- Абстрактные типы данных. Структуры данных

Содержание
- 2. Приоритетная очередь (priority queue) Абстрактные типы данных
- 3. Приоритетная очередь (англ. priority queue) Предположим, что для каждого элемента определён некоторый приоритет. В простейшем случае
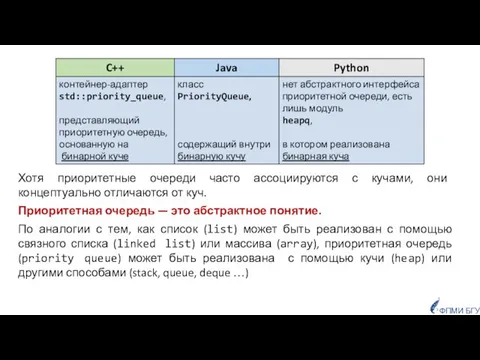
- 4. Хотя приоритетные очереди часто ассоциируются с кучами, они концептуально отличаются от куч. Приоритетная очередь — это
- 5. Бинарная куча (binary heap) Биномиальная куча (binomial heap) Куча Фибоначчи (Fibonacci heap ) Структуры данных
- 6. Куча (англ. heap) — специализированная древовидная структура данных, которая удовлетворяет свойству кучи. В вершинах древовидной структуры
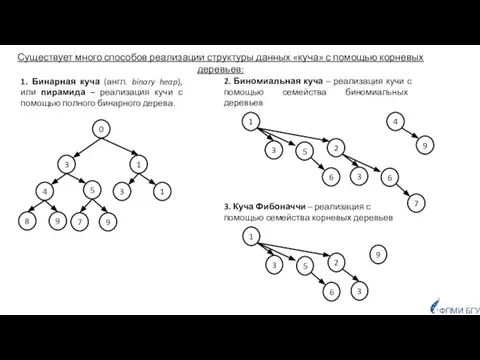
- 7. Существует много способов реализации структуры данных «куча» с помощью корневых деревьев: 1. Бинарная куча (англ. binary
- 8. GetMin() — поиск минимального ключа; IncreaseKey DecreaseKey — модификация ключа вершины на заданную величину (предполагается, что
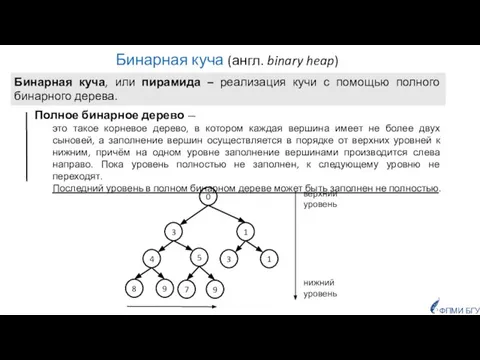
- 9. Бинарная куча (англ. binary heap) Полное бинарное дерево — это такое корневое дерево, в котором каждая
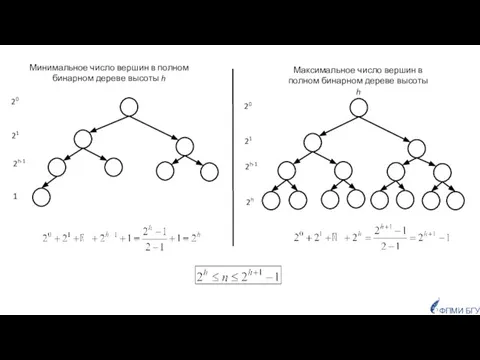
- 10. 20 21 20 21 Максимальное число вершин в полном бинарном дереве высоты h Минимальное число вершин
- 11. Высота h полного бинарного дерева, содержащего n вершин, — O(log n).
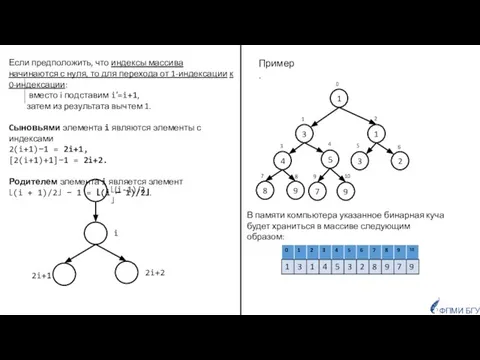
- 12. В памяти компьютера полное бинарное дерево легко реализуется с помощью массива. Если предположить, что индексы массива
- 13. В памяти компьютера указанное бинарная куча будет храниться в массиве следующим образом: Если предположить, что индексы
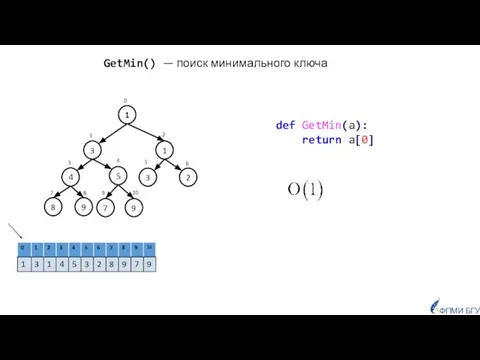
- 14. GetMin() — поиск минимального ключа 1 3 2 3 5 4 1 9 9 7 8
- 15. ExtractMin() — удаление минимального ключа 1 3 2 3 5 4 1 9 9 7 8
- 16. def ExtractMin(a): a[0] = a[len(a) - 1] a.pop() i = 0 while 2 * i +
- 17. ExtractMin() — удаление минимального ключа
- 18. Insert(x) — добавление ключа x 1 3 2 3 5 4 1 9 9 7 8
- 19. def Insert(a, x): a.append(x) i = len(a) - 1 while i > 0: j = (i
- 20. Insert(x) — добавление ключа x
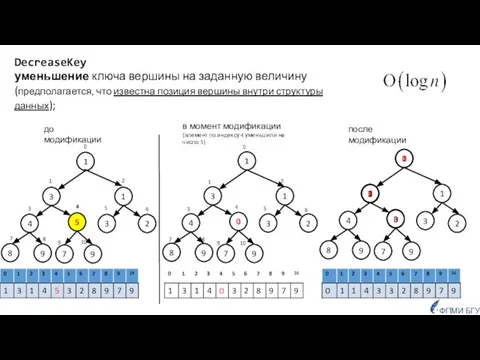
- 21. DecreaseKey уменьшение ключа вершины на заданную величину (предполагается, что известна позиция вершины внутри структуры данных); 1
