- Словарные методы кодирования

Содержание
- 2. Словарные методы Статистические методы компрессии используют статистическую модель данных, и качество сжатия информации напрямую зависит от
- 3. Алгоритм RLE. Первый вариант алгоритма Данный алгоритм необычайно прост в реализации. Групповое кодирование — от английского
- 4. Первый вариант алгоритма RLE В данном алгоритме признаком счетчика служат единицы в двух верхних битах считанного
- 5. Первый вариант RLE Алгоритм рассчитан на деловую графику — изображения с большими областями повторяющегося цвета. Ситуация,
- 6. RLE Второй вариант алгоритма Второй вариант этого алгоритма имеет больший максимальный коэффициент архивации и меньше увеличивает
- 7. RLE 2 Как можно легко подсчитать, в лучшем случае этот алгоритм сжимает файл в 64 раза
- 8. LZW Название алгоритм получил по первым буквам фамилий его разработчиков — Lempel, Ziv и Welch. Сжатие
- 9. Алгоритм LZW Процесс сжатия выглядит достаточно просто. Мы считываем последовательно символы входного потока и проверяем, есть
- 10. LZW реализован в форматах GIF и TIFF. LZW - это способ сжатия данных, который извлекает преимущества
- 11. LZW-сжатие 1. Инициализация цепочки символов. Выбираем размер кода (количество бит) и определяем сколько возможных значений могут
- 12. 2. Процесс сжатия Мы считываем последовательно символы входного потока и проверяем, есть ли в созданной нами
- 13. Пример Пусть мы сжимаем последовательность 45, 55, 55, 151, 55, 55, 55. Тогда, поместим в выходной
- 14. Пример: процесс сжатия Далее мы читаем следующий символ 55 из входного потока и проверяем, есть ли
- 15. Формирование таблицы Можно коротко представить архивацию так: “45” — есть в таблице; “45, 55” — нет.
- 16. 3. Декомпрессия Особенность LZW заключается в том, что для декомпрессии нам не надо сохранять таблицу строк
- 17. 3. Декомпрессия Мы знаем, что для каждого кода надо добавлять в таблицу строку, состоящую из уже
- 18. Ziv-Lempel Coding (ZL or LZ) Авторы: J. Ziv и A. Lempel (1977). Техника адаптивного словаря. Накопление
- 19. Основная идея LZ77 состоит в том, что второе и последующие вхождения некоторой строки символов в сообщении
- 20. LZ77 LZ77 использует "скользящее" по сообщению окно, разделенное на две неравные части. Первая, большая по размеру,
- 21. LZ 77 Поисковый буфер Буфер просмотра вперед Тройка выхода 1 2 3 4 5 6 7
- 22. LZ 77 clc; clear all; close all; str='cabracadabrarrarrad'; strl=length(str); code={'a','000';'b','001';'c','010';'d','011';'r','100'} sbl=7; labl=6; i=1; pos=[]; while i+sbl
- 23. Эффективность
- 24. LZ 78 LZ 78 не использует "скользящее" окно, он хранит словарь из уже просмотренных фраз. При
- 25. LZ 78 Затем в словарь добавляется введенная подстрока. Если словарь уже заполнен, то из него предварительно
- 26. LZ 78 Код выхода двойка Словарь: 0 a Передача в канал: 0 b 0 c 1
- 27. Ziv-Lempel-Welch (LZW)-Codes Идея: вместо последовательностей букв передаются номера слов в некотором словаре. Кодер и декодер в
- 28. Ziv-Lempel-Welch (LZW)-Codes
- 29. Ziv-Lempel-Welch (LZW)-Codes
- 30. LZW Выход: dictionary index (индекс словаря) Словарь кодера: 1 Передача: 2 3 5 5 Декодирование: a
- 31. Алгоритм LZW
- 32. LZW im = rgb2gray(imread('lenna.png')); [h w] = size(im); Q = 16; X = im(:); len =
- 33. LZW X = X0(:); D = [X1(:); X2(:); X3(:)]; lenhX = len_huffman(X); lenhD = len_huffman(D); lenh
- 34. figure(1); clf; sc(out);
- 36. Скачать презентацию
Слайд 2Словарные методы
Статистические методы компрессии используют статистическую модель данных, и качество сжатия информации
Словарные методы
Статистические методы компрессии используют статистическую модель данных, и качество сжатия информации

