Основная терминология курса: шейдер, SM, ROP, TPC, SP. Типы параллельных архитектур: SISD, MISD, SIMD, MIMD, DSP
- Основная терминология курса: шейдер, SM, ROP, TPC, SP. Типы параллельных архитектур: SISD, MISD, SIMD, MIMD, DSP

Содержание
- 2. Введение Схематическое изображение графического адаптера Классификация вычислительных систем по Флинну Схематическое устройство SMP Multithreading Bottleneck
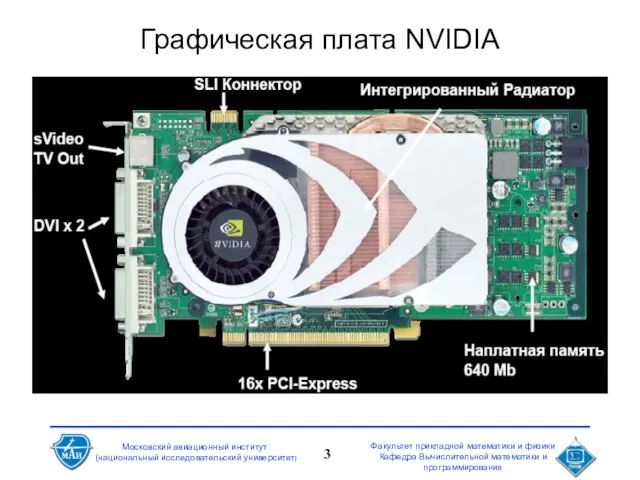
- 3. Графическая плата NVIDIA
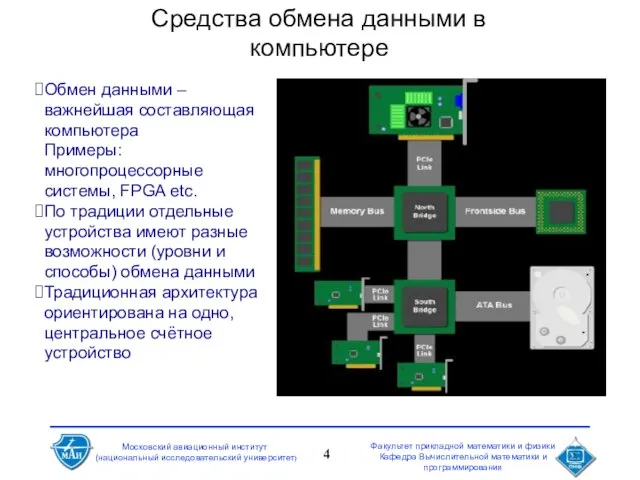
- 4. Средства обмена данными в компьютере Обмен данными – важнейшая составляющая компьютера Примеры: многопроцессорные системы, FPGA etc.
- 5. Программная часть технологии CUDA Введем основные термины и отношения между ними [CUDA C Best Practices, 2010].
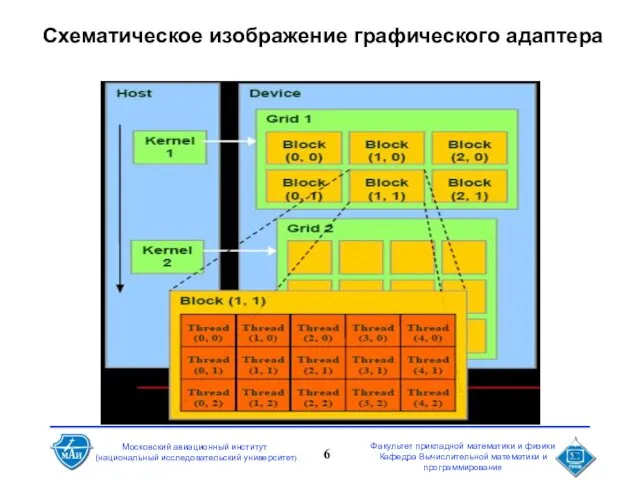
- 6. Схематическое изображение графического адаптера
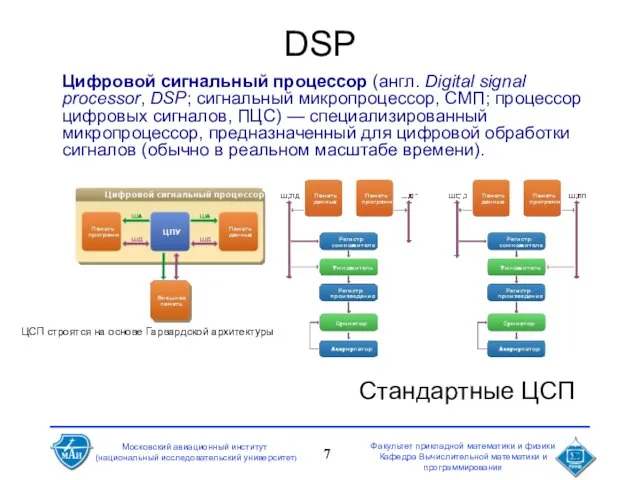
- 7. DSP Цифровой сигнальный процессор (англ. Digital signal processor, DSP; сигнальный микропроцессор, СМП; процессор цифровых сигналов, ПЦС)
- 9. Схематическое изображение устройства графического адаптера
- 10. Схематические особенности видеочипа
- 11. Схематическое расположение блоков GPU
- 12. Графический адаптер на «аппаратном» уровне TPC (Texture process cluster) ROP — Raster Operations Pipeline SP (Streaming