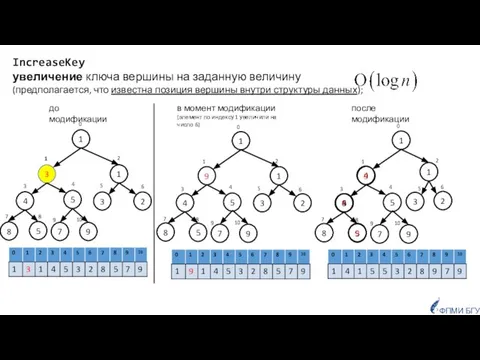
- 22. IncreaseKey увеличение ключа вершины на заданную величину (предполагается, что известна позиция вершины внутри структуры данных); 1
- 23. DecreaseKey уменьшение ключа вершины на заданную величину IncreaseKey увеличение ключа вершины на заданную величину предполагается, что
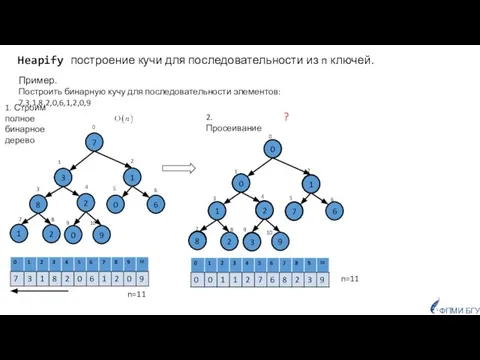
- 24. Heapify построение кучи для последовательности из n ключей. n=11 1. Строим полное бинарное дерево 1 3
- 25. Для того, чтобы оценить время работы построения бинарной кучи для последовательности из n элементов, необходимо оценить
- 26. Так как число вершин полного бинарного дерева высоты h удовлетворяет неравенствам: Получаем оценку сверху на число
- 27. Heapify построение кучи для последовательности из n ключей:
- 28. GetMin() поиск минимального ключа; IncreaseKey DecreaseKey модификация ключа вершины на заданную величину (предполагается, что известна позиция
- 29. На практике бинарную кучу редко приходится реализовывать самостоятельно, поскольку готовые решения есть в стандартных библиотеках многих
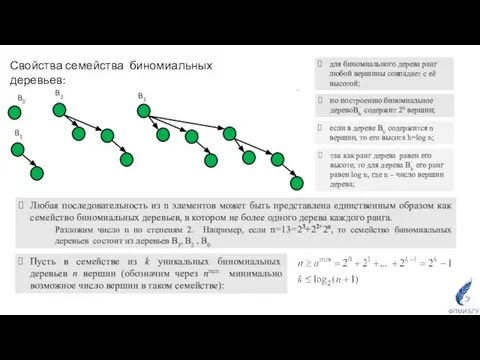
- 30. Биномиальная куча B0 B1 B2 B3 Семейство биномиальных деревьев: у биномиального дерева высоты h на глубине
- 31. Свойства семейства биномиальных деревьев: по построению биномиальное деревоBh содержит 2h вершин; для биномиального дерева ранг любой
- 32. Дополнительные вспомогательные операции link и cut, которые нужны для выполнения базовых операций x y x y
- 33. 1 0 4 3 5 4 9 7 8 2 7 Insert(x) — добавление ключа x.
- 34. 1 0 4 3 5 4 9 7 8 2 7 GetMin() — поиск минимального ключа;
- 35. 1 0 4 3 5 4 9 7 8 2 7 ExtractMin() — удаление минимального ключа;
- 36. Heapify — построение кучи для последовательности из n ключей Биномиальную кучу будем строить вызовом n раз
- 37. то время работы алгоритма Heapify построения кучи для последовательности из n ключей в худшем случае есть
- 38. Предполагается, что задана позиция вершины внутри структуры данных. 0 4 3 5 2 9 7 8
- 39. IncreaseKey(увеличение ключа) Увеличиваем ключ вершины x. Если после этого для x нарушается свойство кучи, то просеиваем
- 40. Увеличиваем ключ вершине x. Время работы алгоритма: Если инвариант 1 для x НЕ выполняется, то 3.1.
- 41. 0 4 3 5 2 9 7 8 1 6 7 8 2 4 5 6
