- Обучение без учителя

Содержание
- 2. Пример После проведения социологического исследования, как выявить группы людей сходных мнений? Есть большая база данных изображений,
- 3. Обучение без учителя Пусть, имеется набор наблюдений: Требуется некоторым образом сделать суждения о наблюдаемых данных Трудно
- 4. Обучение без учителя Кластеризация Разбиение наблюдений на некоторые группы, с максимально близкими наблюдениями внутри групп и
- 5. Обучение без учителя Кластеризация К-средних Смесь нормальных распределений … Понижение размерности Метод главных компонент SOM …
- 6. Отличие от классификации Множество ответов неизвестно Нет четкой меры качества решений Задачи поставлены крайне нечетко
- 7. Кластеризация Постановка задачи (1) Пусть, имеется набор наблюдений: Требуется разбить на некоторые непересекающиеся подмножества (группы, кластеры),
- 8. Кластеризация Постановка задачи (2) Пусть, так же, имеется некоторая мера , характеризующая «схожесть» между объектами Тогда,
- 9. Кластеризация Модель кластеров Под моделью кластеров будем понимать некоторое параметрическое семейство отображений из исходного пространства в
- 10. Алгоритм К-средних Кто хочет рассказать как он работает? Случайным образом выбрать k средних mj j=1,…,k; Для
- 11. Иллюстрация
- 12. Алгоритм К-средних Мера схожести Евклидово расстояние в пространстве Х Модель кластеров Пространство поиска - центры масс
- 13. Алгоритм К-средних Однопараметрический Требует знания только о количестве кластеров Рандомизирован Зависит от начального приближения Не учитывает
- 14. EM алгоритм Общая идеология Пусть есть вектор неизвестных величин и параметрическая модель с так же неизвестным
- 15. EM алгоритм Общая идеология Возьмем некоторые начальные приближения Итеративно t =1… делаем два шага: Expect: согласно
- 16. Кластеризация смесью нормальных распределений Будем считать, что наблюдения сгенерированы смесью нормальных распределений, то есть: Пусть k
- 17. Кластеризация смесью нормальных распределений Возьмем некоторые (случайные) начальные приближения Итеративно для t =1… : E: согласно
- 18. Иллюстрация
- 19. Кластеризация смесью нормальных распределений Плюсы Более полная модель кластеров (больше итоговой информации) Более качественная аппроксимация Эффективная
- 20. Иллюстрация
- 21. Понижение размерности наблюдаемых данных Зачастую, наблюдаемые данные могут обладать высокой размерностью, но в действительности быть функцией
- 22. Метод главных компонент Пусть имеется набор наблюдений Будем строить новый базис в пространстве , таким образом
- 23. Метод главных компонент Расчет базиса Сдвинем все данные таким образом, чтобы их выборочное среднее равнялось нулю
- 24. Метод главных компонент Расчет базиса Векторами нового базиса будут являться собственные вектора ковариационной матрицы Собственные числа
- 25. Иллюстрация Убирая базисные вектора с малыми значениями мы можем сократить размерность без существенной потери информации *Вопрос:
- 26. Случай нормального распределения Расстояние от центра распределения в новой системе координат равно: Так называемое расстояние Махалонобиса
- 27. Метод главных компонент Связь с линейной аппроксимацией Если рассмотреть систему проекций данных на первые главных компонент,
- 28. Метод главных компонент Следует применять: Данные распределены нормально и требуется привести их к более удобной форме
- 29. Самоорганизующиеся карты SOM (Карты Кохенена) Основная идея вписать в данные сетку низкой размерности, и анализировать ее,
- 30. SOM (Карты Кохенена) Модель сетки Матрица узлов Соседство - 4 или 8 связность Каждому узлу соответствует
- 31. SOM (Карты Кохенена) Алгоритм построения Проинициализируем случайными значениями Далее, в случайном порядке будем предъявлять наблюдения и
- 32. SOM (Карты Кохенена) Иллюстрация: исходные данные
- 33. SOM (Карты Кохенена) Иллюстрация: сетка
- 34. SOM (Карты Кохенена) Иллюстрация: проекции на матрицу
- 35. SOM (Карты Кохенена) Практическое использование Данные представляют некоторую поверхность, требуется сократить размерность Хорошо подходят для последующей
- 36. Задание №2 Каждому будут выданы Данные (3 набора) Алгоритмы классификации, реализованные в MatLab Требуется Для каждого
- 37. Содержание отчета Применявшиеся методы Список Алгоритм, по которому оценивались алгоритмы и выбирались параметры Результаты в виде
- 39. Скачать презентацию
Слайд 2Пример
После проведения социологического исследования, как выявить группы людей сходных мнений?
Есть большая база
Пример
После проведения социологического исследования, как выявить группы людей сходных мнений?
Есть большая база

