- Лекция 6_2019

Содержание
- 2. Часть 1. Умножение матрицы на вектор Умножение матрицы на вектор или Задача умножения матрицы на вектор
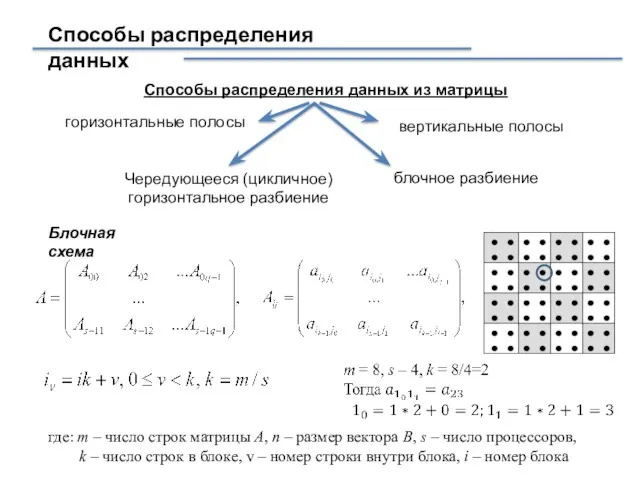
- 3. Способы распределения данных Способы распределения данных из матрицы горизонтальные полосы вертикальные полосы Чередующееся (цикличное) горизонтальное разбиение
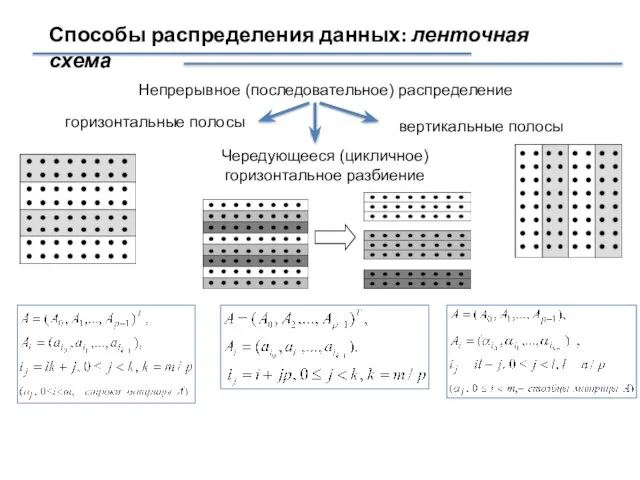
- 4. Способы распределения данных: ленточная схема Непрерывное (последовательное) распределение горизонтальные полосы вертикальные полосы Чередующееся (цикличное) горизонтальное разбиение
- 5. Последовательный алгоритм Для выполнения матрично-векторного умножения необходимо выполнить m операций вычисления скалярного произведения Трудоемкость вычислений имеет
- 6. Алгоритм 1: ленточная схема (разбиение матрицы по строкам) Базовая подзадача - операция скалярного умножения одной строки
- 7. Результаты вычислительных экспериментов
- 8. Алгоритм 2: ленточная схема (разбиение матрицы по столбцам) Базовая подзадача - операция умножения столбца матрицы А
- 9. Схема информационного взаимодействия Для получения элементов результирующего вектора с подзадачи должны обменяться своими промежуточными данными
- 10. Результаты вычислительных экспериментов
- 11. Алгоритм 3: блочная схема Пусть: количество процессоров p=s·q , количество строк матрицы является кратным s: m=k·s
- 12. Алгоритм 3: блочная схема Поэлементное суммирование векторов частичных результатов для каждой горизонтальной полосы (редукция) блоков матрицы
- 13. Результаты вычислительных экспериментов Общее количество базовых подзадач совпадает с числом процессоров p, p=s·q Большое количество блоков
- 14. Сравнение алгоритмов
- 15. Часть 2. Умножение матриц Умножение матриц: или Задача умножения матрицы на матрицу может быть сведена к
- 16. Последовательный базовый алгоритм double MatrixA[Size][Size]; double MatrixB[Size][Size]; double MatrixC[Size][Size]; int i,j,k; ... for (i=0; i for
- 17. Результаты вычислительных экспериментов Эксперименты проводились на двухпроцессорном вычислитель-ном узле на базе четырех-ядерных процессоров Intel Xeon E5320,
- 18. Часть 2. Умножение матриц × =
- 19. Умножение матриц × =
- 20. Умножение матриц Процесс хранит одну строку матрицы A и все столбцы матрицы B
- 21. Трудоемкость
- 22. Способы распределения данных Способы распределения данных матрицы горизонтальные полосы вертикальные полосы Чередующееся (цикличное) горизонтальное разбиение блочное
- 23. Параллельный алгоритм 1: ленточная схема Каждая подзадача содержит по одной строке матрицы А и одному столбцу
- 24. Параллельный алгоритм 1: ленточная схема Топология информационных связей подзадач в виде кольцевой структуры: 1 2 3
- 25. Результаты вычислительных экспериментов
- 26. Параллельный алгоритм 1: ленточная схема void MatrixMultiplicationMPI(double *&A, double *&B, double *&C, int &Size) { int
- 27. int NextProc; int PrevProc; for (p=1; p { NextProc = ProcRank+1; if (ProcRank == ProcNum-1) NextProc
- 28. Параллельный алгоритм 2: ленточная схема Идея: распределение данных в разбиении матриц A и B по строкам
- 29. Параллельный алгоритм 2: ленточная схема
- 30. Параллельный алгоритм 2: ленточная схема Алгоритм Вначале производится рассылка в процесс ранга K элементов K-й строки
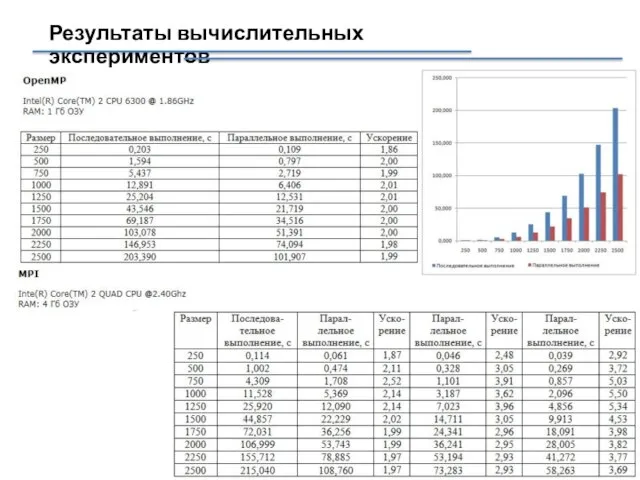
- 31. Результаты вычислительных экспериментов
- 32. Простой блочный алгоритм
- 33. Простой блочный алгоритм Вычисление произведения матриц в конечном поле с помощью простой параллельной схемы умножения. Коэффициент
- 34. Метод Фокса Распределение данных происходит по Блочной схеме Базовая подзадача - процедура вычисления всех элементов одного
- 35. Параллельный алгоритм 2: метод Фокса Выделение информационных зависимостей - для каждой итерации l, 0≤ l блок
- 36. Схема информационного взаимодействия Параллельный алгоритм 2: метод Фокса Масштабирование и распределение подзадач по процессорам Размеры блоков
- 37. Пример: метод Фокса Итерация 1. Диагональные процессы раздают свои элементы матрицы А направо соседям, матрица В
- 38. Пример: метод Фокса Итерация 2. Верхнедиагональные процессы раздают свои элементы матрицы А направо соседям. В матрице
- 39. Пример: метод Фокса х = Итерация 2. Итерация 1. Итерация 3.
- 40. Результаты вычислительных экспериментов
- 41. Алгоритм Кэннона при блочном разделении данных Базовая подзадача - процедура вычисления всех элементов одного из блоков
- 42. Перераспределение блоков исходных матриц на начальном этапе выполнения метода Параллельный алгоритм 3: метод Кэннона
- 43. Пример: метод Кэннона Итерация 1. Циклический сдвиг по строкам: 0-я строка на 0 элементов влево 1-я
- 44. Пример: метод Фокса х = Итерация 2. Итерация 1. Итерация 3.
- 45. Выделение информационных зависимостей В результате начального распределения в каждой базовой подзадаче будут располагаться блоки, которые могут
- 46. Результаты вычислительных экспериментов
- 48. Скачать презентацию
Слайд 2Часть 1. Умножение матрицы на вектор
Умножение матрицы на вектор
или
Задача умножения матрицы на
Часть 1. Умножение матрицы на вектор
Умножение матрицы на вектор
или
Задача умножения матрицы на

