- Алгоритмы биоинформатики

Содержание
- 2. Информатика и Биоинформатика Биологическая задача Формализация Формализация Формализация Алгоритм Алгоритм Алгоритм Алгоритм Алгоритм Тестирование Параметры Параметры
- 3. Пример: сравнение последовательностей Тестирование: алгоритм должен распознавать последовательности, для которых известно, что они биологически (структурно и/или
- 4. Сравнение последовательностей Формализация1: глобальное выравнивание Алгоритм1: Граф выравнивания, динамическое программирование Алгоритм1а: Граф выравнивания, динамическое программирование, линейная
- 5. Сравнение последовательностей Формализация2: локальное выравнивание Алгоритм2: Граф локального выравнивания, динамическое программирование Параметры: Матрица сходства, штраф за
- 6. Сравнение последовательностей Формализация3: локальное выравнивание с аффинными штрафами Алгоритм3: Расширенный граф локального выравнивания, динамическое программирование Параметры:
- 7. Сравнение последовательностей Алгоритм4: FASTA. формальная задача плохо определена Параметры: Размер якоря, матрица сходства, штраф за делецию
- 8. Сравнение последовательностей Алгоритм5: BLAST. формальная задача плохо определена Параметры: Размер якоря, матрица сходства, штраф за делецию
- 9. Выравнивания
- 10. Редакционное расстояние Элементарное преобразование последовательности: замена буквы или удаление буквы или вставка буквы. Редакционное расстояние: минимальное
- 11. Сколько существует выравниваний? Дано: две последовательности S1 и S2 длиной m и n. Сколько есть способов
- 12. Динамическое программирование для редакционного расстояния Граф редакционного расстояния для последователь-ностей S1,S2: вершина vi,j соответствует префиксам последовательностей
- 13. Подмена задачи и обобщение Заменим расстояния di,j на -di,j. Тогда операцию min надо заменить на max.
- 14. Граничные условия wi,j wi+1,j wi,j+1 wi+1,j+1 w1,1 начало w1,2 d2,1 wn,m-1 wn,m w2,1 wn-1,m конец При
- 15. Как не штрафовать за концевые делеции wi,j w1,1 начало w1,2 w2,1 wn,m-1 wn,m w3,1 wn-1,m конец
- 16. Оценка времени работы и необходимой памяти Алгоритм посматривает все вершины графа В каждой вершине делается 3
- 17. Где можно сэкономить? Во-первых не обязательно запоминать веса во всех вершинах. При просмотре матрицы выравнивания (графа
- 18. Линейный по памяти алгоритм Миллера-Маерса Разбиваем одну из последовательностей на две равные части Для каждой точки
- 19. Алгоритм Миллера-Маерса Найденная точка x разбивает матрицу выравнивания на четыре квадранта, два из которых заведомо не
- 20. Еще один способ сэкономить время и память Ясно, что выравнивания D1 и D2 не представляют интереса,
- 21. Локальное выравнивание Локальным оптимальным выравниванием называется такое оптимальное выравнивание фрагментов последовательностей, при котором любое удлинение или
- 22. Алгоритм Смита-Ватермана wi,j w1,1 начало w1,2 w2,1 wn,m-1 wn,m w3,1 wn-1,m конец wn,m-2 wn-2,m w1,3 0
- 23. Алгоритм Смита-Ватермана Пусть есть какой-то путь с неотрицательными весами Построим график веса вдоль пути Абсолютный максимум
- 24. Алгоритм Смита-Ватермана Точка конца пути (от нее начинаем обратный просмотр и восстановление пути) определяется так: (imax,
- 25. Более общая зависимость штрафа за делецию от величины делеции Простейшая модель делеции: элементарное событие – удаление
- 26. Более общая зависимость штрафа за делецию от величины делеции. Алгоритм. Теперь надо просматривать все возможные варианты
- 27. Аффинные штрафы за делецию Вместо логарифмической зависимости используют зависимость вида: Δ ( l ) = dopen+
- 28. Алгоритм для аффинных штрафов Веса на ребрах ei,j сопоставление dopen открытие делеции dext продолжение делеции ei,j
- 29. Рекурсия для аффинных штрафов w i, j = max ( w i-1, j-1+ei j , v
- 30. Матрицы замен
- 31. Откуда берутся параметры для выравнивания? Пусть у нас есть выравнивание. Если последовательности случайные и независимые (модель
- 32. Серия матриц BLOSUM База данных BLOCKS (Henikoff & Henikoff) – безделеционные фрагменты множественных выравниваний (выравнивания получены
- 33. Серия матриц PAM Point Accepted Mutation – эволюционное расстояние, при котором произошла одна замена на 100
- 34. Серия матриц PAM Находим выравнивания, отвечающие расстоянию PAM1 Находим частоты пар и вычисляем частоты пар: p(αβ)
- 35. Статистика выравниваний
- 36. Параметры выравнивания В простейшем случае есть три параметра: премия за совпадение (match) штраф за несовпадение (mism)
- 37. Статистика выравниваний Допустим мы выровняли две последовательности длиной 100 и получили вес 20. Что это значит?
- 38. Статистика выравниваний Базовая (вообще говоря неправильная) модель – Бернуллиевские последовательности (символы генерируются независимо друг от друга
- 39. Частные случаи локального выравнивания mism = 0, indel = 0 – максимальная общая подпоследовательность mism =
- 40. Наибольшая общая подпоследовательность Длина оптимальной подпоследовательности есть случайная величина r(n), зависящая от длины последовательностей. Пусть две
- 41. Наибольшее общее слово Наложим одну последовательность на другую. Будем идти вдоль пары последовательностей и, если буквы
- 42. Зависимость от параметров Показано, что зависимость ожидаемого веса выравнивания от длины последовательности может быть либо логарифмической
- 43. Распределение экстремальных значений Пусть вес выравнивания x (случайная величина) имеет распределение G(S) = P(x Тогда при
- 44. e-value & p-value Количество независимых локальных выравниваний с весом >S описывается распределением Пуассона (Karlin &Altschul) :
- 45. Поиск по банку
- 46. Поиск по банку. Хеширование. Подготовка банка – построение хэш-таблицы. Хэш-функция – номер слова заданного размера (l-tuple,
- 47. Поиск по банку. FASTA. Используется техника поиска якорей с помощью хэш-таблицы. Два якоря (i1,j1), (i2,j2) принадлежат
- 48. Поиск по банку. BLAST1. Ищем якоря с помощью хэш-таблицы Каждый якорь расширяем с тем, чтобы получить
- 49. Поиск по банку. BLAST2. T-соседней l-граммой LT для l-граммы L называется такая l-грамма, что вес ее
- 50. Быстрое выравнивание Ищем якоря с помощью хэш-таблицы Якорь (i1,j1) предшествует якорю (i2,j2), если i1 Получаем ориентированный
- 51. Введение в Байесову статистику
- 52. Введение в Байесову статистику Задача. Мы 3 раза бросили монету и 3 раза выпал орел. Какова
- 53. Введение в Байесову статистику P(3o | p) = p3; P(3o, p) = P(3o | p) Pa
- 54. Введение в Байесову статистику P(p | 3o)= p3 Pa(p) / ∫ p3 Pa(p) dp; В качестве
- 55. Введение в Байесову статистику ML Оценка: p ML= argmax (p3) = 1; (не зависит от распределения
- 56. Определения Пусть у нас есть несколько источников Y событий X (например, несколько монет). Тогда : P(X
- 57. Пример Пусть есть две кости – правильная и кривая (с вероятностью выпасть 6 – 0.5). И
- 58. Оценка параметров по результатам Пусть у нас есть наблюдение D и некоторый набор параметров распределения θ,
- 59. Распределение Дирихле Определение: D(θ|α)=Z-1∏ θi αi δ(∑ θi – 1); Z – нормировочный множитель αi –
- 60. prior = распределение Дирихле Часто в качестве prior используют распределение Дирихле. Параметры этого распределения αi называют
- 61. Скрытые Марковские модели (HMM)
- 62. Пример Пусть некто имеет две монеты – правильную и кривую. Он бросает монету и сообщает нам
- 63. Биологические примеры Дана аминокислотная последовательность трансмембранного белка. Известно, что частоты встречаемости аминокислот в трансмембранных и в
- 64. Описание HMM Пример с монетой можно представить в виде схемы конечного автомата: Прямоугольники означают состояния Кружки
- 65. Решение задачи о монете Пусть нам известна серия бросков: 10011010011100011101111101111110111101 Этой серии можно поставить в соответствие
- 66. Решение задачи о монете Для любого пути можно подсчитать вероятность того, что наблюденная серия соответствует этому
- 67. Viterbi рекурсия Обозначения vk(i) – наилучшая вероятность пути, проходящего через позицию i в состоянии k. πk(i)
- 68. Другая постановка задачи Для каждого наблюденного значения определить вероятность того, что в этот момент монета была
- 69. Оценка параметров HMM Есть две постановки задачи. Есть множество наблюдений с указанием, где происходит смена моделей
- 70. Оценка параметров HMM при наличии обучающей выборки Здесь используется техника оценки параметров методом наибольшего правдоподобия. Пусть
- 71. Оценка параметров HMM при наличии обучающей выборки Можно показать, что при большом количестве наблюдений справедливы оценки
- 72. Если нет обучающей выборки Итеративный алгоритм Баума-Велча. Выберем некоторые наборы параметров HMM (обычно они генерируются случайно).
- 73. Оценки параметров по Бауму-Велчу Имея заданные параметры модели можно определить вероятность перехода между состояниями: P(πi=k, πi+1=l
- 74. Предсказание кодирующих областей в прокариотах Реальная схема HMM для поиска кодирующих областей сложнее: Включает в себя
- 75. Оценка качества обучения Выборку разбивают на два подмножества – обучающую и тестирующую На первой выборке подбирают
- 76. Профили
