- Matrixnet

Содержание
- 2. Линейная регрессия Дано: K N-мерных самплов {xi} для каждого известно значение функции {fi} Найти: вектор a,
- 3. Регуляризация Когда данных мало простое решение не работает Нужна какая-то дополнительная информация, например, мы можем сказать,
- 4. L1 регуляризация Итеративный алгоритм L1 регуляризации У нас есть текущий “остаток” ri, который в начале равен
- 5. Нелинейные модели Если бы у нас были пропорциональные релевантности независимые факторы, нам бы хватило линейной регрессии
- 6. Decision Tree
- 7. Boosting Построение strong learner как комбинации “weak learners” Связь с L1 регуляризацией weak learner = единственный
- 8. Bagging На каждой итерации будем брать не все самплы, а их случайное подмножество Магическим образом более
- 9. Limit on decision tree leafs Дисперсия ошибки значения в листе пропорциональна 1/N, где N – количество
- 10. TreeNet TreeNet товарища Friedman-a это Boosted Decision Tree с Bagging и ограничением на минимальное количество самплов
- 11. MatrixNet http://seodemotivators.ru/
- 12. MatrixNet MatrixNet отличается в 3-х моментах Использование Oblivious Trees Регуляризация значений в листах вместо ограничения на
- 13. Oblivious Trees
- 14. Регуляризация в листьях Вместо ограничения на количество самплов в листьях будем “регуляризовать” значение в листе Например,
- 15. Другие целевые функции А что, если вместо квадратичной ошибки мы хотим оптимизировать что-нибудь другое? Например, для
- 16. Gradient boosting На каждом шаге boosting-a вместо невязки ri мы аппроксимируем производную целевой функции в текущей
- 17. Ranking А что же делать, если мы хотим научиться ранжировать? Целевая функция для ranking (NDCG/pFound/whatever) задана
- 18. Luce-Plackett model Luce-Plackett model позволяет нам назначить вероятности всем перестановкам, если у нас есть веса документов
- 19. Expected pFound Для каждой перестановки мы можем посчитать ее pFound(perm). Также мы знаем вероятность этой перестановки
- 21. Скачать презентацию
Слайд 2Линейная регрессия
Дано: K N-мерных самплов {xi} для каждого известно значение функции {fi}
Найти:
Линейная регрессия
Дано: K N-мерных самплов {xi} для каждого известно значение функции {fi}
Найти:

Слайд 3Регуляризация
Когда данных мало простое решение не работает
Нужна какая-то дополнительная информация, например, мы
Регуляризация
Когда данных мало простое решение не работает
Нужна какая-то дополнительная информация, например, мы

Слайд 4L1 регуляризация
Итеративный алгоритм L1 регуляризации
У нас есть текущий “остаток” ri, который
L1 регуляризация
Итеративный алгоритм L1 регуляризации
У нас есть текущий “остаток” ri, который

Слайд 5Нелинейные модели
Если бы у нас были пропорциональные релевантности независимые факторы, нам бы
Нелинейные модели
Если бы у нас были пропорциональные релевантности независимые факторы, нам бы

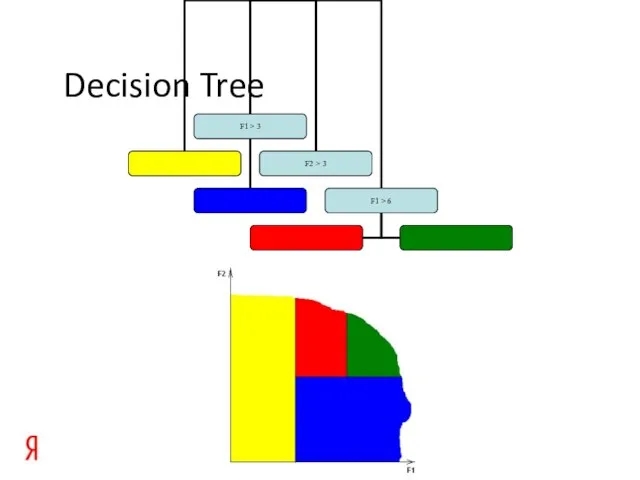
Слайд 6Decision Tree
Decision Tree
Слайд 7Boosting
Построение strong learner как комбинации “weak learners”
Связь с L1 регуляризацией
weak learner =
Boosting
Построение strong learner как комбинации “weak learners”
Связь с L1 регуляризацией
weak learner =

