- Точность коэффициентов регрессии

Содержание
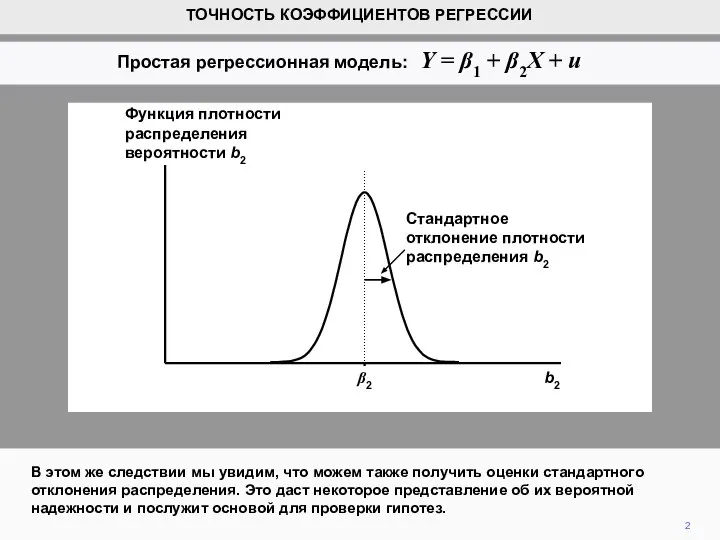
- 2. В этом же следствии мы увидим, что можем также получить оценки стандартного отклонения распределения. Это даст
- 3. Выражения (которые не решены) для дисперсий их распределений показаны выше. См. Вставку 2.3 в тексте для
- 4. Мы сосредоточимся на значении выражения для дисперсии b2. Рассматривая числитель, мы видим, что дисперсия b2 пропорциональна
- 5. Это показано на диаграммах, представленных выше. Случайная составляющая зависимости, Y = 3.0 + 0.8Xпредставленная пунктирной линейна
- 6. Значения Х одинаковы, и одинаковые случайные числа использовались для генерирования значений остаточного члена в 20 наблюдениях.
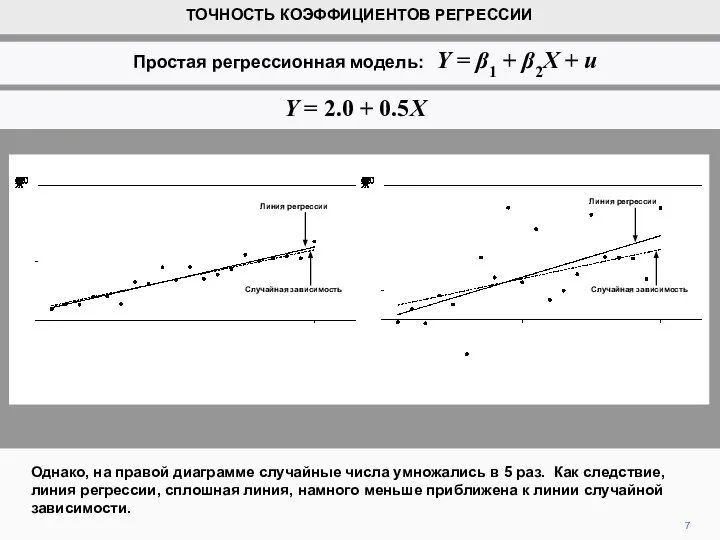
- 7. Однако, на правой диаграмме случайные числа умножались в 5 раз. Как следствие, линия регрессии, сплошная линия,
- 8. Посмотрим на знаменатель выражения для дисперсии b2Чем больше сумма квадратов отклонений X, тем меньше дисперсия b2.
- 9. Однако, значение суммы квадратов отклонений зависит от двух факторов: количества наблюдений и размера отклонений Xi от
- 10. Из приведенного выражения видно, что дисперсия b2 обратно пропорциональна n, числу наблюдений в выборке, которые управляют
- 11. 11 Третьим следствием выражения является то, что дисперсия обратно пропорциональна среднему квадратическому отклонению Х. В чем
