- АрхитектураVLIW / EPIC

Содержание
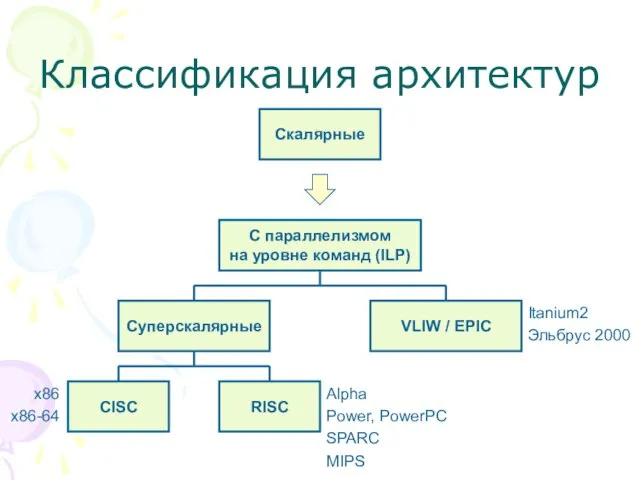
- 2. Классификация архитектур Скалярные С параллелизмом на уровне команд (ILP) Суперскалярные VLIW / EPIC RISC CISC Itanium2
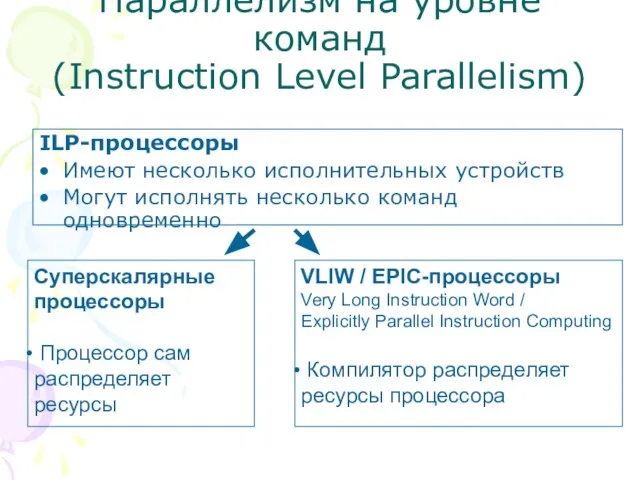
- 3. Параллелизм на уровне команд (Instruction Level Parallelism) ILP-процессоры Имеют несколько исполнительных устройств Могут исполнять несколько команд
- 4. Архитектура VLIW / EPIC VLIW – Very Long Instruction Word EPIC – Explicitly Parallel Instruction Computing
- 5. Сравнение суперскалярных и VLIW/EPIC-процессоров Какие задачи управления приходится решать, чтобы процессор работал быстро: Параллельное исполнение команд
- 6. Сравнение суперскалярных и VLIW/EPIC-процессоров Какие задачи управления приходится решать, чтобы процессор работал быстро: Параллельное исполнение команд
- 7. Сравнение суперскалярных и VLIW/EPIC-процессоров Какие задачи управления приходится решать, чтобы процессор работал быстро: Параллельное исполнение команд
- 8. Сравнение суперскалярных и VLIW/EPIC-процессоров Какие задачи управления приходится решать, чтобы процессор работал быстро: Параллельное исполнение команд
- 9. Сравнение суперскалярных и VLIW/EPIC-процессоров
- 10. Предсказание ветвлений Выборка Декодирование в RISC Переименование регистров Переупорядочение и распараллеливание Исполнение Завершение CISC RISC VLIW
- 11. Архитектура VLIW / EPIC История M-10 (1972) Cydrome (1984-1988) Cydra-5 256 bit VLIW (7 ops.), reg.
- 12. Архитектура Itanium
- 13. Семейство процессоров Itanium 2001 2002 2003 2006 Itanium (Merced) 800 MHz 4 MB L3 cache 180
- 14. Itanium: планы и реальность
- 15. Архитектура Itanium (IA-64) Явный ILP (параллелизм на уровне команд) Компилятор объединяет команды процессора в связки, которые
- 16. Особенности процессоров архитектуры Itanium (IA-64) Простой широкий конвейер Много команд за такт (до 6) Большие вычислительные
- 18. Регистры IA-64
- 19. Регистры IA-64 128 целочисленных регистра 64 бита + 1 бит NAT r0 = 0 целочисленные скалярные
- 20. Вращение регистров Верхние 75% регистров вращающиеся: целочисленные: r32 – r127 вещественные: f32 – f127 предикатные: p16
- 21. Стек регистров При вызове подпрограмм и возврате происходит сдвиг регистрового окна – целочисленные регистры работают как
- 22. Иерархия кэш-памяти Itanium2
- 23. Виртуальная память в IA-64 64-битное виртуальное адресное пространство Размер страницы: 4 KB – 4 GB 32
- 24. Конвейер Itanium2 Короткий 8-стадийный конвейер Полностью детерминированный путь команд Упорядоченная выборка команд, неупорядоченное завершение Рассчитан на
- 25. Исполнительные устройства Число операций за такт
- 26. Сравнение Itanium2 и Opteron
- 27. Itanium2 Montecito (2006) Montecito: 2 ядра по 2 потока (HyperThreading)
- 28. Команды IA-64 Команды IA-64 имеют RISC-подобный фиксированный формат: Пример команды: (p3) add r1 = r3, r4
- 29. Команды IA-64 Связка содержит 3 команды, поле шаблона и стоп-биты. Шаблон указывает типы команд в связке.
- 30. Команды IA-64 Всего возможно 24 различных шаблона: Процессор загружает максимум по 2 связки за такт. Только
- 31. Команды IA-64 Логические (and, …) Арифметические (add, …) Команды сравнения (cmp, …) Команды сдвига (shl, …)
- 32. Особенности целочисленной арифметики в Itanium2 До 6 операций за такт Операция fma (y=a*b+c) выполняется на регистрах
- 33. Особенности вещественной арифметики в Itanium2 Максимальная производительность 2 за такт: двойная точность 4 за такт: одинарная
- 34. Особенности вещественной арифметики в Itanium2 Вещественное деление (32-bit float) Вычисление корня (32-bit float)
- 35. Предсказание ветвлений в Itanium2 BHT – таблица истории ветвлений Адрес перехода и информация о предсказании в
- 36. Предвыборка инструкций в Itanium2 Автоматическая предвыборка следующей кэш-строки в кэш команд L1, если она содержится в
