- Urok_14_PR4_Predstavlenie_texta

Содержание
- 2. Представление данных и программ в компьютере Итак, чтобы компьютер мог воспринять и обработать числовые значения, текст,
- 3. в памяти – ? Кодирование текста на экране – символы двоичные коды
- 4. Вспомним n – информационный вес символа – количество бит в двоичном коде. N – мощность алфавита
- 5. Кодовые таблицы Для представления текстовых данных в компьютерах используют так называемые кодовые таблицы – наборы кодов
- 6. Кодовая таблица ASCII ASCII (англ. American standard code for information interchange, [’æs.ki]) — самая популярная кодовая
- 7. Первая половина таблицы ASCII
- 8. Вторая половина таблицы ASCII
- 9. Проблема ASCII Исторически сложилось, что в 8-битовых кодировках ASCII первую половину кодовой таблицы (0—127) занимают всегда
- 10. Кириллица в ASCII К сожалению, в настоящее время существуют много различных кодовых таблиц для кириллицы в
- 11. Разные кодировки кириллицы Одним из первых стандартов кодирования русских букв был КОИ8 ("Код обмена информацией, 8-битный").
- 12. Unicode С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется
- 13. Развитие Unicode И 65 536 символов становится недостаточно. Консорциум Unicode, который разрабатывает стандарт Unicode, реализовал кодировки
- 14. Различные кодировки Unicode Unicode – это теперь не кодировка, а набор символов, которым ведает всемирная организация
- 15. UTF-8 UTF-8 (от англ. Unicode Transformation Format — «формат преобразования Юникода, 8-битный») — одна из общепринятых
- 16. UTF-16 UTF-16 (от англ. Unicode Transformation Format — «формат преобразования Юникода, 16-битный») — это кодировка символов
- 17. Задание 1. Скачайте и откройте файл ПР4.xlsx. 3. Напишите в файле свои Фамилия, Имя и Отчество
- 19. Скачать презентацию
Слайд 2Представление данных и программ в компьютере
Итак, чтобы компьютер мог воспринять и обработать
Представление данных и программ в компьютере
Итак, чтобы компьютер мог воспринять и обработать
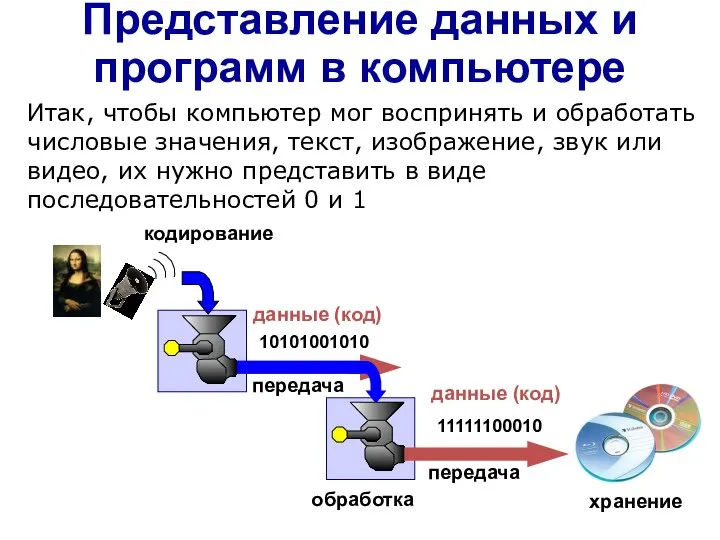
Слайд 3в памяти – ?
Кодирование текста
на экране – символы
двоичные коды
в памяти – ?
Кодирование текста
на экране – символы
двоичные коды

Слайд 4Вспомним
n – информационный вес символа – количество бит в двоичном коде.
N –
Вспомним
n – информационный вес символа – количество бит в двоичном коде.
N –

Слайд 5Кодовые таблицы
Для представления текстовых данных в компьютерах используют так называемые кодовые таблицы
Кодовые таблицы
Для представления текстовых данных в компьютерах используют так называемые кодовые таблицы

