- Алгоритмы работы с графами с использованием MapReduce

Содержание
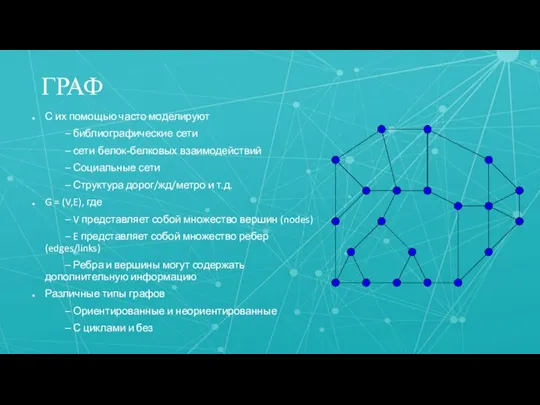
- 2. ГРАФ С их помощью часто моделируют – библиографические сети – сети белок-белковых взаимодействий – Социальные сети
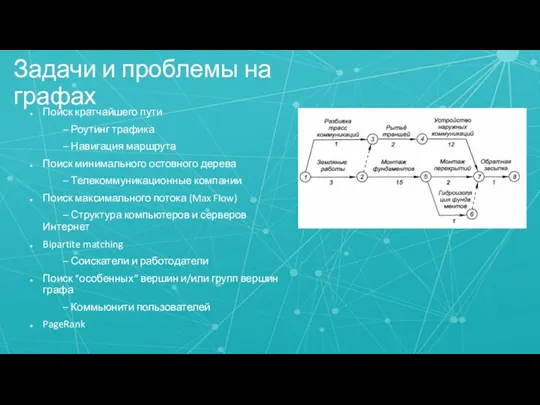
- 3. Задачи и проблемы на графах Поиск кратчайшего пути – Роутинг трафика – Навигация маршрута Поиск минимального
- 4. Графы и MapReduce Большой класс алгоритмов на графах включает – Выполнение вычислений на каждой ноде –
- 5. Матрица смежности Граф представляется как матрица M размером n x n – n = |V| –
- 6. Списки смежности • Берем матрицу смежности и убираем все нули 1: 2 2: 3, 4 3:
- 7. Матрицы смежности + – Удобство математических вычислений – Перемещение по строкам и столбцами соответствует переходу по
- 8. Задача поиска кратчайшего пути Найти кратчайший путь от исходной вершины до заданной (или несколько заданных) Также,
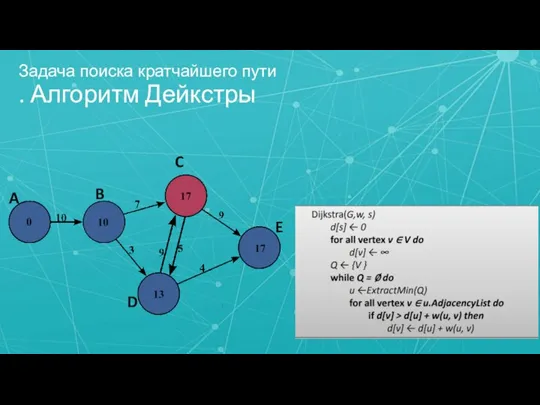
- 9. Задача поиска кратчайшего пути . Алгоритм Дейкстры C A E B D
- 10. Поиск кратчайшего пути Рассмотрим простой случай, когда вес всех ребер одинаков и равен единице Интуитивно: Определим:
- 11. Алгоритм breadth-first search
- 12. Параллельный BFS Представление данных: – Key: вершина n – Value: d (расстояние от начала), adjacency list
- 14. Параллельный BFS
- 15. BFS: итерации • Каждая итерация задачи MapReduce смещает границу продвижения по графу (frontier) на один “hop”
- 16. BFS: критерий завершения Как много итераций нужно для завершения параллельного BFS? Когда первый раз посетили искомую
- 17. BFS vs Дейкстра Алгоритм Дейкстры более эффективен На каждом шаге используются вершины только из пути с
- 18. BFS: Weighted Edges Добавим положительный вес каждому ребру Простая доработка: добавим вес w для каждого ребра
- 19. BFS Weighted: сложности
- 20. BFS Weighted: критерий завершения Как много итераций нужно для завершения параллельного BFS (взвешенный граф)? В худшем
- 21. Графы и MapReduce Большое количество алгоритмов на графах включает в себя: Выполнение вычислений, зависимых от особенностей
- 22. PageRank Модель блуждающего веб-серфера – Пользователь начинает серфинг на случайной веб-странице – Пользователь произвольно кликает по
- 23. Определение Дана страница x, на которую указывают ссылки t1…tn, где – C(t) степень out-degree для t
- 24. Вычисление PageRank без PageRank PageRank может быть рассчитан итеративно Примерный алгоритм: Начать с некоторыми заданными значения
- 25. Упрощения для PageRank Случайный переход и “подвисшие” вершины Нет фактора случайного перехода (random jump) Нет “подвисших”
- 26. Итерация 1
- 27. Итерация 2
- 28. PageRank на MapReduce
- 29. Псевдокод на MapReduce
- 30. Полный PageRank Две дополнительные сложности Как правильно обрабатывать “подвешенные” вершины? Как правильно определить фактор случайного перехода
- 31. Критерии сходимости PageRank Продолжать итерации пока значения PageRank не перестанет изменяться Фиксированное число итераций
- 33. Скачать презентацию
Слайд 2ГРАФ
С их помощью часто моделируют
– библиографические сети
– сети белок-белковых взаимодействий
– Социальные
ГРАФ
С их помощью часто моделируют
– библиографические сети
– сети белок-белковых взаимодействий
– Социальные
Слайд 3Задачи и проблемы на графах
Поиск кратчайшего пути
– Роутинг трафика
– Навигация маршрута
Поиск
Задачи и проблемы на графах
Поиск кратчайшего пути
– Роутинг трафика
– Навигация маршрута
Поиск
Слайд 4Графы и MapReduce
Большой класс алгоритмов на графах включает
– Выполнение вычислений на каждой
Графы и MapReduce
Большой класс алгоритмов на графах включает
– Выполнение вычислений на каждой