- 37. Фрагмент кода на ассемблере для IA-64 Синтаксис инструкций:
- 38. Средства повышения производительности в IA-64 Предикатное исполнение команд Аппаратные счетчики циклов Спекуляция по данным и управлению
- 39. Предикатное исполнение команд Позволяет зависимости по управлению (т.е. условные переходы) преобразовать в зависимости по данным. Пример:
- 40. Аппаратные счетчики циклов Архитектурная поддержка циклов По специальной команде перехода счетчики автоматически уменьшаются и делается проверка
- 41. Спекуляция по управлению Команды загрузки могут выполняться до того, как обнаружится, что это действительно нужно.
- 42. Спекуляция по данным Команды загрузки могут выполняться до того, как обнаружится, что это действительно можно.
- 43. Программная конвейеризация цикла Архитектурная поддержка параллельного исполнения команд цикла. Выполняется с помощью: Предикатных регистров Аппаратных счетчиков
- 51. Процессоры Itanium 9300 (Tukwila) Особенности нового Itanium-а Частота: до 1.73 GHz Режим Turbo boost: до 1.86
- 52. Процессоры Transmeta
- 53. Процессоры Transmeta Особенности архитектуры Архитектура VLIW Динамическая трансляция кода: x86 ? VLIW Интегрированный северный мост Ориентация
- 54. Динамическая двоичная компиляция Технология Code Morphing Преобразование команд x86 в команды VLIW Хранение транслированного кода в
- 55. Динамическая двоичная компиляция Технология Code Morphing Преобразование команд x86 в команды VLIW Хранение транслированного кода в
- 56. Динамическая двоичная компиляция Технология Code Morphing Преобразование команд x86 в команды VLIW Хранение транслированного кода в
- 57. Динамическая двоичная компиляция Технология Code Morphing Преобразование команд x86 в команды VLIW Хранение транслированного кода в
- 58. Динамическая двоичная компиляция Технология Code Morphing Преобразование команд x86 в команды VLIW Хранение транслированного кода в
- 59. Динамическая двоичная компиляция Технология Code Morphing Преобразование команд x86 в команды VLIW Хранение транслированного кода в
- 60. Процессор Transmeta Efficion Особенности Ширина командного слова 256 бит (8 команд) Кэш L1: 64 data /
- 61. Процессор Transmeta Efficion Стадии конвейера
- 62. Процессор Transmeta Efficion Структура команды Исполнительные устройства Отображение регистров
- 63. Архитектура Эльбрус 2000 Бабаян Борис Арташесович чл.корр. РАН Intel Fellow
- 64. Эльбрус 2000 ELBRUS – ExpLicit Basic Resources Utilization Scheduling (явное планирование использования основных ресурсов) Особенности архитектуры
- 65. Процессор Эльбрус Характеристики Командное слово переменной длины (2 – 16 слогов) До 23 операций за такт
- 66. Процессор Эльбрус Формат команды: Число слогов: 2 – 16 Типы слогов (максимальное число в команде) Заголовок
- 67. Процессор Эльбрус ALU0...ALU5 – арифметико-логические устройства; APU – устройство предварительной подкачки массивов; APB – буфер предварительной
- 68. Процессор Эльбрус Динамическая трансляция кода
- 70. Скачать презентацию
Слайд 2Классификация архитектур
Скалярные
С параллелизмом
на уровне команд (ILP)
Суперскалярные
VLIW / EPIC
RISC
CISC
Itanium2
Эльбрус 2000
Alpha
Power, PowerPC
SPARC
MIPS
x86
x86-64
Классификация архитектур
Скалярные
С параллелизмом
на уровне команд (ILP)
Суперскалярные
VLIW / EPIC
RISC
CISC
Itanium2
Эльбрус 2000
Alpha
Power, PowerPC
SPARC
MIPS
x86
x86-64
Слайд 3Параллелизм на уровне команд
(Instruction Level Parallelism)
ILP-процессоры
Имеют несколько исполнительных устройств
Могут исполнять несколько команд
Параллелизм на уровне команд
(Instruction Level Parallelism)
ILP-процессоры
Имеют несколько исполнительных устройств
Могут исполнять несколько команд
Слайд 4Архитектура VLIW / EPIC
VLIW – Very Long Instruction Word
EPIC – Explicitly Parallel
Архитектура VLIW / EPIC
VLIW – Very Long Instruction Word
EPIC – Explicitly Parallel

