- Стандартная библиотека STL

Содержание
- 2. Темы лекции
- 3. Библиотека стандартных шаблонов (STL) (англ. Standard Template Library) — набор согласованных обобщённых алгоритмов, контейнеров, средств доступа
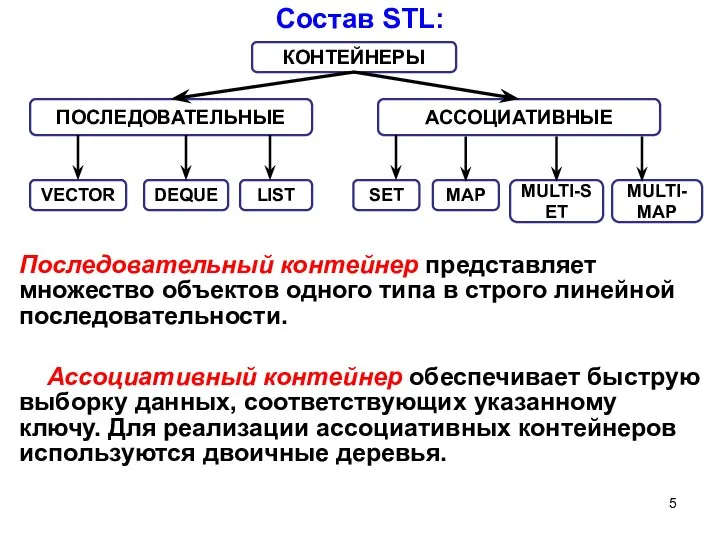
- 4. Состав STL: контейнеры, итераторы, алгоритмы, аллокаторы, адаптеры. Контейнер – хранилище, единицами хранения (элементами) являются другие объекты
- 5. Состав STL: Последовательный контейнер представляет множество объектов одного типа в строго линейной последовательности. Ассоциативный контейнер обеспечивает
- 8. Шаблоны STL основывается на понятии шаблона. Предположим, что для некоторого числа х > 0 нужно часто
- 9. Шаблонные функции Вместо того чтобы писать две функции: double f(double x) { double x2 = 2
- 10. Шаблонные функции // ftempl.срр: Шаблонная функция. #include using namespace std; template T f (T x) {
- 11. Шаблонные структуры Пусть нам нужна структура Pair, чтобы хранить пары значений. Иногда оба значения принадлежат к
- 12. Шаблонные структуры Вместо этого напишем одну шаблонную структуру: // cltempl.срр: #include template struct Pair { void
- 13. Шаблонные структуры template void Pair ::showQ() { cout } int main() { Pair a(37.0, 5.0); Pair
- 14. Замечания Как пользователи STL мы можем не беспокоиться об определениях, так как шаблонные функции, структуры и
- 16. Идея итераторов: Итератор – аналог указателя. Получив итератор какого-то элемента контейнера при помощи операторов инкремента ++
- 17. Итераторы Какие функции должен выполнять итератор? Возможность разыменования того объекта, на который указывает итератор. Возможность изменить
- 18. Типы Итераторы Input Iterator – получаем доступ только для чтения данных (необходим инкремент). Output Iterator –
- 19. Иерархия итераторов Random Access Iterator Bidirectional Iterator Forward Iterator Input Iterator Output Iterator Trivial Iterator Все
- 20. Итераторы обеспечивают доступ к элементам контейнера. С помощью итераторов очень удобно перебирать элементы. Итератор описывается типом
- 21. Операции с итераторами С итераторами можно проводить следующие операции: *iter: получение элемента, на который указывает итератор
- 23. Алгоритмы Алгориты делятся на несколько категорий: немодифицирующие алгоритмы (не изменяющие порядок следования элементов в контейнере) –
- 24. Аллокаторы Аллокаторы предназначены для выделения и освобождения памяти, – низкоуровневый интерфейс. Если контейнер выделяет память при
- 26. Синтаксис вызова обобщенного алгоритма find where = find(first, last, value); Параметры: • first - итератор, указывающий
- 27. #include #include #include #include // Алгоритм find using namespace std; int main() { cout char s[]
- 28. Понятие итератора является ключевым в STL. Алгоритмы STL написаны с применением итераторов в качестве параметров, а
- 30. Vector (Вектор) .
- 31. Vector — это замена стандартному динамическому массиву, память для которого выделяется вручную, с помощью оператора new.
- 32. Методы Vector: push_back() — добавить последний элемент pop_back() — удалить последний элемент clear() — удалить все
- 33. #include #include #include #include // Алгоритм find using namespace std; int main() { cout vector vectorl
- 34. List .
- 35. Контейнер list представляет двухсвязный список. Для его использования необходимо подключить заголовочный файл list: Создание списка: #include
- 36. Получение элементов В отличие от других контейнеров для типа list не определена операция обращения по индексу
- 37. #include #include int main() { std::list numbers = { 1, 2, 3, 4, 5 }; int
- 38. Размер списка Для получения размера списка можно использовать функцию size(): Функция empty() позволяет узнать, пуст ли
- 39. std::list numbers = { 1, 2, 3, 4, 5, 6 }; numbers.resize(4); // оставляем первые четыре
- 40. Изменение элементов списка Функция assign() позволяет заменить все элементы списка определенным набором. Она имеет следующие формы:
- 41. Функция swap() обменивает значениями два списка: std::list list1 = { 1, 2, 3, 4, 5 };
- 42. Добавление элементов Для добавления элементов в контейнер list применяется ряд функций. push_back(val): добавляет значение val в
- 43. Функции push_back(), push_front(), emplace_back() и emplace_front(): Добавление в середину списка с помощью функции emplace(): std::list numbers
- 44. Добавление в середину списка с помощью функции insert(): std::list numbers1 = { 1, 2, 3, 4,
- 45. Удаление элементов Для удаления элементов из контейнера list могут применяться следующие функции: clear(p): удаляет все элементы
- 46. #include #include #include #include using namespace std; int main() { cout list listl = make >("C++
- 47. #include #include #include #include using namespace std; int main() { cout deque dequel = make >("C++
- 48. Map .