- 42. GetMin() — поиск минимального ключа; IncreaseKey DecreaseKey — модификация ключа вершины на заданную величину (предполагается, что
- 43. Куча Фибоначчи (Fibonacci heap) была предложена Майклом Фридманом и Робертом Тарьяном в 1984 году.
- 44. Куча Фибоначчи – это семейство корневых деревьев, для которого выполняются следующие свойства (инварианты): Инвариант 1. Каждая
- 45. DecreaseKey (уменьшение ключа) -1 3 5 2 9 7 8 1 7 8 2 5 6
- 46. 3 5 2 9 7 8 1 7 8 2 9 9 cut(7) cut'(2) cut'(1) Восстановление
- 47. Предположим, что мы выполнили некоторое число исходных операций cut, а они привели к выполнению серии порождённых
- 48. Усреднённая оценка трудоемкости операции добавления нового элемента: Усреднённая оценка трудоемкости операции уменьшения ключа (задана ссылка на
- 49. Применение на практике
- 50. ExtractMin() — удаление минимального ключа; Heapify — строим бинарную кучу для последовательности из n ключей. 2.
- 51. C++ std::sort() Основой служит алгоритм быстрой сортировки – модифицированный QuickSort, он же IntroSort, разработанный специально для
- 52. Сжатие информации. Алгоритм префиксного кодирования Хаффмана
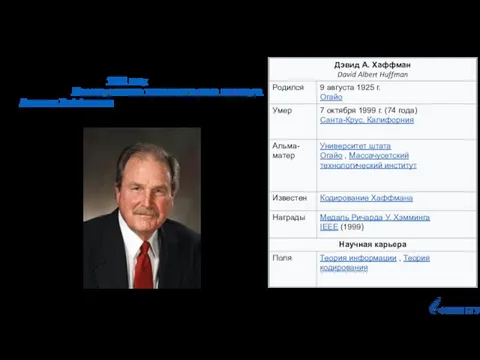
- 53. Метод разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом при написании им курсовой работы
- 54. На вход поступает текст. По тексту строится таблица частот встречаемости символов. Строится дерево кодирования Хаффмана (Н-дерево).
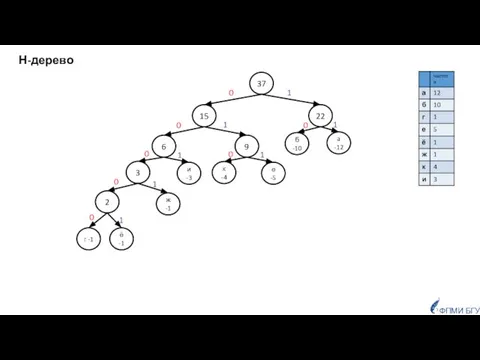
- 55. Каждому символу ставим в соответствие узел дерева, вес узла – частота встречаемости символа в тексте. Полагаем
- 56. 2 ё -1 г -1 и -3 6 к -4 3 ж -1 б -10 15
- 57. 2 ё 1 г 1 и 3 6 к 4 3 ж 1 б 10 15
- 58. Текст : кажжекaa … Закодированный текст: Кодирование: (010)(11 )( 0001)(0001)(011)(010)(11)(11) к а ж ж е к
- 59. 2 ё -1 г -1 и -3 6 к -4 3 ж -1 б -10 15
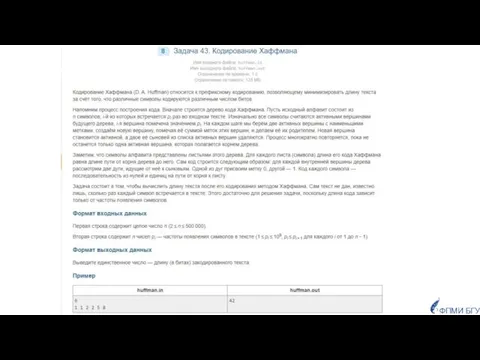
- 60. ЗАДАЧА На вход поступает таблица частот встречаемости символов текста, который будет закодирован классическим алгоритмом Хаффмана. Вам
- 61. 2 ё -1 г -1 и -3 6 к -4 3 ж -1 б -10 15
- 62. Какое время работы у Вашего «наивного алгоритма»? Разработайте более эффективный алгоритм и проверьте себя, решив эту
- 64. ??? ЗАДАНИЕ Выполнить общие задачи в iRunner Тема 3. Структуры данных 0.3. Бинарная куча (проверка на
- 66. Скачать презентацию

