- Инфраструктурные паттерны микросервисной архитектуры

Содержание
- 2. Меня хорошо слышно && видно?
- 3. Карта вебинара Системы оркестрации App server vs virtual machine vs container Service discovery Стратегии деплоя Конфигурирование
- 4. Инфраструктурные паттерны микросервисной архитектуры
- 5. Как разместить несколько сервисов на одной машине? Cервер приложений jvm tomcat/jboss, python uwsgi Виртуальные машины Vagrant,
- 6. Сервер приложений Быстрый деплой Хорошая утилизация ресурсов Отсутствие изоляции по ресурсам между разными сервисами – CPU,
- 7. Виртуальная машина Technology agnostic Изоляция ресурсов между сервисами Большая утилизация ресурсов Долгий деплой
- 8. Контейнеры Technology agnostic Изоляция и ограничение сервисов друг от друга Эффективная утилизация ресурсов
- 9. Service discovery Как клиенту понять, где находится инстанс сервиса?
- 10. Client-side discovery Клиент сам ходит в реест сервисов, получает оттуда данные Сервисы сами себя регистрируют в
- 11. Eureka https://github.com/Netflix/eureka
- 12. Client-side discovery Работает с несколькими системами оркестрации одновременно: k8s, standalone-сервисы, nomad и т.д. Зависит от поддержки
- 13. Server-side discovery Оркестратор регистрирует сервис в реестре При обращении клиент использует service name или ip При
- 14. Стратегии деплоя Recreate Rolling update Blue/green Canary
- 15. Recreate Убить существующий деплой Поднять новый Даунтайм
- 16. Rolling update Снимаем трафик с пода Обновляем версию Переключаем трафик в поду Плюсы и минусы: +
- 17. Blue/green deployment Поднимаем новую версию Проверяем ее Переключаем трафик в новую версию Плюсы и минусы: +
- 18. Канареечные деплои Поднимаем новую версию одновременно со старой Переключаем на нее часть трафика Если все хорошо,
- 19. Observability
- 20. Конфигурирование приложений Конфигурация приложения – это все, что может меняться, между развертываниями приложений. Например, Идентификаторы подключения
- 21. Pull модель конфигурирования В момент старта приложение читает свой конфиг из внешнего сервиса. Конфиг может хранится
- 22. Конфигурирование приложений Конфигурация должна быть отделена от кода Кодовая база приложения может быть в любой момент
- 23. Push модель конфигурирования После деплоя оркестратор передает приложению конфиг Конфиг может передаваться через Переменные окружения (ENV)
- 24. Health check Чтобы проверять, умер под или нет заводится специальный метод (endpoint), по которому проверяется общая
- 25. Логирование Отправить логи из приложения Принять для доставки Доставить для анализа и хранения Проаналазировать Хранить
- 26. ELK ELK Elastic Search Logstash Kibana
- 27. Мониторинг и алертинг Как собирать метрики cpu/memory Продуктовые метрики Технические
- 28. Pull vs Push модель сбора метрик Push модель: приложение само ходит в сервис метрик и пушит
- 29. Prometheus Прометеус ходит по сервисам, забирает агрегированную статистику и складывает в базу.
- 30. Prometheus Прометеус может мониторить инфраструктуру с помощью экспортеров
- 31. Prometheus + grafana Grafana – это интерфейс для визуацилизации графиков, метриков, в целом инструмент построения дашбордов
- 32. Distrubuted tracing Распределенная транзакция – это путь прохождения запроса по разным сервисам. При трассировке, к каждому
- 33. Для чего используется tracing? Упрощенное взаимодействие между командами - при регрессах можно скинуть TraceID, связать систему
- 34. Основая терминология Span - запись об одной логической операции по обработке запроса (тайминги и метаданные). Каждый
- 35. Основая терминология Root Span - это спан, у которого нет ссылки на родительский спан (только Trace
- 36. Какие есть проблемы Не видны проблемы общей инфраструктуры (состояние очередей, IOPS и т.п.), "серые ошибки" в
- 37. Инструментарий distibuted-tracing 2 основных протокола: Opentracing (X-OT-* заголовки) B3 (Zipkin) (X-B3-* заголовки) Клиентские библиотеки и сервера
- 38. Elastic APM Elastic APM – средства для анализа производительности приложений с tracing-ом и метриками
- 39. Microservice chassis Microservice chassis – это паттерн, при котором есть фреймворк, помогающий встраивать сервисы в микросервисную
- 40. Service mesh Почему бы не вынести часть логики из кода приложения в отдельный «слой» взаимодействия сервисов?
- 41. Service mesh Давайте с каждым подом поставим side-прокси сервис, в котором будет вся логика по работе
- 42. Service mesh Неважно, что делают сервисы, но трафик между ними является идеальной точкой для добавления новой
- 43. Service mesh на примере istio
- 44. Балансировка запросов
- 45. Граф сервисов
- 46. Распределенная трассировка
- 47. Service mesh на примере istio
- 48. Service mesh плюсы и минусы Минусы: Увеличение latency Дополнительные ресурсы (mem, cpu) на работу прокси Сложность
- 49. Опрос https://otus.ru/polls/6408/
- 51. Скачать презентацию