- 49. Что такое map Это ассоциативный контейнер, который работает по принципу — [ключ — значение]. Он схож
- 50. Как создать map Сперва понадобится подключить соответствующую библиотеку: Чтобы создать map нужно воспользоваться данной конструкцией: —
- 51. Множества и словари map (multimap) – ассоциативный контейнер, который отсортированные список пар в соответствии с уникальным
- 52. Итераторы для map .
- 53. Итераторы для map Использование итераторов одна из главных тем, если вам понадобится оперировать с этим контейнером.
- 54. #include #include using namespace std; int main() { setlocale(0, ""); map mp; cout > n; for
- 55. Методы map insert Это функция вставки нового элемента. num_1 — ключ. num_2 — значение. Мы можем
- 56. find У этой функции основная цель узнать, есть ли определенный ключ в контейнере. - Если он
- 57. erase Иногда приходится удалять элементы. Для этого у нас есть функция — erase(). Давайте посмотрим как
- 58. Множества и словари set (multiset) – ассоциативный контейнер, который содержит элементы, отсортированные в соответствии с уникальным
- 60. Обобщенный алгоритм merge. Алгоритм merge используется для объединения двух отсортированных последовательностей в единую (отсортированную) последовательность. Параметры
- 61. #include using namespace std; int main() { cout char s[] = "aeiou"; int len = strlen(s);
- 62. #include using namespace std; int main() { cout char s[] = "acegikm"; deque deque1 = make
- 64. Алгоритмы стандартной библиотеки Немодифицирующие операции над последовательностями: all_of any_of none_of // Проверяют, является ли предикат верным
- 65. adjacent_find // Ищет в диапазоне два одинаковых смежных элемента mismatch // Находит первую позицию, в которой
- 66. Модифицирующие операции над последовательностями: copy copy_if // Копирует ряд элементов copy_n // Копирует ряд элементов в
- 67. replace replace_if // заменяет все значения, удовлетворяющие определенным // критериям с другим значением swap // обмен
- 68. Операции разделения: is_partitioned // определяет, разделен ли диапазон данным предикатом partition // делит диапазон элементов на
- 69. Операции, относящиеся к упорядочиванию: is_sorted // проверяет, является ли диапазон отсортированным в порядке // возрастания is_sorted_until
- 70. Операции двоичного поиска (на отсортированных диапазонах) : lower_bound // находит первый элемент диапазона больший чем заданное
- 71. Операции над множествами (на отсортированных диапазонах) : merge // слияние двух отсортированных диапазонов inplace_merge // слияние
- 72. Операции над пирамидой (кучей) : is_heap // проверяет является ли данный диапазон пирамидой is_heap_until // находит
- 73. Этот заголовочный файл содержит набор алгоритмов для выполнения определенных операций над последовательностями числовых значений. Благодаря своей
- 74. Операции минимума/максимума: max // Возвращает наибольший из двух аргументов max_element // Возвращает наибольший элемент в диапазоне
- 75. Алгоритмы из библиотеки C : qsort // Сортирует диапазон элементов любого типа bsearch // Ищет в
- 77. Предикат. Функция-предикат и функтор Предикат, это нечто функциональное, возвращающее тип bool. Есть две возможности организации такой
- 78. bool f (const int& x,const int& y){ return x // создаем синоним типа - указатель на
- 79. Функтор Есть большое множество вариантов их практического применения: - Необходим вызов обычной функции или функции-члена класса.
- 80. any_of template bool any_of (InputIterator first, InputIterator last, UnaryPredicate pred); Проверяет, соответствует ли какой-либо элемент в
- 81. #include // std::cout #include // std::any_of #include // std::array int main () { std::array foo =
- 83. #include #include // Алгоритм accumulate using namespace std; int main() { cout int х[5] = {2,
- 84. Рассмотрим, как функция accumulate использует итераторы. template T accumulate(InputIterator first, Inputlterator last, T init) { while(first
- 85. Функциональные объекты Из определения шаблона accumulate в предыдущем примере видно, что для элементов контейнера задан оператор
- 86. Пример. Использование accumulate для расчета произведения элементов #include #include #include #include using namespace std; int mult(int
- 87. Пример. Расчет произведения с применением функционального объекта class multiply { public: int operator()(int x, int y)
- 88. Пример использования словаря Создаём структуру TicketInfo, который будет содержать все необходимые поля для заявки, а также
- 89. Описание класса struct TicketInfo { long ticket_id; // идентификатор билета long n_reis; // номер рейса string
- 90. int add_ticket() int add_ticket() { setlocale(LC_ALL,"Russian"); long reis_n, id_ticket; char ch[30]; string str; TicketInfo tickets; multimap
- 92. Скачать презентацию