Слайд 3Способы распределения данных
Способы распределения данных из матрицы
горизонтальные полосы
вертикальные полосы
Чередующееся (цикличное) горизонтальное разбиение
блочное
Способы распределения данных
Способы распределения данных из матрицы
горизонтальные полосы
вертикальные полосы
Чередующееся (цикличное) горизонтальное разбиение
блочное
Слайд 4Способы распределения данных: ленточная схема
Непрерывное (последовательное) распределение
горизонтальные полосы
вертикальные полосы
Чередующееся (цикличное) горизонтальное разбиение
Способы распределения данных: ленточная схема
Непрерывное (последовательное) распределение
горизонтальные полосы
вертикальные полосы
Чередующееся (цикличное) горизонтальное разбиение
Слайд 5Последовательный алгоритм
Для выполнения матрично-векторного умножения необходимо выполнить m операций вычисления скалярного произведения
Трудоемкость
Последовательный алгоритм
Для выполнения матрично-векторного умножения необходимо выполнить m операций вычисления скалярного произведения
Трудоемкость

Слайд 6Алгоритм 1: ленточная схема (разбиение матрицы по строкам)
Базовая подзадача - операция скалярного
Алгоритм 1: ленточная схема (разбиение матрицы по строкам)
Базовая подзадача - операция скалярного
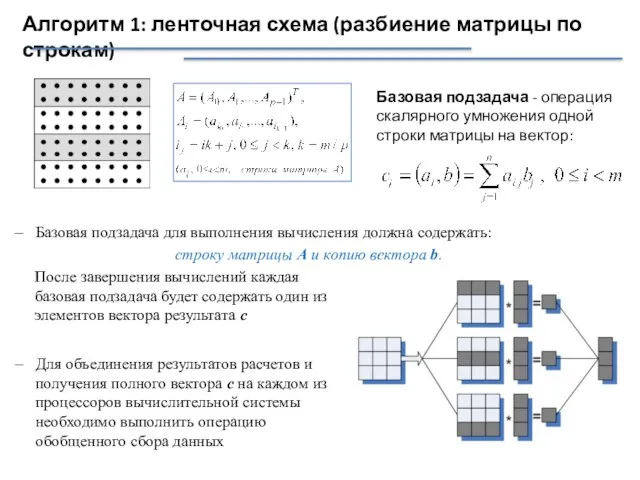
Слайд 7Результаты вычислительных экспериментов
Результаты вычислительных экспериментов
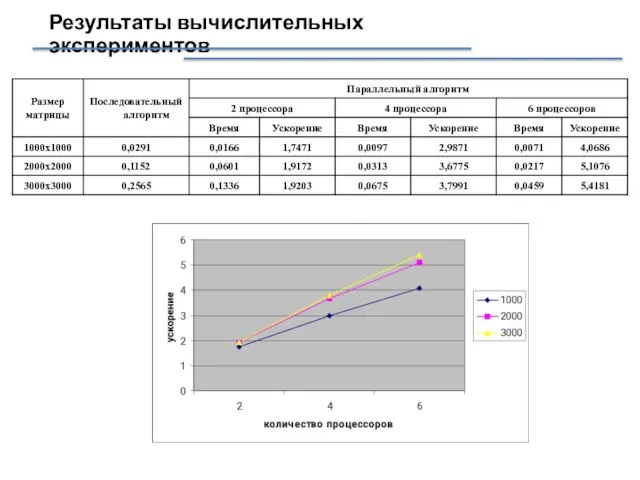
Слайд 8Алгоритм 2: ленточная схема (разбиение матрицы по столбцам)
Базовая подзадача - операция умножения
Алгоритм 2: ленточная схема (разбиение матрицы по столбцам)
Базовая подзадача - операция умножения

