- MAP REDUCE

Содержание
- 2. Параллельное и распределённое программирование Под параллельным программированием понимают: Векторную обработку данных Использование нескольких CPU на компьютере
- 3. Мотивация распределённых вычислений Хотим обрабатывать большие объёмы данных ( > 1 TB) Хотим использовать мощности сотен/тысяч
- 4. Возникающие проблемы Отказы компьютеров Отказы сети Медленная коммуникация между компьютерами Пропускная способность канала ограничена Отсутствует глобальное
- 5. Идеи и решение Идеи Перенести вычисления ближе к данным Максимально снизить сетевые коммуникации Средство контроля распределенных
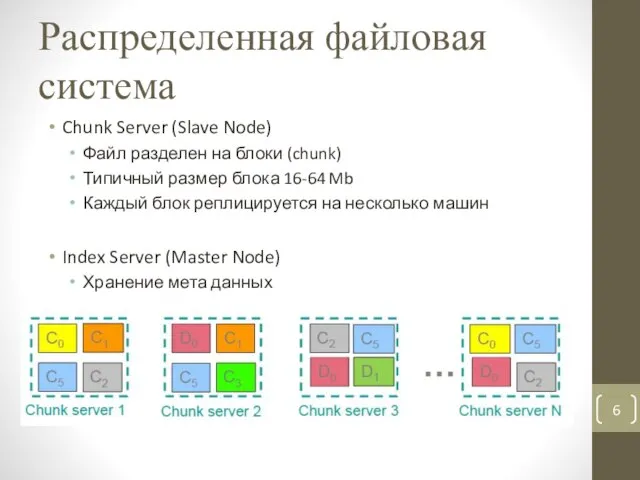
- 6. Распределенная файловая система Chunk Server (Slave Node) Файл разделен на блоки (chunk) Типичный размер блока 16-64
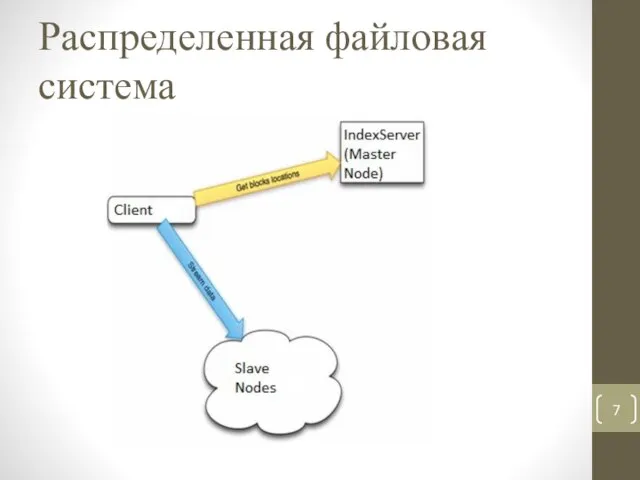
- 7. Распределенная файловая система
- 8. Map Reduce Автоматическое распараллеливание и распределение по нодам Устойчивость к сбоям Автоматичексое управление внутренней коммуникацией между
- 9. Идеология Map Reduce Идеология Map Reduce базируется на 2-х основных парадигмах: Парадигме функционального программирования Парадигме Master/Workers
- 10. Функциональное программирование Функции не изменяют данные – они всегда создают новые Оригинальные данные всегда существуют в
- 11. Пример fun foo(l: int list) = sum(l) + mul(l) + length(l) Порядок функций sum(), mul() и
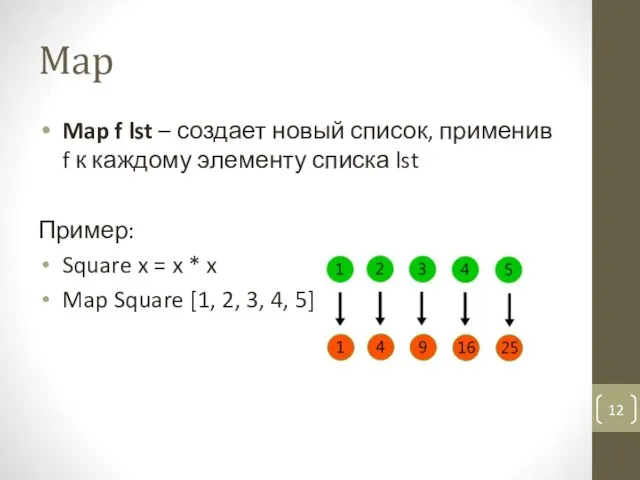
- 12. Map Map f lst – создает новый список, применив f к каждому элементу списка lst Пример:
- 13. Reduce Foldl f x0 lst – свертка структуры данных к единственному значению x0 – аккумулирующее значение
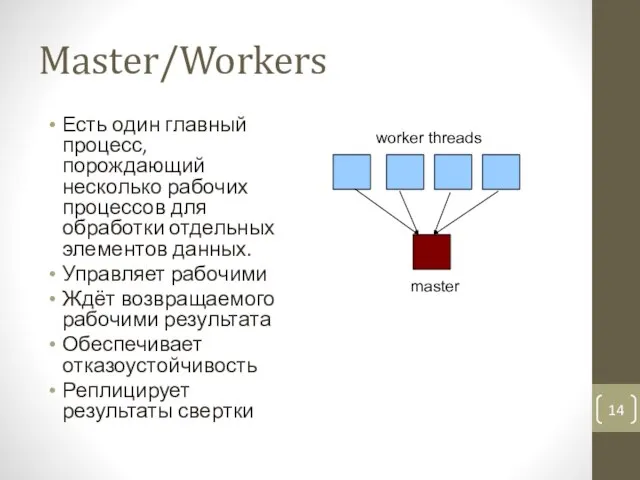
- 14. Master/Workers Есть один главный процесс, порождающий несколько рабочих процессов для обработки отдельных элементов данных. Управляет рабочими
- 15. Поток данных в MapReduce моделе Считывается большой набор данных Map: извлекаем необходимую информацию Shuffle and sort:
- 16. Модель программирования Заимствована из функционального программирования Пользователь реализует две функции: map (in_key, in_value) -> (out_key, intermediate_value)
