- Линейные блочные коды. Коды Хэмминга

Содержание
- 5. В показанном на рис. 1 случае не все слова размерности n принадлежат областям декодирования. Таких кодов
- 6. Код Хэмминга можно построить для любого натурального числа r ≥3. Этот код будет обладать рядом свойств
- 7. Кодирование линейных блочных кодов.
- 8. Поскольку между информационными и кодовыми словами существует взаимно однозначное соответствие, процесс кодирования может быть осуществлен с
- 9. Тогда уравнение (34) принимает вид Фактически, формула (36) описывает процедуру кодирования линейного блочного кода посредством образующей
- 10. Как правило рассматривают так называемые систематические или канонические формы матриц G и H, использующиеся для процедуры
- 11. Соответственно, исходя из свойства (37), следует, что проверочная матрица H состоит из единичной матрицы In-k и
- 12. Для примера также рассмотрим процедуру кодирования с использованием порождающей матрицы G (40). В качестве информационного слова
- 13. Декодирование линейных блочных кодов
- 14. Как и в случае кодирования, декодирование линейных блочных кодов можно осуществлять посредством таблицы по принципу максимального
- 15. В связи с этим используют механизм синдромного декодирования, основанный на использовании проверочной матрицы H. Для понимания
- 16. Соответственно, если хотя бы один из компонент вектора s = {s0; s1; s2} не равен нулю,
- 17. Если сравнить табл. 5.1 и проверочную матрицу (41), то можно увидеть, что ошибке в i-й позиции
- 18. Если наложить на вектор v ошибку в позиции v4 будет получен вектор r = [1 0
- 19. Расширенные коды Хэмминга.
- 20. Расширение кода Хэмминга заключается в дополнении кодового слова дополнительным двоичным разрядом так, чтобы оно содержало четное
- 21. Для примера рассмотрим расширение кода Хэмминга (7,4) - расширенный код Хэмминга (8,4). Кодовый вектор расширенного кода
- 22. Проверочная матрица кода (8,4) получается из проверочной матрицы кода (7,4) в два приема. 1.Слева к матрице
- 23. Рассмотрим процесс коррекции и обнаружения ошибок. Процедура исправления одиночных ошибок совпадает с таковой для обычных кодов
- 25. Скачать презентацию

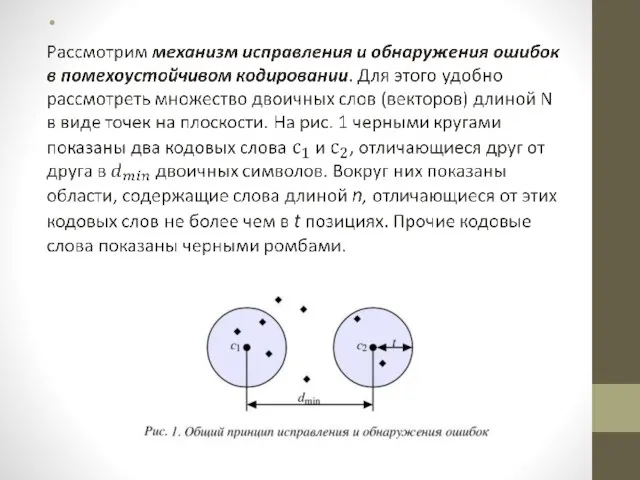

Слайд 5В показанном на рис. 1 случае не все слова размерности n принадлежат
В показанном на рис. 1 случае не все слова размерности n принадлежат

Слайд 6Код Хэмминга можно построить для любого натурального числа r ≥3. Этот код
Код Хэмминга можно построить для любого натурального числа r ≥3. Этот код

Слайд 7Кодирование линейных блочных кодов.
Кодирование линейных блочных кодов.

Слайд 8Поскольку между информационными и кодовыми словами существует взаимно однозначное соответствие, процесс кодирования
Поскольку между информационными и кодовыми словами существует взаимно однозначное соответствие, процесс кодирования

Слайд 9Тогда уравнение (34) принимает вид
Фактически, формула (36) описывает процедуру кодирования линейного блочного
Тогда уравнение (34) принимает вид
Фактически, формула (36) описывает процедуру кодирования линейного блочного
Фактически, формула (36) описывает процедуру кодирования линейного блочного

Слайд 10Как правило рассматривают так называемые систематические или канонические формы матриц G и
Как правило рассматривают так называемые систематические или канонические формы матриц G и

Слайд 11Соответственно, исходя из свойства (37), следует, что проверочная матрица H состоит из
Соответственно, исходя из свойства (37), следует, что проверочная матрица H состоит из

Слайд 12
Для примера также рассмотрим процедуру кодирования с использованием порождающей матрицы G (40).
Для примера также рассмотрим процедуру кодирования с использованием порождающей матрицы G (40).

