- Алгоритмы и контейнеры данных

Содержание
- 2. Введение В рамках курса будут изучаться Алгоритмы сортировки и поиска Контейнеры данных Необходимо освоить Реализацию алгоритмов
- 3. Введение Курс разрабатывался, исходя из использования языка программирования C++ Допускается использование других объектно-ориентированных языков для выполнения
- 4. Введение Стандартная схема сдачи курса два задания на разработку алгоритмов одно задание на разработку контейнера данных
- 5. Введение Альтернативная схема сдачи курса Есть специальное задание для одного-двоих разработчиков. Желательно знание языка C#.
- 6. Тема 1.1. Вычислительная сложность алгоритмов. Алгоритмы сортировки и поиска
- 7. Лекция 1. Понятие вычислительной сложности алгоритма Время выполнения программой той или иной вычислительно сложной задачи является
- 8. Время работы программы Время работы программы зависит от Алгоритма Числа обрабатываемых элементов Конкретного набора элементов Характеристик
- 9. Время работы программы Рассмотрим несколько программ, выполняемых на одной машине в одинаковых условиях с входными наборами
- 10. Изменение времени работы
- 11. Время работы программы Можно заметить, что при больших N существенно различие между первыми тремя программами и
- 12. Утверждение Пусть компьютер соответствует принципу адресности фон Неймана (имеет оперативную память, время обращения к каждой ячейке
- 13. Утверждение Пусть компьютер имеет примерно соответствующий общепринятому набор команд (т.е. в нем нет готовых команд сортировки,
- 14. Утверждение Тогда для большинства задач порядок роста времени работы программы в зависимости от числа элементов определяется
- 15. Выводы При разработке программы невозможно точно определить время ее работы в будущем. Для практических нужд, как
- 16. Выводы Исследование вычислительной сложности алгоритма возможно без знания деталей его реализации на конкретном языке программирования на
- 17. Асимптотическое поведение функции Говорят, что если
- 18. Асимптотическое поведение функции Говорят, что если
- 19. Асимптотическое поведение функции Верно, что
- 20. Асимптотическое поведение функции. Примеры
- 21. Асимптотическое поведение функции Для исследования алгоритма работы достаточно выяснить асимптотическое поведение функции, задающей зависимость времени работы
- 22. Асимптотическое поведение функции. мы можем пренебрегать постоянными коэффициентами и меньшими по порядку добавками [o(g(n))] при оценивании
- 23. Пример max = 0; for ( i = 0 ; i if ( max max =
- 24. Пример. Команды процессора SET R1,0 c1 LOAD R2, c2 LOAD R3, c2 SET R4, 0; c1
- 25. Пример: Время работы программы (k – количество раз, когда условие выполнено, 0 T=2с1+2с2+n(2с3+2с4+c2+2с5+c6)+kc1+c7 2с1+2с2+c7+n(2с3+2с4+c2+2с5+c6) T T=O(n)
- 26. Пример max = 0; for ( i = 0 ; i if ( max max =
- 27. Вычислительная сложность алгоритма Часто время работы алгоритма зависит не только от размера входных данных, но и
- 28. Вычислительная сложность алгоритма Часто асимптотическая сложность алгоритма для средних и наихудших входных данных совпадает Когда я
- 29. Вычислительная сложность алгоритма Существуют алгоритмы (например, QuickSort), вычислительная сложность которых отличается в среднем O(nlg(n) и наихудшем
- 30. Вычислительная сложность алгоритма Вычислительная сложность алгоритма в наилучшем случае обсуждается реже Подумайте, не можете ли Вы
- 31. Выводы Порядок роста времени выполнения программы, как правило, определяется алгоритмом Ключевая характеристика алгоритма – порядок роста
- 32. Лекция 2. Понятие сортировки и поиска. Обзор основных алгоритмов. Линейный поиск в массиве Бинарный поиск в
- 33. Методы поиска Линейный поиск Бинарный поиск Другие методы
- 34. Линейный поиск в массиве Пусть есть массив A длины n Необходимо найти элемент, равный а. Мы
- 35. Линейный поиск в массиве int result = -1; int i = 0; while ( i {
- 36. Линейный поиск в массиве Легко показать, что время работы алгоритма в наихудшем и среднем случае –
- 37. Бинарный поиск в массиве В общем случае реализовать поиск с трудоемкостью, меньшей O(n), невозможно Если мы
- 38. Поиск в отсортированном массиве 17 16 14 11 10 9 8 4 25 23 19 18
- 39. Бинарный поиск Количество сравнений – log2N Неудобство хранения данных в отсортированном массиве – дорогая вставка элемента
- 40. Поиск Если мы хотим еще более быстрого поиска – мы должны наложить еще более жесткие ограничения
- 41. Поиск минимального элемента Задача решается за время, равное O(n) min = 0; for ( i =
- 42. Методы сортировки Сортировка за O(n2) Сортировка за O(nlg(n))
- 43. Сортировка прямым выбором На первом шаге выбирается минимальный элемент и ставится первым После этого мы решаем
- 44. Пример Демонстрационная программа SortStraightSel
- 45. Пример работы 1
- 46. Сортировка прямым выбором Мы просматриваем на первом шаге N элементов, на втором – N-1, и так
- 47. Сортировка пузырьком На каждом шаге перебираются все пары соседних элементов, и если меньший элемент стоит позже
- 48. Пример
- 49. Пример
- 50. Пример
- 51. Пример
- 52. Сортировка пузырьком Необходимо N-1 шагов. На каждом шаге – N-1 сравнение (и, при необходимости, перестановка). Итого
- 53. Быстрые алгоритмы сортировки Алгоритм сортировки MergeSort Представим себе, что левая и правая половина массива отсортированы. Тогда
- 54. Merge Sort 1 3 6 8 2 4 5 7 1 3 6 8 2 4
- 55. Merge Sort 1 3 6 8 2 4 5 7 1 3 6 8 2 4
- 56. Merge Sort 1 3 6 8 2 4 5 7 1 3 6 8 2 4
- 57. Merge Sort Как же сделать половинки массива отсортированными? В массиве из двух элементов половинки отсортированы всегда
- 58. Merge Sort. Неотсортированый массив 4 * 2 = 8, N 2 * 4 = 8, N
- 59. MergeSort Алгоритм MergeSort позволяет нам решить задачу сортировки массива за время, пропорциональное Nlog2N Мы знаем, что
- 60. Пирамидальная сортировка Основана на помещении значений в пирамиду и извлечении их из пирамиды
- 61. QuickSort 3 7 2 9 1 6 5 7 3 7 9 6 5 2 1
- 62. QuickSort Как выполнить QuickSort без использования дополнительной памяти? 3 2 9 1 6 5 7 3
- 63. CombSort В сортировке пузырьком мы сравниваем соседние элементы и меняем их местами Эффективнее на первых шагах
- 64. CombSort Начальный шаг – длина массива, деленная на 1.3 Уменьшение шага – в 1.3 раза
- 65. CombSort 3 2 9 1 6 5 7 Шаг 3 (1 проход) 3 2 9 1
- 66. IntroSort Сочетание пирамидальной и быстрой сортировки Быстрая сортировка лучше в среднем случае, пирамидальная – в наихудшем
- 67. Методы сортировки за O(N) Сортировка подсчетом Цифровая сортировка Карманная сортировка
- 68. Сортировка подсчетом Предположим, в массиве лежат значения, равные 0, 1 и 2 Как выполнить его сортировку
- 69. Сортировка подсчетом 0 2 2 0 1 1 0 2 Этап 1 – подсчитываем число 0,
- 70. Сортировка подсчетом 0 2 2 0 1 1 0 2 Этап 2 – Определяем позиции, на
- 71. Сортировка подсчетом 0 2 2 0 1 1 0 2 Этап 3 – Создаем новый массив
- 72. Сортировка подсчетом 0 2 2 0 1 1 0 2 0 2 2 0 1 1
- 73. Сортировка подсчетом 0 2 2 0 1 1 0 2 0 2 0 2 2 0
- 74. Сортировка подсчетом 0 2 2 0 1 1 0 2 0 0 2 2 0 2
- 75. Сортировка подсчетом 0 2 2 0 1 1 0 2 0 0 1 1 2 2
- 76. Сортировка подсчетом Работает за время O(N+K), где N – число значений в массиве, K – число
- 77. Сортировка подсчетом 3 Дарья Петрова 3 Андрей Васильев 3 Иван Алексеев 2 Алексей Яковлев 2 Артем
- 78. Сортировка подсчетом Порядок студентов был алфавитным Мы отсортировали список по номеру курса. Порядок студентов внутри курса
- 79. Цифровая сортировка Для массивов с большим диапазоном значений сортировка подсчетом не годится Учитывая сохранение порядка элементов
- 80. Цифровая сортировка 532 718 191 265 743 489 170 913 2 8 1 5 3 9
- 81. Карманная сортировка Пусть есть массив N вещественных значений от 0 до 1. Создадим N списков. В
- 82. Другие алгоритмы сортировки Быстрая сортировка (Quick Sort) Сортировка Шелла Сортировка Шейкером Сортировка подсчетом Цифровая сортировка (по
- 83. Другие алгоритмы сортировки Сортировка расческой (Comb Sort) Плавная сортировка (Smooth Sort) Блочная сортировка Patience sorting Introsort
- 84. Лабораторная работа №1. Реализация алгоритмов сортировки и поиска.
- 85. Реализация алгоритмов сортировки и поиска Предлагаются индивидуальные варианты заданий, связанные с реализацией алгоритмов Предпочтительна реализация алгоритма,
- 86. Варианты заданий Реализовать бинарный поиск в массиве Реализовать сортировку Шелла Реализовать сортировку шейкером Реализовать сортировку подсчетом
- 87. Варианты заданий Реализовать метод IntroSort Реализовать цифровую сортировку значений типа int по их двоичной записи Реализовать
- 88. Варианты заданий повышенной сложности Реализовать пирамидальную сортировку Реализовать плавную сортировку (Smooth Sort) Реализовать быструю сортировку (QuickSort)
- 89. Варианты заданий повышенной сложности Реализовать карманную (bucket) сортировку Реализовать алфавитную сортировку M строк суммарной длиной N
- 90. Варианты заданий повышенной сложности Реализовать поиск i-ой порядковой статистики [i-ого по величине числа] методом RandomizedSelect (за
- 91. Понятие порядковой статистики 2 1 7 4 9 3 0 1-ая порядковая статистика – 0 2-ая
- 92. Тема 1.2. Контейнеры данных. Идея хэширования
- 93. Лекция 3. Понятие контейнера данных. Основные типы контейнеров
- 94. Понятие контейнера данных Контейнер – программный объект, отвечающий за хранение набора однотипных данных (элементов контейнера) и
- 95. Контейнеры в языках программирования Контейнер может быть Стандартным объектом языка программирования (массивы фиксированной длины в C)
- 96. Виды контейнеров Массивы Списки Деревья Словари Стеки и очереди Пирамиды. Очереди с приоритетами
- 97. Массивы Массивом называется контейнер, в котором элементы лежат в памяти компьютера подряд Размер массива из N
- 98. Массивы A[0] A[1] A A[i] A[N-1] iM байт NM байт
- 99. Массивы. Ключевые свойства Быстрый поиск элемента по индексу (за O(1)) На C/C++ &(A[n])=&(A)+n Медленная вставка элемента
- 100. Массив. Рост сверх планового размера
- 101. Массивы Запрещая «переезд» массива, мы ограничиваем рост его размера Разрешая «переезд», мы лишаем себя права запоминать
- 102. Пример std::vector array; … int* ptr = &(array[0]); //Запомнили адрес array.push_back( 7 ); //Добавили элемент //Возможен
- 103. Списки Существенным ограничением массива является хранение элементов подряд Оно приводит к сложности расширения массива и вставки
- 104. Списки Пусть каждый элемент помнит, где лежит следующий (хранит его адрес) Тогда достаточно запомнить адрес нулевого
- 105. Списки Элемент Адрес Элемент Адрес Элемент Адрес Элемент Адрес Элемент Адрес(0)
- 106. Список: вставка элемента Элемент Адрес Элемент Адрес Элемент Адрес(0)
- 107. Список: вставка элемента Время вставки элемента в середину списка – O(1), т.е. не зависит от размера
- 108. Списки Недостаток списка: в нем, даже отсортированном, нельзя реализовать бинарный поиск (слишком дорого искать середину списка)
- 109. Списки Бывают: Однонаправленными (каждый элемент знает следующий) Двунаправленными (каждый элемент знает следующий и предыдущий)
- 110. Деревья Отсортированный массив хорош, поскольку позволяет бинарный поиск за время O(logN) Добавление нового элемента при этом
- 111. Граф Рассмотрим множество A из N элементов и множество B, состоящее из пар элементов множества A
- 112. Граф Это множество называется графом и может быть представлено в виде 1 0 2 3 4
- 113. Граф Элементы A – узлы графа Элементы B – ребра графа. Ребро задается своим начальным и
- 114. Граф Граф называется неориентированным, если для любого ребра {a,b}, входящего в граф, ребро {b,a} тоже входит
- 115. Неориентированный граф? 1 0 2 3 4
- 116. Неориентированный граф? 1 0 2 3 4
- 117. Упрощенное изображение неориентированного графа 1 0 2 3 4
- 118. Неориентированные графы Неориентированный граф является связным, если из любого узла a можно попасть в любой узел
- 119. Связный граф? 1 0 2 3 4
- 120. Связный граф? 1 0 2 3 4
- 121. Неориентированные графы Неориентированный граф является ациклическим, если в нем не существует маршрутов без повторения ребер, которые
- 122. Ациклический граф? 1 0 2 3 4
- 123. Ациклический граф? 1 0 2 3 4
- 124. Деревья Деревом называется связный ациклический неориентированный граф Если ациклический неориентированный граф – не связный, то это
- 125. Утверждение В любом дереве можно ввести отношение предок-потомок со следующими свойствами Предок соединен с потомком ребром
- 126. Доказательство Возьмем произвольный узел и объявим его корнем. Все соединенные с ним узлы – его потомки
- 127. Иллюстрация
- 128. Дерево Итак, деревом называется контейнер, в котором Элементы связаны отношением предок-потомок У каждого элемента 0 или
- 129. Дерево Корень Листья
- 130. Бинарное дерево Бинарным называется дерево, в котором у каждого элемента не более 2 потомков Один из
- 131. Бинарное дерево Корень Листья
- 132. Бинарное дерево поиска Бинарное дерево называется деревом поиска, если Левый потомок любого элемента и все элементы
- 133. Бинарное дерево поиска
- 134. Бинарное дерево. Поиск 4
- 135. Бинарное дерево. Добавление элемента 2.5 2.5
- 136. Бинарное дерево поиска Как и отсортированный массив, поддерживает поиск за log(N) В отличие от отсортированного массива,
- 137. Сбалансированное дерево Дерево является сбалансированным, если разница между его максимальной и минимальной глубиной (количеством элементов от
- 138. Сбалансированное дерево
- 139. Сбалансированное дерево 2.5
- 140. Несбалансированное дерево 4.5 4.2
- 141. Сбалансированное дерево Дерево должно быть сбалансированным, чтобы поддерживать поиск и добавление элемента за log(N) Существуют различные
- 142. Сбалансированное дерево Варианты: Красно-черные деревья AVL-деревья
- 143. Словари Словарь – структура данных, в которой ключам сопоставляются значения (как в толковом словаре словам сопоставляются
- 144. Словарь Code 4 Test 4 Error 5 Byte 4 File 4 Line 4 Task 4
- 145. Словарь Ключи (в данном случае строковые) отсортированы по алфавиту Значения (в данном случае целочисленные) не влияют
- 146. Пирамиды Пирамида – это бинарное дерево со следующими свойствами Все уровни дерева, возможно кроме последнего, полностью
- 147. Пирамида? 17 16 18 Нет – не заполнен 3-ий уровень
- 148. Пирамида? 11 Да
- 149. Пирамида? 2.5 Нет – на 4-ом уровне заполнен не самый левый элемент
- 150. Пирамида? Да
- 151. Пирамида? 25 17 16 Да
- 152. Пирамида Пирамида называется невозрастающей, если любой родительский элемент больше (либо равен) обоих дочерних элементов Пирамида называется
- 153. Невозрастающая пирамида 11
- 154. Неубывающая пирамида 14 12 23
- 155. Операции над невозрастающей пирамидой Из невозрастающей пирамиды можно извлечь максимальный элемент за время O(logN) так, чтобы
- 156. Извлечение элемента из пирамиды 27 12 20 8 23 7 9 11
- 157. Извлечение элемента из пирамиды 27 Правильный фрагмент Правильный фрагмент Возможно нарушение порядка
- 158. Извлечение элемента из пирамиды 12 20 8 23 7 9 11 27
- 159. Извлечение элемента из пирамиды 12 20 8 23 7 9 11 Правильный фрагмент Правильный фрагмент 27
- 160. Извлечение элемента из пирамиды 12 20 8 23 7 9 11 27
- 161. Извлечение элемента из пирамиды 27 Завершено!
- 162. Добавление элемента в пирамиду 14 11 Возможно нарушение порядка Корректный фрагмент 12 11 8 10 7
- 163. Добавление элемента в пирамиду 14 11 Выбираем максимум 12 11 8 10 7 6
- 164. Добавление элемента в пирамиду 14 11 12 11 8 10 7 6 Корректный фрагмент Корректный фрагмент
- 165. Добавление элемента в пирамиду 14 11 12 11 8 10 7 6 Корректный фрагмент Корректный фрагмент
- 166. Применение пирамиды Пирамида используется в пирамидальной сортировке – построив пирамиду и извлекая из нее элементы, мы
- 167. Хранение пирамиды Мы можем хранить пирамиду как обычное бинарное дерево (каждый узел представляется как структура, состоящая
- 168. Хранение пирамиды Пирамиду можно хранить без выделения дополнительной памяти Для этого пирамида представляется как массив
- 169. Хранение пирамиды Уровень K пирамиды занимает в массиве позиции от 2K-1 до 2K+1-2 Например, уровень 0
- 170. Хранение пирамиды 27 12 20 8 23 7 9 11 27 23 12 20 8 7
- 171. Хранение пирамиды Потомками элемента A[ K ] являются A[ 2 * K + 1 ] –
- 172. Задание Как выглядит код, проверяющий массив на то, что он является невозрастающей пирамидой?
- 173. Стек Стеком называется контейнер, поддерживающий принцип Last In – First Out Мы можем в любой момент
- 174. Стек
- 175. Стек Стек может быть построен на базе практически другого контейнера, например массива Стек ограничивает количество операций
- 176. Очередь Очередь – это контейнер, поддерживающий принцип First In – First Out Существуют операции добавления элемента
- 177. Очередь
- 178. Очередь Очередь также легко реализуется на базе другого контейнера (например, массива)
- 179. Лекция 4. Хэш-таблицы. Понятие о хэш-функции. Идея хэширования.
- 180. Хэш-таблицы. Постановка задачи. Бинарные деревья поиска позволили реализовать поиск элемента в контейнере за O(logN) Это правило
- 181. Хэш-таблицы – прямая адресация Пусть в контейнере планируется хранить целые числа от 0 до 232-1 Для
- 182. Хэш-таблицы – прямая адресация Исходное состояние – значение всех элементов не совпадает с номером, набор пустой
- 183. Хэш-таблицы – прямая адресация 2 Поиск элемента 0 Не совпали – значит, такого нет 7 Поиск
- 184. О достоинствах и недостатках схемы Поиск любого элемента выполняется за фиксированное время (O(1)) Добавление нового элемента
- 185. Идея хэш-функции Обеспечить поиск и добавление элемента за время, равное O(1), возможно, если позиция полностью определяется
- 186. Идея хэш-функции Итак, необходимо, чтобы элемент со значением x сохранялся в позиции h(x). h(x) – хэш-функция
- 187. Пример Рассмотрим контейнер целых чисел Для хранения – массив из 11 элементов h(x) = x %
- 188. Пример хэш-таблицы 52 Добавление элемента 52 % 11 = 8 37 Добавление элемента 37 % 11
- 189. Пример хэш-таблицы 16 Поиск элемента 16 % 11 = 5 19 Поиск элемента 19 % 11
- 190. Пример хэш-таблицы 37 Поиск элемента 37 % 11 = 4 Найден
- 191. Коллизии Мы не хотим выделять память на каждое возможное значение элемента (реально встретившихся значений обычно много
- 192. Коллизии Значит, возможна ситуация, когда мы пытаемся добавить элемент, а место занято. Эта ситуация называется коллизией
- 193. Пример коллизии 96 Добавление элемента 96 % 11 = 8 Коллизия
- 194. Необходимо разрешение коллизий Правила разрешения коллизий должны определять, что делать при коллизии (куда поместить полученный элемент)
- 195. Разрешение коллизий: хранение списков Будем хранить в каждом элементе массива не значение, а список значений Новое
- 196. Разрешение коллизий: хранение списков, h(x) = x % 11, добавление 45 93 51 12
- 197. 17 29 89 12 45 93 51 12 Разрешение коллизий: хранение списков, h(x) = x %
- 198. Разрешение коллизий хранением списков В наихудшем случае время поиска O(N) – если возникнет один список Время
- 199. Разрешение коллизий хранением списков Предположим, что Вероятности попадания элемента в любую ячейку равны Количество ячеек M
- 200. Разрешение коллизий методом сдвига Достаточно легко удалить элемент – просто удаляем его из списка. Время удаления
- 201. Разрешение коллизий методом сдвига Часто хочется упростить структуру и не хранить массив списков В этом случае
- 202. Разрешение коллизий методом сдвига Если мы не можем положить элемент в нужную ячейку – пытаемся положить
- 203. Почему линейное исследование? При попытке № i поместить значение k мы пробуем ячейку h( k ,
- 204. Разрешение коллизий методом сдвига , h(x) = x % 11, добавление 45 12 95 24
- 205. Разрешение коллизий методом сдвига , h(x) = x % 11, поиск 45 24 95 17 95
- 206. Разрешение коллизий методом сдвига Метод работает, только если длина массива не меньше числа элементов Когда элементов
- 207. Разрешение коллизий: квадратичное исследование При попытке № i поместить значение k мы пробуем ячейку h( k
- 208. Квадратичное исследование, h(x, i) = ( x % 11 + i + i2 ) % 11)
- 209. 45 12 95 17 95 89 12 24 Не найден Найден! Квадратичное исследование, h(x, i) =
- 210. Квадратичное исследование, h(x, i) = ( x % 11 + i + i2 ) % 11)
- 211. Квадратичное исследование, h(x, i) =( x % 8 + i / 2+ i2 / 2) %
- 212. Выводы: Квадратичное исследование менее подвержено опасности кластеризации, чем линейное. При квадратичном исследовании важен выбор функции так,
- 213. Двойное хэширование Методы линейного и квадратичного исследования неприемлемы при большом числе коллизий Если мы добавляем N
- 214. Двойное хэширование Идея двойного хэширования в том, чтобы использовать вторую хэш-функцию для определения смещения h( k
- 215. Варианты: m – степень двойки h2(k) – нечетная для любого k, h2(k)= 2h3(k)+1 m – простое
- 216. Двойное хэширование, h1(x) = x % 11, h2(x) = 1 + x % 10 95 18
- 217. 73 52 24 95 17 52 18 33 Не найден Найден! Двойное хэширование, h1(x) = x
- 218. Двойное хэширование: выводы Двойное хэширование – лучший из методов с открытой адресацией (т.е. с хранением значений
- 219. 18 73 52 Удаление элементов из хэш-таблицы с открытой адресацией h1(x) = x % 11, h2(x)
- 220. Удаление элементов Просто удалить элемент нельзя – нарушится поиск тех, которые были добавлены после него Можно
- 221. DELETED 18 73 52 Удаление элементов из хэш-таблицы с открытой адресацией h1(x) = x % 11,
- 222. Удаление элементов Специальное значение Deleted позволяет удалить элемент Но позиция в таблице после этого остается занятой
- 223. Выбор хэш-функции Мы будем считать, что элементы массива – целые числа Если они не целые числа
- 224. Пример: строки ANSI «Alexey» В памяти - 108(‘l’) 101(‘e’) 101(‘e’) 120(‘x’) 121(‘y’) 0 65(‘A’) В числовой
- 225. Варианты хэш-функции Метод деления Метод умножения Универсальное хэширование
- 226. Метод деления h( k ) = k % m m – число позиций в хэш-таблице Преимущество
- 227. Метод умножения h( k ) = [ m ( kA - [ kA ] ) ]
- 228. Метод умножения Можно избежать вещественных вычислений. m=2w, A=s/2w, 0 h( k ) = [ m (
- 229. Универсальное хэширование Ясно, что для любой хэш-функции можно подобрать значения, при которых она работает плохо (коллизии
- 230. Универсальное хэширование Идея универсального хэширования – случайный выбор хэш-функции так, чтобы для любой сгенерированной злоумышленником последовательности
- 231. Универсальное хэширование Множество N хэш-функций hn(k) универсально, если для любых ключей k, l существует не больше
- 232. Универсальное хэширование Пример функции Пусть p – простое число, ключи – от 0 до p –
- 233. Другие применения хэш-функций Криптография. Криптография с закрытым ключом – зная ключ, можно построить хэш-функции для шифрования
- 234. Лабораторная работа №2. Реализация контейнеров данных.
- 235. Реализация контейнеров данных Предлагаются индивидуальные варианты заданий, связанные с реализацией контейнеров Предпочтительна реализация контейнера, сопровождаемая подготовкой
- 236. Варианты заданий Реализовать класс списка с операциями добавления элемента, удаления элемента, доступа к первому элементу, доступа
- 237. Варианты заданий Реализовать класс массива элементов, значение которых может быть 0 или 1, с выделением 1
- 238. Варианты заданий повышенной сложности Реализовать класс АВЛ-дерева с операциями добавления элемента, удаления элемента, доступа к первому
- 239. Тема 2.1. Библиотека STL как пример стандартной библиотеки языка программирования. Использование контейнеров и алгоритмов STL.
- 240. Лекция 5. Шаблоны и пространства имен в C++
- 241. Шаблоны Рассмотрим функцию сортировки массива целых чисел и функцию сортировки телефонной книги (программа Sort). Они очень
- 242. Шаблоны Для решения этой проблемы придуманы шаблоны. Шаблон – это «заготовка» функции, которая может быть конкретизирована
- 243. SortTemplates Мы определили заготовку функции сортировки для произвольного типа. Когда компилятор видит попытку вызова Sort для
- 244. Шаблоны Параметром шаблона может быть не только тип данных, но и число (режим работы функции) Пример
- 245. Синтаксис определения функции-шаблона template имя функции( параметры функции) { тело функции } Для параметра шаблона указывается
- 246. Вопрос Медленнее ли работа шаблона, чем работа нормальной функции?
- 247. Ответ Нет, не медленнее – это механизм уровня компиляции. Еще при сборке шаблон заменяется на несколько
