Слайд 2
Fig. 1.6.1. M.Flynn's classifications: classes SISD and SIMD
CPU is one or several
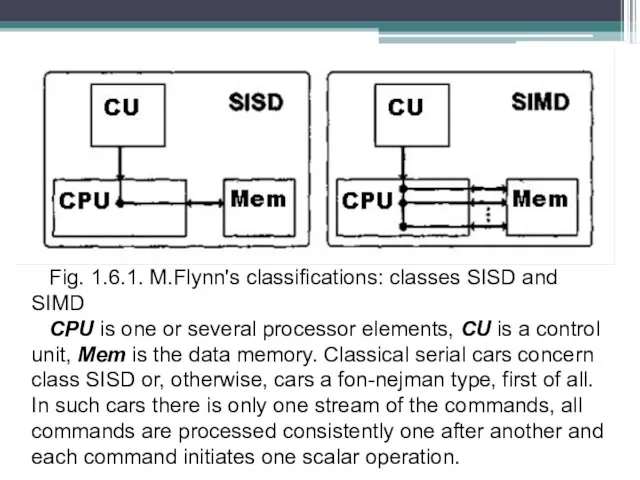
processor elements, CU is a control unit, Mem is the data memory. Classical serial cars concern class SISD or, otherwise, cars a fon-nejman type, first of all. In such cars there is only one stream of the commands, all commands are processed consistently one after another and each command initiates one scalar operation.
Слайд 3SIMD (Single Instruction stream/Multiple Data stream) - a single stream of commands

and a plural data stream (fig. 1.6.1). In this class of architecture one stream of commands including, unlike the previous class, vector commands remains. It allows carrying out one arithmetic operation at once over many data, for example, over vector elements.
MISD (Multiple Instruction stream/Single Data stream) - a plural stream of commands and a single data stream (fig. 1.6.2). Definition means presence in architecture of many processors processing the same data stream. However neither Flynn, nor other experts in the field of architecture of computers could not present till now a convincing example of the real-life computing system constructed on the given principle. A number of researchers is carried by conveyor cars to the given class, however it has not found a definitive recognition in scientific community. We will consider that while the given class is empty.
Слайд 4
Fig. 1.6.2. Classes MISD and MIMD M.Flynn's classifications
MIMD (Multiple Instruction stream/Multiple Data
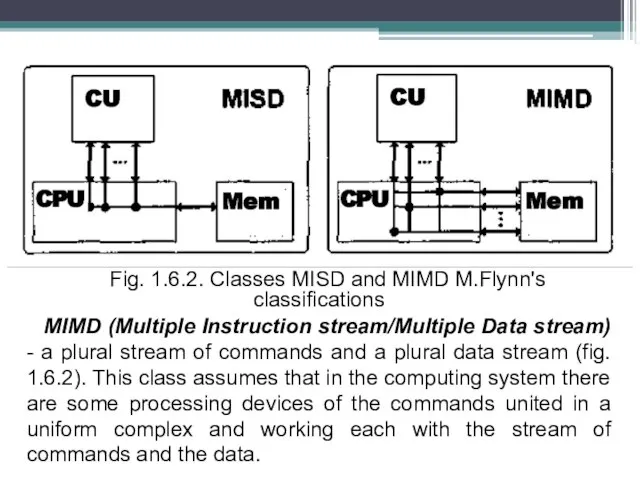
stream) - a plural stream of commands and a plural data stream (fig. 1.6.2). This class assumes that in the computing system there are some processing devices of the commands united in a uniform complex and working each with the stream of commands and the data.
Слайд 5R. Hokney's classification. R. Hockney has developed the approach to classification for

