- Кластерная индексация файлов для оптимизации поиска информации в распределенной файловой системе

Содержание
- 2. Актуальность: Высокие темпы роста объема текстовой информации Накопление неклассифицированных данных в распределенной структуре Отсутствие возможности оптимального
- 3. Цель: Целью работы является разработка метода эффективного поиска текстовой информации в распределенной файловой системе с высокой
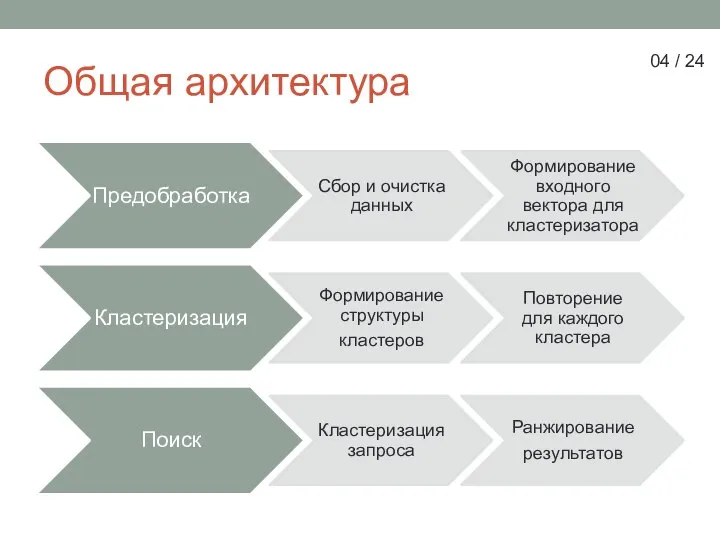
- 4. Общая архитектура 04 / 24
- 5. Выборка: Иерархическая структурированная библиотека открытая для скачивания объемом 21гб 05 / 24
- 6. Сбор и очистка данных: Данные Полученные очищенные слова данные отравляются На формирование входного вектора 06 /
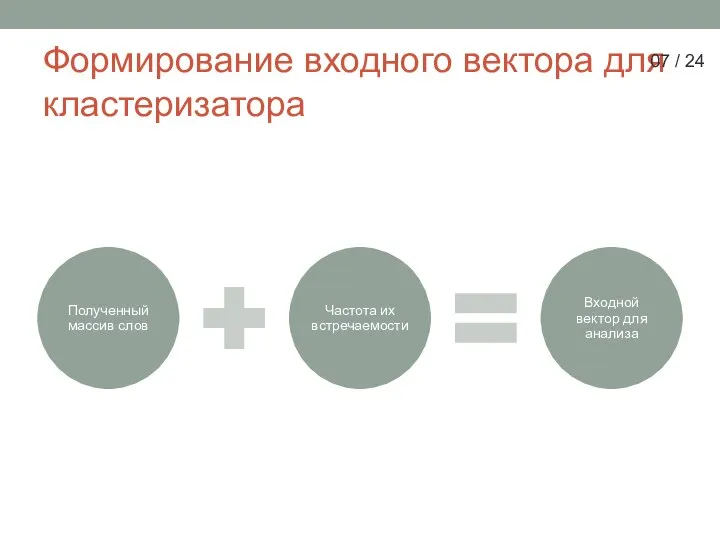
- 7. Формирование входного вектора для кластеризатора 07 / 24
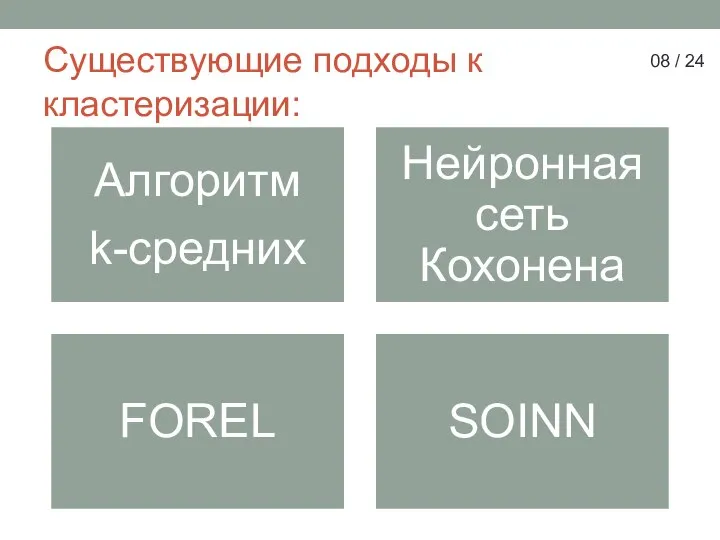
- 8. Существующие подходы к кластеризации: 08 / 24
- 9. Существующие подходы к индексации 09 / 24
- 10. Обоснование выбранного решение: Устойчивость к шумам Скорость Точность Адаптивность Отсутствие необходимости в эвристиках SOINN 10 /
- 11. Формирование структуры кластеров 11 / 24
- 12. Индексация Каждому кластеру присваивается уникальный индекс в порядке вложенности Пределом кластеризации является сведение к один кластер
- 13. Пример иерархической индексированной кластерной структуры файлов По окончанию иерархической кластеризации каждый файл отделяется в отдельный персональный
- 14. Пример вида метаинформации в документе 14 / 24
- 15. Пример сохраненной метаинформации в текстовом файле 15 / 24
- 16. Поиск 16 / 24
- 17. Имплементация: 17 / 24
- 18. Визуальный интерфейс 18/ 24
- 19. Поисковый запрос 19 / 24
- 20. Расширение поискового запроса 20 / 24
- 21. Экран настроек 21 / 24
- 22. Анализ эффективности: 400мб 1,5гб 7 мс 18 мс 21гб 19 мс 23 мс 22 / 24
- 23. Сравнительная характеристика алгоритмов поиска 23 / 24
- 25. Скачать презентацию
Слайд 2Актуальность:
Высокие темпы роста объема текстовой информации
Накопление неклассифицированных данных в распределенной структуре
Отсутствие возможности
Актуальность:
Высокие темпы роста объема текстовой информации
Накопление неклассифицированных данных в распределенной структуре
Отсутствие возможности