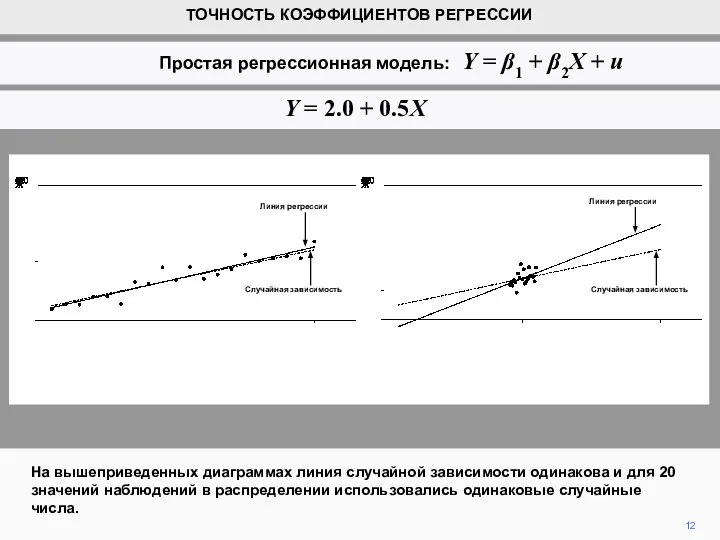
- 12. На вышеприведенных диаграммах линия случайной зависимости одинакова и для 20 значений наблюдений в распределении использовались одинаковые
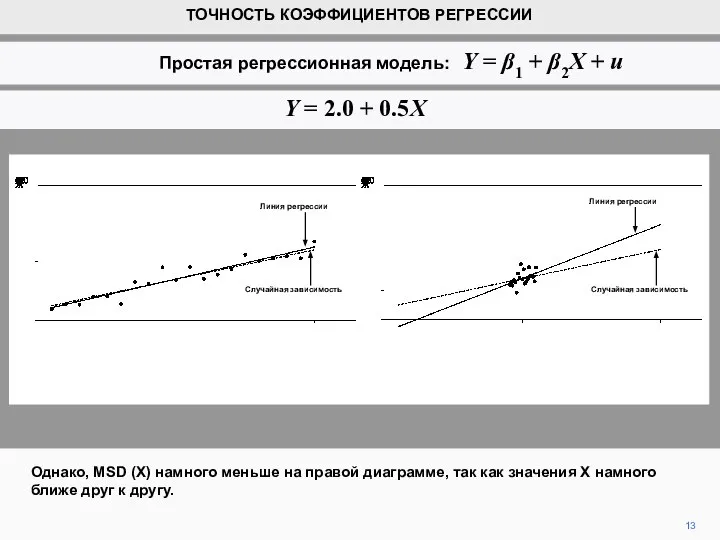
- 13. Однако, MSD (X) намного меньше на правой диаграмме, так как значения Х намного ближе друг к
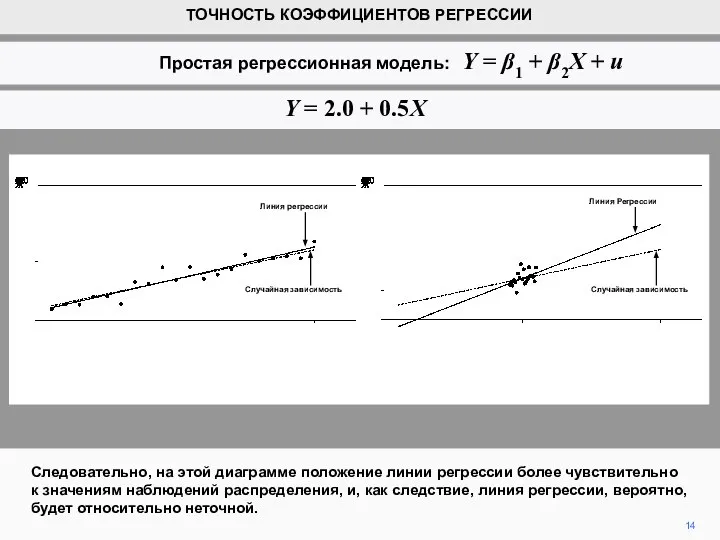
- 14. Следовательно, на этой диаграмме положение линии регрессии более чувствительно к значениям наблюдений распределения, и, как следствие,
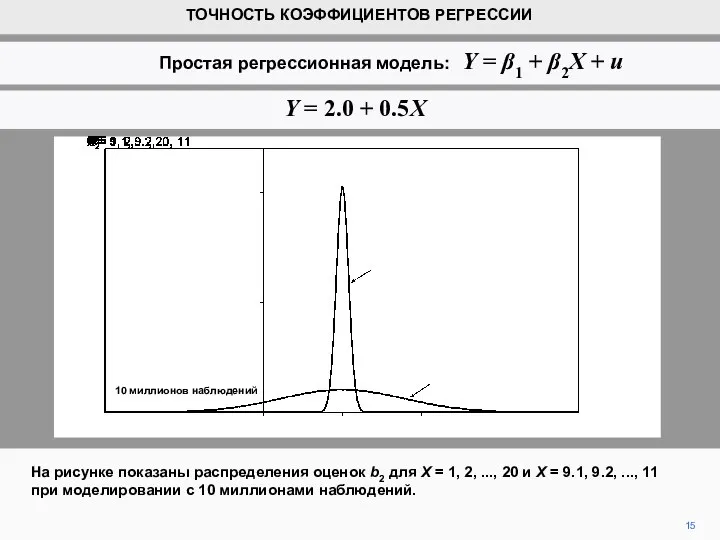
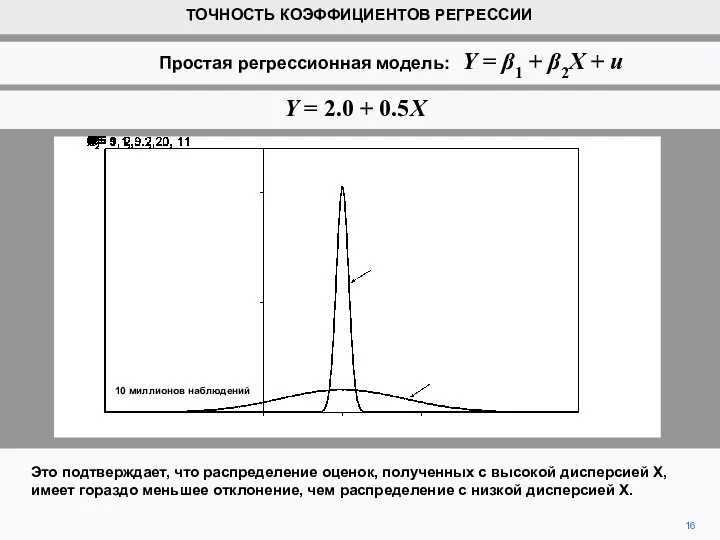
- 15. На рисунке показаны распределения оценок b2 для X = 1, 2, ..., 20 и X =
- 16. Это подтверждает, что распределение оценок, полученных с высокой дисперсией Х, имеет гораздо меньшее отклонение, чем распределение
- 17. Конечно, как видно из выражений дисперсии, отношение MSD (X) к дисперсии u важнее, чем ее абсолютное
- 18. 18 Мы не можем рассчитать теоретические дисперсии именно потому, что не знаем дисперсии остаточного члена. Однако,
- 19. 19 Очевидно, что разброс остатков относительно линии регрессии будет отражать неизвестный разброс u относительно линии Yi
- 20. 20 Одной из мер разброса остатков является их средняя квадратическая ошибка, MSD(e), которая определяется формулой, указанной