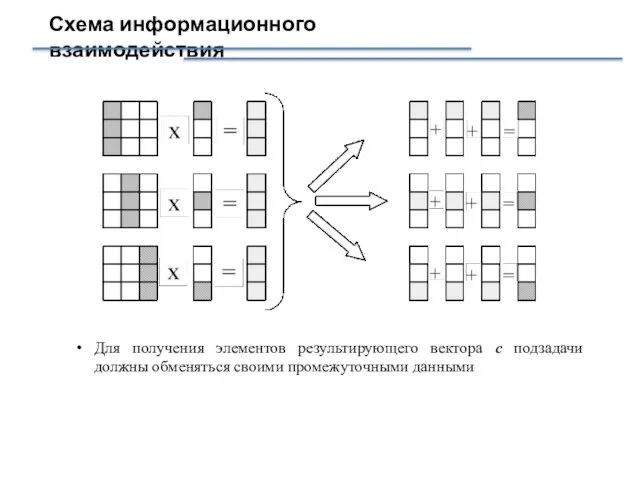
Слайд 9Схема информационного взаимодействия
Для получения элементов результирующего вектора с подзадачи должны обменяться
Схема информационного взаимодействия
Для получения элементов результирующего вектора с подзадачи должны обменяться
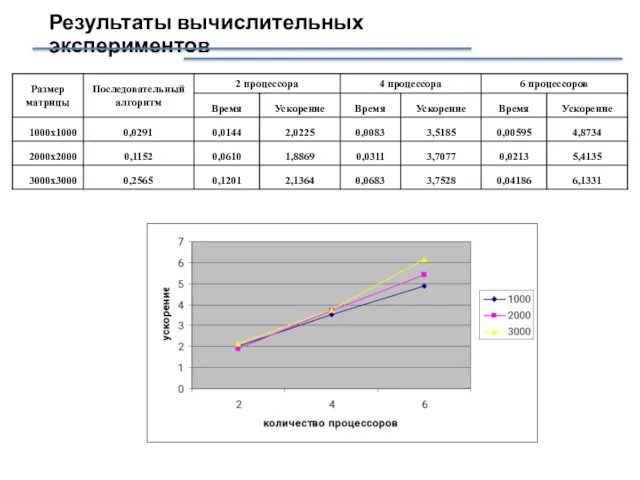
Слайд 10Результаты вычислительных экспериментов
Результаты вычислительных экспериментов
Слайд 11Алгоритм 3: блочная схема
Пусть:
количество процессоров p=s·q ,
количество строк матрицы является кратным
Алгоритм 3: блочная схема
Пусть:
количество процессоров p=s·q ,
количество строк матрицы является кратным

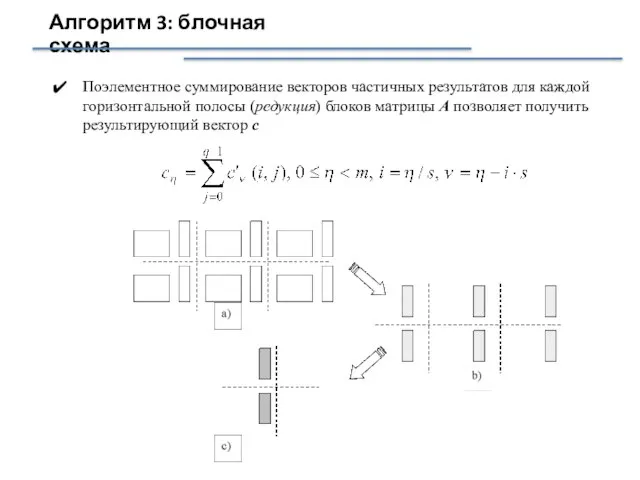
Слайд 12Алгоритм 3: блочная схема
Поэлементное суммирование векторов частичных результатов для каждой горизонтальной полосы
Алгоритм 3: блочная схема
Поэлементное суммирование векторов частичных результатов для каждой горизонтальной полосы
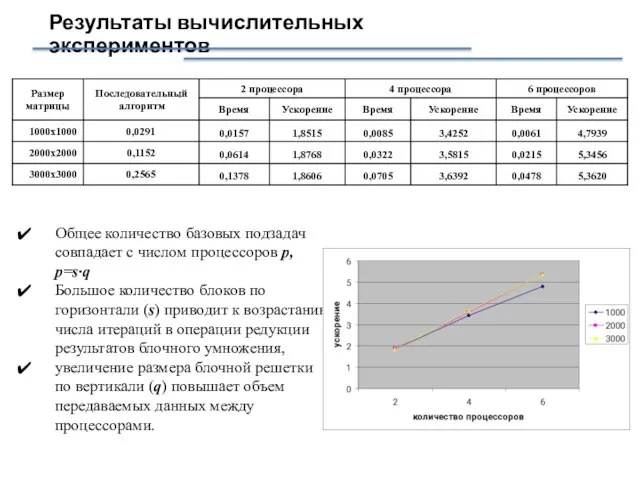
Слайд 13Результаты вычислительных экспериментов
Общее количество базовых подзадач совпадает с числом процессоров p, p=s·q
Большое
Результаты вычислительных экспериментов
Общее количество базовых подзадач совпадает с числом процессоров p, p=s·q
Большое
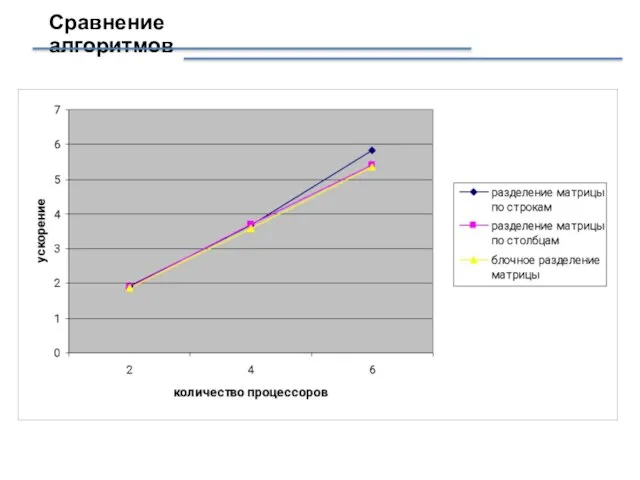
Слайд 14Сравнение алгоритмов
Сравнение алгоритмов
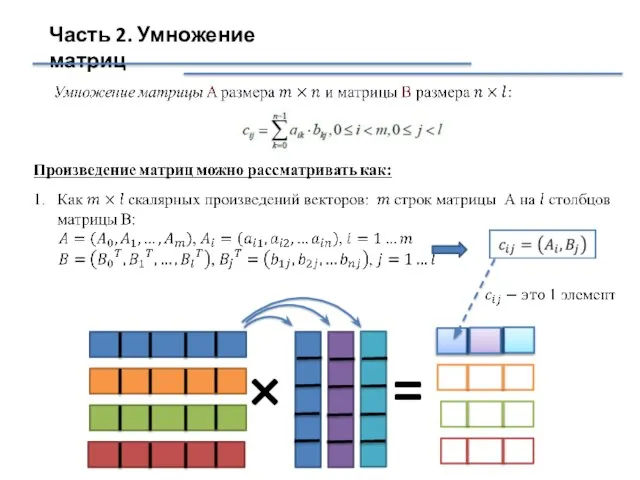
Слайд 15Часть 2. Умножение матриц
Умножение матриц:
или
Задача умножения матрицы на матрицу может быть сведена
Часть 2. Умножение матриц
Умножение матриц:
или
Задача умножения матрицы на матрицу может быть сведена