Слайд 3Обучение без учителя
Пусть, имеется набор наблюдений:
Требуется некоторым образом сделать суждения о наблюдаемых
Обучение без учителя
Пусть, имеется набор наблюдений:
Требуется некоторым образом сделать суждения о наблюдаемых

Слайд 4Обучение без учителя
Кластеризация
Разбиение наблюдений на некоторые группы, с максимально близкими наблюдениями внутри
Обучение без учителя
Кластеризация
Разбиение наблюдений на некоторые группы, с максимально близкими наблюдениями внутри

Слайд 5Обучение без учителя
Кластеризация
К-средних
Смесь нормальных распределений
…
Понижение размерности
Метод главных компонент
SOM
…
Анализ плотности распределения
Аппроксимация плотности распределения
Обучение без учителя
Кластеризация
К-средних
Смесь нормальных распределений
…
Понижение размерности
Метод главных компонент
SOM
…
Анализ плотности распределения
Аппроксимация плотности распределения

Слайд 6Отличие от классификации
Множество ответов неизвестно
Нет четкой меры качества решений
Задачи поставлены крайне нечетко
Отличие от классификации
Множество ответов неизвестно
Нет четкой меры качества решений
Задачи поставлены крайне нечетко

Слайд 7Кластеризация
Постановка задачи (1)
Пусть, имеется набор наблюдений:
Требуется разбить на некоторые непересекающиеся подмножества (группы,
Кластеризация
Постановка задачи (1)
Пусть, имеется набор наблюдений:
Требуется разбить на некоторые непересекающиеся подмножества (группы,

Слайд 8Кластеризация
Постановка задачи (2)
Пусть, так же, имеется некоторая мера , характеризующая «схожесть» между
Кластеризация
Постановка задачи (2)
Пусть, так же, имеется некоторая мера , характеризующая «схожесть» между

Слайд 9Кластеризация
Модель кластеров
Под моделью кластеров будем понимать некоторое параметрическое семейство отображений из исходного
Кластеризация
Модель кластеров
Под моделью кластеров будем понимать некоторое параметрическое семейство отображений из исходного

Слайд 10Алгоритм К-средних
Кто хочет рассказать как он работает?
Случайным образом выбрать k средних mj
Алгоритм К-средних
Кто хочет рассказать как он работает?
Случайным образом выбрать k средних mj

Слайд 11Иллюстрация
Иллюстрация
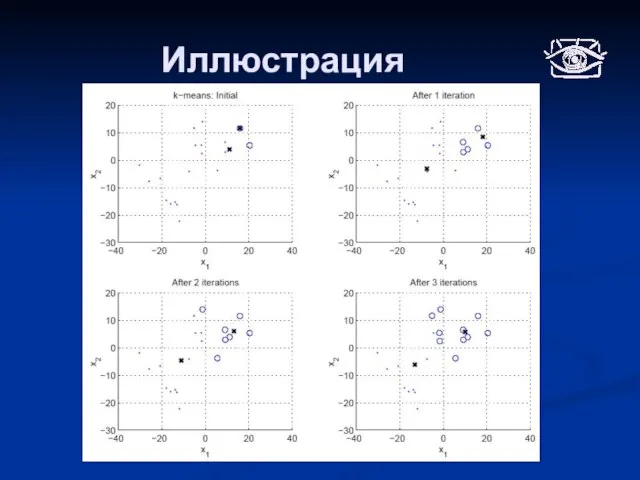
Слайд 12Алгоритм К-средних
Мера схожести
Евклидово расстояние в пространстве Х
Модель кластеров
Пространство поиска - центры
Алгоритм К-средних
Мера схожести
Евклидово расстояние в пространстве Х
Модель кластеров
Пространство поиска - центры

Слайд 13Алгоритм К-средних
Однопараметрический
Требует знания только о количестве кластеров
Рандомизирован
Зависит от начального приближения
Не учитывает строения
Алгоритм К-средних
Однопараметрический
Требует знания только о количестве кластеров
Рандомизирован
Зависит от начального приближения
Не учитывает строения
Слайд 14EM алгоритм
Общая идеология
Пусть есть вектор неизвестных величин
и параметрическая модель с так же
EM алгоритм
Общая идеология
Пусть есть вектор неизвестных величин
и параметрическая модель с так же

Слайд 15EM алгоритм
Общая идеология
Возьмем некоторые начальные приближения
Итеративно t =1… делаем два шага:
Expect:
EM алгоритм
Общая идеология
Возьмем некоторые начальные приближения
Итеративно t =1… делаем два шага:
Expect:

