- L3: Apache Spark. Введение

Содержание
- 2. План презентации Apache Spark обзор Как работает Spark RDD Трансформация и действие Структура задания Spark ©2020
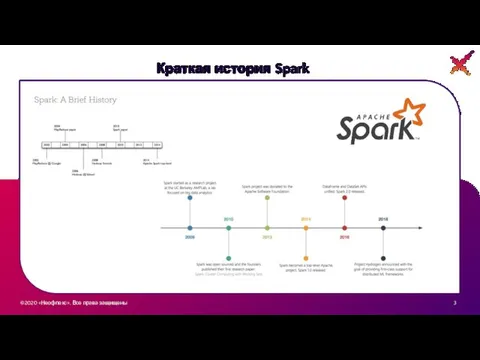
- 3. ©2020 «Неофлекс». Все права защищены 3 Краткая история Spark
- 4. ©2020 «Неофлекс». Все права защищены 3 Что такое Apache Spark Apache Spark – это BigData фреймворк
- 5. ©2020 «Неофлекс». Все права защищены 3 Преимущества и особенности Apache Spark Spark — всё-в-одном для работы
- 6. ©2020 «Неофлекс». Все права защищены 3 Преимущества и особенности Apache Spark
- 7. ©2020 «Неофлекс». Все права защищены 3 MapReduce и Spark
- 8. ©2020 «Неофлекс». Все права защищены 3 MapReduce и Spark Преимущество Spark особенно проявляется если необходимо выполнить
- 9. ©2020 «Неофлекс». Все права защищены 3 MapReduce и Spark
- 10. ©2020 «Неофлекс». Все права защищены 3 MapReduce и Spark Меньше шагов – Spark job это набор
- 11. ©2020 «Неофлекс». Все права защищены 3 MapReduce и Spark Жизненный цикл процессов MapReduce – каждый шаг
- 12. ©2020 «Неофлекс». Все права защищены 3 Развитие MapReduce - Tez Tez – позволяет запустить цепочку MR
- 13. ©2020 «Неофлекс». Все права защищены 3 MapReduce: word count Необходимо написать Mapper и Reducer все остальное
- 14. ©2020 «Неофлекс». Все права защищены 3 MapReduce и Spark: упрощение разработки MapReduce Java val sc =
- 15. Особенности Spark Для каждого набора данных Spark ведет Lineage и может пересчитать данные с любого момента
- 16. Основные концепции Spark ©2020 «Неофлекс». Все права защищены 11
- 17. ©2020 «Неофлекс». Все права защищены 3 RDD На самом деле внутри это набор партиций… Работаем с
- 18. ©2020 «Неофлекс». Все права защищены 3 RDD RDD - Resilient Distributed Dataset: Неизменяемая распределенная коллекция (таблица)
- 19. ©2020 «Неофлекс». Все права защищены 3 Трансформация и действие val textFile = sc.textFile("hdfs://...") val splits =
- 20. ©2020 «Неофлекс». Все права защищены 3 Трансформация и действие Трансформация не приводит к запуску вычислений Действие
- 21. Плюсы и минусы Lazy Evaluation Улучшает читаемость кода, можно разбивать на небольшие куски, потом все соберется
- 22. ©2020 «Неофлекс». Все права защищены 3 Lazy Evaluation кэширование RDD: textFile RDD: splits Подсчет к-ва RDD:
- 23. ©2020 «Неофлекс». Все права защищены 3 Lazy Evaluation кэширование RDD: textFile RDD: splits Подсчет к-ва RDD:
- 24. Как устроено приложение Spark ©2020 «Неофлекс». Все права защищены 11
- 25. ©2020 «Неофлекс». Все права защищены 3 Приложение Spark executors cores Каждая задача получает для выполнения: num_executors
- 26. ©2020 «Неофлекс». Все права защищены 3 Приложение Spark Для каждого действия строится DAG выполнения DAG отправляется
- 27. ©2020 «Неофлекс». Все права защищены 3 Приложение Spark Этап это последовательность трансформаций разделенных Shuffle
- 28. Звучит интересно, хочу попробовать !!! ©2020 «Неофлекс». Все права защищены 11
- 29. ©2020 «Неофлекс». Все права защищены 3 Как можно попробовать Spark 3. Распаковать архив в любую папку
- 30. ©2020 «Неофлекс». Все права защищены 3 Как можно попробовать Spark 5. Запустить: bin/spark-shell - интерпретатор Scala
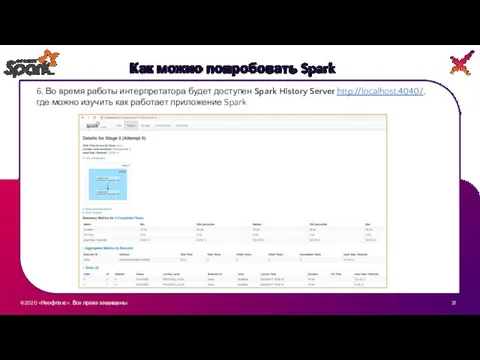
- 31. ©2020 «Неофлекс». Все права защищены 3 Как можно попробовать Spark 6. Во время работы интерпретатора будет
- 33. Скачать презентацию
Слайд 2План презентации
Apache Spark обзор
Как работает Spark
RDD
Трансформация и действие
Структура задания Spark
©2020 «Неофлекс».
План презентации
Apache Spark обзор
Как работает Spark
RDD
Трансформация и действие
Структура задания Spark
©2020 «Неофлекс».