Слайд 6Кодовая таблица ASCII
ASCII (англ. American standard code for information interchange, [’æs.ki]) —
Кодовая таблица ASCII
ASCII (англ. American standard code for information interchange, [’æs.ki]) —
![Кодовая таблица ASCII ASCII (англ. American standard code for information interchange, [’æs.ki])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1175946/slide-5.jpg)
Слайд 7Первая половина таблицы ASCII
Первая половина таблицы ASCII
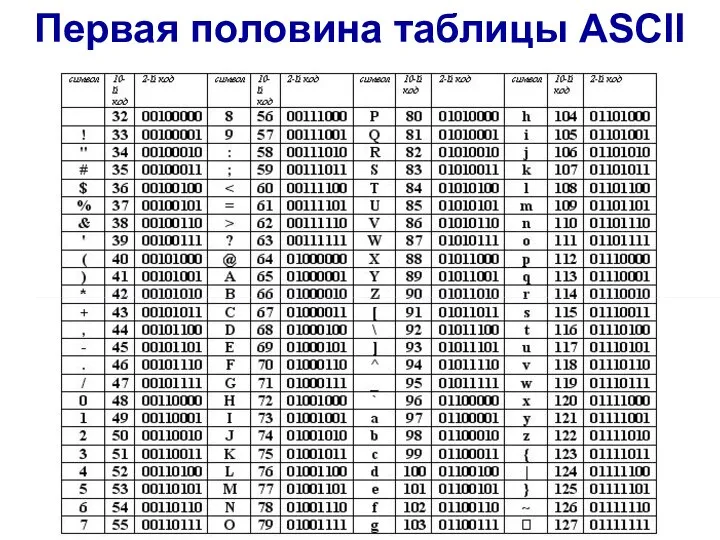
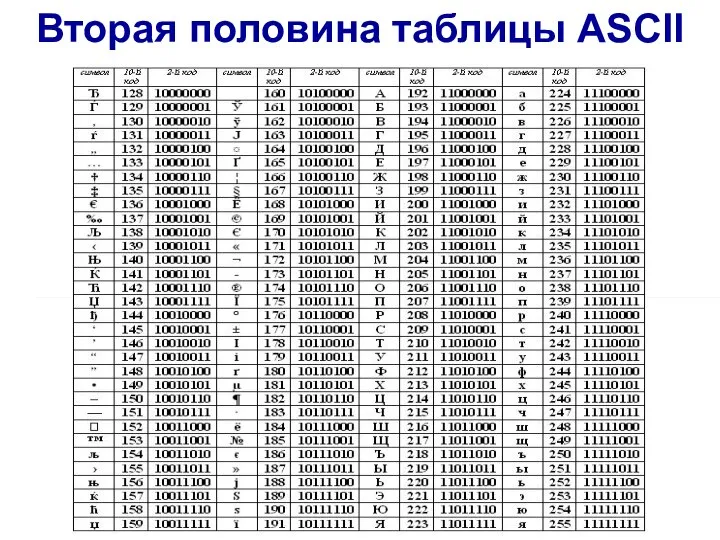
Слайд 8Вторая половина таблицы ASCII
Вторая половина таблицы ASCII
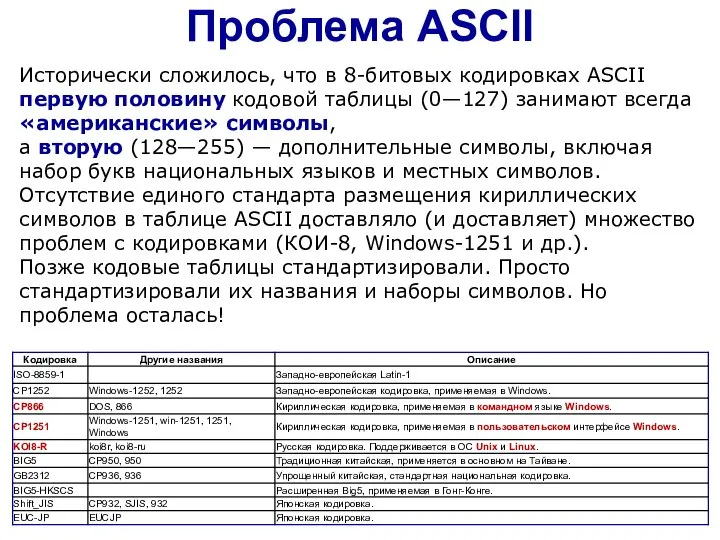
Слайд 9Проблема ASCII
Исторически сложилось, что в 8-битовых кодировках ASCII первую половину кодовой таблицы
Проблема ASCII
Исторически сложилось, что в 8-битовых кодировках ASCII первую половину кодовой таблицы
Слайд 10Кириллица в ASCII
К сожалению, в настоящее время существуют много различных кодовых таблиц
Кириллица в ASCII
К сожалению, в настоящее время существуют много различных кодовых таблиц