- 13. Классификация вычислительных систем по Флинну
- 14. Классы систем
- 15. Классификация систем CPU – SISD Multithreading: позволяет запускать множество потоков – параллелизм на уровне задач (MIMD)
- 16. SIMT (Single instruction, multiple threads) Параллельно на каждом SM выполняется большое число отдельных нитей (threads) Нити
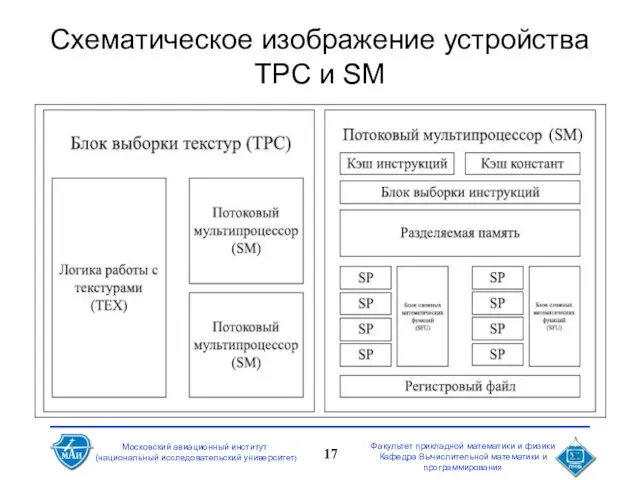
- 17. Схематическое изображение устройства TPC и SM
- 18. Symmetric Multiprocessor Architecture (SMP) Каждый процессор имеет свои L1 и L2 кэши подсоединен к общей шине
- 19. Symmetric Multiprocessor Architecture (SMP)
- 20. Программная модель CUDA Параллельная часть кода выполняется как большое количество нитей (threads) Нити группируются в блоки
- 21. Что такое ВОРП (WARP)? Device делает 1 grid в любой момент SM обрабатывает 1 или более
- 22. Итоги лекции В результате лекции Вы должны : Понимать возможности использования GPU для расчётов с точки
- 24. Скачать презентацию
Слайд 2Введение
Схематическое изображение графического адаптера
Классификация вычислительных систем по Флинну
Схематическое устройство
Введение
Схематическое изображение графического адаптера
Классификация вычислительных систем по Флинну
Схематическое устройство