Слайд 16Последовательный базовый алгоритм
double MatrixA[Size][Size];
double MatrixB[Size][Size];
double MatrixC[Size][Size];
int i,j,k;
...
for (i=0; i for
Последовательный базовый алгоритм
double MatrixA[Size][Size];
double MatrixB[Size][Size];
double MatrixC[Size][Size];
int i,j,k;
...
for (i=0; i
![Последовательный базовый алгоритм double MatrixA[Size][Size]; double MatrixB[Size][Size]; double MatrixC[Size][Size]; int i,j,k; ...](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/906018/slide-15.jpg)
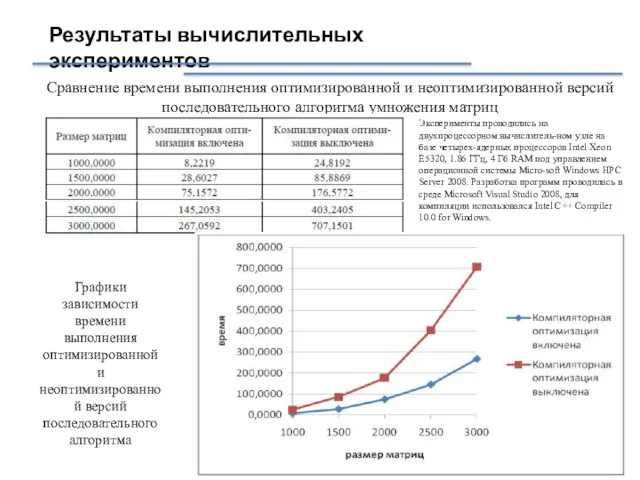
Слайд 17Результаты вычислительных экспериментов
Эксперименты проводились на двухпроцессорном вычислитель-ном узле на базе четырех-ядерных
Результаты вычислительных экспериментов
Эксперименты проводились на двухпроцессорном вычислитель-ном узле на базе четырех-ядерных
Слайд 18Часть 2. Умножение матриц
×
=
Часть 2. Умножение матриц
×
=
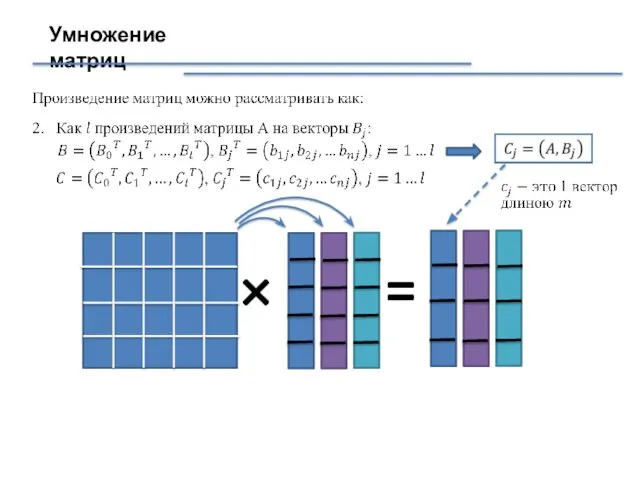
Слайд 19Умножение матриц
×
=
Умножение матриц
×
=
Слайд 20Умножение матриц
Процесс хранит одну строку матрицы A и все столбцы матрицы B
Умножение матриц
Процесс хранит одну строку матрицы A и все столбцы матрицы B

