- Трудоёмкость алгоритмов

Содержание
- 2. ФПМИ БГУ Алгоритм это конечная последовательность чётко определенных, реализуемых компьютером инструкций, предназначенная для решения определенного класса
- 3. Определение Трудоёмкость алгоритма – это функция T(l), которая оценивает сверху время, требуемое для решения задачи. Возникают
- 4. В рамках нашей дисциплины мы будем работать с детерминированными алгоритмами. Детерминированный алгоритм Для одних и тех
- 5. Как подсчитать время работы детерминированного алгоритма ? Модель вычислительного устройства: Равнодоступная адресная машина (англ. Random-Access Machine
- 6. Равнодоступная адресная машина представляет собой вычислительную машину с одним сумматором, в котором команды программы не могут
- 7. Элементарный шаг вычисления: Если в качестве модели вычислений взять неветвящуюся программу и предположить, что алгоритм –
- 8. ФПМИ БГУ На практике …. Программы, написанные на языках высокого уровня, нужно переводить в машинный код.
- 9. На практике …. Даже имея готовый ассемблерный код реализации алгоритма, не представляется возможным узнать, какое время
- 10. ФПМИ БГУ Если вы пишете на C ++ и решаете типичную алгоритмическую задачу, то можете предположить,
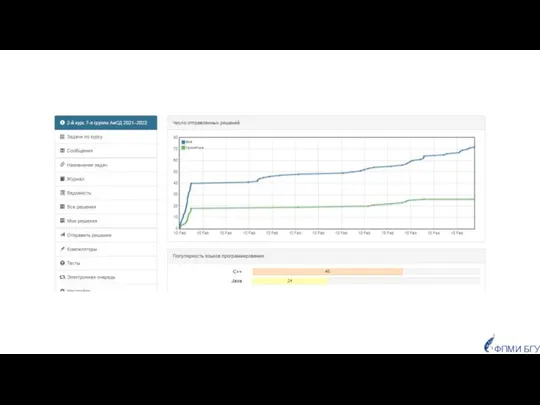
- 11. ФПМИ БГУ Популярность языков программирования у студентов
- 12. ФПМИ БГУ
- 13. ФПМИ БГУ
- 14. ФПМИ БГУ
- 15. ФПМИ БГУ
- 16. ФПМИ БГУ
- 17. ФПМИ БГУ 2022 год
- 18. ФПМИ БГУ
- 19. ФПМИ БГУ
- 20. ФПМИ БГУ
- 21. ФПМИ БГУ
- 22. Для оценки времени работы детерминированного алгоритма в худшем случае будем искать такой набор входных данных, на
- 23. Среднее время работы детерминированного алгоритма по всем возможным наборам входных данных Все входные данные разбиваем на
- 24. Пример. Задан массив из n уникальных элементов и некоторое число x. Необходимо определить есть ли число
- 25. А как же подсчитать время работы рандомизированного алгоритма в худшем случае? данные 1 1-й запуск алгоритма
- 26. Функции можно сгруппировать по скорости роста в три основных класса (три асимптотики): о большое от f
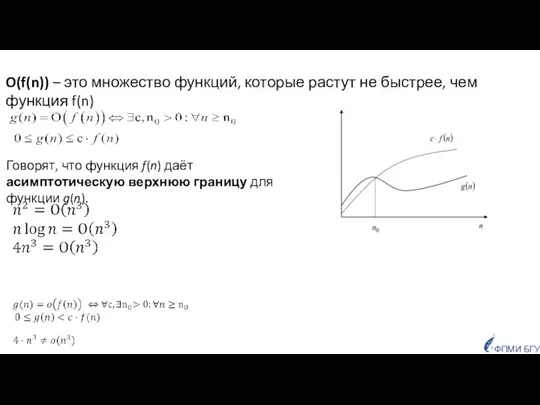
- 27. O(f(n)) – это множество функций, которые растут не быстрее, чем функция f(n) Говорят, что функция f(n)
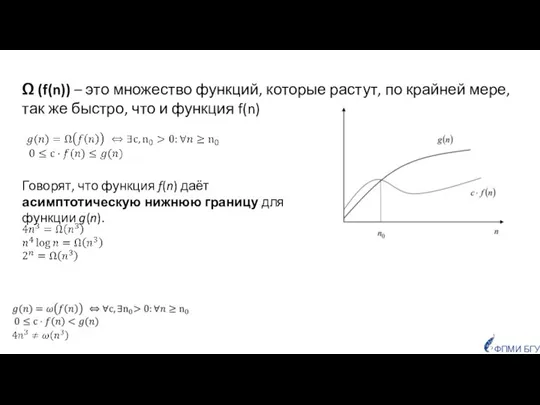
- 28. Ω (f(n)) – это множество функций, которые растут, по крайней мере, так же быстро, что и
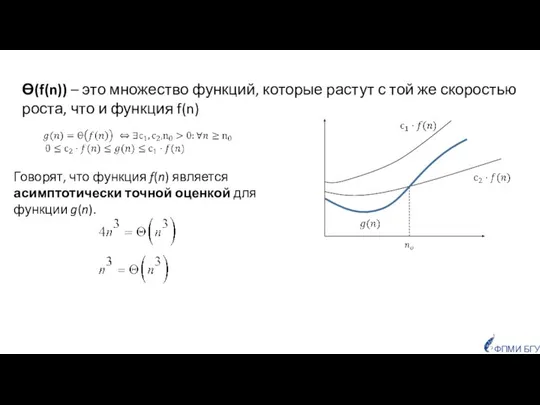
- 29. Ө(f(n)) – это множество функций, которые растут с той же скоростью роста, что и функция f(n)