- 248. Шаблоны классов Точно так же, как функция, шаблоном может быть и класс. Шаблоны классов часто используются
- 249. Синтаксис определения класса-шаблона template class имя { //Определение класса. В нем могут //использоваться параметры шаблона …
- 250. Пример шаблона класса Класс комплексного числа, работающего с типами double, float - ComplexTemplate
- 251. Задание Написать класс вектора, который сможет работать как с вещественными, так и с комплексными числами. Также
- 252. Частичная спецификация шаблона Предположим, некоторый класс работает одинаково для всех типов данных При этом для одного
- 253. Частичная спецификация шаблона template class TemplateClass { }; template class TemplateClass { };
- 254. Пространства имен В большой программе велик риск, что имена классов и функций будут повторяться. Для борьбы
- 255. Пространства имен. Пример namespace N1 { class A { …}; } namespace N2 { class A
- 256. Пространства имен Как видно на предыдущем слайде, заключив классы в пространство имен, мы можем не бояться
- 257. Лекция 6. Контейнеры STL – общие принципы
- 258. Основные контейнеры vector – массив list – список valarray – вектор (массив с арифметическими операциями) set
- 259. Требования к реализации контейнеров Независимость реализации контейнера от типа используемых данных (могут предъявляться минимальные требования к
- 260. Требования к реализации контейнеров Возможность единообразной реализации операций (например, перебора) для нескольких контейнеров Константность логически константных
- 261. Решения Для обеспечения независимости от типа элемента используем шаблоны C++ Для обеспечения независимости контейнера от конкретного
- 262. Решения Для возможности сортировки данных одного типа по разным критериям контейнер не использует оператор сравнения у
- 263. Решения Для обеспечения константности логически константных операций, устойчивости к многопоточности и возможности единообразной работы с несколькими
- 264. Итераторы Итератором называется программный объект со следующими свойствами Объект связан с определенным объектом-контейнером и указывает на
- 265. Итераторы Каждому типу контейнера соответствует свой тип итератора. Для контейнеров STL этот тип можно получить как
- 266. Итераторы. Контрольный массив Есть массив в стиле C int a[100]; Существует ли итератор у этого конттейнера?
- 267. Итераторы. Контрольный вопрос. Да! Это переменная типа int*, указывающая на любой его элемент. Указывает на элемент
- 268. Простейшее применение итераторов Практически все контейнеры STL имеют Метод begin() – возвращает итератор, указывающий на первый
- 269. Простейшее применение итераторов void Print ( T element ) void PrintAll( A container ) { for
- 270. Простейшее применение итераторов Код работоспособен для любого контейнера STL и любого типа элемента (если для него
- 271. Классификация итераторов Итератор всегда имеет оператор ++ Кроме того, он может иметь (а может – не
- 272. Классификация итераторов Мы хотим иметь возможность применять итераторы для чтения данных из потока ввода (например, из
- 273. Классификация итераторов Мы хотим использовать итераторы для записи данных в файл. std::ofstream file_out( “out.txt” ); std::ostream_iterator
- 274. Классификация итераторов Любой итератор контейнера имеет Операцию доступа к объекту на чтение Операцию доступа к объекту
- 275. Классификация итераторов Если к набору операций однонаправленного итератора добавить операцию – (переход к предыдущему элементу), мы
- 276. Классификация итераторов Если к набору операций двунаправленного итератора добавить возможность сдвига на N позиций вперед или
- 277. Вопрос Ясно, что технически возможно реализовать сдвиг по списку или бинарному дереву поиска на N позиций
- 278. Ответ Сдвиг на N позиций работал бы за время O(N) для списка и бинарного дерева Пользователь
- 279. Классификация итераторов
- 280. Компараторы Вспомним алгоритм сортировки пузырьком void sort ( T* A , int N ) { for
- 281. Компараторы Мы можем применить этот алгоритм для любого типа, имеющего оператор сравнения Предположим, у нас есть
- 282. Компараторы Использовать приведенный выше код мы не сможем Что делать?
- 283. Компараторы Мы должны передать критерий сортировки как параметр функции или параметр шаблона Значит, критерий сортировки может
- 284. Компараторы template void sort ( T* A , int N , TComparator comparator ) { for
- 285. Компараторы class UsualComparator { bool operator()( T a , T b ) { return a }
- 286. Компараторы Код на предыдущем слайде приводит к обычной сортировке с использованием оператора сравнения. В функцию sort
- 287. Компараторы Мы можем реализовать другие типы компараторов и создать другие объекты компараторы Передавая их в качестве
- 288. Компараторы Компаратор можно передать и контейнеру, нуждающемуся в упорядочении своих элементов (неубывающей пирамиде, дереву поиска, словарю).
- 289. Аллокаторы Компараторы позволяют настроить метод сравнения объекта Аналогично аллокаторы позволяют настроить метод выделения и освобождения памяти
- 290. Лекция 7. Контейнеры STL - реализация
- 291. Массивы в STL - std::vector Реализует массив Тип элемента задается как параметр шаблона. Тип элемента должен
- 292. Массивы в STL - std::vector Метод at – доступ по индексу с проверкой корректности, также за
- 293. Массивы в STL - std::vector std::vector определяет тип итератора std::vector ::iterator. Этот итератор является итератором с
- 294. Массивы в STL - std::vector
- 295. Массивы в STL - std::vector Для размещения элементов в памяти std::vector использует аллокатор. Тип аллокатора задается
- 296. Списки в STL – std::list std::list реализует стратегию работы со списками независимо от типа хранимых элементов.
- 297. Списки в STL – std::list Методы front(), back() предоставляют доступ к первому и последнему элементу контейнера
- 298. Списки в STL – std::list std::list определяет тип итератора std::list ::iterator. Этот итератор является двунаправленным итератором
- 299. Списки в STL – std::list Используются аллокаторыИспользуются аллокаторы так же, как в массиве. Операции вставки элемента
- 300. Бинарное дерево поиска в STL – std::set std::set реализует работу с бинарным деревом поиска независимо от
- 301. Бинарное дерево поиска в STL – std::set Бинарный поиск реализуется методом find, работает за время O(logN)
- 302. Бинарное дерево поиска в STL – std::set Добавление элемента реализуется методом insert. Результатом добавления является итератор,
- 303. Бинарное дерево поиска в STL – std::set std::set определяет тип итератора std::set ::iterator. Этот итератор является
- 304. Бинарное дерево поиска в STL – std::set Используются аллокаторыИспользуются аллокаторы так же, как в массиве Хранить
- 305. std::multi_set Набор операций аналогичен std::set find возвращает первый элемент, равный данному insert возвращает только итератор. Успех
- 306. std::multi_set Перебор элементов, равных данному: for ( TContainer::iterator iter = Container.lower_bound( x ) ; iter !=
- 307. Словарь в STL – std::map std::map реализует работу со словарем, имеющим произвольный тип ключа и произвольный
- 308. Словарь в STL – std::map Методы find, lower_bound, upper_bound, equal_range, insert, erase – аналогичны std::set Доступ
- 309. Словарь в STL – std::map std::map определяет тип итератора std::map ::iterator. Этот итератор является двунаправленным итератором
- 310. Словарь в STL – std::map Используются аллокаторыИспользуются аллокаторы так же, как в массиве Хранить несколько значений
- 311. std::multi_map Аналогичен std::map Не реализуется обращение по индексу map[ key ]. Как и в stdКак и
- 312. Двусторонняя очередь – std::deque std::deque реализует поведение двусторонней очереди std::deque позволяет задать тип элемента как параметр
- 313. Двусторонняя очередь – std::deque Быстрый доступ по индексу – как в std::vector Deq[ i ] Deq.at(
- 314. Двусторонняя очередь – std::deque Методы front(), back() предоставляют доступ к первому и последнему элементу контейнера за
- 315. Двусторонняя очередь – std::deque std::deque определяет тип итератора std::deque ::iterator. Этот итератор является итератором с произвольным
- 316. Двусторонняя очередь – std::deque Для размещения элементов в памяти std::deque использует аллокаторДля размещения элементов в памяти
- 317. Очередь – std::queue Реализует очередь Тип элемента задается как параметр шаблона. Необходимо существование конструктора по умолчанию
- 318. Очередь – std::queue Набор операций включает методы push (добавить элемент в конец очереди) pop (извлечь элемент
- 319. Очередь – std::queue Очередь может эффективно работать при различных стратегиях размещения данных в памяти, поэтому не
- 320. Очередь – std::queue Тип внутреннего контейнера задается как второй параметр шаблона std::queue. Этот внутренний контейнер должен
- 321. Стек – std::stack Реализует стек Тип элемента задается как параметр шаблона. Необходимо существование конструктора по умолчанию
- 322. Стек – std::stack Набор операций включает push (добавить элемент) pop (извлечь последний добавленный элемент) back (доступ
- 323. Стек – std::stack Стек может быть реализован на базе различных контейнеров. Базовый контейнер может быть задан
- 324. Очередь с приоритетами – std::priority_queue Очередь с приоритетами – это очередь, в которой элементам сопоставлен приоритет
- 325. Очередь с приоритетами – std::priority_queue Тип элемента задается как первый параметр шаблона. Необходимо существование конструктора по
- 326. Очередь с приоритетами – std::priority_queue Набор операций включает push (добавить элемент) pop (извлечь элемент с максимальным
- 327. Очередь с приоритетами – std::priority_queue Как реализуется очередь с приоритетами?
- 328. Очередь с приоритетами – std::priority_queue Очередь с приоритетами строится на базе невозрастающей пирамиды Используется хранение пирамиды
- 329. Очередь с приоритетами – std::priority_queue Для хранения «пирамиды как массива» может использоваться любой контейнер, имеющий итератор
- 330. Хэш-таблица – std::hash_map Класс std::hash_map реализует хэш-таблицу Как и stdКак и std::Как и std::map, std::hash_map хранит
- 331. Хэш-таблица – std::hash_map За вычисление хэш-функции и проверки на равенство отвечает специальный объект – хэш-компаратор. Он
- 332. Хэш-таблица – std::hash_map Необходимый размер хэш-таблицы вычисляется и динамически меняется. Задаваемая пользователем хэш-функция должна лишь вычислять
- 333. Не совсем контейнеры Существуют объекты библиотеки STL, которые не являются контейнерами но реализуют определенные возможности контейнеров
- 334. Строка – std::basic_string Строка является массивом символов Для представления символов могут использоваться различные типы данных (char,
- 335. Строка как массив std::basic_string определяет тип итераторов с произвольным доступом – std::basic_string ::iterator. std::basic_string имеет методы
- 336. Отличия строки std::basic_string требует от используемого типа символов расширенного набора операций См. char_traits std::basic_string определяет дополнительные
- 337. Вектор – std::val_array Есть доступ по индексу [] Есть метод size Реализует маетматические операции над векторами
- 338. Битовый массив – std::bit_set Возможен доступ к биту с помощью оператора [] Дополнительно реализуются побитовые операции
- 339. Потоки ввода-вывода и итераторы Основным инструментом ввода-вывода в STL являются потоки ввода-вывода Поток ввода – это
- 340. Потоки ввода-вывода и итераторы Поток вывода – это устройство, в которое можно вывести значение того или
- 341. Потоки ввода-вывода и итераторы Если мы читаем из потока или записываем в поток однотипные значения, целесообразно
- 342. Задание Напишите программу, читающую набор целых чисел из файла и записывающую их в другой файл Используйте
- 343. Лабораторная работа №3. Использование стандартных контейнеров данных
- 344. Задание Разработать программу на языке C++, реализующую функциональность в соответствии с вариантом задания. Настоятельно рекомендуется использование
- 345. Варианты задания Реализовать программу, хранящую совокупность многоугольников на плоскости и позволяющую организовать быстрый поиск многоугольников, попадающих
- 346. Варианты задания Реализовать программу, хранящую совокупность отрезков на плоскости и поддерживающую добавление отрезка и быстрый поиск
- 347. Варианты задания Реализовать программу, хранящую множество шариков, летающих в комнате, поддерживающих добавление и удаление шарика и
- 348. Варианты задания Реализовать систему регистрации сделок на бирже. Для каждой сделки указывается, какой товар продан, в
- 349. Варианты задания Реализовать программу электронного магазина, поддерживающую три операции Добавление информации о появлении в продаже очередной
- 350. Варианты задания Реализовать программу, которая получает результаты измерений одной и той же меняющейся величины 10 датчиками.
- 351. Варианты задания При голосовании приходят результаты в виде «На участке № такой-то такая-то партия получила столько-то
- 352. Варианты задания Корабли присылают в каждый момент времени данные о своей скорости и направлении и свои
- 353. Варианты задания Завод по сборке автомобилей покупает комплекты комплектующих и производит автомобили из них. Необходимо хранить
- 354. Варианты задания Подразделения фирмы, нуждающиеся в покупке компьютеров, вносят заказы в базу данных. Отдел закупок вносит
- 355. Варианты задания Операционная система хранит базу данных процессов. Процесс имеет постоянный приоритет (константа, задается пользователем) и
- 356. Лекция 8. Стандартные алгоритмы STL. Простейший стандартный алгоритм for_each Возможности применения алгоритмов на примере for_each Другие
- 357. std::for_each Алгоритм std::for_each заключается в вызове заданной функции для каждого элемента контейнера for_each не делает предположений
- 358. std::for_each - пример for_each( v1.begin() , v1.end() , Print ) эквивалентно for ( v1::iterator iter =
- 359. std::for_each В приведенном примере мы вызывали функцию Print, единственным параметром которой был элемент контейнера, для которого
- 360. Пример – вызов функции с несколькими параметрами for ( v1::iterator iter = v1.begin() ; iter !=
- 361. Пример – вызов метода класса с несколькими параметрами for ( v1::iterator iter = v1.begin() ; iter
- 362. std::for_each Ясно, что мы должны уметь применять for_each для таких ситуаций – иначе этот механизм бесполезен
- 363. Шаблоны. Взаимозаменяемость классов и функций for_each – это шаблон функции. Шаблоны C++ являются механизмом времени компиляции.
- 364. Шаблоны. Взаимозаменяемость классов и функций Но это означает, что с точки зрения for_each не важно, что
- 365. Класс-функция class Printer { public: Printer( std::ostream& stream ) :Stream(stream) {} void operator()(int a ) {
- 366. Класс-функция С точки зрения шаблона for_each, объект класса Printer – полный аналог функции, имеющей один параметр.
- 367. Класс-функция Printer printer( stream1 ); std::for_each( v1.begin() , v1.end() , printer ); эквивалентно for ( v1::iterator
- 368. Класс-функция И это уже эквивалентно for ( v1::iterator iter = v1.begin() ; iter != v1.end() ;
- 369. Вызов метода класса for ( v1::iterator iter = v1.begin() ; iter != v1.end() ; iter++ )
- 370. Вызов метода класса class ProcessorAdapter { public: ProcessorAdapter ( Processor& processor ) :Proc( processor ) {}
- 371. Вызов метода класса ProcessorAdapter adapter( processor ); std::for_each( int_vector.begin() , int_vector.end() , adapter ); эквивалентно for
- 372. Возвращаемое значение for_each Функция for_each возвращает тот объект, метод operator() которого она вызвала для всех элементов
- 373. Задание Реализуйте поиск максимума массива вещественных чисел через for_each
- 374. Решение class MaxSearch { public: MaxSearch( double first ) :CurMax( first ) {} void operatorI()( double
- 375. Решение std::vector double _vector; … MaxSearch search(*double _vector.begin() ); search = std::for_each( double_vector.begin() , double_vector.end() ,
- 376. Вызовы функций с параметрами – готовые механизмы Если мы хотим вызвать для всех методов контейнера функцию
- 377. Вызовы функций с параметрами – готовые механизмы Другие готовые механизмы для вызова функций и методов классов
- 378. Методы поиска Все методы принимают два итератора (указывающие на начало последовательности и на следующий за последним
- 379. Методы поиска find – поиск равного данному find_if – поиск соответствующего условию find_first_of – поиск в
- 380. Задание Как найти первый символ, больший квадрата предыдущего? Предложите два метода
- 381. Поиск нарушения порядка в массиве в стиле C bool Test( double a , double b )
- 382. Методы подсчета count – подсчет элементов, равных данному count_if – подсчет количества элементов, соответствующих условию Входные
- 383. Методы подсчета Фиксированный тип – не годится. Вариант: template TIterator::difference_type count( TIterator begin , TIterator end
- 384. Методы подсчета В данном случае в классе TIterator должно быть что-то вроде class TIterator { public:
- 385. Методы подсчета В этом случае мы не сможем использовать указатель как итератор массива в стиле C
- 386. Методы подсчета - решение Определим шаблонный класс iterator_traits вида template class iterator_traits { typedef TIterator::difference_type difference_type;
- 387. Методы подсчета - решение template iterator_traits ::difference_type count( TIterator begin , TIterator end , TValue value
- 388. Методы подсчета - решение Внешне кажется, что ничего не изменилось iterator_traits ::difference_type это эквивалент TIterator::difference_type Но
- 389. Методы подсчета - решение Определим частичную спецификацию шаблона iterator_traits вида template class iterator_traits { typedef int
- 390. Методы подсчета - решение int A[ 5 ]; … int n = std::count( A , A+5
- 391. Минимумы и максимумы max_element и min_element ищут максимальный или минимальный элемент последовательности Принимают итераторы, указывающие на
- 392. Сравнение последовательностей equal – проверка на равенство mismatch – поиск первого различия lexicographical_compare Задается объект-компаратор Типы
- 393. Сравнение последовательностей В одном массиве строки, в другом числа Нужно проверить, что длина строки номер i
- 394. Подпоследовательности search - поиск первого вхождения подпоследовательности в последовательность. Задаются 4 итератора и компаратор find_end -
- 395. Задание Предложите два способа поиска трех нечетных чисел подряд – с помощью search и search_n
- 396. Копирование сopy копирует одну последовательность в другую Задаются 3 итератора – начало и конец первой последовательности
- 397. Копирование vector2.resize( vector1.size() ); std::copy( vector1.begin() , vector1.end() , vector2.begin() ); или std::copy( vector1.begin() , vector1.end()
- 398. Вопрос Корректен ли код, копирующий 5 первых элементов последовательности в конец? const int N = …;
- 399. Копирование Не корректен, если N Если есть двунаправленный итератор, можно использовать const int N = …;
- 400. Преобразование Преобразование последовательности double TransformT( double c ) { return 1.8 * c + 32; }
- 401. Преобразование двух последовательностей Результат преобразования записывается в третью. double Fib( double a , double b )
- 402. Удаление std::remove удаляет из последовательности, заданной двумя итераторами, элементы, равные данному std::remove не может изменить количество
- 403. Удаление
- 404. Удаление Результатом remove является итератор, указывающий на элемент, следующий за последним оставшимся После remove следует специфичным
- 405. Удаление remove_if – удаление элементов, соответствующих условию Задача: удалить первые 10 отрицательных чисел unique – встретив
- 406. Удаление remove_copy – копирует элементы во вторую последовательность, удаляя равные данному remove_copy_if - копирует элементы во
- 407. Замена Аналогично удалению, но заменяет на заданное значение std:replace std::replace_if std::replace_copy std::replace_copy_if
- 408. Заполнение std::fill – принимает начальный и конечный итераторы, значение std::fill_n – принимает итератор вывода, значение и
- 409. Заполнение. Примеры std::vector int_vector; int_vector.resize( 100 ); std::fill( int_vector.begin() , int_vector.end() , 0 ); std::vector int_vector;
- 410. Заполнение Можно задать не значение, а функцию (которая будет вызвана для каждого элемента контейнера и ее
- 411. Заполнение class FibonacciGenerator { public: FibonacciGenerator() :First( 0 ),Second( 1 ) {} int operator()() { int
- 412. Перестановки std::swap – меняет местами два значения, принимая ссылки std::iter_swap – меняет местами значения, на которые
- 413. Перестановки Какой иетратор требуется для выполнения swap_ranges?
- 414. Перестановки std::reverse, std::reverse_copy – переставляет в обратном порядке std::rotate, std::rotate_copy – циклический сдвиг std::random_shuffle – случайные
- 415. Лексикографические перестановки abc acb bac bca cab cba
- 416. Лексикографические перестановки prev_permutation – предыдущая перестановка next_permutation – следующая перестановка Принимает два двунаправленных итератора и объект-компаратор
- 417. Сортировки std::sort – сортировка (обычно быстрая сортировка) std::stable_sort – сортировка с сохранением порядка равных элементов std::partial_sort
- 418. Сортировки vector2.resize( 10 ); std::partial_sort_copy( vector1.begin() , vector1.end() , vector2.begin() , vector2.end() );
- 419. Сортировки std::nth_element – поиск порядковой статистики (гарантирует, что на позиции N будет тот элемент, который был
- 420. Сортировки class Student { public: double AverageGrade() const; }; class StudentComparator { public: bool operator( const
- 421. Бинарный поиск std::binary_search – бинарный поиск в отсортированной последовательности (true, если найден) std::lower_bound - первый элемент,
- 422. Слияние std::merge – объединяет две отсортированные последовательности в одну std::inplace_merge – объединение двух отсортированных половин последовательности
- 423. Слияние for ( int k = 1 ; k { for ( int i = 0
- 424. Разделение Делим последовательность на группы, соответствующие условию и не соответствующие ему - partition Если нужно сохранить
- 425. Пирамиды std::make_heap – расставляет элементы в последовательности так, как они лежали бы в невозрастающей пирамиде в
- 426. make_heap 6 7 5 9 4 8 Исходная последовательность Измененная последовательность 3 2 8 7 9
- 427. Вопрос Как реализовать пирамидальную сортировку вектора?
- 428. Пирамидальная сортировка std::make_heap ( vec.begin() , vec.end() ); std::sort_heap( vec.begin() , vec.end() )
- 429. Множественные операции Реализуются над отсортированными последовательностями std::includes – проверка включения std::set_union - объединение std::set_intersection - пересечение
- 430. Лабораторная работа №4. Использование стандартных алгоритмов STL.
- 431. Задание Разработать программу на языке C++, реализующую функциональность в соответствии с вариантом задания. Настоятельно рекомендуется использование
- 432. Варианты задания Реализовать программу хранения массива геометрических фигур в двумерном пространстве. Фигура – это окружность или
- 433. Варианты задания Реализовать программу, хранящую в отсортированном массиве список пользователей операционной системы с информацией об имени
- 434. Варианты задания Разработайте программу, хранящую базу данных телефонной компании (фамилия, номер, остаток денег на счету) и
- 435. Варианты задания Реализуйте программу, заполняющую массив фиксированной длины прочитанными из файла значениями или случайными значениями (по
- 436. Варианты задания Реализуйте программу, считывающие из двух файлов два набора строчек и проверяющую их на совпадение.
- 437. Варианты задания База данных телефонной компании реализована в форме отсортированного массива. Периодически приходит дополнение к базе
- 438. Варианты задания Прочитайте из файла последовательность чисел и выведите все возможные их перестановки в лексикографическом порядке
- 440. Скачать презентацию
Слайд 2Введение
В рамках курса будут изучаться
Алгоритмы сортировки и поиска
Контейнеры данных
Необходимо освоить
Реализацию алгоритмов и
Введение
В рамках курса будут изучаться
Алгоритмы сортировки и поиска
Контейнеры данных
Необходимо освоить
Реализацию алгоритмов и

