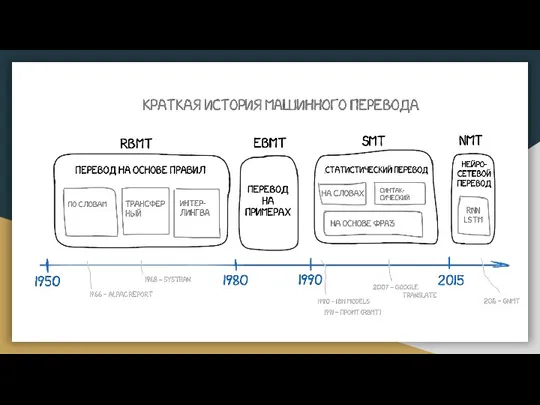
- Развитие машинного перевода

Содержание
- 2. Машина Троянского В 1933 году Советский ученый Пётр Троянский обращается в Академию Наук СССР с изобретённой
- 4. Машинный перевод на основе правил — Rule-based Machine Translation (RBMT)
- 5. Среди плюсов RBMT отмечают морфологическую точность (не путает слова), воспроизводимость (все переводчики получат одинаковый результат) и
- 6. Машинный перевод на примерах — Example-based Machine Translation (EBMT) Основной приницп: А что если не пытаться
- 7. Статистический машинный перевод — Statistical Machine Translation (SMT)
- 9. Статистический перевод по словам — Word-based SMT Model 1: мешок слов Классический подход — делим всё
- 10. Model 2: учёт порядка слов в предложении Отсутствие знаний о порядке слов в языках стало проблемой
- 11. Model 3: добавление отсутствующих слов Часто при переводе появляются новые слова, которых не было в оригинальном
- 12. Статистический перевод по фразам — Phrase-based SMT Для обучения он разбивал текст не только на слова,
- 13. Нейронный машинный перевод — Neural Machine Translation (NMT) Помните приложение Prisma, которое обрабатывало фото в стиле
- 14. Первая нейросеть умеет только кодировать предложение в набор цифр-характеристик, а вторая только декодировать их обратно в
- 15. RNN сейчас применяют в: распознавание речи в Siri , подсказки слов на клавиатуре , генерация музыки
- 16. Google Translate (2016) В 2016 году Google включил нейронный перевод девяти языков между собой, в 2017
- 17. Яндекс Переводчик (2017) Яндекс запустил свой нейросетевой перевод в 2017 году. Главным отличием они заявили гибридность.
- 19. Скачать презентацию

Слайд 4Машинный перевод на основе правил — Rule-based Machine Translation (RBMT)
Машинный перевод на основе правил — Rule-based Machine Translation (RBMT)

Слайд 5Среди плюсов RBMT отмечают морфологическую точность (не путает слова), воспроизводимость (все переводчики
Среди плюсов RBMT отмечают морфологическую точность (не путает слова), воспроизводимость (все переводчики

Слайд 6Машинный перевод на примерах — Example-based Machine Translation (EBMT)
Основной приницп: А что
Машинный перевод на примерах — Example-based Machine Translation (EBMT)
Основной приницп: А что

Слайд 7Статистический машинный перевод — Statistical Machine Translation (SMT)
Статистический машинный перевод — Statistical Machine Translation (SMT)

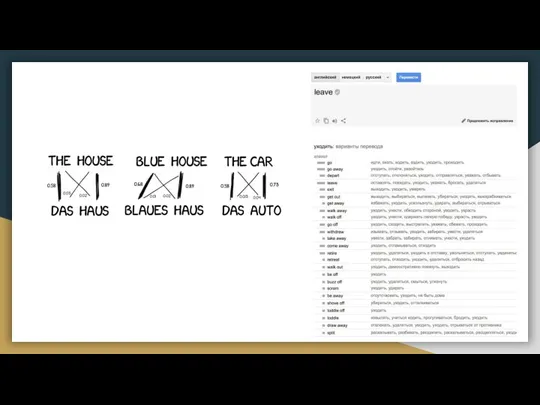
Слайд 9Статистический перевод по словам — Word-based SMT
Model 1: мешок слов
Классический подход —
Статистический перевод по словам — Word-based SMT
Model 1: мешок слов
Классический подход —

Слайд 10Model 2: учёт порядка слов в предложении
Отсутствие знаний о порядке слов в
Model 2: учёт порядка слов в предложении
Отсутствие знаний о порядке слов в

Слайд 11Model 3: добавление отсутствующих слов
Часто при переводе появляются новые слова, которых не
Model 3: добавление отсутствующих слов
Часто при переводе появляются новые слова, которых не

Слайд 12Статистический перевод по фразам — Phrase-based SMT
Для обучения он разбивал текст не
Статистический перевод по фразам — Phrase-based SMT
Для обучения он разбивал текст не

Слайд 13Нейронный машинный перевод — Neural Machine Translation (NMT)
Помните приложение Prisma, которое обрабатывало
Нейронный машинный перевод — Neural Machine Translation (NMT)
Помните приложение Prisma, которое обрабатывало

Слайд 14Первая нейросеть умеет только кодировать предложение в набор цифр-характеристик, а вторая только
Первая нейросеть умеет только кодировать предложение в набор цифр-характеристик, а вторая только