- 77. Способы описания множественного выравнивания Дано: множественное выравнивание. Задача: определить принадлежит ли некая последовательность данному семейству. Простейший
- 78. Энтропия колонки Пусть колонка содержит nα букв типа α. Тогда вероятность появления такой колонки при случайных
- 79. HMM профиль Модель: каждая последовательность множественного выравнивания является серией скрытой Марковской модели. Профиль – описание Марковской
- 80. HMM с учетом возможности вставок Делеция в профиле и в последовательности могут идти подряд (в отличие
- 81. Определение параметров модели Для начала надо определиться с длиной модели. В случае, если обучающее множественное выравнивание
- 82. Для тонких выравниваний Простейшие варианты псевдоотсчетов: Правило Лапласа: к каждому счетчику прибавить 1: ek (a) =
- 83. Смеси Дирихле Представим себе, что на распределение вероятностей влияют несколько источников – частота встречаемости символа в
- 84. Использование матрицы замен Еще один способ введения псевдоотсчетов. У нас есть матрица замен аминокислотных остатков (например,
- 85. Использование предка Все последовательности xk в выравнивании произошли от общего предка y. P(yj=a | alignment)=qa∏kP(xkj|a)/∑a' qa∏kP(xkj|a)
- 86. А чему же равно A? Для компенсации малости выборок используют псевдоотсчеты. Разные подходы дают разные распределения
- 87. Это еще не все … При вычислении эмиссионных вероятностей используется предположение о независимости испытаний. Однако, в
- 88. Взвешивание последовательностей Способ учета неравномерной представленности последовательностей в выборке называется взвешиванием последовательностей. Каждой последовательности в выравнивании
- 89. Взвешивание последовательностей Метод Герштейна-Сонхаммера-Чотьи Пусть нам известно филогенетическое дерево с расстояниями на ветвях. На листьях –
- 90. Взвешивание последовательностей Многогранники Воронова Поместим объекты в некоторое метрическое пространство. Каждый объект хочет иметь "поместье" –
- 91. Вероятность модели при условии, что последовательность x принадлежит модели M: P( x | M) P(M) P(M
- 92. Взвешивание последовательностей Максимизация энтропии Пусть k(i,a) – количество остатков типа a в колонке i, mi –
- 93. Обобщенный подход: ∑i Hi(w) → max, ∑kwk=1; где Hi(w) = ∑a pia log pia; pia –
- 94. Множественное выравнивание
- 95. Множественное выравнивание Способ написать несколько последовательностей друг под другом (может быть с пропусками) так, чтобы в
- 96. Оценка качества множественного выравнивания Энтропийная оценка Обычно считают, что колонки в выравнивании независимы. Поэтому качество выравнивания
- 97. Оценка качества множественного выравнивания Сумма пар Другой традиционный способ оценки – сумма весов матрицы соответствия аминокислотных
- 98. Если есть функционал, то его надо оптимизировать Элементарные переходы: Сопоставление трех Сопоставление двух и одна делеция
- 99. Динамическое программирование для множественного выравнивания Количество вершин равно ∏посл. Li = O(LN) Количество ребер из каждой
- 100. Прогрессивное выравнивание Строится бинарное дерево (guide tree, путеводное дерево) – листья = последовательности Дерево обходится начиная
- 101. Выравнивание профилей Выравнивание одной стопки последовательности относительно другой – обычное динамическое программирование. Оптимизируется сумма парных весов:
- 102. ClustalW Строится матрица расстояний с использованием попарных выравниваний Строится NJ дерево (метод ближайшего соседа) Строится прогрессивное
- 103. Улучшение выравнивания Недостаток прогрессивных методов: если для некоторой группы последовательностей выравнивание построено, то оно уже не
- 104. Множественное выравнивание с помощью HMM Каждому множественное выравнивание соответствует скрытая Марковская модель. Можно применить алгоритм максимизации
- 105. Блочное выравнивание
- 106. Поиск сигналов
- 107. Постановка задачи Дано несколько (например,20) последовательностей. Длина каждой последовательности - 200 В каждой последовательности найти короткий
- 108. Графвая постановка задачи. Дан многодольный граф: Каждой доле соответствует последовательность Вершины – сайты Ребра проводятся между
- 109. HMM-постановка задачи Найти HMM, описывающую наилучший сайт. Для описания сайта используют следующую модель: Start Не сайт
- 110. Алгоритм максимизации ожидания Допустим нам приблизительно известна структура сайта. Применяем алгоритм Баума-Велча. Получаем структуру сайта. Алгоритм
- 111. Гиббс сэмплер Задача: найти набор позиций сайтов в последовательностях Инициация: В качестве решения выбираем произвольный набор
- 112. Вероятности для Гиббс сэмплера Вероятности для Гиббс сэмплера
- 113. Комбинаторные методы
- 114. RNA
- 115. Вторичная структура РНК Вторичной структурой называется совокупность спаренных оснований Биологическая роль вторичной структуры: Структурная РНК –
- 116. Элементы вторичной структуры Шпилька Спираль Внутренняя петля Множственная петля Выпячивание Псевдоузел 5' 3'
- 117. Способы представления вторичных структур Топологическая схема Круговая диаграмма Массив спаренных оснований Список спиралей
- 118. Задача Дана последовательность. Найти правильную вторичную структуру. Золотой стандарт: тРНК, рРНК. Количество возможных вторичных структур очень
- 119. Комбинаторный подход Построим граф: вершины – потенциальные нуклеотидные пары (или потенциальные спирали) Ребро проводится, если пары
- 120. Структуры без псевдоузлов Структура без псевдоузлов = правильное скобочное выражение Может быть представлено в виде дерева
- 121. Оптимизация количества спаренных оснований Обозначим |s| - мощность структуры (количество спаренных оснований) Пусть s1 и s2
- 122. Оптимизация количества спаренных оснований Пусть нам известны оптимальные структуры Srt для всех фрагментов i≤ r ≤
- 123. Динамическое программирование для количества спаренных оснований (Нуссинофф) Количество спаренных оснований в оптимальной структуре S*i,j+1 определяется как
- 124. Динамическое программирование для количества спаренных оснований При поиске оптимального количества спаренных оснований заполняется треугольная матрица весов
- 125. Восстановление структуры по матрице спаривания - - 17 - 2 2 16 - 3 15 -
- 126. Восстановление структуры по матрице спаривания SearchStruct (int i, int j) { int i0=i, j0=j; do{ if(i
- 127. Энергия вторичной структуры Энергия спиралей Энергия петель (энтропия) A – U C – G A –
- 128. Энергия петель Энергия свободной цепи ΔG = B + 3/2 kT ln L Для шпилек при
- 129. Минимизация энергии Обычное динамическое программирование не проходит – нет аддитивности. Определения нуклеотид h называется доступным для
- 130. Алгоритм Зукера Введем две переменные: W(i,j) – минимальная энергия для структуры на фрагменте последовательности [i, j];
- 131. Алгоритм Зукера Рекурсия для W требует времени T≈O(L3) Рекурсия для V требует гораздо большего времени T≈O(2L)
- 132. Проблемы минимизации энергии Только около 80% тРНК сворачиваются в правильную структуру Энергетические параметры определены не очень
- 133. Решение проблем Искать субоптимальные структуры Искать эволюционно консервативные структуры. структуры тРНК и рРНК определены именно так
- 134. Поиск субоптимальных структур и структурных элементов Статистическая сумма Z = ∑ exp(-ΔGi /kT) Если мы просуммируем
- 135. Консенсусные вторичные структуры РНК
- 136. Основные задачи Построение консенсуса Дано: набор последовательностей для которых известно, что они имеют общую вторичную структуру
- 137. Метод ковариаций Пусть дано множественное выравнивание последовательностей Взаимная информация двух колонок: I(A,B) = ∑ αβ fAB(αβ)
- 138. Грамматики Определения Терминальным символом называется символ, который может получаться в строке (обозначается малыми буквами) Нетерминальный символ
- 139. Стохастические контекстно-свободные грамматики Контекстно-свободные грамматики имеют правила вида W → β β – терминальные и/или нетерминальные
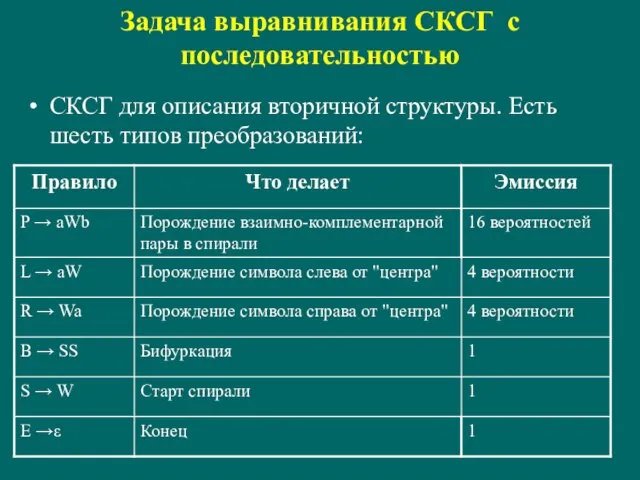
- 140. Задача выравнивания СКСГ с последовательностью СКСГ для описания вторичной структуры. Есть шесть типов преобразований:
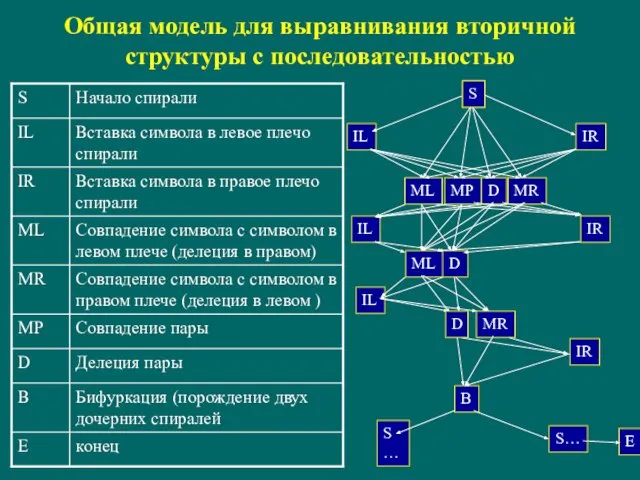
- 141. Общая модель для выравнивания вторичной структуры с последовательностью
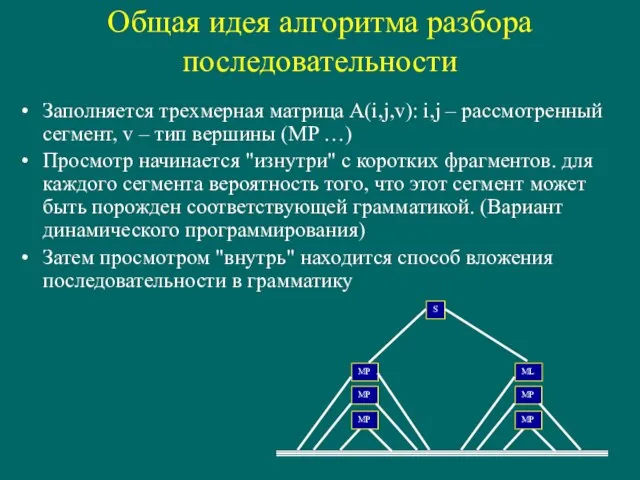
- 142. Общая идея алгоритма разбора последовательности Заполняется трехмерная матрица A(i,j,v): i,j – рассмотренный сегмент, v – тип
- 143. Поиск генов
- 145. Скачать презентацию
Слайд 2Информатика и Биоинформатика
Биологическая задача
Формализация
Формализация
Формализация
Алгоритм
Алгоритм
Алгоритм
Алгоритм
Алгоритм
Тестирование
Параметры
Параметры
Параметры
Параметры
Параметры
Определение области применимости
Информатика и Биоинформатика
Биологическая задача
Формализация
Формализация
Формализация
Алгоритм
Алгоритм
Алгоритм
Алгоритм
Алгоритм
Тестирование
Параметры
Параметры
Параметры
Параметры
Параметры
Определение области применимости
Слайд 3Пример: сравнение последовательностей
Тестирование: алгоритм должен распознавать последовательности, для которых известно, что они
Пример: сравнение последовательностей
Тестирование: алгоритм должен распознавать последовательности, для которых известно, что они