Слайд 3Приоритетная очередь (англ. priority queue)
Предположим, что для каждого элемента определён некоторый приоритет.
Приоритетная очередь (англ. priority queue)
Предположим, что для каждого элемента определён некоторый приоритет.

Слайд 4Хотя приоритетные очереди часто ассоциируются с кучами, они концептуально отличаются от куч.
Хотя приоритетные очереди часто ассоциируются с кучами, они концептуально отличаются от куч.
Слайд 5Бинарная куча (binary heap)
Биномиальная куча (binomial heap)
Куча Фибоначчи (Fibonacci heap )
Структуры данных
Бинарная куча (binary heap)
Биномиальная куча (binomial heap)
Куча Фибоначчи (Fibonacci heap )
Структуры данных

Слайд 6Куча (англ. heap) — специализированная древовидная структура данных, которая удовлетворяет свойству кучи.
Куча (англ. heap) — специализированная древовидная структура данных, которая удовлетворяет свойству кучи.

Слайд 7Существует много способов реализации структуры данных «куча» с помощью корневых деревьев:
1.
Существует много способов реализации структуры данных «куча» с помощью корневых деревьев:
1.
Слайд 8GetMin() — поиск минимального ключа;
IncreaseKey
DecreaseKey
— модификация ключа вершины на заданную
GetMin() — поиск минимального ключа;
IncreaseKey
DecreaseKey
— модификация ключа вершины на заданную

Слайд 9Бинарная куча (англ. binary heap)
Полное бинарное дерево —
это такое корневое дерево,
Бинарная куча (англ. binary heap)
Полное бинарное дерево —
это такое корневое дерево,
Слайд 1020
21
20
21
Максимальное число вершин в полном бинарном дереве высоты h
Минимальное число вершин в
20
21
20
21
Максимальное число вершин в полном бинарном дереве высоты h
Минимальное число вершин в
Слайд 11Высота h полного бинарного дерева, содержащего n вершин, — O(log n).
Высота h полного бинарного дерева, содержащего n вершин, — O(log n).

Слайд 12В памяти компьютера полное бинарное дерево легко реализуется с помощью массива.
Если предположить,
В памяти компьютера полное бинарное дерево легко реализуется с помощью массива.
Если предположить,

Слайд 13В памяти компьютера указанное бинарная куча будет храниться в массиве следующим образом:
В памяти компьютера указанное бинарная куча будет храниться в массиве следующим образом:
Слайд 14GetMin() — поиск минимального ключа
1
3
2
3
5
4
1
9
9
7
8
def GetMin(a):
return a[0]
GetMin() — поиск минимального ключа
1
3
2
3
5
4
1
9
9
7
8
def GetMin(a):
return a[0]
Слайд 15ExtractMin() — удаление минимального ключа
1
3
2
3
5
4
1
9
9
7
8
n=11
a
i
n=10
1
3
2
3
5
4
9
9
7
8
n=10
1
9
2
9
ExtractMin() — удаление минимального ключа
1
3
2
3
5
4
1
9
9
7
8
n=11
a
i
n=10
1
3
2
3
5
4
9
9
7
8
n=10
1
9
2
9
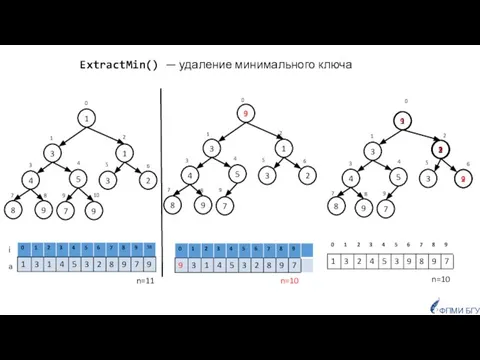
Слайд 16def ExtractMin(a):
a[0] = a[len(a) - 1]
a.pop()
i = 0
while
def ExtractMin(a):
a[0] = a[len(a) - 1]
a.pop()
i = 0
while
![def ExtractMin(a): a[0] = a[len(a) - 1] a.pop() i = 0 while](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/856419/slide-15.jpg)
Слайд 17ExtractMin() — удаление минимального ключа
ExtractMin() — удаление минимального ключа