- 21. 21 Прежде чем пойти дальше, задайте себе следующий вопрос: какая прямая вероятнее будет ближе к точкам,
- 22. 22 Ответ – линия регрессии, так как по определению она строится таким образом, чтобы свести к
- 23. 23 Следовательно, разброс остатков у нее меньше, чем разброс значений u, а MSD(e) имеет тенденцию занижать
- 24. 24 Действительно, можно показать, что математическое ожидание MSD(e), если имеется всего одна независимая переменная, находится выражением
- 25. 25 Однако отсюда следует, что мы можем получить несмещенную оценку σu2, умножив MSD(e) на n /
- 26. 26 Затем мы можем получить оценки стандартных отклонений распределений b1 и b2, подставив su2 для σu2
- 27. 27 Они описываются как стандартные ошибки b1 и b2, «оценки среднеквадратических отклонений» являются более полными. ТОЧНОСТЬ
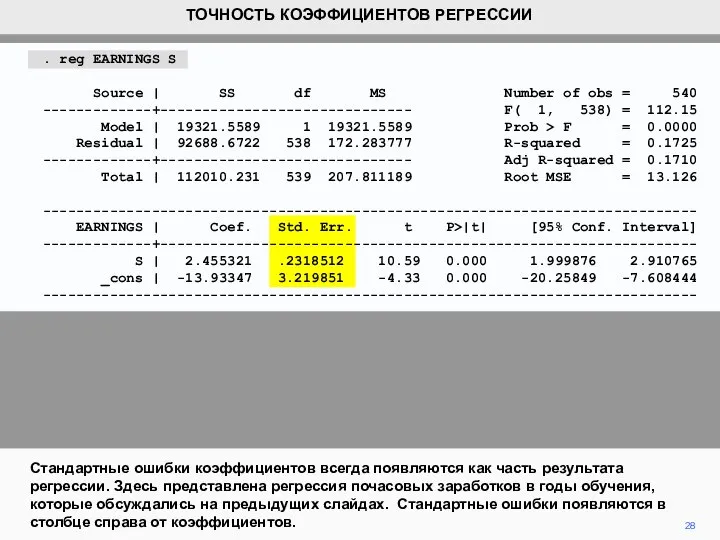
- 28. 28 Стандартные ошибки коэффициентов всегда появляются как часть результата регрессии. Здесь представлена регрессия почасовых заработков в
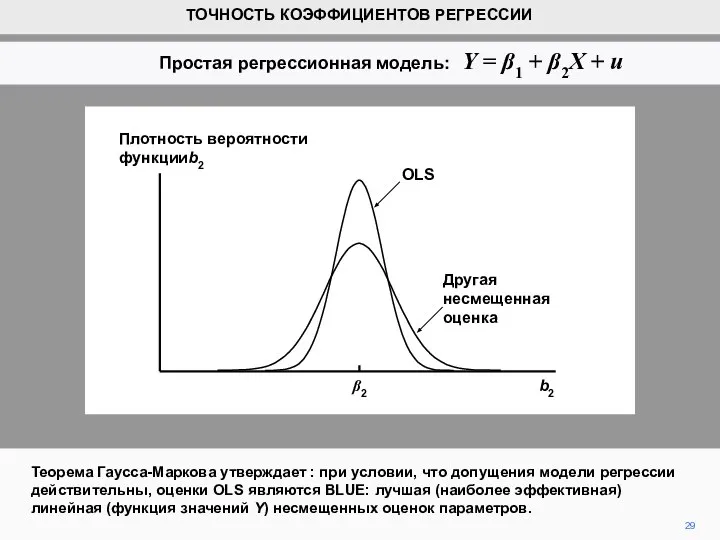
- 29. Теорема Гаусса-Маркова утверждает : при условии, что допущения модели регрессии действительны, оценки OLS являются BLUE: лучшая
- 31. Скачать презентацию
Слайд 3Выражения (которые не решены) для дисперсий их распределений показаны выше. См. Вставку
Выражения (которые не решены) для дисперсий их распределений показаны выше. См. Вставку