Слайд 3Алгоритм RLE.
Первый вариант алгоритма
Данный алгоритм необычайно прост в реализации. Групповое кодирование
Алгоритм RLE.
Первый вариант алгоритма
Данный алгоритм необычайно прост в реализации. Групповое кодирование

Слайд 4Первый вариант алгоритма
RLE
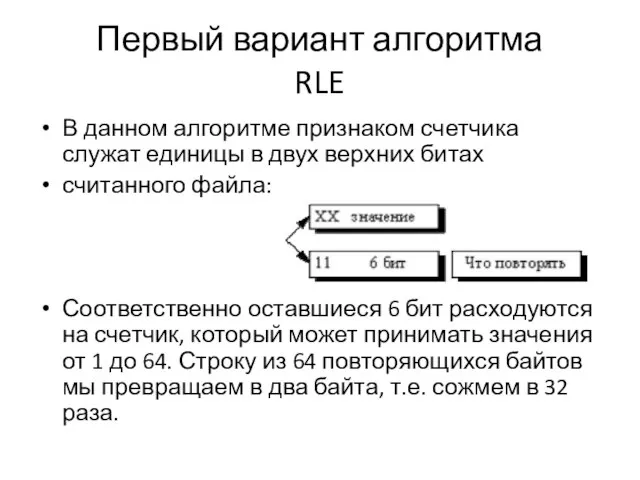
В данном алгоритме признаком счетчика служат единицы в двух верхних
Первый вариант алгоритма
RLE
В данном алгоритме признаком счетчика служат единицы в двух верхних
Слайд 5Первый вариант RLE
Алгоритм рассчитан на деловую графику — изображения с большими областями
Первый вариант RLE
Алгоритм рассчитан на деловую графику — изображения с большими областями

Слайд 6RLE
Второй вариант алгоритма
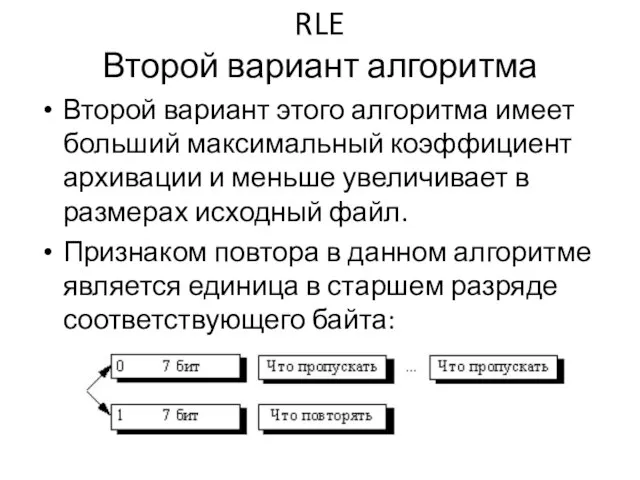
Второй вариант этого алгоритма имеет больший максимальный коэффициент архивации и
RLE
Второй вариант алгоритма
Второй вариант этого алгоритма имеет больший максимальный коэффициент архивации и
Слайд 7RLE 2
Как можно легко подсчитать, в лучшем случае этот алгоритм сжимает файл
RLE 2
Как можно легко подсчитать, в лучшем случае этот алгоритм сжимает файл

Слайд 8LZW
Название алгоритм получил по первым буквам фамилий его разработчиков —
Lempel, Ziv и
LZW
Название алгоритм получил по первым буквам фамилий его разработчиков —
Lempel, Ziv и