Слайд 18Insert(x) — добавление ключа x
1
3
2
3
5
4
1
9
9
7
8
n=11
a
i
n=12
n=12
1
3
2
3
5
4
1
9
7
8
0
1
3
5
6
9
8
7
2
4
9
10
0
11
3
0
1
0
1
0
Insert(x) — добавление ключа x
1
3
2
3
5
4
1
9
9
7
8
n=11
a
i
n=12
n=12
1
3
2
3
5
4
1
9
7
8
0
1
3
5
6
9
8
7
2
4
9
10
0
11
3
0
1
0
1
0

Слайд 19def Insert(a, x):
a.append(x)
i = len(a) - 1
while i >
def Insert(a, x):
a.append(x)
i = len(a) - 1
while i >

Слайд 20Insert(x) — добавление ключа x
Insert(x) — добавление ключа x

Слайд 21DecreaseKey
уменьшение ключа вершины на заданную величину
(предполагается, что известна позиция вершины
DecreaseKey
уменьшение ключа вершины на заданную величину
(предполагается, что известна позиция вершины
Слайд 22IncreaseKey
увеличение ключа вершины на заданную величину
(предполагается, что известна позиция вершины
IncreaseKey
увеличение ключа вершины на заданную величину
(предполагается, что известна позиция вершины
Слайд 23DecreaseKey
уменьшение ключа вершины на заданную величину
IncreaseKey
увеличение ключа вершины
DecreaseKey
уменьшение ключа вершины на заданную величину
IncreaseKey
увеличение ключа вершины

Слайд 24Heapify построение кучи для последовательности из n ключей.
n=11
1. Строим полное бинарное дерево
1
3
6
0
8
7
2
9
0
1
2.
Heapify построение кучи для последовательности из n ключей.
n=11
1. Строим полное бинарное дерево
1
3
6
0
8
7
2
9
0
1
2.
Слайд 25Для того, чтобы оценить время работы построения бинарной кучи для последовательности из
Для того, чтобы оценить время работы построения бинарной кучи для последовательности из

Слайд 26Так как число вершин полного бинарного дерева высоты h удовлетворяет неравенствам:
Получаем оценку
Так как число вершин полного бинарного дерева высоты h удовлетворяет неравенствам:
Получаем оценку

Слайд 27Heapify построение кучи для последовательности из n ключей:
Heapify построение кучи для последовательности из n ключей:

Слайд 28GetMin()
поиск минимального ключа;
IncreaseKey
DecreaseKey
модификация ключа вершины на заданную величину
(предполагается,
GetMin()
поиск минимального ключа;
IncreaseKey
DecreaseKey
модификация ключа вершины на заданную величину
(предполагается,

Слайд 29На практике бинарную кучу редко приходится реализовывать самостоятельно, поскольку готовые решения есть
На практике бинарную кучу редко приходится реализовывать самостоятельно, поскольку готовые решения есть
Слайд 30Биномиальная куча
B0
B1
B2
B3
Семейство биномиальных деревьев:
у биномиального дерева высоты h на глубине d находится
Биномиальная куча
B0
B1
B2
B3
Семейство биномиальных деревьев:
у биномиального дерева высоты h на глубине d находится

Слайд 31Свойства семейства биномиальных деревьев:
по построению биномиальное деревоBh содержит 2h вершин;
для биномиального
Свойства семейства биномиальных деревьев:
по построению биномиальное деревоBh содержит 2h вершин;
для биномиального
Слайд 32Дополнительные вспомогательные операции link и cut,
которые нужны для выполнения базовых операций
x
y
x
y
+
link(x,y)
cut(y)
x
y
z
u
x
z
u
y
x≤y
Дополнительные вспомогательные операции link и cut,
которые нужны для выполнения базовых операций
x
y
x
y
+
link(x,y)
cut(y)
x
y
z
u
x
z
u
y
x≤y