Слайд 3Библиотека стандартных шаблонов (STL) (англ. Standard Template Library) — набор согласованных обобщённых алгоритмов, контейнеров, средств доступа к их
Библиотека стандартных шаблонов (STL) (англ. Standard Template Library) — набор согласованных обобщённых алгоритмов, контейнеров, средств доступа к их

Слайд 4Состав STL:
контейнеры,
итераторы,
алгоритмы,
аллокаторы,
адаптеры.
Контейнер – хранилище, единицами хранения (элементами) являются другие объекты + набор
Состав STL:
контейнеры,
итераторы,
алгоритмы,
аллокаторы,
адаптеры.
Контейнер – хранилище, единицами хранения (элементами) являются другие объекты + набор

Слайд 5Состав STL:
Последовательный контейнер представляет множество объектов одного типа в строго линейной последовательности.
Состав STL:
Последовательный контейнер представляет множество объектов одного типа в строго линейной последовательности.
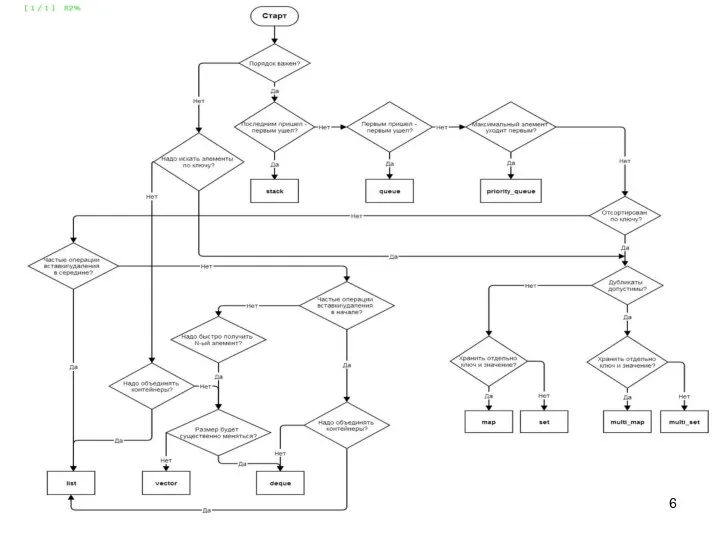

Слайд 8Шаблоны
STL основывается на понятии шаблона.
Предположим, что для некоторого числа
х
Шаблоны
STL основывается на понятии шаблона.
Предположим, что для некоторого числа
х

Слайд 9Шаблонные функции
Вместо того чтобы писать две функции:
double f(double x)
Шаблонные функции
Вместо того чтобы писать две функции:
double f(double x)