Слайд 3Карта вебинара
Системы оркестрации
App server vs virtual machine vs container
Service discovery
Стратегии деплоя
Конфигурирование приложений
Логирование
Мониторинг
Карта вебинара
Системы оркестрации
App server vs virtual machine vs container
Service discovery
Стратегии деплоя
Конфигурирование приложений
Логирование
Мониторинг

Слайд 4Инфраструктурные паттерны микросервисной архитектуры
Инфраструктурные паттерны микросервисной архитектуры
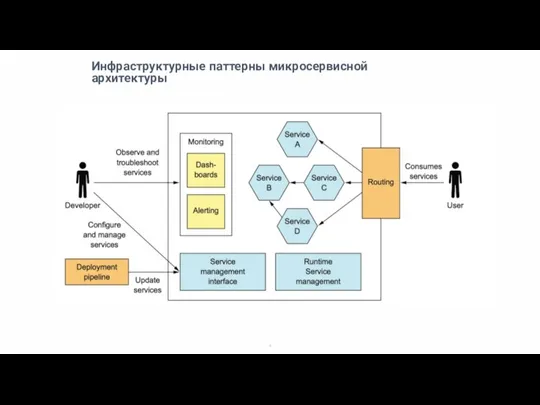
Слайд 5Как разместить несколько сервисов на одной машине?
Cервер приложений jvm tomcat/jboss, python uwsgi
Виртуальные
Как разместить несколько сервисов на одной машине?
Cервер приложений jvm tomcat/jboss, python uwsgi
Виртуальные
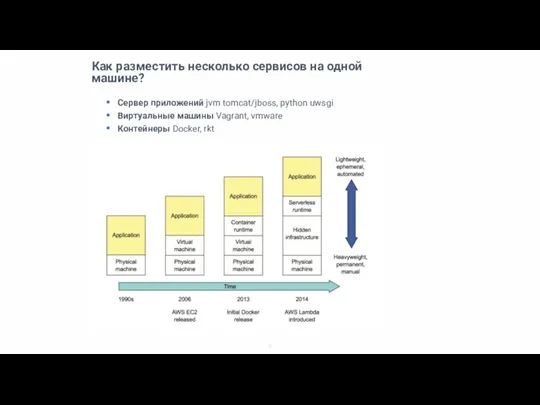
Слайд 6Сервер приложений
Быстрый деплой
Хорошая утилизация ресурсов
Отсутствие изоляции по ресурсам между разными сервисами –
Сервер приложений
Быстрый деплой
Хорошая утилизация ресурсов
Отсутствие изоляции по ресурсам между разными сервисами –
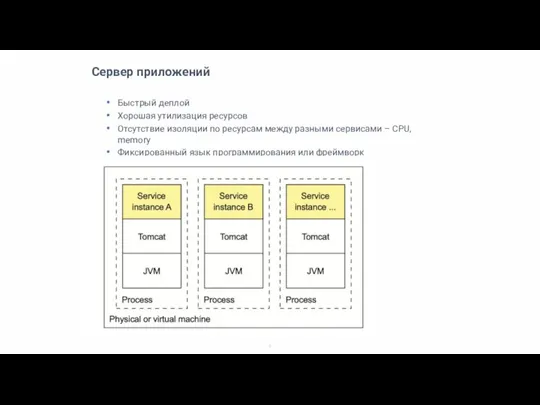
Слайд 7Виртуальная машина
Technology agnostic
Изоляция ресурсов между сервисами
Большая утилизация ресурсов
Долгий деплой
Виртуальная машина
Technology agnostic
Изоляция ресурсов между сервисами
Большая утилизация ресурсов
Долгий деплой
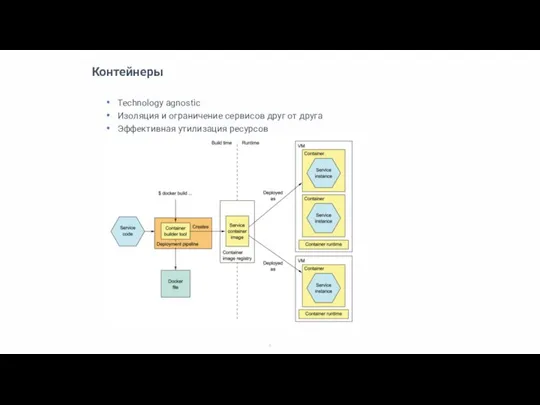
Слайд 8Контейнеры
Technology agnostic
Изоляция и ограничение сервисов друг от друга
Эффективная утилизация ресурсов
Контейнеры
Technology agnostic
Изоляция и ограничение сервисов друг от друга
Эффективная утилизация ресурсов
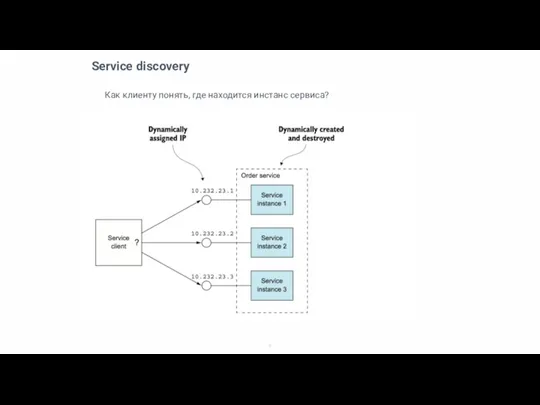
Слайд 9Service discovery
Как клиенту понять, где находится инстанс сервиса?
Service discovery
Как клиенту понять, где находится инстанс сервиса?
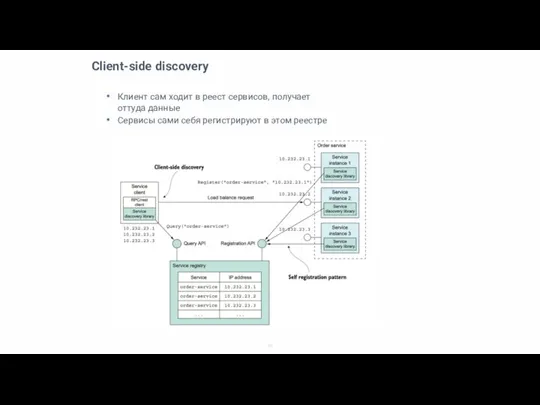
Слайд 10Client-side discovery
Клиент сам ходит в реест сервисов, получает оттуда данные
Сервисы сами себя
Client-side discovery
Клиент сам ходит в реест сервисов, получает оттуда данные
Сервисы сами себя
Слайд 11Eureka
https://github.com/Netflix/eureka
Eureka
https://github.com/Netflix/eureka