Слайд 3Графическая плата NVIDIA
Графическая плата NVIDIA
Слайд 4Средства обмена данными в
компьютере
Обмен данными – важнейшая составляющая компьютера
Примеры: многопроцессорные системы, FPGA
Средства обмена данными в
компьютере
Обмен данными – важнейшая составляющая компьютера
Примеры: многопроцессорные системы, FPGA
Слайд 5Программная часть технологии CUDA
Введем основные термины и отношения между ними [CUDA C
Программная часть технологии CUDA
Введем основные термины и отношения между ними [CUDA C

Слайд 6Схематическое изображение графического адаптера
Схематическое изображение графического адаптера
Слайд 7DSP
Цифровой сигнальный процессор (англ. Digital signal processor, DSP; сигнальный микропроцессор, СМП; процессор цифровых
DSP
Цифровой сигнальный процессор (англ. Digital signal processor, DSP; сигнальный микропроцессор, СМП; процессор цифровых

Слайд 9Схематическое изображение устройства графического адаптера
Схематическое изображение устройства графического адаптера
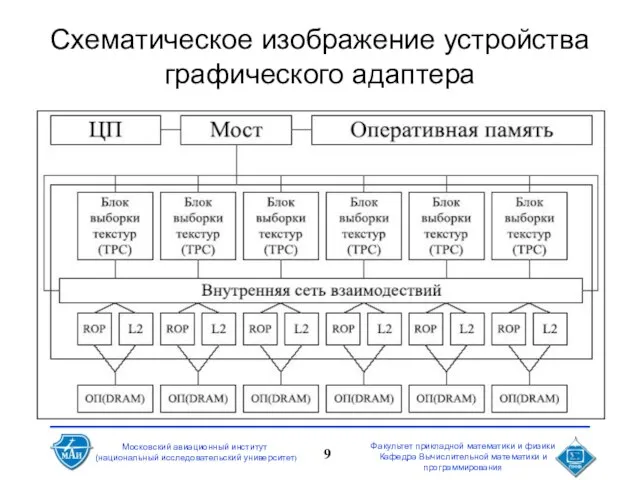
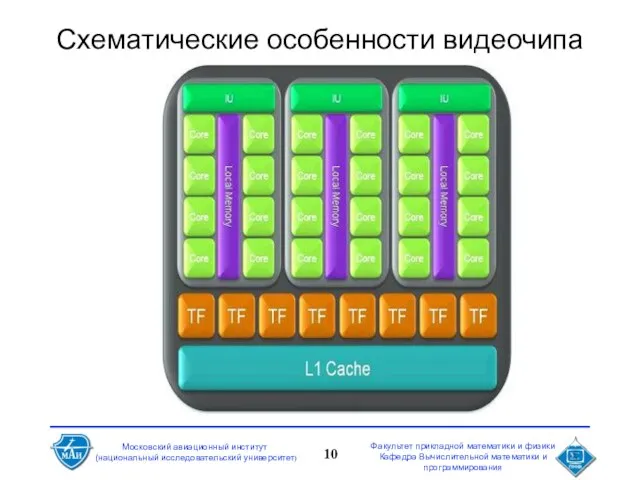
Слайд 10Схематические особенности видеочипа
Схематические особенности видеочипа
Слайд 11Схематическое расположение блоков GPU
Схематическое расположение блоков GPU
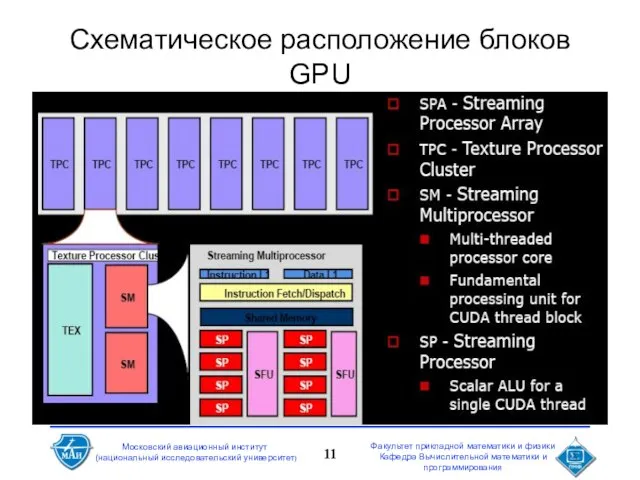
Слайд 12Графический адаптер на «аппаратном» уровне
TPC (Texture process cluster)
ROP — Raster Operations Pipeline
SP
Графический адаптер на «аппаратном» уровне
TPC (Texture process cluster)
ROP — Raster Operations Pipeline
SP