Слайд 3Цель:
Целью работы является разработка метода эффективного поиска текстовой информации в распределенной файловой
Цель:
Целью работы является разработка метода эффективного поиска текстовой информации в распределенной файловой

Слайд 4Общая архитектура
04 / 24
Общая архитектура
04 / 24
Слайд 5Выборка:
Иерархическая структурированная библиотека открытая для скачивания объемом 21гб
05 / 24
Выборка:
Иерархическая структурированная библиотека открытая для скачивания объемом 21гб
05 / 24

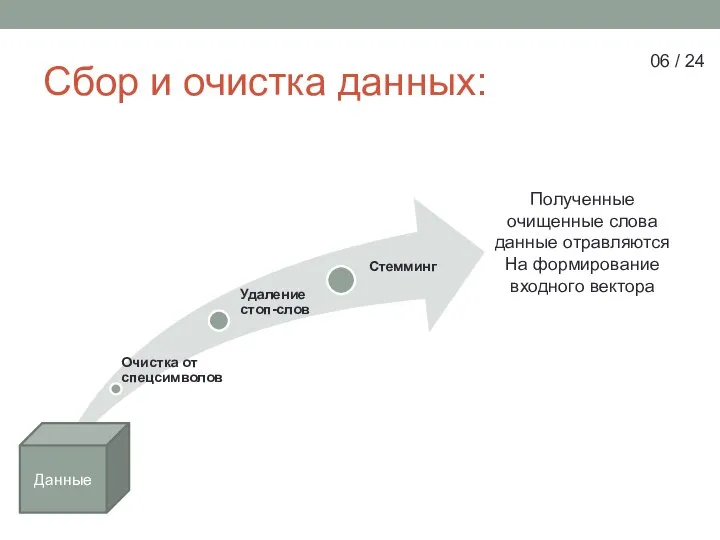
Слайд 6Сбор и очистка данных:
Данные
Полученные очищенные слова данные отравляются
На формирование входного вектора
06
Сбор и очистка данных:
Данные
Полученные очищенные слова данные отравляются
На формирование входного вектора
06
Слайд 7Формирование входного вектора для кластеризатора
07 / 24
Формирование входного вектора для кластеризатора
07 / 24
Слайд 8Существующие подходы к кластеризации:
08 / 24
Существующие подходы к кластеризации:
08 / 24
Слайд 9Существующие подходы к индексации
09 / 24
Существующие подходы к индексации
09 / 24

Слайд 10Обоснование выбранного решение:
Устойчивость к шумам
Скорость
Точность
Адаптивность
Отсутствие необходимости в эвристиках
SOINN
10 / 24
Обоснование выбранного решение:
Устойчивость к шумам
Скорость
Точность
Адаптивность
Отсутствие необходимости в эвристиках
SOINN
10 / 24