Слайд 21Трудоемкость
Трудоемкость

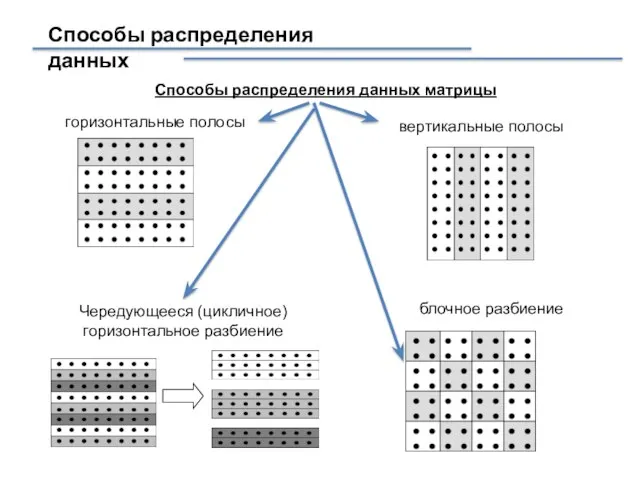
Слайд 22Способы распределения данных
Способы распределения данных матрицы
горизонтальные полосы
вертикальные полосы
Чередующееся (цикличное) горизонтальное разбиение
блочное разбиение
Способы распределения данных
Способы распределения данных матрицы
горизонтальные полосы
вертикальные полосы
Чередующееся (цикличное) горизонтальное разбиение
блочное разбиение
Слайд 23Параллельный алгоритм 1: ленточная схема
Каждая подзадача содержит по одной строке матрицы А
Параллельный алгоритм 1: ленточная схема
Каждая подзадача содержит по одной строке матрицы А

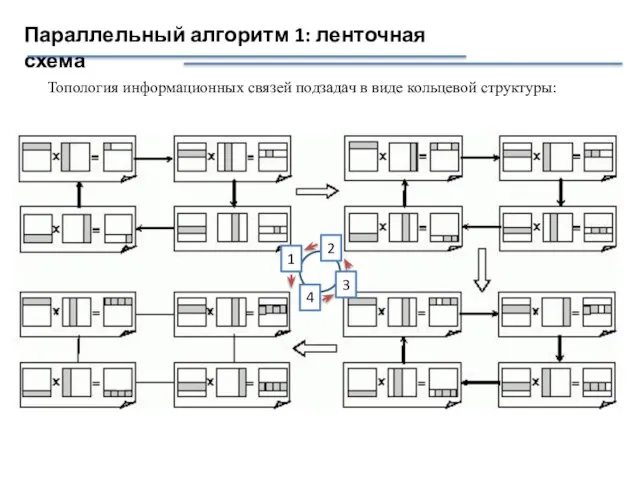
Слайд 24Параллельный алгоритм 1: ленточная схема
Топология информационных связей подзадач в виде кольцевой структуры:
1
2
3
4
Параллельный алгоритм 1: ленточная схема
Топология информационных связей подзадач в виде кольцевой структуры:
1
2
3
4
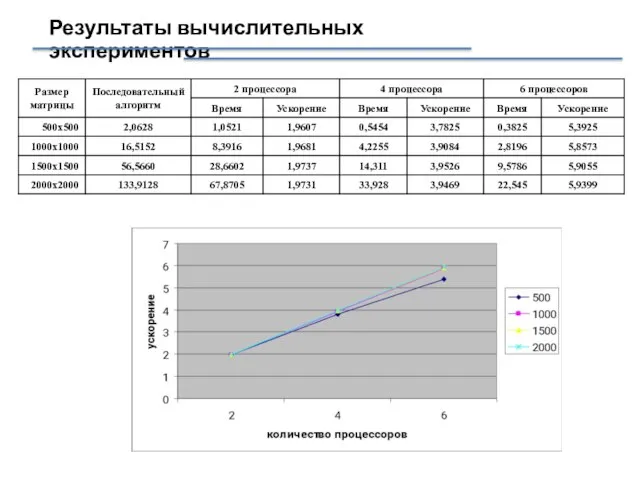
Слайд 25Результаты вычислительных экспериментов
Результаты вычислительных экспериментов
Слайд 26Параллельный алгоритм 1: ленточная схема
void MatrixMultiplicationMPI(double *&A, double *&B, double *&C, int
Параллельный алгоритм 1: ленточная схема
void MatrixMultiplicationMPI(double *&A, double *&B, double *&C, int

Слайд 27int NextProc;
int PrevProc;
for (p=1; p < ProcNum; p++)
{ NextProc
int NextProc;
int PrevProc;
for (p=1; p < ProcNum; p++)
{ NextProc

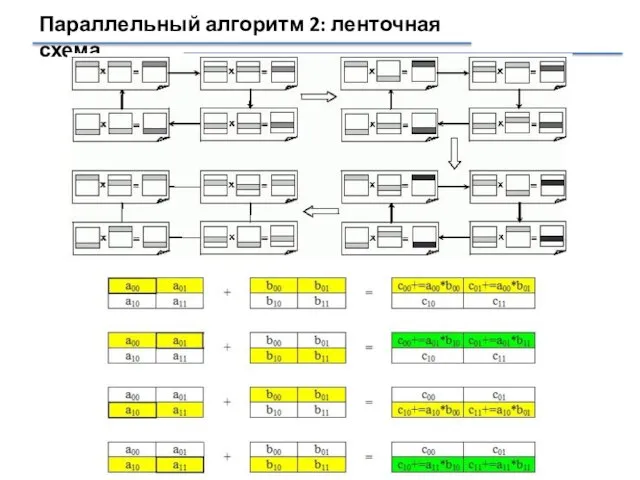
Слайд 28Параллельный алгоритм 2: ленточная схема
Идея: распределение данных в разбиении матриц A и
Параллельный алгоритм 2: ленточная схема
Идея: распределение данных в разбиении матриц A и

Слайд 29Параллельный алгоритм 2: ленточная схема
Параллельный алгоритм 2: ленточная схема
Слайд 30Параллельный алгоритм 2: ленточная схема
Алгоритм
Вначале производится рассылка в процесс ранга K элементов
Параллельный алгоритм 2: ленточная схема
Алгоритм
Вначале производится рассылка в процесс ранга K элементов