Слайд 5Сравнение суперскалярных и VLIW/EPIC-процессоров
Какие задачи управления приходится решать, чтобы процессор работал быстро:
Параллельное
Сравнение суперскалярных и VLIW/EPIC-процессоров
Какие задачи управления приходится решать, чтобы процессор работал быстро:
Параллельное

Слайд 6Сравнение суперскалярных и VLIW/EPIC-процессоров
Какие задачи управления приходится решать, чтобы процессор работал быстро:
Параллельное
Сравнение суперскалярных и VLIW/EPIC-процессоров
Какие задачи управления приходится решать, чтобы процессор работал быстро:
Параллельное

Слайд 7Сравнение суперскалярных и VLIW/EPIC-процессоров
Какие задачи управления приходится решать, чтобы процессор работал быстро:
Параллельное
Сравнение суперскалярных и VLIW/EPIC-процессоров
Какие задачи управления приходится решать, чтобы процессор работал быстро:
Параллельное
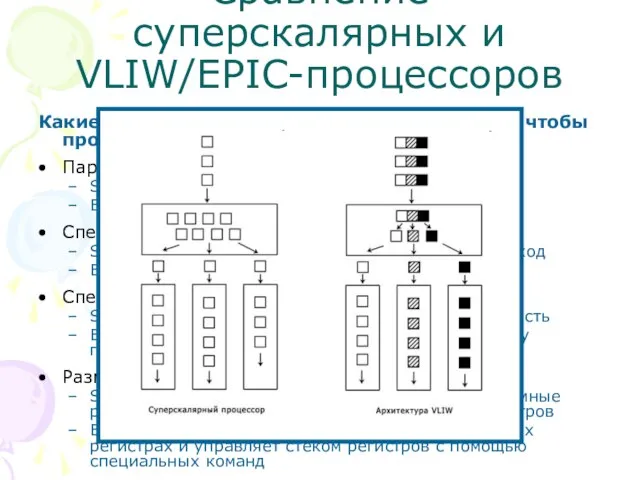
Слайд 8Сравнение суперскалярных и VLIW/EPIC-процессоров
Какие задачи управления приходится решать, чтобы процессор работал быстро:
Параллельное
Сравнение суперскалярных и VLIW/EPIC-процессоров
Какие задачи управления приходится решать, чтобы процессор работал быстро:
Параллельное

Слайд 9Сравнение суперскалярных и VLIW/EPIC-процессоров
Сравнение суперскалярных и VLIW/EPIC-процессоров

Слайд 10Предсказание ветвлений
Выборка
Декодирование в RISC
Переименование регистров
Переупорядочение и распараллеливание
Исполнение
Завершение
CISC
RISC
VLIW
Этапы обработки команды
Сравнение конвейеров
Предсказание ветвлений
Выборка
Декодирование в RISC
Переименование регистров
Переупорядочение и распараллеливание
Исполнение
Завершение
CISC
RISC
VLIW
Этапы обработки команды
Сравнение конвейеров
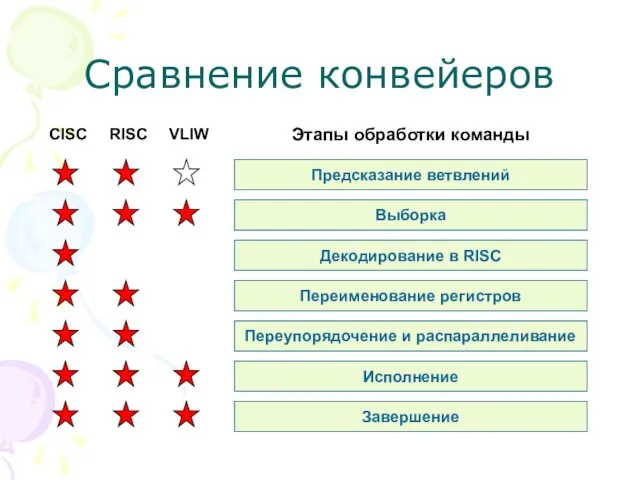
Слайд 11Архитектура VLIW / EPIC
История
M-10 (1972)
Cydrome (1984-1988)
Cydra-5
256 bit VLIW (7 ops.), reg. rotation.,
Архитектура VLIW / EPIC
История
M-10 (1972)
Cydrome (1984-1988)
Cydra-5
256 bit VLIW (7 ops.), reg. rotation.,

Слайд 12Архитектура Itanium
Архитектура Itanium
Слайд 13Семейство процессоров Itanium
2001
2002
2003
2006
Itanium
(Merced)
800 MHz
4 MB L3 cache
180 nm
Itanium2
(McKinley)
1 GHz
3 MB L3 cache
180
Семейство процессоров Itanium
2001
2002
2003
2006
Itanium
(Merced)
800 MHz
4 MB L3 cache
180 nm
Itanium2
(McKinley)
1 GHz
3 MB L3 cache
180

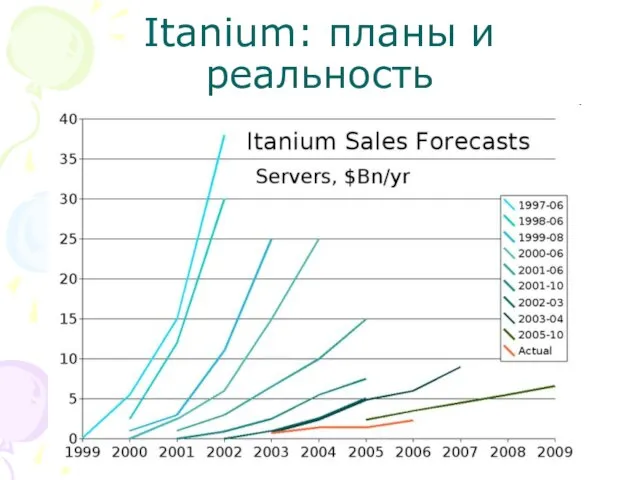
Слайд 14Itanium: планы и реальность
Itanium: планы и реальность
Слайд 15Архитектура Itanium (IA-64)
Явный ILP (параллелизм на уровне команд)
Компилятор объединяет команды процессора в
Архитектура Itanium (IA-64)
Явный ILP (параллелизм на уровне команд)
Компилятор объединяет команды процессора в