- 17. Функция map На вход функции поступают данные в виде пар ключ-значение. Например данные из текстового файла
- 18. Функция reduce После завершения стадии map’a все промежуточные значения для каждого выходного ключа добавляются в список
- 19. MapReduce: workers
- 20. Параллелизм Функции map() выполняются параллельно, создавая различные промежуточные данные для различных входных групп данных Функции reduce()
- 21. Локальность Главная программа разбивает задачи основываясь на расположении данных: старается запускать map функцию на той же
- 22. Устойчивость к сбоям Главная программа обнаруживает отказы рабочих нодов и перезапускает задачи. Также происходит повторный запуск
- 23. Оптимизация Фаза reduce не может начаться пока не закончена фаза map. Один медленный диск может замедлить
- 24. Оптимизация Расширение набора пользовательских функций: Partition(ключ, кол-во reduce узлов) => reduce узел для данного ключа Часто
- 25. MapReduce: workers (opt.)
- 26. Пример: подсчет статистики по словам Map(string input_key, input_value): // input_key: document name // input_value: document contents
- 27. Пример: YAHOO web graph Для каждой странички формируетя список веб документов, ссылающихся на эту страничку На
- 28. Пример: Last.fm top list На проигрыватель установлен плагин Last.fm Пользователь слушает песню => пишется лог вида
- 29. Реализации Google Недоступна вне Google GFS Hadoop Открытая имплементация на Java HDFS Aster Data Cluster-optimized SQL
- 30. Решаемые задачи Индексация интернета Задачи исследования данных Data Mining данных Задачи построения отчетов Рендеринг набора кадров
- 31. Будущее Microsoft Dryad – развитие идей map reduce. Программист определяет ацикличный направленный граф с С++ кодом
- 32. Язык диаграмм Dryad G^n = параллельный запуск n копий G A >= B = подключить входы
- 34. Скачать презентацию
Слайд 2
Параллельное и распределённое программирование
Под параллельным программированием понимают:
Векторную обработку данных
Использование нескольких CPU на
Параллельное и распределённое программирование
Под параллельным программированием понимают:
Векторную обработку данных
Использование нескольких CPU на