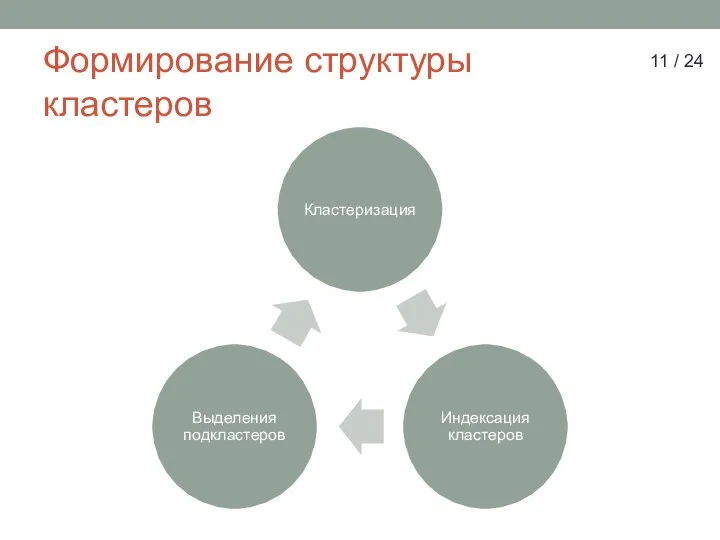
Слайд 11Формирование структуры
кластеров
11 / 24
Формирование структуры
кластеров
11 / 24
Слайд 12Индексация
Каждому кластеру присваивается уникальный индекс в порядке вложенности
Пределом кластеризации является сведение к
Индексация
Каждому кластеру присваивается уникальный индекс в порядке вложенности
Пределом кластеризации является сведение к

Слайд 13Пример иерархической индексированной кластерной структуры файлов
По окончанию иерархической кластеризации каждый файл отделяется
Пример иерархической индексированной кластерной структуры файлов
По окончанию иерархической кластеризации каждый файл отделяется

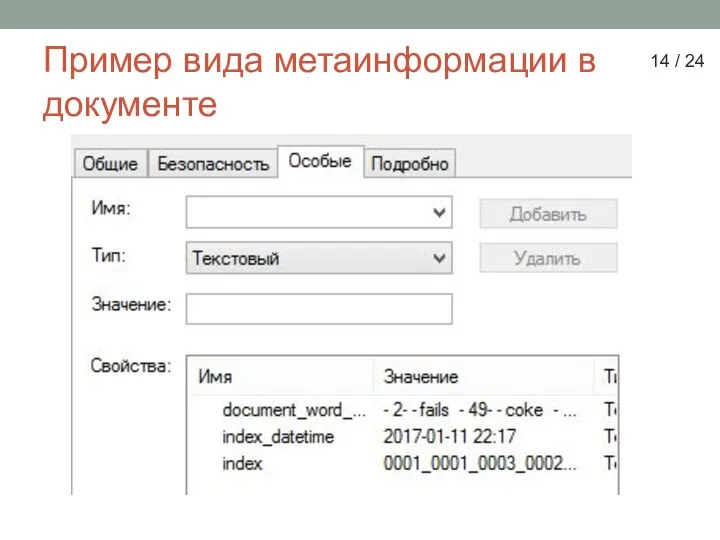
Слайд 14Пример вида метаинформации в документе
14 / 24
Пример вида метаинформации в документе
14 / 24
Слайд 15Пример сохраненной
метаинформации в текстовом файле
15 / 24
Пример сохраненной
метаинформации в текстовом файле
15 / 24