Слайд 3Введение
Курс разрабатывался, исходя из использования языка программирования C++
Допускается использование других объектно-ориентированных языков
Введение
Курс разрабатывался, исходя из использования языка программирования C++
Допускается использование других объектно-ориентированных языков

Слайд 4Введение
Стандартная схема сдачи курса
два задания на разработку алгоритмов
одно задание на разработку контейнера
Введение
Стандартная схема сдачи курса
два задания на разработку алгоритмов
одно задание на разработку контейнера

Слайд 5Введение
Альтернативная схема сдачи курса
Есть специальное задание для одного-двоих разработчиков. Желательно знание языка
Введение
Альтернативная схема сдачи курса
Есть специальное задание для одного-двоих разработчиков. Желательно знание языка

Слайд 6Тема 1.1. Вычислительная сложность алгоритмов. Алгоритмы сортировки и поиска
Тема 1.1. Вычислительная сложность алгоритмов. Алгоритмы сортировки и поиска

Слайд 7Лекция 1. Понятие вычислительной сложности алгоритма
Время выполнения программой той или иной вычислительно
Лекция 1. Понятие вычислительной сложности алгоритма
Время выполнения программой той или иной вычислительно

Слайд 8Время работы программы
Время работы программы зависит от
Алгоритма
Числа обрабатываемых элементов
Конкретного набора элементов
Характеристик компьютера
Особенностей
Время работы программы
Время работы программы зависит от
Алгоритма
Числа обрабатываемых элементов
Конкретного набора элементов
Характеристик компьютера
Особенностей

Слайд 9Время работы программы
Рассмотрим несколько программ, выполняемых на одной машине в одинаковых условиях
Время работы программы
Рассмотрим несколько программ, выполняемых на одной машине в одинаковых условиях

Слайд 10Изменение времени работы
Изменение времени работы

Слайд 11Время работы программы
Можно заметить, что при больших N существенно различие между первыми
Время работы программы
Можно заметить, что при больших N существенно различие между первыми

Слайд 12Утверждение
Пусть компьютер соответствует принципу адресности фон Неймана (имеет оперативную память, время обращения
Утверждение
Пусть компьютер соответствует принципу адресности фон Неймана (имеет оперативную память, время обращения

Слайд 13Утверждение
Пусть компьютер имеет примерно соответствующий общепринятому набор команд (т.е. в нем нет
Утверждение
Пусть компьютер имеет примерно соответствующий общепринятому набор команд (т.е. в нем нет

Слайд 14Утверждение
Тогда для большинства задач порядок роста времени работы программы в зависимости от
Утверждение
Тогда для большинства задач порядок роста времени работы программы в зависимости от

Слайд 15Выводы
При разработке программы невозможно точно определить время ее работы в будущем.
Для практических
Выводы
При разработке программы невозможно точно определить время ее работы в будущем.
Для практических

Слайд 16Выводы
Исследование вычислительной сложности алгоритма возможно без знания деталей его реализации на конкретном
Выводы
Исследование вычислительной сложности алгоритма возможно без знания деталей его реализации на конкретном

Слайд 17Асимптотическое поведение функции
Говорят, что
если
Асимптотическое поведение функции
Говорят, что
если

Слайд 18Асимптотическое поведение функции
Говорят, что
если
Асимптотическое поведение функции
Говорят, что
если

Слайд 19Асимптотическое поведение функции
Верно, что
Асимптотическое поведение функции
Верно, что

Слайд 20Асимптотическое поведение функции. Примеры
Асимптотическое поведение функции. Примеры

Слайд 21Асимптотическое поведение функции
Для исследования алгоритма работы достаточно выяснить асимптотическое поведение функции, задающей
Асимптотическое поведение функции
Для исследования алгоритма работы достаточно выяснить асимптотическое поведение функции, задающей

Слайд 22Асимптотическое поведение функции.
мы можем пренебрегать постоянными коэффициентами и меньшими по порядку добавками
Асимптотическое поведение функции.
мы можем пренебрегать постоянными коэффициентами и меньшими по порядку добавками

Слайд 23Пример
max = 0;
for ( i = 0 ; i < n ;
Пример
max = 0;
for ( i = 0 ; i < n ;

Слайд 24Пример. Команды процессора
SET R1,0 c1
LOAD R2, <адрес n> c2
LOAD R3, <адрес A> c2
SET R4, 0; c1
start:
Пример. Команды процессора
SET R1,0 c1
LOAD R2, <адрес n> c2
LOAD R3, <адрес A> c2
SET R4, 0; c1
start:

Слайд 25Пример:
Время работы программы (k – количество раз, когда условие выполнено, 0<=k<=n)
T=2с1+2с2+n(2с3+2с4+c2+2с5+c6)+kc1+c7
2с1+2с2+c7+n(2с3+2с4+c2+2с5+c6)<=T
T<=2с1+2с2+c7 +n(2с3+2с4+c2+c1+2с5+c6)
T=O(n)
Пример:
Время работы программы (k – количество раз, когда условие выполнено, 0<=k<=n)
T=2с1+2с2+n(2с3+2с4+c2+2с5+c6)+kc1+c7
2с1+2с2+c7+n(2с3+2с4+c2+2с5+c6)<=T
T<=2с1+2с2+c7 +n(2с3+2с4+c2+c1+2с5+c6)
T=O(n)

Слайд 26Пример
max = 0;
for ( i = 0 ; i < n ;
Пример
max = 0;
for ( i = 0 ; i < n ;

Слайд 27Вычислительная сложность алгоритма
Часто время работы алгоритма зависит не только от размера входных
Вычислительная сложность алгоритма
Часто время работы алгоритма зависит не только от размера входных

Слайд 28Вычислительная сложность алгоритма
Часто асимптотическая сложность алгоритма для средних и наихудших входных данных
Вычислительная сложность алгоритма
Часто асимптотическая сложность алгоритма для средних и наихудших входных данных

Слайд 29Вычислительная сложность алгоритма
Существуют алгоритмы (например, QuickSort), вычислительная сложность которых отличается в среднем
Вычислительная сложность алгоритма
Существуют алгоритмы (например, QuickSort), вычислительная сложность которых отличается в среднем

Слайд 30Вычислительная сложность алгоритма
Вычислительная сложность алгоритма в наилучшем случае обсуждается реже
Подумайте, не можете
Вычислительная сложность алгоритма
Вычислительная сложность алгоритма в наилучшем случае обсуждается реже
Подумайте, не можете

Слайд 31Выводы
Порядок роста времени выполнения программы, как правило, определяется алгоритмом
Ключевая характеристика алгоритма
Выводы
Порядок роста времени выполнения программы, как правило, определяется алгоритмом
Ключевая характеристика алгоритма

Слайд 32Лекция 2. Понятие сортировки и поиска. Обзор основных алгоритмов.
Линейный поиск в массиве
Бинарный
Лекция 2. Понятие сортировки и поиска. Обзор основных алгоритмов.
Линейный поиск в массиве
Бинарный