Слайд 4Мы сосредоточимся на значении выражения для дисперсии b2. Рассматривая числитель, мы видим,
Мы сосредоточимся на значении выражения для дисперсии b2. Рассматривая числитель, мы видим,

Слайд 5Это показано на диаграммах, представленных выше. Случайная составляющая зависимости, Y = 3.0
Это показано на диаграммах, представленных выше. Случайная составляющая зависимости, Y = 3.0
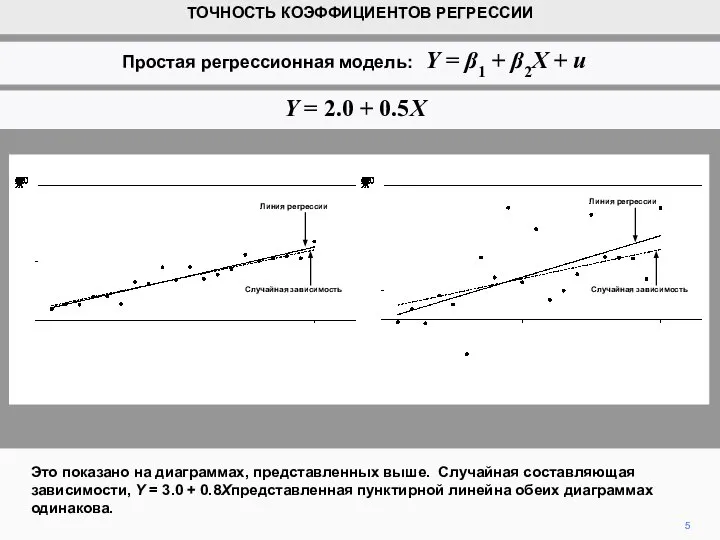
Слайд 6Значения Х одинаковы, и одинаковые случайные числа использовались для генерирования значений остаточного
Значения Х одинаковы, и одинаковые случайные числа использовались для генерирования значений остаточного
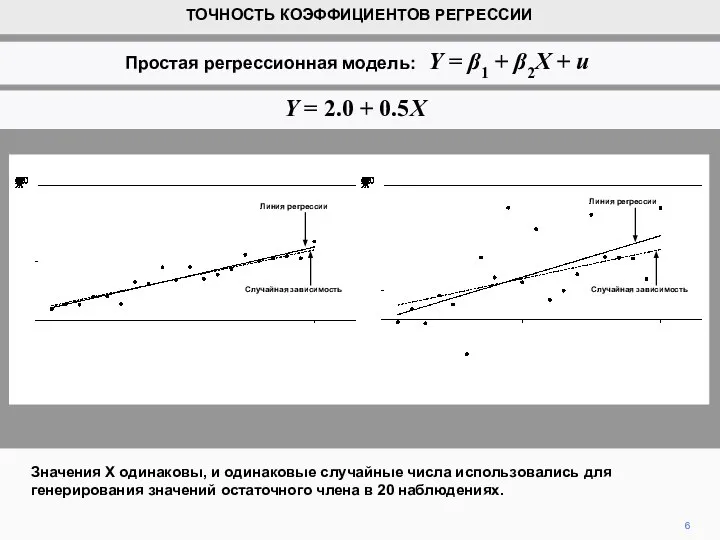
Слайд 7Однако, на правой диаграмме случайные числа умножались в 5 раз. Как следствие,
Однако, на правой диаграмме случайные числа умножались в 5 раз. Как следствие,
Слайд 8Посмотрим на знаменатель выражения для дисперсии b2Чем больше сумма квадратов отклонений X,
Посмотрим на знаменатель выражения для дисперсии b2Чем больше сумма квадратов отклонений X,