Слайд 5Матрица смежности
Граф представляется как матрица M размером n x n
– n
Матрица смежности
Граф представляется как матрица M размером n x n
– n
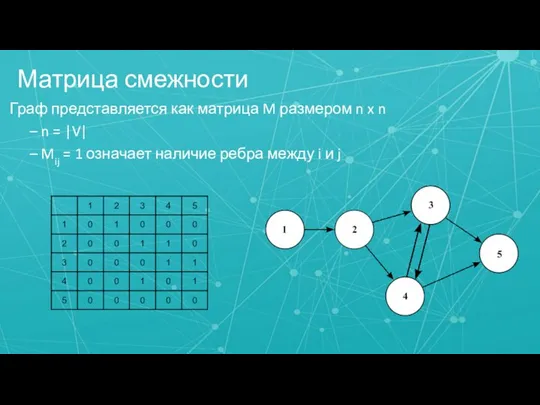
Слайд 6Списки смежности
• Берем матрицу смежности и убираем все нули
1: 2
2: 3,
Списки смежности
• Берем матрицу смежности и убираем все нули
1: 2
2: 3,

Слайд 7Матрицы смежности
+
– Удобство математических вычислений
– Перемещение по строкам и столбцами соответствует
Матрицы смежности
+
– Удобство математических вычислений
– Перемещение по строкам и столбцами соответствует

Слайд 8Задача поиска кратчайшего пути
Найти кратчайший путь от исходной вершины до заданной (или
Задача поиска кратчайшего пути
Найти кратчайший путь от исходной вершины до заданной (или

Слайд 9Задача поиска кратчайшего пути
. Алгоритм Дейкстры
C
A
E
B
D
Задача поиска кратчайшего пути
. Алгоритм Дейкстры
C
A
E
B
D
Слайд 10Поиск кратчайшего пути
Рассмотрим простой случай, когда вес всех ребер одинаков и равен
Поиск кратчайшего пути
Рассмотрим простой случай, когда вес всех ребер одинаков и равен

