- MongoDB (продолжение)

Содержание
- 2. Отсутствие JOIN-ов Мы должны делать JOIN-ы вручную, в коде своего приложения. По существу, мы должны делать
- 3. Денормализация Еще одна альтернатива использованию JOIN-ов - денормализация. Исторически денормализация использовалась для оптимизации производительности, или когда
- 4. Мало или много коллекций Учитывая то, что коллекции не привязывают нас к конкретной схеме, вполне возможно
- 5. MapReduce MapReduce - это подход к обработке данных, который имеет два серьёзных преимущества по сравнению с
- 6. Теория и практика MapReduce - процесс двухступенчатый. Сначала делается map (отображение), затем - reduce (свёртка). На
- 7. (Прелесть данного подхода заключается в хранении результатов; отчёты генерируются быстро и рост данных контролируется - для
- 8. Теперь сосредоточимся на понимании концепции. Первым делом рассмотрим функцию отображения. Задача функции отображения - породить значения,
- 9. this ссылается на текущий рассматриваемый документ. Надеюсь, результирующие данные прояснят для вас картину происходящего. При использовании
- 10. Давайте изменим нашу map-функцию несколько надуманным способом: Первый промежуточный результат теперь изменится на: Обратите внимание, как
- 11. Reduce-функция Reduce-функция берёт каждое из этих промежуточных значений и выдаёт конечный результат. Вот так будет выглядеть
- 12. Технически в MongoDB результат выглядит так: Это и есть наш конечный результат. Почему мы просто не
- 13. Чистая практика Сперва давайте создадим набор данных:
- 14. Теперь можно создать map и reduce функции (консоль MongoDB позволяет вводить многострочные конструкции):
- 15. Мы выполним команду mapReduce над коллекцией hits следующим образом: Надпись {out: 'hit_stats'} означает, что результат сохраняется
- 16. Индексы В самом начале мы видели коллекцию system.indexes, которая содержит информацию о всех индексах в нашей
- 17. Шардинг MongoDB поддерживает авто-шардинг. Шардинг - это подход к масштабируемости, когда отдельные части данных хранятся на
- 18. Репликация Репликация в MongoDB работает сходным образом с репликацией в реляционных базах данных. Записи посылаются на
- 20. Скачать презентацию

Слайд 3Денормализация
Еще одна альтернатива использованию JOIN-ов - денормализация. Исторически денормализация использовалась для
Денормализация
Еще одна альтернатива использованию JOIN-ов - денормализация. Исторически денормализация использовалась для

Слайд 4Мало или много коллекций
Учитывая то, что коллекции не привязывают нас к конкретной
Мало или много коллекций
Учитывая то, что коллекции не привязывают нас к конкретной

Слайд 5MapReduce
MapReduce - это подход к обработке данных, который имеет два серьёзных преимущества
MapReduce
MapReduce - это подход к обработке данных, который имеет два серьёзных преимущества

Слайд 6Теория и практика
MapReduce - процесс двухступенчатый. Сначала делается map (отображение), затем - reduce (свёртка). На этапе
Теория и практика
MapReduce - процесс двухступенчатый. Сначала делается map (отображение), затем - reduce (свёртка). На этапе

Слайд 7(Прелесть данного подхода заключается в хранении результатов; отчёты генерируются быстро и рост
(Прелесть данного подхода заключается в хранении результатов; отчёты генерируются быстро и рост
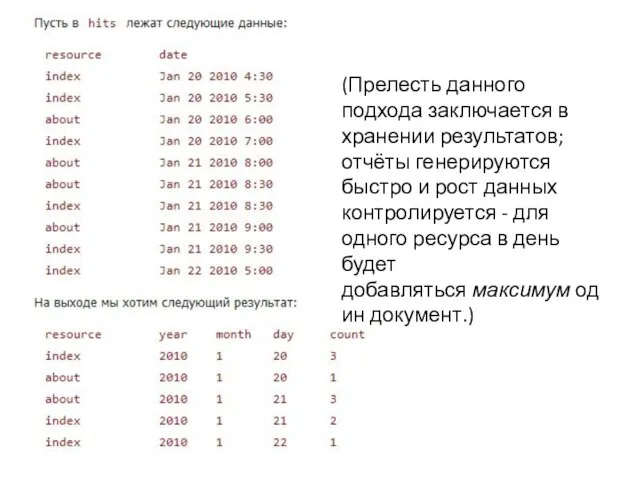
Слайд 8Теперь сосредоточимся на понимании концепции.
Первым делом рассмотрим функцию отображения. Задача функции
Теперь сосредоточимся на понимании концепции.
Первым делом рассмотрим функцию отображения. Задача функции

Слайд 9this ссылается на текущий рассматриваемый документ. Надеюсь, результирующие данные прояснят для вас картину
this ссылается на текущий рассматриваемый документ. Надеюсь, результирующие данные прояснят для вас картину

Слайд 10Давайте изменим нашу map-функцию несколько надуманным способом:
Первый промежуточный результат теперь изменится на:
Обратите внимание,
Давайте изменим нашу map-функцию несколько надуманным способом:
Первый промежуточный результат теперь изменится на:
Обратите внимание,

Слайд 11Reduce-функция
Reduce-функция берёт каждое из этих промежуточных значений и выдаёт конечный результат. Вот так
Reduce-функция
Reduce-функция берёт каждое из этих промежуточных значений и выдаёт конечный результат. Вот так