Слайд 3©2020 «Неофлекс». Все права защищены
3
Краткая история Spark
©2020 «Неофлекс». Все права защищены
3
Краткая история Spark
Слайд 4©2020 «Неофлекс». Все права защищены
3
Что такое Apache Spark
Apache Spark – это BigData фреймворк с открытым исходным
©2020 «Неофлекс». Все права защищены
3
Что такое Apache Spark
Apache Spark – это BigData фреймворк с открытым исходным

Слайд 5©2020 «Неофлекс». Все права защищены
3
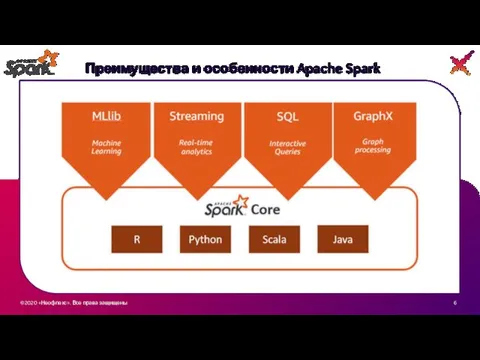
Преимущества и особенности Apache Spark
Spark — всё-в-одном для
©2020 «Неофлекс». Все права защищены
3
Преимущества и особенности Apache Spark
Spark — всё-в-одном для

Слайд 6©2020 «Неофлекс». Все права защищены
3
Преимущества и особенности Apache Spark
©2020 «Неофлекс». Все права защищены
3
Преимущества и особенности Apache Spark
Слайд 7©2020 «Неофлекс». Все права защищены
3
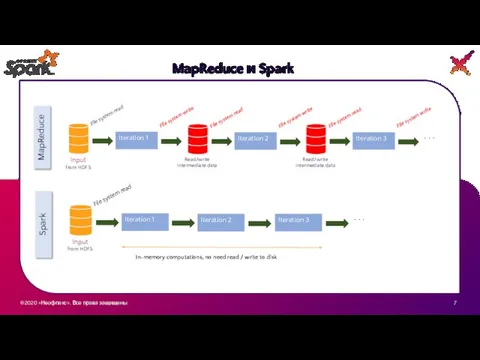
MapReduce и Spark
©2020 «Неофлекс». Все права защищены
3
MapReduce и Spark
Слайд 8©2020 «Неофлекс». Все права защищены
3
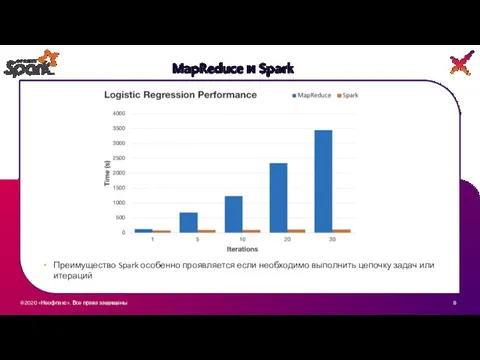
MapReduce и Spark
Преимущество Spark особенно проявляется если необходимо
©2020 «Неофлекс». Все права защищены
3
MapReduce и Spark
Преимущество Spark особенно проявляется если необходимо
Слайд 9©2020 «Неофлекс». Все права защищены
3
MapReduce и Spark
©2020 «Неофлекс». Все права защищены
3
MapReduce и Spark