Слайд 12Client-side discovery
Работает с несколькими системами оркестрации одновременно: k8s, standalone-сервисы, nomad и т.д.
Client-side discovery
Работает с несколькими системами оркестрации одновременно: k8s, standalone-сервисы, nomad и т.д.

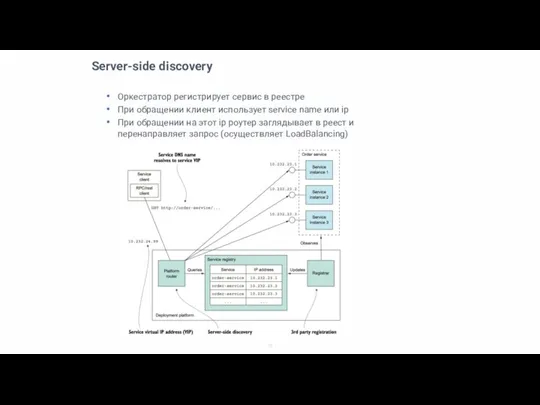
Слайд 13Server-side discovery
Оркестратор регистрирует сервис в реестре
При обращении клиент использует service name или
Server-side discovery
Оркестратор регистрирует сервис в реестре
При обращении клиент использует service name или
Слайд 14Стратегии деплоя
Recreate
Rolling update
Blue/green
Canary
Стратегии деплоя
Recreate
Rolling update
Blue/green
Canary

