- Архитектуры с параллелизмом на уровне команд

Содержание
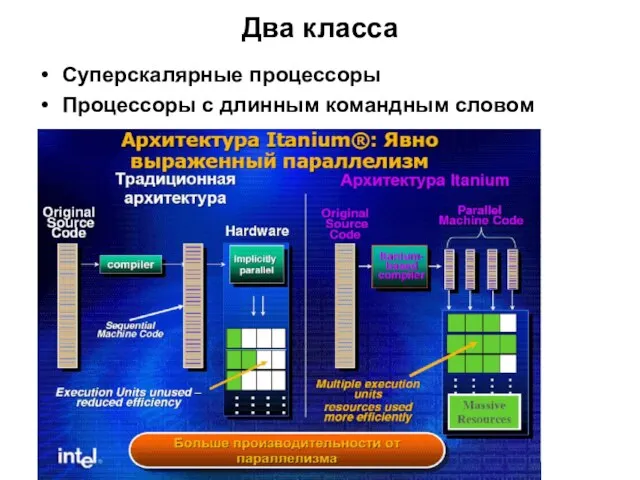
- 2. Два класса Суперскалярные процессоры Процессоры с длинным командным словом
- 4. Динамическое исполнение команд в суперскалярном процессоре Предсказание ветвлений (переходов) (branch prediction). Переименование регистров, чтобы удалить зависимости
- 5. Как реализован конвейер? Устройство предварительной обработки инструкций в порядке их следования в программном коде (front end).
- 6. Устройство front end Предсказание следующей инструкции. Используются два алгоритма предсказания переходов. Динамический алгоритм работает на стадии
- 7. Пример переименования регистров (1) a = x + f; a = x + f; (2) b
- 8. Каждый МОП может проходить через следующие стадии: 1. находится в очереди планировщика, но ещё не готов
- 9. Устройство Out-Of-Order execution Планирование и распределение микроопераций Выполнение микроопераций и запоминание их результатов временно в буфере
- 10. Блок упорядоченного завершения Запись результатов обратно во внешние архитектурные регистры, постоянная запись данных, если это необходимо.
- 11. Упрощенная схема процессора
- 12. Pentium III
- 13. Alpha 21264
- 14. Athlon
- 15. Opteron
- 16. Гипертранспорт
- 20. Скачать презентацию

Слайд 4Динамическое исполнение команд в суперскалярном процессоре
Предсказание ветвлений (переходов) (branch prediction).
Переименование регистров, чтобы
Динамическое исполнение команд в суперскалярном процессоре
Предсказание ветвлений (переходов) (branch prediction).
Переименование регистров, чтобы

Слайд 5Как реализован конвейер?
Устройство предварительной обработки инструкций в порядке их следования в программном
Как реализован конвейер?
Устройство предварительной обработки инструкций в порядке их следования в программном

Слайд 6Устройство front end
Предсказание следующей инструкции. Используются два алгоритма предсказания переходов. Динамический
Устройство front end
Предсказание следующей инструкции. Используются два алгоритма предсказания переходов. Динамический

Слайд 7Пример переименования регистров
(1) a = x + f; a = x + f;
(2) b =
Пример переименования регистров
(1) a = x + f; a = x + f;
(2) b =

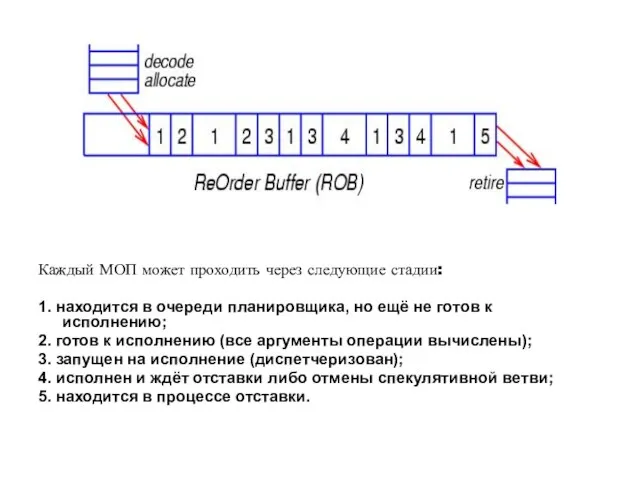
Слайд 8Каждый МОП может проходить через следующие стадии:
1. находится в очереди планировщика, но
Каждый МОП может проходить через следующие стадии:
1. находится в очереди планировщика, но
Слайд 9Устройство Out-Of-Order execution
Планирование и распределение микроопераций
Выполнение микроопераций и запоминание их результатов
Устройство Out-Of-Order execution
Планирование и распределение микроопераций
Выполнение микроопераций и запоминание их результатов