- 30. f(n) даёт асимптотическую верхнюю границу для функции g(n) f(n) даёт асимптотическую нижнюю границу для функции g(n)
- 31. ФПМИ БГУ Скрытые под асимптотикой константы … Доказательство Константы можно выбрать и по-другому, однако важно не
- 32. ФПМИ БГУ
- 33. ФПМИ БГУ
- 34. ФПМИ БГУ
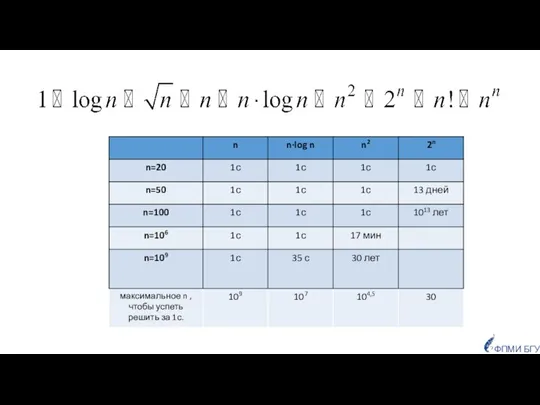
- 35. 1. Время последовательного поиска элемента x в произвольном массиве из n элементов? 3. Время построения бинарного
- 36. Трудоёмкость алгоритма – это функция T(l), которая оценивает сверху время, требуемое для решения задачи. Для того,
- 37. ФПМИ БГУ
- 38. ФПМИ БГУ Логарифмируем и, учитывая, что число бит является целым числом, получаем
- 39. ФПМИ БГУ Логарифмируем и, учитывая, что число бит является целым числом, получаем
- 40. ФПМИ БГУ Логарифмируем и, учитывая, что число бит является целым числом, получаем
- 41. ФПМИ БГУ
- 42. ФПМИ БГУ Решение Найдём множество возможных входных данных где входным числом будем считать Тогда
- 43. Решение ФПМИ БГУ
- 44. Оценка трудоёмкости алгоритма Сформулировали задачу и описали алгоритм её решения. Вычислили время работы алгоритма (в худшем
- 45. Сведения из математики ФПМИ БГУ Алгоритм называется полиномиальным, если его трудоемкость
- 46. Размерность задачи Время работы алгоритма Трудоёмкость ФПМИ БГУ Будем предполагать, что в результате суммирования не произойдёт
- 47. Сведения из математики 1) Экспоненциальная функция это функция: 2) Любая экспоненциальная функция возрастает быстрее полиномиальной функции.
- 48. ФПМИ БГУ Размерность задачи Время работы алгоритма Трудоёмкость биты
- 49. ФПМИ БГУ
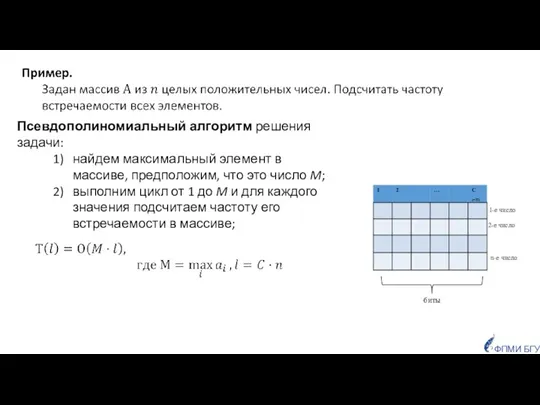
- 50. ФПМИ БГУ 1-е число 2-е число n-е число биты Псевдополиномиальный алгоритм решения задачи: найдем максимальный элемент
- 51. ФПМИ БГУ Для задач, имеющих числовые параметры, псевдополиномиальные алгоритмы на практике ведут себя как экспоненциальные только
- 52. ФПМИ БГУ
- 53. ФПМИ БГУ
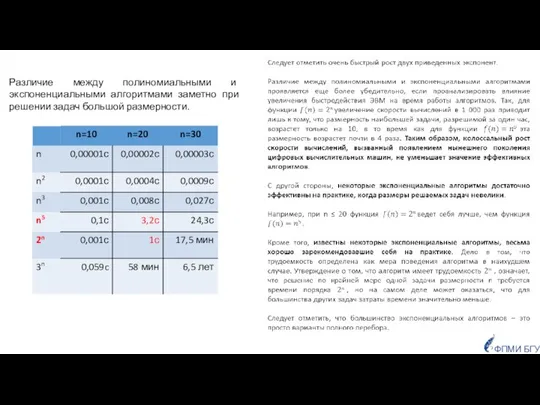
- 54. Различие между полиномиальными и экспоненциальными алгоритмами заметно при решении задач большой размерности. ФПМИ БГУ
- 55. ФПМИ БГУ Размерность задачи биты число n полиномиальный или экспоненциальный? полиномиальный или экспоненциальный?
- 57. Скачать презентацию
Слайд 2ФПМИ БГУ
Алгоритм
это конечная последовательность чётко определенных, реализуемых компьютером инструкций, предназначенная для решения
ФПМИ БГУ
Алгоритм
это конечная последовательность чётко определенных, реализуемых компьютером инструкций, предназначенная для решения