Слайд 3Мотивация распределённых вычислений
Хотим обрабатывать большие объёмы данных ( > 1 TB)
Хотим использовать
Мотивация распределённых вычислений
Хотим обрабатывать большие объёмы данных ( > 1 TB)
Хотим использовать

Слайд 4Возникающие проблемы
Отказы компьютеров
Отказы сети
Медленная коммуникация между компьютерами
Пропускная способность канала ограничена
Отсутствует глобальное
Возникающие проблемы
Отказы компьютеров
Отказы сети
Медленная коммуникация между компьютерами
Пропускная способность канала ограничена
Отсутствует глобальное

Слайд 5Идеи и решение
Идеи
Перенести вычисления ближе к данным
Максимально снизить сетевые коммуникации
Средство контроля распределенных
Идеи и решение
Идеи
Перенести вычисления ближе к данным
Максимально снизить сетевые коммуникации
Средство контроля распределенных

Слайд 6Распределенная файловая система
Chunk Server (Slave Node)
Файл разделен на блоки (chunk)
Типичный размер блока
Распределенная файловая система
Chunk Server (Slave Node)
Файл разделен на блоки (chunk)
Типичный размер блока
Слайд 7Распределенная файловая система
Распределенная файловая система
Слайд 8Map Reduce
Автоматическое распараллеливание и распределение по нодам
Устойчивость к сбоям
Автоматичексое управление внутренней коммуникацией
Map Reduce
Автоматическое распараллеливание и распределение по нодам
Устойчивость к сбоям
Автоматичексое управление внутренней коммуникацией

Слайд 9Идеология Map Reduce
Идеология Map Reduce базируется на 2-х основных парадигмах:
Парадигме функционального программирования
Парадигме
Идеология Map Reduce
Идеология Map Reduce базируется на 2-х основных парадигмах:
Парадигме функционального программирования
Парадигме

Слайд 10Функциональное программирование
Функции не изменяют данные – они всегда создают новые
Оригинальные данные всегда
Функциональное программирование
Функции не изменяют данные – они всегда создают новые
Оригинальные данные всегда

Слайд 11Пример
fun foo(l: int list) =
sum(l) + mul(l) + length(l)
Порядок функций
Пример
fun foo(l: int list) =
sum(l) + mul(l) + length(l)
Порядок функций

Слайд 12Map
Map f lst – создает новый список, применив f к каждому элементу
Map
Map f lst – создает новый список, применив f к каждому элементу
Слайд 13Reduce
Foldl f x0 lst – свертка структуры данных к единственному значению
x0 –
Reduce
Foldl f x0 lst – свертка структуры данных к единственному значению
x0 –

Слайд 14Master/Workers
Есть один главный процесс, порождающий несколько рабочих процессов для обработки отдельных элементов
Master/Workers
Есть один главный процесс, порождающий несколько рабочих процессов для обработки отдельных элементов
Слайд 15Поток данных в MapReduce моделе
Считывается большой набор данных
Map: извлекаем необходимую информацию
Shuffle and
Поток данных в MapReduce моделе
Считывается большой набор данных
Map: извлекаем необходимую информацию
Shuffle and

Слайд 16Модель программирования
Заимствована из функционального программирования
Пользователь реализует две функции:
map (in_key, in_value) ->
(out_key,
Модель программирования
Заимствована из функционального программирования
Пользователь реализует две функции:
map (in_key, in_value) ->
(out_key,

Слайд 17Функция map
На вход функции поступают данные в виде пар ключ-значение. Например данные
Функция map
На вход функции поступают данные в виде пар ключ-значение. Например данные

Слайд 18Функция reduce
После завершения стадии map’a все промежуточные значения для каждого выходного ключа
Функция reduce
После завершения стадии map’a все промежуточные значения для каждого выходного ключа