Слайд 31Результаты вычислительных экспериментов
Результаты вычислительных экспериментов
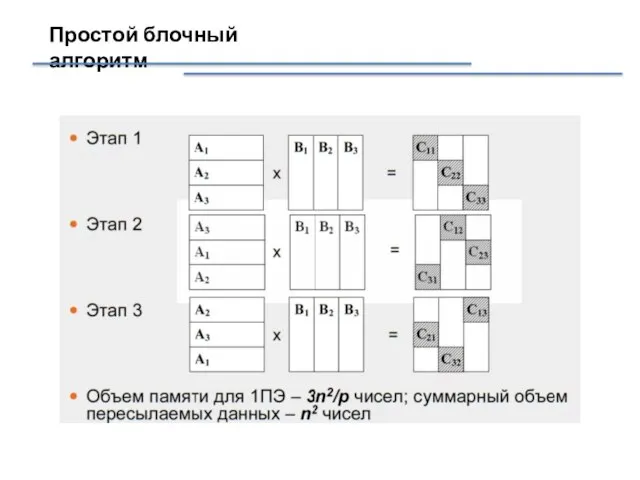
Слайд 32Простой блочный алгоритм
Простой блочный алгоритм
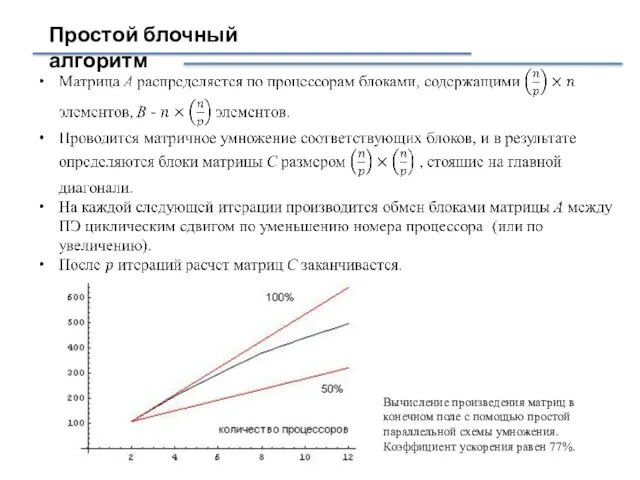
Слайд 33Простой блочный алгоритм
Вычисление произведения матриц в конечном поле с помощью простой параллельной
Простой блочный алгоритм
Вычисление произведения матриц в конечном поле с помощью простой параллельной
Слайд 34Метод Фокса
Распределение данных происходит по Блочной схеме
Базовая подзадача - процедура вычисления всех
Метод Фокса
Распределение данных происходит по Блочной схеме
Базовая подзадача - процедура вычисления всех

Слайд 35Параллельный алгоритм 2: метод Фокса
Выделение информационных зависимостей - для каждой итерации l,
Параллельный алгоритм 2: метод Фокса
Выделение информационных зависимостей - для каждой итерации l,

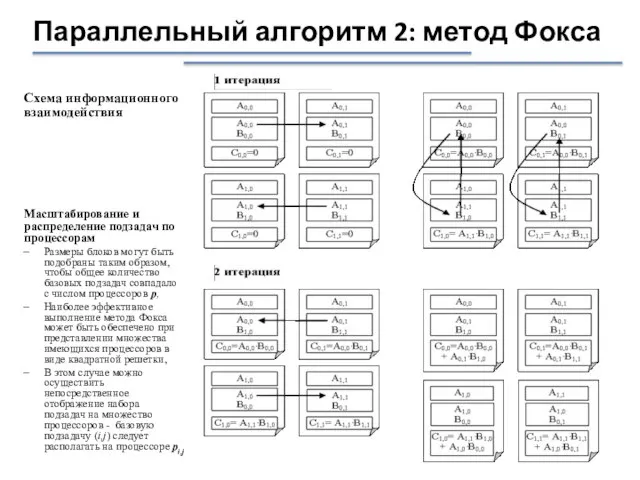
Слайд 36Схема информационного взаимодействия
Параллельный алгоритм 2: метод Фокса
Масштабирование и распределение подзадач по
Схема информационного взаимодействия
Параллельный алгоритм 2: метод Фокса
Масштабирование и распределение подзадач по
Слайд 37Пример: метод Фокса
Итерация 1. Диагональные процессы раздают свои элементы матрицы А направо
Пример: метод Фокса
Итерация 1. Диагональные процессы раздают свои элементы матрицы А направо

