- Модели и задачи Data Mining

Содержание
- 2. Классификация и регрессия Постановка задачи В задачах классификации и регрессии требуется определить значение зависимой переменной объекта
- 3. Формально задачу классификации и регрессии можно описать следующим образом. Имеется множество объектов: I={i1, i2, …ij, …in
- 4. В Data Mining часто набор независимых переменных обозначают в виде вектора: X={x1, x2, …xj, …xn },
- 5. Представление результатов Правила классификации В задачах классификации и регрессии обнаруженная функциональная зависимость между переменными может быть
- 6. 1. Классификационные правила состоят из двух частей: условия и заключения: если (условие) то (заключение). Условием является
- 7. Относительная независимость связана с возможной их противоречивостью друг другу. Если переменные, характеризующие некоторый объект, удовлетворяют условным
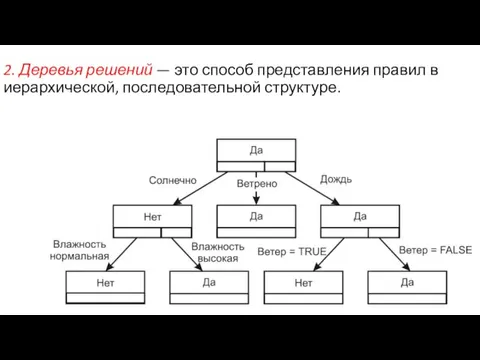
- 8. 2. Деревья решений — это способ представления правил в иерархической, последовательной структуре.
- 9. 3. Математическая функция выражает отношение зависимой переменной от независимых переменных. В этом случае анализируемые объекты рассматриваются
- 10. Очевидно, что все переменные должны быть представлены в виде числовых параметров. Для преобразования логических и категориальных
- 11. Другой способ представления исходно категориальной переменной в системе — это замена возможных значений набором двоичных признаков.
- 12. Методы построения правил классификации. Например, метод Naive Bayes Условная вероятность принадлежности объекта к cr при равенстве
- 13. Методы построения деревьев решений. Например, алгоритм покрытия Построение деревьев решений для каждого класса по отдельности. На
- 16. Методы построения математических функций. Семейство линейных функций Множественная линейная регрессия: Y = a1*X1 + a2*X2 +
- 17. Полиномиальная регрессия В полиномиальной регрессии степень некоторых независимых переменных превышает 1: Y = a1*X1 + (a2)²*X2
- 18. Линейная регрессия: Легко моделируется, полезна при создании не сложной зависимости, при небольшом количестве данных. Обозначения интуитивно-понятны.
- 19. Гребневая (ридж) регрессия В случае высокой коллинеарности переменных стандартная линейная и полиномиальная регрессии становятся неэффективными. Регрессия
- 20. Ансамбли моделей Разработано множество различных методов и алгоритмов формирования ансамблей. Цель объединения— улучшить (усилить) решение, которое
- 21. Правило 80/20 (Закон Парето) – эмпирическое правило, названное в честь экономиста и социолога Вильфредо Парето, в