Слайд 33Методы поиска
Линейный поиск
Бинарный поиск
Другие методы
Методы поиска
Линейный поиск
Бинарный поиск
Другие методы

Слайд 34Линейный поиск в массиве
Пусть есть массив A длины n
Необходимо найти элемент, равный
Линейный поиск в массиве
Пусть есть массив A длины n
Необходимо найти элемент, равный

Слайд 35Линейный поиск в массиве
int result = -1;
int i = 0;
while ( i
Линейный поиск в массиве
int result = -1;
int i = 0;
while ( i

Слайд 36Линейный поиск в массиве
Легко показать, что время работы алгоритма в наихудшем и
Линейный поиск в массиве
Легко показать, что время работы алгоритма в наихудшем и

Слайд 37Бинарный поиск в массиве
В общем случае реализовать поиск с трудоемкостью, меньшей O(n),
Бинарный поиск в массиве
В общем случае реализовать поиск с трудоемкостью, меньшей O(n),

Слайд 38Поиск в отсортированном массиве
17
16
14
11
10
9
8
4
25
23
19
18
3
1
27
17
16
14
11
10
9
8
4
25
23
19
18
3
1
27
18
17
16
14
11
10
9
8
4
25
23
19
18
3
1
27
18
18
17
16
14
11
10
9
8
4
25
23
19
18
3
1
27
18
Поиск в отсортированном массиве
17
16
14
11
10
9
8
4
25
23
19
18
3
1
27
17
16
14
11
10
9
8
4
25
23
19
18
3
1
27
18
17
16
14
11
10
9
8
4
25
23
19
18
3
1
27
18
18
17
16
14
11
10
9
8
4
25
23
19
18
3
1
27
18

Слайд 39Бинарный поиск
Количество сравнений – log2N
Неудобство хранения данных в отсортированном массиве – дорогая
Бинарный поиск
Количество сравнений – log2N
Неудобство хранения данных в отсортированном массиве – дорогая

Слайд 40Поиск
Если мы хотим еще более быстрого поиска – мы должны наложить еще
Поиск
Если мы хотим еще более быстрого поиска – мы должны наложить еще

Слайд 41Поиск минимального элемента
Задача решается за время, равное O(n)
min = 0;
for ( i
Поиск минимального элемента
Задача решается за время, равное O(n)
min = 0;
for ( i

Слайд 42Методы сортировки
Сортировка за O(n2)
Сортировка за O(nlg(n))
Методы сортировки
Сортировка за O(n2)
Сортировка за O(nlg(n))

Слайд 43Сортировка прямым выбором
На первом шаге выбирается минимальный элемент и ставится первым
После этого
Сортировка прямым выбором
На первом шаге выбирается минимальный элемент и ставится первым
После этого

Слайд 44Пример
Демонстрационная программа SortStraightSel
Пример
Демонстрационная программа SortStraightSel

Слайд 45Пример работы
1
Пример работы
1

Слайд 46Сортировка прямым выбором
Мы просматриваем на первом шаге N элементов, на втором –
Сортировка прямым выбором
Мы просматриваем на первом шаге N элементов, на втором –

Слайд 47Сортировка пузырьком
На каждом шаге перебираются все пары соседних элементов, и если меньший
Сортировка пузырьком
На каждом шаге перебираются все пары соседних элементов, и если меньший

Слайд 48Пример
Пример

Слайд 49Пример
Пример

Слайд 50Пример
Пример

Слайд 51Пример
Пример

Слайд 52Сортировка пузырьком
Необходимо N-1 шагов.
На каждом шаге – N-1 сравнение (и, при необходимости,
Сортировка пузырьком
Необходимо N-1 шагов.
На каждом шаге – N-1 сравнение (и, при необходимости,

Слайд 53Быстрые алгоритмы сортировки
Алгоритм сортировки MergeSort
Представим себе, что левая и правая половина массива
Быстрые алгоритмы сортировки
Алгоритм сортировки MergeSort
Представим себе, что левая и правая половина массива

Слайд 54Merge Sort
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
На каждом шаге сравниваются два элемента - один из первой
Merge Sort
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
На каждом шаге сравниваются два элемента - один из первой

Слайд 55Merge Sort
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
Merge Sort
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7

Слайд 56Merge Sort
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
Merge Sort
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7
1
3
6
8
2
4
5
7

Слайд 57Merge Sort
Как же сделать половинки массива отсортированными?
В массиве из двух элементов половинки
Merge Sort
Как же сделать половинки массива отсортированными?
В массиве из двух элементов половинки

Слайд 58Merge Sort. Неотсортированый массив
4 * 2 = 8, N
2 * 4 =
Merge Sort. Неотсортированый массив
4 * 2 = 8, N
2 * 4 =

Слайд 59MergeSort
Алгоритм MergeSort позволяет нам решить задачу сортировки массива за время, пропорциональное Nlog2N
Мы
MergeSort
Алгоритм MergeSort позволяет нам решить задачу сортировки массива за время, пропорциональное Nlog2N
Мы

Слайд 60Пирамидальная сортировка
Основана на помещении значений в пирамиду и извлечении их из пирамиды
Пирамидальная сортировка
Основана на помещении значений в пирамиду и извлечении их из пирамиды

Слайд 61QuickSort
3
7
2
9
1
6
5
7
3
7
9
6
5
2
1
Мы взяли число и разделили массив на две части – значения меньше
QuickSort
3
7
2
9
1
6
5
7
3
7
9
6
5
2
1
Мы взяли число и разделили массив на две части – значения меньше

Слайд 62QuickSort
Как выполнить QuickSort без использования дополнительной памяти?
3
2
9
1
6
5
7
3
2
9
7
6
5
1
3
9
2
7
6
5
1
2
9
3
7
6
5
1
3
2
9
1
6
5
7
QuickSort
Как выполнить QuickSort без использования дополнительной памяти?
3
2
9
1
6
5
7
3
2
9
7
6
5
1
3
9
2
7
6
5
1
2
9
3
7
6
5
1
3
2
9
1
6
5
7

Слайд 63CombSort
В сортировке пузырьком мы сравниваем соседние элементы и меняем их местами
Эффективнее на
CombSort
В сортировке пузырьком мы сравниваем соседние элементы и меняем их местами
Эффективнее на

Слайд 64CombSort
Начальный шаг – длина массива, деленная на 1.3
Уменьшение шага – в 1.3
CombSort
Начальный шаг – длина массива, деленная на 1.3
Уменьшение шага – в 1.3

Слайд 65CombSort
3
2
9
1
6
5
7
Шаг 3 (1 проход)
3
2
9
1
6
7
5
Шаг 5 (1 проход)
2
3
6
5
9
7
1
Шаг 2 (2 прохода)
2
3
5
6
9
7
1
Шаг 1 (2
CombSort
3
2
9
1
6
5
7
Шаг 3 (1 проход)
3
2
9
1
6
7
5
Шаг 5 (1 проход)
2
3
6
5
9
7
1
Шаг 2 (2 прохода)
2
3
5
6
9
7
1
Шаг 1 (2

Слайд 66IntroSort
Сочетание пирамидальной и быстрой сортировки
Быстрая сортировка лучше в среднем случае, пирамидальная –
IntroSort
Сочетание пирамидальной и быстрой сортировки
Быстрая сортировка лучше в среднем случае, пирамидальная –

Слайд 67Методы сортировки за O(N)
Сортировка подсчетом
Цифровая сортировка
Карманная сортировка
Методы сортировки за O(N)
Сортировка подсчетом
Цифровая сортировка
Карманная сортировка

Слайд 68Сортировка подсчетом
Предположим, в массиве лежат значения, равные 0, 1 и 2
Как выполнить
Сортировка подсчетом
Предположим, в массиве лежат значения, равные 0, 1 и 2
Как выполнить

Слайд 69Сортировка подсчетом
0
2
2
0
1
1
0
2
Этап 1 – подсчитываем число 0, единиц и двоек
Сортировка подсчетом
0
2
2
0
1
1
0
2
Этап 1 – подсчитываем число 0, единиц и двоек

Слайд 70Сортировка подсчетом
0
2
2
0
1
1
0
2
Этап 2 – Определяем позиции, на которых должны лежать 0, 1
Сортировка подсчетом
0
2
2
0
1
1
0
2
Этап 2 – Определяем позиции, на которых должны лежать 0, 1

Слайд 71Сортировка подсчетом
0
2
2
0
1
1
0
2
Этап 3 – Создаем новый массив и устанавливаем счетчики
Сортировка подсчетом
0
2
2
0
1
1
0
2
Этап 3 – Создаем новый массив и устанавливаем счетчики

Слайд 72Сортировка подсчетом
0
2
2
0
1
1
0
2
0
2
2
0
1
1
0
2
0
0
2
2
0
1
1
0
2
0
2
Сортировка подсчетом
0
2
2
0
1
1
0
2
0
2
2
0
1
1
0
2
0
0
2
2
0
1
1
0
2
0
2

Слайд 73Сортировка подсчетом
0
2
2
0
1
1
0
2
0
2
0
2
2
0
1
1
0
2
0
2
2
0
2
2
0
1
1
0
2
0
0
2
2
Сортировка подсчетом
0
2
2
0
1
1
0
2
0
2
0
2
2
0
1
1
0
2
0
2
2
0
2
2
0
1
1
0
2
0
0
2
2

Слайд 74Сортировка подсчетом
0
2
2
0
1
1
0
2
0
0
2
2
0
2
2
0
1
1
0
2
0
0
1
2
2
0
2
2
0
1
1
0
2
0
0
1
1
2
2
Сортировка подсчетом
0
2
2
0
1
1
0
2
0
0
2
2
0
2
2
0
1
1
0
2
0
0
1
2
2
0
2
2
0
1
1
0
2
0
0
1
1
2
2

Слайд 75Сортировка подсчетом
0
2
2
0
1
1
0
2
0
0
1
1
2
2
0
2
2
0
1
1
0
2
0
0
0
1
1
2
2
0
2
2
0
1
1
0
2
0
0
0
1
1
2
2
2
Сортировка подсчетом
0
2
2
0
1
1
0
2
0
0
1
1
2
2
0
2
2
0
1
1
0
2
0
0
0
1
1
2
2
0
2
2
0
1
1
0
2
0
0
0
1
1
2
2
2

Слайд 76Сортировка подсчетом
Работает за время O(N+K), где N – число значений в массиве,
Сортировка подсчетом
Работает за время O(N+K), где N – число значений в массиве,

Слайд 77Сортировка подсчетом
3
Дарья
Петрова
3
Андрей
Васильев
3
Иван
Алексеев
2
Алексей
Яковлев
2
Артем
Сидоров
2
Кирилл
Борисов
1
Владимир
Широков
1
Ольга
Иванова
Курс
Имя
Фамилия
Сортировка подсчетом
3
Дарья
Петрова
3
Андрей
Васильев
3
Иван
Алексеев
2
Алексей
Яковлев
2
Артем
Сидоров
2
Кирилл
Борисов
1
Владимир
Широков
1
Ольга
Иванова
Курс
Имя
Фамилия

Слайд 78Сортировка подсчетом
Порядок студентов был алфавитным
Мы отсортировали список по номеру курса. Порядок студентов
Сортировка подсчетом
Порядок студентов был алфавитным
Мы отсортировали список по номеру курса. Порядок студентов

Слайд 79Цифровая сортировка
Для массивов с большим диапазоном значений сортировка подсчетом не годится
Учитывая сохранение
Цифровая сортировка
Для массивов с большим диапазоном значений сортировка подсчетом не годится
Учитывая сохранение

Слайд 80Цифровая сортировка
532
718
191
265
743
489
170
913
2
8
1
5
3
9
0
3
170
191
532
743
913
265
718
489
7
9
3
4
1
6
1
8
913
718
532
743
265
170
489
191
9
7
5
7
2
1
4
1
170
191
265
489
532
718
743
913
Последовательно сортируем по цифрам, начиная с последней.
Трудоемкость O(R*(N+K)), где R –
Цифровая сортировка
532
718
191
265
743
489
170
913
2
8
1
5
3
9
0
3
170
191
532
743
913
265
718
489
7
9
3
4
1
6
1
8
913
718
532
743
265
170
489
191
9
7
5
7
2
1
4
1
170
191
265
489
532
718
743
913
Последовательно сортируем по цифрам, начиная с последней.
Трудоемкость O(R*(N+K)), где R –

Слайд 81Карманная сортировка
Пусть есть массив N вещественных значений от 0 до 1.
Создадим N
Карманная сортировка
Пусть есть массив N вещественных значений от 0 до 1.
Создадим N

Слайд 82Другие алгоритмы сортировки
Быстрая сортировка (Quick Sort)
Сортировка Шелла
Сортировка Шейкером
Сортировка подсчетом
Цифровая сортировка (по младшему
Другие алгоритмы сортировки
Быстрая сортировка (Quick Sort)
Сортировка Шелла
Сортировка Шейкером
Сортировка подсчетом
Цифровая сортировка (по младшему

Слайд 83Другие алгоритмы сортировки
Сортировка расческой (Comb Sort)
Плавная сортировка (Smooth Sort)
Блочная сортировка
Patience sorting
Introsort
Другие алгоритмы сортировки
Сортировка расческой (Comb Sort)
Плавная сортировка (Smooth Sort)
Блочная сортировка
Patience sorting
Introsort

Слайд 84Лабораторная работа №1. Реализация алгоритмов сортировки и поиска.
Лабораторная работа №1. Реализация алгоритмов сортировки и поиска.

Слайд 85Реализация алгоритмов сортировки и поиска
Предлагаются индивидуальные варианты заданий, связанные с реализацией алгоритмов
Предпочтительна
Реализация алгоритмов сортировки и поиска
Предлагаются индивидуальные варианты заданий, связанные с реализацией алгоритмов
Предпочтительна

Слайд 86Варианты заданий
Реализовать бинарный поиск в массиве
Реализовать сортировку Шелла
Реализовать сортировку шейкером
Реализовать сортировку подсчетом
Варианты заданий
Реализовать бинарный поиск в массиве
Реализовать сортировку Шелла
Реализовать сортировку шейкером
Реализовать сортировку подсчетом

Слайд 87Варианты заданий
Реализовать метод IntroSort
Реализовать цифровую сортировку значений типа int по их двоичной
Варианты заданий
Реализовать метод IntroSort
Реализовать цифровую сортировку значений типа int по их двоичной

Слайд 88Варианты заданий повышенной сложности
Реализовать пирамидальную сортировку
Реализовать плавную сортировку (Smooth Sort)
Реализовать быструю сортировку
Варианты заданий повышенной сложности
Реализовать пирамидальную сортировку
Реализовать плавную сортировку (Smooth Sort)
Реализовать быструю сортировку

Слайд 89Варианты заданий повышенной сложности
Реализовать карманную (bucket) сортировку
Реализовать алфавитную сортировку M строк суммарной
Варианты заданий повышенной сложности
Реализовать карманную (bucket) сортировку
Реализовать алфавитную сортировку M строк суммарной

Слайд 90Варианты заданий повышенной сложности
Реализовать поиск i-ой порядковой статистики [i-ого по величине числа]
Варианты заданий повышенной сложности
Реализовать поиск i-ой порядковой статистики [i-ого по величине числа]

Слайд 91Понятие порядковой статистики
2
1
7
4
9
3
0
1-ая порядковая статистика – 0
2-ая – 1
3-я – 2
4-ая –
Понятие порядковой статистики
2
1
7
4
9
3
0
1-ая порядковая статистика – 0
2-ая – 1
3-я – 2
4-ая –

Слайд 92Тема 1.2. Контейнеры данных. Идея хэширования
Тема 1.2. Контейнеры данных. Идея хэширования

Слайд 93Лекция 3. Понятие контейнера данных. Основные типы контейнеров
Лекция 3. Понятие контейнера данных. Основные типы контейнеров

Слайд 94Понятие контейнера данных
Контейнер – программный объект, отвечающий за хранение набора однотипных данных
Понятие контейнера данных
Контейнер – программный объект, отвечающий за хранение набора однотипных данных

Слайд 95Контейнеры в языках программирования
Контейнер может быть
Стандартным объектом языка программирования (массивы фиксированной длины
Контейнеры в языках программирования
Контейнер может быть
Стандартным объектом языка программирования (массивы фиксированной длины

Слайд 96Виды контейнеров
Массивы
Списки
Деревья
Словари
Стеки и очереди
Пирамиды. Очереди с приоритетами
Виды контейнеров
Массивы
Списки
Деревья
Словари
Стеки и очереди
Пирамиды. Очереди с приоритетами

Слайд 97Массивы
Массивом называется контейнер, в котором элементы лежат в памяти компьютера подряд
Размер массива
Массивы
Массивом называется контейнер, в котором элементы лежат в памяти компьютера подряд
Размер массива

Слайд 98Массивы
A[0]
A[1]
A
A[i]
A[N-1]
iM байт
NM байт
Массивы
A[0]
A[1]
A
A[i]
A[N-1]
iM байт
NM байт
![Массивы A[0] A[1] A A[i] A[N-1] iM байт NM байт](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/378472/slide-97.jpg)
Слайд 99Массивы. Ключевые свойства
Быстрый поиск элемента по индексу (за O(1))
На C/C++
&(A[n])=&(A)+n
Медленная вставка элемента
Массивы. Ключевые свойства
Быстрый поиск элемента по индексу (за O(1))
На C/C++
&(A[n])=&(A)+n
Медленная вставка элемента

Слайд 100Массив. Рост сверх планового размера
Массив. Рост сверх планового размера

Слайд 101Массивы
Запрещая «переезд» массива, мы ограничиваем рост его размера
Разрешая «переезд», мы лишаем себя
Массивы
Запрещая «переезд» массива, мы ограничиваем рост его размера
Разрешая «переезд», мы лишаем себя

Слайд 102Пример
std::vector< int > array;
…
int* ptr = &(array[0]); //Запомнили адрес
array.push_back( 7 ); //Добавили элемент
//Возможен «переезд»
std::cout
Пример
std::vector< int > array;
…
int* ptr = &(array[0]); //Запомнили адрес
array.push_back( 7 ); //Добавили элемент
//Возможен «переезд»
std::cout
![Пример std::vector array; … int* ptr = &(array[0]); //Запомнили адрес array.push_back( 7](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/378472/slide-101.jpg)
Слайд 103Списки
Существенным ограничением массива является хранение элементов подряд
Оно приводит к сложности расширения массива
Списки
Существенным ограничением массива является хранение элементов подряд
Оно приводит к сложности расширения массива

Слайд 104Списки
Пусть каждый элемент помнит, где лежит следующий (хранит его адрес)
Тогда достаточно запомнить
Списки
Пусть каждый элемент помнит, где лежит следующий (хранит его адрес)
Тогда достаточно запомнить

Слайд 105Списки
Элемент
Адрес
Элемент
Адрес
Элемент
Адрес
Элемент
Адрес
Элемент
Адрес(0)
Списки
Элемент
Адрес
Элемент
Адрес
Элемент
Адрес
Элемент
Адрес
Элемент
Адрес(0)