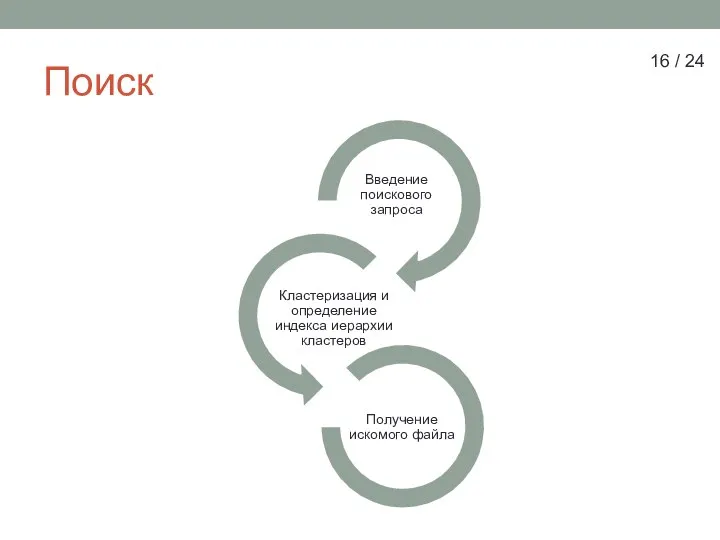
Слайд 16Поиск
16 / 24
Поиск
16 / 24
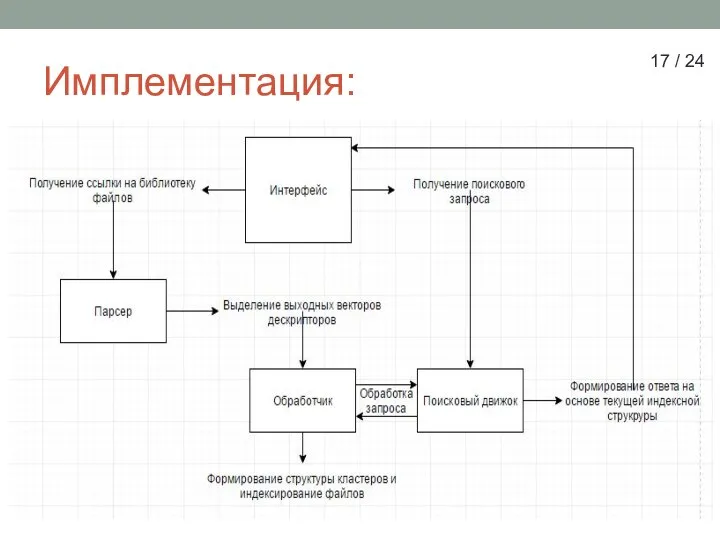
Слайд 17Имплементация:
17 / 24
Имплементация:
17 / 24
Слайд 18Визуальный интерфейс
18/ 24
Визуальный интерфейс
18/ 24

Слайд 19Поисковый запрос
19 / 24
Поисковый запрос
19 / 24

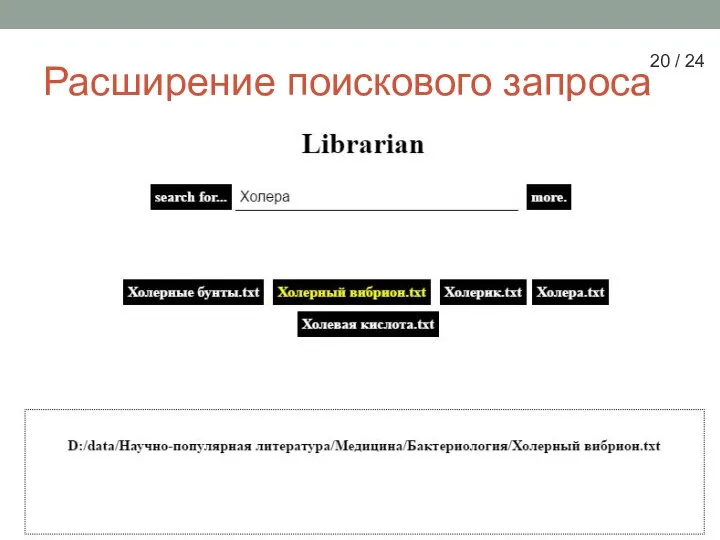
Слайд 20Расширение поискового запроса
20 / 24
Расширение поискового запроса
20 / 24
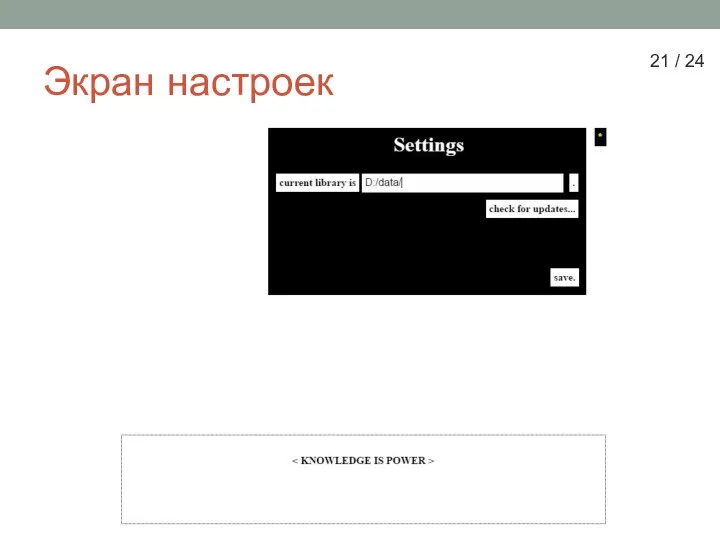
Слайд 21Экран настроек
21 / 24
Экран настроек
21 / 24
Слайд 22Анализ эффективности:
400мб
1,5гб
7 мс
18 мс
21гб
19 мс
23 мс
22 / 24
Анализ эффективности:
400мб
1,5гб
7 мс
18 мс
21гб
19 мс
23 мс
22 / 24