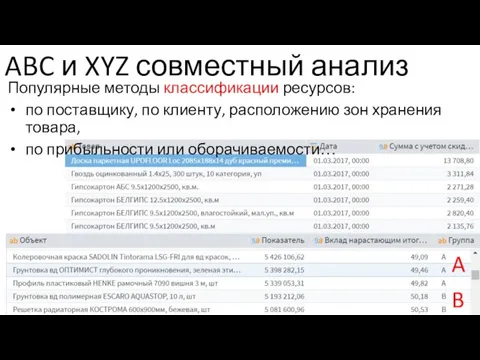
- 22. ABC и XYZ совместный анализ Популярные методы классификации ресурсов: по поставщику, по клиенту, расположению зон хранения
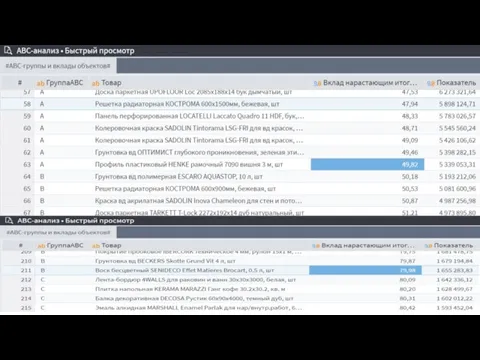
- 23. Существует классический способ ранжирования по АВС анализу в части прибыльности где: А — 80% прибыли В
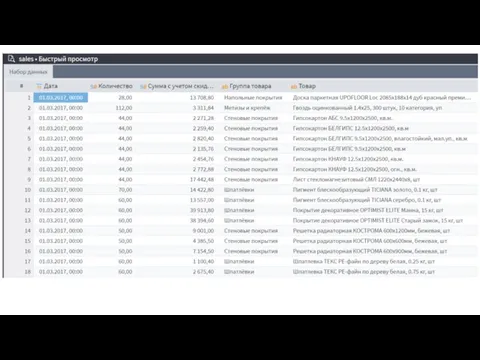
- 24. АВС анализ в управлении запасами (1) Эффективное управление запасами позволяет предприятию удовлетворять ожидания потребителей, создавая товарные
- 25. Анализ оборачиваемости товара (2) Оборачиваемость запасов - это показатель обновляемости товара в течение расчетного периода, например,
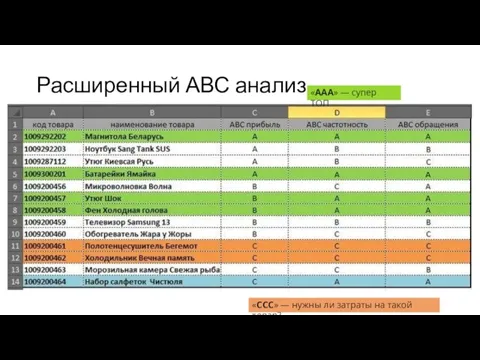
- 26. Расширенный АВС анализ (3) АВС анализ можно проводить по частотности заказов. Частотность заказов - сколько месяцев
- 27. Расширенный АВС анализ (4) Количество обращений означает, сколько отдельных заказов было сделано по каждому товару не
- 28. Расширенный АВС анализ «ААА» — супер ТОП «ССС» — нужны ли затраты на такой товар?
- 29. Выводы по расширенному АВС анализу: Товар по прибыльности относится к категории А, но в расширенном АВС
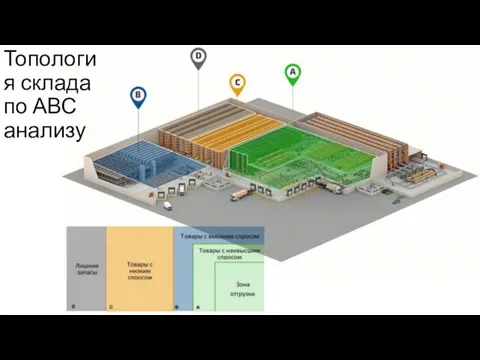
- 30. Топология склада по АВС анализу
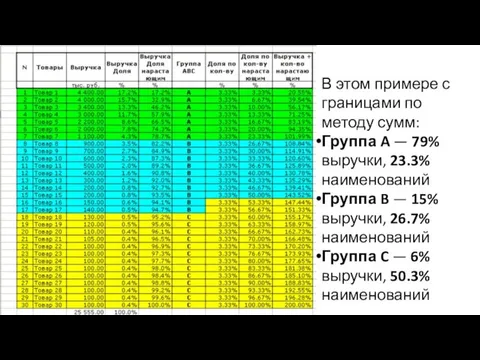
- 31. Простые методы определения границ групп ABC-анализа: эмпирический метод, метод сумм Границы определяются по значению суммы двух
- 32. В этом примере с границами по методу сумм: Группа A — 79% выручки, 23.3% наименований Группа
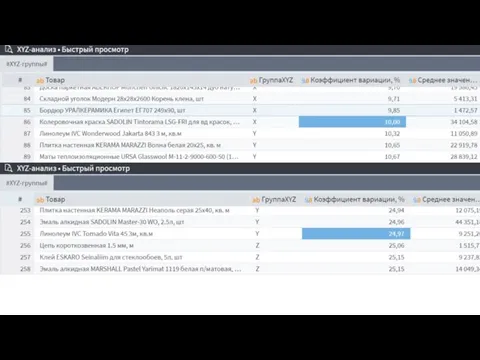
- 33. XYZ анализ XYZ анализ, это метод прогноза и анализа стабильности и колебаний спроса продаж по товарам
- 34. XYZ-анализ позволяет классифицировать объекты в зависимости от характера потребления и точности прогнозирования его изменения. X –
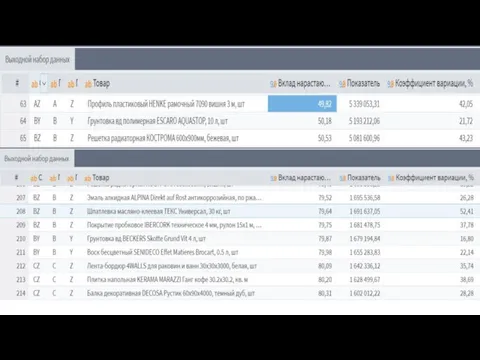
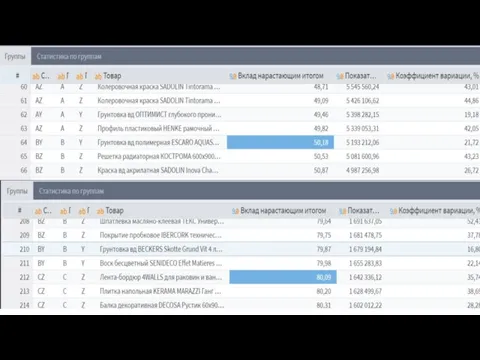
- 35. Формула расчета коэффициента вариации (колебаний) спроса =СТАНДОТКЛОНП(C2:E2)/СРЗНАЧ(C2:E2) Магнитола и Утюг относятся к категории Z Ноутбук и
- 36. XYZ анализ по клиентам Клиенты категории X — стабильные продажи. По таким клиентам достаточно просто прогнозировать
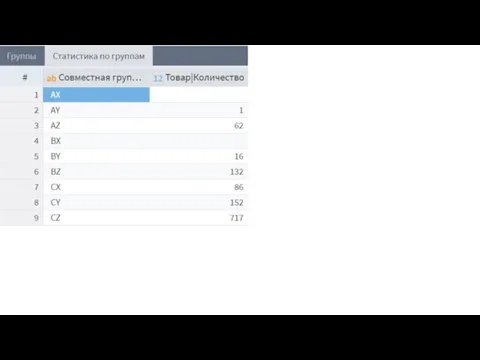
- 37. Матрица ABC-XYZ – единый анализ Результаты ABC и XYZ анализа можно совместить и получить разделение на
- 46. Скачать презентацию
Слайд 2Классификация и регрессия
Постановка задачи
В задачах классификации и регрессии требуется определить значение зависимой
Классификация и регрессия
Постановка задачи
В задачах классификации и регрессии требуется определить значение зависимой