Слайд 11Алгоритм breadth-first search
Алгоритм breadth-first search

Слайд 12Параллельный BFS
Представление данных:
– Key: вершина n
– Value: d (расстояние от
Параллельный BFS
Представление данных:
– Key: вершина n
– Value: d (расстояние от

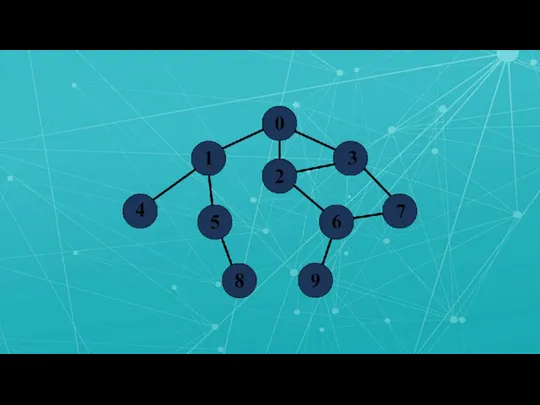
Слайд 14Параллельный BFS
Параллельный BFS

Слайд 15BFS: итерации
• Каждая итерация задачи MapReduce смещает границу продвижения по графу (frontier)
BFS: итерации
• Каждая итерация задачи MapReduce смещает границу продвижения по графу (frontier)
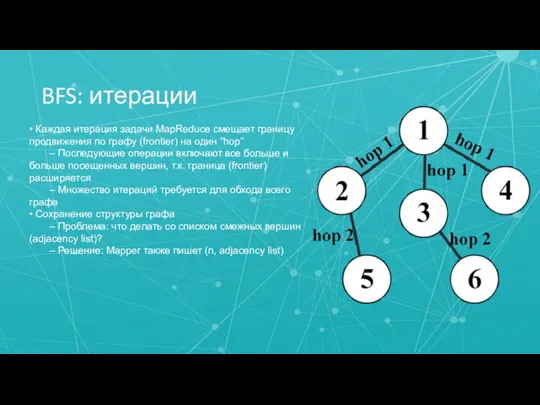
Слайд 16BFS: критерий завершения
Как много итераций нужно для завершения параллельного BFS?
Когда первый
BFS: критерий завершения
Как много итераций нужно для завершения параллельного BFS?
Когда первый

Слайд 17BFS vs Дейкстра
Алгоритм Дейкстры более эффективен
На каждом шаге используются вершины только
BFS vs Дейкстра
Алгоритм Дейкстры более эффективен
На каждом шаге используются вершины только

Слайд 18BFS: Weighted Edges
Добавим положительный вес каждому ребру
Простая доработка: добавим вес w
BFS: Weighted Edges
Добавим положительный вес каждому ребру
Простая доработка: добавим вес w

Слайд 19BFS Weighted: сложности
BFS Weighted: сложности
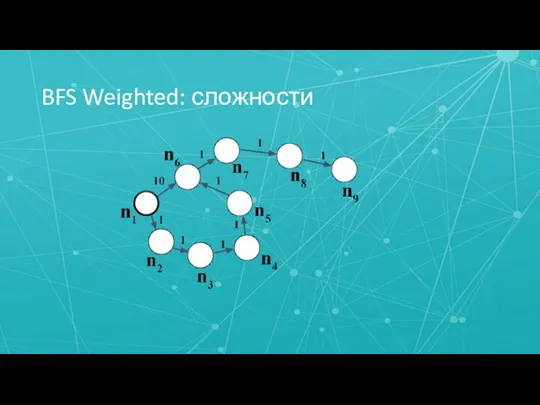
Слайд 20BFS Weighted: критерий завершения
Как много итераций нужно для завершения параллельного BFS (взвешенный
BFS Weighted: критерий завершения
Как много итераций нужно для завершения параллельного BFS (взвешенный

Слайд 21Графы и MapReduce
Большое количество алгоритмов на графах включает в себя:
Выполнение вычислений,
Графы и MapReduce
Большое количество алгоритмов на графах включает в себя:
Выполнение вычислений,

Слайд 22PageRank
Модель блуждающего веб-серфера
– Пользователь начинает серфинг на случайной веб-странице
– Пользователь произвольно
PageRank
Модель блуждающего веб-серфера
– Пользователь начинает серфинг на случайной веб-странице
– Пользователь произвольно