Слайд 9Однако, значение суммы квадратов отклонений зависит от двух факторов: количества наблюдений и
Однако, значение суммы квадратов отклонений зависит от двух факторов: количества наблюдений и

Слайд 10Из приведенного выражения видно, что дисперсия b2 обратно пропорциональна n, числу наблюдений
Из приведенного выражения видно, что дисперсия b2 обратно пропорциональна n, числу наблюдений

Слайд 1111
Третьим следствием выражения является то, что дисперсия обратно пропорциональна среднему квадратическому отклонению
11
Третьим следствием выражения является то, что дисперсия обратно пропорциональна среднему квадратическому отклонению

Слайд 12На вышеприведенных диаграммах линия случайной зависимости одинакова и для 20 значений наблюдений
На вышеприведенных диаграммах линия случайной зависимости одинакова и для 20 значений наблюдений
Слайд 13Однако, MSD (X) намного меньше на правой диаграмме, так как значения Х
Однако, MSD (X) намного меньше на правой диаграмме, так как значения Х
Слайд 14Следовательно, на этой диаграмме положение линии регрессии более чувствительно к значениям наблюдений
Следовательно, на этой диаграмме положение линии регрессии более чувствительно к значениям наблюдений
Слайд 15На рисунке показаны распределения оценок b2 для X = 1, 2, ...,
На рисунке показаны распределения оценок b2 для X = 1, 2, ...,
Слайд 16Это подтверждает, что распределение оценок, полученных с высокой дисперсией Х, имеет гораздо
Это подтверждает, что распределение оценок, полученных с высокой дисперсией Х, имеет гораздо
Слайд 17Конечно, как видно из выражений дисперсии, отношение MSD (X) к дисперсии u
Конечно, как видно из выражений дисперсии, отношение MSD (X) к дисперсии u

Слайд 1818
Мы не можем рассчитать теоретические дисперсии именно потому, что не знаем дисперсии
18
Мы не можем рассчитать теоретические дисперсии именно потому, что не знаем дисперсии

Слайд 1919
Очевидно, что разброс остатков относительно линии регрессии будет отражать неизвестный разброс u
19
Очевидно, что разброс остатков относительно линии регрессии будет отражать неизвестный разброс u

Слайд 2020
Одной из мер разброса остатков является их средняя квадратическая ошибка, MSD(e), которая
20
Одной из мер разброса остатков является их средняя квадратическая ошибка, MSD(e), которая

Слайд 2121
Прежде чем пойти дальше, задайте себе следующий вопрос: какая прямая вероятнее будет
21
Прежде чем пойти дальше, задайте себе следующий вопрос: какая прямая вероятнее будет