Слайд 10©2020 «Неофлекс». Все права защищены
3
MapReduce и Spark
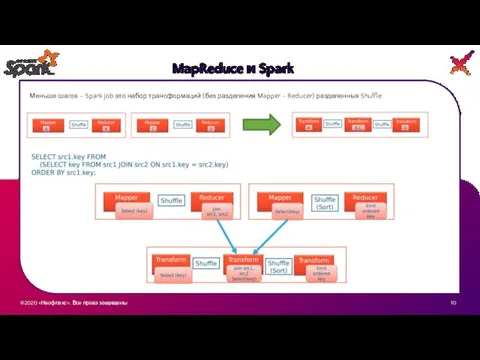
Меньше шагов – Spark job это
©2020 «Неофлекс». Все права защищены
3
MapReduce и Spark
Меньше шагов – Spark job это
Слайд 11©2020 «Неофлекс». Все права защищены
3
MapReduce и Spark
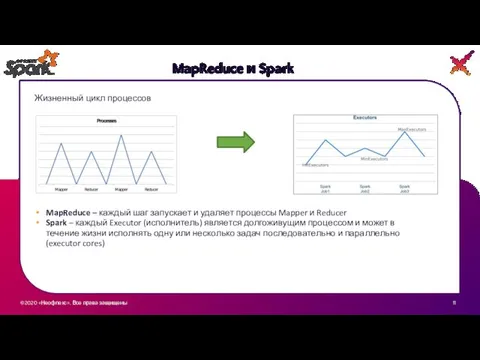
Жизненный цикл процессов
MapReduce – каждый шаг
©2020 «Неофлекс». Все права защищены
3
MapReduce и Spark
Жизненный цикл процессов
MapReduce – каждый шаг
Слайд 12©2020 «Неофлекс». Все права защищены
3
Развитие MapReduce - Tez
Tez – позволяет запустить цепочку
©2020 «Неофлекс». Все права защищены
3
Развитие MapReduce - Tez
Tez – позволяет запустить цепочку

Слайд 13©2020 «Неофлекс». Все права защищены
3
MapReduce: word count
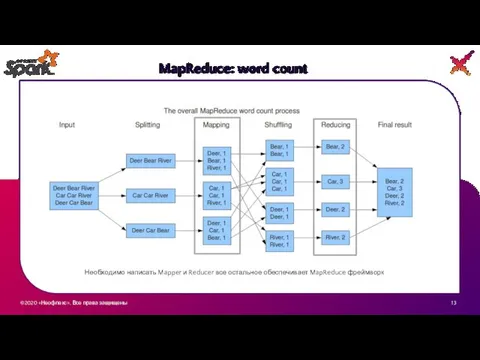
Необходимо написать Mapper и Reducer все
©2020 «Неофлекс». Все права защищены
3
MapReduce: word count
Необходимо написать Mapper и Reducer все
Слайд 14©2020 «Неофлекс». Все права защищены
3
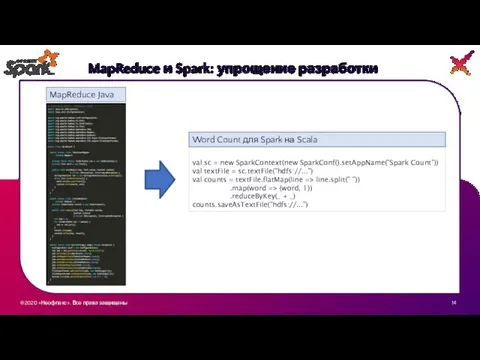
MapReduce и Spark: упрощение разработки
MapReduce Java
val sc =
©2020 «Неофлекс». Все права защищены
3
MapReduce и Spark: упрощение разработки
MapReduce Java
val sc =
Слайд 15Особенности Spark
Для каждого набора данных Spark ведет Lineage и может пересчитать данные
Особенности Spark
Для каждого набора данных Spark ведет Lineage и может пересчитать данные

