- Кластеризация. Структура экзаменационных билетов

Содержание
- 2. Структура экзаменационного билета В билете 2 задания: 1 задание – предварительный анализ данных (исследование данных, визуальный
- 3. Примеры задания 1 На основе индивидуальных данных о клиентах банка (файл “….csv”) проведите оценку основных статистических
- 4. Примеры задания 1 3. С использованием SAS Studio проведите кластеризацию объектов недвижимости из набора данных «...csv»
- 5. Примеры задания 2 1. Постройте и исследуйте три регрессионные зависимости срока кредитования от возраста и длительности
- 6. Кластерный анализ в SAS/STAT
- 7. Кластерный анализ в SAS/STAT
- 8. Результаты
- 9. Дендрограмма
- 10. Number of Clusters - количество кластеров Clusters Joined - имена объединенных кластеров. (Наблюдения идентифицируются либо по
- 12. Скачать презентацию
Слайд 2Структура экзаменационного билета
В билете 2 задания:
1 задание – предварительный анализ данных (исследование
Структура экзаменационного билета
В билете 2 задания:
1 задание – предварительный анализ данных (исследование

Слайд 3Примеры задания 1
На основе индивидуальных данных о клиентах банка (файл “….csv”) проведите
Примеры задания 1
На основе индивидуальных данных о клиентах банка (файл “….csv”) проведите

Слайд 4Примеры задания 1
3. С использованием SAS Studio проведите кластеризацию объектов недвижимости из
Примеры задания 1
3. С использованием SAS Studio проведите кластеризацию объектов недвижимости из

Слайд 5Примеры задания 2
1. Постройте и исследуйте три регрессионные зависимости срока кредитования от
Примеры задания 2
1. Постройте и исследуйте три регрессионные зависимости срока кредитования от

Слайд 6Кластерный анализ в SAS/STAT
Кластерный анализ в SAS/STAT
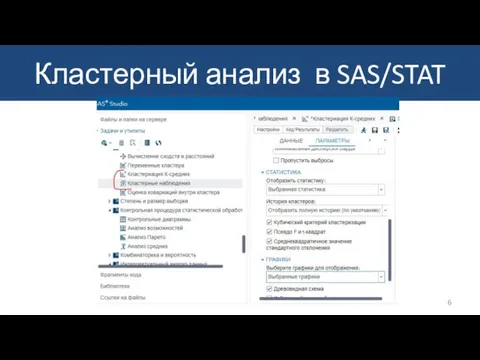
Слайд 7Кластерный анализ в SAS/STAT
Кластерный анализ в SAS/STAT
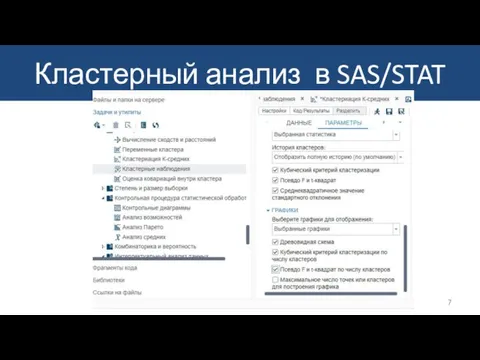
Слайд 8Результаты
Результаты
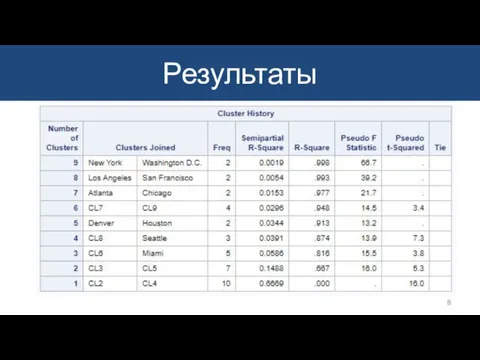
Слайд 9Дендрограмма
Дендрограмма

Слайд 10Number of Clusters - количество кластеров
Clusters Joined - имена объединенных кластеров. (Наблюдения
Number of Clusters - количество кластеров
Clusters Joined - имена объединенных кластеров. (Наблюдения

 Мусороперерабатывающее предприятие
Мусороперерабатывающее предприятие Виды официальных писем
Виды официальных писем Отважные путешественники (4 класс)
Отважные путешественники (4 класс) Презентация на тему Оттава - столица Северной Америки
Презентация на тему Оттава - столица Северной Америки  презентация сайт
презентация сайт Трудовое право
Трудовое право Презентация на тему Гондурас
Презентация на тему Гондурас  Формирование социокультурной компетенции у учащихся на уроках английского языка
Формирование социокультурной компетенции у учащихся на уроках английского языка Рис. 2 Концепция развертывания стратегических планов развития университета. Объединяющей и направляющей должна быть система мене
Рис. 2 Концепция развертывания стратегических планов развития университета. Объединяющей и направляющей должна быть система мене Колледж сферы услуг № 32
Колледж сферы услуг № 32 Азия, Африка, Латинская Америка во 2-ой пол. XX века. Поиск путей развития
Азия, Африка, Латинская Америка во 2-ой пол. XX века. Поиск путей развития 7 wonders of Belarus
7 wonders of Belarus Теория доказательства и аргументации
Теория доказательства и аргументации Торги: правила
Торги: правила Frames
Frames  Система управления бизнес-процессами
Система управления бизнес-процессами Санаторий Марциальные воды в Карелии. Лечение, отдых, встречи
Санаторий Марциальные воды в Карелии. Лечение, отдых, встречи Клинический разбор
Клинический разбор Планеты-гиганты и маленький Плутон (5 класс)
Планеты-гиганты и маленький Плутон (5 класс) Процесс формообразования: Прокатка
Процесс формообразования: Прокатка КОНКУРС ЛУЧШИХ УЧИТЕЛЕЙ ОБРАЗОВАТЕЛЬНЫХ УЧРЕЖДЕНИЙДЛЯ ДЕНЕЖНОГО ПООЩРЕНИЯ ЗА ВЫСОКОЕ ПЕДАГОГИЧЕСКОЕ МАСТЕРСТВОИ ЗНАЧИТЕЛЬНЫЙ
КОНКУРС ЛУЧШИХ УЧИТЕЛЕЙ ОБРАЗОВАТЕЛЬНЫХ УЧРЕЖДЕНИЙДЛЯ ДЕНЕЖНОГО ПООЩРЕНИЯ ЗА ВЫСОКОЕ ПЕДАГОГИЧЕСКОЕ МАСТЕРСТВОИ ЗНАЧИТЕЛЬНЫЙ  Физиология, биохимия микроорганизмов (прокариотов: бактерий, эукариотов: простейших, грибов, вирусов)
Физиология, биохимия микроорганизмов (прокариотов: бактерий, эукариотов: простейших, грибов, вирусов) Понятие личности в социальной психологии
Понятие личности в социальной психологии требования к фгос пекарь 1-2урок
требования к фгос пекарь 1-2урок Фотоотчет распространения промотиража газеты Маяк
Фотоотчет распространения промотиража газеты Маяк Букингемский дворец
Букингемский дворец Складання та оформлення номенклатури справ у діловодстві
Складання та оформлення номенклатури справ у діловодстві kinoshot
kinoshot