Слайд 3Определение
Трудоёмкость алгоритма – это функция T(l), которая оценивает сверху время, требуемое для
Определение
Трудоёмкость алгоритма – это функция T(l), которая оценивает сверху время, требуемое для

Слайд 4В рамках нашей дисциплины мы будем работать с детерминированными алгоритмами.
Детерминированный алгоритм
Для одних
В рамках нашей дисциплины мы будем работать с детерминированными алгоритмами.
Детерминированный алгоритм
Для одних

Слайд 5Как подсчитать время работы детерминированного алгоритма ?
Модель вычислительного устройства:
Равнодоступная адресная машина (англ.
Как подсчитать время работы детерминированного алгоритма ?
Модель вычислительного устройства:
Равнодоступная адресная машина (англ.

Слайд 6Равнодоступная адресная машина представляет собой вычислительную машину с одним сумматором, в котором
Равнодоступная адресная машина представляет собой вычислительную машину с одним сумматором, в котором

Слайд 7Элементарный шаг вычисления:
Если в качестве модели вычислений взять неветвящуюся программу и предположить,
Элементарный шаг вычисления:
Если в качестве модели вычислений взять неветвящуюся программу и предположить,

Слайд 8ФПМИ БГУ
На практике ….
Программы, написанные на языках высокого уровня, нужно переводить в
ФПМИ БГУ
На практике ….
Программы, написанные на языках высокого уровня, нужно переводить в