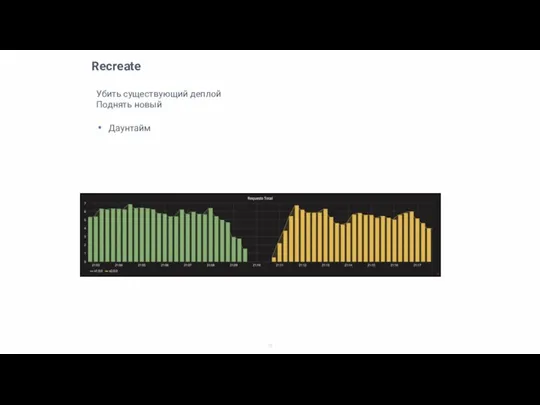
Слайд 15Recreate
Убить существующий деплой
Поднять новый
Даунтайм
Recreate
Убить существующий деплой
Поднять новый
Даунтайм
Слайд 16Rolling update
Снимаем трафик с пода
Обновляем версию
Переключаем трафик в поду
Плюсы и минусы:
+ нет
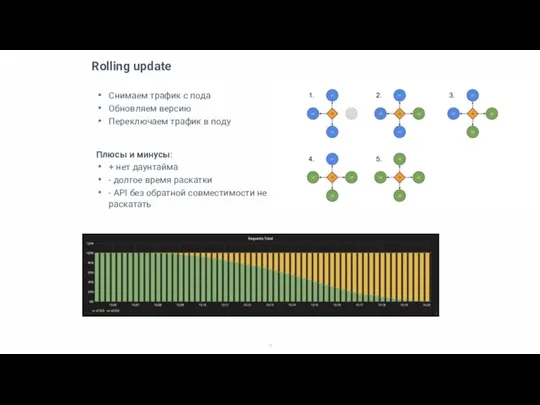
Rolling update
Снимаем трафик с пода
Обновляем версию
Переключаем трафик в поду
Плюсы и минусы:
+ нет
Слайд 17Blue/green deployment
Поднимаем новую версию
Проверяем ее
Переключаем трафик в новую версию
Плюсы и минусы:
+ нет
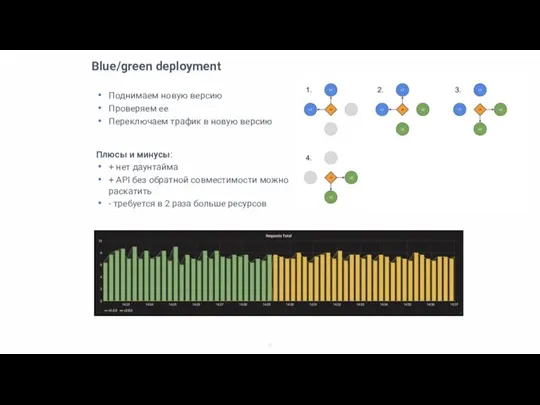
Blue/green deployment
Поднимаем новую версию
Проверяем ее
Переключаем трафик в новую версию
Плюсы и минусы:
+ нет
Слайд 18Канареечные деплои
Поднимаем новую версию одновременно со старой
Переключаем на нее часть трафика
Если все
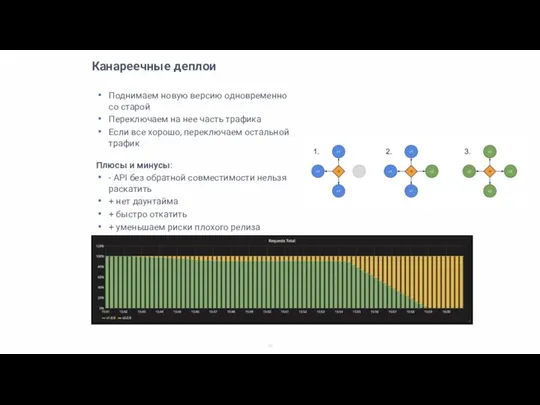
Канареечные деплои
Поднимаем новую версию одновременно со старой
Переключаем на нее часть трафика
Если все
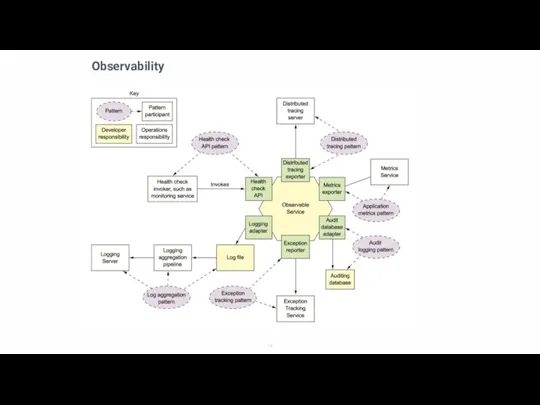
Слайд 19Observability
Observability
Слайд 20Конфигурирование приложений
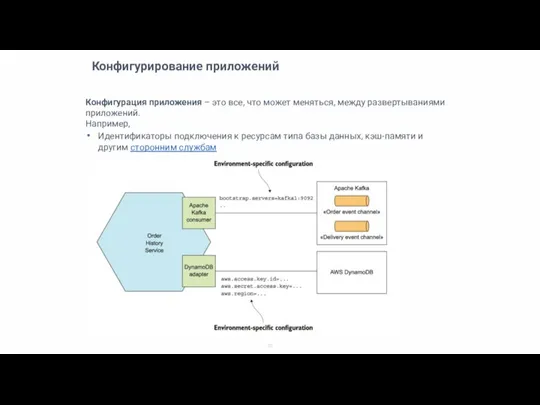
Конфигурация приложения – это все, что может меняться, между развертываниями
Конфигурирование приложений
Конфигурация приложения – это все, что может меняться, между развертываниями
Слайд 21Pull модель конфигурирования
В момент старта приложение читает свой конфиг из внешнего сервиса.
Pull модель конфигурирования
В момент старта приложение читает свой конфиг из внешнего сервиса.