Слайд 16Основные концепции Spark
©2020 «Неофлекс». Все права защищены
11
Основные концепции Spark
©2020 «Неофлекс». Все права защищены
11

Слайд 17©2020 «Неофлекс». Все права защищены
3
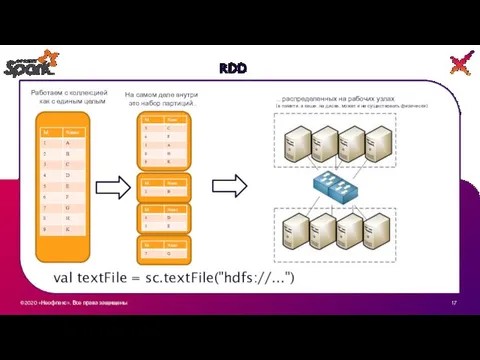
RDD
На самом деле внутри
это набор партиций…
Работаем с
©2020 «Неофлекс». Все права защищены
3
RDD
На самом деле внутри
это набор партиций…
Работаем с
Слайд 18©2020 «Неофлекс». Все права защищены
3
RDD
RDD - Resilient Distributed Dataset:
Неизменяемая распределенная коллекция (таблица)
Отказоустойчивая
©2020 «Неофлекс». Все права защищены
3
RDD
RDD - Resilient Distributed Dataset:
Неизменяемая распределенная коллекция (таблица)
Отказоустойчивая

Слайд 19©2020 «Неофлекс». Все права защищены
3
Трансформация и действие
val textFile = sc.textFile("hdfs://...")
val splits =
©2020 «Неофлекс». Все права защищены
3
Трансформация и действие
val textFile = sc.textFile("hdfs://...")
val splits =

Слайд 20©2020 «Неофлекс». Все права защищены
3
Трансформация и действие
Трансформация
не приводит к запуску вычислений
Действие
©2020 «Неофлекс». Все права защищены
3
Трансформация и действие
Трансформация
не приводит к запуску вычислений
Действие

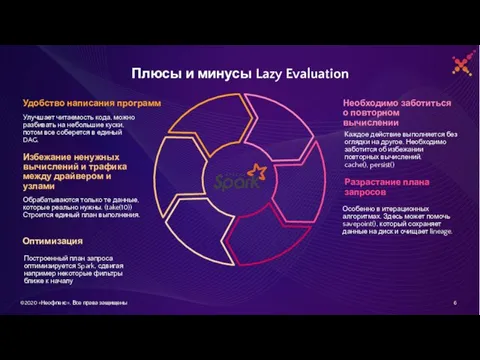
Слайд 21Плюсы и минусы Lazy Evaluation
Улучшает читаемость кода, можно разбивать на небольшие куски,
Плюсы и минусы Lazy Evaluation
Улучшает читаемость кода, можно разбивать на небольшие куски,
Слайд 22©2020 «Неофлекс». Все права защищены
3
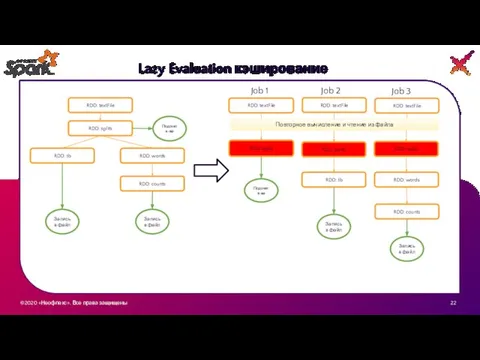
Lazy Evaluation кэширование
RDD: textFile
RDD: splits
Подсчет к-ва
RDD: textFile
RDD: splits
RDD:
©2020 «Неофлекс». Все права защищены
3
Lazy Evaluation кэширование
RDD: textFile
RDD: splits
Подсчет к-ва
RDD: textFile
RDD: splits
RDD:
Слайд 23©2020 «Неофлекс». Все права защищены
3
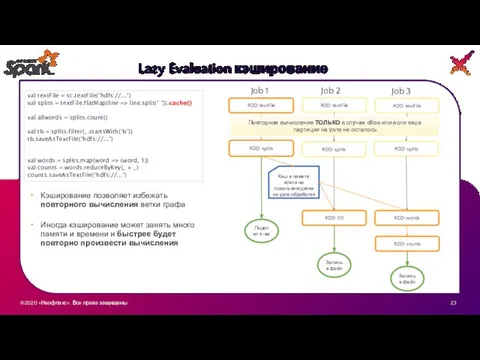
Lazy Evaluation кэширование
RDD: textFile
RDD: splits
Подсчет к-ва
RDD: textFile
RDD: splits
RDD:
©2020 «Неофлекс». Все права защищены
3
Lazy Evaluation кэширование
RDD: textFile
RDD: splits
Подсчет к-ва
RDD: textFile
RDD: splits
RDD:
Слайд 24Как устроено приложение Spark
©2020 «Неофлекс». Все права защищены
11
Как устроено приложение Spark
©2020 «Неофлекс». Все права защищены
11