Слайд 9На практике ….
Даже имея готовый ассемблерный код реализации алгоритма, не представляется возможным
На практике ….
Даже имея готовый ассемблерный код реализации алгоритма, не представляется возможным

Слайд 10ФПМИ БГУ
Если вы пишете на C ++ и решаете типичную алгоритмическую задачу,
ФПМИ БГУ
Если вы пишете на C ++ и решаете типичную алгоритмическую задачу,

Слайд 11ФПМИ БГУ
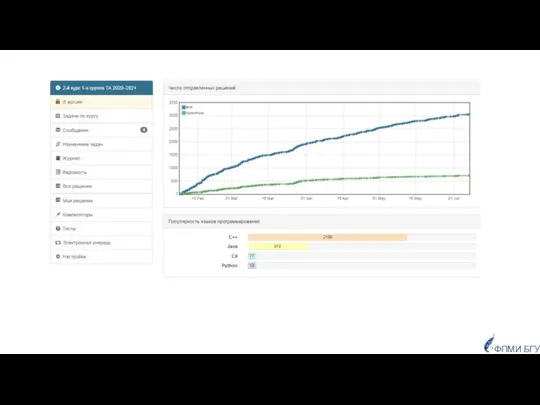
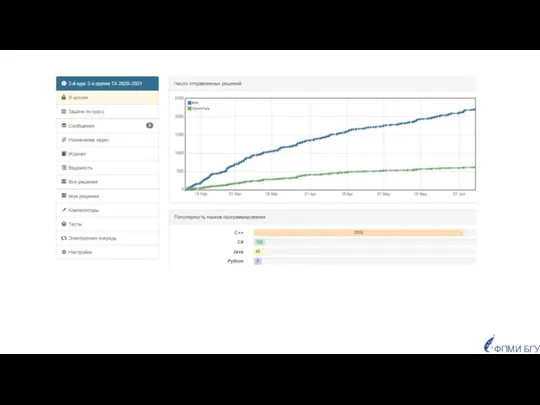
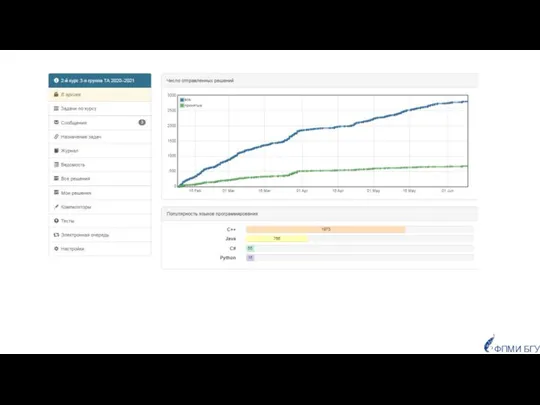
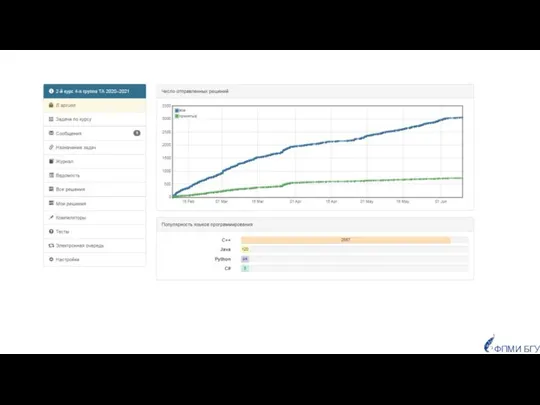
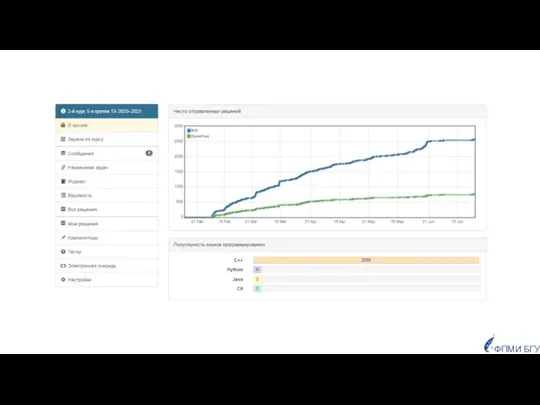
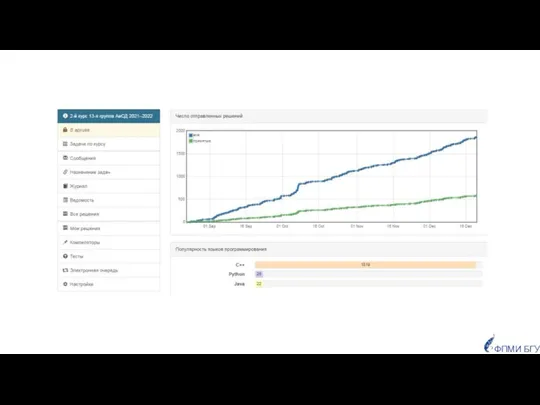
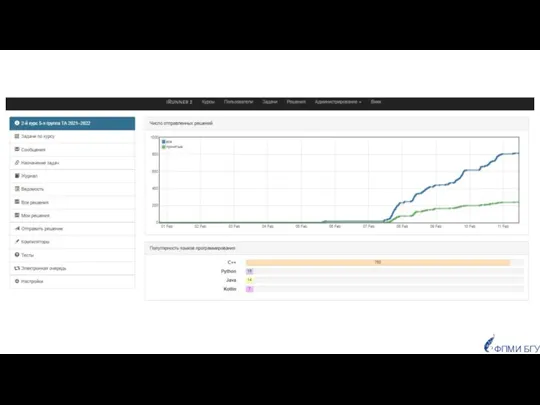
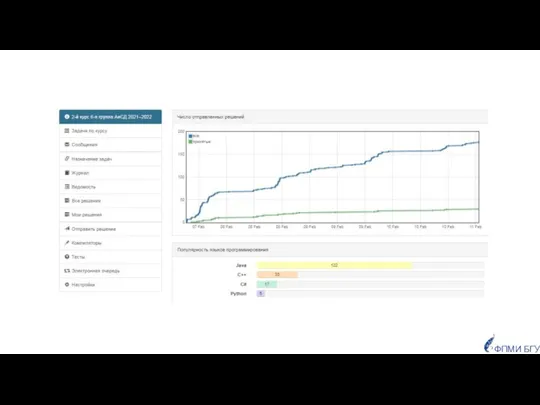
Популярность языков программирования
у студентов
ФПМИ БГУ
Популярность языков программирования
у студентов