more detailed ordering of the computers getting to class MIMD on M.Flynn systematization. Class MIMD is extremely wide and unites the whole set of various types of architecture. Trying to systematize architecture in this class, R. Hockney has received the hierarchical structure presented on fig. 1.6.3.
The basic idea of classification consists in the following. The plural stream of commands can be processed in two ways: or one conveyor processing device working in a mode of division of time for separate streams, or each stream is processed by the own device. The first possibility is used in MIMD-computers which the author names conveyor.
Слайд 6Fig. 1.6.3. R. Hokney's additional classification of class MIMD
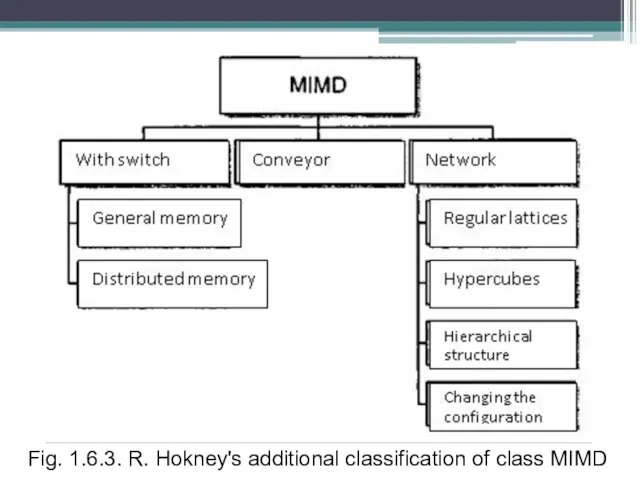
Слайд 7The architecture using the second possibility, in turn, again share on two

classes. MIMD-computers in which direct communication of each processor with everyone, realized by means of the switch is possible get to the first class. In the second class there are MIMD-computers in which direct communication of each processor is possible only with the nearest neighbors in a network, and interaction of remote processors is supported by special system of routing.
Among MIMD-cars with switch Hokney allocates in what all memory is distributed among processors as their local memory. In this case dialogue of processors is realized by means of the difficult switch making a considerable part of the computer. Such cars carry the name of MIMD-cars with the distributed memory. If memory is the divided resource accessible to all processors through the switch MIMD-cars are systems with the general memory.
Слайд 8According to type of switches it is possible to spend classification and

further: the simple switch, the multicascade switch, the general type and etc. Many modern computing systems have both the general divided memory, and the distributed local. The author considers such systems as hybrid MIMD with the switch.
By consideration of MIMD-cars with network structure it is considered that all of them have the distributed memory, and the further classification is spent according to network topology: a star-shaped network, regular lattices of different dimension, hypercubes, networks with hierarchical structure, such as trees, pyramids, clusters and, at last, the networks changing the configuration.
Let's notice that if the architecture of the computer is designed with use of several networks with various topology, that, most likely, by analogy to hybrid MIMD-cars to switches, it is necessary to name them hybrid network MIMD-cars, and using ideas of different classes - simply hybrid MIMD-cars.
Слайд 9Computing systems with symmetric multiprocessing processing.
SMP architecture (symmetric multiprocessing) - symmetric multiprocessing

architecture. The main feature of systems with architecture SMP is presence of the general physical memory divided by all processors.
SMP the system consists of several homogeneous processors and a file of the general memory. One of often used in SMP architecture of approaches for formation of scaled, popular system of memory, consists in the homogeneous organisation of access to memory by means of the organisation of the scaled channel memory-processors. Each operation of access to memory is interpreted as transaction on the type processors-memories.
Слайд 10SMP is one computer with several processors equal in rights. All the

rest - in one copy: one memory, one subsystem of the input/conclusion, one operating system. The word "equal in rights" (as well as a word "symmetric" in the architecture name) means that each processor can do everything that any another. Each processor has access to all memory, can carry out any operation of input/conclusion, interrupt other processors etc. But this representation it is fair only at software level. That actually in SMP there are some devices of memory is held back.
In SMP each processor has at least one own cache memory (and it is possible, and a little). Cache memory presence (or simply cache) is necessary for achievement of good productivity as the basic memory (DRAM - Direct Random Access Memory) works too slowly in comparison with speed of processors, and every year this parity worsens. The cache works with speed of the processor, but this equipment expensive and consequently cache memory devices possess concerning small capacity.
Слайд 11Transfer of the data implicitly made by equipment SMP between caches is