Слайд 13Классификация вычислительных систем по Флинну
Классификация вычислительных систем по Флинну
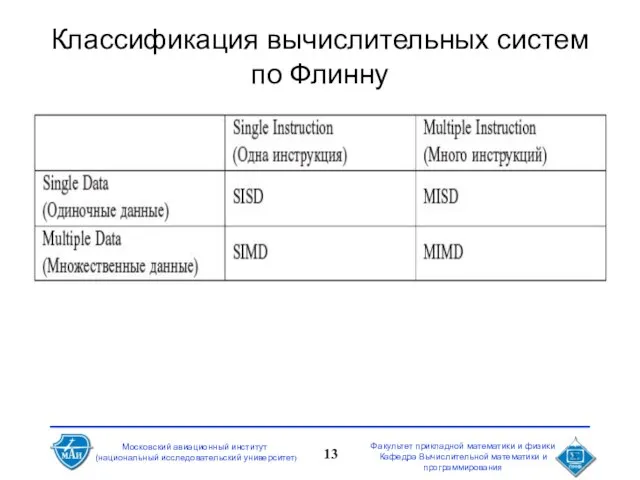
Слайд 14Классы систем
Классы систем

Слайд 15Классификация систем
CPU – SISD
Multithreading: позволяет запускать множество потоков – параллелизм на уровне
Классификация систем
CPU – SISD
Multithreading: позволяет запускать множество потоков – параллелизм на уровне

Слайд 16SIMT (Single instruction, multiple threads)
Параллельно на каждом SM выполняется большое число отдельных
SIMT (Single instruction, multiple threads)
Параллельно на каждом SM выполняется большое число отдельных

Слайд 17Схематическое изображение устройства TPC и SM
Схематическое изображение устройства TPC и SM
Слайд 18Symmetric Multiprocessor Architecture (SMP)
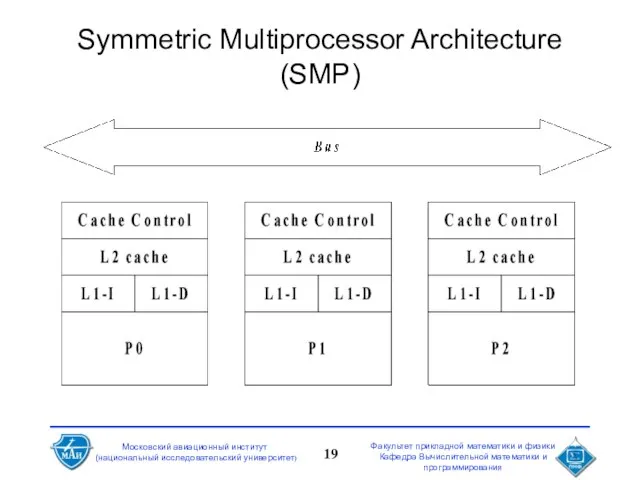
Каждый процессор
имеет свои L1 и L2 кэши
подсоединен к общей
Symmetric Multiprocessor Architecture (SMP)
Каждый процессор
имеет свои L1 и L2 кэши
подсоединен к общей

Слайд 19Symmetric Multiprocessor Architecture (SMP)
Symmetric Multiprocessor Architecture (SMP)
Слайд 20Программная модель CUDA
Параллельная часть кода выполняется как большое количество нитей (threads)
Нити группируются
Программная модель CUDA
Параллельная часть кода выполняется как большое количество нитей (threads)
Нити группируются

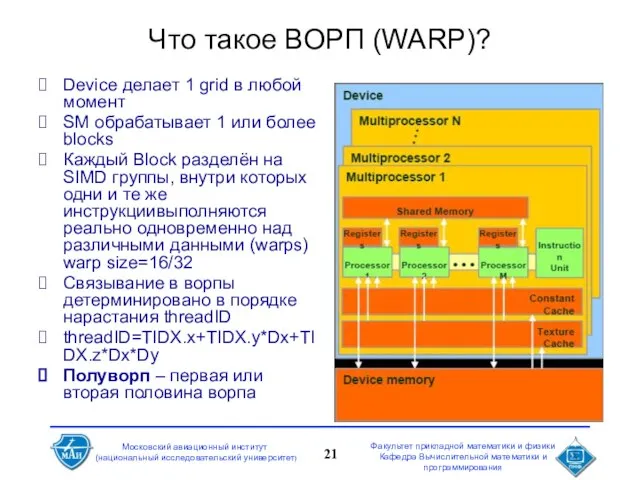
Слайд 21Что такое ВОРП (WARP)?
Device делает 1 grid в любой момент
SM обрабатывает 1
Что такое ВОРП (WARP)?
Device делает 1 grid в любой момент
SM обрабатывает 1
Слайд 22Итоги лекции
В результате лекции Вы должны :
Понимать возможности использования GPU для расчётов
Итоги лекции
В результате лекции Вы должны :
Понимать возможности использования GPU для расчётов