Слайд 11Разные кодировки кириллицы
Одним из первых стандартов кодирования русских букв был КОИ8 ("Код
Разные кодировки кириллицы
Одним из первых стандартов кодирования русских букв был КОИ8 ("Код

Слайд 12Unicode
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного
Unicode
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного

Слайд 13Развитие Unicode
И 65 536 символов становится недостаточно.
Консорциум Unicode, который разрабатывает стандарт
Развитие Unicode
И 65 536 символов становится недостаточно.
Консорциум Unicode, который разрабатывает стандарт

Слайд 14Различные кодировки Unicode
Unicode – это теперь не кодировка, а набор символов, которым
Различные кодировки Unicode
Unicode – это теперь не кодировка, а набор символов, которым

Слайд 15UTF-8
UTF-8 (от англ. Unicode Transformation Format — «формат преобразования Юникода, 8-битный») —
UTF-8
UTF-8 (от англ. Unicode Transformation Format — «формат преобразования Юникода, 8-битный») —

Слайд 16UTF-16
UTF-16 (от англ. Unicode Transformation Format — «формат преобразования Юникода, 16-битный») —
UTF-16
UTF-16 (от англ. Unicode Transformation Format — «формат преобразования Юникода, 16-битный») —

Слайд 17Задание
1. Скачайте и откройте файл ПР4.xlsx.
3. Напишите в файле свои Фамилия, Имя
Задание
1. Скачайте и откройте файл ПР4.xlsx.
3. Напишите в файле свои Фамилия, Имя