Слайд 331
0
4
3
5
4
9
7
8
2
7
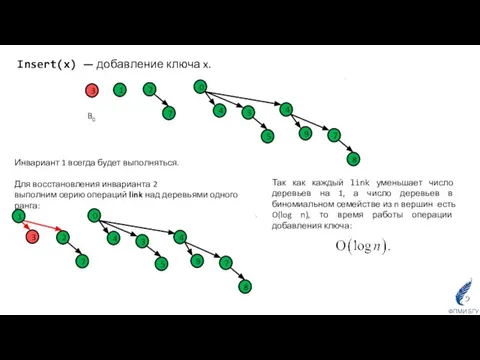
Insert(x) — добавление ключа x.
3
0
4
3
5
4
9
7
8
2
7
3
Инвариант 1 всегда будет выполняться.
Для восстановления
1
0
4
3
5
4
9
7
8
2
7
Insert(x) — добавление ключа x.
3
0
4
3
5
4
9
7
8
2
7
3
Инвариант 1 всегда будет выполняться.
Для восстановления
Слайд 341
0
4
3
5
4
9
7
8
2
7
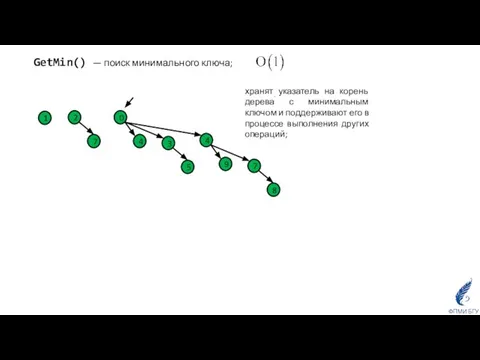
GetMin() — поиск минимального ключа;
хранят указатель на корень дерева с
1
0
4
3
5
4
9
7
8
2
7
GetMin() — поиск минимального ключа;
хранят указатель на корень дерева с
Слайд 351
0
4
3
5
4
9
7
8
2
7
ExtractMin() — удаление минимального ключа;
4
3
5
4
9
7
8
2
7
1
4
3
5
4
9
7
8
2
7
1) после серии
cut:
2) выполним серию
1
0
4
3
5
4
9
7
8
2
7
ExtractMin() — удаление минимального ключа;
4
3
5
4
9
7
8
2
7
1
4
3
5
4
9
7
8
2
7
1) после серии
cut:
2) выполним серию

Слайд 36Heapify — построение кучи для последовательности из n ключей
Биномиальную кучу будем строить
Heapify — построение кучи для последовательности из n ключей
Биномиальную кучу будем строить

Слайд 37то время работы алгоритма Heapify построения кучи для последовательности из n ключей
то время работы алгоритма Heapify построения кучи для последовательности из n ключей

Слайд 38Предполагается, что задана позиция вершины внутри структуры данных.
0
4
3
5
2
9
7
8
DecreaseKey (уменьшение ключа)
Уменьшаем ключ
Предполагается, что задана позиция вершины внутри структуры данных.
0
4
3
5
2
9
7
8
DecreaseKey (уменьшение ключа)
Уменьшаем ключ

Слайд 39IncreaseKey(увеличение ключа)
Увеличиваем ключ вершины x.
Если после этого для x нарушается
IncreaseKey(увеличение ключа)
Увеличиваем ключ вершины x.
Если после этого для x нарушается

Слайд 40Увеличиваем ключ вершине x.
Время работы алгоритма:
Если инвариант 1 для x
Увеличиваем ключ вершине x.
Время работы алгоритма:
Если инвариант 1 для x

Слайд 410
4
3
5
2
9
7
8
1
6
7
8
2
4
5
6
3
4
3
5
2
9
7
8
6
7
8
4
5
6
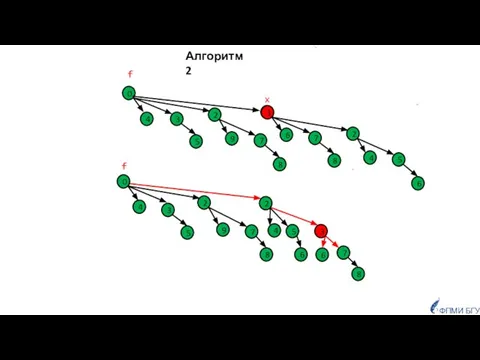
Алгоритм 2
f
x
f
3
2
0
0
4
3
5
2
9
7
8
1
6
7
8
2
4
5
6
3
4
3
5
2
9
7
8
6
7
8
4
5
6
Алгоритм 2
f
x
f
3
2
0
Слайд 42GetMin() — поиск минимального ключа;
IncreaseKey
DecreaseKey
— модификация ключа вершины на заданную
GetMin() — поиск минимального ключа;
IncreaseKey
DecreaseKey
— модификация ключа вершины на заданную

Слайд 43Куча Фибоначчи
(Fibonacci heap)
была предложена Майклом Фридманом
и
Робертом Тарьяном
в 1984 году.
Куча Фибоначчи
(Fibonacci heap)
была предложена Майклом Фридманом
и
Робертом Тарьяном
в 1984 году.
Слайд 44Куча Фибоначчи – это семейство корневых деревьев, для которого выполняются следующие свойства
Куча Фибоначчи – это семейство корневых деревьев, для которого выполняются следующие свойства