Слайд 22Конфигурирование приложений
Конфигурация должна быть отделена от кода
Кодовая база приложения может быть
Конфигурирование приложений
Конфигурация должна быть отделена от кода
Кодовая база приложения может быть
Слайд 23Push модель конфигурирования
После деплоя оркестратор передает приложению конфиг
Конфиг может передаваться через
Переменные окружения
Push модель конфигурирования
После деплоя оркестратор передает приложению конфиг
Конфиг может передаваться через
Переменные окружения

Слайд 24Health check
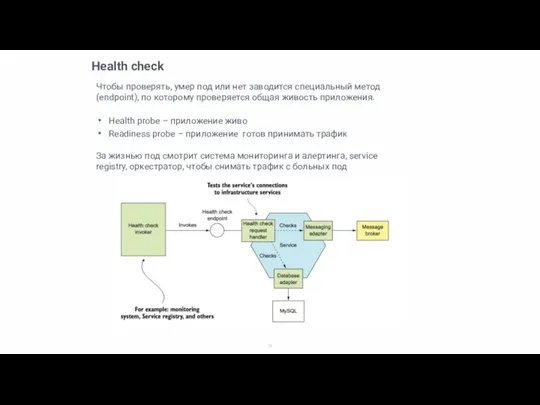
Чтобы проверять, умер под или нет заводится специальный метод (endpoint), по
Health check
Чтобы проверять, умер под или нет заводится специальный метод (endpoint), по
Слайд 25Логирование
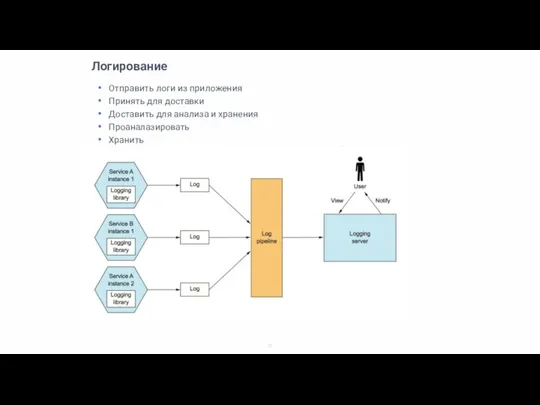
Отправить логи из приложения
Принять для доставки
Доставить для анализа и хранения
Проаналазировать
Хранить
Логирование
Отправить логи из приложения
Принять для доставки
Доставить для анализа и хранения
Проаналазировать
Хранить
Слайд 26ELK
ELK
Elastic Search
Logstash
Kibana
ELK
ELK
Elastic Search
Logstash
Kibana

Слайд 27Мониторинг и алертинг
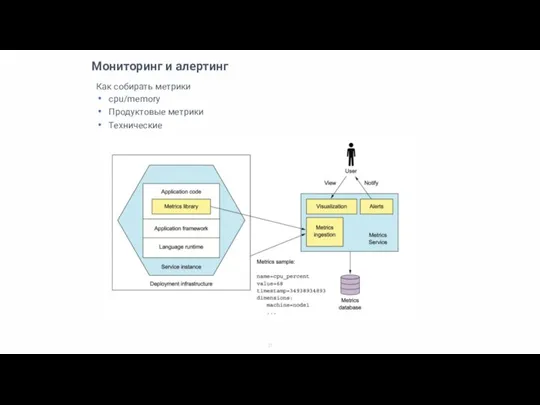
Как собирать метрики
cpu/memory
Продуктовые метрики
Технические
Мониторинг и алертинг
Как собирать метрики
cpu/memory
Продуктовые метрики
Технические
Слайд 28Pull vs Push модель сбора метрик
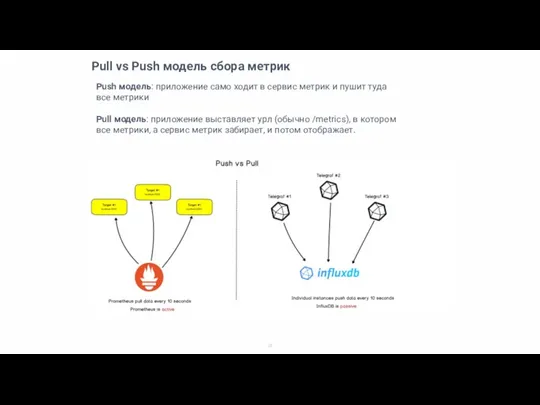
Push модель: приложение само ходит в сервис
Pull vs Push модель сбора метрик
Push модель: приложение само ходит в сервис
Слайд 29Prometheus
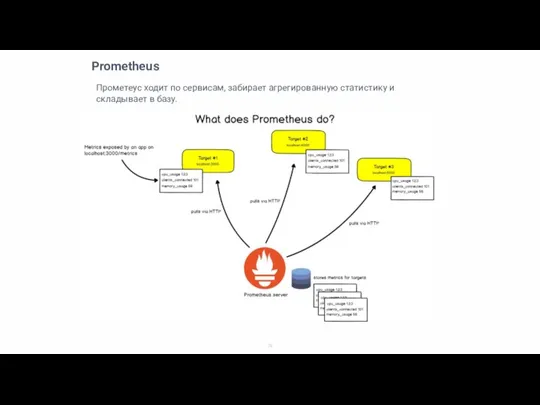
Прометеус ходит по сервисам, забирает агрегированную статистику и складывает в базу.
Prometheus
Прометеус ходит по сервисам, забирает агрегированную статистику и складывает в базу.
Слайд 30Prometheus
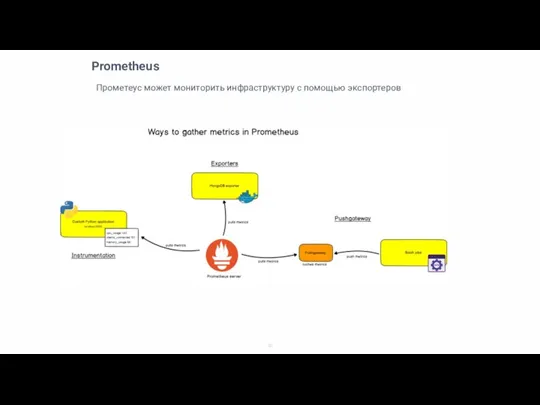
Прометеус может мониторить инфраструктуру с помощью экспортеров
Prometheus
Прометеус может мониторить инфраструктуру с помощью экспортеров
Слайд 31Prometheus + grafana
Grafana – это интерфейс для визуацилизации графиков, метриков, в целом
Prometheus + grafana
Grafana – это интерфейс для визуацилизации графиков, метриков, в целом