Слайд 8Bagging
На каждой итерации будем брать не все самплы, а их случайное подмножество
Магическим
Bagging
На каждой итерации будем брать не все самплы, а их случайное подмножество
Магическим

Слайд 9Limit on decision tree leafs
Дисперсия ошибки значения в листе пропорциональна 1/N, где
Limit on decision tree leafs
Дисперсия ошибки значения в листе пропорциональна 1/N, где

Слайд 10TreeNet
TreeNet товарища Friedman-a это Boosted Decision Tree с Bagging и ограничением на
TreeNet
TreeNet товарища Friedman-a это Boosted Decision Tree с Bagging и ограничением на

Слайд 11MatrixNet
http://seodemotivators.ru/
MatrixNet
http://seodemotivators.ru/

Слайд 12MatrixNet
MatrixNet отличается в 3-х моментах
Использование Oblivious Trees
Регуляризация значений в листах вместо ограничения
MatrixNet
MatrixNet отличается в 3-х моментах
Использование Oblivious Trees
Регуляризация значений в листах вместо ограничения

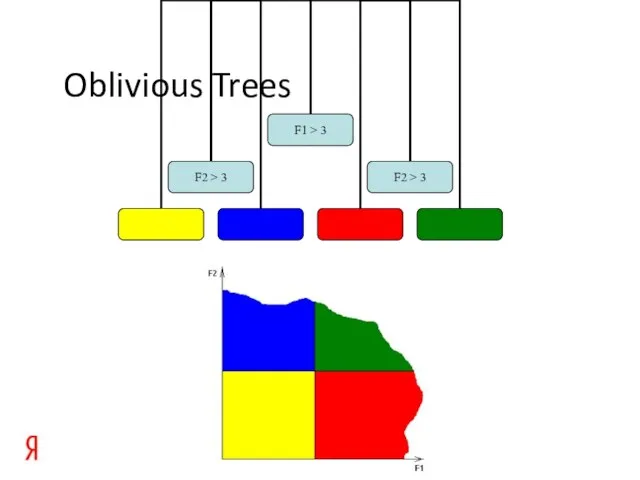
Слайд 13Oblivious Trees
Oblivious Trees
Слайд 14Регуляризация в листьях
Вместо ограничения на количество самплов в листьях будем “регуляризовать” значение
Регуляризация в листьях
Вместо ограничения на количество самплов в листьях будем “регуляризовать” значение

Слайд 15Другие целевые функции
А что, если вместо квадратичной ошибки мы хотим оптимизировать что-нибудь
Другие целевые функции
А что, если вместо квадратичной ошибки мы хотим оптимизировать что-нибудь

Слайд 16Gradient boosting
На каждом шаге boosting-a вместо невязки ri мы аппроксимируем производную целевой
Gradient boosting
На каждом шаге boosting-a вместо невязки ri мы аппроксимируем производную целевой

Слайд 17Ranking
А что же делать, если мы хотим научиться ранжировать?
Целевая функция для ranking
Ranking
А что же делать, если мы хотим научиться ранжировать?
Целевая функция для ranking

Слайд 18Luce-Plackett model
Luce-Plackett model позволяет нам назначить вероятности всем перестановкам, если у нас
Luce-Plackett model
Luce-Plackett model позволяет нам назначить вероятности всем перестановкам, если у нас

Слайд 19Expected pFound
Для каждой перестановки мы можем посчитать ее pFound(perm). Также мы знаем
Expected pFound
Для каждой перестановки мы можем посчитать ее pFound(perm). Также мы знаем