Слайд 3Формально задачу классификации и регрессии можно описать следующим образом.
Имеется множество объектов:
Формально задачу классификации и регрессии можно описать следующим образом.
Имеется множество объектов:

Слайд 4В Data Mining часто набор независимых переменных обозначают в виде вектора:
X={x1,
В Data Mining часто набор независимых переменных обозначают в виде вектора:
X={x1,

Слайд 5Представление результатов
Правила классификации
В задачах классификации и регрессии обнаруженная функциональная зависимость между переменными
Представление результатов
Правила классификации
В задачах классификации и регрессии обнаруженная функциональная зависимость между переменными

Слайд 61. Классификационные правила состоят из двух частей: условия и заключения:
если (условие)
1. Классификационные правила состоят из двух частей: условия и заключения:
если (условие)

Слайд 7Относительная независимость связана с возможной их противоречивостью друг другу.
Если переменные, характеризующие
Относительная независимость связана с возможной их противоречивостью друг другу.
Если переменные, характеризующие

Слайд 82. Деревья решений — это способ представления правил в иерархической, последовательной структуре.
2. Деревья решений — это способ представления правил в иерархической, последовательной структуре.
Слайд 93. Математическая функция выражает отношение зависимой переменной от независимых переменных.
В этом
3. Математическая функция выражает отношение зависимой переменной от независимых переменных.
В этом

Слайд 10Очевидно, что все переменные должны быть представлены в виде числовых параметров.
Для
Очевидно, что все переменные должны быть представлены в виде числовых параметров.
Для

Слайд 11Другой способ представления исходно категориальной переменной в системе — это замена возможных
Другой способ представления исходно категориальной переменной в системе — это замена возможных

Слайд 12Методы построения правил классификации. Например, метод Naive Bayes
Условная вероятность принадлежности объекта к
Методы построения правил классификации. Например, метод Naive Bayes
Условная вероятность принадлежности объекта к