Слайд 32Distrubuted tracing
Распределенная транзакция – это путь прохождения запроса по разным сервисам.
При
Distrubuted tracing
Распределенная транзакция – это путь прохождения запроса по разным сервисам.
При

Слайд 33Для чего используется tracing?
Упрощенное взаимодействие между командами - при регрессах можно скинуть
Для чего используется tracing?
Упрощенное взаимодействие между командами - при регрессах можно скинуть

Слайд 34Основая терминология
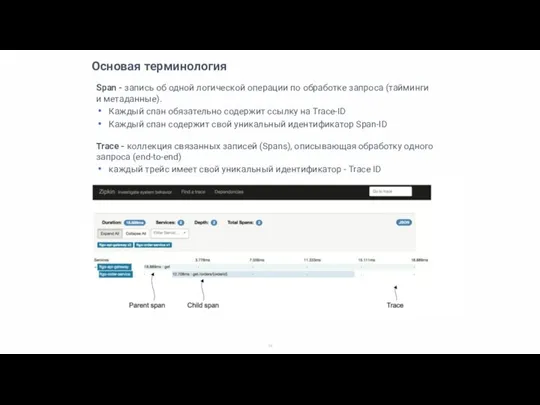
Span - запись об одной логической операции по обработке запроса (тайминги
Основая терминология
Span - запись об одной логической операции по обработке запроса (тайминги
Слайд 35Основая терминология
Root Span - это спан, у которого нет ссылки на родительский
Основая терминология
Root Span - это спан, у которого нет ссылки на родительский

Слайд 36Какие есть проблемы
Не видны проблемы общей инфраструктуры (состояние очередей, IOPS и т.п.),
Какие есть проблемы
Не видны проблемы общей инфраструктуры (состояние очередей, IOPS и т.п.),

Слайд 37Инструментарий distibuted-tracing
2 основных протокола:
Opentracing (X-OT-* заголовки)
B3 (Zipkin) (X-B3-* заголовки)
Клиентские библиотеки и сервера
Инструментарий distibuted-tracing
2 основных протокола:
Opentracing (X-OT-* заголовки)
B3 (Zipkin) (X-B3-* заголовки)
Клиентские библиотеки и сервера