Слайд 23Определение
Дана страница x, на которую указывают ссылки t1…tn, где
– C(t) степень
Определение
Дана страница x, на которую указывают ссылки t1…tn, где
– C(t) степень

Слайд 24Вычисление PageRank без PageRank
PageRank может быть рассчитан итеративно
Примерный алгоритм:
Начать с некоторыми
Вычисление PageRank без PageRank
PageRank может быть рассчитан итеративно
Примерный алгоритм:
Начать с некоторыми

Слайд 25Упрощения для PageRank
Случайный переход и “подвисшие” вершины
Нет фактора случайного перехода (random jump)
Нет
Упрощения для PageRank
Случайный переход и “подвисшие” вершины
Нет фактора случайного перехода (random jump)
Нет

Слайд 26Итерация 1
Итерация 1
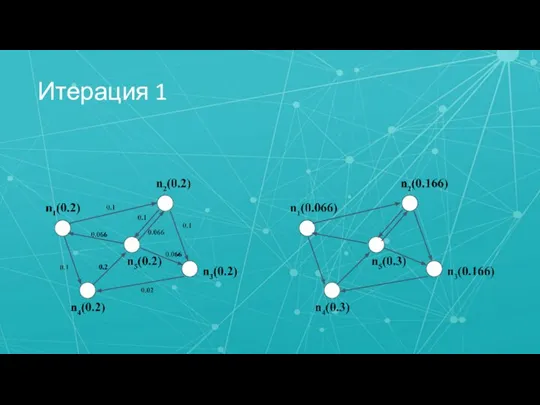
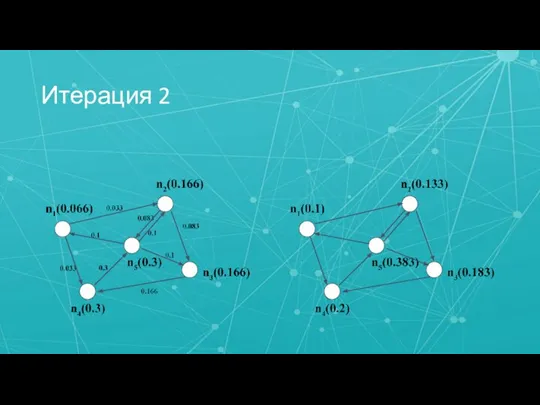
Слайд 27Итерация 2
Итерация 2
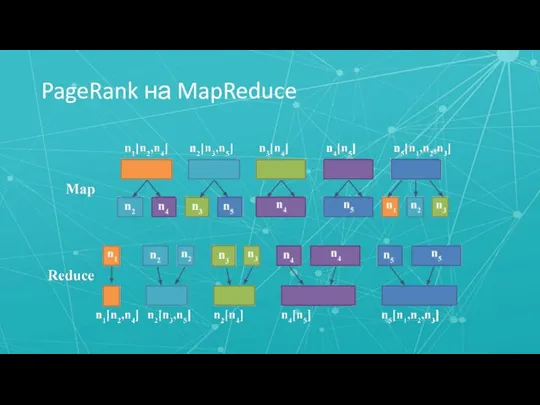
Слайд 28PageRank на MapReduce
PageRank на MapReduce
Слайд 29Псевдокод на MapReduce
Псевдокод на MapReduce

Слайд 30Полный PageRank
Две дополнительные сложности
Как правильно обрабатывать “подвешенные” вершины?
Как правильно определить фактор случайного
Полный PageRank
Две дополнительные сложности
Как правильно обрабатывать “подвешенные” вершины?
Как правильно определить фактор случайного

Слайд 31Критерии сходимости PageRank
Продолжать итерации пока значения PageRank не перестанет изменяться
Фиксированное число итераций
Критерии сходимости PageRank
Продолжать итерации пока значения PageRank не перестанет изменяться
Фиксированное число итераций