Слайд 12Технически в MongoDB результат выглядит так:
Это и есть наш конечный результат.
Почему мы
Технически в MongoDB результат выглядит так:
Это и есть наш конечный результат.
Почему мы

Слайд 13Чистая практика
Сперва давайте создадим набор данных:
Чистая практика
Сперва давайте создадим набор данных:

Слайд 14Теперь можно создать map и reduce функции (консоль MongoDB позволяет вводить многострочные конструкции):
Теперь можно создать map и reduce функции (консоль MongoDB позволяет вводить многострочные конструкции):

Слайд 15Мы выполним команду mapReduce над коллекцией hits следующим образом:
Надпись {out: 'hit_stats'} означает, что результат сохраняется в
Мы выполним команду mapReduce над коллекцией hits следующим образом:
Надпись {out: 'hit_stats'} означает, что результат сохраняется в

Слайд 16Индексы
В самом начале мы видели коллекцию system.indexes, которая содержит информацию о всех индексах
Индексы
В самом начале мы видели коллекцию system.indexes, которая содержит информацию о всех индексах

Слайд 17Шардинг
MongoDB поддерживает авто-шардинг. Шардинг - это подход к масштабируемости, когда отдельные части
Шардинг
MongoDB поддерживает авто-шардинг. Шардинг - это подход к масштабируемости, когда отдельные части

Слайд 18Репликация
Репликация в MongoDB работает сходным образом с репликацией в реляционных базах данных.
Репликация
Репликация в MongoDB работает сходным образом с репликацией в реляционных базах данных.

 Автоматизация процесса управления документооборотом путём внедрения 1С Документооборот в ООО ВЭГТРАНС
Автоматизация процесса управления документооборотом путём внедрения 1С Документооборот в ООО ВЭГТРАНС Анализ и оптимизация автоматизированной системы документооборота предприятия
Анализ и оптимизация автоматизированной системы документооборота предприятия Программирование – процес создания прорамм
Программирование – процес создания прорамм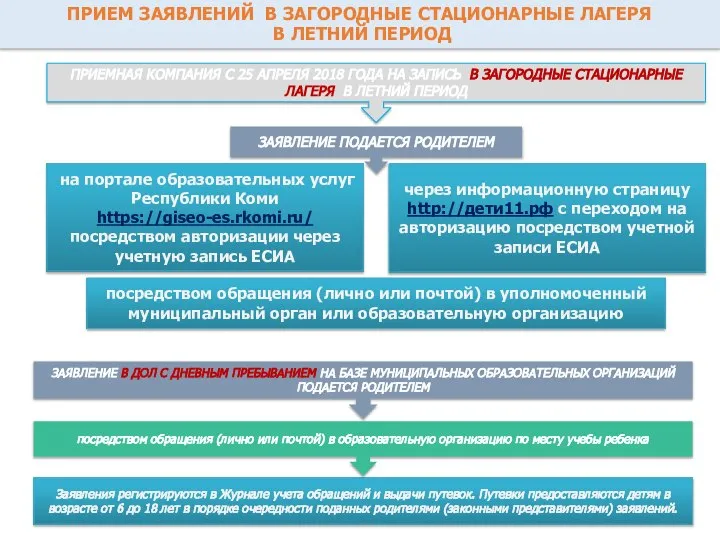 Прием заявлений в загородные стационарные лагеря в летний период
Прием заявлений в загородные стационарные лагеря в летний период Biarum slides IFMO
Biarum slides IFMO Задача
Задача Методология ведения научно-исследовательской работы
Методология ведения научно-исследовательской работы Управление памятью в операционных системах
Управление памятью в операционных системах Моделирование динамического режима движения жидкости в простой гидравлической системе
Моделирование динамического режима движения жидкости в простой гидравлической системе Ссылки. Практикум
Ссылки. Практикум Циклические конструкции Цикл с предусловием Цикл с постусловием Цикл с параметром Вложенные циклы
Циклические конструкции Цикл с предусловием Цикл с постусловием Цикл с параметром Вложенные циклы Линейные алгоритмы и их реализация на языке программирования Pascal
Линейные алгоритмы и их реализация на языке программирования Pascal Справка о ходе выполнения мероприятий Дорожной карты цифровизации
Справка о ходе выполнения мероприятий Дорожной карты цифровизации Моделирование окружающего мира
Моделирование окружающего мира Блочная структура элементов. Свойство display. Размеры. Урок №5
Блочная структура элементов. Свойство display. Размеры. Урок №5 Перестановка строк и столбцов в матрице
Перестановка строк и столбцов в матрице Компьютерная графика
Компьютерная графика Информатика и информация. Кодирование и измерение информации
Информатика и информация. Кодирование и измерение информации Работа с файлами и папками в операционной системе Windows
Работа с файлами и папками в операционной системе Windows Технологии Ethernet, Fast Ethernet,Token Ring и Gigabit Ethernet
Технологии Ethernet, Fast Ethernet,Token Ring и Gigabit Ethernet Технологическая архитектура предприятия
Технологическая архитектура предприятия Что такое программное обеспечение (ПО) компьютера?
Что такое программное обеспечение (ПО) компьютера? Интернет-журнал PDC-Paradis des chains
Интернет-журнал PDC-Paradis des chains Ретаргетинг в Яндекс.Директ
Ретаргетинг в Яндекс.Директ Создание информации с помощью интернет-сервисов
Создание информации с помощью интернет-сервисов Величины. Характеристики величин
Величины. Характеристики величин Системно-деятельностный подход на уроках информатики
Системно-деятельностный подход на уроках информатики Компьютерная графика
Компьютерная графика