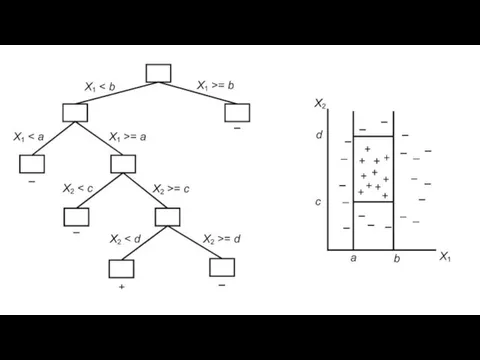
Слайд 13Методы построения деревьев решений. Например, алгоритм покрытия
Построение деревьев решений для каждого класса
Методы построения деревьев решений. Например, алгоритм покрытия
Построение деревьев решений для каждого класса


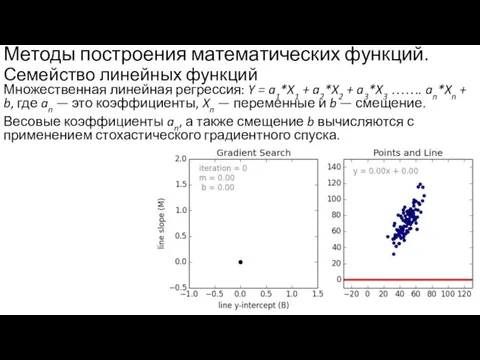
Слайд 16Методы построения математических функций. Семейство линейных функций
Множественная линейная регрессия: Y = a1*X1
Методы построения математических функций. Семейство линейных функций
Множественная линейная регрессия: Y = a1*X1
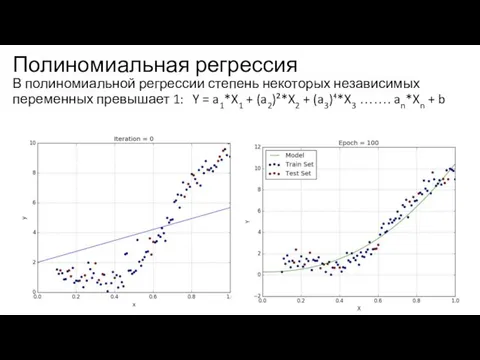
Слайд 17Полиномиальная регрессия
В полиномиальной регрессии степень некоторых независимых переменных превышает 1: Y =
Полиномиальная регрессия
В полиномиальной регрессии степень некоторых независимых переменных превышает 1: Y =
Слайд 18Линейная регрессия:
Легко моделируется, полезна при создании не сложной зависимости, при небольшом количестве
Линейная регрессия:
Легко моделируется, полезна при создании не сложной зависимости, при небольшом количестве

Слайд 19Гребневая (ридж) регрессия
В случае высокой коллинеарности переменных стандартная линейная и полиномиальная регрессии
Гребневая (ридж) регрессия
В случае высокой коллинеарности переменных стандартная линейная и полиномиальная регрессии

Слайд 20Ансамбли моделей
Разработано множество различных методов и алгоритмов формирования ансамблей.
Цель объединения— улучшить
Ансамбли моделей
Разработано множество различных методов и алгоритмов формирования ансамблей.
Цель объединения— улучшить

Слайд 21Правило 80/20 (Закон Парето) – эмпирическое правило, названное в честь экономиста и
Правило 80/20 (Закон Парето) – эмпирическое правило, названное в честь экономиста и

Слайд 22ABC и XYZ совместный анализ
Популярные методы классификации ресурсов:
по поставщику, по клиенту,
ABC и XYZ совместный анализ
Популярные методы классификации ресурсов:
по поставщику, по клиенту,
Слайд 23Существует классический способ ранжирования по АВС анализу в части прибыльности где:
А —
Существует классический способ ранжирования по АВС анализу в части прибыльности где:
А —

Слайд 24АВС анализ в управлении запасами (1)
Эффективное управление запасами позволяет предприятию удовлетворять ожидания
АВС анализ в управлении запасами (1)
Эффективное управление запасами позволяет предприятию удовлетворять ожидания

Слайд 25Анализ оборачиваемости товара (2)
Оборачиваемость запасов - это показатель обновляемости товара в течение
Анализ оборачиваемости товара (2)
Оборачиваемость запасов - это показатель обновляемости товара в течение

Слайд 26Расширенный АВС анализ (3)
АВС анализ можно проводить по частотности заказов.
Частотность заказов
Расширенный АВС анализ (3)
АВС анализ можно проводить по частотности заказов.
Частотность заказов