the fastest and cheapest communication medium in any parallel architecture of general purpose. Therefore in the presence of a great number of short transactions when it is necessary to synchronise often access to the general data, architecture SMP is the best choice; any other architecture works worse. Besides, architecture SMP is most safe, if there is no confidence of that, how many actions on synchronisation is required, as the reality is always worse than expectations. From this does not follow that date transmission between caches is desirable. The parallel program will be always carried out by that faster, than its parts less co-operate. But if these parts have to co-operate often the program will faster work on SMP.
Слайд 12The main advantage of architecture SMP in comparison with other approaches to

realization of multiprocessor systems is the transparency for program applications. This factor essentially improves time of an exit for the market and readiness of traditional commercial applications for systems SMP in comparison with other multiprocessor architecture.
Primary benefits of SMP-systems:
• simplicity and universality for programming. Architecture SMP does not impose restrictions on the model of programming used at an application creation: the model of parallel branches when all processors work absolutely independently from each other - however is usually used, it is possible to realise and the models using an interprocessor exchange. Use of the general memory increases speed of such exchange, the user also has access at once to all memory size. For SMP-systems there are rather effective remedies automatic paralleling.
Слайд 13• ease in operation. As a rule, SMP-systems use the system of

cooling based on air air-conditioning that facilitates their maintenance service.
• rather low price.
Disadvantages:
• systems with the general memory, constructed on the system tyre, are badly scaled
This important lack of SMP-system does not allow to consider their rather perspective. The reasons of bad scalability consist that at present the tyre is capable to process only one transaction owing to what there are problems of a resolution of conflicts at the simultaneous reference of several processors to the same areas of the general physical memory. Computing elements start to disturb each other. When there will be such conflict, depends on speed of communication and from quantity of computing elements. Now conflicts can occur in the presence of 8-24
Слайд 14processors. Besides, the system tired has limited (though also high) carrying capacity

(ПС) and the limited number of slots. All it with evidence interferes with productivity increase at increase in number of processors and numbers of connected users. In real systems it is possible to use no more than 32 processors. For construction of scaled systems on the basis of SMP are used cluster or NUMA-architecture. At work with SMP systems use a so-called paradigm of programming with divided memory (shared memory paradigm).
Computing systems with mass parallelism.
MPP architecture (massive parallel processing) - massive-parallel architecture. The main feature of such architecture consists that memory is physically divided. In this case the system is under construction of the separate modules containing the processor, local bank of operational memory, two communication processors (rooters) or the network adapter,
Слайд 15sometimes - hard disks and-or other devices of input/conclusion. One rooter is

used for transfer of commands, another - for date transmission. As a matter of fact, such modules represent full-function computers. To bank OP from the given module processors (CENTRAL PROCESSING UNIT) from the same module have access only. Modules incorporate special communication channels. The user can define logic number of the processor to which it is connected, and to organize an exchange of messages with other processors. Two variants of work of an operating system (OS) by architecture cars MPP are used. In one high-grade operating system (OS) works only by the operating car (front-end), on each separate module strongly cut down variant of OS which are ensuring functioning only of a branch located in it of the parallel application works. In the second variant on each module the high-grade UNIX-like OS established separately on each module works.
Слайд 16The main advantage:
The main advantage of systems with separate memory is

good scalability: unlike SMP-systems in cars with separate memory each processor has access only to the local memory in this connection there is no necessity in instruction cycle synchronization of processors. Almost all records on productivity for today are established by the cars of such architecture consisting of several thousand of processors (ASCI Red, ASCI Blue Pacific).
Disadvantages:
• absence of the general memory considerably reduces speed of an interprocessor exchange as there is no general environment for the data storage, intended for an exchange between processors. The special technics of programming for realization of an exchange by messages between processors Is required.
• each processor can use only the limited volume of local bank of memory.
Слайд 17• owing to the specified architectural lacks considerable efforts as much as