Слайд 9Алгоритм LZW
Процесс сжатия выглядит достаточно просто. Мы считываем последовательно символы входного потока
Алгоритм LZW
Процесс сжатия выглядит достаточно просто. Мы считываем последовательно символы входного потока

Слайд 10LZW реализован в форматах GIF и TIFF.
LZW - это способ сжатия данных,
LZW реализован в форматах GIF и TIFF.
LZW - это способ сжатия данных,

Слайд 11LZW-сжатие
1. Инициализация цепочки символов.
Выбираем размер кода (количество бит) и определяем
LZW-сжатие
1. Инициализация цепочки символов.
Выбираем размер кода (количество бит) и определяем

Слайд 122. Процесс сжатия
Мы считываем последовательно символы входного потока и проверяем, есть
2. Процесс сжатия
Мы считываем последовательно символы входного потока и проверяем, есть

Слайд 13Пример
Пусть мы сжимаем последовательность
45, 55, 55, 151, 55, 55, 55.
Тогда,
Пример
Пусть мы сжимаем последовательность
45, 55, 55, 151, 55, 55, 55.
Тогда,

Слайд 14Пример: процесс сжатия
Далее мы читаем следующий символ 55 из входного потока
Пример: процесс сжатия
Далее мы читаем следующий символ 55 из входного потока

Слайд 15Формирование таблицы
Можно коротко представить архивацию так:
“45” — есть в таблице;
“45,
Формирование таблицы
Можно коротко представить архивацию так:
“45” — есть в таблице;
“45,

Слайд 163. Декомпрессия
Особенность LZW заключается в том, что для декомпрессии нам не надо
3. Декомпрессия
Особенность LZW заключается в том, что для декомпрессии нам не надо

Слайд 173. Декомпрессия
Мы знаем, что для каждого кода надо добавлять в таблицу строку,
3. Декомпрессия
Мы знаем, что для каждого кода надо добавлять в таблицу строку,

Слайд 18Ziv-Lempel Coding (ZL or LZ)
Авторы: J. Ziv и A. Lempel (1977).
Техника адаптивного
Ziv-Lempel Coding (ZL or LZ)
Авторы: J. Ziv и A. Lempel (1977).
Техника адаптивного

Слайд 19Основная идея LZ77 состоит в том, что второе и последующие вхождения некоторой
Основная идея LZ77 состоит в том, что второе и последующие вхождения некоторой

Слайд 20LZ77
LZ77 использует "скользящее" по сообщению окно, разделенное на две неравные части. Первая,
LZ77
LZ77 использует "скользящее" по сообщению окно, разделенное на две неравные части. Первая,

Слайд 21LZ 77
Поисковый буфер
Буфер просмотра вперед
Тройка выхода
1
2
3
4
5
6
7
8
8
0
1
3
d
0
e
2
f
Передает в канала:
PKZip, Zip,
LZ 77
Поисковый буфер
Буфер просмотра вперед
Тройка выхода 1 2 3 4 5 6 7 8 8 0 1 3 d 0 e 2 f Передает в канала: PKZip, Zip,

Слайд 22LZ 77
clc;
clear all;
close all;
str='cabracadabrarrarrad';
strl=length(str);
code={'a','000';'b','001';'c','010';'d','011';'r','100'}
sbl=7;
labl=6;
i=1;
pos=[];
while i+sblsb=str(i:i+sbl-1);
if i+sbl+labl-1lab=str(i+sbl:i+sbl+labl-1);
else
lab=str(i+sbl:end);
end
sp=lab(1);
pos=[];
for j=1:sbl
if sp~=sb(j)
offset=0;
ml=0;
%send code
else
pos=[pos j];
end
end
Ml=[];
for k=1:length(pos)
count=0;
m=1;
flag=0;
for l=pos(k):sbl+labl
while
LZ 77
clc;
clear all;
close all;
str='cabracadabrarrarrad';
strl=length(str);
code={'a','000';'b','001';'c','010';'d','011';'r','100'}
sbl=7;
labl=6;
i=1;
pos=[];
while i+sbl
if i+sbl+labl-1
else
lab=str(i+sbl:end);
end
sp=lab(1);
pos=[];
for j=1:sbl
if sp~=sb(j)
offset=0;
ml=0;
%send code
else
pos=[pos j];
end
end
Ml=[];
for k=1:length(pos)
count=0;
m=1;
flag=0;
for l=pos(k):sbl+labl
while