Слайд 4Сравнение последовательностей
Формализация1: глобальное выравнивание
Алгоритм1: Граф выравнивания, динамическое программирование
Алгоритм1а: Граф выравнивания, динамическое программирование,
Сравнение последовательностей
Формализация1: глобальное выравнивание
Алгоритм1: Граф выравнивания, динамическое программирование
Алгоритм1а: Граф выравнивания, динамическое программирование,

Слайд 5Сравнение последовательностей
Формализация2: локальное выравнивание
Алгоритм2: Граф локального выравнивания, динамическое программирование
Параметры: Матрица сходства, штраф
Сравнение последовательностей
Формализация2: локальное выравнивание
Алгоритм2: Граф локального выравнивания, динамическое программирование
Параметры: Матрица сходства, штраф

Слайд 6Сравнение последовательностей
Формализация3: локальное выравнивание с аффинными штрафами
Алгоритм3: Расширенный граф локального выравнивания, динамическое
Сравнение последовательностей
Формализация3: локальное выравнивание с аффинными штрафами
Алгоритм3: Расширенный граф локального выравнивания, динамическое

Слайд 7Сравнение последовательностей
Алгоритм4: FASTA. формальная задача плохо определена
Параметры: Размер якоря, матрица сходства, штраф
Сравнение последовательностей
Алгоритм4: FASTA. формальная задача плохо определена
Параметры: Размер якоря, матрица сходства, штраф

Слайд 8Сравнение последовательностей
Алгоритм5: BLAST. формальная задача плохо определена
Параметры: Размер якоря, матрица сходства, штраф
Сравнение последовательностей
Алгоритм5: BLAST. формальная задача плохо определена
Параметры: Размер якоря, матрица сходства, штраф

Слайд 9Выравнивания
Выравнивания

Слайд 10Редакционное расстояние
Элементарное преобразование последовательности: замена буквы или удаление буквы или вставка буквы.
Редакционное
Редакционное расстояние
Элементарное преобразование последовательности: замена буквы или удаление буквы или вставка буквы.
Редакционное

Слайд 11Сколько существует выравниваний?
Дано: две последовательности S1 и S2 длиной m и n.
Сколько существует выравниваний?
Дано: две последовательности S1 и S2 длиной m и n.

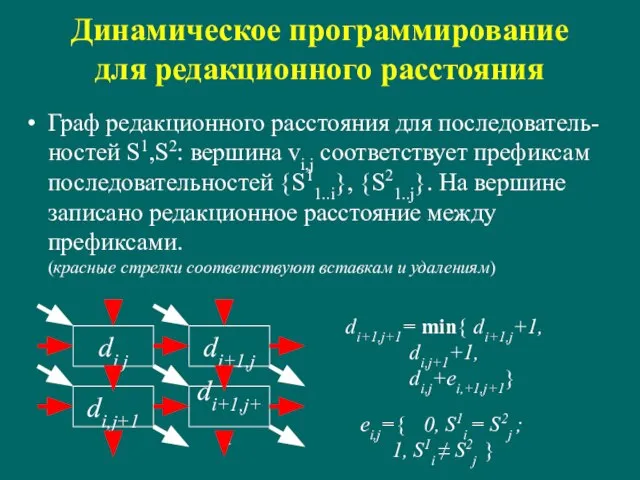
Слайд 12Динамическое программирование для редакционного расстояния
Граф редакционного расстояния для последователь-ностей S1,S2: вершина vi,j
Динамическое программирование для редакционного расстояния
Граф редакционного расстояния для последователь-ностей S1,S2: вершина vi,j
Слайд 13Подмена задачи и обобщение
Заменим расстояния di,j на -di,j. Тогда операцию min надо
Подмена задачи и обобщение
Заменим расстояния di,j на -di,j. Тогда операцию min надо

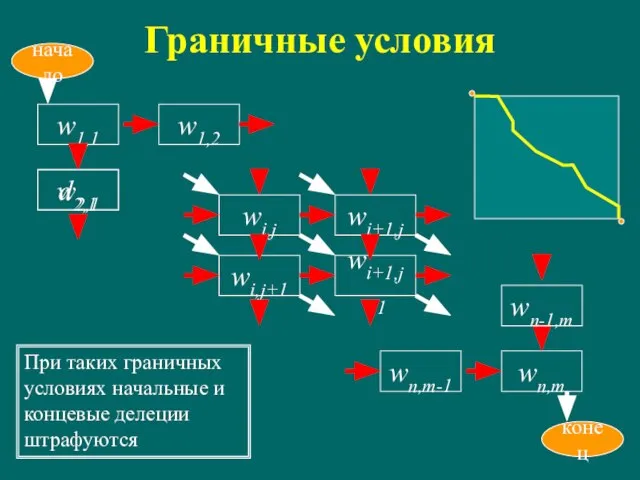
Слайд 14Граничные условия
wi,j
wi+1,j
wi,j+1
wi+1,j+1
w1,1
начало
w1,2
d2,1
wn,m-1
wn,m
w2,1
wn-1,m
конец
При таких граничных условиях начальные и концевые делеции штрафуются
Граничные условия
wi,j
wi+1,j
wi,j+1
wi+1,j+1
w1,1
начало
w1,2
d2,1
wn,m-1
wn,m
w2,1
wn-1,m
конец
При таких граничных условиях начальные и концевые делеции штрафуются
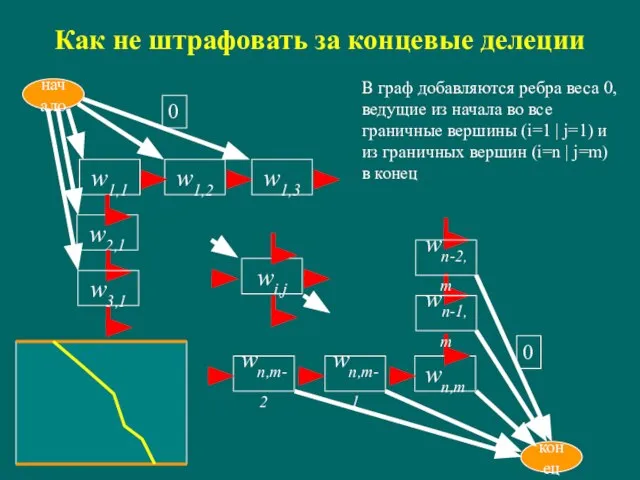
Слайд 15Как не штрафовать за концевые делеции
wi,j
w1,1
начало
w1,2
w2,1
wn,m-1
wn,m
w3,1
wn-1,m
конец
wn,m-2
wn-2,m
w1,3
0
0
В граф добавляются ребра веса 0, ведущие
Как не штрафовать за концевые делеции
wi,j
w1,1
начало
w1,2
w2,1
wn,m-1
wn,m
w3,1
wn-1,m
конец
wn,m-2
wn-2,m
w1,3
0
0
В граф добавляются ребра веса 0, ведущие
Слайд 16Оценка времени работы и необходимой памяти
Алгоритм посматривает все вершины графа
В каждой вершине
Оценка времени работы и необходимой памяти
Алгоритм посматривает все вершины графа
В каждой вершине

Слайд 17Где можно сэкономить?
Во-первых не обязательно запоминать веса во всех вершинах. При просмотре
Где можно сэкономить?
Во-первых не обязательно запоминать веса во всех вершинах. При просмотре

Слайд 18Линейный по памяти алгоритм Миллера-Маерса
Разбиваем одну из последовательностей на две равные части
Для
Линейный по памяти алгоритм Миллера-Маерса
Разбиваем одну из последовательностей на две равные части
Для

Слайд 19Алгоритм Миллера-Маерса
Найденная точка x разбивает матрицу выравнивания на четыре квадранта, два из
Алгоритм Миллера-Маерса
Найденная точка x разбивает матрицу выравнивания на четыре квадранта, два из

Слайд 20Еще один способ сэкономить время и память
Ясно, что выравнивания D1 и D2
Еще один способ сэкономить время и память
Ясно, что выравнивания D1 и D2

Слайд 21Локальное выравнивание
Локальным оптимальным выравниванием называется такое оптимальное выравнивание фрагментов последовательностей, при котором
Локальное выравнивание
Локальным оптимальным выравниванием называется такое оптимальное выравнивание фрагментов последовательностей, при котором