Слайд 38Пример: метод Фокса
Итерация 2. Верхнедиагональные процессы раздают свои элементы матрицы А направо
Пример: метод Фокса
Итерация 2. Верхнедиагональные процессы раздают свои элементы матрицы А направо
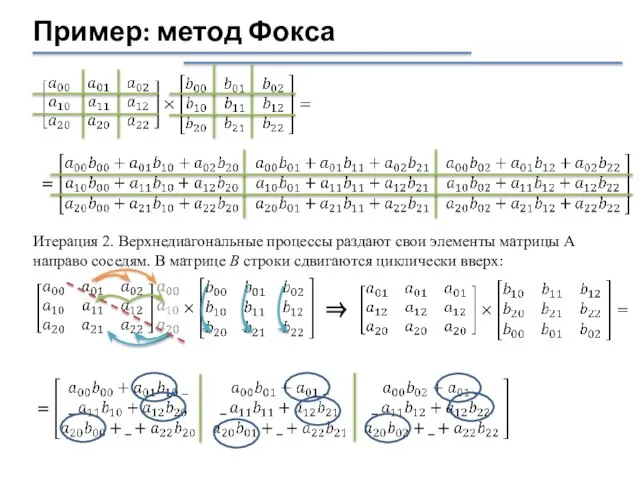
Слайд 39Пример: метод Фокса
х
=
Итерация 2.
Итерация 1.
Итерация 3.
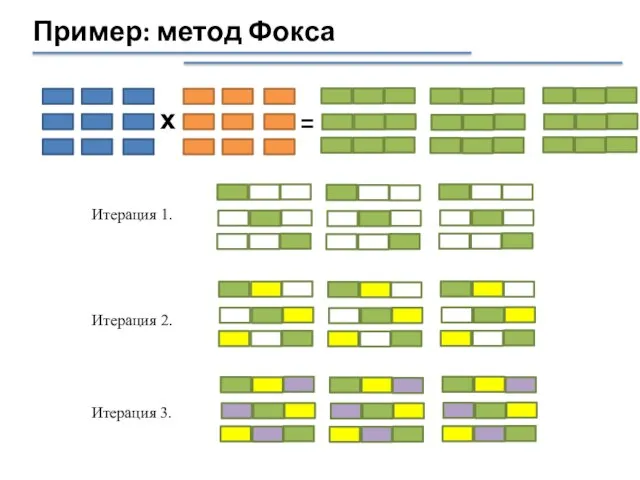
Пример: метод Фокса
х
=
Итерация 2.
Итерация 1.
Итерация 3.
Слайд 40Результаты вычислительных экспериментов
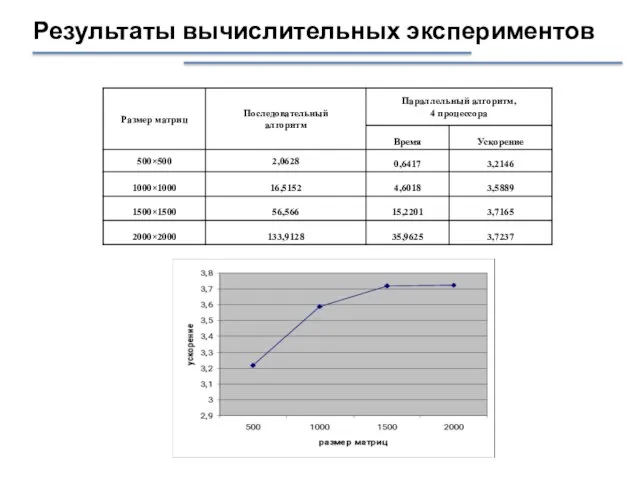
Результаты вычислительных экспериментов
Слайд 41Алгоритм Кэннона при блочном разделении данных
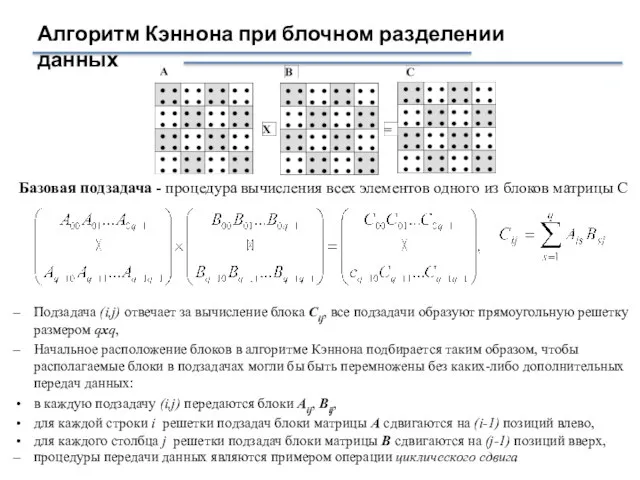
Базовая подзадача - процедура вычисления всех элементов
Алгоритм Кэннона при блочном разделении данных
Базовая подзадача - процедура вычисления всех элементов
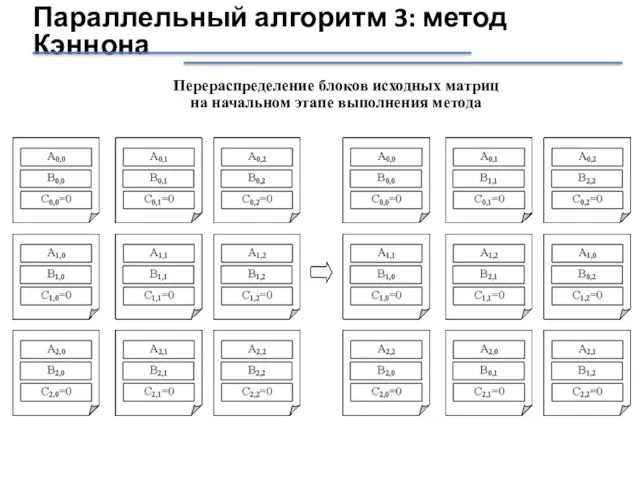
Слайд 42Перераспределение блоков исходных матриц
на начальном этапе выполнения метода
Параллельный алгоритм 3: метод
Перераспределение блоков исходных матриц
на начальном этапе выполнения метода
Параллельный алгоритм 3: метод
Слайд 43Пример: метод Кэннона
Итерация 1. Циклический сдвиг по строкам: 0-я строка на 0
Пример: метод Кэннона
Итерация 1. Циклический сдвиг по строкам: 0-я строка на 0

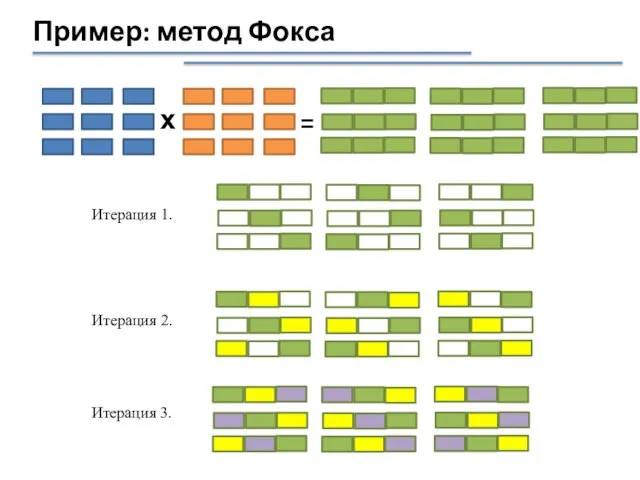
Слайд 44Пример: метод Фокса
х
=
Итерация 2.
Итерация 1.
Итерация 3.
Пример: метод Фокса
х
=
Итерация 2.
Итерация 1.
Итерация 3.
Слайд 45Выделение информационных зависимостей
В результате начального распределения в каждой базовой подзадаче будут располагаться
Выделение информационных зависимостей
В результате начального распределения в каждой базовой подзадаче будут располагаться