Слайд 13Декодирование линейных блочных кодов
Декодирование линейных блочных кодов

Слайд 14Как и в случае кодирования, декодирование линейных блочных кодов можно осуществлять посредством
Как и в случае кодирования, декодирование линейных блочных кодов можно осуществлять посредством

Слайд 15В связи с этим используют механизм синдромного декодирования, основанный на использовании проверочной
В связи с этим используют механизм синдромного декодирования, основанный на использовании проверочной

Слайд 16Соответственно, если хотя бы один из компонент вектора s = {s0; s1;
Соответственно, если хотя бы один из компонент вектора s = {s0; s1;

Слайд 17Если сравнить табл. 5.1 и проверочную матрицу (41), то можно увидеть, что
Если сравнить табл. 5.1 и проверочную матрицу (41), то можно увидеть, что

Слайд 18Если наложить на вектор v ошибку в позиции v4 будет получен вектор
Если наложить на вектор v ошибку в позиции v4 будет получен вектор

Слайд 19Расширенные коды Хэмминга.
Расширенные коды Хэмминга.

Слайд 20Расширение кода Хэмминга заключается в дополнении кодового слова дополнительным двоичным разрядом так,
Расширение кода Хэмминга заключается в дополнении кодового слова дополнительным двоичным разрядом так,

Слайд 21Для примера рассмотрим расширение кода Хэмминга (7,4) - расширенный код Хэмминга (8,4).
Для примера рассмотрим расширение кода Хэмминга (7,4) - расширенный код Хэмминга (8,4).

Слайд 22Проверочная матрица кода (8,4) получается из проверочной матрицы кода (7,4) в два
Проверочная матрица кода (8,4) получается из проверочной матрицы кода (7,4) в два

Слайд 23Рассмотрим процесс коррекции и обнаружения ошибок.
Процедура исправления одиночных ошибок совпадает с таковой
Рассмотрим процесс коррекции и обнаружения ошибок.
Процедура исправления одиночных ошибок совпадает с таковой

 Как просмотреть видеоинструкцию о Подключении ВТБ Бизнес онлайн
Как просмотреть видеоинструкцию о Подключении ВТБ Бизнес онлайн Язык Javascript
Язык Javascript Нотация EPC
Нотация EPC Изучение социально-политического значения проекта НЭБ для развития в России информационного общества и информационной экономики
Изучение социально-политического значения проекта НЭБ для развития в России информационного общества и информационной экономики Smart. Оформление POS-кредитов просто, быстро и без бумаг
Smart. Оформление POS-кредитов просто, быстро и без бумаг Преобразования формы предмета. (2 занятие)
Преобразования формы предмета. (2 занятие) v3
v3 Схема работы системы штрихкодирования готовой продукции на ОАО КЗСК
Схема работы системы штрихкодирования готовой продукции на ОАО КЗСК Иллюстрация и демонстрация. Их различие на экране ЭВМ
Иллюстрация и демонстрация. Их различие на экране ЭВМ Системы счисления
Системы счисления Flask. Пример Hello
Flask. Пример Hello Вывод и ввод данных
Вывод и ввод данных Бизнес план интернет магазина Leki-shop
Бизнес план интернет магазина Leki-shop Сетевой этикет
Сетевой этикет Основы программирования на языке Python
Основы программирования на языке Python Числа в компьютере
Числа в компьютере Арифметические операции в позиционных системах счисления представление информации в компьютере
Арифметические операции в позиционных системах счисления представление информации в компьютере Классификация программного обеспечения (ПО)
Классификация программного обеспечения (ПО) Программирование линейных алгоритмов
Программирование линейных алгоритмов Универсальная система обмена данными и юридически значимыми электронными документами 2022
Универсальная система обмена данными и юридически значимыми электронными документами 2022 Одномерные массивы. Часть 2
Одномерные массивы. Часть 2 Криптография для школьников
Криптография для школьников Линейный алгоритм
Линейный алгоритм Шаблон презентаций
Шаблон презентаций Словесные информационные модели
Словесные информационные модели tekstovye-dokumenty-i-tehnologii-ih-sozdaniya
tekstovye-dokumenty-i-tehnologii-ih-sozdaniya Мобильное программирование. Лекция №4
Мобильное программирование. Лекция №4 Введение в ANSYS
Введение в ANSYS