечень атрибутов потока
#include
int pthread_create(pthread_t *thread,
Потоки POSIX.
pthread_t — идентификатор потока;
pthread_attr_t — перечень атрибутов потока
#include
int pthread_create(pthread_t *thread,

Слайд 6Поддержка многопоточности в современном C++.
Поддержка многопоточности в современном C++.
Слайд 7#include
#include
// N N+1 N+2 ... M
void thread_function(int N, int M,
#include
#include
// N N+1 N+2 ... M
void thread_function(int N, int M,

Слайд 8POSIX mutex
pthread_mutex_t
int pthread_mutex_init(pthread_mutex_t *mutex,
const pthread_mutexattr_t *attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t
POSIX mutex
pthread_mutex_t
int pthread_mutex_init(pthread_mutex_t *mutex,
const pthread_mutexattr_t *attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t

Слайд 9OpenMP - высокоуровневый API для многопоточного программирования на C, C++ и Fortran
OpenMP
OpenMP - высокоуровневый API для многопоточного программирования на C, C++ и Fortran
OpenMP

Слайд 10Как это выглядит?
распараллеливание осуществляется с помощью директив компилятора:
#pragma omp
область
Как это выглядит?
распараллеливание осуществляется с помощью директив компилятора:
#pragma omp
область

Слайд 11(не)последовательность исполнения в OpenMP
(не)последовательность исполнения в OpenMP

Слайд 12Наиболее используемый функционал OpenMP
Tim Mattson, The OpenMP Common Core: A hands on
Наиболее используемый функционал OpenMP
Tim Mattson, The OpenMP Common Core: A hands on
Слайд 13Пример 1. Последовательная сумма массива (редукция).
Пример 1. Последовательная сумма массива (редукция).

Слайд 14Пример 2. Редукция с parallel for.
Пример 2. Редукция с parallel for.

Слайд 15Пример 3. Редукция с parallel for и критической секцией.
Пример 3. Редукция с parallel for и критической секцией.

Слайд 16Пример 4. Редукция с omp parallel for и reduction.
Пример 4. Редукция с omp parallel for и reduction.

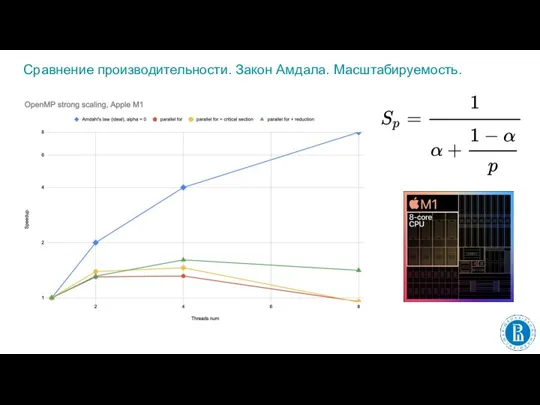
Слайд 17Сравнение производительности. Закон Амдала. Масштабируемость.
Сравнение производительности. Закон Амдала. Масштабируемость.
Слайд 18Домашнее Задание 1. Параллельное умножение матриц (DGEMM)
Реализовать параллельную реализацию умножения матриц DGEMM
Домашнее Задание 1. Параллельное умножение матриц (DGEMM)
Реализовать параллельную реализацию умножения матриц DGEMM

Слайд 19Домашнее Задание 1. Замечания.
alpha = 1 и beta = 0;
элементы A,
Домашнее Задание 1. Замечания.
alpha = 1 и beta = 0;
элементы A,

Слайд 20Домашнее Задание 1. Замечания.
ДЗ1 должно быть реализовано на языке C;
код должен быть
Домашнее Задание 1. Замечания.
ДЗ1 должно быть реализовано на языке C;
код должен быть

 Восхождение на гору Информация
Восхождение на гору Информация Конструкции структурного программирования в Си
Конструкции структурного программирования в Си Adobe InDesign. Быстрое погружение
Adobe InDesign. Быстрое погружение 3D-моделирование. Знакомство с TinkerCAD
3D-моделирование. Знакомство с TinkerCAD Понятие массива. Одномерные и двумерные массивы
Понятие массива. Одномерные и двумерные массивы Application Software
Application Software Unity (cross-platform game engine)
Unity (cross-platform game engine) Front-end. Back-end
Front-end. Back-end Принципы ООП
Принципы ООП Организация ввода и вывода данных начала программирования
Организация ввода и вывода данных начала программирования Машинный перевод
Машинный перевод Роль информатики и информационных технологий в современном мире
Роль информатики и информационных технологий в современном мире Стимулирование развития инноваций
Стимулирование развития инноваций Циклические процессы. Операторы циклов в С+
Циклические процессы. Операторы циклов в С+ Использование видеоматериалов YouTube в целях повышения мотивации к изучению немецкого языка
Использование видеоматериалов YouTube в целях повышения мотивации к изучению немецкого языка Сфера деятельности Adobe Systems
Сфера деятельности Adobe Systems Работа с графическими объектами в Microsoft Word
Работа с графическими объектами в Microsoft Word ИНФОРМАТИКА 11
ИНФОРМАТИКА 11 This is Your Presentation Title
This is Your Presentation Title Quiz in Java Script
Quiz in Java Script Программный комплекс ИС БТИ
Программный комплекс ИС БТИ Администрирование вычислительных систем и сетей
Администрирование вычислительных систем и сетей Продвижение библиотеки в социальных сетях. Всероссийский конкурс
Продвижение библиотеки в социальных сетях. Всероссийский конкурс Новые учебно-методические пособия для изучающих 1С:Предприятию
Новые учебно-методические пособия для изучающих 1С:Предприятию Приложения для изучения иностранных языков для iOS и Android
Приложения для изучения иностранных языков для iOS и Android Наглядные формы представления информации
Наглядные формы представления информации Магістерська робота на тему: Організація обміну даних між пристроями розумного будинку
Магістерська робота на тему: Організація обміну даних між пристроями розумного будинку ГИС_Введение_Лекция 6 (1)
ГИС_Введение_Лекция 6 (1)