Слайд 106Список: вставка элемента
Элемент
Адрес
Элемент
Адрес
Элемент
Адрес(0)
Список: вставка элемента
Элемент
Адрес
Элемент
Адрес
Элемент
Адрес(0)

Слайд 107Список: вставка элемента
Время вставки элемента в середину списка – O(1), т.е. не
Список: вставка элемента
Время вставки элемента в середину списка – O(1), т.е. не

Слайд 108Списки
Недостаток списка: в нем, даже отсортированном, нельзя реализовать бинарный поиск (слишком дорого
Списки
Недостаток списка: в нем, даже отсортированном, нельзя реализовать бинарный поиск (слишком дорого

Слайд 109Списки
Бывают:
Однонаправленными (каждый элемент знает следующий)
Двунаправленными (каждый элемент знает следующий и предыдущий)
Списки
Бывают:
Однонаправленными (каждый элемент знает следующий)
Двунаправленными (каждый элемент знает следующий и предыдущий)

Слайд 110Деревья
Отсортированный массив хорош, поскольку позволяет бинарный поиск за время O(logN)
Добавление нового элемента
Деревья
Отсортированный массив хорош, поскольку позволяет бинарный поиск за время O(logN)
Добавление нового элемента

Слайд 111Граф
Рассмотрим множество A из N элементов и множество B, состоящее из пар
Граф
Рассмотрим множество A из N элементов и множество B, состоящее из пар

Слайд 112Граф
Это множество называется графом и может быть представлено в виде
1
0
2
3
4
Граф
Это множество называется графом и может быть представлено в виде
1
0
2
3
4

Слайд 113Граф
Элементы A – узлы графа
Элементы B – ребра графа. Ребро задается своим
Граф
Элементы A – узлы графа
Элементы B – ребра графа. Ребро задается своим

Слайд 114Граф
Граф называется неориентированным, если для любого ребра {a,b}, входящего в граф, ребро
Граф
Граф называется неориентированным, если для любого ребра {a,b}, входящего в граф, ребро

Слайд 115Неориентированный граф?
1
0
2
3
4
Неориентированный граф?
1
0
2
3
4

Слайд 116Неориентированный граф?
1
0
2
3
4
Неориентированный граф?
1
0
2
3
4

Слайд 117Упрощенное изображение неориентированного графа
1
0
2
3
4
Упрощенное изображение неориентированного графа
1
0
2
3
4

Слайд 118Неориентированные графы
Неориентированный граф является связным, если из любого узла a можно попасть
Неориентированные графы
Неориентированный граф является связным, если из любого узла a можно попасть

Слайд 119Связный граф?
1
0
2
3
4
Связный граф?
1
0
2
3
4

Слайд 120Связный граф?
1
0
2
3
4
Связный граф?
1
0
2
3
4

Слайд 121Неориентированные графы
Неориентированный граф является ациклическим, если в нем не существует маршрутов без
Неориентированные графы
Неориентированный граф является ациклическим, если в нем не существует маршрутов без

Слайд 122Ациклический граф?
1
0
2
3
4
Ациклический граф?
1
0
2
3
4

Слайд 123Ациклический граф?
1
0
2
3
4
Ациклический граф?
1
0
2
3
4

Слайд 124Деревья
Деревом называется связный ациклический неориентированный граф
Если ациклический неориентированный граф – не связный,
Деревья
Деревом называется связный ациклический неориентированный граф
Если ациклический неориентированный граф – не связный,

Слайд 125Утверждение
В любом дереве можно ввести отношение предок-потомок со следующими свойствами
Предок соединен с
Утверждение
В любом дереве можно ввести отношение предок-потомок со следующими свойствами
Предок соединен с

Слайд 126Доказательство
Возьмем произвольный узел и объявим его корнем.
Все соединенные с ним узлы –
Доказательство
Возьмем произвольный узел и объявим его корнем.
Все соединенные с ним узлы –

Слайд 127Иллюстрация
Иллюстрация

Слайд 128Дерево
Итак, деревом называется контейнер, в котором
Элементы связаны отношением предок-потомок
У каждого элемента 0
Дерево
Итак, деревом называется контейнер, в котором
Элементы связаны отношением предок-потомок
У каждого элемента 0

Слайд 129Дерево
Корень
Листья
Дерево
Корень
Листья

Слайд 130Бинарное дерево
Бинарным называется дерево, в котором у каждого элемента не более 2
Бинарное дерево
Бинарным называется дерево, в котором у каждого элемента не более 2

Слайд 131Бинарное дерево
Корень
Листья
Бинарное дерево
Корень
Листья

Слайд 132Бинарное дерево поиска
Бинарное дерево называется деревом поиска, если
Левый потомок любого элемента и
Бинарное дерево поиска
Бинарное дерево называется деревом поиска, если
Левый потомок любого элемента и

Слайд 133Бинарное дерево поиска
Бинарное дерево поиска

Слайд 134Бинарное дерево. Поиск
4
Бинарное дерево. Поиск
4

Слайд 135Бинарное дерево. Добавление элемента
2.5
2.5
Бинарное дерево. Добавление элемента
2.5
2.5

Слайд 136Бинарное дерево поиска
Как и отсортированный массив, поддерживает поиск за log(N)
В отличие от
Бинарное дерево поиска
Как и отсортированный массив, поддерживает поиск за log(N)
В отличие от

Слайд 137Сбалансированное дерево
Дерево является сбалансированным, если разница между его максимальной и минимальной глубиной
Сбалансированное дерево
Дерево является сбалансированным, если разница между его максимальной и минимальной глубиной

Слайд 138Сбалансированное дерево
Сбалансированное дерево

Слайд 139Сбалансированное дерево
2.5
Сбалансированное дерево
2.5

Слайд 140Несбалансированное дерево
4.5
4.2
Несбалансированное дерево
4.5
4.2

Слайд 141Сбалансированное дерево
Дерево должно быть сбалансированным, чтобы поддерживать поиск и добавление элемента за
Сбалансированное дерево
Дерево должно быть сбалансированным, чтобы поддерживать поиск и добавление элемента за

Слайд 142Сбалансированное дерево
Варианты:
Красно-черные деревья
AVL-деревья
Сбалансированное дерево
Варианты:
Красно-черные деревья
AVL-деревья

Слайд 143Словари
Словарь – структура данных, в которой ключам сопоставляются значения (как в толковом
Словари
Словарь – структура данных, в которой ключам сопоставляются значения (как в толковом

Слайд 144Словарь
Code
4
Test
4
Error
5
Byte
4
File
4
Line
4
Task
4
Словарь
Code
4
Test
4
Error
5
Byte
4
File
4
Line
4
Task
4

Слайд 145Словарь
Ключи (в данном случае строковые) отсортированы по алфавиту
Значения (в данном случае целочисленные)
Словарь
Ключи (в данном случае строковые) отсортированы по алфавиту
Значения (в данном случае целочисленные)

Слайд 146Пирамиды
Пирамида – это бинарное дерево со следующими свойствами
Все уровни дерева, возможно кроме
Пирамиды
Пирамида – это бинарное дерево со следующими свойствами
Все уровни дерева, возможно кроме

Слайд 147Пирамида?
17
16
18
Нет – не заполнен 3-ий уровень
Пирамида?
17
16
18
Нет – не заполнен 3-ий уровень

Слайд 148Пирамида?
11
Да
Пирамида?
11
Да

Слайд 149Пирамида?
2.5
Нет – на 4-ом уровне заполнен не самый левый элемент
Пирамида?
2.5
Нет – на 4-ом уровне заполнен не самый левый элемент

Слайд 150Пирамида?
Да
Пирамида?
Да

Слайд 151Пирамида?
25
17
16
Да
Пирамида?
25
17
16
Да

Слайд 152Пирамида
Пирамида называется невозрастающей, если любой родительский элемент больше (либо равен) обоих дочерних
Пирамида
Пирамида называется невозрастающей, если любой родительский элемент больше (либо равен) обоих дочерних

Слайд 153Невозрастающая пирамида
11
Невозрастающая пирамида
11

Слайд 154Неубывающая пирамида
14
12
23
Неубывающая пирамида
14
12
23

Слайд 155Операции над невозрастающей пирамидой
Из невозрастающей пирамиды можно извлечь максимальный элемент за время
Операции над невозрастающей пирамидой
Из невозрастающей пирамиды можно извлечь максимальный элемент за время

Слайд 156Извлечение элемента из пирамиды
27
12
20
8
23
7
9
11
Извлечение элемента из пирамиды
27
12
20
8
23
7
9
11

Слайд 157Извлечение элемента из пирамиды
27
Правильный фрагмент
Правильный фрагмент
Возможно нарушение порядка
Извлечение элемента из пирамиды
27
Правильный фрагмент
Правильный фрагмент
Возможно нарушение порядка

Слайд 158Извлечение элемента из пирамиды
12
20
8
23
7
9
11
27
Извлечение элемента из пирамиды
12
20
8
23
7
9
11
27

Слайд 159Извлечение элемента из пирамиды
12
20
8
23
7
9
11
Правильный фрагмент
Правильный фрагмент
27
Извлечение элемента из пирамиды
12
20
8
23
7
9
11
Правильный фрагмент
Правильный фрагмент
27

Слайд 160Извлечение элемента из пирамиды
12
20
8
23
7
9
11
27
Извлечение элемента из пирамиды
12
20
8
23
7
9
11
27

Слайд 161Извлечение элемента из пирамиды
27
Завершено!
Извлечение элемента из пирамиды
27
Завершено!

Слайд 162Добавление элемента в пирамиду
14
11
Возможно нарушение порядка
Корректный фрагмент
12
11
8
10
7
6
Добавление элемента в пирамиду
14
11
Возможно нарушение порядка
Корректный фрагмент
12
11
8
10
7
6

Слайд 163Добавление элемента в пирамиду
14
11
Выбираем максимум
12
11
8
10
7
6
Добавление элемента в пирамиду
14
11
Выбираем максимум
12
11
8
10
7
6

Слайд 164Добавление элемента в пирамиду
14
11
12
11
8
10
7
6
Корректный фрагмент
Корректный фрагмент
Возможно нарушение
Выбираем максимум
Добавление элемента в пирамиду
14
11
12
11
8
10
7
6
Корректный фрагмент
Корректный фрагмент
Возможно нарушение
Выбираем максимум

Слайд 165Добавление элемента в пирамиду
14
11
12
11
8
10
7
6
Корректный фрагмент
Корректный фрагмент
Возможно нарушение
Выбираем максимум
Завершено!
Добавление элемента в пирамиду
14
11
12
11
8
10
7
6
Корректный фрагмент
Корректный фрагмент
Возможно нарушение
Выбираем максимум
Завершено!

Слайд 166Применение пирамиды
Пирамида используется в пирамидальной сортировке – построив пирамиду и извлекая из
Применение пирамиды
Пирамида используется в пирамидальной сортировке – построив пирамиду и извлекая из

Слайд 167Хранение пирамиды
Мы можем хранить пирамиду как обычное бинарное дерево (каждый узел представляется
Хранение пирамиды
Мы можем хранить пирамиду как обычное бинарное дерево (каждый узел представляется

Слайд 168Хранение пирамиды
Пирамиду можно хранить без выделения дополнительной памяти
Для этого пирамида представляется как
Хранение пирамиды
Пирамиду можно хранить без выделения дополнительной памяти
Для этого пирамида представляется как

Слайд 169Хранение пирамиды
Уровень K пирамиды занимает в массиве позиции от 2K-1 до 2K+1-2
Например,
Хранение пирамиды
Уровень K пирамиды занимает в массиве позиции от 2K-1 до 2K+1-2
Например,

Слайд 170Хранение пирамиды
27
12
20
8
23
7
9
11
27
23
12
20
8
7
9
11
Хранение пирамиды
27
12
20
8
23
7
9
11
27
23
12
20
8
7
9
11

Слайд 171Хранение пирамиды
Потомками элемента A[ K ] являются
A[ 2 * K + 1
Хранение пирамиды
Потомками элемента A[ K ] являются
A[ 2 * K + 1
![Хранение пирамиды Потомками элемента A[ K ] являются A[ 2 * K](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/378472/slide-170.jpg)
Слайд 172Задание
Как выглядит код, проверяющий массив на то, что он является невозрастающей пирамидой?
Задание
Как выглядит код, проверяющий массив на то, что он является невозрастающей пирамидой?

Слайд 173Стек
Стеком называется контейнер, поддерживающий принцип Last In – First Out
Мы можем в
Стек
Стеком называется контейнер, поддерживающий принцип Last In – First Out
Мы можем в

Слайд 174Стек
Стек

Слайд 175Стек
Стек может быть построен на базе практически другого контейнера, например массива
Стек ограничивает
Стек
Стек может быть построен на базе практически другого контейнера, например массива
Стек ограничивает

Слайд 176Очередь
Очередь – это контейнер, поддерживающий принцип First In – First Out
Существуют операции
Очередь
Очередь – это контейнер, поддерживающий принцип First In – First Out
Существуют операции

Слайд 177Очередь
Очередь

Слайд 178Очередь
Очередь также легко реализуется на базе другого контейнера (например, массива)
Очередь
Очередь также легко реализуется на базе другого контейнера (например, массива)

Слайд 179Лекция 4. Хэш-таблицы. Понятие о хэш-функции. Идея хэширования.
Лекция 4. Хэш-таблицы. Понятие о хэш-функции. Идея хэширования.

Слайд 180Хэш-таблицы. Постановка задачи.
Бинарные деревья поиска позволили реализовать поиск элемента в контейнере за
Хэш-таблицы. Постановка задачи.
Бинарные деревья поиска позволили реализовать поиск элемента в контейнере за

Слайд 181Хэш-таблицы – прямая адресация
Пусть в контейнере планируется хранить целые числа от 0
Хэш-таблицы – прямая адресация
Пусть в контейнере планируется хранить целые числа от 0

Слайд 182Хэш-таблицы – прямая адресация
Исходное состояние – значение всех элементов не совпадает с
Хэш-таблицы – прямая адресация
Исходное состояние – значение всех элементов не совпадает с

Слайд 183Хэш-таблицы – прямая адресация
2
Поиск элемента
0
Не совпали – значит, такого нет
7
Поиск элемента
Совпали –
Хэш-таблицы – прямая адресация
2
Поиск элемента
0
Не совпали – значит, такого нет
7
Поиск элемента
Совпали –

Слайд 184О достоинствах и недостатках схемы
Поиск любого элемента выполняется за фиксированное время (O(1))
Добавление
О достоинствах и недостатках схемы
Поиск любого элемента выполняется за фиксированное время (O(1))
Добавление

Слайд 185Идея хэш-функции
Обеспечить поиск и добавление элемента за время, равное O(1), возможно, если
Идея хэш-функции
Обеспечить поиск и добавление элемента за время, равное O(1), возможно, если

Слайд 186Идея хэш-функции
Итак, необходимо, чтобы элемент со значением x сохранялся в позиции h(x).
Идея хэш-функции
Итак, необходимо, чтобы элемент со значением x сохранялся в позиции h(x).

Слайд 187Пример
Рассмотрим контейнер целых чисел
Для хранения – массив из 11 элементов
h(x) = x
Пример
Рассмотрим контейнер целых чисел
Для хранения – массив из 11 элементов
h(x) = x

Слайд 188Пример хэш-таблицы
52
Добавление элемента
52 % 11 = 8
37
Добавление элемента
37 % 11 = 4
Пример хэш-таблицы
52
Добавление элемента
52 % 11 = 8
37
Добавление элемента
37 % 11 = 4

Слайд 189Пример хэш-таблицы
16
Поиск элемента
16 % 11 = 5
19
Поиск элемента
19 % 11 = 8
Не
Пример хэш-таблицы
16
Поиск элемента
16 % 11 = 5
19
Поиск элемента
19 % 11 = 8
Не

Слайд 190Пример хэш-таблицы
37
Поиск элемента
37 % 11 = 4
Найден
Пример хэш-таблицы
37
Поиск элемента
37 % 11 = 4
Найден

Слайд 191Коллизии
Мы не хотим выделять память на каждое возможное значение элемента (реально встретившихся
Коллизии
Мы не хотим выделять память на каждое возможное значение элемента (реально встретившихся

Слайд 192Коллизии
Значит, возможна ситуация, когда мы пытаемся добавить элемент, а место занято.
Эта ситуация
Коллизии
Значит, возможна ситуация, когда мы пытаемся добавить элемент, а место занято.
Эта ситуация

Слайд 193Пример коллизии
96
Добавление элемента
96 % 11 = 8
Коллизия
Пример коллизии
96
Добавление элемента
96 % 11 = 8
Коллизия

Слайд 194Необходимо разрешение коллизий
Правила разрешения коллизий должны определять, что делать при коллизии (куда
Необходимо разрешение коллизий
Правила разрешения коллизий должны определять, что делать при коллизии (куда

Слайд 195Разрешение коллизий: хранение списков
Будем хранить в каждом элементе массива не значение, а
Разрешение коллизий: хранение списков
Будем хранить в каждом элементе массива не значение, а

Слайд 196Разрешение коллизий: хранение списков, h(x) = x % 11, добавление
45
93
51
12
Разрешение коллизий: хранение списков, h(x) = x % 11, добавление
45
93
51
12

Слайд 19717
29
89
12
45
93
51
12
Разрешение коллизий: хранение списков, h(x) = x % 11, поиск
Не найден
Найден!
17
29
89
12
45
93
51
12
Разрешение коллизий: хранение списков, h(x) = x % 11, поиск
Не найден
Найден!

Слайд 198Разрешение коллизий хранением списков
В наихудшем случае время поиска O(N) – если возникнет
Разрешение коллизий хранением списков
В наихудшем случае время поиска O(N) – если возникнет

Слайд 199Разрешение коллизий хранением списков
Предположим, что
Вероятности попадания элемента в любую ячейку равны
Количество ячеек
Разрешение коллизий хранением списков
Предположим, что
Вероятности попадания элемента в любую ячейку равны
Количество ячеек

Слайд 200Разрешение коллизий методом сдвига
Достаточно легко удалить элемент – просто удаляем его из
Разрешение коллизий методом сдвига
Достаточно легко удалить элемент – просто удаляем его из

Слайд 201Разрешение коллизий методом сдвига
Часто хочется упростить структуру и не хранить массив списков
В
Разрешение коллизий методом сдвига
Часто хочется упростить структуру и не хранить массив списков
В

Слайд 202Разрешение коллизий методом сдвига
Если мы не можем положить элемент в нужную ячейку
Разрешение коллизий методом сдвига
Если мы не можем положить элемент в нужную ячейку

Слайд 203Почему линейное исследование?
При попытке № i поместить значение k мы пробуем ячейку
Почему линейное исследование?
При попытке № i поместить значение k мы пробуем ячейку

Слайд 204Разрешение коллизий методом сдвига , h(x) = x % 11, добавление
45
12
95
24
Разрешение коллизий методом сдвига , h(x) = x % 11, добавление
45
12
95
24

Слайд 205Разрешение коллизий методом сдвига , h(x) = x % 11, поиск
45
24
95
17
95
89
12
12
Не найден
Найден!
Разрешение коллизий методом сдвига , h(x) = x % 11, поиск
45
24
95
17
95
89
12
12
Не найден
Найден!