Слайд 19MapReduce: workers
MapReduce: workers
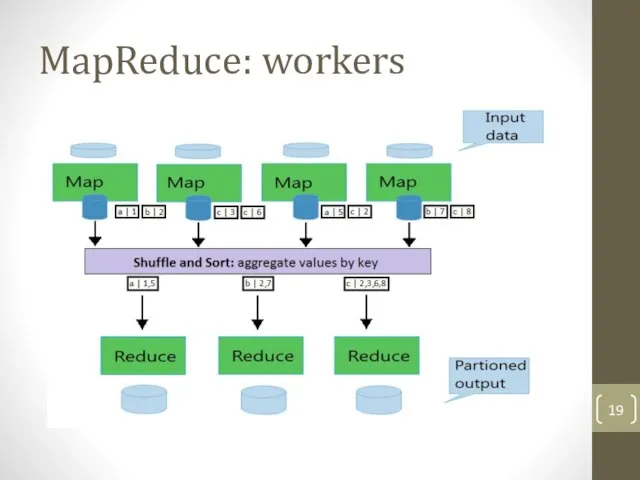
Слайд 20Параллелизм
Функции map() выполняются параллельно, создавая различные промежуточные данные для различных входных групп
Параллелизм
Функции map() выполняются параллельно, создавая различные промежуточные данные для различных входных групп

Слайд 21Локальность
Главная программа разбивает задачи основываясь на расположении данных: старается запускать map функцию
Локальность
Главная программа разбивает задачи основываясь на расположении данных: старается запускать map функцию

Слайд 22Устойчивость к сбоям
Главная программа обнаруживает отказы рабочих нодов и перезапускает задачи. Также
Устойчивость к сбоям
Главная программа обнаруживает отказы рабочих нодов и перезапускает задачи. Также

Слайд 23Оптимизация
Фаза reduce не может начаться пока не закончена фаза map. Один медленный
Оптимизация
Фаза reduce не может начаться пока не закончена фаза map. Один медленный

Слайд 24Оптимизация
Расширение набора пользовательских функций:
Partition(ключ, кол-во reduce узлов) => reduce узел для данного
Оптимизация
Расширение набора пользовательских функций:
Partition(ключ, кол-во reduce узлов) => reduce узел для данного

Слайд 25MapReduce: workers (opt.)
MapReduce: workers (opt.)
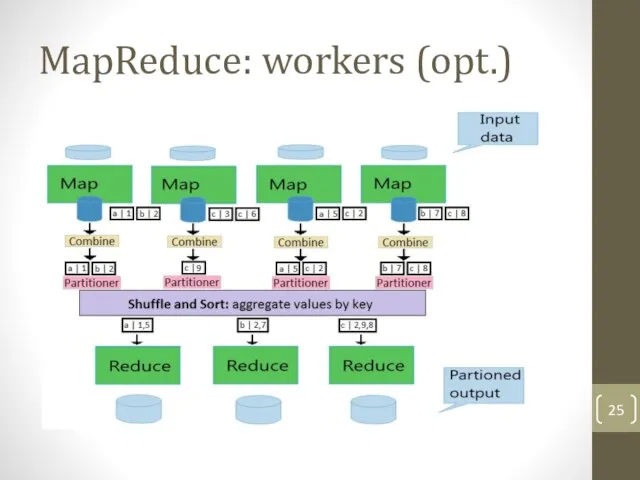
Слайд 26Пример: подсчет статистики
по словам
Map(string input_key, input_value):
// input_key: document name
// input_value: document
Пример: подсчет статистики
по словам
Map(string input_key, input_value):
// input_key: document name
// input_value: document

Слайд 27Пример: YAHOO web graph
Для каждой странички формируетя список веб документов, ссылающихся на
Пример: YAHOO web graph
Для каждой странички формируетя список веб документов, ссылающихся на

Слайд 28Пример: Last.fm top list
На проигрыватель установлен плагин Last.fm
Пользователь слушает песню => пишется
Пример: Last.fm top list
На проигрыватель установлен плагин Last.fm
Пользователь слушает песню => пишется