Слайд 45DecreaseKey (уменьшение ключа)
-1
3
5
2
9
7
8
1
7
8
2
5
6
0
операции cut, которые выполняются для восстановления инварианта 1 будем
DecreaseKey (уменьшение ключа)
-1
3
5
2
9
7
8
1
7
8
2
5
6
0
операции cut, которые выполняются для восстановления инварианта 1 будем

Слайд 463
5
2
9
7
8
1
7
8
2
9
9
cut(7)
cut'(2)
cut'(1)
Восстановление инварианта 3:
серия порожденных cut'
Восстановление инварианта 2:
серия операций link над корневыми деревьями
3
5
2
9
7
8
1
7
8
2
9
9
cut(7)
cut'(2)
cut'(1)
Восстановление инварианта 3:
серия порожденных cut'
Восстановление инварианта 2:
серия операций link над корневыми деревьями

Слайд 47Предположим, что мы выполнили некоторое число исходных операций cut, а они привели
Предположим, что мы выполнили некоторое число исходных операций cut, а они привели

Слайд 48Усреднённая оценка трудоемкости операции добавления нового элемента:
Усреднённая оценка трудоемкости операции уменьшения
Усреднённая оценка трудоемкости операции добавления нового элемента:
Усреднённая оценка трудоемкости операции уменьшения

Слайд 49Применение на практике
Применение на практике

Слайд 50ExtractMin() — удаление минимального ключа;
Heapify —
строим бинарную кучу для последовательности
ExtractMin() — удаление минимального ключа;
Heapify —
строим бинарную кучу для последовательности

Слайд 51C++ std::sort()
Основой служит алгоритм быстрой сортировки – модифицированный QuickSort, он же
C++ std::sort()
Основой служит алгоритм быстрой сортировки – модифицированный QuickSort, он же

Слайд 52Сжатие информации.
Алгоритм префиксного кодирования Хаффмана
Сжатие информации.
Алгоритм префиксного кодирования Хаффмана

Слайд 53Метод разработан в 1952 году
аспирантом Массачусетского технологического института
Дэвидом Хаффманом при написании им курсовой работы
Метод разработан в 1952 году
аспирантом Массачусетского технологического института
Дэвидом Хаффманом при написании им курсовой работы
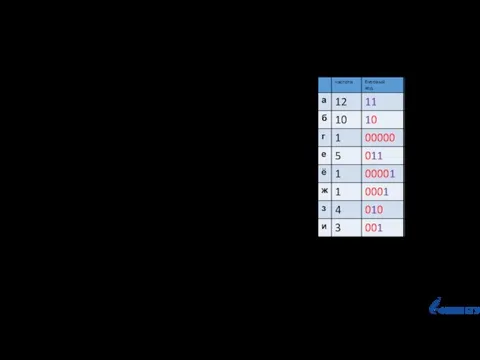
Слайд 54На вход поступает текст. По тексту строится таблица частот встречаемости символов.
Строится
На вход поступает текст. По тексту строится таблица частот встречаемости символов.
Строится
Слайд 55Каждому символу ставим в соответствие узел дерева, вес узла – частота встречаемости
Каждому символу ставим в соответствие узел дерева, вес узла – частота встречаемости

Слайд 562
ё -1
г -1
и -3
6
к -4
3
ж -1
б -10
15
9
е -5
a -12
22
37
0
0
0
0
0
0
0
1
1
1
1
1
1
1
Н-дерево
2
ё -1
г -1
и -3
6
к -4
3
ж -1
б -10
15
9
е -5
a -12
22
37
0
0
0
0
0
0
0
1
1
1
1
1
1
1
Н-дерево
Слайд 572
ё
1
г
1
и
3
6
к
4
3
ж 1
б
10
15
9
е
5
a
12
22
37
0
0
0
0
0
0
0
1
1
1
1
1
1
1
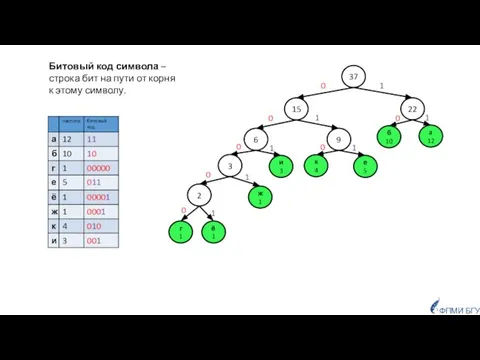
Битовый код символа –
строка бит
2
ё
1
г
1
и
3
6
к
4
3
ж 1
б
10
15
9
е
5
a
12
22
37
0
0
0
0
0
0
0
1
1
1
1
1
1
1
Битовый код символа –
строка бит
Слайд 58Текст :
кажжекaa …
Закодированный текст:
Кодирование:
(010)(11 )( 0001)(0001)(011)(010)(11)(11)
к а ж ж
Текст :
кажжекaa …
Закодированный текст:
Кодирование:
(010)(11 )( 0001)(0001)(011)(010)(11)(11)
к а ж ж