 Подобие треугольников. Второй признак
Подобие треугольников. Второй признак Скалярное произведение векторов. 9 класс
Скалярное произведение векторов. 9 класс Тригонометрические уравнения. Устный счет
Тригонометрические уравнения. Устный счет Прямоугольные треугольники
Прямоугольные треугольники Вычислительная сложность алгоритма
Вычислительная сложность алгоритма Вычитание натуральных чисел
Вычитание натуральных чисел Индивидуальное задание №8. Построение линии пересечения тора и конуса
Индивидуальное задание №8. Построение линии пересечения тора и конуса Первообразная
Первообразная Площадь правильного треугольника
Площадь правильного треугольника Презентация на тему Решение планиметрических задач на нахождение геометрических величин
Презентация на тему Решение планиметрических задач на нахождение геометрических величин  Застосування явної різницевоі схеми до розв'язку крайовоі задачі для рівняння переносу задач механіки суцільного середовища
Застосування явної різницевоі схеми до розв'язку крайовоі задачі для рівняння переносу задач механіки суцільного середовища Случаи сложения вида +5
Случаи сложения вида +5 Прилижение функций
Прилижение функций Определение производной
Определение производной Комбинаторные задачи Тема «Введение в вероятность». Учитель Козловская Т.В. МБОУ «Хову-Аксынская СОШ»
Комбинаторные задачи Тема «Введение в вероятность». Учитель Козловская Т.В. МБОУ «Хову-Аксынская СОШ» Построения в пространстве
Построения в пространстве Логарифм степени
Логарифм степени Параллельность прямых и плоскостей (10 класс)
Параллельность прямых и плоскостей (10 класс) Логарифмы. Задания В7, В11 на ЕГЭ
Логарифмы. Задания В7, В11 на ЕГЭ Кто что любит поесть?
Кто что любит поесть? Презентация по математике "Сложение и вычитание двузначных чисел в пределах 100" -
Презентация по математике "Сложение и вычитание двузначных чисел в пределах 100" -  Математика в профессиях
Математика в профессиях Сложение и вычитание многозначных чисел
Сложение и вычитание многозначных чисел Числовые ряды
Числовые ряды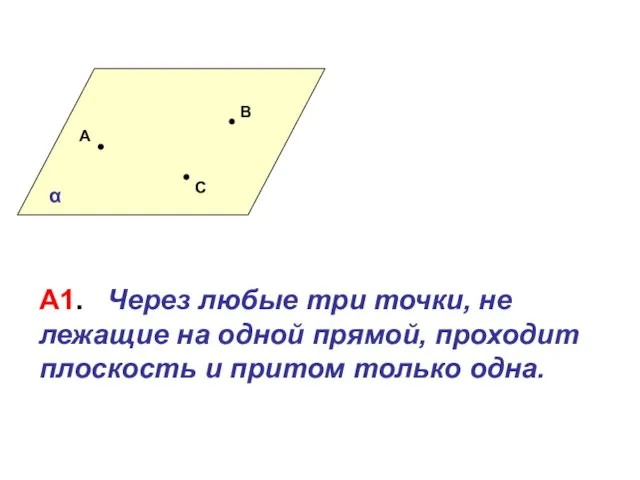 Плоскости
Плоскости Презентация на тему Сложение и вычитание натуральных чисел (5 класс)
Презентация на тему Сложение и вычитание натуральных чисел (5 класс)  Стереометрия. Практическая работа
Стереометрия. Практическая работа Теория вероятности. Задачи. 9 класс
Теория вероятности. Задачи. 9 класс