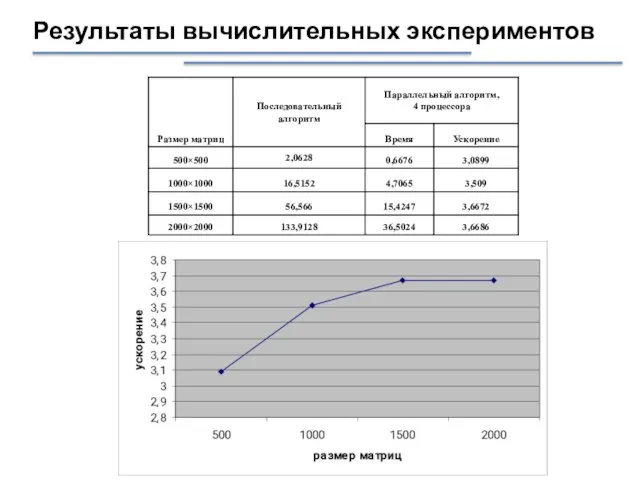
Слайд 46Результаты вычислительных экспериментов
Результаты вычислительных экспериментов
 Электронный читальный зал для официального интернет-ресурса архивной службы
Электронный читальный зал для официального интернет-ресурса архивной службы Настройка МФА
Настройка МФА Создание web-сайта буктрейлеров литературы, рекомендованной лицеистам для чтения летом для школьной библиотеки
Создание web-сайта буктрейлеров литературы, рекомендованной лицеистам для чтения летом для школьной библиотеки Реализация типового сервиса вопросов и ответов
Реализация типового сервиса вопросов и ответов MT_webinar_19.03 (1)
MT_webinar_19.03 (1) Разработка АИС Советник для анализа и принятия решений при торговых операций на рынке Forex
Разработка АИС Советник для анализа и принятия решений при торговых операций на рынке Forex Как давать фотографию в инстаграм на ПК
Как давать фотографию в инстаграм на ПК Персональный сайт учителя как средство повышения профессиональной компетенции учителя на примере предмета окружающий мир
Персональный сайт учителя как средство повышения профессиональной компетенции учителя на примере предмета окружающий мир Формализмы как средство представления знаний
Формализмы как средство представления знаний Topslide. Дизайн, эффективность, скорость
Topslide. Дизайн, эффективность, скорость Троичные ЭВМ и перспективы их применения
Троичные ЭВМ и перспективы их применения Реализация алгоритмов в компьютере. Язык С++. Лекция 2
Реализация алгоритмов в компьютере. Язык С++. Лекция 2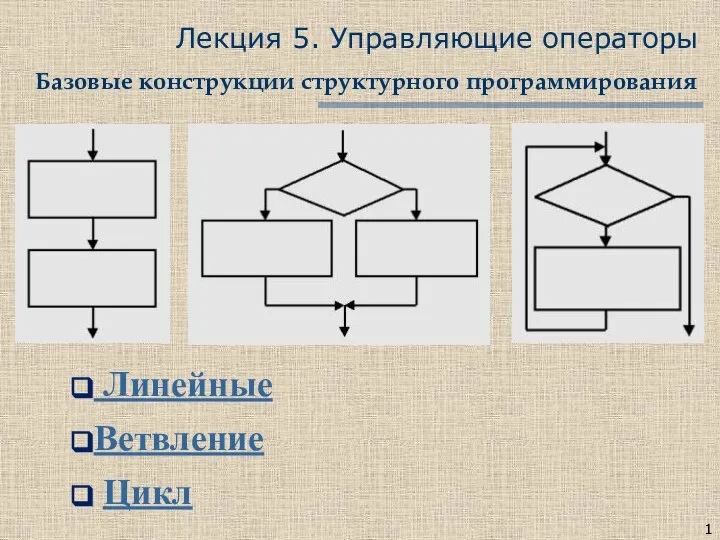 Управляющие операторы. Базовые конструкции структурного программирования. Лекция 5
Управляющие операторы. Базовые конструкции структурного программирования. Лекция 5 Электронный документооборот
Электронный документооборот Cети ЦВМ - системообразующий элемент сложных технических систем
Cети ЦВМ - системообразующий элемент сложных технических систем Arm builder. Создание docker-образа для компиляции программ и библиотек под arm архитектурой
Arm builder. Создание docker-образа для компиляции программ и библиотек под arm архитектурой Презентация на тему Введение в информатику
Презентация на тему Введение в информатику  Цикл с параметром в Pascal. Lazarus
Цикл с параметром в Pascal. Lazarus Операционные системы
Операционные системы Операторы ввода-вывода, целочисленная арифметика в языке Python
Операторы ввода-вывода, целочисленная арифметика в языке Python Информационные технологии в профессиональной деятельности
Информационные технологии в профессиональной деятельности Культура – информационно-обусловленный фактор становления личности
Культура – информационно-обусловленный фактор становления личности Paris MOU. Информационная система THETIS. Калькулятор расчета риска
Paris MOU. Информационная система THETIS. Калькулятор расчета риска Инструменты графического редактора Paint
Инструменты графического редактора Paint Лекция 1
Лекция 1 11 Функции (1) (1)
11 Функции (1) (1) Компьютерные вирусы
Компьютерные вирусы Алгоритмизация. Блок-схемы
Алгоритмизация. Блок-схемы