Слайд 23Эффективность
Эффективность

Слайд 24LZ 78
LZ 78 не использует "скользящее" окно, он хранит словарь из
LZ 78
LZ 78 не использует "скользящее" окно, он хранит словарь из

Слайд 25LZ 78
Затем в словарь добавляется введенная подстрока. Если словарь уже заполнен, то
LZ 78
Затем в словарь добавляется введенная подстрока. Если словарь уже заполнен, то

Слайд 26LZ 78
Код выхода двойка
Словарь:
0
a
Передача в канал:
0
b
0
c
1
b
4
c
Декодирование:
a
b
c
a
a b
b
c
Требуется не ограничивать
LZ 78
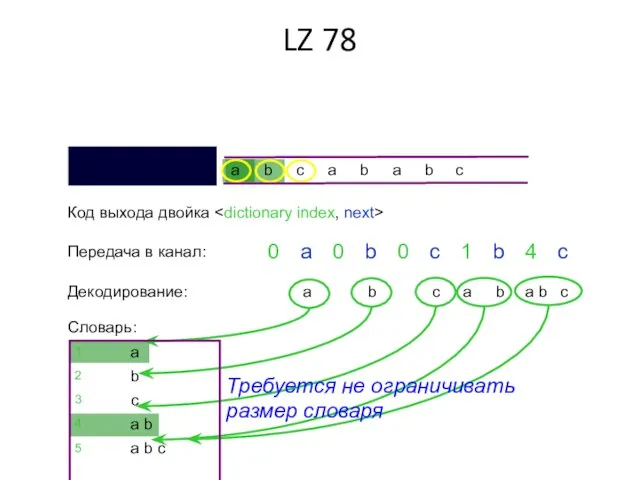
Код выхода двойка Словарь: 0 a Передача в канал: 0 b 0 c 1 b 4 c Декодирование: a b c a a b b c Требуется не ограничивать
Слайд 27Ziv-Lempel-Welch (LZW)-Codes
Идея: вместо последовательностей букв передаются номера слов в некотором словаре.
Кодер и
Ziv-Lempel-Welch (LZW)-Codes
Идея: вместо последовательностей букв передаются номера слов в некотором словаре.
Кодер и

Слайд 28Ziv-Lempel-Welch (LZW)-Codes
Ziv-Lempel-Welch (LZW)-Codes

Слайд 29Ziv-Lempel-Welch (LZW)-Codes
Ziv-Lempel-Welch (LZW)-Codes

Слайд 30LZW
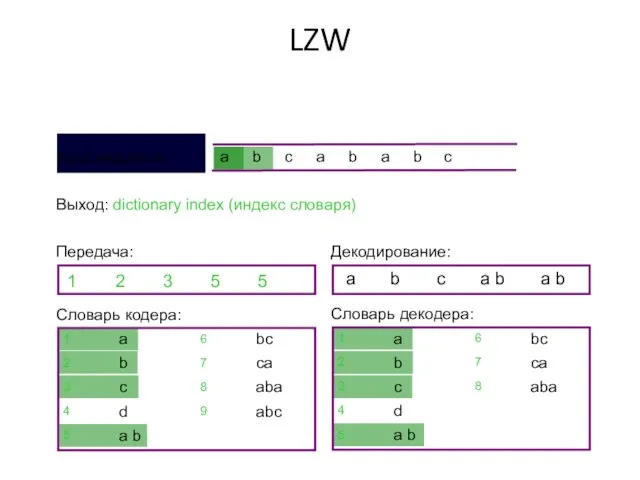
Выход: dictionary index (индекс словаря)
Словарь кодера:
1
Передача:
2
3
5
5
Декодирование:
a
b
c
a b
a b
Словарь декодера:
Input sequence:
LZW
Выход: dictionary index (индекс словаря)
Словарь кодера:
1
Передача:
2
3
5
5
Декодирование:
a
b
c
a b
a b
Словарь декодера:
Input sequence:
Слайд 31Алгоритм LZW
Алгоритм LZW

