- Прототип автоматизированной системы поиска дубликатов документов для цифровых научных библиотек

Содержание
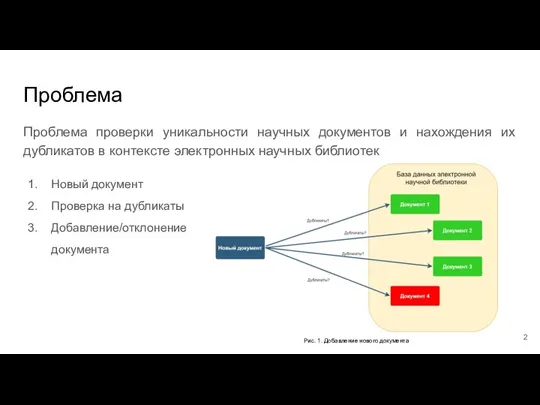
- 2. Проблема Проблема проверки уникальности научных документов и нахождения их дубликатов в контексте электронных научных библиотек Новый
- 3. Цель и задачи Цель: разработка сервиса поиска дубликатов в электронных научных библиотеках. Задачи: Исследовать способы организации
- 4. Существующие решения Алгоритм “шинглов”: Физическое представление данных Точность ~91% Неустойчив к мелким изменениям Неустойчив к перестановкам
- 5. Предлагаемое решение Алгоритм TF–RIDF: Точность ~95% Учитывает статистику всей коллекции Устойчив к мелким изменениям Устойчив к
- 6. Серверная часть: Язык программирования – Java Сервер – Spring Boot Многопоточность – Concurrent, Guava Агрегация данных
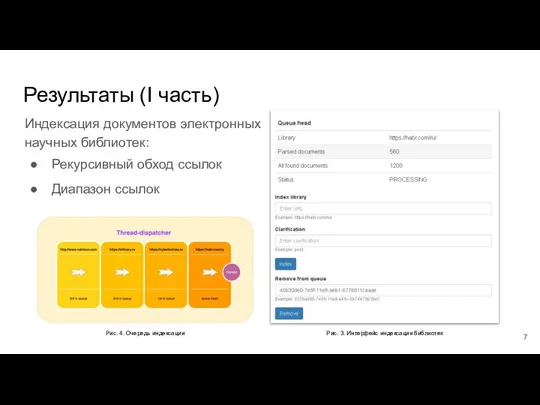
- 7. Результаты (I часть) Индексация документов электронных научных библиотек: Рекурсивный обход ссылок Диапазон ссылок Рис. 4. Очередь
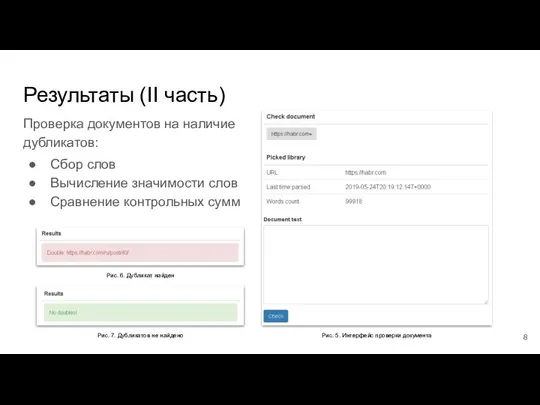
- 8. Результаты (II часть) Проверка документов на наличие дубликатов: Сбор слов Вычисление значимости слов Сравнение контрольных сумм
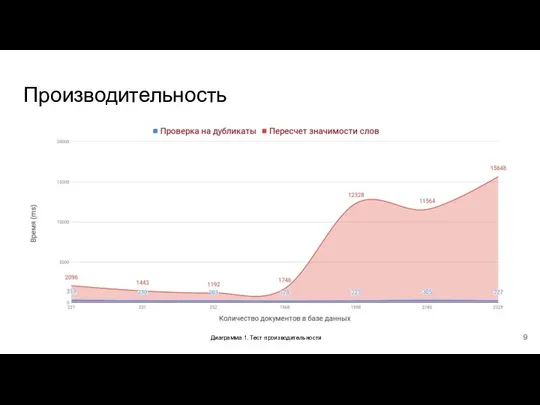
- 9. Производительность Диаграмма 1. Тест производительности
- 10. Выводы Свойства системы: Алгоритм TF–RIDF Индексация электронных научных библиотек Быстрая проверка на дубликаты ~200ms
- 12. Скачать презентацию
Слайд 2Проблема
Проблема проверки уникальности научных документов и нахождения их дубликатов в контексте электронных
Проблема
Проблема проверки уникальности научных документов и нахождения их дубликатов в контексте электронных
Слайд 3Цель и задачи
Цель: разработка сервиса поиска дубликатов в электронных научных библиотеках.
Задачи:
Исследовать
Цель и задачи
Цель: разработка сервиса поиска дубликатов в электронных научных библиотеках.
Задачи:
Исследовать

