- Алгорітми стискання інформації

Содержание
- 2. Базові відомості Стиснення інформації дозволяє зменшити час передавання повідомлення і його об'єм Трансляція аудіо файлу, оціфрованого
- 3. Ентропія Шеннона «A Mathematical Theory of Communication» Bell System Technical Journal, 1948 L-H надлишковість коду (L-H)/L
- 5. Методи стискання інформації Стискання без втрат: Шеннона-Фано (Shannon-Fano) Хаффмена (Huffman) Лемпела-Зіва-Велча (LZW) Арифметичне стискання Стискання з
- 6. Алгоритми стиснення без втрат Стиснення способом кодування серій (RLE - Run Length Encoding) 44 44 44
- 7. Стискання за алгоритмом Шеннона – Фано Літерний текст (повідомлення) кодується у двійковому коді, як правило, при
- 8. Приклад. Розглянемо текст (to be or not to be). Випишемо за порядком літери, як вони зустрічаються
- 9. Стискання за алгоритмом Хаффмена Алгоритм: літери повідомлення записуються в таблицю у порядку зменшення ймовірностей; дві останні
- 11. Арифметичне кодування Розроблений у 1979 році в IBM. Досягає більшого ступеня стиснення, ніж Хаффмена, більш складний
- 12. Приклад. На вході рядок «ABCDAABD» 4 унікальних символи, основа = 4, довжина даних = 8 призначаємо
- 13. MPEG: Загальна інформація Стандарт стиснення MPEG розроблений Експертної групою кінематографії (Moving Picture Experts Group - MPEG).
- 14. Як працює MPEG Залежно від деяких причин кожен frame (кадр) в MPEG може бути наступного виду:
- 16. Техніка кодування Для більшого стиснення в B і P кадрах використовується алгоритм передбачення руху (що дозволяє
- 17. JPEG Файл з розширенням JPG - це те ж саме, що і JPEG. Термін JPEG насправді
- 18. Фотографія заходу сонця в форматі JPEG зі зменшенням ступеня стиснення зліва направо
- 19. JPEG - за і проти До недоліків стиснення за стандартом JPEG слід віднести появу на відновлених
- 21. Скачать презентацию
Слайд 2Базові відомості
Стиснення інформації дозволяє зменшити час передавання повідомлення і його об'єм
Трансляція аудіо
Базові відомості
Стиснення інформації дозволяє зменшити час передавання повідомлення і його об'єм
Трансляція аудіо

Слайд 3Ентропія Шеннона
«A Mathematical Theory of Communication»
Bell System Technical Journal, 1948
L-H надлишковість
Ентропія Шеннона
«A Mathematical Theory of Communication»
Bell System Technical Journal, 1948
L-H надлишковість

Слайд 5Методи стискання інформації
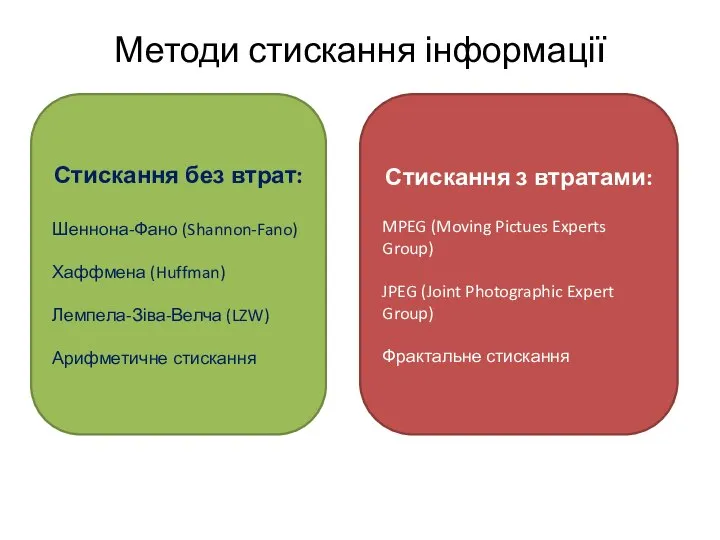
Стискання без втрат:
Шеннона-Фано (Shannon-Fano)
Хаффмена (Huffman)
Лемпела-Зіва-Велча (LZW)
Арифметичне стискання
Стискання з втратами:
MPEG (Moving
Методи стискання інформації
Стискання без втрат:
Шеннона-Фано (Shannon-Fano)
Хаффмена (Huffman)
Лемпела-Зіва-Велча (LZW)
Арифметичне стискання
Стискання з втратами:
MPEG (Moving
Слайд 6Алгоритми стиснення без втрат
Стиснення способом кодування серій
(RLE - Run Length Encoding)
44
Алгоритми стиснення без втрат
Стиснення способом кодування серій
(RLE - Run Length Encoding)
44