Слайд 32LZW
im = rgb2gray(imread('lenna.png'));
[h w] = size(im);
Q = 16;
X = im(:);
len = numel(X);
lenh
LZW
im = rgb2gray(imread('lenna.png'));
[h w] = size(im);
Q = 16;
X = im(:);
len = numel(X);
lenh
![LZW im = rgb2gray(imread('lenna.png')); [h w] = size(im); Q = 16; X](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/842906/slide-31.jpg)
Слайд 33LZW
X = X0(:);
D = [X1(:); X2(:); X3(:)];
lenhX = len_huffman(X);
lenhD = len_huffman(D);
lenh =
LZW
X = X0(:);
D = [X1(:); X2(:); X3(:)];
lenhX = len_huffman(X);
lenhD = len_huffman(D);
lenh =
![LZW X = X0(:); D = [X1(:); X2(:); X3(:)]; lenhX = len_huffman(X);](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/842906/slide-32.jpg)
Слайд 34figure(1); clf; sc(out);
figure(1); clf; sc(out);

 Технология программированного обучения
Технология программированного обучения Трехмерное моделирование в современном мире
Трехмерное моделирование в современном мире СЁРЧ. Автоматическая система рекомендаций и подбора контента
СЁРЧ. Автоматическая система рекомендаций и подбора контента Параграф 5. Представление целых чисел в компьютере
Параграф 5. Представление целых чисел в компьютере Как решить проблему сетевого подключения imou, вызванную кодом безопасности?
Как решить проблему сетевого подключения imou, вызванную кодом безопасности? Дип-фейк. Перспективы и последствия
Дип-фейк. Перспективы и последствия Информатика. Моё хобби
Информатика. Моё хобби Программная реализация алгоритма Дейсктры
Программная реализация алгоритма Дейсктры Lektsia_3
Lektsia_3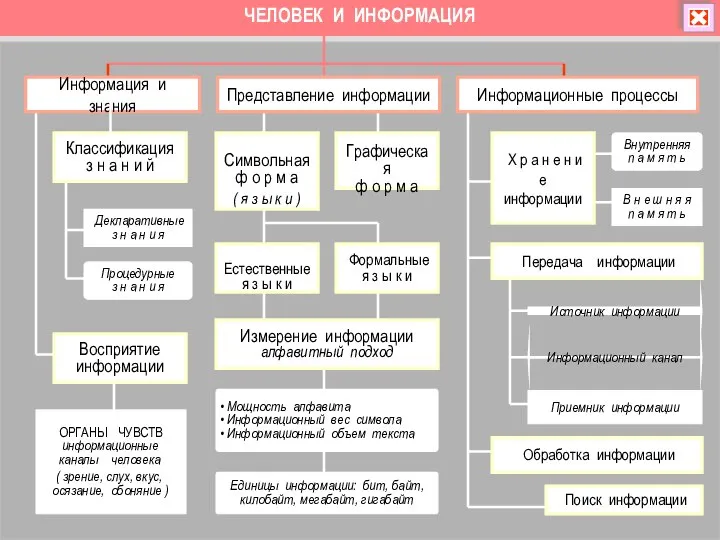 Человек и информация. Информация и знания
Человек и информация. Информация и знания Обучение: Топ-менеждер
Обучение: Топ-менеждер Кибербезопасность и хакинг