Слайд 16Кластеризация смесью нормальных распределений
Будем считать, что наблюдения сгенерированы смесью нормальных распределений, то
Кластеризация смесью нормальных распределений
Будем считать, что наблюдения сгенерированы смесью нормальных распределений, то

Слайд 17Кластеризация смесью нормальных распределений
Возьмем некоторые (случайные) начальные приближения
Итеративно для t =1… :
E:
Кластеризация смесью нормальных распределений
Возьмем некоторые (случайные) начальные приближения
Итеративно для t =1… :
E:

Слайд 18Иллюстрация
Иллюстрация
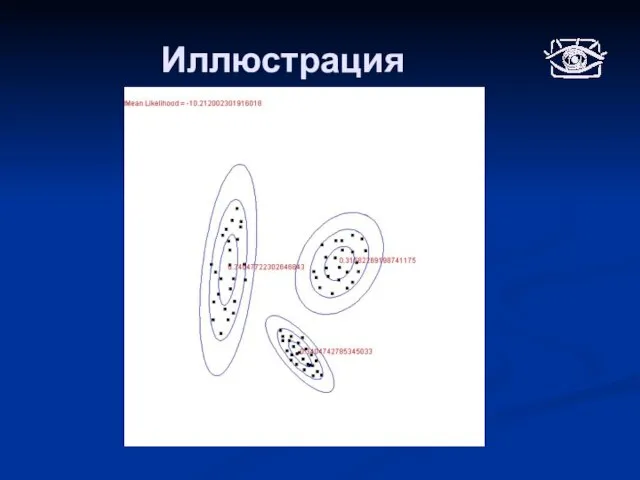
Слайд 19Кластеризация смесью нормальных распределений
Плюсы
Более полная модель кластеров (больше итоговой информации)
Более качественная аппроксимация
Эффективная
Кластеризация смесью нормальных распределений
Плюсы
Более полная модель кластеров (больше итоговой информации)
Более качественная аппроксимация
Эффективная

Слайд 20Иллюстрация
Иллюстрация

Слайд 21Понижение размерности наблюдаемых данных
Зачастую, наблюдаемые данные могут обладать высокой размерностью, но в
Понижение размерности наблюдаемых данных
Зачастую, наблюдаемые данные могут обладать высокой размерностью, но в

Слайд 22Метод главных компонент
Пусть имеется набор наблюдений
Будем строить новый базис в пространстве ,
Метод главных компонент
Пусть имеется набор наблюдений
Будем строить новый базис в пространстве ,

Слайд 23Метод главных компонент
Расчет базиса
Сдвинем все данные таким образом, чтобы их выборочное среднее
Метод главных компонент
Расчет базиса
Сдвинем все данные таким образом, чтобы их выборочное среднее

Слайд 24Метод главных компонент
Расчет базиса
Векторами нового базиса будут являться собственные вектора ковариационной матрицы
Собственные
Метод главных компонент
Расчет базиса
Векторами нового базиса будут являться собственные вектора ковариационной матрицы
Собственные

Слайд 25Иллюстрация
Убирая базисные вектора с малыми значениями мы можем сократить размерность без существенной
Иллюстрация
Убирая базисные вектора с малыми значениями мы можем сократить размерность без существенной

Слайд 26Случай нормального распределения
Расстояние от центра распределения в новой системе координат равно:
Так называемое
Случай нормального распределения
Расстояние от центра распределения в новой системе координат равно:
Так называемое

Слайд 27Метод главных компонент
Связь с линейной аппроксимацией
Если рассмотреть систему проекций данных на первые
Метод главных компонент
Связь с линейной аппроксимацией
Если рассмотреть систему проекций данных на первые
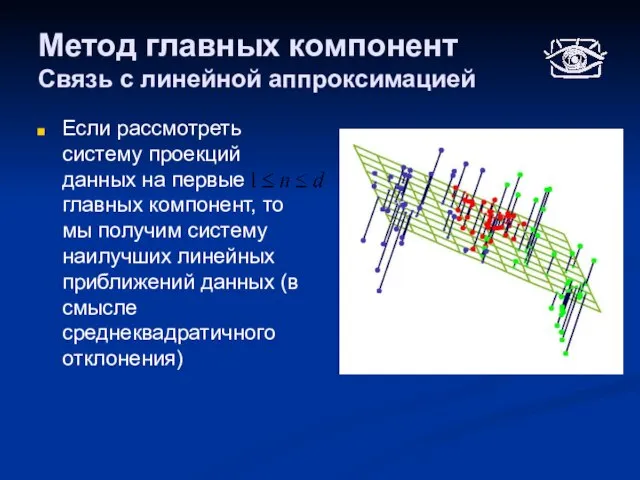
Слайд 28Метод главных компонент
Следует применять:
Данные распределены нормально и требуется привести их к более
Метод главных компонент
Следует применять:
Данные распределены нормально и требуется привести их к более