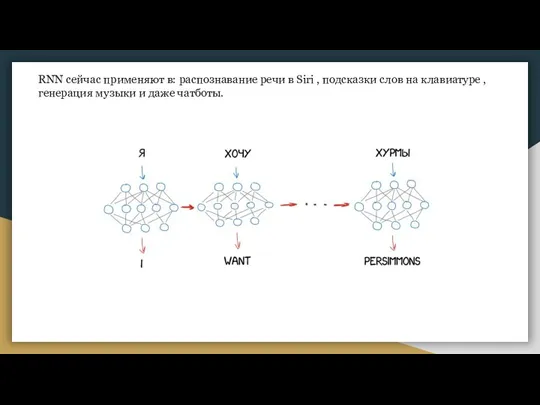
Слайд 15RNN сейчас применяют в: распознавание речи в Siri , подсказки слов на
RNN сейчас применяют в: распознавание речи в Siri , подсказки слов на
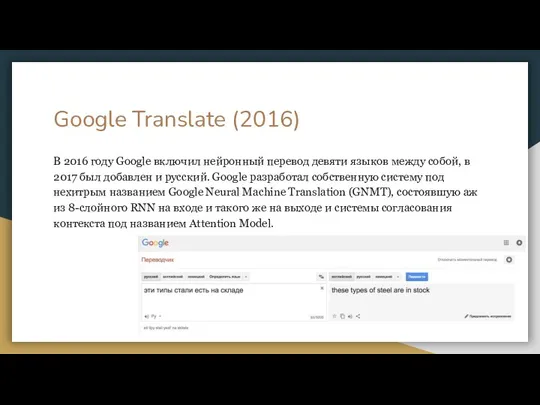
Слайд 16Google Translate (2016)
В 2016 году Google включил нейронный перевод девяти языков между
Google Translate (2016)
В 2016 году Google включил нейронный перевод девяти языков между
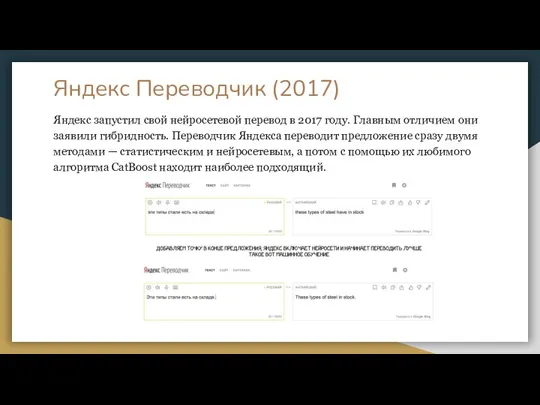
Слайд 17Яндекс Переводчик (2017)
Яндекс запустил свой нейросетевой перевод в 2017 году. Главным отличием
Яндекс Переводчик (2017)
Яндекс запустил свой нейросетевой перевод в 2017 году. Главным отличием
 Системы шифрования
Системы шифрования Брендбук. Руководство по использованию фирменного стиля
Брендбук. Руководство по использованию фирменного стиля Объект. Задания к уроку
Объект. Задания к уроку Модификация данных
Модификация данных Задача 3.30. Решение
Задача 3.30. Решение JavaScript История развития
JavaScript История развития ТЗ сайту Зрозуміло
ТЗ сайту Зрозуміло Компьютерные сети
Компьютерные сети Шестой межрегиональный форум Вера и дело. Противодействие фальшивым новостям и формирование верифицированного контента
Шестой межрегиональный форум Вера и дело. Противодействие фальшивым новостям и формирование верифицированного контента PAM
PAM Онлайн-обучение портал Elducation.Ru, дистанционный курс Гибкие компетенции в проектной деятельности
Онлайн-обучение портал Elducation.Ru, дистанционный курс Гибкие компетенции в проектной деятельности Презентация на тему Мультимедийные технологии
Презентация на тему Мультимедийные технологии  Файлы и папки. Урок 3
Файлы и папки. Урок 3 Сайт решу ОГЭ. Тема 4, 5. Все задания
Сайт решу ОГЭ. Тема 4, 5. Все задания Авторизация и Аутентификация
Авторизация и Аутентификация Общие сведения о мультимедийных технологиях
Общие сведения о мультимедийных технологиях Медиапланирование в интернете
Медиапланирование в интернете Концепция ERP-системы 1С:Управление предприятием
Концепция ERP-системы 1С:Управление предприятием Представление об организации, использование БД и СУБД
Представление об организации, использование БД и СУБД Программа Воркшопа. Как подготовить публичное выступление
Программа Воркшопа. Как подготовить публичное выступление DH Standard AVN Update
DH Standard AVN Update Школа::Кода Основы программирования на языке Python. 27 занятие
Школа::Кода Основы программирования на языке Python. 27 занятие Расстояние между пачкой и клеймом
Расстояние между пачкой и клеймом Data Science
Data Science Електронна оплата за транспортні послуги у громадському транспорті
Електронна оплата за транспортні послуги у громадському транспорті Презентация
Презентация Обучение команды Beeline по продукту LMS SmartExpert
Обучение команды Beeline по продукту LMS SmartExpert Планирование разработки программного обеспечения (лекция 3)
Планирование разработки программного обеспечения (лекция 3)