Слайд 2222
Ответ – линия регрессии, так как по определению она строится таким образом,
22
Ответ – линия регрессии, так как по определению она строится таким образом,

Слайд 2323
Следовательно, разброс остатков у нее меньше, чем разброс значений u, а MSD(e)
23
Следовательно, разброс остатков у нее меньше, чем разброс значений u, а MSD(e)

Слайд 2424
Действительно, можно показать, что математическое ожидание MSD(e), если имеется всего одна независимая
24
Действительно, можно показать, что математическое ожидание MSD(e), если имеется всего одна независимая

Слайд 2525
Однако отсюда следует, что мы можем получить несмещенную оценку σu2, умножив MSD(e)
25
Однако отсюда следует, что мы можем получить несмещенную оценку σu2, умножив MSD(e)

Слайд 2626
Затем мы можем получить оценки стандартных отклонений распределений b1 и b2, подставив
26
Затем мы можем получить оценки стандартных отклонений распределений b1 и b2, подставив

Слайд 2727
Они описываются как стандартные ошибки b1 и b2, «оценки среднеквадратических отклонений» являются
27
Они описываются как стандартные ошибки b1 и b2, «оценки среднеквадратических отклонений» являются

Слайд 2828
Стандартные ошибки коэффициентов всегда появляются как часть результата регрессии. Здесь представлена регрессия
28
Стандартные ошибки коэффициентов всегда появляются как часть результата регрессии. Здесь представлена регрессия
Слайд 29Теорема Гаусса-Маркова утверждает : при условии, что допущения модели регрессии действительны, оценки
Теорема Гаусса-Маркова утверждает : при условии, что допущения модели регрессии действительны, оценки
 Методы работы с источниками информации Неграмотным человеком завтрашнего дня будет не тот, кто не умеет читать, а тот, кто не научи
Методы работы с источниками информации Неграмотным человеком завтрашнего дня будет не тот, кто не умеет читать, а тот, кто не научи WHILE … WEND ЦИКЛ
WHILE … WEND ЦИКЛ NTPP. Общие факты
NTPP. Общие факты Онлайн-конструктора документов Октима
Онлайн-конструктора документов Октима Исследование подходов для аутентификации пользователей беспроводной сети с применением различных LDAP решений
Исследование подходов для аутентификации пользователей беспроводной сети с применением различных LDAP решений Основные свойства и структура системы
Основные свойства и структура системы Презентация на тему Системы счисления
Презентация на тему Системы счисления  Направления развития и итоги работы. Руководитель отдела системного администрирования МРЦ Волга-2
Направления развития и итоги работы. Руководитель отдела системного администрирования МРЦ Волга-2 Что такое программирование
Что такое программирование Теоретические и прикладные аспекты информационного противоборства в сети Интернет
Теоретические и прикладные аспекты информационного противоборства в сети Интернет Представление текстовой информации в ПК
Представление текстовой информации в ПК Устройства образующие типовой компьютер
Устройства образующие типовой компьютер Алгоритмы. Этапы решения задач на ЭВМ
Алгоритмы. Этапы решения задач на ЭВМ Презентация на тему ОС Windows. История её развития и применение
Презентация на тему ОС Windows. История её развития и применение  Образцы технических решений
Образцы технических решений Измерение информации
Измерение информации Работа с файловыми архивами
Работа с файловыми архивами Порядок предоставления в электронной форме услуги Государственная экспертиза проектной документации
Порядок предоставления в электронной форме услуги Государственная экспертиза проектной документации DH Standard AVN Update
DH Standard AVN Update Социальные медиа
Социальные медиа Доработка вёрстки страницы о товаре
Доработка вёрстки страницы о товаре Системное программное обеспечение
Системное программное обеспечение Потенциал инстаграм-проекта по совершенствованию навыков говорения итальяно-язычных студентов (РКИ, уровень А2))
Потенциал инстаграм-проекта по совершенствованию навыков говорения итальяно-язычных студентов (РКИ, уровень А2)) Библиотека и молодёжь
Библиотека и молодёжь Visual storytelling &data visualization best practices
Visual storytelling &data visualization best practices Системы программирования и прикладное программное обеспечение
Системы программирования и прикладное программное обеспечение Вычисление суммы первых n элементов знакочередующегося степенного ряда
Вычисление суммы первых n элементов знакочередующегося степенного ряда Компьютерные сети. Виды, структура, принципы функционирования
Компьютерные сети. Виды, структура, принципы функционирования