Слайд 12ФПМИ БГУ
ФПМИ БГУ
Слайд 13ФПМИ БГУ
ФПМИ БГУ
Слайд 14ФПМИ БГУ
ФПМИ БГУ
Слайд 15ФПМИ БГУ
ФПМИ БГУ
Слайд 16ФПМИ БГУ
ФПМИ БГУ
Слайд 17ФПМИ БГУ
2022 год
ФПМИ БГУ
2022 год

Слайд 18ФПМИ БГУ
ФПМИ БГУ
Слайд 19ФПМИ БГУ
ФПМИ БГУ
Слайд 20ФПМИ БГУ
ФПМИ БГУ
Слайд 21ФПМИ БГУ
ФПМИ БГУ
Слайд 22Для оценки времени работы детерминированного алгоритма в худшем случае будем искать такой
Для оценки времени работы детерминированного алгоритма в худшем случае будем искать такой

Слайд 23Среднее время работы детерминированного алгоритма
по всем возможным наборам входных данных
Все входные
Среднее время работы детерминированного алгоритма
по всем возможным наборам входных данных
Все входные

Слайд 24Пример.
Задан массив из n уникальных элементов и некоторое число x.
Необходимо определить
Пример.
Задан массив из n уникальных элементов и некоторое число x.
Необходимо определить

Слайд 25А как же подсчитать время работы рандомизированного алгоритма в худшем случае?
данные 1
1-й
А как же подсчитать время работы рандомизированного алгоритма в худшем случае?
данные 1
1-й

Слайд 26Функции можно сгруппировать по скорости роста в три основных класса (три асимптотики):
о
Функции можно сгруппировать по скорости роста в три основных класса (три асимптотики):
о