Слайд 22Алгоритм Смита-Ватермана
wi,j
w1,1
начало
w1,2
w2,1
wn,m-1
wn,m
w3,1
wn-1,m
конец
wn,m-2
wn-2,m
w1,3
0
0
В граф добавляются ребра веса 0, ведущие из начала во все
Алгоритм Смита-Ватермана
wi,j
w1,1
начало
w1,2
w2,1
wn,m-1
wn,m
w3,1
wn-1,m
конец
wn,m-2
wn-2,m
w1,3
0
0
В граф добавляются ребра веса 0, ведущие из начала во все
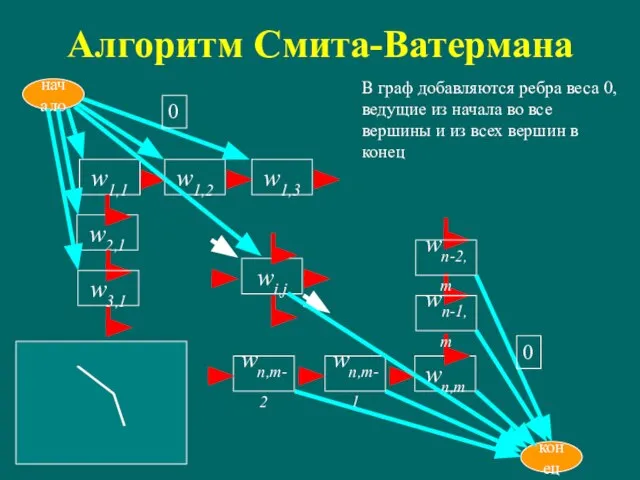
Слайд 23Алгоритм Смита-Ватермана
Пусть есть какой-то путь с неотрицательными весами
Построим график веса вдоль пути
Абсолютный
Алгоритм Смита-Ватермана
Пусть есть какой-то путь с неотрицательными весами
Построим график веса вдоль пути
Абсолютный

Слайд 24Алгоритм Смита-Ватермана
Точка конца пути (от нее начинаем обратный просмотр и восстановление пути)
Алгоритм Смита-Ватермана
Точка конца пути (от нее начинаем обратный просмотр и восстановление пути)

Слайд 25Более общая зависимость штрафа за делецию от величины делеции
Простейшая модель делеции: элементарное
Более общая зависимость штрафа за делецию от величины делеции
Простейшая модель делеции: элементарное

Слайд 26Более общая зависимость штрафа за делецию от величины делеции. Алгоритм.
Теперь надо просматривать
Более общая зависимость штрафа за делецию от величины делеции. Алгоритм.
Теперь надо просматривать

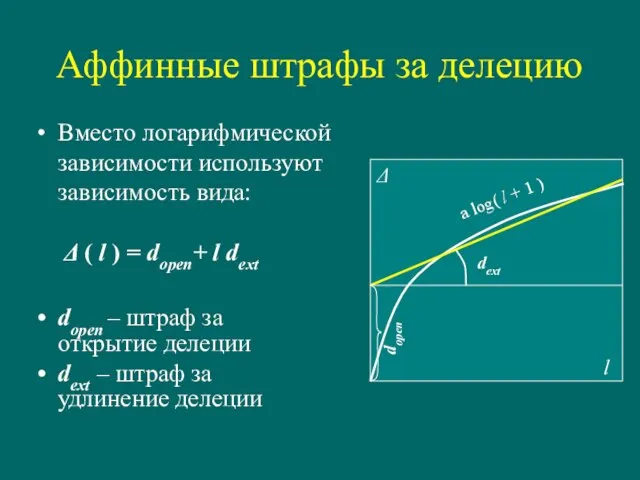
Слайд 27Аффинные штрафы за делецию
Вместо логарифмической зависимости используют зависимость вида:
Δ ( l
Аффинные штрафы за делецию
Вместо логарифмической зависимости используют зависимость вида: Δ ( l
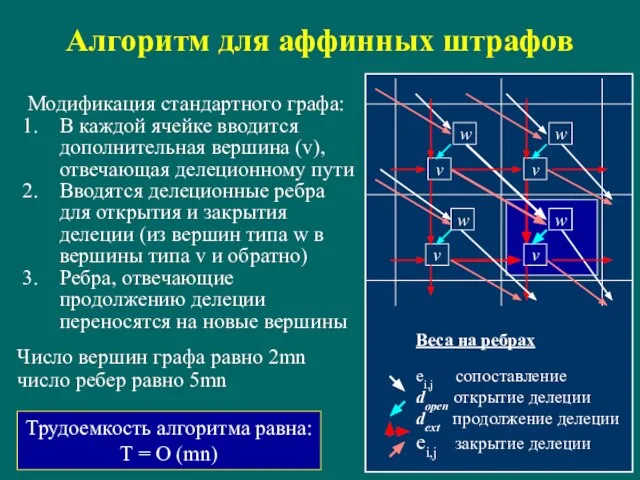
Слайд 28Алгоритм для аффинных штрафов
Веса на ребрах
ei,j сопоставление
dopen открытие делеции
dext продолжение делеции
ei,j закрытие
Алгоритм для аффинных штрафов
Веса на ребрах
ei,j сопоставление
dopen открытие делеции
dext продолжение делеции
ei,j закрытие
Слайд 29Рекурсия для аффинных штрафов
w i, j = max ( w i-1, j-1+ei
Рекурсия для аффинных штрафов
w i, j = max ( w i-1, j-1+ei

Слайд 30Матрицы замен
Матрицы замен

Слайд 31Откуда берутся параметры для выравнивания?
Пусть у нас есть выравнивание. Если последовательности случайные
Откуда берутся параметры для выравнивания?
Пусть у нас есть выравнивание. Если последовательности случайные

Слайд 32Серия матриц BLOSUM
База данных BLOCKS (Henikoff & Henikoff) – безделеционные фрагменты множественных
Серия матриц BLOSUM
База данных BLOCKS (Henikoff & Henikoff) – безделеционные фрагменты множественных

Слайд 33Серия матриц PAM
Point Accepted Mutation – эволюционное расстояние, при котором произошла одна
Серия матриц PAM
Point Accepted Mutation – эволюционное расстояние, при котором произошла одна

Слайд 34Серия матриц PAM
Находим выравнивания, отвечающие расстоянию PAM1
Находим частоты пар и вычисляем частоты
Серия матриц PAM
Находим выравнивания, отвечающие расстоянию PAM1
Находим частоты пар и вычисляем частоты

Слайд 35Статистика выравниваний
Статистика выравниваний

Слайд 36Параметры выравнивания
В простейшем случае есть три параметра:
премия за совпадение (match)
штраф за несовпадение
Параметры выравнивания
В простейшем случае есть три параметра:
премия за совпадение (match)
штраф за несовпадение

Слайд 37Статистика выравниваний
Допустим мы выровняли две последовательности длиной 100 и получили вес 20.
Статистика выравниваний
Допустим мы выровняли две последовательности длиной 100 и получили вес 20.

Слайд 38Статистика выравниваний
Базовая (вообще говоря неправильная) модель – Бернуллиевские последовательности (символы генерируются независимо
Статистика выравниваний
Базовая (вообще говоря неправильная) модель – Бернуллиевские последовательности (символы генерируются независимо

Слайд 39Частные случаи локального выравнивания
mism = 0, indel = 0 – максимальная
Частные случаи локального выравнивания
mism = 0, indel = 0 – максимальная

Слайд 40Наибольшая общая подпоследовательность
Длина оптимальной подпоследовательности есть случайная величина r(n), зависящая от длины
Наибольшая общая подпоследовательность
Длина оптимальной подпоследовательности есть случайная величина r(n), зависящая от длины

Слайд 41Наибольшее общее слово
Наложим одну последовательность на другую. Будем идти вдоль пары последовательностей
Наибольшее общее слово
Наложим одну последовательность на другую. Будем идти вдоль пары последовательностей

Слайд 42Зависимость от параметров
Показано, что зависимость ожидаемого веса выравнивания от длины последовательности может
Зависимость от параметров
Показано, что зависимость ожидаемого веса выравнивания от длины последовательности может

Слайд 43Распределение экстремальных значений
Пусть вес выравнивания x (случайная величина) имеет распределение
G(S) =
Распределение экстремальных значений
Пусть вес выравнивания x (случайная величина) имеет распределение
G(S) =

Слайд 44e-value & p-value
Количество независимых локальных выравниваний с весом >S описывается распределением Пуассона
e-value & p-value
Количество независимых локальных выравниваний с весом >S описывается распределением Пуассона

Слайд 45Поиск по банку
Поиск по банку

Слайд 46Поиск по банку. Хеширование.
Подготовка банка – построение хэш-таблицы. Хэш-функция – номер слова
Поиск по банку. Хеширование.
Подготовка банка – построение хэш-таблицы. Хэш-функция – номер слова

Слайд 47Поиск по банку. FASTA.
Используется техника поиска якорей с помощью хэш-таблицы.
Два якоря (i1,j1),
Поиск по банку. FASTA.
Используется техника поиска якорей с помощью хэш-таблицы.
Два якоря (i1,j1),

Слайд 48Поиск по банку. BLAST1.
Ищем якоря с помощью хэш-таблицы
Каждый якорь расширяем с тем,
Поиск по банку. BLAST1.
Ищем якоря с помощью хэш-таблицы
Каждый якорь расширяем с тем,

Слайд 49Поиск по банку. BLAST2.
T-соседней l-граммой LT для l-граммы L называется такая l-грамма,
Поиск по банку. BLAST2.
T-соседней l-граммой LT для l-граммы L называется такая l-грамма,

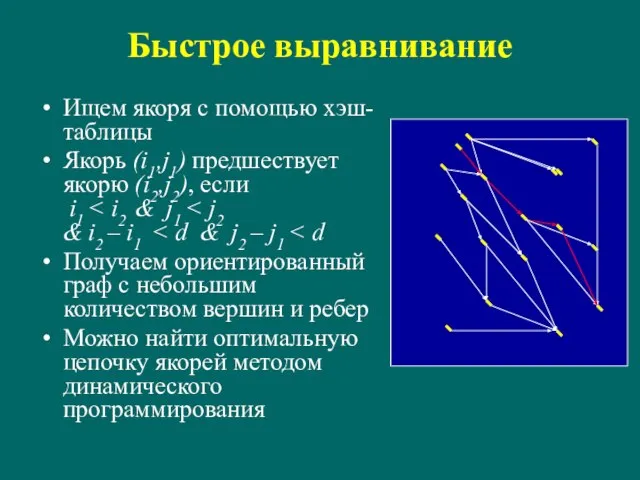
Слайд 50Быстрое выравнивание
Ищем якоря с помощью хэш-таблицы
Якорь (i1,j1) предшествует якорю (i2,j2), если
i1
Быстрое выравнивание
Ищем якоря с помощью хэш-таблицы
Якорь (i1,j1) предшествует якорю (i2,j2), если
i1
Слайд 51Введение в Байесову статистику
Введение в Байесову статистику

Слайд 52Введение в Байесову статистику
Задача. Мы 3 раза бросили монету и 3 раза
Введение в Байесову статистику
Задача. Мы 3 раза бросили монету и 3 раза

Слайд 53Введение в Байесову статистику
P(3o | p) = p3;
P(3o, p) = P(3o |
Введение в Байесову статистику
P(3o | p) = p3;
P(3o, p) = P(3o |

Слайд 54Введение в Байесову статистику
P(p | 3o)= p3 Pa(p) / ∫ p3 Pa(p)
Введение в Байесову статистику
P(p | 3o)= p3 Pa(p) / ∫ p3 Pa(p)

Слайд 55Введение в Байесову статистику
ML Оценка:
p ML= argmax (p3) = 1;
(не зависит
Введение в Байесову статистику
ML Оценка:
p ML= argmax (p3) = 1;
(не зависит

Слайд 56Определения
Пусть у нас есть несколько источников Y событий X (например, несколько монет).
Определения
Пусть у нас есть несколько источников Y событий X (например, несколько монет).