Слайд 10Блок упорядоченного завершения
Запись результатов обратно во внешние архитектурные регистры, постоянная запись
Блок упорядоченного завершения
Запись результатов обратно во внешние архитектурные регистры, постоянная запись

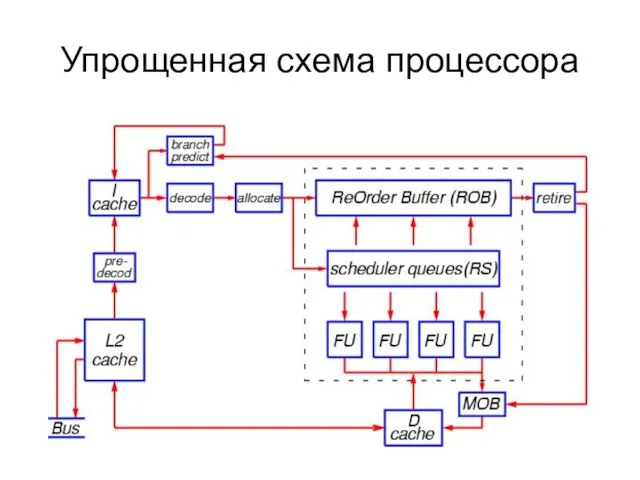
Слайд 11Упрощенная схема процессора
Упрощенная схема процессора
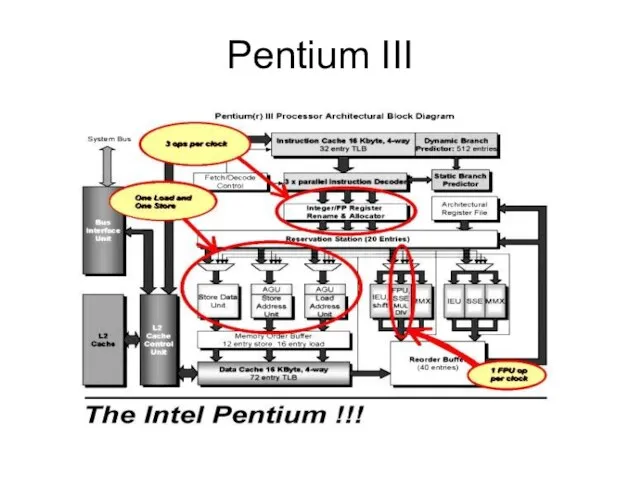
Слайд 12Pentium III
Pentium III
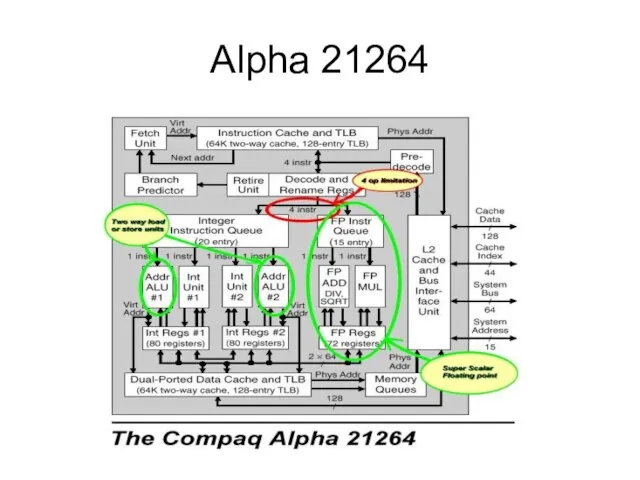
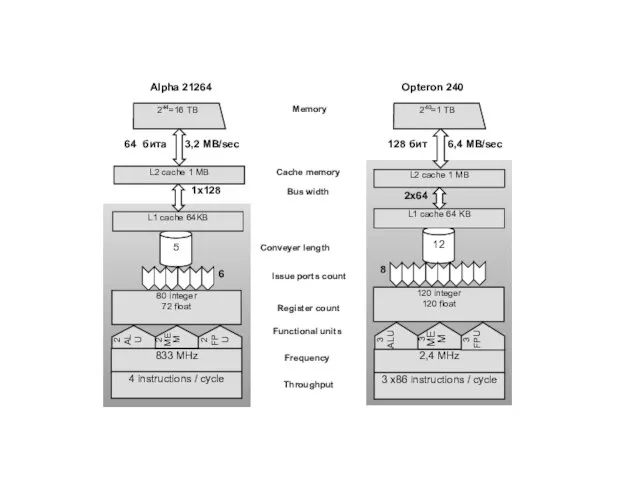
Слайд 13Alpha 21264
Alpha 21264
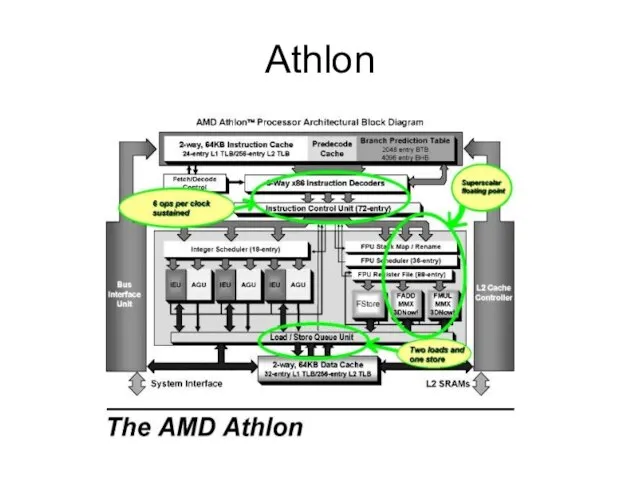
Слайд 14Athlon
Athlon
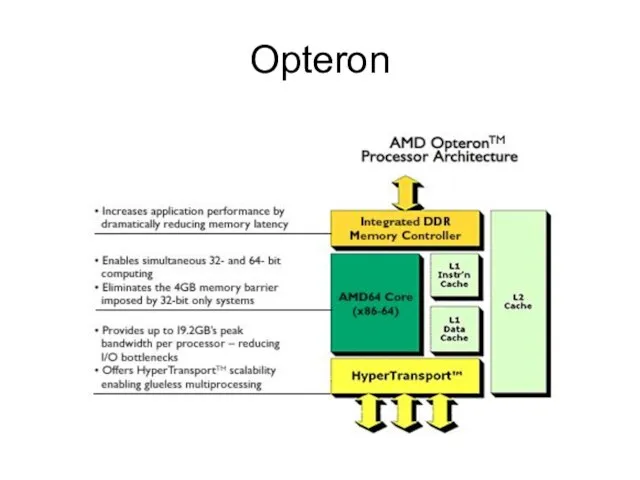
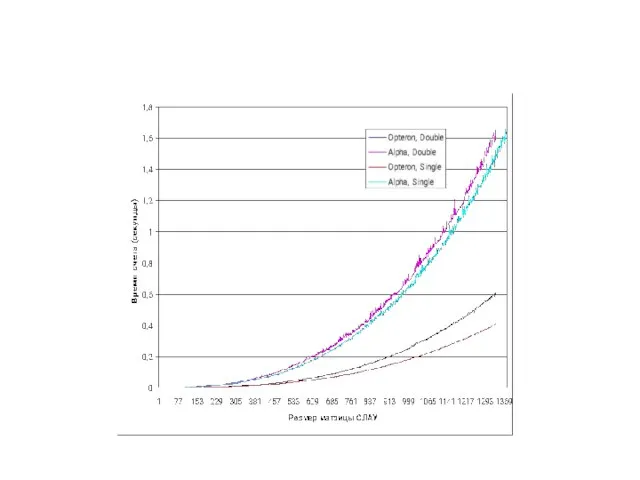
Слайд 15Opteron
Opteron
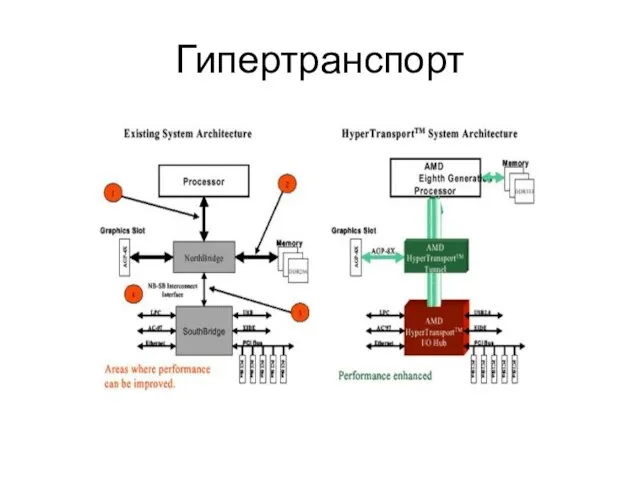
Слайд 16Гипертранспорт
Гипертранспорт
 Информационные технологии в электротехнике
Информационные технологии в электротехнике ПАКЕТ
ПАКЕТ Электрическая схема
Электрическая схема Пропорции и особенности изображения животных