Слайд 592
ё -1
г -1
и -3
6
к -4
3
ж -1
б -10
15
9
е -5
a -12
22
37
0
0
0
0
0
0
0
1
1
1
1
1
1
1
Декодирование:
для декодирования требуется
2
ё -1
г -1
и -3
6
к -4
3
ж -1
б -10
15
9
е -5
a -12
22
37
0
0
0
0
0
0
0
1
1
1
1
1
1
1
Декодирование:
для декодирования требуется

Слайд 60ЗАДАЧА
На вход поступает таблица частот встречаемости символов текста, который будет закодирован классическим
ЗАДАЧА
На вход поступает таблица частот встречаемости символов текста, который будет закодирован классическим

Слайд 612
ё -1
г -1
и -3
6
к -4
3
ж -1
б -10
15
9
е -5
a -12
22
37
0
0
0
0
0
0
0
1
1
1
1
1
1
1
по таблице частот строим
2
ё -1
г -1
и -3
6
к -4
3
ж -1
б -10
15
9
е -5
a -12
22
37
0
0
0
0
0
0
0
1
1
1
1
1
1
1
по таблице частот строим

Слайд 62Какое время работы у Вашего «наивного алгоритма»?
Разработайте более эффективный алгоритм и проверьте
Какое время работы у Вашего «наивного алгоритма»?
Разработайте более эффективный алгоритм и проверьте
Слайд 64???
ЗАДАНИЕ
Выполнить общие задачи в iRunner
Тема 3. Структуры данных
0.3. Бинарная куча (проверка на соответствие
???
ЗАДАНИЕ
Выполнить общие задачи в iRunner
Тема 3. Структуры данных
0.3. Бинарная куча (проверка на соответствие

 Язык программирования C# 6.0, модуль 1
Язык программирования C# 6.0, модуль 1 Префиксная и постфиксная формы записи выражений
Префиксная и постфиксная формы записи выражений Процесс формирования социолекта (на материале сайта diary.ru)
Процесс формирования социолекта (на материале сайта diary.ru) OriginLab. Часть 3
OriginLab. Часть 3 Размещение графики на Web-страницах
Размещение графики на Web-страницах Разработка компьютерной программы, обучающей умениям оценивания диагностируемости систем управления
Разработка компьютерной программы, обучающей умениям оценивания диагностируемости систем управления Презентация на тему Цикл с предусловием «Пока»
Презентация на тему Цикл с предусловием «Пока»  Поколения ЭВМ
Поколения ЭВМ 5298
5298 Основы подготовки и проведения презентации на английском языке
Основы подготовки и проведения презентации на английском языке Предметно-ориентированный язык
Предметно-ориентированный язык Изобретения, которые потрясли мир
Изобретения, которые потрясли мир Основы работы с поисковыми системами
Основы работы с поисковыми системами Создать форму для выбора блюд из меню с помощью приложения. Пример задания
Создать форму для выбора блюд из меню с помощью приложения. Пример задания Использование ресурса Plickers на уроках в начальной школе
Использование ресурса Plickers на уроках в начальной школе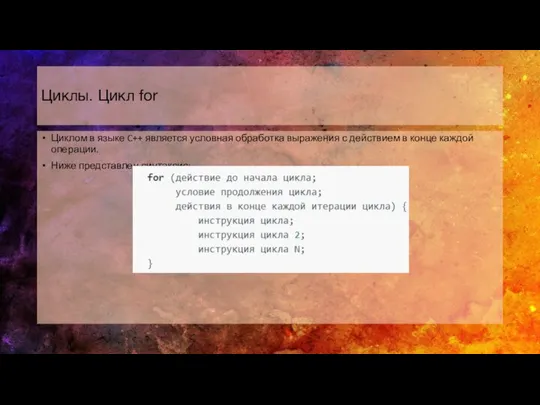 Циклы. Цикл for
Циклы. Цикл for Всероссийский урок безопасности школьников в сети Интернет
Всероссийский урок безопасности школьников в сети Интернет Онлайн сервіси обробки зображень
Онлайн сервіси обробки зображень Вычисление параметров сложного теплообмена с использованием FreeFEM++
Вычисление параметров сложного теплообмена с использованием FreeFEM++ Основные методы обеспечения качества функционирования
Основные методы обеспечения качества функционирования Roku Feedback
Roku Feedback Обработка текстовой информации
Обработка текстовой информации Компьютерные сети
Компьютерные сети Что такое Инстаграм?
Что такое Инстаграм? Шрифт Times New Roman
Шрифт Times New Roman ПО Книга Памяти
ПО Книга Памяти Практические возможности графического редактора Paint
Практические возможности графического редактора Paint Представление экспериментальных данных в графической форме
Представление экспериментальных данных в графической форме