Слайд 38Elastic APM
Elastic APM – средства для анализа производительности приложений с tracing-ом и
Elastic APM
Elastic APM – средства для анализа производительности приложений с tracing-ом и
Слайд 39Microservice chassis
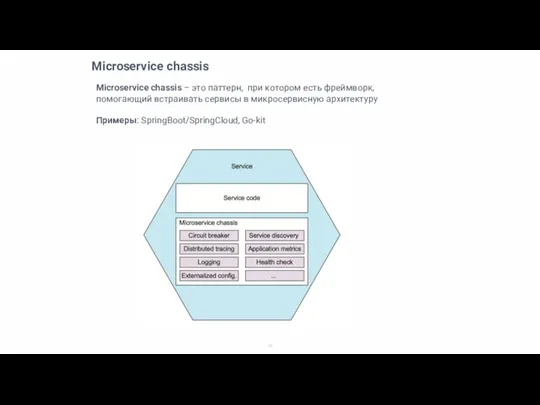
Microservice chassis – это паттерн, при котором есть фреймворк, помогающий встраивать
Microservice chassis
Microservice chassis – это паттерн, при котором есть фреймворк, помогающий встраивать
Слайд 40Service mesh
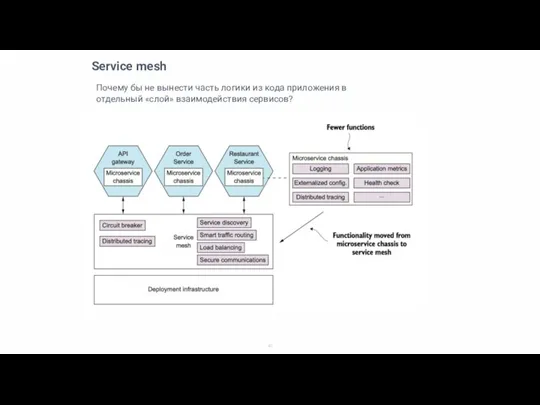
Почему бы не вынести часть логики из кода приложения в отдельный
Service mesh
Почему бы не вынести часть логики из кода приложения в отдельный
Слайд 41Service mesh
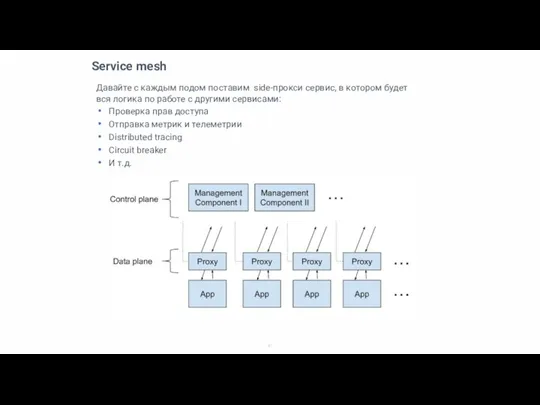
Давайте с каждым подом поставим side-прокси сервис, в котором будет вся
Service mesh
Давайте с каждым подом поставим side-прокси сервис, в котором будет вся
Слайд 42Service mesh
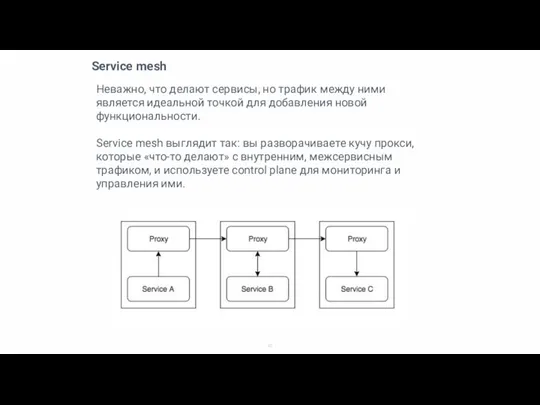
Неважно, что делают сервисы, но трафик между ними является идеальной точкой
Service mesh
Неважно, что делают сервисы, но трафик между ними является идеальной точкой
Слайд 43Service mesh на примере istio
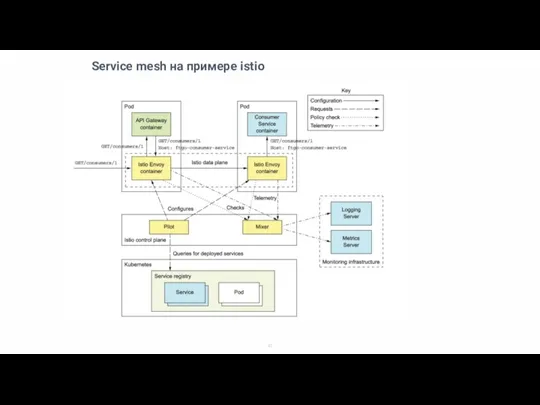
Service mesh на примере istio
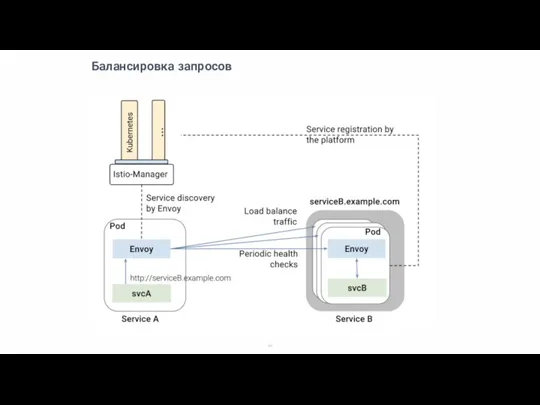
Слайд 44Балансировка запросов
Балансировка запросов
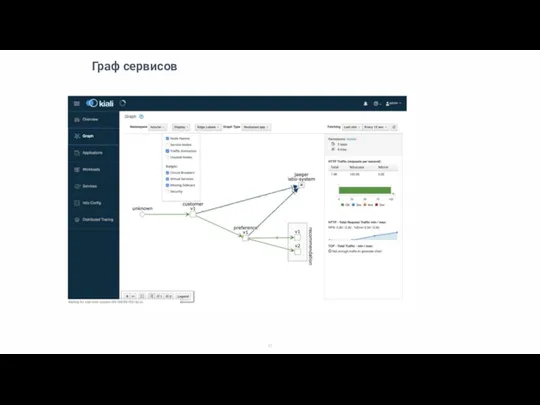
Слайд 45Граф сервисов
Граф сервисов
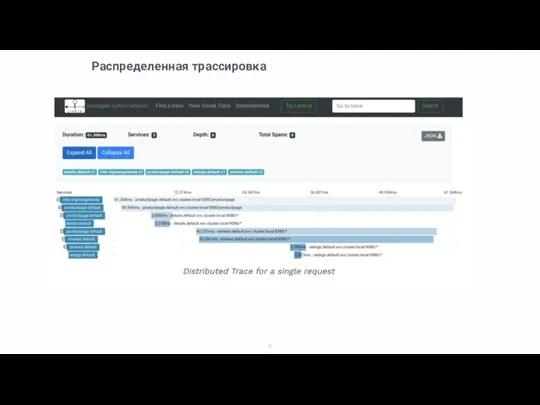
Слайд 46Распределенная трассировка
Распределенная трассировка
Слайд 47Service mesh на примере istio
Service mesh на примере istio
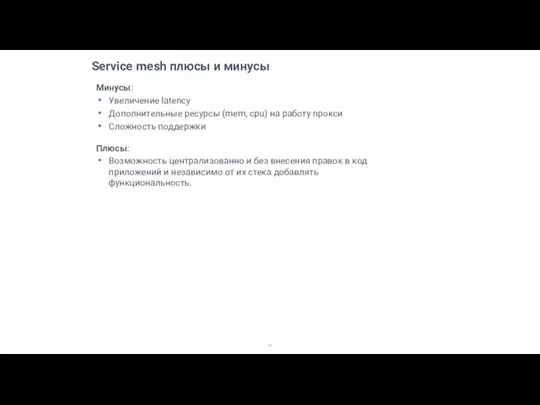
Слайд 48Service mesh плюсы и минусы
Минусы:
Увеличение latency
Дополнительные ресурсы (mem, cpu) на работу прокси
Сложность
Service mesh плюсы и минусы
Минусы:
Увеличение latency
Дополнительные ресурсы (mem, cpu) на работу прокси
Сложность
Слайд 49Опрос
https://otus.ru/polls/6408/
Опрос
https://otus.ru/polls/6408/