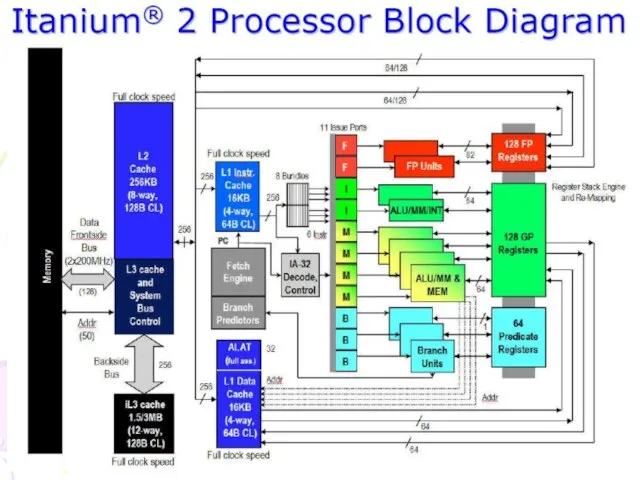
Слайд 16Особенности процессоров архитектуры Itanium (IA-64)
Простой широкий конвейер
Много команд за такт (до 6)
Большие
Особенности процессоров архитектуры Itanium (IA-64)
Простой широкий конвейер
Много команд за такт (до 6)
Большие

Слайд 18Регистры IA-64
Регистры IA-64

Слайд 19Регистры IA-64
128 целочисленных регистра
64 бита + 1 бит NAT
r0 = 0
целочисленные скалярные
Регистры IA-64
128 целочисленных регистра
64 бита + 1 бит NAT
r0 = 0
целочисленные скалярные

Слайд 20Вращение регистров
Верхние 75% регистров вращающиеся:
целочисленные: r32 – r127
вещественные: f32 – f127
предикатные: p16
Вращение регистров
Верхние 75% регистров вращающиеся:
целочисленные: r32 – r127
вещественные: f32 – f127
предикатные: p16

Слайд 21Стек регистров
При вызове подпрограмм и возврате происходит сдвиг регистрового окна – целочисленные
Стек регистров
При вызове подпрограмм и возврате происходит сдвиг регистрового окна – целочисленные

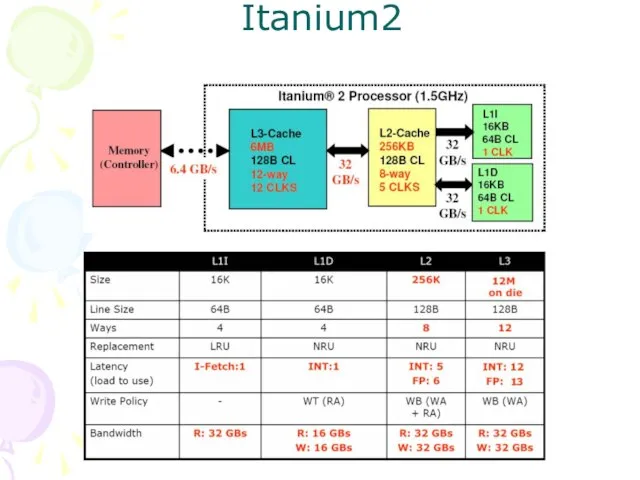
Слайд 22Иерархия кэш-памяти Itanium2
Иерархия кэш-памяти Itanium2
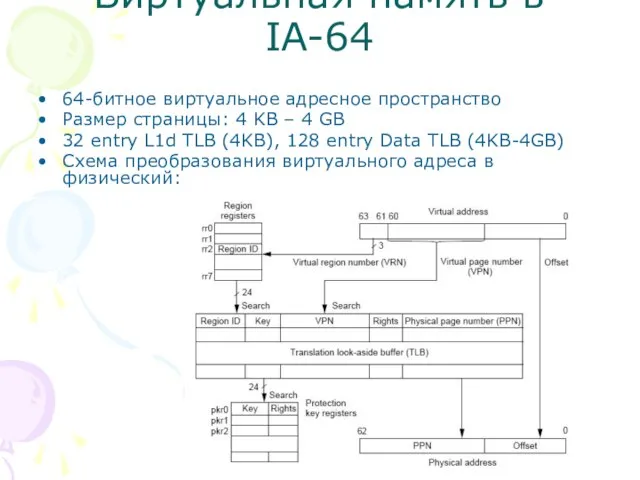
Слайд 23Виртуальная память в IA-64
64-битное виртуальное адресное пространство
Размер страницы: 4 KB – 4
Виртуальная память в IA-64
64-битное виртуальное адресное пространство
Размер страницы: 4 KB – 4
Слайд 24Конвейер Itanium2
Короткий 8-стадийный конвейер
Полностью детерминированный путь команд
Упорядоченная выборка команд, неупорядоченное завершение
Рассчитан на
Конвейер Itanium2
Короткий 8-стадийный конвейер
Полностью детерминированный путь команд
Упорядоченная выборка команд, неупорядоченное завершение
Рассчитан на