Слайд 7Стискання за алгоритмом Шеннона – Фано
Літерний текст (повідомлення) кодується у двійковому коді,
Стискання за алгоритмом Шеннона – Фано
Літерний текст (повідомлення) кодується у двійковому коді,

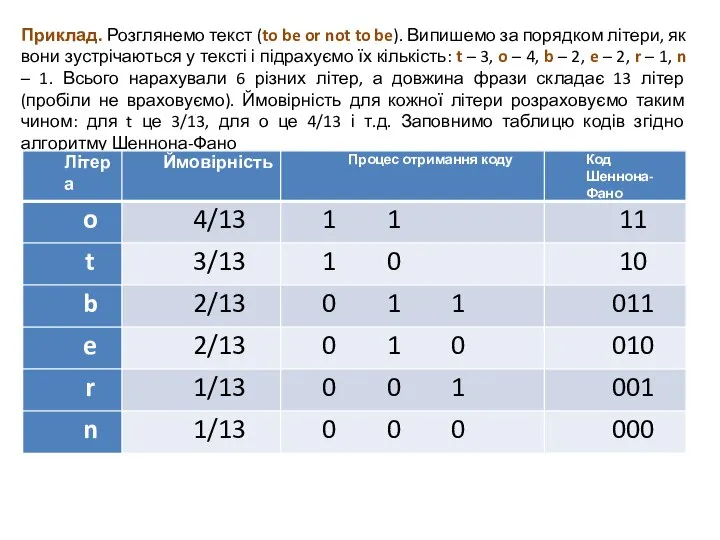
Слайд 8Приклад. Розглянемо текст (to be or not to be). Випишемо за порядком
Приклад. Розглянемо текст (to be or not to be). Випишемо за порядком
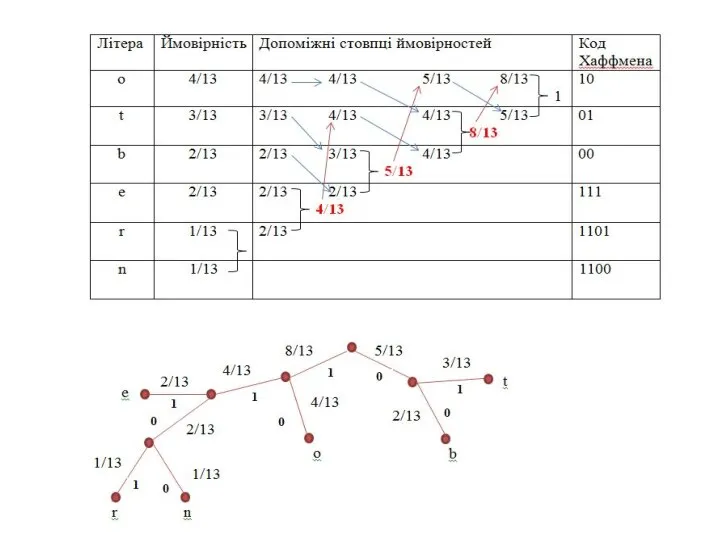
Слайд 9Стискання за алгоритмом Хаффмена
Алгоритм:
літери повідомлення записуються в таблицю у порядку зменшення ймовірностей;
дві
Стискання за алгоритмом Хаффмена
Алгоритм:
літери повідомлення записуються в таблицю у порядку зменшення ймовірностей;
дві