 Совмещение технологий локального и глобального позиционирования в ОС Android
Совмещение технологий локального и глобального позиционирования в ОС Android HTML таблицы+img
HTML таблицы+img Тренды instagram в развитии личного пространства
Тренды instagram в развитии личного пространства Интернет и гаджеты: как защитить
Интернет и гаджеты: как защитить Компьютерные вирусы
Компьютерные вирусы Информация и её свойства
Информация и её свойства Web of science. Символы усечения
Web of science. Символы усечения Защита конфиденциальной информации
Защита конфиденциальной информации Адресация в сети Интернет
Адресация в сети Интернет Система электронных ценников на базе Е-INK технологии
Система электронных ценников на базе Е-INK технологии Гимп (Урок 6)
Гимп (Урок 6) Организация вычислений в электронных таблицах
Организация вычислений в электронных таблицах Mit App Inventor. Компонент текст, переменные, арифметика (урок 2)
Mit App Inventor. Компонент текст, переменные, арифметика (урок 2) Как преуспеть в тестировании
Как преуспеть в тестировании Дискретная форма представления информации. Единицы измерения информации
Дискретная форма представления информации. Единицы измерения информации Интернет. Электронная почта
Интернет. Электронная почта Элементы алгебры логики. Математические основы информатики
Элементы алгебры логики. Математические основы информатики 202b64355ed2741af4039e665cb537b1
202b64355ed2741af4039e665cb537b1 Защита операционной системы при работе в интернете с помощью модема-маршрутизатора
Защита операционной системы при работе в интернете с помощью модема-маршрутизатора Устройство для сна
Устройство для сна Функции информационного менеджмента. Мотивация в сфере информатизации
Функции информационного менеджмента. Мотивация в сфере информатизации Конструирование программного продукта
Конструирование программного продукта Работа компьютерных сетей. Домен. Частная виртуальная сеть
Работа компьютерных сетей. Домен. Частная виртуальная сеть Использование связей
Использование связей Создание групп (сообществ) в образовательной сети
Создание групп (сообществ) в образовательной сети Развитие вычислительной техники
Развитие вычислительной техники Анонимная война
Анонимная война Модель текстового документа
Модель текстового документа