Слайд 57Пример
Пусть есть две кости – правильная и кривая (с вероятностью выпасть 6
Пример
Пусть есть две кости – правильная и кривая (с вероятностью выпасть 6

Слайд 58Оценка параметров по результатам
Пусть у нас есть наблюдение D и некоторый набор
Оценка параметров по результатам
Пусть у нас есть наблюдение D и некоторый набор

Слайд 59Распределение Дирихле
Определение:
D(θ|α)=Z-1∏ θi αi δ(∑ θi – 1);
Z – нормировочный множитель
αi
Распределение Дирихле
Определение:
D(θ|α)=Z-1∏ θi αi δ(∑ θi – 1);
Z – нормировочный множитель
αi

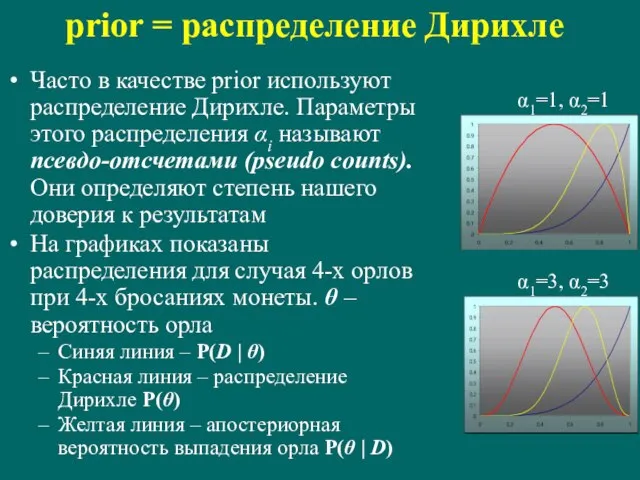
Слайд 60prior = распределение Дирихле
Часто в качестве prior используют распределение Дирихле. Параметры этого
prior = распределение Дирихле
Часто в качестве prior используют распределение Дирихле. Параметры этого
Слайд 61Скрытые Марковские модели (HMM)
Скрытые Марковские модели (HMM)

Слайд 62Пример
Пусть некто имеет две монеты – правильную и кривую. Он бросает монету
Пример
Пусть некто имеет две монеты – правильную и кривую. Он бросает монету

Слайд 63Биологические примеры
Дана аминокислотная последовательность трансмембранного белка. Известно, что частоты встречаемости аминокислот в
Биологические примеры
Дана аминокислотная последовательность трансмембранного белка. Известно, что частоты встречаемости аминокислот в

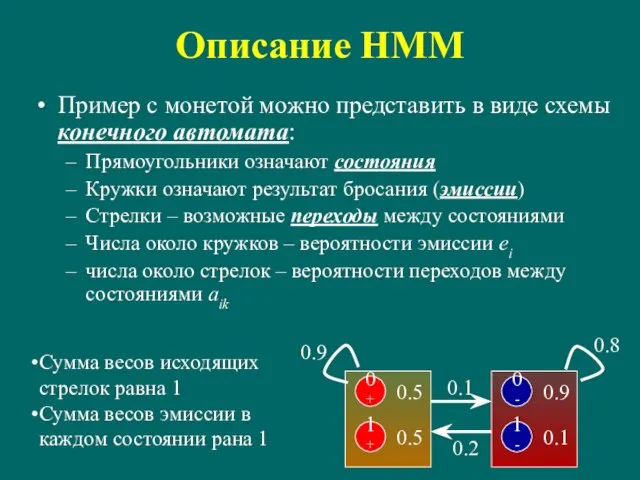
Слайд 64Описание HMM
Пример с монетой можно представить в виде схемы конечного автомата:
Прямоугольники означают
Описание HMM
Пример с монетой можно представить в виде схемы конечного автомата:
Прямоугольники означают
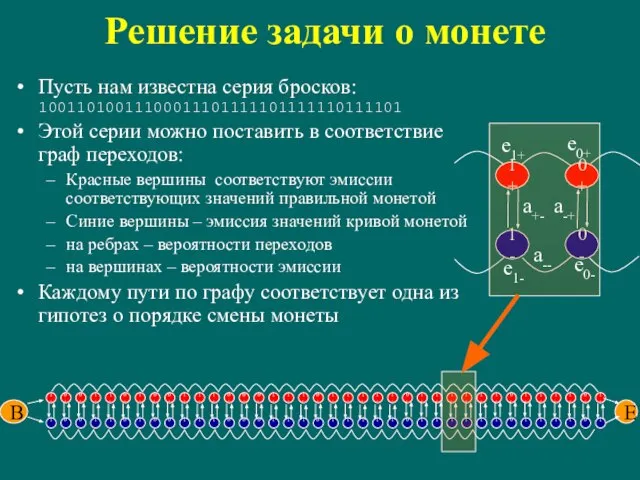
Слайд 65Решение задачи о монете
Пусть нам известна серия бросков:
10011010011100011101111101111110111101
Этой серии можно поставить в
Решение задачи о монете
Пусть нам известна серия бросков:
10011010011100011101111101111110111101
Этой серии можно поставить в
Слайд 66Решение задачи о монете
Для любого пути можно подсчитать вероятность того, что наблюденная
Решение задачи о монете
Для любого пути можно подсчитать вероятность того, что наблюденная

Слайд 67Viterbi рекурсия
Обозначения
vk(i) – наилучшая вероятность пути, проходящего через позицию i в состоянии
Viterbi рекурсия
Обозначения
vk(i) – наилучшая вероятность пути, проходящего через позицию i в состоянии

Слайд 68Другая постановка задачи
Для каждого наблюденного значения определить вероятность того, что в этот
Другая постановка задачи
Для каждого наблюденного значения определить вероятность того, что в этот

Слайд 69Оценка параметров HMM
Есть две постановки задачи.
Есть множество наблюдений с указанием, где происходит
Оценка параметров HMM
Есть две постановки задачи.
Есть множество наблюдений с указанием, где происходит

Слайд 70Оценка параметров HMM при наличии обучающей выборки
Здесь используется техника оценки параметров методом
Оценка параметров HMM при наличии обучающей выборки
Здесь используется техника оценки параметров методом

Слайд 71Оценка параметров HMM при наличии обучающей выборки
Можно показать, что при большом количестве
Оценка параметров HMM при наличии обучающей выборки
Можно показать, что при большом количестве

Слайд 72Если нет обучающей выборки
Итеративный алгоритм Баума-Велча.
Выберем некоторые наборы параметров HMM (обычно
Если нет обучающей выборки
Итеративный алгоритм Баума-Велча.
Выберем некоторые наборы параметров HMM (обычно

Слайд 73Оценки параметров по Бауму-Велчу
Имея заданные параметры модели можно определить вероятность перехода между
Оценки параметров по Бауму-Велчу
Имея заданные параметры модели можно определить вероятность перехода между

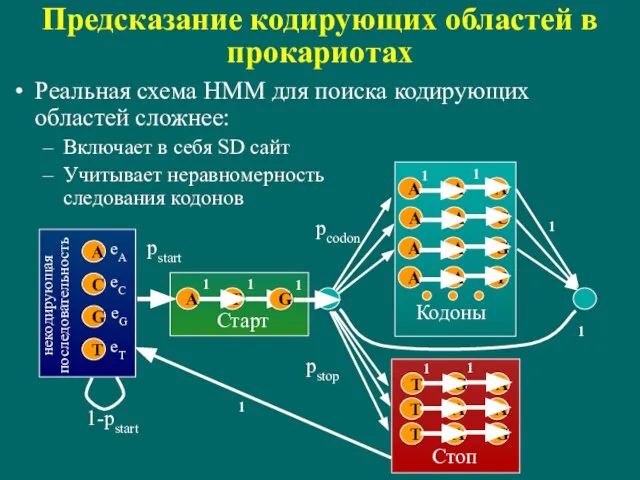
Слайд 74Предсказание кодирующих областей в прокариотах
Реальная схема HMM для поиска кодирующих областей сложнее:
Включает
Предсказание кодирующих областей в прокариотах
Реальная схема HMM для поиска кодирующих областей сложнее:
Включает
Слайд 75Оценка качества обучения
Выборку разбивают на два подмножества – обучающую и тестирующую
На первой
Оценка качества обучения
Выборку разбивают на два подмножества – обучающую и тестирующую
На первой

Слайд 76Профили
Профили

Слайд 77Способы описания
множественного выравнивания
Дано: множественное выравнивание.
Задача: определить принадлежит ли некая последовательность данному
Способы описания
множественного выравнивания
Дано: множественное выравнивание.
Задача: определить принадлежит ли некая последовательность данному

Слайд 78Энтропия колонки
Пусть колонка содержит nα букв типа α. Тогда вероятность появления такой
Энтропия колонки
Пусть колонка содержит nα букв типа α. Тогда вероятность появления такой