Пропорции и особенности изображения животных Методическая служба МБОУ Большесундырская СОШ им.В.А.Верендеева Моргаушского района Чувашской Республики
Методическая служба МБОУ Большесундырская СОШ им.В.А.Верендеева Моргаушского района Чувашской Республики Why We All Need to Get A Girlfriend
Why We All Need to Get A Girlfriend Расписание занятий по пинг - понгу
Расписание занятий по пинг - понгу тема 1.2 Суповое отд
тема 1.2 Суповое отд Путешествие по осеннему лесу
Путешествие по осеннему лесу Управление качеством
Управление качеством tls2
tls2 План реализации мероприятий Технологической платформы «Медицина будущего» по направлению «Многокомпонентные биокомпозиционн
План реализации мероприятий Технологической платформы «Медицина будущего» по направлению «Многокомпонентные биокомпозиционн Ланцетники
Ланцетники Атеизм как религия
Атеизм как религия Автопортрет Т.Г. Шевченко
Автопортрет Т.Г. Шевченко Социальные пособия. 6 классы
Социальные пособия. 6 классы Бриф 05.02.2019 для раздела Правильное питание
Бриф 05.02.2019 для раздела Правильное питание Исковое производство
Исковое производство Тоталитарные интернет-сообщества: как избежать, победить и выжить в мире ловцов виртуальных душ
Тоталитарные интернет-сообщества: как избежать, победить и выжить в мире ловцов виртуальных душ Донской А.Г. 26.01._Об особенностях реализации НПП
Донской А.Г. 26.01._Об особенностях реализации НПП Презентация на тему Становление новой России
Презентация на тему Становление новой России Влияние рок- музыки на здоровье подростка
Влияние рок- музыки на здоровье подростка Valuation exercise,или почем сегодня Yandex
Valuation exercise,или почем сегодня Yandex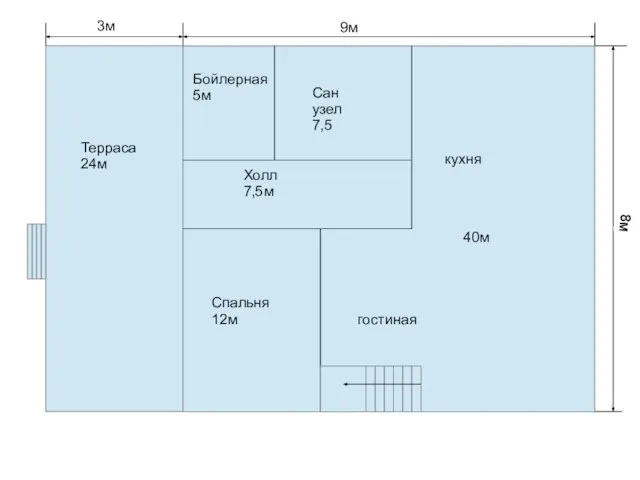 Дом. Планировка
Дом. Планировка Классификация видов термической обработки стали. Отжиг. (Лекция 6)
Классификация видов термической обработки стали. Отжиг. (Лекция 6) Rytsarskaya_kultura_v_Evrope (1)
Rytsarskaya_kultura_v_Evrope (1) Права инвалидов
Права инвалидов Влияние вредных привычек на сердечно-сосудистую и дыхательную системы
Влияние вредных привычек на сердечно-сосудистую и дыхательную системы