Слайд 27O(f(n)) – это множество функций, которые растут не быстрее, чем функция f(n)
Говорят,
O(f(n)) – это множество функций, которые растут не быстрее, чем функция f(n)
Говорят,
Слайд 28Ω (f(n)) – это множество функций, которые растут, по крайней мере, так
Ω (f(n)) – это множество функций, которые растут, по крайней мере, так
Слайд 29Ө(f(n)) – это множество функций, которые растут с той же скоростью роста,
Ө(f(n)) – это множество функций, которые растут с той же скоростью роста,
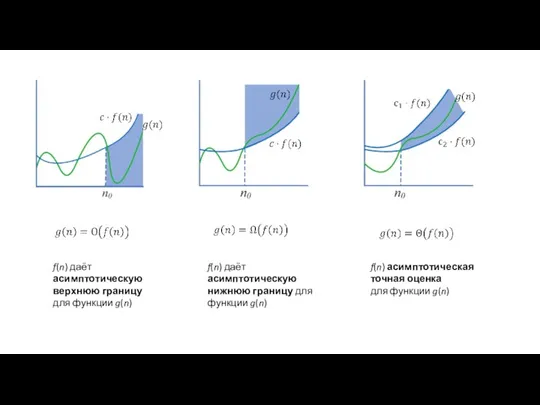
Слайд 30f(n) даёт асимптотическую верхнюю границу
для функции g(n)
f(n) даёт асимптотическую нижнюю границу
f(n) даёт асимптотическую верхнюю границу
для функции g(n)
f(n) даёт асимптотическую нижнюю границу
Слайд 31ФПМИ БГУ
Скрытые под асимптотикой константы …
Доказательство
Константы можно выбрать и по-другому, однако важно
ФПМИ БГУ
Скрытые под асимптотикой константы …
Доказательство
Константы можно выбрать и по-другому, однако важно

Слайд 32ФПМИ БГУ
ФПМИ БГУ

Слайд 33ФПМИ БГУ
ФПМИ БГУ

Слайд 34ФПМИ БГУ
ФПМИ БГУ
Слайд 351. Время последовательного поиска элемента x в произвольном массиве из n элементов?
1. Время последовательного поиска элемента x в произвольном массиве из n элементов?

Слайд 36Трудоёмкость алгоритма –
это функция T(l), которая оценивает сверху время, требуемое для
Трудоёмкость алгоритма –
это функция T(l), которая оценивает сверху время, требуемое для

Слайд 37
ФПМИ БГУ
ФПМИ БГУ

Слайд 38
ФПМИ БГУ
Логарифмируем и, учитывая, что число бит является целым числом, получаем
ФПМИ БГУ
Логарифмируем и, учитывая, что число бит является целым числом, получаем

Слайд 39
ФПМИ БГУ
Логарифмируем и, учитывая, что число бит является целым числом, получаем
ФПМИ БГУ
Логарифмируем и, учитывая, что число бит является целым числом, получаем

Слайд 40
ФПМИ БГУ
Логарифмируем и, учитывая, что число бит является целым числом, получаем
ФПМИ БГУ
Логарифмируем и, учитывая, что число бит является целым числом, получаем

Слайд 41
ФПМИ БГУ
ФПМИ БГУ

Слайд 42
ФПМИ БГУ
Решение
Найдём множество возможных входных данных
где входным числом будем считать
Тогда
ФПМИ БГУ
Решение
Найдём множество возможных входных данных
где входным числом будем считать
Тогда

Слайд 43Решение
ФПМИ БГУ
Решение
ФПМИ БГУ

Слайд 44Оценка трудоёмкости алгоритма
Сформулировали задачу и описали алгоритм её решения.
Вычислили время работы алгоритма
Оценка трудоёмкости алгоритма
Сформулировали задачу и описали алгоритм её решения.
Вычислили время работы алгоритма

Слайд 45
Сведения из математики
ФПМИ БГУ
Алгоритм называется полиномиальным, если его трудоемкость
Сведения из математики
ФПМИ БГУ
Алгоритм называется полиномиальным, если его трудоемкость