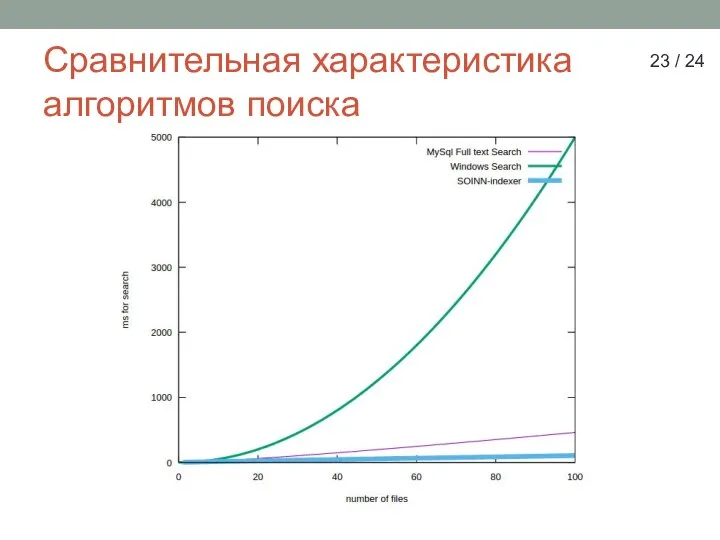
Слайд 23Сравнительная характеристика алгоритмов поиска
23 / 24
Сравнительная характеристика алгоритмов поиска
23 / 24
 Кто мы, зачем, куда мы идем
Кто мы, зачем, куда мы идем Функциональное описание и моделирование систем
Функциональное описание и моделирование систем Иновационные продукты и технологии
Иновационные продукты и технологии Инструкция по формированию электронных документов по информационному взаимодействию
Инструкция по формированию электронных документов по информационному взаимодействию Кодирование информации
Кодирование информации Имя цвета в системе NCS
Имя цвета в системе NCS Daniel Jurafsky & James H. Martin. Speech and Language Processing
Daniel Jurafsky & James H. Martin. Speech and Language Processing Использование диаграмм Эйлера-Венна при решении логических задач
Использование диаграмм Эйлера-Венна при решении логических задач Исполнитель Калькулятор
Исполнитель Калькулятор Информационная система Единое хранилище данных (ИС ЕХД)
Информационная система Единое хранилище данных (ИС ЕХД) Обобщенное программирование
Обобщенное программирование Онлайн-школа IT Кулебяка. Проект
Онлайн-школа IT Кулебяка. Проект Трейд для Android. АЛОР
Трейд для Android. АЛОР Устройство компьютера
Устройство компьютера Обучение по санитарно-просветительским программам Основы здорового питания. Регистрация на сайте
Обучение по санитарно-просветительским программам Основы здорового питания. Регистрация на сайте Программирование на языке Паскаль. Простейшие программы
Программирование на языке Паскаль. Простейшие программы Понятие ОС Windows
Понятие ОС Windows Матрицы. 10 класс
Матрицы. 10 класс Методы журналистского творчества. Методика работы с источниками информации
Методы журналистского творчества. Методика работы с источниками информации Работа библиотеки при музее пожарной части №1 ГУ Служба пожаротушения и аварийно-спасательных работ ДЧС СКО
Работа библиотеки при музее пожарной части №1 ГУ Служба пожаротушения и аварийно-спасательных работ ДЧС СКО Цветовые модели компьютерной графики
Цветовые модели компьютерной графики План воплощения социального проекта История школы
План воплощения социального проекта История школы Медиакоммуникации
Медиакоммуникации Коммуникационное VS Информационное общество
Коммуникационное VS Информационное общество Разработка нейронной сети для выявления и предотвращения антисоциального поведения на территории учебного заведения
Разработка нейронной сети для выявления и предотвращения антисоциального поведения на территории учебного заведения Ответ на тест
Ответ на тест Работа с готовой электронной таблицей:добавление и удаление строк и столбцов,изменение формул и их копирование
Работа с готовой электронной таблицей:добавление и удаление строк и столбцов,изменение формул и их копирование Программное обеспечение (ПО) персонального компьютера
Программное обеспечение (ПО) персонального компьютера