Слайд 27Расширенный АВС анализ (4)
Количество обращений означает, сколько отдельных заказов было сделано по
Расширенный АВС анализ (4)
Количество обращений означает, сколько отдельных заказов было сделано по

Слайд 28Расширенный АВС анализ
«ААА» — супер ТОП
«ССС» — нужны ли затраты на такой
Расширенный АВС анализ
«ААА» — супер ТОП
«ССС» — нужны ли затраты на такой
Слайд 29Выводы по расширенному АВС анализу:
Товар по прибыльности относится к категории А, но
Выводы по расширенному АВС анализу:
Товар по прибыльности относится к категории А, но

Слайд 30Топология склада по АВС анализу
Топология склада по АВС анализу
Слайд 31Простые методы определения границ групп ABC-анализа: эмпирический метод, метод сумм
Границы
Простые методы определения границ групп ABC-анализа: эмпирический метод, метод сумм
Границы

Слайд 32В этом примере с границами по методу сумм:
Группа A — 79% выручки, 23.3%
В этом примере с границами по методу сумм:
Группа A — 79% выручки, 23.3%
Слайд 33XYZ анализ
XYZ анализ, это метод прогноза и анализа стабильности и колебаний спроса
XYZ анализ
XYZ анализ, это метод прогноза и анализа стабильности и колебаний спроса

Слайд 34XYZ-анализ позволяет классифицировать объекты в зависимости от характера потребления и точности прогнозирования
XYZ-анализ позволяет классифицировать объекты в зависимости от характера потребления и точности прогнозирования

Слайд 35Формула расчета коэффициента вариации (колебаний) спроса
=СТАНДОТКЛОНП(C2:E2)/СРЗНАЧ(C2:E2)
Магнитола и Утюг относятся к категории Z
Ноутбук и
Формула расчета коэффициента вариации (колебаний) спроса
=СТАНДОТКЛОНП(C2:E2)/СРЗНАЧ(C2:E2)
Магнитола и Утюг относятся к категории Z
Ноутбук и

Слайд 36XYZ анализ по клиентам
Клиенты категории X — стабильные продажи. По таким клиентам
XYZ анализ по клиентам
Клиенты категории X — стабильные продажи. По таким клиентам

Слайд 37Матрица ABC-XYZ – единый анализ
Результаты ABC и XYZ анализа можно совместить и
Матрица ABC-XYZ – единый анализ
Результаты ABC и XYZ анализа можно совместить и

 Системы счисления
Системы счисления Аппаратная реализация компьютера
Аппаратная реализация компьютера Программирование на языке C++
Программирование на языке C++ ВК: продвижение страницы
ВК: продвижение страницы Домашняя компьютерная сеть
Домашняя компьютерная сеть Data Warehouse Concepts and Architectures
Data Warehouse Concepts and Architectures Dugapur PU mix sistem
Dugapur PU mix sistem Теория игр
Теория игр Компьютерный дизайн. Цветовые модели
Компьютерный дизайн. Цветовые модели inf_92882
inf_92882 Информация и информационные системы
Информация и информационные системы Инструкция. Web- Quest Mechanic’s Trap
Инструкция. Web- Quest Mechanic’s Trap net intro
net intro Выпускная квалификационная работа: применение XML технологий на MS SQL для сопровождения корпоративных приложений
Выпускная квалификационная работа: применение XML технологий на MS SQL для сопровождения корпоративных приложений Фейковые новости и как их отличить от настоящих
Фейковые новости и как их отличить от настоящих Лекция 3-4
Лекция 3-4 Claroline. Системы дистанционного обучения
Claroline. Системы дистанционного обучения Алгоритмы
Алгоритмы Construct 2.создаем спиннер
Construct 2.создаем спиннер Презентация5_Исключительные ситуации
Презентация5_Исключительные ситуации Многозадачность как свойство операционной системы. Параллельные последовательности
Многозадачность как свойство операционной системы. Параллельные последовательности Розробка та створення Інтернет-провайдери Харкова
Розробка та створення Інтернет-провайдери Харкова Начало. Конец
Начало. Конец Режим анализ ZEMAX
Режим анализ ZEMAX Рабочий стол заказов
Рабочий стол заказов Презентация
Презентация Innovative technologies of event-management in the field of media and information literacy (MIL)
Innovative technologies of event-management in the field of media and information literacy (MIL) Информационная система
Информационная система