Слайд 206Разрешение коллизий методом сдвига
Метод работает, только если длина массива не меньше числа
Разрешение коллизий методом сдвига
Метод работает, только если длина массива не меньше числа

Слайд 207Разрешение коллизий: квадратичное исследование
При попытке № i поместить значение k мы пробуем
Разрешение коллизий: квадратичное исследование
При попытке № i поместить значение k мы пробуем

Слайд 208Квадратичное исследование,
h(x, i) = ( x % 11 + i +
Квадратичное исследование, h(x, i) = ( x % 11 + i +

Слайд 20945
12
95
17
95
89
12
24
Не найден
Найден!
Квадратичное исследование,
h(x, i) = ( x % 11 + i
45
12
95
17
95
89
12
24
Не найден
Найден!
Квадратичное исследование, h(x, i) = ( x % 11 + i

Слайд 210Квадратичное исследование,
h(x, i) = ( x % 11 + i +
Квадратичное исследование, h(x, i) = ( x % 11 + i +

Слайд 211Квадратичное исследование,
h(x, i) =( x % 8 + i / 2+
Квадратичное исследование, h(x, i) =( x % 8 + i / 2+

Слайд 212Выводы:
Квадратичное исследование менее подвержено опасности кластеризации, чем линейное.
При квадратичном исследовании важен выбор
Выводы:
Квадратичное исследование менее подвержено опасности кластеризации, чем линейное.
При квадратичном исследовании важен выбор

Слайд 213Двойное хэширование
Методы линейного и квадратичного исследования неприемлемы при большом числе коллизий
Если мы
Двойное хэширование
Методы линейного и квадратичного исследования неприемлемы при большом числе коллизий
Если мы

Слайд 214Двойное хэширование
Идея двойного хэширования в том, чтобы использовать вторую хэш-функцию для определения
Двойное хэширование
Идея двойного хэширования в том, чтобы использовать вторую хэш-функцию для определения

Слайд 215Варианты:
m – степень двойки
h2(k) – нечетная для любого k, h2(k)= 2h3(k)+1
m –
Варианты:
m – степень двойки
h2(k) – нечетная для любого k, h2(k)= 2h3(k)+1
m –

Слайд 216Двойное хэширование, h1(x) = x % 11, h2(x) = 1 + x
Двойное хэширование, h1(x) = x % 11, h2(x) = 1 + x

Слайд 21773
52
24
95
17
52
18
33
Не найден
Найден!
Двойное хэширование, h1(x) = x % 11, h2(x) = 1 +
73
52
24
95
17
52
18
33
Не найден
Найден!
Двойное хэширование, h1(x) = x % 11, h2(x) = 1 +

Слайд 218Двойное хэширование: выводы
Двойное хэширование – лучший из методов с открытой адресацией (т.е.
Двойное хэширование: выводы
Двойное хэширование – лучший из методов с открытой адресацией (т.е.

Слайд 21918
73
52
Удаление элементов из хэш-таблицы с открытой адресацией h1(x) = x % 11,
18
73
52
Удаление элементов из хэш-таблицы с открытой адресацией h1(x) = x % 11,

Слайд 220Удаление элементов
Просто удалить элемент нельзя – нарушится поиск тех, которые были добавлены
Удаление элементов
Просто удалить элемент нельзя – нарушится поиск тех, которые были добавлены

Слайд 221DELETED
18
73
52
Удаление элементов из хэш-таблицы с открытой адресацией h1(x) = x % 11,
DELETED
18
73
52
Удаление элементов из хэш-таблицы с открытой адресацией h1(x) = x % 11,

Слайд 222Удаление элементов
Специальное значение Deleted позволяет удалить элемент
Но позиция в таблице после этого
Удаление элементов
Специальное значение Deleted позволяет удалить элемент
Но позиция в таблице после этого

Слайд 223Выбор хэш-функции
Мы будем считать, что элементы массива – целые числа
Если они не
Выбор хэш-функции
Мы будем считать, что элементы массива – целые числа
Если они не

Слайд 224Пример: строки ANSI
«Alexey»
В памяти -
108(‘l’)
101(‘e’)
101(‘e’)
120(‘x’)
121(‘y’)
0
65(‘A’)
В числовой форме – 71933814662521
121+101*256+120*2562+101*2563
+108*2564+65*2565
Пример: строки ANSI
«Alexey»
В памяти -
108(‘l’)
101(‘e’)
101(‘e’)
120(‘x’)
121(‘y’)
0
65(‘A’)
В числовой форме – 71933814662521
121+101*256+120*2562+101*2563
+108*2564+65*2565

Слайд 225Варианты хэш-функции
Метод деления
Метод умножения
Универсальное хэширование
Варианты хэш-функции
Метод деления
Метод умножения
Универсальное хэширование

Слайд 226Метод деления
h( k ) = k % m
m – число позиций в
Метод деления
h( k ) = k % m
m – число позиций в

Слайд 227Метод умножения
h( k ) = [ m ( kA - [ kA
Метод умножения
h( k ) = [ m ( kA - [ kA

Слайд 228Метод умножения
Можно избежать вещественных вычислений. m=2w, A=s/2w, 0h( k ) = [
Метод умножения
Можно избежать вещественных вычислений. m=2w, A=s/2w, 0

Слайд 229Универсальное хэширование
Ясно, что для любой хэш-функции можно подобрать значения, при которых она
Универсальное хэширование
Ясно, что для любой хэш-функции можно подобрать значения, при которых она

Слайд 230Универсальное хэширование
Идея универсального хэширования – случайный выбор хэш-функции так, чтобы для любой
Универсальное хэширование
Идея универсального хэширования – случайный выбор хэш-функции так, чтобы для любой

Слайд 231Универсальное хэширование
Множество N хэш-функций hn(k) универсально, если для любых ключей k, l
Универсальное хэширование
Множество N хэш-функций hn(k) универсально, если для любых ключей k, l

Слайд 232Универсальное хэширование
Пример функции
Пусть p – простое число, ключи – от 0 до
Универсальное хэширование
Пример функции
Пусть p – простое число, ключи – от 0 до

Слайд 233Другие применения хэш-функций
Криптография.
Криптография с закрытым ключом – зная ключ, можно построить
Другие применения хэш-функций
Криптография.
Криптография с закрытым ключом – зная ключ, можно построить

Слайд 234Лабораторная работа №2. Реализация контейнеров данных.
Лабораторная работа №2. Реализация контейнеров данных.

Слайд 235Реализация контейнеров данных
Предлагаются индивидуальные варианты заданий, связанные с реализацией контейнеров
Предпочтительна реализация контейнера,
Реализация контейнеров данных
Предлагаются индивидуальные варианты заданий, связанные с реализацией контейнеров
Предпочтительна реализация контейнера,

Слайд 236Варианты заданий
Реализовать класс списка с операциями добавления элемента, удаления элемента, доступа к
Варианты заданий
Реализовать класс списка с операциями добавления элемента, удаления элемента, доступа к

Слайд 237Варианты заданий
Реализовать класс массива элементов, значение которых может быть 0 или 1,
Варианты заданий
Реализовать класс массива элементов, значение которых может быть 0 или 1,

Слайд 238Варианты заданий повышенной сложности
Реализовать класс АВЛ-дерева с операциями добавления элемента, удаления элемента,
Варианты заданий повышенной сложности
Реализовать класс АВЛ-дерева с операциями добавления элемента, удаления элемента,

Слайд 239Тема 2.1. Библиотека STL как пример стандартной библиотеки языка программирования. Использование контейнеров
Тема 2.1. Библиотека STL как пример стандартной библиотеки языка программирования. Использование контейнеров

Слайд 240Лекция 5. Шаблоны и пространства имен в C++
Лекция 5. Шаблоны и пространства имен в C++

Слайд 241Шаблоны
Рассмотрим функцию сортировки массива целых чисел и функцию сортировки телефонной книги (программа
Шаблоны
Рассмотрим функцию сортировки массива целых чисел и функцию сортировки телефонной книги (программа

Слайд 242Шаблоны
Для решения этой проблемы придуманы шаблоны.
Шаблон – это «заготовка» функции, которая может
Шаблоны
Для решения этой проблемы придуманы шаблоны.
Шаблон – это «заготовка» функции, которая может

Слайд 243SortTemplates
Мы определили заготовку функции сортировки для произвольного типа.
Когда компилятор видит попытку вызова
SortTemplates
Мы определили заготовку функции сортировки для произвольного типа.
Когда компилятор видит попытку вызова

Слайд 244Шаблоны
Параметром шаблона может быть не только тип данных, но и число (режим
Шаблоны
Параметром шаблона может быть не только тип данных, но и число (режим

Слайд 245Синтаксис определения функции-шаблона
template < параметры шаблона >
имя функции( параметры функции)
{
тело функции
}
Для параметра
Синтаксис определения функции-шаблона
template < параметры шаблона >
имя функции( параметры функции)
{
тело функции
}
Для параметра

Слайд 246Вопрос
Медленнее ли работа шаблона, чем работа нормальной функции?
Вопрос
Медленнее ли работа шаблона, чем работа нормальной функции?

Слайд 247Ответ
Нет, не медленнее – это механизм уровня компиляции. Еще при сборке шаблон
Ответ
Нет, не медленнее – это механизм уровня компиляции. Еще при сборке шаблон

Слайд 248Шаблоны классов
Точно так же, как функция, шаблоном может быть и класс.
Шаблоны классов
Шаблоны классов
Точно так же, как функция, шаблоном может быть и класс.
Шаблоны классов

Слайд 249Синтаксис определения
класса-шаблона
template <параметры шаблона> class имя
{
//Определение класса. В нем могут
//использоваться
Синтаксис определения
класса-шаблона
template <параметры шаблона> class имя
{
//Определение класса. В нем могут
//использоваться

Слайд 250Пример шаблона класса
Класс комплексного числа, работающего с типами double, float - ComplexTemplate
Пример шаблона класса
Класс комплексного числа, работающего с типами double, float - ComplexTemplate

Слайд 251Задание
Написать класс вектора, который сможет работать как с вещественными, так и с
Задание
Написать класс вектора, который сможет работать как с вещественными, так и с

Слайд 252Частичная спецификация шаблона
Предположим, некоторый класс работает одинаково для всех типов данных
При этом
Частичная спецификация шаблона
Предположим, некоторый класс работает одинаково для всех типов данных
При этом

Слайд 253Частичная спецификация шаблона
template < class T >
class TemplateClass
{
};
template <>
class TemplateClass < int
Частичная спецификация шаблона
template < class T >
class TemplateClass
{
};
template <>
class TemplateClass < int

Слайд 254Пространства имен
В большой программе велик риск, что имена классов и функций будут
Пространства имен
В большой программе велик риск, что имена классов и функций будут

Слайд 255Пространства имен. Пример
namespace N1
{
class A { …};
}
namespace N2
{
class A { …};
}
N1::A a1;
N2::A
Пространства имен. Пример
namespace N1
{
class A { …};
}
namespace N2
{
class A { …};
}
N1::A a1;
N2::A

Слайд 256Пространства имен
Как видно на предыдущем слайде, заключив классы в пространство имен, мы
Пространства имен
Как видно на предыдущем слайде, заключив классы в пространство имен, мы

Слайд 257Лекция 6. Контейнеры STL – общие принципы
Лекция 6. Контейнеры STL – общие принципы

Слайд 258Основные контейнеры
vector – массив
list – список
valarray – вектор (массив
Основные контейнеры
vector – массив
list – список
valarray – вектор (массив

Слайд 259Требования к реализации контейнеров
Независимость реализации контейнера от типа используемых данных (могут предъявляться
Требования к реализации контейнеров
Независимость реализации контейнера от типа используемых данных (могут предъявляться

Слайд 260Требования к реализации контейнеров
Возможность единообразной реализации операций (например, перебора) для нескольких контейнеров
Константность
Требования к реализации контейнеров
Возможность единообразной реализации операций (например, перебора) для нескольких контейнеров
Константность

Слайд 261Решения
Для обеспечения независимости от типа элемента используем шаблоны C++
Для обеспечения независимости контейнера
Решения
Для обеспечения независимости от типа элемента используем шаблоны C++
Для обеспечения независимости контейнера

Слайд 262Решения
Для возможности сортировки данных одного типа по разным критериям контейнер не использует
Решения
Для возможности сортировки данных одного типа по разным критериям контейнер не использует

Слайд 263Решения
Для обеспечения константности логически константных операций, устойчивости к многопоточности и возможности единообразной
Решения
Для обеспечения константности логически константных операций, устойчивости к многопоточности и возможности единообразной

Слайд 264Итераторы
Итератором называется программный объект со следующими свойствами
Объект связан с определенным объектом-контейнером и
Итераторы
Итератором называется программный объект со следующими свойствами
Объект связан с определенным объектом-контейнером и

Слайд 265Итераторы
Каждому типу контейнера соответствует свой тип итератора. Для контейнеров STL этот тип
Итераторы
Каждому типу контейнера соответствует свой тип итератора. Для контейнеров STL этот тип

Слайд 266Итераторы. Контрольный массив
Есть массив в стиле C
int a[100];
Существует ли итератор у этого
Итераторы. Контрольный массив
Есть массив в стиле C
int a[100];
Существует ли итератор у этого
![Итераторы. Контрольный массив Есть массив в стиле C int a[100]; Существует ли итератор у этого конттейнера?](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/378472/slide-265.jpg)
Слайд 267Итераторы. Контрольный вопрос.
Да! Это переменная типа int*, указывающая на любой его элемент.
Указывает
Итераторы. Контрольный вопрос.
Да! Это переменная типа int*, указывающая на любой его элемент.
Указывает

Слайд 268Простейшее применение итераторов
Практически все контейнеры STL имеют
Метод begin() – возвращает итератор, указывающий
Простейшее применение итераторов
Практически все контейнеры STL имеют
Метод begin() – возвращает итератор, указывающий

Слайд 269Простейшее применение итераторов
void Print ( T element )
void PrintAll( A container
Простейшее применение итераторов
void Print ( T element )
void PrintAll( A container

Слайд 270Простейшее применение итераторов
Код работоспособен для любого контейнера STL и любого типа элемента
Простейшее применение итераторов
Код работоспособен для любого контейнера STL и любого типа элемента

Слайд 271Классификация итераторов
Итератор всегда имеет оператор ++
Кроме того, он может иметь (а может
Классификация итераторов
Итератор всегда имеет оператор ++
Кроме того, он может иметь (а может

Слайд 272Классификация итераторов
Мы хотим иметь возможность применять итераторы для чтения данных из потока
Классификация итераторов
Мы хотим иметь возможность применять итераторы для чтения данных из потока

Слайд 273Классификация итераторов
Мы хотим использовать итераторы для записи данных в файл.
std::ofstream file_out(
Классификация итераторов
Мы хотим использовать итераторы для записи данных в файл.
std::ofstream file_out(

Слайд 274Классификация итераторов
Любой итератор контейнера имеет
Операцию доступа к объекту на чтение
Операцию доступа к
Классификация итераторов
Любой итератор контейнера имеет
Операцию доступа к объекту на чтение
Операцию доступа к

Слайд 275Классификация итераторов
Если к набору операций однонаправленного итератора добавить операцию – (переход к
Классификация итераторов
Если к набору операций однонаправленного итератора добавить операцию – (переход к

Слайд 276Классификация итераторов
Если к набору операций двунаправленного итератора добавить возможность сдвига на N
Классификация итераторов
Если к набору операций двунаправленного итератора добавить возможность сдвига на N

Слайд 277Вопрос
Ясно, что технически возможно реализовать сдвиг по списку или бинарному дереву поиска
Вопрос
Ясно, что технически возможно реализовать сдвиг по списку или бинарному дереву поиска

Слайд 278Ответ
Сдвиг на N позиций работал бы за время O(N) для списка и
Ответ
Сдвиг на N позиций работал бы за время O(N) для списка и

Слайд 279Классификация итераторов
Классификация итераторов

Слайд 280Компараторы
Вспомним алгоритм сортировки пузырьком
void sort ( T* A , int N )
{
for
Компараторы
Вспомним алгоритм сортировки пузырьком
void sort ( T* A , int N )
{
for

Слайд 281Компараторы
Мы можем применить этот алгоритм для любого типа, имеющего оператор сравнения
Предположим, у
Компараторы
Мы можем применить этот алгоритм для любого типа, имеющего оператор сравнения
Предположим, у

Слайд 282Компараторы
Использовать приведенный выше код мы не сможем
Что делать?
Компараторы
Использовать приведенный выше код мы не сможем
Что делать?

Слайд 283Компараторы
Мы должны передать критерий сортировки как параметр функции или параметр шаблона
Значит, критерий
Компараторы
Мы должны передать критерий сортировки как параметр функции или параметр шаблона
Значит, критерий

Слайд 284Компараторы
template < class TComparator >
void sort ( T* A , int N
Компараторы
template < class TComparator >
void sort ( T* A , int N

Слайд 285Компараторы
class UsualComparator
{
bool operator()( T a , T b )
{
return a < b;
}
};
T
Компараторы
class UsualComparator
{
bool operator()( T a , T b )
{
return a < b;
}
};
T

Слайд 286Компараторы
Код на предыдущем слайде приводит к обычной сортировке с использованием оператора сравнения.
В
Компараторы
Код на предыдущем слайде приводит к обычной сортировке с использованием оператора сравнения.
В

Слайд 287Компараторы
Мы можем реализовать другие типы компараторов и создать другие объекты компараторы
Передавая их
Компараторы
Мы можем реализовать другие типы компараторов и создать другие объекты компараторы
Передавая их

Слайд 288Компараторы
Компаратор можно передать и контейнеру, нуждающемуся в упорядочении своих элементов (неубывающей пирамиде,
Компараторы
Компаратор можно передать и контейнеру, нуждающемуся в упорядочении своих элементов (неубывающей пирамиде,

Слайд 289Аллокаторы
Компараторы позволяют настроить метод сравнения объекта
Аналогично аллокаторы позволяют настроить метод выделения и
Аллокаторы
Компараторы позволяют настроить метод сравнения объекта
Аналогично аллокаторы позволяют настроить метод выделения и

Слайд 290Лекция 7. Контейнеры STL - реализация
Лекция 7. Контейнеры STL - реализация

Слайд 291Массивы в STL - std::vector
Реализует массив
Тип элемента задается как параметр шаблона.
Тип элемента
Массивы в STL - std::vector
Реализует массив
Тип элемента задается как параметр шаблона.
Тип элемента

Слайд 292Массивы в STL - std::vector
Метод at – доступ по индексу с проверкой
Массивы в STL - std::vector
Метод at – доступ по индексу с проверкой

Слайд 293Массивы в STL - std::vector
std::vector определяет тип итератора std::vector::iterator. Этот итератор является
Массивы в STL - std::vector
std::vector определяет тип итератора std::vector

Слайд 294Массивы в STL - std::vector
Массивы в STL - std::vector

Слайд 295Массивы в STL - std::vector
Для размещения элементов в памяти std::vector использует аллокатор.
Массивы в STL - std::vector
Для размещения элементов в памяти std::vector использует аллокатор.