possible to use system resources are required. It defines the high price of the software for massive-parallel systems with separate memory.
The cluster’s organization of computing systems.
The cluster is a server group (called "nods") which work together, carry out the general problems and clients see them as one system. Thanks to the special equipment and the software, such level of protection against failures which is impossible at use of one server is provided. In case of failure of one of servers, a problem which it carried out, other server and working capacity of system incurs is restored. Thus users notice only time loss of working capacity and if the application is written competently and at all do not notice (except a small pause).
Слайд 18The cluster is the connected set of high-grade computers used as a

uniform resource. "The high-grade computer" is understood as concept the complete computer system possessing everything that is required for its functioning, including processors, memory, an input/conclusion subsystem, and also an operating system, subsystems, applications etc. Usually for this purpose suit personal computers or parallel systems which can possess architecture SMP and even NUMA. Clusters are loosely bound systems, communications of sites one of standard network technologies (Fast/Gigabit Ethernet, Myrinet) on base bus architecture or the switchboard is used. Therefore they are cheaper in construction by updating MPP of architecture.

 Конструкт урока
Конструкт урока Презентация на тему Профессия шофер
Презентация на тему Профессия шофер  Камышинский ХБКТекстильный кластер «Поволжье»
Камышинский ХБКТекстильный кластер «Поволжье» Совет Существ
Совет Существ Береги глаза смолоду!
Береги глаза смолоду! Диаграмма №1
Диаграмма №1  Правила сравнения дробей
Правила сравнения дробей Очистка поверхностных вод Минско-Вилейской системы
Очистка поверхностных вод Минско-Вилейской системы Об обучении эсперанто
Об обучении эсперанто Бренд города
Бренд города Янтарные штучки
Янтарные штучки Обязательные элементы спортивных дисциплин
Обязательные элементы спортивных дисциплин Молдавия
Молдавия Металлы
Металлы Материалы К заседанию Общественного совета при Федеральной службе по экологическому, технологическому и атомному надзору ПРЕД
Материалы К заседанию Общественного совета при Федеральной службе по экологическому, технологическому и атомному надзору ПРЕД Компания «ФОРМА»ПРЕДСТАВЛЯЕТ…….
Компания «ФОРМА»ПРЕДСТАВЛЯЕТ……. Мировая история: переход к новому времени. Россия в 16-17вв.
Мировая история: переход к новому времени. Россия в 16-17вв. Бизнес-план придорожного отеля Кипарис
Бизнес-план придорожного отеля Кипарис psikhya_Microsoft_PowerPoint
psikhya_Microsoft_PowerPoint Партнёрство бизнеса и Даунсайд Ап. Дети с синдромом Дауна в России Каждый год в России рождается 2500 детей с синдромом Дауна. От 85% та
Партнёрство бизнеса и Даунсайд Ап. Дети с синдромом Дауна в России Каждый год в России рождается 2500 детей с синдромом Дауна. От 85% та «Для ребят дошкольного возраста игры имеют исключительное значение: игра для них – учеба, игра для них – труд, игра для них – серье
«Для ребят дошкольного возраста игры имеют исключительное значение: игра для них – учеба, игра для них – труд, игра для них – серье Сущность человека и смысл человеческой жизни
Сущность человека и смысл человеческой жизни Организация внеурочной деятельности
Организация внеурочной деятельности Авангардизм в музыке
Авангардизм в музыке Результаты анкетирования«Определение уровня информированности о подготовке и процедуре проведения ЕГЭ» (ноябрь 2010г.)
Результаты анкетирования«Определение уровня информированности о подготовке и процедуре проведения ЕГЭ» (ноябрь 2010г.) Творчество Караваджо, Веласкеса
Творчество Караваджо, Веласкеса Вирусные видео на YouTube: успех - дело техники
Вирусные видео на YouTube: успех - дело техники Adidas performance outdoor ss'22
Adidas performance outdoor ss'22