Слайд 46Размерность задачи
Время работы алгоритма
Трудоёмкость
ФПМИ БГУ
Будем предполагать, что в результате суммирования не произойдёт
Размерность задачи
Время работы алгоритма
Трудоёмкость
ФПМИ БГУ
Будем предполагать, что в результате суммирования не произойдёт

Слайд 47
Сведения из математики
1) Экспоненциальная функция это функция:
2) Любая экспоненциальная функция возрастает быстрее
Сведения из математики
1) Экспоненциальная функция это функция:
2) Любая экспоненциальная функция возрастает быстрее

Слайд 48
ФПМИ БГУ
Размерность задачи
Время работы алгоритма
Трудоёмкость
биты
ФПМИ БГУ
Размерность задачи
Время работы алгоритма
Трудоёмкость
биты

Слайд 49
ФПМИ БГУ
ФПМИ БГУ

Слайд 50ФПМИ БГУ
1-е число
2-е число
n-е число
биты
Псевдополиномиальный алгоритм решения задачи:
найдем максимальный элемент в
ФПМИ БГУ
1-е число
2-е число
n-е число
биты
Псевдополиномиальный алгоритм решения задачи:
найдем максимальный элемент в
Слайд 51ФПМИ БГУ
Для задач, имеющих числовые параметры, псевдополиномиальные алгоритмы на практике ведут себя
ФПМИ БГУ
Для задач, имеющих числовые параметры, псевдополиномиальные алгоритмы на практике ведут себя

Слайд 52ФПМИ БГУ
ФПМИ БГУ

Слайд 53ФПМИ БГУ
ФПМИ БГУ

Слайд 54Различие между полиномиальными и экспоненциальными алгоритмами заметно при решении задач большой размерности.
ФПМИ
Различие между полиномиальными и экспоненциальными алгоритмами заметно при решении задач большой размерности.
ФПМИ
Слайд 55
ФПМИ БГУ
Размерность задачи
биты
число n
полиномиальный или экспоненциальный?
полиномиальный или экспоненциальный?
ФПМИ БГУ
Размерность задачи
биты
число n
полиномиальный или экспоненциальный?
полиномиальный или экспоненциальный?

 Продвижение Новопятницкой сельской библиотеки в социальных сетях
Продвижение Новопятницкой сельской библиотеки в социальных сетях Tabular information
Tabular information теги HTML
теги HTML Предзаказ
Предзаказ Задание 3. Снегопад
Задание 3. Снегопад Игра Hero's Tanks на Scratch
Игра Hero's Tanks на Scratch App inventor. Bluetooth: передача данных
App inventor. Bluetooth: передача данных Фирма Позитив
Фирма Позитив VRProject VRGame
VRProject VRGame Подготовка к зачету
Подготовка к зачету Жанры журналистики
Жанры журналистики PnP Perspective-n-Point. Восстановление точек в 3D-пространстве по их перспективной проекции на плоскость сенсора камеры
PnP Perspective-n-Point. Восстановление точек в 3D-пространстве по их перспективной проекции на плоскость сенсора камеры Функции в Excel
Функции в Excel Методы формирования информационной компетенции на уроках физики
Методы формирования информационной компетенции на уроках физики Стимулирование развития инноваций
Стимулирование развития инноваций Основы построения моделирующего алгоритма в среде GPSS World
Основы построения моделирующего алгоритма в среде GPSS World Планета алгоритмика. Клад
Планета алгоритмика. Клад Countdown 4 Poster Scheme
Countdown 4 Poster Scheme Manual Sops Editor
Manual Sops Editor Форматирование строк
Форматирование строк 1240031 (2)
1240031 (2) Data PowerPoint
Data PowerPoint Битрикс — фреймворк?
Битрикс — фреймворк? Daemon Tools Lite
Daemon Tools Lite Анализ группы анимешников
Анализ группы анимешников PHP. Разработка блога
PHP. Разработка блога Текстовый редактор MS Word: создание и редактирование формул. 8 класс
Текстовый редактор MS Word: создание и редактирование формул. 8 класс Знаковые модели моделирование и формализация
Знаковые модели моделирование и формализация