Слайд 10Шаблонные функции
// ftempl.срр: Шаблонная функция.
#include
using namespace std;
template
T
Шаблонные функции
// ftempl.срр: Шаблонная функция.
#include
using namespace std;
template
T

Слайд 11Шаблонные структуры
Пусть нам нужна структура Pair, чтобы хранить пары значений. Иногда
Шаблонные структуры
Пусть нам нужна структура Pair, чтобы хранить пары значений. Иногда

Слайд 12Шаблонные структуры
Вместо этого напишем одну шаблонную структуру:
// cltempl.срр:
#include
template
struct
Шаблонные структуры
Вместо этого напишем одну шаблонную структуру:
// cltempl.срр:
#include
template
struct

Слайд 13Шаблонные структуры
template < typename T>
void Pair::showQ()
{
cout << x/y <<
Шаблонные структуры
template < typename T>
void Pair
{
cout << x/y <<

Слайд 14Замечания
Как пользователи STL мы можем не беспокоиться об определениях, так как
Замечания
Как пользователи STL мы можем не беспокоиться об определениях, так как


Слайд 16Идея итераторов:
Итератор – аналог указателя. Получив итератор какого-то элемента контейнера при
Идея итераторов:
Итератор – аналог указателя. Получив итератор какого-то элемента контейнера при

Слайд 17Итераторы
Какие функции должен выполнять итератор?
Возможность разыменования того объекта, на который указывает итератор.
Возможность
Итераторы
Какие функции должен выполнять итератор?
Возможность разыменования того объекта, на который указывает итератор.
Возможность

Слайд 18Типы Итераторы
Input Iterator – получаем доступ только для чтения данных (необходим
Типы Итераторы
Input Iterator – получаем доступ только для чтения данных (необходим

Слайд 19Иерархия итераторов
Random Access Iterator
Bidirectional Iterator
Forward Iterator
Input Iterator Output Iterator
Иерархия итераторов
Random Access Iterator
Bidirectional Iterator
Forward Iterator
Input Iterator Output Iterator
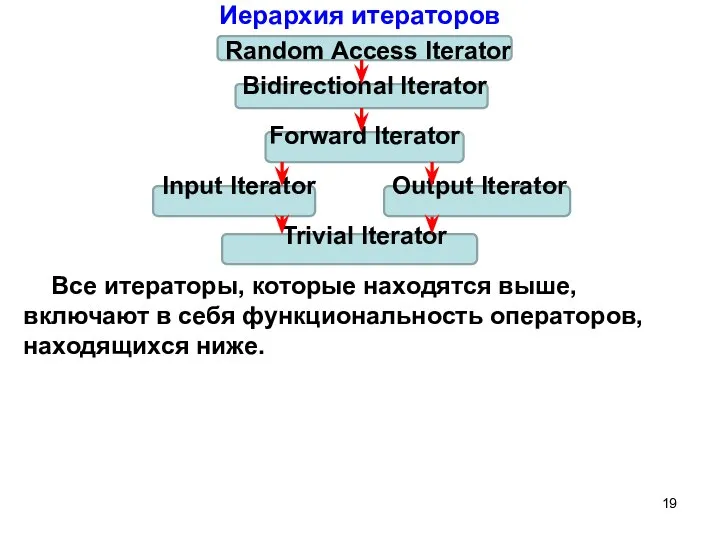
Слайд 20Итераторы обеспечивают доступ к элементам контейнера. С помощью итераторов очень удобно перебирать
Итераторы обеспечивают доступ к элементам контейнера. С помощью итераторов очень удобно перебирать

Слайд 21Операции с итераторами
С итераторами можно проводить следующие операции:
*iter: получение элемента, на который
Операции с итераторами
С итераторами можно проводить следующие операции:
*iter: получение элемента, на который


Слайд 23Алгоритмы
Алгориты делятся на несколько категорий:
немодифицирующие алгоритмы (не изменяющие порядок следования элементов
Алгоритмы
Алгориты делятся на несколько категорий:
немодифицирующие алгоритмы (не изменяющие порядок следования элементов

Слайд 24Аллокаторы
Аллокаторы предназначены для выделения и освобождения памяти, – низкоуровневый интерфейс. Если
Аллокаторы
Аллокаторы предназначены для выделения и освобождения памяти, – низкоуровневый интерфейс. Если


Слайд 26Синтаксис вызова обобщенного алгоритма find
where = find(first, last, value);
Параметры:
• first
where = find(first, last, value);
Параметры:
• first