Кибербезопасность и хакинг Моя идея для школы будущего. Школа - интернат для одаренных детей Intel.Corp
Моя идея для школы будущего. Школа - интернат для одаренных детей Intel.Corp Установка сносок
Установка сносок Элементы современной электронной презентации на примере проекта Моя группа
Элементы современной электронной презентации на примере проекта Моя группа Программирование (Python)
Программирование (Python) Информационная безопасность. Защита баз данных
Информационная безопасность. Защита баз данных Relative Strength Index
Relative Strength Index Информационные технологии в управлении
Информационные технологии в управлении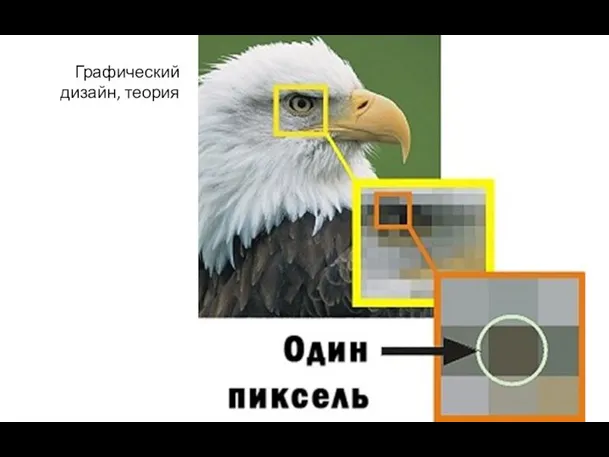 2.3 Введение, пиксели
2.3 Введение, пиксели Выполнила: ученица 10класса МОУ СОШ №14 Чекундинского сельского поселения. Журавлева Лариса.
Выполнила: ученица 10класса МОУ СОШ №14 Чекундинского сельского поселения. Журавлева Лариса.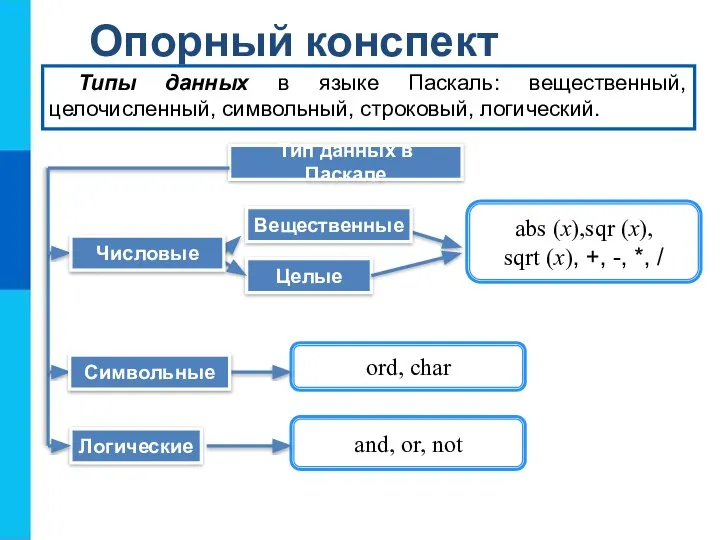 Типы данных в языке Паскаль: вещественный, целочисленный, символьный, строковый, логический
Типы данных в языке Паскаль: вещественный, целочисленный, символьный, строковый, логический Семинар-тренинг 5-8 октября 2014 года. Реестр документов. Документы Интеркампани
Семинар-тренинг 5-8 октября 2014 года. Реестр документов. Документы Интеркампани Презентация на тему Табличные информационные модели
Презентация на тему Табличные информационные модели  Путешествие в типографию
Путешествие в типографию База данных
База данных Содержательный подход измерению количества информации
Содержательный подход измерению количества информации Этапы развития технических средств и информационных ресурсов
Этапы развития технических средств и информационных ресурсов