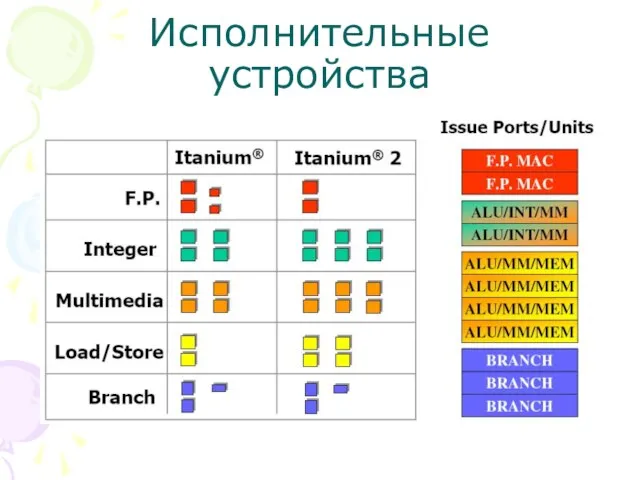
Слайд 25Исполнительные устройства
Число операций за такт
Исполнительные устройства
Число операций за такт
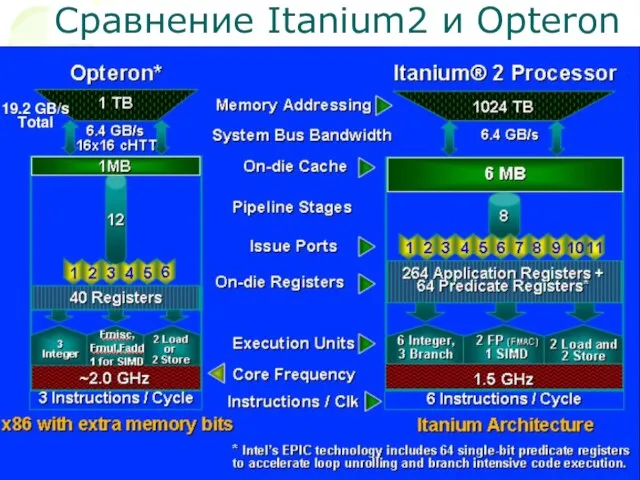
Слайд 26Сравнение Itanium2 и Opteron
Сравнение Itanium2 и Opteron
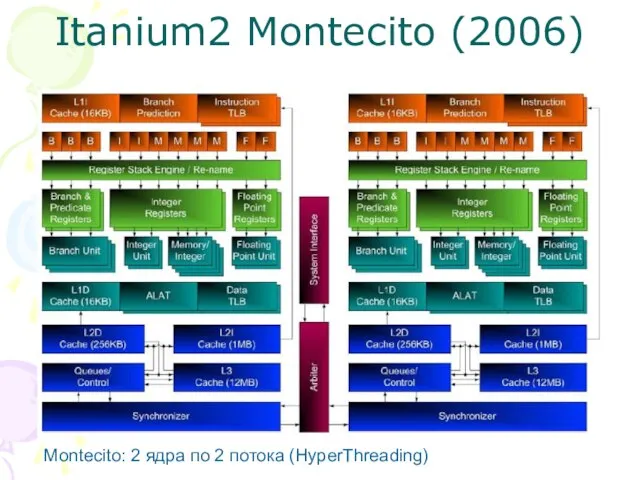
Слайд 27Itanium2 Montecito (2006)
Montecito: 2 ядра по 2 потока (HyperThreading)
Itanium2 Montecito (2006)
Montecito: 2 ядра по 2 потока (HyperThreading)
Слайд 28Команды IA-64
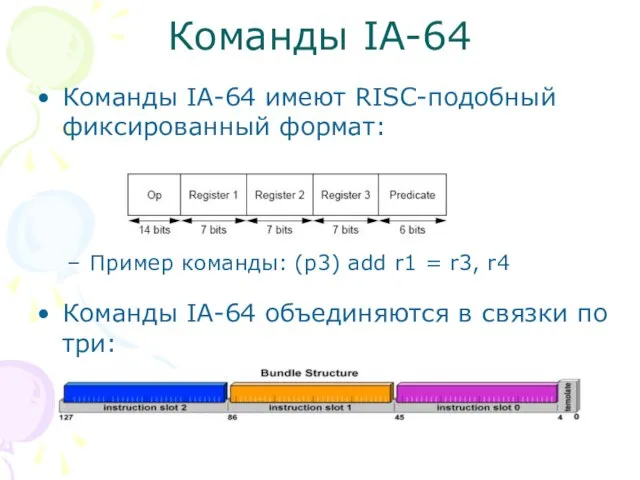
Команды IA-64 имеют RISC-подобный фиксированный формат:
Пример команды: (p3) add r1 = r3,
Команды IA-64
Команды IA-64 имеют RISC-подобный фиксированный формат:
Пример команды: (p3) add r1 = r3,
Слайд 29Команды IA-64
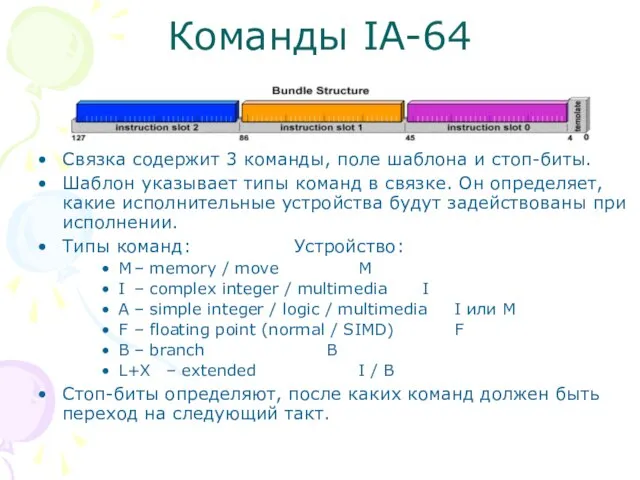
Связка содержит 3 команды, поле шаблона и стоп-биты.
Шаблон указывает типы команд
Команды IA-64
Связка содержит 3 команды, поле шаблона и стоп-биты.
Шаблон указывает типы команд
Слайд 30Команды IA-64
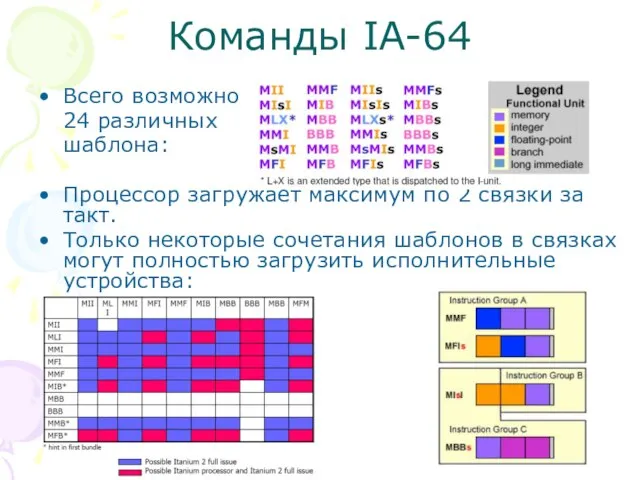
Всего возможно
24 различных
шаблона:
Процессор загружает максимум по 2 связки за такт.
Только некоторые
Команды IA-64
Всего возможно
24 различных
шаблона:
Процессор загружает максимум по 2 связки за такт.
Только некоторые
Слайд 31Команды IA-64
Логические (and, …)
Арифметические (add, …)
Команды сравнения (cmp, …)
Команды сдвига (shl, …)
SIMD
Команды IA-64
Логические (and, …)
Арифметические (add, …)
Команды сравнения (cmp, …)
Команды сдвига (shl, …)
SIMD