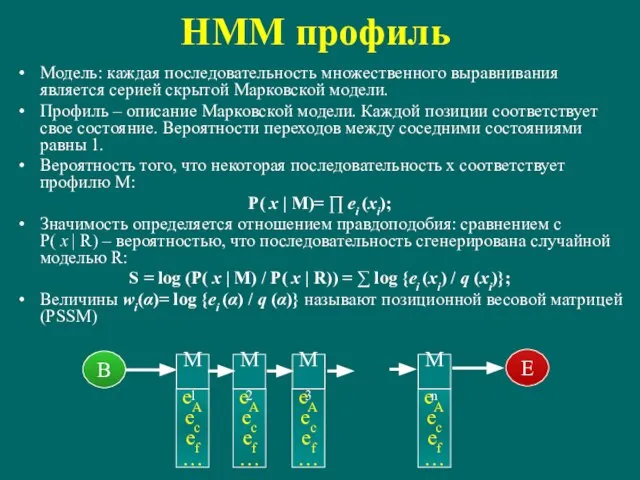
Слайд 79HMM профиль
Модель: каждая последовательность множественного выравнивания является серией скрытой Марковской модели.
Профиль –
HMM профиль
Модель: каждая последовательность множественного выравнивания является серией скрытой Марковской модели.
Профиль –
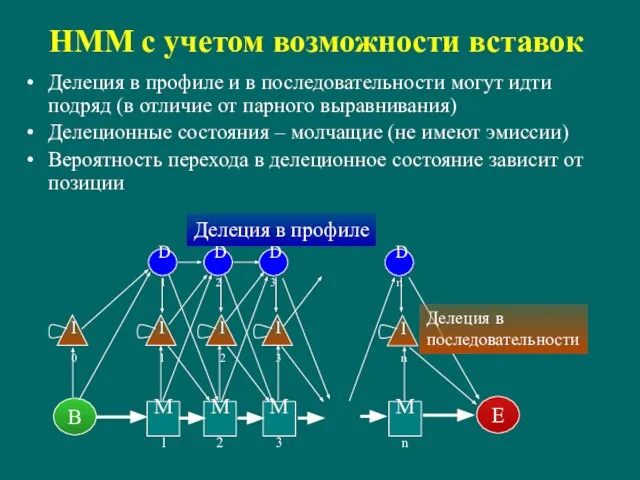
Слайд 80HMM с учетом возможности вставок
Делеция в профиле и в последовательности могут идти
HMM с учетом возможности вставок
Делеция в профиле и в последовательности могут идти
Слайд 81Определение параметров модели
Для начала надо определиться с длиной модели. В случае, если
Определение параметров модели
Для начала надо определиться с длиной модели. В случае, если

Слайд 82Для тонких выравниваний
Простейшие варианты псевдоотсчетов:
Правило Лапласа: к каждому счетчику
прибавить 1:
ek
Для тонких выравниваний
Простейшие варианты псевдоотсчетов:
Правило Лапласа: к каждому счетчику
прибавить 1:
ek

Слайд 83Смеси Дирихле
Представим себе, что на распределение вероятностей влияют несколько источников – частота
Смеси Дирихле
Представим себе, что на распределение вероятностей влияют несколько источников – частота

Слайд 84Использование матрицы замен
Еще один способ введения псевдоотсчетов. У нас есть матрица замен
Использование матрицы замен
Еще один способ введения псевдоотсчетов. У нас есть матрица замен

Слайд 85Использование предка
Все последовательности xk в выравнивании произошли от общего предка y.
P(yj=a
Использование предка
Все последовательности xk в выравнивании произошли от общего предка y.
P(yj=a

Слайд 86А чему же равно A?
Для компенсации малости выборок используют псевдоотсчеты.
Разные подходы дают
А чему же равно A?
Для компенсации малости выборок используют псевдоотсчеты.
Разные подходы дают

Слайд 87Это еще не все …
При вычислении эмиссионных вероятностей используется предположение о
Это еще не все …
При вычислении эмиссионных вероятностей используется предположение о

Слайд 88Взвешивание последовательностей
Способ учета неравномерной представленности последовательностей в выборке называется взвешиванием последовательностей.
Каждой последовательности
Взвешивание последовательностей
Способ учета неравномерной представленности последовательностей в выборке называется взвешиванием последовательностей.
Каждой последовательности

Слайд 89Взвешивание последовательностей Метод Герштейна-Сонхаммера-Чотьи
Пусть нам известно филогенетическое дерево с расстояниями на ветвях.
Взвешивание последовательностей Метод Герштейна-Сонхаммера-Чотьи
Пусть нам известно филогенетическое дерево с расстояниями на ветвях.

Слайд 90Взвешивание последовательностей Многогранники Воронова
Поместим объекты в некоторое метрическое пространство. Каждый объект хочет
Взвешивание последовательностей Многогранники Воронова
Поместим объекты в некоторое метрическое пространство. Каждый объект хочет

Слайд 91Вероятность модели при условии, что последовательность x принадлежит модели M:
P( x |
Вероятность модели при условии, что последовательность x принадлежит модели M:
P( x |

Слайд 92Взвешивание последовательностей Максимизация энтропии
Пусть k(i,a) – количество остатков типа a в колонке
Взвешивание последовательностей Максимизация энтропии
Пусть k(i,a) – количество остатков типа a в колонке

Слайд 93Обобщенный подход:
∑i Hi(w) → max, ∑kwk=1;
где Hi(w) = ∑a pia log pia;
Обобщенный подход:
∑i Hi(w) → max, ∑kwk=1;
где Hi(w) = ∑a pia log pia;

Слайд 94Множественное выравнивание
Множественное выравнивание

Слайд 95Множественное выравнивание
Способ написать несколько последовательностей друг под другом (может быть с пропусками)
Множественное выравнивание
Способ написать несколько последовательностей друг под другом (может быть с пропусками)

Слайд 96Оценка качества множественного выравнивания
Энтропийная оценка
Обычно считают, что колонки в выравнивании независимы. Поэтому
Оценка качества множественного выравнивания
Энтропийная оценка
Обычно считают, что колонки в выравнивании независимы. Поэтому

Слайд 97Оценка качества множественного выравнивания
Сумма пар
Другой традиционный способ оценки – сумма весов матрицы
Оценка качества множественного выравнивания
Сумма пар
Другой традиционный способ оценки – сумма весов матрицы

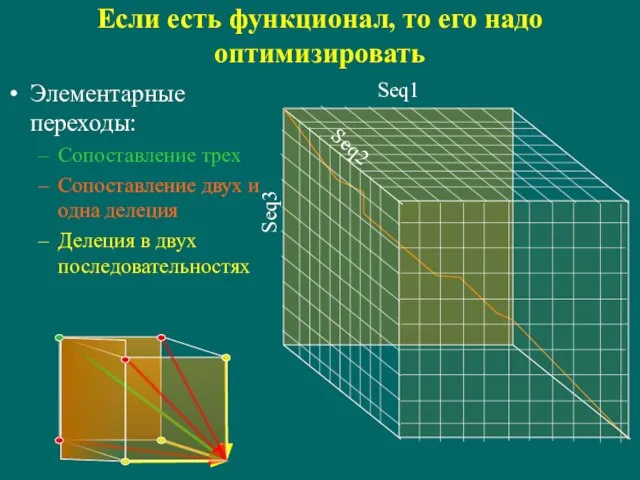
Слайд 98Если есть функционал, то его надо оптимизировать
Элементарные переходы:
Сопоставление трех
Сопоставление двух и одна
Если есть функционал, то его надо оптимизировать
Элементарные переходы:
Сопоставление трех
Сопоставление двух и одна
Слайд 99Динамическое программирование для множественного выравнивания
Количество вершин равно ∏посл. Li = O(LN)
Количество ребер
Динамическое программирование для множественного выравнивания
Количество вершин равно ∏посл. Li = O(LN)
Количество ребер

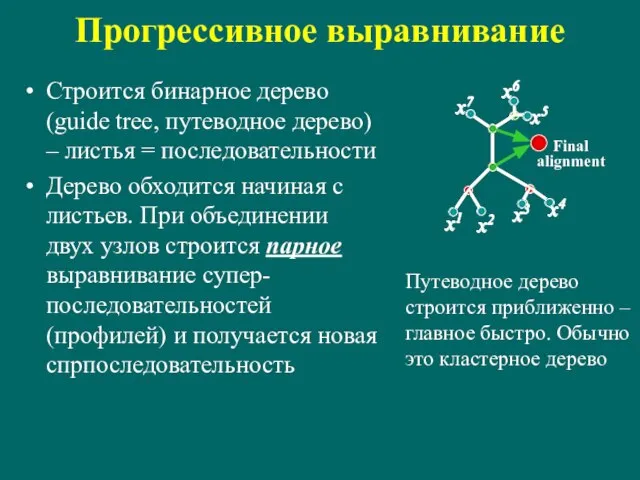
Слайд 100Прогрессивное выравнивание
Строится бинарное дерево (guide tree, путеводное дерево) – листья = последовательности
Дерево
Прогрессивное выравнивание
Строится бинарное дерево (guide tree, путеводное дерево) – листья = последовательности
Дерево
Слайд 101Выравнивание профилей
Выравнивание одной стопки последовательности относительно другой – обычное динамическое программирование.
Оптимизируется сумма
Выравнивание профилей
Выравнивание одной стопки последовательности относительно другой – обычное динамическое программирование.
Оптимизируется сумма

Слайд 102ClustalW
Строится матрица расстояний с использованием попарных выравниваний
Строится NJ дерево (метод ближайшего соседа)
Строится
ClustalW
Строится матрица расстояний с использованием попарных выравниваний
Строится NJ дерево (метод ближайшего соседа)
Строится

Слайд 103Улучшение выравнивания
Недостаток прогрессивных методов: если для некоторой группы последовательностей выравнивание построено, то
Улучшение выравнивания
Недостаток прогрессивных методов: если для некоторой группы последовательностей выравнивание построено, то

Слайд 104Множественное выравнивание с помощью HMM
Каждому множественное выравнивание соответствует скрытая Марковская модель.
Можно применить
Множественное выравнивание с помощью HMM
Каждому множественное выравнивание соответствует скрытая Марковская модель.
Можно применить

Слайд 105Блочное выравнивание
Блочное выравнивание

Слайд 106Поиск сигналов
Поиск сигналов

Слайд 107Постановка задачи
Дано несколько (например,20) последовательностей. Длина каждой последовательности - 200
В каждой последовательности
Постановка задачи
Дано несколько (например,20) последовательностей. Длина каждой последовательности - 200
В каждой последовательности

Слайд 108Графвая постановка задачи.
Дан многодольный граф:
Каждой доле соответствует последовательность
Вершины – сайты
Ребра проводятся между
Графвая постановка задачи.
Дан многодольный граф:
Каждой доле соответствует последовательность
Вершины – сайты
Ребра проводятся между