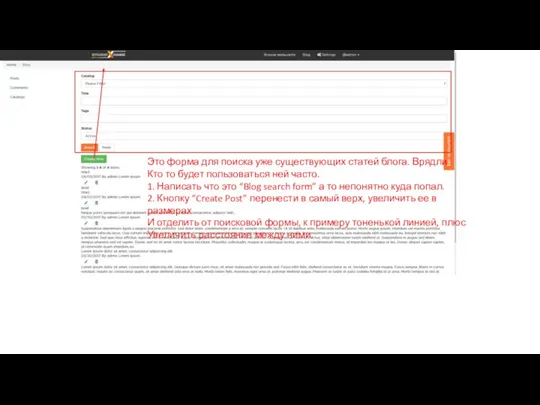 Форма для поиска уже существующих статей блога “Blog search form”
Форма для поиска уже существующих статей блога “Blog search form” Продвижение в социальных сетях
Продвижение в социальных сетях Основы комплексной системы защиты информации
Основы комплексной системы защиты информации Проверка кандидата
Проверка кандидата Welcome to Hell - оffice
Welcome to Hell - оffice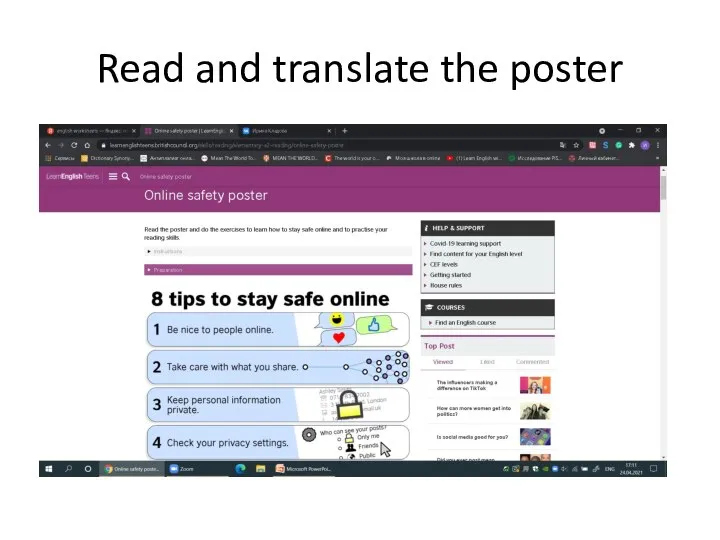 Read and translate the poster
Read and translate the poster Как создать конференцию в ZOOM
Как создать конференцию в ZOOM Всё есть число. Пифагорийцы
Всё есть число. Пифагорийцы Логические основы компьютера
Логические основы компьютера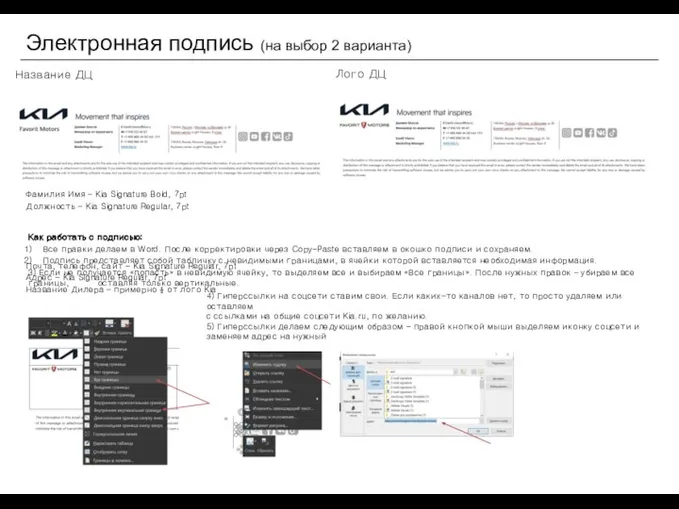 Kia how to электронная подпись
Kia how to электронная подпись Одномерные массивы: задачи сортировок элементов массива. Лекция 7
Одномерные массивы: задачи сортировок элементов массива. Лекция 7 Кибербезопасность. Прекрасный, опасный, кибербезопасный мир
Кибербезопасность. Прекрасный, опасный, кибербезопасный мир Windows 11 – операционная система 2021
Windows 11 – операционная система 2021 Компьютерные Вирусы
Компьютерные Вирусы Мир информатики
Мир информатики Базы данных ка модель предметной области
Базы данных ка модель предметной области Mein Lieblingsautor ist Stan Lee
Mein Lieblingsautor ist Stan Lee Массивы в Javascript
Массивы в Javascript Машинное обучение на языке программирования Python
Машинное обучение на языке программирования Python Условия. Ветвление алгоритма. Конструкция логического выбора if
Условия. Ветвление алгоритма. Конструкция логического выбора if Печатать ПРЕЗЕНТАЦИЯ
Печатать ПРЕЗЕНТАЦИЯ Библиотека села Ныр
Библиотека села Ныр Работа с файлами (ввод и вывод)
Работа с файлами (ввод и вывод) Основные понятия реляционной БД
Основные понятия реляционной БД Изучение функционирования системы
Изучение функционирования системы Формирование интерфейса проекта
Формирование интерфейса проекта Компьютерное моделирование/ Геофизика
Компьютерное моделирование/ Геофизика “Правда или действие”. Игра
“Правда или действие”. Игра