Слайд 32Особенности целочисленной арифметики в Itanium2
До 6 операций за такт
Операция fma (y=a*b+c) выполняется
Особенности целочисленной арифметики в Itanium2
До 6 операций за такт
Операция fma (y=a*b+c) выполняется

Слайд 33Особенности вещественной арифметики в Itanium2
Максимальная производительность
2 за такт: двойная точность
4 за такт:
Особенности вещественной арифметики в Itanium2
Максимальная производительность
2 за такт: двойная точность
4 за такт:

Слайд 34Особенности вещественной арифметики в Itanium2
Вещественное деление (32-bit float)
Вычисление корня (32-bit float)
Особенности вещественной арифметики в Itanium2
Вещественное деление (32-bit float)
Вычисление корня (32-bit float)

Слайд 35Предсказание ветвлений в Itanium2
BHT – таблица истории ветвлений
Адрес перехода и информация о
Предсказание ветвлений в Itanium2
BHT – таблица истории ветвлений
Адрес перехода и информация о

Слайд 36Предвыборка инструкций в Itanium2
Автоматическая предвыборка следующей кэш-строки в кэш команд L1, если
Предвыборка инструкций в Itanium2
Автоматическая предвыборка следующей кэш-строки в кэш команд L1, если

Слайд 37Фрагмент кода
на ассемблере для IA-64
Синтаксис инструкций:
Фрагмент кода
на ассемблере для IA-64
Синтаксис инструкций:

Слайд 38Средства повышения производительности в IA-64
Предикатное исполнение команд
Аппаратные счетчики циклов
Спекуляция по данным и
Средства повышения производительности в IA-64
Предикатное исполнение команд
Аппаратные счетчики циклов
Спекуляция по данным и

Слайд 39Предикатное исполнение команд
Позволяет зависимости по управлению (т.е. условные переходы) преобразовать в зависимости
Предикатное исполнение команд
Позволяет зависимости по управлению (т.е. условные переходы) преобразовать в зависимости

Слайд 40Аппаратные счетчики циклов
Архитектурная поддержка циклов
По специальной команде перехода счетчики автоматически уменьшаются и
Аппаратные счетчики циклов
Архитектурная поддержка циклов
По специальной команде перехода счетчики автоматически уменьшаются и

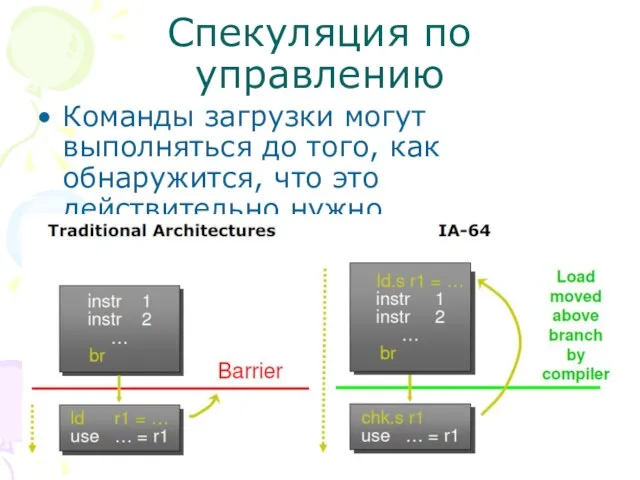
Слайд 41Спекуляция по управлению
Команды загрузки могут выполняться до того, как обнаружится, что это
Спекуляция по управлению
Команды загрузки могут выполняться до того, как обнаружится, что это
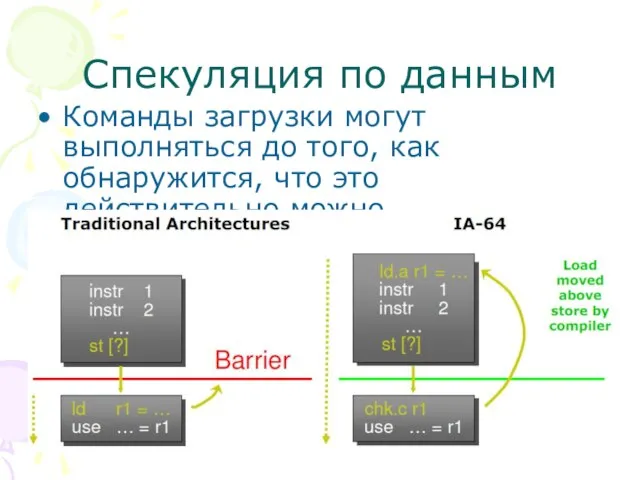
Слайд 42Спекуляция по данным
Команды загрузки могут выполняться до того, как обнаружится, что это
Спекуляция по данным
Команды загрузки могут выполняться до того, как обнаружится, что это
Слайд 43Программная конвейеризация цикла
Архитектурная поддержка параллельного исполнения команд цикла.
Выполняется с помощью:
Предикатных регистров
Аппаратных счетчиков
Программная конвейеризация цикла
Архитектурная поддержка параллельного исполнения команд цикла.
Выполняется с помощью:
Предикатных регистров
Аппаратных счетчиков








Слайд 51Процессоры Itanium 9300 (Tukwila)
Особенности нового Itanium-а
Частота: до 1.73 GHz
Режим Turbo boost: до
Процессоры Itanium 9300 (Tukwila)
Особенности нового Itanium-а
Частота: до 1.73 GHz
Режим Turbo boost: до