Слайд 27#include
#include
#include
#include // Алгоритм find
using namespace std;
#include
#include
#include
#include
using namespace std;

Слайд 28Понятие итератора является ключевым в STL. Алгоритмы STL написаны с применением итераторов
Понятие итератора является ключевым в STL. Алгоритмы STL написаны с применением итераторов
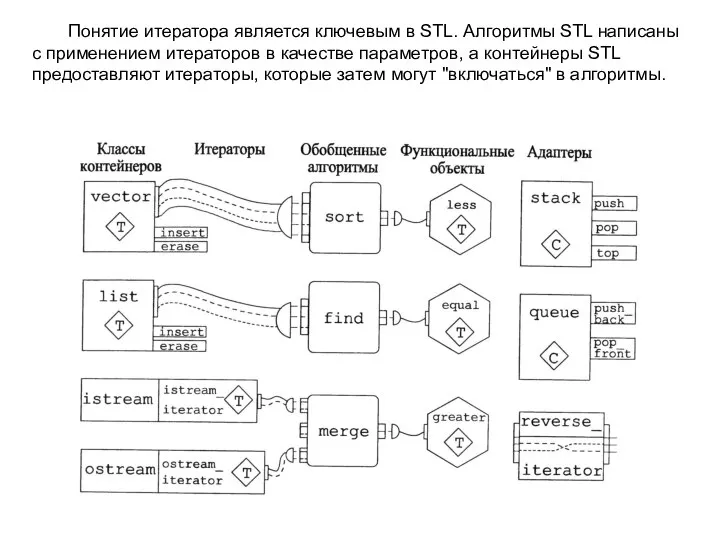

Слайд 30Vector (Вектор)
.
Vector (Вектор)
.

Слайд 31Vector — это замена стандартному динамическому массиву, память для которого выделяется вручную,
Vector — это замена стандартному динамическому массиву, память для которого выделяется вручную,

Слайд 32Методы Vector:
push_back() — добавить последний элемент
pop_back() — удалить последний элемент
clear() — удалить
Методы Vector:
push_back() — добавить последний элемент
pop_back() — удалить последний элемент
clear() — удалить

Слайд 33#include
#include
#include
#include // Алгоритм find
using
#include
#include
#include
#include
using

Слайд 34List
.
List
.

Слайд 35Контейнер list представляет двухсвязный список. Для его использования необходимо подключить заголовочный файл list:
Создание списка:
#include
std::list
Контейнер list представляет двухсвязный список. Для его использования необходимо подключить заголовочный файл list:
Создание списка:
#include std::list

Слайд 36Получение элементов
В отличие от других контейнеров для типа list не определена операция
Получение элементов
В отличие от других контейнеров для типа list не определена операция

Слайд 37
#include
#include
int main()
{
std::list numbers = { 1, 2, 3, 4,
#include
#include
int main()
{
std::list

Слайд 38Размер списка
Для получения размера списка можно использовать функцию size():
Функция empty() позволяет узнать, пуст ли список.
Размер списка
Для получения размера списка можно использовать функцию size():
Функция empty() позволяет узнать, пуст ли список.

Слайд 39
std::list numbers = { 1, 2, 3, 4, 5, 6 };
numbers.resize(4); //
std::list
numbers.resize(4); //

Слайд 40Изменение элементов списка
Функция assign() позволяет заменить все элементы списка определенным набором. Она имеет следующие
Изменение элементов списка
Функция assign() позволяет заменить все элементы списка определенным набором. Она имеет следующие

Слайд 41Функция swap() обменивает значениями два списка:
std::list list1 = { 1, 2, 3, 4, 5
Функция swap() обменивает значениями два списка:
std::list
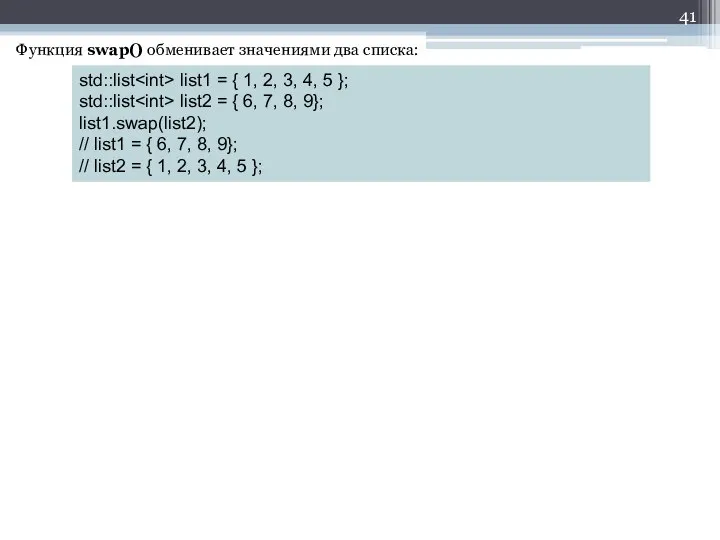
Слайд 42Добавление элементов
Для добавления элементов в контейнер list применяется ряд функций.
push_back(val): добавляет значение
Добавление элементов
Для добавления элементов в контейнер list применяется ряд функций.
push_back(val): добавляет значение