Слайд 29Реализации
Google
Недоступна вне Google
GFS
Hadoop
Открытая имплементация на Java
HDFS
Aster Data
Cluster-optimized SQL Database которая также реализует
Реализации
Google
Недоступна вне Google
GFS
Hadoop
Открытая имплементация на Java
HDFS
Aster Data
Cluster-optimized SQL Database которая также реализует

Слайд 30Решаемые задачи
Индексация интернета
Задачи исследования данных
Data Mining данных
Задачи построения отчетов
Рендеринг набора кадров высококачественной
Решаемые задачи
Индексация интернета
Задачи исследования данных
Data Mining данных
Задачи построения отчетов
Рендеринг набора кадров высококачественной

Слайд 31Будущее
Microsoft Dryad – развитие идей map reduce.
Программист определяет ацикличный направленный граф с
Будущее
Microsoft Dryad – развитие идей map reduce.
Программист определяет ацикличный направленный граф с

Слайд 32Язык диаграмм Dryad
G^n = параллельный запуск n копий G
A >= B =
Язык диаграмм Dryad
G^n = параллельный запуск n копий G
A >= B =

 Данную презентацию использовать для изучения в 11 классе темы «Излучения и спектры. Спектральный анализ» Темы рассматриваются в
Данную презентацию использовать для изучения в 11 классе темы «Излучения и спектры. Спектральный анализ» Темы рассматриваются в  Животные живого уголка
Животные живого уголка Пирин, Рила и Централен Балкан са едни от най- големите и ценни защитени територии в Европа. В тях се опазват естествени екосистеми,
Пирин, Рила и Централен Балкан са едни от най- големите и ценни защитени територии в Европа. В тях се опазват естествени екосистеми,  Музыкальные инструменты
Музыкальные инструменты Интернет – образование
Интернет – образование Ковчег
Ковчег Разработка корпоративной структуры
Разработка корпоративной структуры Gli ospiti di Jerry. Chi è?
Gli ospiti di Jerry. Chi è? Круговая теория любви А. Рейса
Круговая теория любви А. Рейса Тема 1
Тема 1 Проверочная работа по теме «Строение клетки»
Проверочная работа по теме «Строение клетки» Не храм, не золотое зданье, Не круг отобранных друзей, - Христова Церковь есть собранье Крестом искупленных людей.
Не храм, не золотое зданье, Не круг отобранных друзей, - Христова Церковь есть собранье Крестом искупленных людей. Презентация на тему Виды компьютерных вирусов Антивирусные программы
Презентация на тему Виды компьютерных вирусов Антивирусные программы  Это у нас, это гордость Вятки
Это у нас, это гордость Вятки Новогодний калейдоскоп
Новогодний калейдоскоп День космонавтики (12 апреля)
День космонавтики (12 апреля) Катаракта и современные методы лечения
Катаракта и современные методы лечения Футбол моя любимая игра
Футбол моя любимая игра Афинский Акрополь
Афинский Акрополь Презентация на тему Самопрезентация учителя
Презентация на тему Самопрезентация учителя Writing a book report
Writing a book report Возможности «1С:Зарплата и управление персоналом 8 КОРП» для автоматизации крупных предприятий и холдингов
Возможности «1С:Зарплата и управление персоналом 8 КОРП» для автоматизации крупных предприятий и холдингов Бонусная программа общероссийского профсоюза образования
Бонусная программа общероссийского профсоюза образования Презентация на тему Адам Смит
Презентация на тему Адам Смит Преодоление страхов и психолого-эмоционального напряжения средствами данстерапии
Преодоление страхов и психолого-эмоционального напряжения средствами данстерапии «Использование информационных технологий в составлении оценочных средств. Тестовые задания»
«Использование информационных технологий в составлении оценочных средств. Тестовые задания» Бизнес план магазина одежды New Style
Бизнес план магазина одежды New Style Презентация на тему MS Excel основы работы
Презентация на тему MS Excel основы работы