Слайд 52Процессоры Transmeta
Процессоры Transmeta

Слайд 53Процессоры Transmeta
Особенности архитектуры
Архитектура VLIW
Динамическая трансляция кода: x86 ? VLIW
Интегрированный северный мост
Ориентация на
Процессоры Transmeta
Особенности архитектуры
Архитектура VLIW
Динамическая трансляция кода: x86 ? VLIW
Интегрированный северный мост
Ориентация на

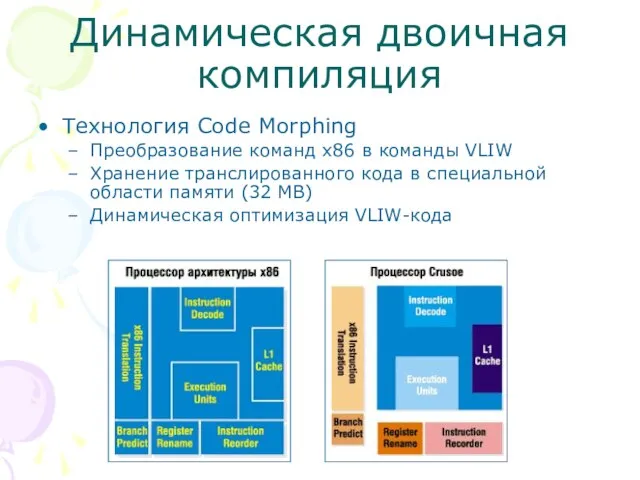
Слайд 54Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода
Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода
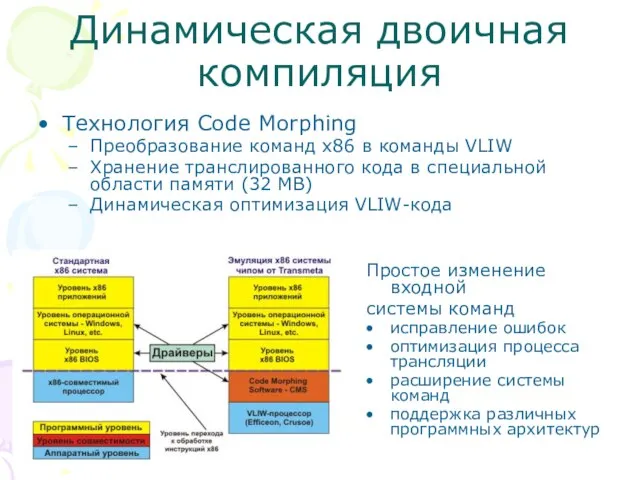
Слайд 55Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода
Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода
Слайд 56Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода
Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода

Слайд 57Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода
Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода

Слайд 58Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода
Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода

Слайд 59Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода
Динамическая двоичная компиляция
Технология Code Morphing
Преобразование команд x86 в команды VLIW
Хранение транслированного кода

Слайд 60Процессор Transmeta Efficion
Особенности
Ширина командного слова 256 бит (8 команд)
Кэш L1: 64 data
Процессор Transmeta Efficion
Особенности
Ширина командного слова 256 бит (8 команд)
Кэш L1: 64 data

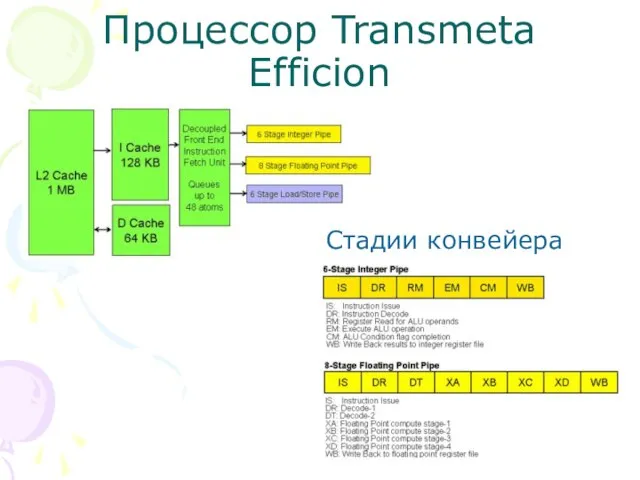
Слайд 61Процессор Transmeta Efficion
Стадии конвейера
Процессор Transmeta Efficion
Стадии конвейера
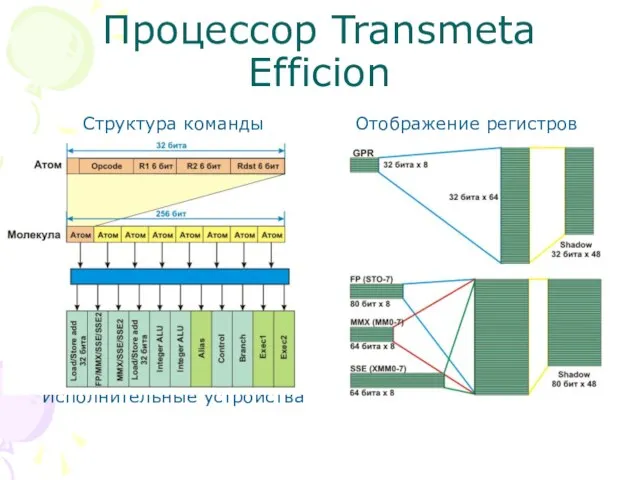
Слайд 62Процессор Transmeta Efficion
Структура команды
Исполнительные устройства
Отображение регистров
Процессор Transmeta Efficion
Структура команды
Исполнительные устройства
Отображение регистров
Слайд 63Архитектура
Эльбрус 2000
Бабаян
Борис Арташесович
чл.корр. РАН
Intel Fellow
Архитектура
Эльбрус 2000
Бабаян
Борис Арташесович
чл.корр. РАН
Intel Fellow

Слайд 64Эльбрус 2000
ELBRUS – ExpLicit Basic Resources Utilization Scheduling
(явное планирование использования основных ресурсов)
Особенности
Эльбрус 2000
ELBRUS – ExpLicit Basic Resources Utilization Scheduling
(явное планирование использования основных ресурсов)
Особенности