 Гаджеты: вред или польза
Гаджеты: вред или польза Текстовый редактор
Текстовый редактор Язык программирования СИ
Язык программирования СИ Редактор электронных таблиц MS Excel. Тема 3
Редактор электронных таблиц MS Excel. Тема 3 Информационные технологии в обработке текстов. Автоматическое чтение текста
Информационные технологии в обработке текстов. Автоматическое чтение текста Методика построения А3. Дивизион Сталь Дирекция по операционным улучшения
Методика построения А3. Дивизион Сталь Дирекция по операционным улучшения Цифровизация ЖКХ
Цифровизация ЖКХ Об использовании устройств мобильной связи
Об использовании устройств мобильной связи Основы работы с интеграционными сервисами ФРМО/ФРМР
Основы работы с интеграционными сервисами ФРМО/ФРМР Сервисы интернет
Сервисы интернет Презентация на тему Рисуем в Word
Презентация на тему Рисуем в Word  Создание человеко-программно-аппаратных систем
Создание человеко-программно-аппаратных систем Приложение для изучения информатики Рlay Market
Приложение для изучения информатики Рlay Market Дискретное представление информации
Дискретное представление информации 11 Методы идентификации и установления подлинности
11 Методы идентификации и установления подлинности Тернарный оператор ?:Лекция 25
Тернарный оператор ?:Лекция 25 Алгоритм установления соединения в сети IP-телефонии по протоколу SIP
Алгоритм установления соединения в сети IP-телефонии по протоколу SIP Основные угрозы и методы обеспечения информационной безопасности. Принципы защиты информации от несанкционированного доступа
Основные угрозы и методы обеспечения информационной безопасности. Принципы защиты информации от несанкционированного доступа Электронные таблицы
Электронные таблицы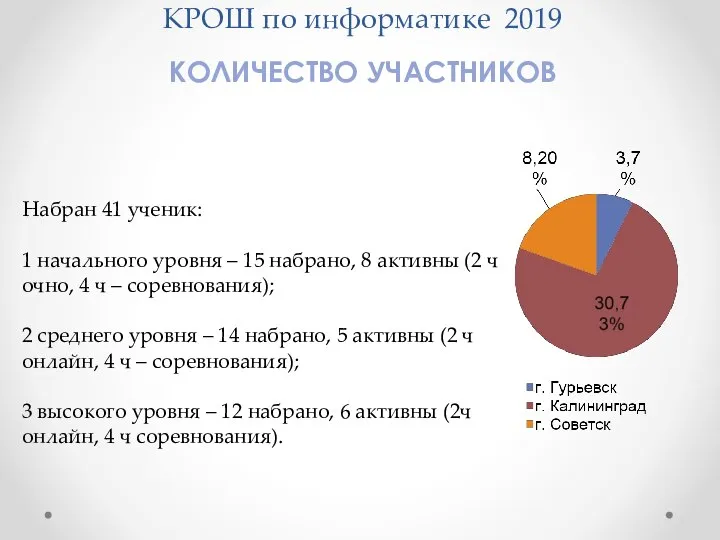 КРОШ по информатике
КРОШ по информатике Хакатоны: как не спать 24 часа, а потом побывать на ТВ и за рубежом
Хакатоны: как не спать 24 часа, а потом побывать на ТВ и за рубежом Защита информации в интернете
Защита информации в интернете Стандартизация показателей
Стандартизация показателей Абстрактные фигуры. Шрифтовые узоры
Абстрактные фигуры. Шрифтовые узоры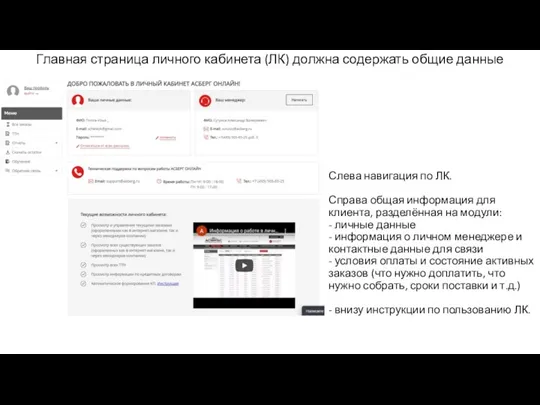 Главная страница личного кабинета
Главная страница личного кабинета Grid
Grid Внесение изменений на сайте
Внесение изменений на сайте Создание web-сайта
Создание web-сайта