Слайд 296Списки в STL – std::list
std::list реализует стратегию работы со списками независимо от
Списки в STL – std::list
std::list реализует стратегию работы со списками независимо от

Слайд 297Списки в STL – std::list
Методы front(), back() предоставляют доступ к первому и
Списки в STL – std::list
Методы front(), back() предоставляют доступ к первому и

Слайд 298Списки в STL – std::list
std::list определяет тип итератора std::list::iterator. Этот итератор является
Списки в STL – std::list
std::list определяет тип итератора std::list

Слайд 299Списки в STL – std::list
Используются аллокаторыИспользуются аллокаторы так же, как в массиве.
Операции
Списки в STL – std::list
Используются аллокаторыИспользуются аллокаторы так же, как в массиве.
Операции

Слайд 300Бинарное дерево поиска в STL – std::set
std::set реализует работу с бинарным деревом
Бинарное дерево поиска в STL – std::set
std::set реализует работу с бинарным деревом

Слайд 301Бинарное дерево поиска в STL – std::set
Бинарный поиск реализуется методом find, работает
Бинарное дерево поиска в STL – std::set
Бинарный поиск реализуется методом find, работает

Слайд 302Бинарное дерево поиска в STL – std::set
Добавление элемента реализуется методом insert. Результатом
Бинарное дерево поиска в STL – std::set
Добавление элемента реализуется методом insert. Результатом

Слайд 303Бинарное дерево поиска в STL – std::set
std::set определяет тип итератора std::set::iterator. Этот
Бинарное дерево поиска в STL – std::set
std::set определяет тип итератора std::set

Слайд 304Бинарное дерево поиска в STL – std::set
Используются аллокаторыИспользуются аллокаторы так же, как
Бинарное дерево поиска в STL – std::set
Используются аллокаторыИспользуются аллокаторы так же, как

Слайд 305std::multi_set
Набор операций аналогичен std::set
find возвращает первый элемент, равный данному
insert возвращает только итератор.
std::multi_set
Набор операций аналогичен std::set
find возвращает первый элемент, равный данному
insert возвращает только итератор.

Слайд 306std::multi_set
Перебор элементов, равных данному:
for ( TContainer::iterator iter = Container.lower_bound( x ) ;
std::multi_set
Перебор элементов, равных данному:
for ( TContainer::iterator iter = Container.lower_bound( x ) ;

Слайд 307Словарь в STL – std::map
std::map реализует работу со словарем, имеющим произвольный тип
Словарь в STL – std::map
std::map реализует работу со словарем, имеющим произвольный тип

Слайд 308Словарь в STL – std::map
Методы find, lower_bound, upper_bound, equal_range, insert, erase –
Словарь в STL – std::map
Методы find, lower_bound, upper_bound, equal_range, insert, erase –

Слайд 309Словарь в STL – std::map
std::map определяет тип итератора std::map::iterator. Этот итератор является
Словарь в STL – std::map
std::map определяет тип итератора std::map

Слайд 310Словарь в STL – std::map
Используются аллокаторыИспользуются аллокаторы так же, как в массиве
Хранить
Словарь в STL – std::map
Используются аллокаторыИспользуются аллокаторы так же, как в массиве
Хранить

Слайд 311std::multi_map
Аналогичен std::map
Не реализуется обращение по индексу map[ key ].
Как и в stdКак
std::multi_map
Аналогичен std::map
Не реализуется обращение по индексу map[ key ].
Как и в stdКак
![std::multi_map Аналогичен std::map Не реализуется обращение по индексу map[ key ]. Как](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/378472/slide-310.jpg)
Слайд 312Двусторонняя очередь – std::deque
std::deque реализует поведение двусторонней очереди
std::deque позволяет задать тип элемента
Двусторонняя очередь – std::deque
std::deque реализует поведение двусторонней очереди
std::deque позволяет задать тип элемента

Слайд 313Двусторонняя очередь – std::deque
Быстрый доступ по индексу – как в std::vector
Deq[ i
Двусторонняя очередь – std::deque
Быстрый доступ по индексу – как в std::vector
Deq[ i

Слайд 314Двусторонняя очередь – std::deque
Методы front(), back() предоставляют доступ к первому и последнему
Двусторонняя очередь – std::deque
Методы front(), back() предоставляют доступ к первому и последнему

Слайд 315Двусторонняя очередь – std::deque
std::deque определяет тип итератора std::deque::iterator. Этот итератор является итератором
Двусторонняя очередь – std::deque
std::deque определяет тип итератора std::deque

Слайд 316Двусторонняя очередь – std::deque
Для размещения элементов в памяти std::deque использует аллокаторДля размещения
Двусторонняя очередь – std::deque
Для размещения элементов в памяти std::deque использует аллокаторДля размещения

Слайд 317Очередь – std::queue
Реализует очередь
Тип элемента задается как параметр шаблона.
Необходимо существование конструктора по
Очередь – std::queue
Реализует очередь
Тип элемента задается как параметр шаблона.
Необходимо существование конструктора по

Слайд 318Очередь – std::queue
Набор операций включает методы
push (добавить элемент в конец очереди)
pop
Очередь – std::queue
Набор операций включает методы
push (добавить элемент в конец очереди)
pop

Слайд 319Очередь – std::queue
Очередь может эффективно работать при различных стратегиях размещения данных в
Очередь – std::queue
Очередь может эффективно работать при различных стратегиях размещения данных в

Слайд 320Очередь – std::queue
Тип внутреннего контейнера задается как второй параметр шаблона std::queue.
Этот
Очередь – std::queue
Тип внутреннего контейнера задается как второй параметр шаблона std::queue.
Этот

Слайд 321Стек – std::stack
Реализует стек
Тип элемента задается как параметр шаблона.
Необходимо существование конструктора по
Стек – std::stack
Реализует стек
Тип элемента задается как параметр шаблона.
Необходимо существование конструктора по

Слайд 322Стек – std::stack
Набор операций включает
push (добавить элемент)
pop (извлечь последний добавленный элемент)
back
Стек – std::stack
Набор операций включает
push (добавить элемент)
pop (извлечь последний добавленный элемент)
back

Слайд 323Стек – std::stack
Стек может быть реализован на базе различных контейнеров.
Базовый контейнер
Стек – std::stack
Стек может быть реализован на базе различных контейнеров.
Базовый контейнер

Слайд 324Очередь с приоритетами – std::priority_queue
Очередь с приоритетами – это очередь, в которой
Очередь с приоритетами – std::priority_queue
Очередь с приоритетами – это очередь, в которой

Слайд 325Очередь с приоритетами – std::priority_queue
Тип элемента задается как первый параметр шаблона.
Необходимо существование
Очередь с приоритетами – std::priority_queue
Тип элемента задается как первый параметр шаблона.
Необходимо существование

Слайд 326Очередь с приоритетами – std::priority_queue
Набор операций включает
push (добавить элемент)
pop (извлечь элемент
Очередь с приоритетами – std::priority_queue
Набор операций включает
push (добавить элемент)
pop (извлечь элемент

Слайд 327Очередь с приоритетами – std::priority_queue
Как реализуется очередь с приоритетами?
Очередь с приоритетами – std::priority_queue
Как реализуется очередь с приоритетами?

Слайд 328Очередь с приоритетами – std::priority_queue
Очередь с приоритетами строится на базе невозрастающей пирамиды
Используется
Очередь с приоритетами – std::priority_queue
Очередь с приоритетами строится на базе невозрастающей пирамиды
Используется

Слайд 329Очередь с приоритетами – std::priority_queue
Для хранения «пирамиды как массива» может использоваться любой
Очередь с приоритетами – std::priority_queue
Для хранения «пирамиды как массива» может использоваться любой

Слайд 330Хэш-таблица – std::hash_map
Класс std::hash_map реализует хэш-таблицу
Как и stdКак и std::Как и std::map,
Хэш-таблица – std::hash_map
Класс std::hash_map реализует хэш-таблицу
Как и stdКак и std::Как и std::map,

Слайд 331Хэш-таблица – std::hash_map
За вычисление хэш-функции и проверки на равенство отвечает специальный объект
Хэш-таблица – std::hash_map
За вычисление хэш-функции и проверки на равенство отвечает специальный объект

Слайд 332Хэш-таблица – std::hash_map
Необходимый размер хэш-таблицы вычисляется и динамически меняется.
Задаваемая пользователем хэш-функция
Хэш-таблица – std::hash_map
Необходимый размер хэш-таблицы вычисляется и динамически меняется.
Задаваемая пользователем хэш-функция

Слайд 333Не совсем контейнеры
Существуют объекты библиотеки STL, которые не являются контейнерами но реализуют
Не совсем контейнеры
Существуют объекты библиотеки STL, которые не являются контейнерами но реализуют

Слайд 334Строка – std::basic_string
Строка является массивом символов
Для представления символов могут использоваться различные типы
Строка – std::basic_string
Строка является массивом символов
Для представления символов могут использоваться различные типы

Слайд 335Строка как массив
std::basic_string определяет тип итераторов с произвольным доступом – std::basic_string::iterator.
std::basic_string имеет
Строка как массив
std::basic_string определяет тип итераторов с произвольным доступом – std::basic_string
std::basic_string имеет

Слайд 336Отличия строки
std::basic_string требует от используемого типа символов расширенного набора операций
См. char_traits
std::basic_string определяет
Отличия строки
std::basic_string требует от используемого типа символов расширенного набора операций
См. char_traits
std::basic_string определяет

Слайд 337Вектор – std::val_array
Есть доступ по индексу []
Есть метод size
Реализует маетматические операции над
Вектор – std::val_array
Есть доступ по индексу []
Есть метод size
Реализует маетматические операции над
![Вектор – std::val_array Есть доступ по индексу [] Есть метод size Реализует маетматические операции над векторами](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/378472/slide-336.jpg)
Слайд 338Битовый массив – std::bit_set
Возможен доступ к биту с помощью оператора []
Дополнительно реализуются
Битовый массив – std::bit_set
Возможен доступ к биту с помощью оператора []
Дополнительно реализуются
![Битовый массив – std::bit_set Возможен доступ к биту с помощью оператора [] Дополнительно реализуются побитовые операции](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/378472/slide-337.jpg)
Слайд 339Потоки ввода-вывода и итераторы
Основным инструментом ввода-вывода в STL являются потоки ввода-вывода
Поток ввода
Потоки ввода-вывода и итераторы
Основным инструментом ввода-вывода в STL являются потоки ввода-вывода
Поток ввода

Слайд 340Потоки ввода-вывода и итераторы
Поток вывода – это устройство, в которое можно вывести
Потоки ввода-вывода и итераторы
Поток вывода – это устройство, в которое можно вывести

Слайд 341Потоки ввода-вывода и итераторы
Если мы читаем из потока или записываем в поток
Потоки ввода-вывода и итераторы
Если мы читаем из потока или записываем в поток

Слайд 342Задание
Напишите программу, читающую набор целых чисел из файла и записывающую их в
Задание
Напишите программу, читающую набор целых чисел из файла и записывающую их в

Слайд 343Лабораторная работа №3. Использование стандартных контейнеров данных
Лабораторная работа №3. Использование стандартных контейнеров данных

Слайд 344Задание
Разработать программу на языке C++, реализующую функциональность в соответствии с вариантом задания.
Настоятельно
Задание
Разработать программу на языке C++, реализующую функциональность в соответствии с вариантом задания.
Настоятельно

Слайд 345Варианты задания
Реализовать программу, хранящую совокупность многоугольников на плоскости и позволяющую организовать быстрый
Варианты задания
Реализовать программу, хранящую совокупность многоугольников на плоскости и позволяющую организовать быстрый

Слайд 346Варианты задания
Реализовать программу, хранящую совокупность отрезков на плоскости и поддерживающую добавление отрезка
Варианты задания
Реализовать программу, хранящую совокупность отрезков на плоскости и поддерживающую добавление отрезка

Слайд 347Варианты задания
Реализовать программу, хранящую множество шариков, летающих в комнате, поддерживающих добавление и
Варианты задания
Реализовать программу, хранящую множество шариков, летающих в комнате, поддерживающих добавление и

Слайд 348Варианты задания
Реализовать систему регистрации сделок на бирже. Для каждой сделки указывается, какой
Варианты задания
Реализовать систему регистрации сделок на бирже. Для каждой сделки указывается, какой

Слайд 349Варианты задания
Реализовать программу электронного магазина, поддерживающую три операции
Добавление информации о появлении в
Варианты задания
Реализовать программу электронного магазина, поддерживающую три операции
Добавление информации о появлении в

Слайд 350Варианты задания
Реализовать программу, которая получает результаты измерений одной и той же меняющейся
Варианты задания
Реализовать программу, которая получает результаты измерений одной и той же меняющейся

Слайд 351Варианты задания
При голосовании приходят результаты в виде «На участке № такой-то такая-то
Варианты задания
При голосовании приходят результаты в виде «На участке № такой-то такая-то

Слайд 352Варианты задания
Корабли присылают в каждый момент времени данные о своей скорости и
Варианты задания
Корабли присылают в каждый момент времени данные о своей скорости и

Слайд 353Варианты задания
Завод по сборке автомобилей покупает комплекты комплектующих и производит автомобили из
Варианты задания
Завод по сборке автомобилей покупает комплекты комплектующих и производит автомобили из

Слайд 354Варианты задания
Подразделения фирмы, нуждающиеся в покупке компьютеров, вносят заказы в базу данных.
Варианты задания
Подразделения фирмы, нуждающиеся в покупке компьютеров, вносят заказы в базу данных.

Слайд 355Варианты задания
Операционная система хранит базу данных процессов. Процесс имеет постоянный приоритет (константа,
Варианты задания
Операционная система хранит базу данных процессов. Процесс имеет постоянный приоритет (константа,

Слайд 356Лекция 8. Стандартные алгоритмы STL.
Простейший стандартный алгоритм for_each
Возможности применения алгоритмов на примере
Лекция 8. Стандартные алгоритмы STL.
Простейший стандартный алгоритм for_each
Возможности применения алгоритмов на примере

Слайд 357std::for_each
Алгоритм std::for_each заключается в вызове заданной функции для каждого элемента контейнера
for_each не
std::for_each
Алгоритм std::for_each заключается в вызове заданной функции для каждого элемента контейнера
for_each не

Слайд 358std::for_each - пример
for_each( v1.begin() , v1.end() , Print )
эквивалентно
for ( v1::iterator iter
std::for_each - пример
for_each( v1.begin() , v1.end() , Print )
эквивалентно
for ( v1::iterator iter

Слайд 359std::for_each
В приведенном примере мы вызывали функцию Print, единственным параметром которой был элемент
std::for_each
В приведенном примере мы вызывали функцию Print, единственным параметром которой был элемент

Слайд 360Пример – вызов функции с несколькими параметрами
for ( v1::iterator iter = v1.begin()
Пример – вызов функции с несколькими параметрами
for ( v1::iterator iter = v1.begin()

Слайд 361Пример – вызов метода класса с несколькими параметрами
for ( v1::iterator iter =
Пример – вызов метода класса с несколькими параметрами
for ( v1::iterator iter =

Слайд 362std::for_each
Ясно, что мы должны уметь применять for_each для таких ситуаций – иначе
std::for_each
Ясно, что мы должны уметь применять for_each для таких ситуаций – иначе

Слайд 363Шаблоны. Взаимозаменяемость классов и функций
for_each – это шаблон функции.
Шаблоны C++ являются механизмом
Шаблоны. Взаимозаменяемость классов и функций
for_each – это шаблон функции.
Шаблоны C++ являются механизмом

Слайд 364Шаблоны. Взаимозаменяемость классов и функций
Но это означает, что с точки зрения for_each
Шаблоны. Взаимозаменяемость классов и функций
Но это означает, что с точки зрения for_each

Слайд 365Класс-функция
class Printer
{
public:
Printer( std::ostream& stream )
:Stream(stream) {}
void operator()(int a )
{
Print( Stream , a
Класс-функция
class Printer
{
public:
Printer( std::ostream& stream )
:Stream(stream) {}
void operator()(int a )
{
Print( Stream , a

Слайд 366Класс-функция
С точки зрения шаблона for_each, объект класса Printer – полный аналог функции,
Класс-функция
С точки зрения шаблона for_each, объект класса Printer – полный аналог функции,

Слайд 367Класс-функция
Printer printer( stream1 );
std::for_each( v1.begin() , v1.end() , printer );
эквивалентно
for (
Класс-функция
Printer printer( stream1 );
std::for_each( v1.begin() , v1.end() , printer );
эквивалентно
for (

Слайд 368Класс-функция
И это уже эквивалентно
for ( v1::iterator iter = v1.begin() ;
iter !=
Класс-функция
И это уже эквивалентно
for ( v1::iterator iter = v1.begin() ;
iter !=

Слайд 369Вызов метода класса
for ( v1::iterator iter = v1.begin() ;
iter != v1.end()
Вызов метода класса
for ( v1::iterator iter = v1.begin() ;
iter != v1.end()

Слайд 370Вызов метода класса
class ProcessorAdapter
{
public:
ProcessorAdapter ( Processor& processor )
:Proc( processor ) {}
void operator()( int
Вызов метода класса
class ProcessorAdapter
{
public:
ProcessorAdapter ( Processor& processor )
:Proc( processor ) {}
void operator()( int

Слайд 371Вызов метода класса
ProcessorAdapter adapter( processor );
std::for_each( int_vector.begin() , int_vector.end() , adapter );
эквивалентно
for
Вызов метода класса
ProcessorAdapter adapter( processor );
std::for_each( int_vector.begin() , int_vector.end() , adapter );
эквивалентно
for

Слайд 372Возвращаемое значение for_each
Функция for_each возвращает тот объект, метод operator() которого она вызвала
Возвращаемое значение for_each
Функция for_each возвращает тот объект, метод operator() которого она вызвала

Слайд 373Задание
Реализуйте поиск максимума массива вещественных чисел через for_each
Задание
Реализуйте поиск максимума массива вещественных чисел через for_each

Слайд 374Решение
class MaxSearch
{
public:
MaxSearch( double first )
:CurMax( first ) {}
void operatorI()( double cur )
{
if
Решение
class MaxSearch
{
public:
MaxSearch( double first )
:CurMax( first ) {}
void operatorI()( double cur )
{
if

Слайд 375Решение
std::vector < double > double _vector;
…
MaxSearch search(*double _vector.begin() );
search = std::for_each( double_vector.begin()
Решение
std::vector < double > double _vector;
…
MaxSearch search(*double _vector.begin() );
search = std::for_each( double_vector.begin()

Слайд 376Вызовы функций с параметрами – готовые механизмы
Если мы хотим вызвать для всех
Вызовы функций с параметрами – готовые механизмы
Если мы хотим вызвать для всех