Слайд 25©2020 «Неофлекс». Все права защищены
3
Приложение Spark
executors
cores
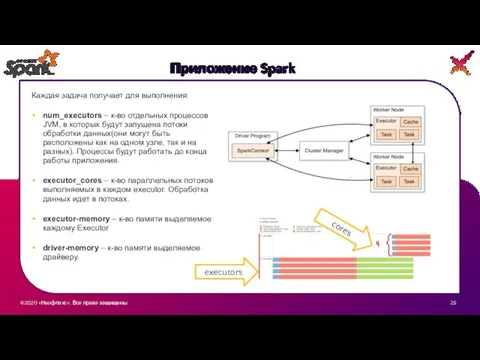
Каждая задача получает для выполнения:
num_executors – к-во
©2020 «Неофлекс». Все права защищены
3
Приложение Spark
executors
cores
Каждая задача получает для выполнения:
num_executors – к-во
Слайд 26©2020 «Неофлекс». Все права защищены
3
Приложение Spark
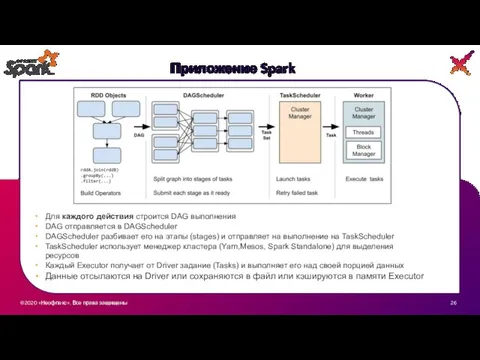
Для каждого действия строится DAG выполнения
DAG отправляется
©2020 «Неофлекс». Все права защищены
3
Приложение Spark
Для каждого действия строится DAG выполнения
DAG отправляется
Слайд 27©2020 «Неофлекс». Все права защищены
3
Приложение Spark
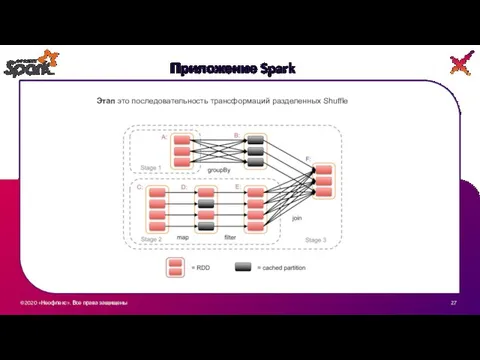
Этап это последовательность трансформаций разделенных Shuffle
©2020 «Неофлекс». Все права защищены
3
Приложение Spark
Этап это последовательность трансформаций разделенных Shuffle
Слайд 28Звучит интересно, хочу попробовать !!!
©2020 «Неофлекс». Все права защищены
11
Звучит интересно, хочу попробовать !!!
©2020 «Неофлекс». Все права защищены
11