Слайд 109HMM-постановка задачи
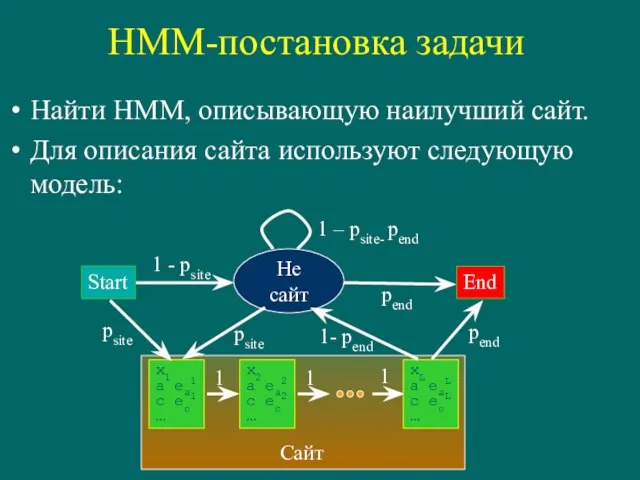
Найти HMM, описывающую наилучший сайт.
Для описания сайта используют следующую модель:
Start
Не сайт
x1
a
HMM-постановка задачи
Найти HMM, описывающую наилучший сайт.
Для описания сайта используют следующую модель:
Start
Не сайт
x1
a
Слайд 110Алгоритм максимизации ожидания
Допустим нам приблизительно известна структура сайта.
Применяем алгоритм Баума-Велча.
Получаем
Алгоритм максимизации ожидания
Допустим нам приблизительно известна структура сайта.
Применяем алгоритм Баума-Велча.
Получаем

Слайд 111Гиббс сэмплер
Задача: найти набор позиций сайтов в последовательностях
Инициация: В качестве решения
Гиббс сэмплер
Задача: найти набор позиций сайтов в последовательностях
Инициация: В качестве решения

Слайд 112Вероятности для Гиббс сэмплера
Вероятности для Гиббс сэмплера
Вероятности для Гиббс сэмплера
Вероятности для Гиббс сэмплера

Слайд 113Комбинаторные методы
Комбинаторные методы

Слайд 114RNA
RNA

Слайд 115Вторичная структура РНК
Вторичной структурой называется совокупность спаренных оснований
Биологическая роль вторичной структуры:
Структурная РНК
Вторичная структура РНК
Вторичной структурой называется совокупность спаренных оснований
Биологическая роль вторичной структуры:
Структурная РНК

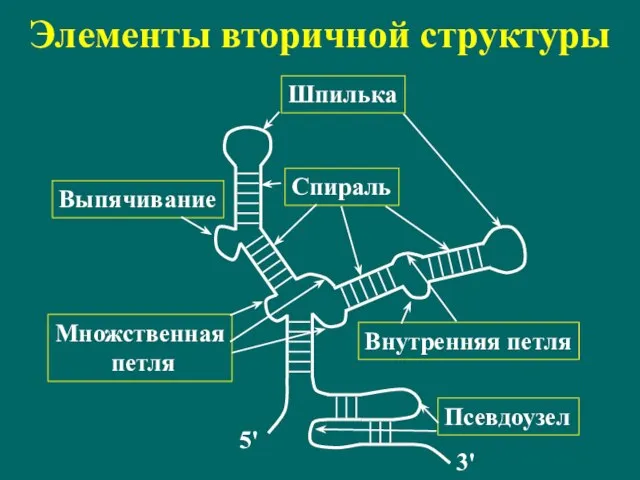
Слайд 116Элементы вторичной структуры
Шпилька
Спираль
Внутренняя петля
Множственная
петля
Выпячивание
Псевдоузел
5'
3'
Элементы вторичной структуры
Шпилька
Спираль
Внутренняя петля
Множственная
петля
Выпячивание
Псевдоузел
5'
3'
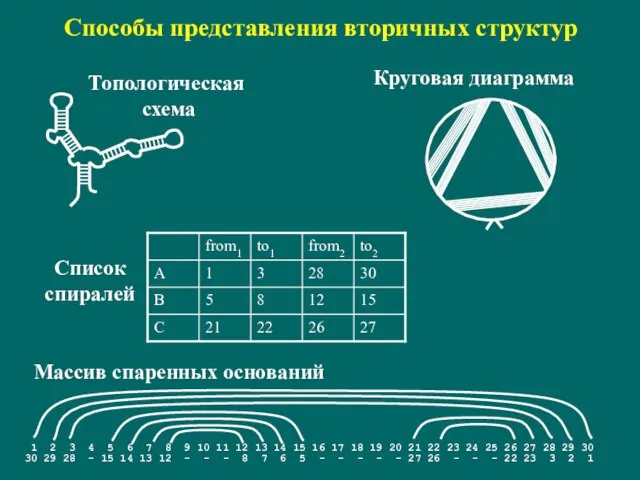
Слайд 117Способы представления вторичных структур
Топологическая
схема
Круговая диаграмма
Массив спаренных оснований
Список
спиралей
Способы представления вторичных структур
Топологическая
схема
Круговая диаграмма
Массив спаренных оснований
Список
спиралей
Слайд 118Задача
Дана последовательность.
Найти правильную вторичную структуру.
Золотой стандарт: тРНК, рРНК.
Количество возможных вторичных структур
Задача
Дана последовательность.
Найти правильную вторичную структуру.
Золотой стандарт: тРНК, рРНК.
Количество возможных вторичных структур

Слайд 119Комбинаторный подход
Построим граф:
вершины – потенциальные нуклеотидные пары (или потенциальные спирали)
Ребро проводится,
Комбинаторный подход
Построим граф:
вершины – потенциальные нуклеотидные пары (или потенциальные спирали)
Ребро проводится,
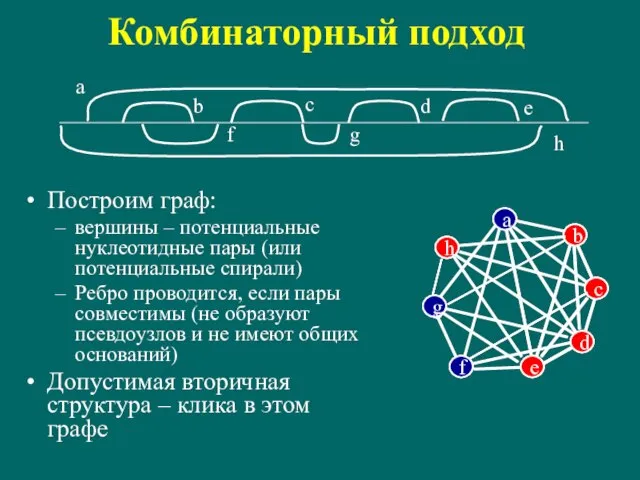
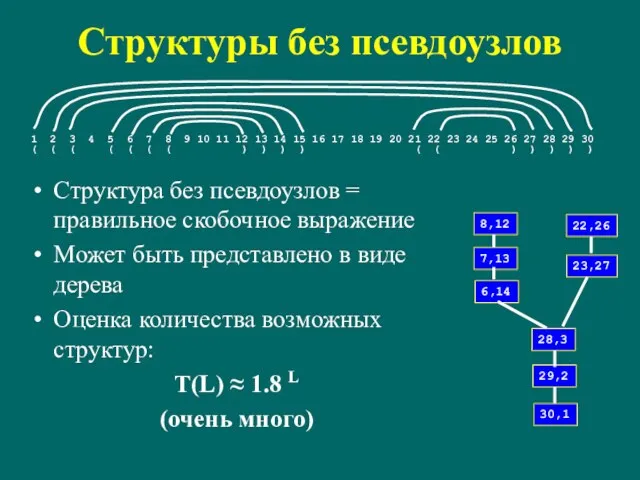
Слайд 120Структуры без псевдоузлов
Структура без псевдоузлов = правильное скобочное выражение
Может быть представлено в
Структуры без псевдоузлов
Структура без псевдоузлов = правильное скобочное выражение
Может быть представлено в
Слайд 121Оптимизация количества спаренных оснований
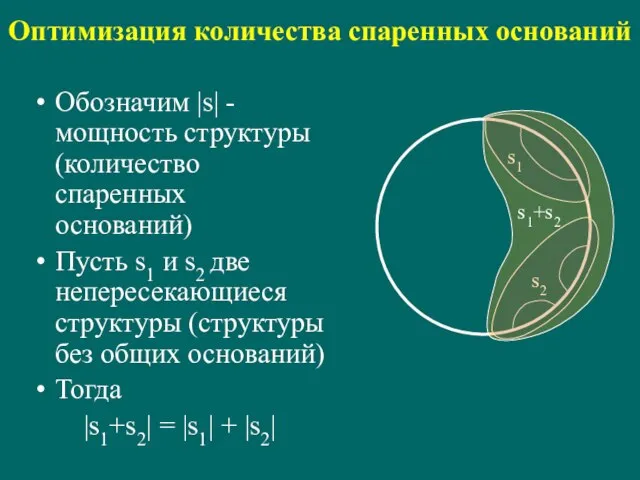
Обозначим |s| - мощность структуры (количество спаренных оснований)
Пусть s1
Оптимизация количества спаренных оснований
Обозначим |s| - мощность структуры (количество спаренных оснований)
Пусть s1
Слайд 122Оптимизация количества спаренных оснований
Пусть нам известны оптимальные структуры Srt для всех фрагментов
i≤
Оптимизация количества спаренных оснований
Пусть нам известны оптимальные структуры Srt для всех фрагментов
i≤

Слайд 123Динамическое программирование для количества спаренных оснований (Нуссинофф)
Количество спаренных оснований в оптимальной структуре
Динамическое программирование для количества спаренных оснований (Нуссинофф)
Количество спаренных оснований в оптимальной структуре

Слайд 124Динамическое программирование для количества спаренных оснований
При поиске оптимального количества спаренных оснований заполняется
Динамическое программирование для количества спаренных оснований
При поиске оптимального количества спаренных оснований заполняется