Слайд 377Вызовы функций с параметрами – готовые механизмы
Другие готовые механизмы для вызова функций
Вызовы функций с параметрами – готовые механизмы
Другие готовые механизмы для вызова функций

Слайд 378Методы поиска
Все методы принимают два итератора (указывающие на начало последовательности и на
Методы поиска
Все методы принимают два итератора (указывающие на начало последовательности и на

Слайд 379Методы поиска
find – поиск равного данному
find_if – поиск соответствующего условию
find_first_of – поиск
Методы поиска
find – поиск равного данному
find_if – поиск соответствующего условию
find_first_of – поиск

Слайд 380Задание
Как найти первый символ, больший квадрата предыдущего?
Предложите два метода
Задание
Как найти первый символ, больший квадрата предыдущего?
Предложите два метода

Слайд 381Поиск нарушения порядка в массиве в стиле C
bool Test( double a ,
Поиск нарушения порядка в массиве в стиле C
bool Test( double a ,

Слайд 382Методы подсчета
count – подсчет элементов, равных данному
count_if – подсчет количества элементов, соответствующих
Методы подсчета
count – подсчет элементов, равных данному
count_if – подсчет количества элементов, соответствующих

Слайд 383Методы подсчета
Фиксированный тип – не годится.
Вариант:
template < class TIterator , class
Методы подсчета
Фиксированный тип – не годится.
Вариант:
template < class TIterator , class

Слайд 384Методы подсчета
В данном случае в классе TIterator должно быть что-то вроде
class TIterator
{
public:
typedef
Методы подсчета
В данном случае в классе TIterator должно быть что-то вроде
class TIterator
{
public:
typedef

Слайд 385Методы подсчета
В этом случае мы не сможем использовать указатель как итератор массива
Методы подсчета
В этом случае мы не сможем использовать указатель как итератор массива

Слайд 386Методы подсчета - решение
Определим шаблонный класс iterator_traits вида
template < class TIterator >
class
Методы подсчета - решение
Определим шаблонный класс iterator_traits вида
template < class TIterator >
class

Слайд 387Методы подсчета - решение
template < class TIterator , class TValue >
iterator_traits::difference_type count(
TIterator
Методы подсчета - решение
template < class TIterator , class TValue >
iterator_traits
TIterator

Слайд 388Методы подсчета - решение
Внешне кажется, что ничего не изменилось
iterator_traits::difference_type
это эквивалент
TIterator::difference_type
Но теперь пользователь
Методы подсчета - решение
Внешне кажется, что ничего не изменилось
iterator_traits
это эквивалент
TIterator::difference_type
Но теперь пользователь

Слайд 389Методы подсчета - решение
Определим частичную спецификацию шаблона iterator_traits вида
template< >
class iterator_traits
{
typedef int
Методы подсчета - решение
Определим частичную спецификацию шаблона iterator_traits вида
template< >
class iterator_traits
{
typedef int

Слайд 390Методы подсчета - решение
int A[ 5 ];
…
int n = std::count( A ,
Методы подсчета - решение
int A[ 5 ];
…
int n = std::count( A ,
![Методы подсчета - решение int A[ 5 ]; … int n =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/378472/slide-389.jpg)
Слайд 391Минимумы и максимумы
max_element и min_element ищут максимальный или минимальный элемент последовательности
Принимают итераторы,
Минимумы и максимумы
max_element и min_element ищут максимальный или минимальный элемент последовательности
Принимают итераторы,

Слайд 392Сравнение последовательностей
equal – проверка на равенство
mismatch – поиск первого различия
lexicographical_compare
Задается объект-компаратор
Типы элементов
Сравнение последовательностей
equal – проверка на равенство
mismatch – поиск первого различия
lexicographical_compare
Задается объект-компаратор
Типы элементов

Слайд 393Сравнение последовательностей
В одном массиве строки, в другом числа
Нужно проверить, что длина строки
Сравнение последовательностей
В одном массиве строки, в другом числа
Нужно проверить, что длина строки

Слайд 394Подпоследовательности
search - поиск первого вхождения подпоследовательности в последовательность. Задаются 4 итератора и
Подпоследовательности
search - поиск первого вхождения подпоследовательности в последовательность. Задаются 4 итератора и

Слайд 395Задание
Предложите два способа поиска трех нечетных чисел подряд – с помощью search
Задание
Предложите два способа поиска трех нечетных чисел подряд – с помощью search

Слайд 396Копирование
сopy копирует одну последовательность в другую
Задаются 3 итератора – начало и конец
Копирование
сopy копирует одну последовательность в другую
Задаются 3 итератора – начало и конец

Слайд 397Копирование
vector2.resize( vector1.size() );
std::copy( vector1.begin() , vector1.end() , vector2.begin() );
или
std::copy( vector1.begin() , vector1.end()
Копирование
vector2.resize( vector1.size() );
std::copy( vector1.begin() , vector1.end() , vector2.begin() );
или
std::copy( vector1.begin() , vector1.end()

Слайд 398Вопрос
Корректен ли код, копирующий 5 первых элементов последовательности в конец?
const int N
Вопрос
Корректен ли код, копирующий 5 первых элементов последовательности в конец?
const int N

Слайд 399Копирование
Не корректен, если N < 10. Мы затрем элементы до того, как
Копирование
Не корректен, если N < 10. Мы затрем элементы до того, как

Слайд 400Преобразование
Преобразование последовательности
double TransformT( double c )
{
return 1.8 * c + 32;
}
std::vector temperatures;
…
std::transform(
Преобразование
Преобразование последовательности
double TransformT( double c )
{
return 1.8 * c + 32;
}
std::vector
…
std::transform(

Слайд 401Преобразование двух последовательностей
Результат преобразования записывается в третью.
double Fib( double a , double
Преобразование двух последовательностей
Результат преобразования записывается в третью.
double Fib( double a , double

Слайд 402Удаление
std::remove удаляет из последовательности, заданной двумя итераторами, элементы, равные данному
std::remove не может
Удаление
std::remove удаляет из последовательности, заданной двумя итераторами, элементы, равные данному
std::remove не может

Слайд 403Удаление
Удаление

Слайд 404Удаление
Результатом remove является итератор, указывающий на элемент, следующий за последним оставшимся
После remove
Удаление
Результатом remove является итератор, указывающий на элемент, следующий за последним оставшимся
После remove

Слайд 405Удаление
remove_if – удаление элементов, соответствующих условию
Задача: удалить первые 10 отрицательных чисел
unique –
Удаление
remove_if – удаление элементов, соответствующих условию
Задача: удалить первые 10 отрицательных чисел
unique –

Слайд 406Удаление
remove_copy – копирует элементы во вторую последовательность, удаляя равные данному
remove_copy_if - копирует
Удаление
remove_copy – копирует элементы во вторую последовательность, удаляя равные данному
remove_copy_if - копирует

Слайд 407Замена
Аналогично удалению, но заменяет на заданное значение
std:replace
std::replace_if
std::replace_copy
std::replace_copy_if
Замена
Аналогично удалению, но заменяет на заданное значение
std:replace
std::replace_if
std::replace_copy
std::replace_copy_if

Слайд 408Заполнение
std::fill – принимает начальный и конечный итераторы, значение
std::fill_n – принимает итератор вывода,
Заполнение
std::fill – принимает начальный и конечный итераторы, значение
std::fill_n – принимает итератор вывода,

Слайд 409Заполнение. Примеры
std::vector< int> int_vector;
int_vector.resize( 100 );
std::fill( int_vector.begin() , int_vector.end() , 0 );
Заполнение. Примеры
std::vector< int> int_vector;
int_vector.resize( 100 );
std::fill( int_vector.begin() , int_vector.end() , 0 );

Слайд 410Заполнение
Можно задать не значение, а функцию (которая будет вызвана для каждого элемента
Заполнение
Можно задать не значение, а функцию (которая будет вызвана для каждого элемента

Слайд 411Заполнение
class FibonacciGenerator
{
public:
FibonacciGenerator()
:First( 0 ),Second( 1 ) {}
int operator()()
{
Заполнение
class FibonacciGenerator
{
public:
FibonacciGenerator()
:First( 0 ),Second( 1 ) {}
int operator()()
{

Слайд 412Перестановки
std::swap – меняет местами два значения, принимая ссылки
std::iter_swap – меняет местами значения,
Перестановки
std::swap – меняет местами два значения, принимая ссылки
std::iter_swap – меняет местами значения,

Слайд 413Перестановки
Какой иетратор требуется для выполнения swap_ranges?
Перестановки
Какой иетратор требуется для выполнения swap_ranges?

Слайд 414Перестановки
std::reverse, std::reverse_copy – переставляет в обратном порядке
std::rotate, std::rotate_copy – циклический сдвиг
std::random_shuffle –
Перестановки
std::reverse, std::reverse_copy – переставляет в обратном порядке
std::rotate, std::rotate_copy – циклический сдвиг
std::random_shuffle –

Слайд 415Лексикографические перестановки
abc
acb
bac
bca
cab
cba
Лексикографические перестановки
abc
acb
bac
bca
cab
cba

Слайд 416Лексикографические перестановки
prev_permutation – предыдущая перестановка
next_permutation – следующая перестановка
Принимает два двунаправленных итератора и
Лексикографические перестановки
prev_permutation – предыдущая перестановка
next_permutation – следующая перестановка
Принимает два двунаправленных итератора и

Слайд 417Сортировки
std::sort – сортировка (обычно быстрая сортировка)
std::stable_sort – сортировка с сохранением порядка равных
Сортировки
std::sort – сортировка (обычно быстрая сортировка)
std::stable_sort – сортировка с сохранением порядка равных

Слайд 418Сортировки
vector2.resize( 10 );
std::partial_sort_copy(
vector1.begin() , vector1.end() , vector2.begin() , vector2.end() );
Сортировки
vector2.resize( 10 );
std::partial_sort_copy(
vector1.begin() , vector1.end() , vector2.begin() , vector2.end() );

Слайд 419Сортировки
std::nth_element – поиск порядковой статистики (гарантирует, что на позиции N будет тот
Сортировки
std::nth_element – поиск порядковой статистики (гарантирует, что на позиции N будет тот

Слайд 420Сортировки
class Student
{
public:
double AverageGrade() const;
};
class StudentComparator
{
public:
bool operator( const Student& a , const Student&
Сортировки
class Student
{
public:
double AverageGrade() const;
};
class StudentComparator
{
public:
bool operator( const Student& a , const Student&

Слайд 421Бинарный поиск
std::binary_search – бинарный поиск в отсортированной последовательности (true, если найден)
std::lower_bound -
Бинарный поиск
std::binary_search – бинарный поиск в отсортированной последовательности (true, если найден)
std::lower_bound -

Слайд 422Слияние
std::merge – объединяет две отсортированные последовательности в одну
std::inplace_merge – объединение двух отсортированных
Слияние
std::merge – объединяет две отсортированные последовательности в одну
std::inplace_merge – объединение двух отсортированных

Слайд 423Слияние
for ( int k = 1 ; k < n; k *=
Слияние
for ( int k = 1 ; k < n; k *=

Слайд 424Разделение
Делим последовательность на группы, соответствующие условию и не соответствующие ему - partition
Если
Разделение
Делим последовательность на группы, соответствующие условию и не соответствующие ему - partition
Если

Слайд 425Пирамиды
std::make_heap – расставляет элементы в последовательности так, как они лежали бы в
Пирамиды
std::make_heap – расставляет элементы в последовательности так, как они лежали бы в

Слайд 426make_heap
6
7
5
9
4
8
Исходная последовательность
Измененная последовательность
3
2
8
7
9
6
4
5
3
2
make_heap
6
7
5
9
4
8
Исходная последовательность
Измененная последовательность
3
2
8
7
9
6
4
5
3
2

Слайд 427Вопрос
Как реализовать пирамидальную сортировку вектора?
Вопрос
Как реализовать пирамидальную сортировку вектора?

Слайд 428Пирамидальная сортировка
std::make_heap ( vec.begin() , vec.end() );
std::sort_heap( vec.begin() , vec.end() )
Пирамидальная сортировка
std::make_heap ( vec.begin() , vec.end() );
std::sort_heap( vec.begin() , vec.end() )

Слайд 429Множественные операции
Реализуются над отсортированными последовательностями
std::includes – проверка включения
std::set_union - объединение
std::set_intersection - пересечение
std::set_difference
Множественные операции
Реализуются над отсортированными последовательностями
std::includes – проверка включения
std::set_union - объединение
std::set_intersection - пересечение
std::set_difference

Слайд 430Лабораторная работа №4. Использование стандартных алгоритмов STL.
Лабораторная работа №4. Использование стандартных алгоритмов STL.

Слайд 431Задание
Разработать программу на языке C++, реализующую функциональность в соответствии с вариантом задания.
Настоятельно
Задание
Разработать программу на языке C++, реализующую функциональность в соответствии с вариантом задания.
Настоятельно

Слайд 432Варианты задания
Реализовать программу хранения массива геометрических фигур в двумерном пространстве. Фигура –
Варианты задания
Реализовать программу хранения массива геометрических фигур в двумерном пространстве. Фигура –

Слайд 433Варианты задания
Реализовать программу, хранящую в отсортированном массиве список пользователей операционной системы с
Варианты задания
Реализовать программу, хранящую в отсортированном массиве список пользователей операционной системы с

Слайд 434Варианты задания
Разработайте программу, хранящую базу данных телефонной компании (фамилия, номер, остаток денег
Варианты задания
Разработайте программу, хранящую базу данных телефонной компании (фамилия, номер, остаток денег

Слайд 435Варианты задания
Реализуйте программу, заполняющую массив фиксированной длины прочитанными из файла значениями или
Варианты задания
Реализуйте программу, заполняющую массив фиксированной длины прочитанными из файла значениями или

Слайд 436Варианты задания
Реализуйте программу, считывающие из двух файлов два набора строчек и проверяющую
Варианты задания
Реализуйте программу, считывающие из двух файлов два набора строчек и проверяющую

Слайд 437Варианты задания
База данных телефонной компании реализована в форме отсортированного массива. Периодически приходит
Варианты задания
База данных телефонной компании реализована в форме отсортированного массива. Периодически приходит

Слайд 438Варианты задания
Прочитайте из файла последовательность чисел и выведите все возможные их перестановки
Варианты задания
Прочитайте из файла последовательность чисел и выведите все возможные их перестановки

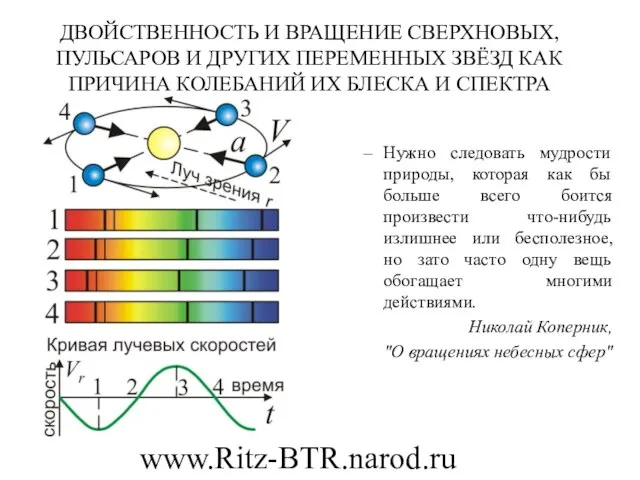 www.Ritz-BTR.narod.ru
www.Ritz-BTR.narod.ru Ресурсы и назначения
Ресурсы и назначения Интернет 11 класс
Интернет 11 класс Мастер – класс Вязка туристических узлов, применение их в туристской деятельности
Мастер – класс Вязка туристических узлов, применение их в туристской деятельности реклама
реклама Фантазии синьора Родари
Фантазии синьора Родари Развитие творческих способностей учащихся на уроках информатики
Развитие творческих способностей учащихся на уроках информатики Оформляем работу интересно и правильно
Оформляем работу интересно и правильно Информационно-аналитическая система «Курорты Кубани»
Информационно-аналитическая система «Курорты Кубани» Правосудие в современной России
Правосудие в современной России Классификация магнитных материалов
Классификация магнитных материалов Психология в экскурсоведении
Психология в экскурсоведении Илья Муромец и Соловей-разбойник
Илья Муромец и Соловей-разбойник День открытых дверей
День открытых дверей Психолого-педагогические вопросы развития культуры детской социальной инициативы в образовательных учреждениях
Психолого-педагогические вопросы развития культуры детской социальной инициативы в образовательных учреждениях Давыдова Александра. Предвыборная программа кандидата в СС ФМОПИ II созыва
Давыдова Александра. Предвыборная программа кандидата в СС ФМОПИ II созыва Исследовательский проектИстория народной медицины
Исследовательский проектИстория народной медицины Внеземные цивилизации
Внеземные цивилизации Карта пробных ароматов: Al Haramain/Aysha (милая)
Карта пробных ароматов: Al Haramain/Aysha (милая) Презентация на тему Бой у мыса Акций
Презентация на тему Бой у мыса Акций  Вступление в материаловедение
Вступление в материаловедение  Урок русского языка в 5 классеУчитель Сухицкая В.Т.Брянский городской лицей №1имени А.С.Пушкина
Урок русского языка в 5 классеУчитель Сухицкая В.Т.Брянский городской лицей №1имени А.С.Пушкина Виды и рода вооружённых Сил РФ. Сухопутные войска
Виды и рода вооружённых Сил РФ. Сухопутные войска Движение денежных средств: структура, содержание и аналитические возможности
Движение денежных средств: структура, содержание и аналитические возможности Интерференция света
Интерференция света Санитария и гигиена при приготовлении пищи
Санитария и гигиена при приготовлении пищи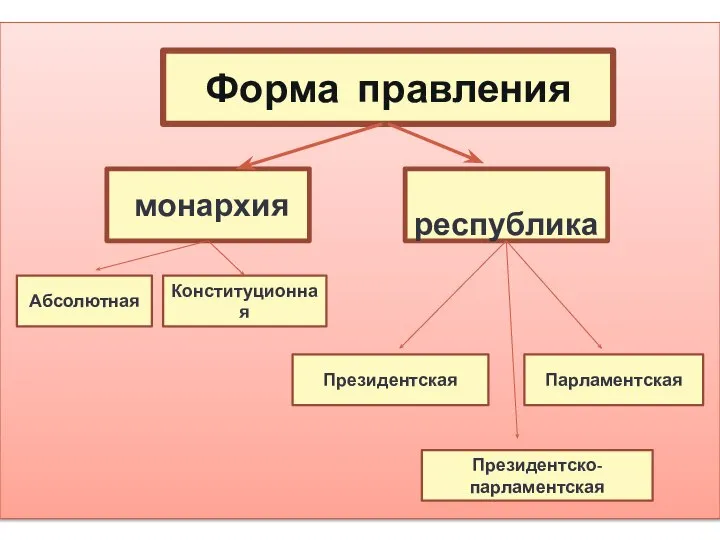 Форма правления
Форма правления Презентация на тему Мы против гриппа
Презентация на тему Мы против гриппа