Слайд 43Функции push_back(), push_front(), emplace_back() и emplace_front():
Добавление в середину списка с помощью функции emplace():
std::list
Функции push_back(), push_front(), emplace_back() и emplace_front():
Добавление в середину списка с помощью функции emplace():
std::list

Слайд 44Добавление в середину списка с помощью функции insert():
std::list numbers1 = { 1, 2,
Добавление в середину списка с помощью функции insert():
std::list

Слайд 45Удаление элементов
Для удаления элементов из контейнера list могут применяться следующие функции:
clear(p): удаляет
Удаление элементов
Для удаления элементов из контейнера list могут применяться следующие функции:
clear(p): удаляет

Слайд 46#include
#include
#include
#include
using namespace std;
<Функция
#include
#include
#include
#include
using namespace std;
<Функция

Слайд 47#include
#include
#include
#include
using namespace std;
<Функция make
#include
#include
#include
#include
using namespace std;
<Функция make

Слайд 48Map
.
Map
.

Слайд 49Что такое map
Это ассоциативный контейнер, который работает по принципу — [ключ — значение].
Что такое map
Это ассоциативный контейнер, который работает по принципу — [ключ — значение].
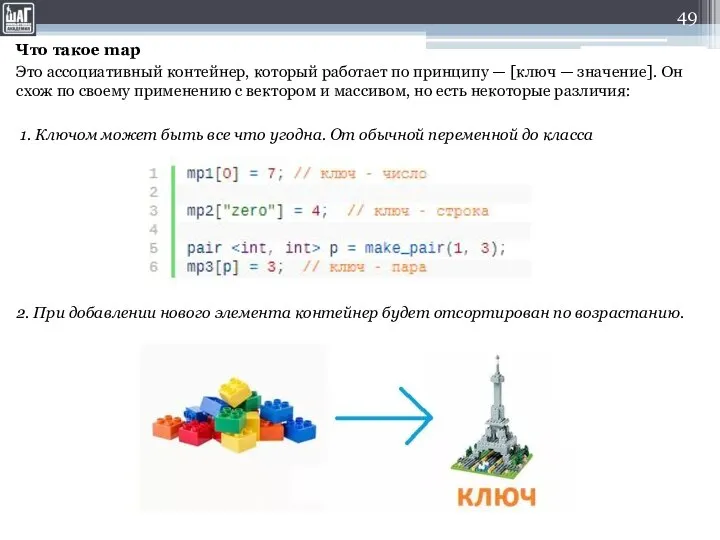
Слайд 50Как создать map
Сперва понадобится подключить соответствующую библиотеку:
Чтобы создать map нужно воспользоваться данной конструкцией:
—
Как создать map
Сперва понадобится подключить соответствующую библиотеку:
Чтобы создать map нужно воспользоваться данной конструкцией:

Слайд 51Множества и словари
map (multimap) – ассоциативный контейнер, который отсортированные список пар
Множества и словари
map (multimap) – ассоциативный контейнер, который отсортированные список пар

Слайд 52Итераторы для map
.
Итераторы для map
.

Слайд 53Итераторы для map
Использование итераторов одна из главных тем, если вам понадобится оперировать с этим контейнером.
Итераторы для map
Использование итераторов одна из главных тем, если вам понадобится оперировать с этим контейнером.

Слайд 54#include
#include
#include
#include

Слайд 55Методы map
insert
Это функция вставки нового элемента.
num_1 — ключ.
num_2 — значение.
Методы map
insert
Это функция вставки нового элемента.
num_1 — ключ.
num_2 — значение.