Слайд 65Процессор Эльбрус
Характеристики
Командное слово переменной длины (2 – 16 слогов)
До 23 операций за
Процессор Эльбрус
Характеристики
Командное слово переменной длины (2 – 16 слогов)
До 23 операций за

Слайд 66Процессор Эльбрус
Формат команды:
Число слогов: 2 – 16
Типы слогов (максимальное число в команде)
Заголовок
Процессор Эльбрус
Формат команды:
Число слогов: 2 – 16
Типы слогов (максимальное число в команде)
Заголовок

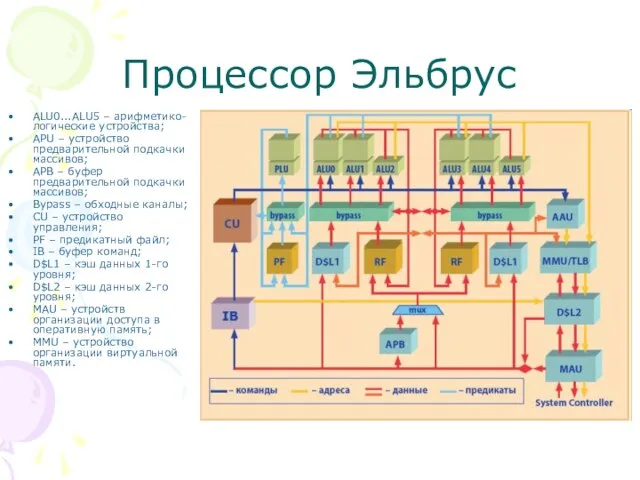
Слайд 67Процессор Эльбрус
ALU0...ALU5 – арифметико-логические устройства;
APU – устройство предварительной подкачки массивов;
APB
Процессор Эльбрус
ALU0...ALU5 – арифметико-логические устройства;
APU – устройство предварительной подкачки массивов;
APB
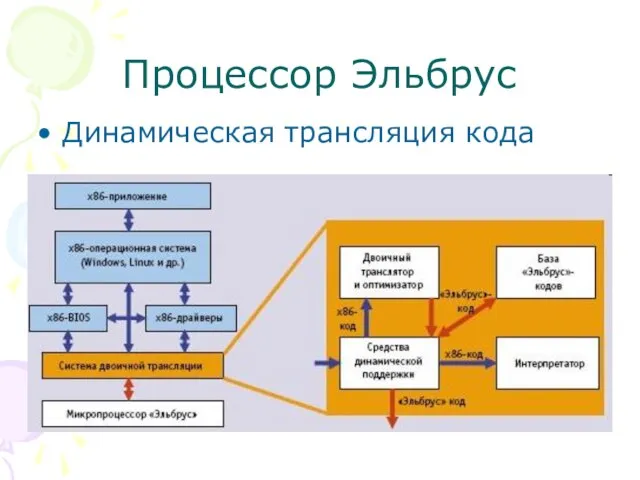
Слайд 68Процессор Эльбрус
Динамическая трансляция кода
Процессор Эльбрус
Динамическая трансляция кода
 м. Буськ, вул.Надсяння
м. Буськ, вул.Надсяння Seoul
Seoul Правила постановки и реализации цели
Правила постановки и реализации цели Идея образовательного кластера
Идея образовательного кластера Арисова
Арисова КОМПАНИЯ EURORESEARCH AND CONSULTING ЕВРОРЕСЕЧ И КОНСАЛТИНГ
КОМПАНИЯ EURORESEARCH AND CONSULTING ЕВРОРЕСЕЧ И КОНСАЛТИНГ ООО СПК «ЮНИТИ РЕ»
ООО СПК «ЮНИТИ РЕ» Красота природы в эпоксидной смоле
Красота природы в эпоксидной смоле Техническое регулирование: вчера, сегодня, завтра
Техническое регулирование: вчера, сегодня, завтра http://www.comp-mgpu.ru
http://www.comp-mgpu.ru Маркетинговые исследования города
Маркетинговые исследования города Управление запасами в логистике. Выбор варианта поставок
Управление запасами в логистике. Выбор варианта поставок Влияние факторов внешней среды на микроорганизмы
Влияние факторов внешней среды на микроорганизмы 5 класс. Кубановедение
5 класс. Кубановедение 20140414_chernobylskaya_katastrofa
20140414_chernobylskaya_katastrofa Индия и Китай в древности (10 класс)
Индия и Китай в древности (10 класс) Решение линейных уравнений с параметром
Решение линейных уравнений с параметром Бажов Каменный цветок
Бажов Каменный цветок Интеллектуальная игра Знатоки спорта
Интеллектуальная игра Знатоки спорта Город City
Город City Проект концепции информатизации здравоохранения Астраханской области
Проект концепции информатизации здравоохранения Астраханской области Жёлтый блокнот
Жёлтый блокнот Московский Кремль Интерактивная интеллектуальная игра
Московский Кремль Интерактивная интеллектуальная игра Social and personality development and types of play pre-school years
Social and personality development and types of play pre-school years  Конкурсный отбор площадок на статус ФИП в 2012 году Сайт http://fip.kpmo.ru А.К.Белолуцкая, заместитель директора АНО «Институт проблем обр
Конкурсный отбор площадок на статус ФИП в 2012 году Сайт http://fip.kpmo.ru А.К.Белолуцкая, заместитель директора АНО «Институт проблем обр Факторы, влиящие на поведение потребителя
Факторы, влиящие на поведение потребителя ПРОГРАММНО-ТЕХНИЧЕСКИЙ КОМПЛЕКСавтоматизированной системы управлениярежимами, энергетической эффективностью, эксплуатационн
ПРОГРАММНО-ТЕХНИЧЕСКИЙ КОМПЛЕКСавтоматизированной системы управлениярежимами, энергетической эффективностью, эксплуатационн Непредельные углеводороды. Алкены
Непредельные углеводороды. Алкены