Слайд 11Арифметичне кодування
Розроблений у 1979 році в IBM. Досягає більшого ступеня стиснення, ніж
Арифметичне кодування
Розроблений у 1979 році в IBM. Досягає більшого ступеня стиснення, ніж

Слайд 12Приклад. На вході рядок «ABCDAABD»
4 унікальних символи, основа = 4, довжина даних
Приклад. На вході рядок «ABCDAABD»
4 унікальних символи, основа = 4, довжина даних

Слайд 13MPEG: Загальна інформація
Стандарт стиснення MPEG розроблений Експертної групою кінематографії (Moving Picture Experts
MPEG: Загальна інформація
Стандарт стиснення MPEG розроблений Експертної групою кінематографії (Moving Picture Experts

Слайд 14Як працює MPEG
Залежно від деяких причин кожен frame (кадр) в MPEG може
Як працює MPEG
Залежно від деяких причин кожен frame (кадр) в MPEG може


Слайд 16Техніка кодування
Для більшого стиснення в B і P кадрах використовується алгоритм передбачення
Техніка кодування
Для більшого стиснення в B і P кадрах використовується алгоритм передбачення

Слайд 17JPEG
Файл з розширенням JPG - це те ж саме, що і JPEG.
JPEG
Файл з розширенням JPG - це те ж саме, що і JPEG.

Слайд 18Фотографія заходу сонця в форматі JPEG зі зменшенням ступеня стиснення зліва направо
Фотографія заходу сонця в форматі JPEG зі зменшенням ступеня стиснення зліва направо

Слайд 19JPEG - за і проти
До недоліків стиснення за стандартом JPEG слід віднести
JPEG - за і проти
До недоліків стиснення за стандартом JPEG слід віднести

 Петровский Чат
Петровский Чат Контрольная работа №1. Технология 7 класс
Контрольная работа №1. Технология 7 класс История развития средств коммуникации
История развития средств коммуникации Информатика, информация и её классификация
Информатика, информация и её классификация ВКР: Повышение эффективности труда инженера-технолога за счет разработки подсистем в АИС T-FLEX DOCs 12
ВКР: Повышение эффективности труда инженера-технолога за счет разработки подсистем в АИС T-FLEX DOCs 12 Проведение урока он-лайн на платформе Zoom
Проведение урока он-лайн на платформе Zoom Графические операторы среды программирования QBasic
Графические операторы среды программирования QBasic Я лисенок Вилли
Я лисенок Вилли Welcome to Hell - оffice
Welcome to Hell - оffice Графический редактор Paint
Графический редактор Paint Администрирование 2020-2
Администрирование 2020-2 Онлайн образование с применением машинного обучения
Онлайн образование с применением машинного обучения Изменение формы представления информации
Изменение формы представления информации Социальная инженерия
Социальная инженерия Безмаркерный видеоанализ
Безмаркерный видеоанализ prezentatsia
prezentatsia 2.Вводная лекция
2.Вводная лекция Цифровая обработка звукового сигнала
Цифровая обработка звукового сигнала Ввод информации в память компьютера. 5 класс
Ввод информации в память компьютера. 5 класс Презентация на тему Создание Web-сайта
Презентация на тему Создание Web-сайта  События и Слушатели
События и Слушатели Классы и объекты. Тема 5
Классы и объекты. Тема 5 Программное обеспечение для параметрического представления границ
Программное обеспечение для параметрического представления границ Алгоритми з розгалуженням
Алгоритми з розгалуженням Введение в инфокоммуникационные системы и сети
Введение в инфокоммуникационные системы и сети Средства анализа и визуализации данных. Обработка числовой информации в электронных таблицах
Средства анализа и визуализации данных. Обработка числовой информации в электронных таблицах Тематический календарь 2020
Тематический календарь 2020 Настройка контекстной рекламы
Настройка контекстной рекламы