Слайд 4Существующие решения
Алгоритм “шинглов”:
Физическое представление данных
Точность ~91%
Неустойчив к мелким изменениям
Неустойчив к перестановкам слов
Отсутствие
Существующие решения
Алгоритм “шинглов”:
Физическое представление данных
Точность ~91%
Неустойчив к мелким изменениям
Неустойчив к перестановкам слов
Отсутствие

Слайд 5Предлагаемое решение
Алгоритм TF–RIDF:
Точность ~95%
Учитывает статистику всей коллекции
Устойчив к мелким изменениям
Устойчив к перестановкам
Предлагаемое решение
Алгоритм TF–RIDF:
Точность ~95%
Учитывает статистику всей коллекции
Устойчив к мелким изменениям
Устойчив к перестановкам

Слайд 6Серверная часть:
Язык программирования – Java
Сервер – Spring Boot
Многопоточность – Concurrent, Guava
Агрегация данных
Серверная часть:
Язык программирования – Java
Сервер – Spring Boot
Многопоточность – Concurrent, Guava
Агрегация данных

Слайд 7Результаты (I часть)
Индексация документов электронных научных библиотек:
Рекурсивный обход ссылок
Диапазон ссылок
Рис. 4. Очередь
Результаты (I часть)
Индексация документов электронных научных библиотек:
Рекурсивный обход ссылок
Диапазон ссылок
Рис. 4. Очередь
Слайд 8Результаты (II часть)
Проверка документов на наличие дубликатов:
Сбор слов
Вычисление значимости слов
Сравнение контрольных сумм
Рис.
Результаты (II часть)
Проверка документов на наличие дубликатов:
Сбор слов
Вычисление значимости слов
Сравнение контрольных сумм
Рис.
Слайд 9Производительность
Диаграмма 1. Тест производительности
Производительность
Диаграмма 1. Тест производительности
Слайд 10Выводы
Свойства системы:
Алгоритм TF–RIDF
Индексация электронных научных библиотек
Быстрая проверка на дубликаты ~200ms
Выводы
Свойства системы:
Алгоритм TF–RIDF
Индексация электронных научных библиотек
Быстрая проверка на дубликаты ~200ms

 Что такое SwapXI
Что такое SwapXI Инструменты для групповой работы
Инструменты для групповой работы Уютная библиотека. Защита проекта
Уютная библиотека. Защита проекта Основные понятия ООП
Основные понятия ООП Электронная информационно-образовательная среда РУТ(МИИИТ)
Электронная информационно-образовательная среда РУТ(МИИИТ) Научите Ваш table tent продвижению через социальные сети и сбору данных
Научите Ваш table tent продвижению через социальные сети и сбору данных Разработка модуля тестирования для программного продукта для МБУ ДО АР Детская Музыкальная Школа Станицы Ольгинской
Разработка модуля тестирования для программного продукта для МБУ ДО АР Детская Музыкальная Школа Станицы Ольгинской Системная среда
Системная среда Почта Росии
Почта Росии Анимированные иконки - сердечки
Анимированные иконки - сердечки Рунет: безопасная загрузка
Рунет: безопасная загрузка Программирование линейных вычислительных процессов
Программирование линейных вычислительных процессов Разработка класса двусвязного списка с разной реализацией
Разработка класса двусвязного списка с разной реализацией Баги и баг-трекеры
Баги и баг-трекеры Информационные системы и технологии
Информационные системы и технологии Микроядро Mach. ОС на его основе
Микроядро Mach. ОС на его основе Классификация компьютерных сетей
Классификация компьютерных сетей Презентация на тему Основные понятия компьютерной графики
Презентация на тему Основные понятия компьютерной графики  2_Topologija_KS
2_Topologija_KS Реализация игры
Реализация игры Штрих-коды, бумажные носители информации, Qr-коды
Штрих-коды, бумажные носители информации, Qr-коды Отправить сообщения на электронный адрес на темы Электронная почта
Отправить сообщения на электронный адрес на темы Электронная почта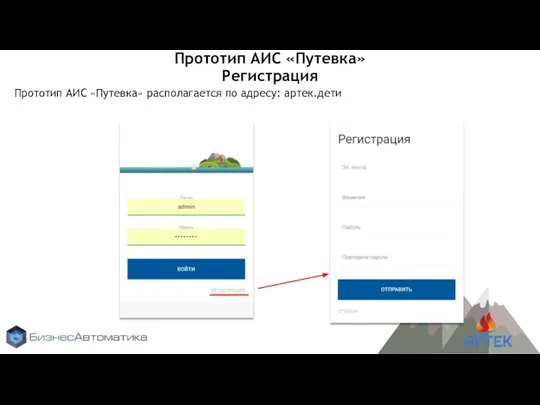 Регистрация в АИС Путевка
Регистрация в АИС Путевка Кодирование графической информации
Кодирование графической информации Элементы языка SQL
Элементы языка SQL Знаковые модели. Моделирование и формализация
Знаковые модели. Моделирование и формализация Работа с Интернет магазином, Интернет - СМИ, Интернет - библиотекой
Работа с Интернет магазином, Интернет - СМИ, Интернет - библиотекой Инструменты графического редактора Paint. 5 класс
Инструменты графического редактора Paint. 5 класс