Слайд 56find
У этой функции основная цель узнать, есть ли определенный ключ в контейнере.
-
find
У этой функции основная цель узнать, есть ли определенный ключ в контейнере.
-

Слайд 57erase
Иногда приходится удалять элементы. Для этого у нас есть функция — erase().
Давайте
erase
Иногда приходится удалять элементы. Для этого у нас есть функция — erase().
Давайте

Слайд 58Множества и словари
set (multiset) – ассоциативный контейнер, который содержит элементы, отсортированные в
Множества и словари
set (multiset) – ассоциативный контейнер, который содержит элементы, отсортированные в


Слайд 60Обобщенный алгоритм merge.
Алгоритм merge используется для объединения двух отсортированных последовательностей в единую
Обобщенный алгоритм merge.
Алгоритм merge используется для объединения двух отсортированных последовательностей в единую

Слайд 61#include <...>
using namespace std;
int main()
{
cout << "merge
#include <...>
using namespace std;
int main()
{
cout << "merge
![#include using namespace std; int main() { cout char s[] = "aeiou";](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/924419/slide-60.jpg)
Слайд 62#include <...>
using namespace std;
int main()
{
cout << "Объединение
#include <...>
using namespace std;
int main()
{
cout << "Объединение
![#include using namespace std; int main() { cout char s[] = "acegikm";](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/924419/slide-61.jpg)

Слайд 64Алгоритмы стандартной библиотеки
Немодифицирующие операции над последовательностями:
all_of
any_of
none_of // Проверяют, является ли предикат верным
Алгоритмы стандартной библиотеки
Немодифицирующие операции над последовательностями:
all_of
any_of
none_of // Проверяют, является ли предикат верным

Слайд 65adjacent_find // Ищет в диапазоне два одинаковых смежных элемента
mismatch // Находит
adjacent_find // Ищет в диапазоне два одинаковых смежных элемента
mismatch // Находит

Слайд 66 Модифицирующие операции над последовательностями:
copy
copy_if // Копирует ряд элементов
copy_n // Копирует ряд
Модифицирующие операции над последовательностями:
copy
copy_if // Копирует ряд элементов
copy_n // Копирует ряд

Слайд 67replace
replace_if // заменяет все значения, удовлетворяющие определенным
// критериям с другим значением
replace
replace_if // заменяет все значения, удовлетворяющие определенным
// критериям с другим значением

Слайд 68 Операции разделения:
is_partitioned // определяет, разделен ли диапазон данным предикатом
partition // делит
Операции разделения:
is_partitioned // определяет, разделен ли диапазон данным предикатом
partition // делит

Слайд 69 Операции, относящиеся к упорядочиванию:
is_sorted // проверяет, является ли диапазон отсортированным в
Операции, относящиеся к упорядочиванию:
is_sorted // проверяет, является ли диапазон отсортированным в

Слайд 70 Операции двоичного поиска (на отсортированных диапазонах) :
lower_bound // находит первый элемент
Операции двоичного поиска (на отсортированных диапазонах) :
lower_bound // находит первый элемент

Слайд 71 Операции над множествами (на отсортированных диапазонах) :
merge // слияние двух отсортированных диапазонов
Операции над множествами (на отсортированных диапазонах) :
merge // слияние двух отсортированных диапазонов

Слайд 72 Операции над пирамидой (кучей) :
is_heap // проверяет является ли данный диапазон
Операции над пирамидой (кучей) :
is_heap // проверяет является ли данный диапазон

Слайд 73Этот заголовочный файл содержит набор алгоритмов для выполнения определенных операций над последовательностями
Этот заголовочный файл содержит набор алгоритмов для выполнения определенных операций над последовательностями

Слайд 74 Операции минимума/максимума:
max // Возвращает наибольший из двух аргументов
max_element // Возвращает
Операции минимума/максимума:
max // Возвращает наибольший из двух аргументов
max_element // Возвращает

Слайд 75 Алгоритмы из библиотеки C :
qsort // Сортирует диапазон элементов любого типа
Алгоритмы из библиотеки C :
qsort // Сортирует диапазон элементов любого типа


Слайд 77Предикат. Функция-предикат и функтор
Предикат, это нечто функциональное, возвращающее тип bool. Есть две
Предикат. Функция-предикат и функтор
Предикат, это нечто функциональное, возвращающее тип bool. Есть две

Слайд 78bool f (const int& x,const int& y){ return x// создаем
bool f (const int& x,const int& y){ return x

Слайд 79Функтор
Есть большое множество вариантов их практического применения:
- Необходим вызов обычной функции или
Функтор
Есть большое множество вариантов их практического применения:
- Необходим вызов обычной функции или