Слайд 29©2020 «Неофлекс». Все права защищены
3
Как можно попробовать Spark
3. Распаковать архив в любую
©2020 «Неофлекс». Все права защищены
3
Как можно попробовать Spark
3. Распаковать архив в любую

Слайд 30©2020 «Неофлекс». Все права защищены
3
Как можно попробовать Spark
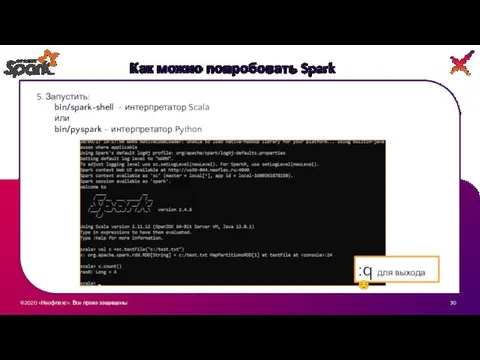
5. Запустить:
bin/spark-shell - интерпретатор Scala
или
bin/pyspark
©2020 «Неофлекс». Все права защищены
3
Как можно попробовать Spark
5. Запустить:
bin/spark-shell - интерпретатор Scala
или
bin/pyspark
Слайд 31©2020 «Неофлекс». Все права защищены
3
Как можно попробовать Spark
6. Во время работы интерпретатора
©2020 «Неофлекс». Все права защищены
3
Как можно попробовать Spark
6. Во время работы интерпретатора
 Компьютер-исполнитель команд. Программный принцип работы компьютера
Компьютер-исполнитель команд. Программный принцип работы компьютера Криптовалюта
Криптовалюта Типы данных в языке Паскаль: вещественный, целочисленный, символьный, строковый, логический
Типы данных в языке Паскаль: вещественный, целочисленный, символьный, строковый, логический Шрифт. Типографика
Шрифт. Типографика Какие из данных функций будут пересекаться на заданном интервале: cos(x), tg(x), sin(x) на интервале [a;b]
Какие из данных функций будут пересекаться на заданном интервале: cos(x), tg(x), sin(x) на интервале [a;b] Цифровая мода
Цифровая мода Таблицы в текстовом процессоре
Таблицы в текстовом процессоре Инструкция по созданию заявок. Форма для работы с отчетом
Инструкция по созданию заявок. Форма для работы с отчетом Анализ дизайна интернет-сайтов
Анализ дизайна интернет-сайтов Как компьютерный вирус проникает в компьютер?
Как компьютерный вирус проникает в компьютер? Страна должна знать своих героев в лицо, ну или знать хотя бы их имена.
Страна должна знать своих героев в лицо, ну или знать хотя бы их имена. Реквием по фронту. Библиотека Korolev
Реквием по фронту. Библиотека Korolev Алгоритмы на тему Графы
Алгоритмы на тему Графы Клуб успешных людей On the list
Клуб успешных людей On the list Персональный компьютер (ПК)
Персональный компьютер (ПК) Объектноориентированное программирование. Наследование
Объектноориентированное программирование. Наследование Цвет в компьютерной графике
Цвет в компьютерной графике Руководство программиста
Руководство программиста Обработка графической информации. Вставка изображений в документы
Обработка графической информации. Вставка изображений в документы Табличный процессор Microsoft Excel
Табличный процессор Microsoft Excel МОФР - практика. Решение всех задач
МОФР - практика. Решение всех задач Запрещенные тематики для таргетированной рекламы
Запрещенные тематики для таргетированной рекламы Пошаговая инструкция по регистрации. Центр компетенций
Пошаговая инструкция по регистрации. Центр компетенций 30 ноября – международный день защиты информации
30 ноября – международный день защиты информации Вирусное ПО
Вирусное ПО Программные средства реализации информационных процессов
Программные средства реализации информационных процессов EtherChannel. Агрегирование каналов
EtherChannel. Агрегирование каналов Архитектура персонального компьютера
Архитектура персонального компьютера