 Ерёмина Наталья Петровна учитель русского языка и литературы первой квалификационной категории
Ерёмина Наталья Петровна учитель русского языка и литературы первой квалификационной категории Особенности чувашской национальной кухни
Особенности чувашской национальной кухни Выдающиеся писатели России
Выдающиеся писатели России Презентация на тему Квадратное уравнение и его корни (8 класс)
Презентация на тему Квадратное уравнение и его корни (8 класс) Паевой инвестиционный фонд (ПИФ) – новый для России способ вложения денег, который с каждым годом становится всё более популярным.
Паевой инвестиционный фонд (ПИФ) – новый для России способ вложения денег, который с каждым годом становится всё более популярным.  ИНТЕГРИРОВАННЫЙ УРОК С КОМПЬЮТЕРНОЙ ПОДДЕРЖКОЙпо русскому языку и окружающему миру по теме: «Правописание падежных окончаний им
ИНТЕГРИРОВАННЫЙ УРОК С КОМПЬЮТЕРНОЙ ПОДДЕРЖКОЙпо русскому языку и окружающему миру по теме: «Правописание падежных окончаний им Мы идем в театр
Мы идем в театр Управління освіти і науки Вінницької обласної державної адміністрації Управління освіти Вінницької міської ради Фізико-математи
Управління освіти і науки Вінницької обласної державної адміністрації Управління освіти Вінницької міської ради Фізико-математи Орнамент
Орнамент Методика обучения квадратным уравнениям
Методика обучения квадратным уравнениям Животная клетка
Животная клетка Конкурс чтецов 1-4 классов в Выльгортской Школе №1
Конкурс чтецов 1-4 классов в Выльгортской Школе №1 Реклама на спинках кресел в кинотеатрах
Реклама на спинках кресел в кинотеатрах Презентация на тему Религиозные конфликты
Презентация на тему Религиозные конфликты Танцы народов мира
Танцы народов мира Размер пособия в Республике Коми
Размер пособия в Республике Коми Связь потребностей и видов деятельности
Связь потребностей и видов деятельности Sortir
Sortir Разрез
Разрез English is like a global in modern world
English is like a global in modern world Kit vivienda Unifamiliar
Kit vivienda Unifamiliar Место духовной музыки в мировой художественной культуре
Место духовной музыки в мировой художественной культуре Водопоровод
Водопоровод Значение и специфика театрального искусства
Значение и специфика театрального искусства Общие сведения
Общие сведения Pronomi personali e pronomi/aggettivi possessivi
Pronomi personali e pronomi/aggettivi possessivi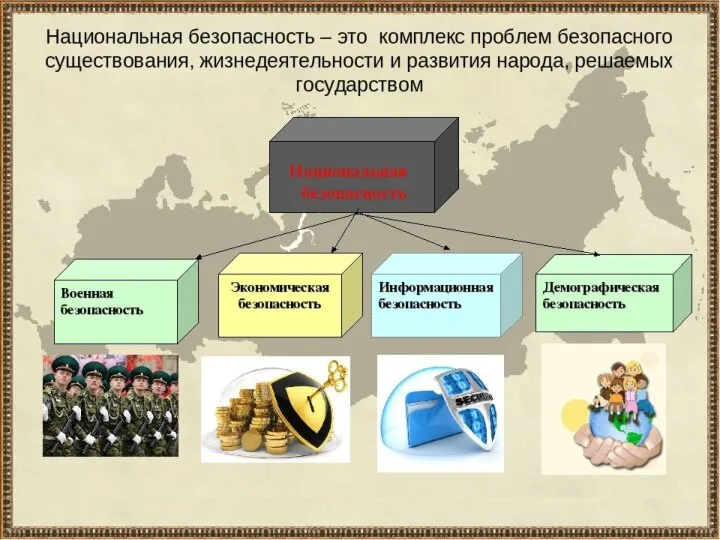 Национальная безопасность
Национальная безопасность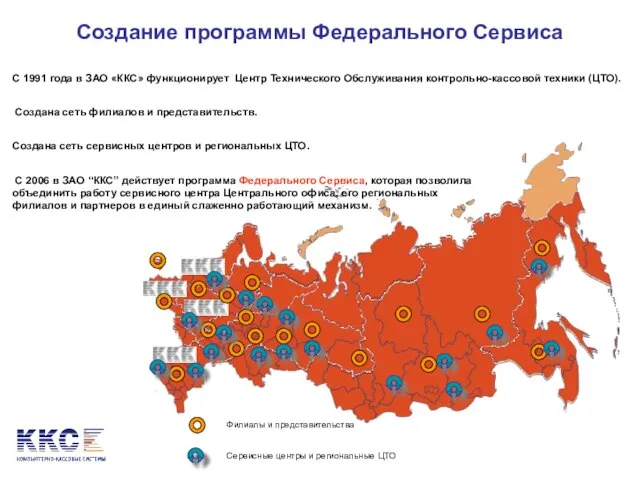 Создание программы Федерального Сервиса
Создание программы Федерального Сервиса