Слайд 80any_of
template
bool any_of (InputIterator first, InputIterator last, UnaryPredicate
any_of
template
bool any_of (InputIterator first, InputIterator last, UnaryPredicate

Слайд 81#include // std::cout
#include // std::any_of
#include // std::array
int main ()
#include
#include
#include
int main ()


Слайд 83#include <...>
#include // Алгоритм accumulate
using namespace std;
int main()
#include <...>
#include
using namespace std;
int main()

Слайд 84Рассмотрим, как функция accumulate использует итераторы.
template
T
Рассмотрим, как функция accumulate использует итераторы.
template
T

Слайд 85Функциональные объекты
Из определения шаблона accumulate в предыдущем примере видно, что для элементов
Функциональные объекты
Из определения шаблона accumulate в предыдущем примере видно, что для элементов

Слайд 86Пример. Использование accumulate для расчета произведения элементов
#include
#include
#include
Пример. Использование accumulate для расчета произведения элементов
#include
#include
#include

Слайд 87Пример. Расчет произведения с применением функционального объекта
class multiply
{
public:
Пример. Расчет произведения с применением функционального объекта
class multiply
{
public:

Слайд 88Пример использования словаря
Создаём структуру TicketInfo, который будет содержать все необходимые поля для
Пример использования словаря
Создаём структуру TicketInfo, который будет содержать все необходимые поля для

Слайд 89Описание класса
struct TicketInfo
{
long ticket_id; // идентификатор билета
long n_reis; // номер рейса
string
Описание класса
struct TicketInfo
{
long ticket_id; // идентификатор билета
long n_reis; // номер рейса
string

Слайд 90int add_ticket()
int add_ticket()
{ setlocale(LC_ALL,"Russian");
long reis_n, id_ticket;
char ch[30]; string str;
TicketInfo tickets;
multimap::iterator it;
bool yes(false),
int add_ticket()
int add_ticket()
{ setlocale(LC_ALL,"Russian");
long reis_n, id_ticket;
char ch[30]; string str;
TicketInfo tickets;
multimap
bool yes(false),
![int add_ticket() int add_ticket() { setlocale(LC_ALL,"Russian"); long reis_n, id_ticket; char ch[30]; string](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/924419/slide-89.jpg)
 IoC Inversion of Control инверсия управления. Dependency Injection (внедрение зависимостей)
IoC Inversion of Control инверсия управления. Dependency Injection (внедрение зависимостей) логика
логика Особенности материалов для соцсетей: пост, лонгрид подкаст
Особенности материалов для соцсетей: пост, лонгрид подкаст 1_количество_инф
1_количество_инф Использование свободного программного обеспечения для обучения графике
Использование свободного программного обеспечения для обучения графике Информация
Информация Разработка автоматизированной информационной системы учета материальных и иных активов в ЦЦОД IT-Куб г. Княгинино
Разработка автоматизированной информационной системы учета материальных и иных активов в ЦЦОД IT-Куб г. Княгинино Создание кроссворда в текстовом процессоре Word. 8 класс
Создание кроссворда в текстовом процессоре Word. 8 класс Анализ неструктурированных данных и оптимизация их хранения
Анализ неструктурированных данных и оптимизация их хранения ВКР: Разработка агрегатора сервисных центров по ремонту электроники
ВКР: Разработка агрегатора сервисных центров по ремонту электроники Настройка Vlan
Настройка Vlan Составление комбинированных алгоритмов для графических исполнителей
Составление комбинированных алгоритмов для графических исполнителей Макросы MoveHim и MoveTo
Макросы MoveHim и MoveTo Дистанционная подготовка
Дистанционная подготовка Отношения между объектами
Отношения между объектами Библиотечный урок В гостях у книжки о структуре книги
Библиотечный урок В гостях у книжки о структуре книги Интересные факты
Интересные факты Створюємо блог
Створюємо блог Школа “Успех в Internet PRO100”
Школа “Успех в Internet PRO100” Мемы
Мемы Самоаудит отделений boxberry через мобильное приложение Checkpoint
Самоаудит отделений boxberry через мобильное приложение Checkpoint Работа редактора с композицией медиатекста
Работа редактора с композицией медиатекста Jobs Guessing Game
Jobs Guessing Game App that change adventures
App that change adventures Основные логические операции
Основные логические операции Улучшаем монетизацию c РСЯ
Улучшаем монетизацию c РСЯ Представление данных в текстовом формате. Информационные технологии
Представление данных в текстовом формате. Информационные технологии Триггеры в презентации. Применение
Триггеры в презентации. Применение