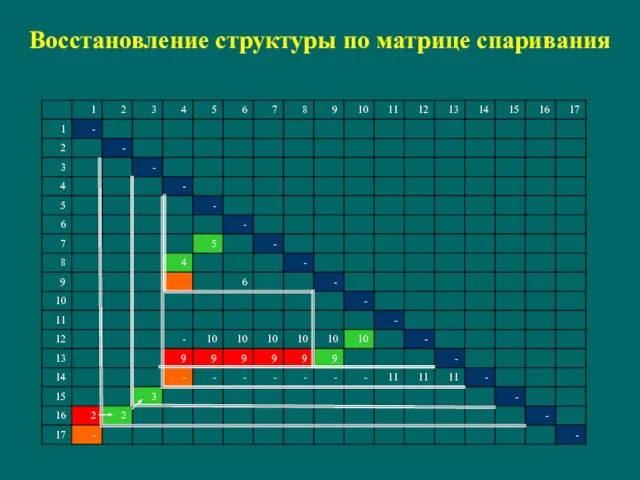
Слайд 125Восстановление структуры по матрице спаривания
-
-
17
-
2
2
16
-
3
15
-
11
11
11
-
-
-
-
-
-
-
14
-
9
9
9
9
9
9
13
-
10
10
10
10
10
10
-
12
-
11
-
10
-
6
9
-
4
8
-
5
7
-
6
-
5
-
4
-
3
-
2
-
1
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
Восстановление структуры по матрице спаривания
-
-
17
-
2
2
16
-
3
15
-
11
11
11
-
-
-
-
-
-
-
14
-
9
9
9
9
9
9
13
-
10
10
10
10
10
10
-
12
-
11
-
10
-
6
9
-
4
8
-
5
7
-
6
-
5
-
4
-
3
-
2
-
1
17
16
15
14
13
12
11
10
9
8
7
6
5
4
3
2
1
Слайд 126Восстановление структуры по матрице спаривания
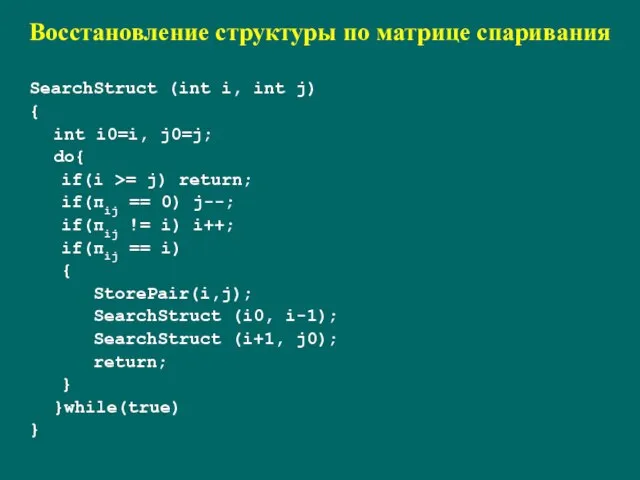
SearchStruct (int i, int j)
{
int i0=i, j0=j;
do{
if(i >=
Восстановление структуры по матрице спаривания
SearchStruct (int i, int j)
{
int i0=i, j0=j;
do{
if(i >=
Слайд 127Энергия вторичной структуры
Энергия спиралей
Энергия петель (энтропия)
A – U
C – G
A – U
G
Энергия вторичной структуры
Энергия спиралей
Энергия петель (энтропия)
A – U
C – G
A – U
G

Слайд 128Энергия петель
Энергия свободной цепи
ΔG = B + 3/2 kT ln L
Для шпилек
Энергия петель
Энергия свободной цепи
ΔG = B + 3/2 kT ln L
Для шпилек

Слайд 129Минимизация энергии
Обычное динамическое программирование не проходит – нет аддитивности.
Определения
нуклеотид h называется
Минимизация энергии
Обычное динамическое программирование не проходит – нет аддитивности.
Определения
нуклеотид h называется

Слайд 130Алгоритм Зукера
Введем две переменные:
W(i,j) – минимальная энергия для структуры на фрагменте
Алгоритм Зукера
Введем две переменные:
W(i,j) – минимальная энергия для структуры на фрагменте

Слайд 131Алгоритм Зукера
Рекурсия для W требует времени
T≈O(L3)
Рекурсия для V требует гораздо большего
Алгоритм Зукера
Рекурсия для W требует времени
T≈O(L3)
Рекурсия для V требует гораздо большего

Слайд 132Проблемы минимизации энергии
Только около 80% тРНК сворачиваются в правильную структуру
Энергетические параметры определены
Проблемы минимизации энергии
Только около 80% тРНК сворачиваются в правильную структуру
Энергетические параметры определены

Слайд 133Решение проблем
Искать субоптимальные структуры
Искать эволюционно консервативные структуры.
структуры тРНК и рРНК определены именно
Решение проблем
Искать субоптимальные структуры
Искать эволюционно консервативные структуры.
структуры тРНК и рРНК определены именно

Слайд 134Поиск субоптимальных структур и структурных элементов
Статистическая сумма
Z = ∑ exp(-ΔGi /kT)
Если мы
Поиск субоптимальных структур и структурных элементов
Статистическая сумма
Z = ∑ exp(-ΔGi /kT)
Если мы

Слайд 135Консенсусные вторичные структуры РНК
Консенсусные вторичные структуры РНК

Слайд 136Основные задачи
Построение консенсуса
Дано: набор последовательностей для которых известно, что они имеют общую
Основные задачи
Построение консенсуса
Дано: набор последовательностей для которых известно, что они имеют общую

Слайд 137Метод ковариаций
Пусть дано множественное выравнивание последовательностей
Взаимная информация двух колонок:
I(A,B) = ∑ αβ
Метод ковариаций
Пусть дано множественное выравнивание последовательностей
Взаимная информация двух колонок:
I(A,B) = ∑ αβ

Слайд 138Грамматики
Определения
Терминальным символом называется символ, который может получаться в строке (обозначается малыми буквами)
Нетерминальный
Грамматики
Определения
Терминальным символом называется символ, который может получаться в строке (обозначается малыми буквами)
Нетерминальный

Слайд 139Стохастические контекстно-свободные грамматики
Контекстно-свободные грамматики имеют правила вида
W → β
β – терминальные и/или
Стохастические контекстно-свободные грамматики
Контекстно-свободные грамматики имеют правила вида
W → β
β – терминальные и/или

Слайд 140Задача выравнивания СКСГ с последовательностью
СКСГ для описания вторичной структуры. Есть шесть типов
Задача выравнивания СКСГ с последовательностью
СКСГ для описания вторичной структуры. Есть шесть типов
Слайд 141Общая модель для выравнивания вторичной структуры с последовательностью
Общая модель для выравнивания вторичной структуры с последовательностью
Слайд 142Общая идея алгоритма разбора последовательности
Заполняется трехмерная матрица A(i,j,v): i,j – рассмотренный сегмент,
Общая идея алгоритма разбора последовательности
Заполняется трехмерная матрица A(i,j,v): i,j – рассмотренный сегмент,
Слайд 143Поиск генов
Поиск генов

 Конкурс чтецов «Здравствуй, Зима-красавица!
Конкурс чтецов «Здравствуй, Зима-красавица! Презентация на тему Москва – столица России 2 класс
Презентация на тему Москва – столица России 2 класс Уголовное право
Уголовное право Дистанционное образование в России
Дистанционное образование в России Презентация на тему Электролитическая диссоциация
Презентация на тему Электролитическая диссоциация Цвет. Основы цветоведения
Цвет. Основы цветоведения  ГРИД-ДИСПЕТЧЕР: РЕАЛИЗАЦИЯ СЛУЖБЫ ДИСПЕТЧЕРИЗАЦИИ ЗАДАНИЙ В ГРИД
ГРИД-ДИСПЕТЧЕР: РЕАЛИЗАЦИЯ СЛУЖБЫ ДИСПЕТЧЕРИЗАЦИИ ЗАДАНИЙ В ГРИД Роль классного руководителя в формировании учебной мотивации учащихся
Роль классного руководителя в формировании учебной мотивации учащихся Оксфорд Класс. English для успешных людей
Оксфорд Класс. English для успешных людей Женский образ ХХ века, или
Женский образ ХХ века, или Учительские
Учительские Нормативная и информационная база планирования. Тема 3
Нормативная и информационная база планирования. Тема 3 Проект индивидуального жилого дома для Сёрена Растреда
Проект индивидуального жилого дома для Сёрена Растреда Строительство и запуск производственного комплекса по глубокой переработке картофеля и овощей на площадке вновь создаваемого Аг
Строительство и запуск производственного комплекса по глубокой переработке картофеля и овощей на площадке вновь создаваемого Аг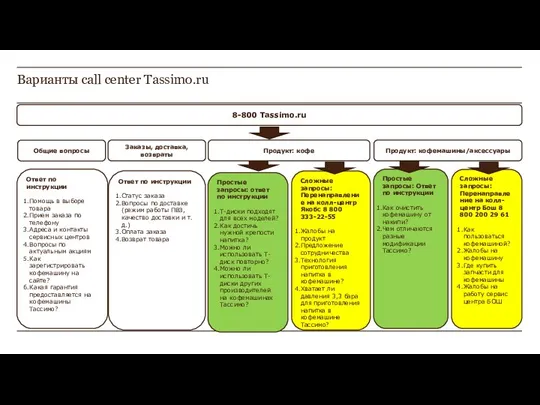 Варианты call center Tassimo.ru
Варианты call center Tassimo.ru Поэтика ОБЭРИУтов
Поэтика ОБЭРИУтов Развивающие занятия для дошкольников
Развивающие занятия для дошкольников Сочиненимӕ цӕттӕгӕнӕн урок: ӕмбалы хорзӕх уӕ алкӕй дӕр уӕд
Сочиненимӕ цӕттӕгӕнӕн урок: ӕмбалы хорзӕх уӕ алкӕй дӕр уӕд 59030 (2)
59030 (2) Автоматизация работы с таргетированной рекламой в социальных сетях!
Автоматизация работы с таргетированной рекламой в социальных сетях! КВАДРОЦИКЛЫ И КВАДРОЦИКЛЫ С ПОСАДКОЙ «БОК О БОК» CAN-AM 2013 г. в. Ванкувер/25-26 мая 2012 г.
КВАДРОЦИКЛЫ И КВАДРОЦИКЛЫ С ПОСАДКОЙ «БОК О БОК» CAN-AM 2013 г. в. Ванкувер/25-26 мая 2012 г. Оценка ювелирных изделий из золота. Стандарты работы с клиентами ломбарда. Лекция №4
Оценка ювелирных изделий из золота. Стандарты работы с клиентами ломбарда. Лекция №4 Устный журнал
Устный журнал Региональный открытый краеведческий проект ПётрПервый.ру
Региональный открытый краеведческий проект ПётрПервый.ру Презентация ЛПЗ №4
Презентация ЛПЗ №4 Страдательные причастия настоящего времени. Гласные в суффиксах страдательных причастий настоящего времени
Страдательные причастия настоящего времени. Гласные в суффиксах страдательных причастий настоящего времени Ажурные игрушки
Ажурные игрушки Организация системы автоматической ликвидацииасинхронных режимов
Организация системы автоматической ликвидацииасинхронных режимов