Слайд 29Самоорганизующиеся карты
SOM (Карты Кохенена)
Основная идея
вписать в данные сетку низкой размерности, и анализировать
Самоорганизующиеся карты
SOM (Карты Кохенена)
Основная идея
вписать в данные сетку низкой размерности, и анализировать

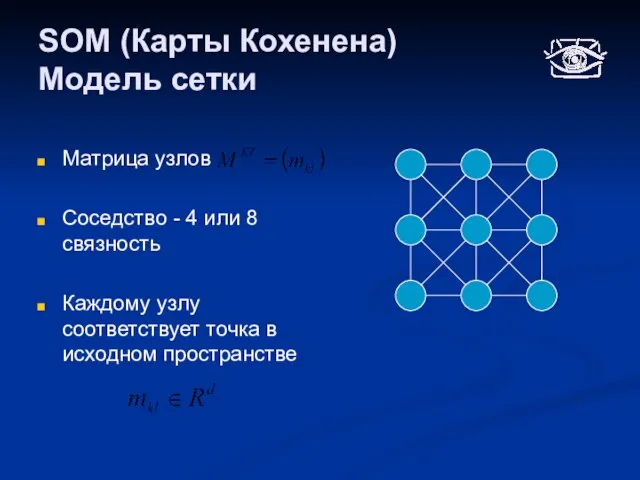
Слайд 30SOM (Карты Кохенена)
Модель сетки
Матрица узлов
Соседство - 4 или 8 связность
Каждому узлу соответствует
SOM (Карты Кохенена)
Модель сетки
Матрица узлов
Соседство - 4 или 8 связность
Каждому узлу соответствует
Слайд 31SOM (Карты Кохенена)
Алгоритм построения
Проинициализируем случайными значениями
Далее, в случайном порядке будем предъявлять
SOM (Карты Кохенена)
Алгоритм построения
Проинициализируем случайными значениями
Далее, в случайном порядке будем предъявлять

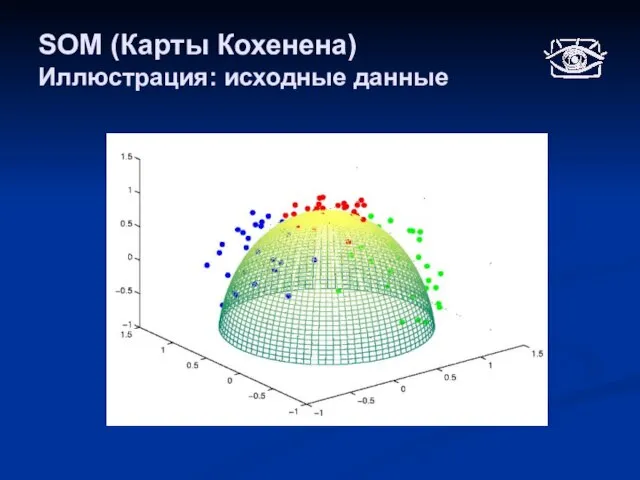
Слайд 32SOM (Карты Кохенена)
Иллюстрация: исходные данные
SOM (Карты Кохенена)
Иллюстрация: исходные данные
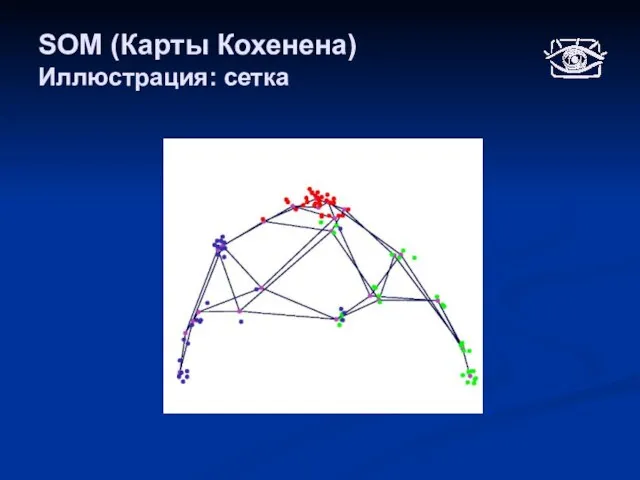
Слайд 33SOM (Карты Кохенена)
Иллюстрация: сетка
SOM (Карты Кохенена)
Иллюстрация: сетка
Слайд 34SOM (Карты Кохенена)
Иллюстрация: проекции на матрицу
SOM (Карты Кохенена)
Иллюстрация: проекции на матрицу

Слайд 35SOM (Карты Кохенена)
Практическое использование
Данные представляют некоторую поверхность, требуется сократить размерность
Хорошо подходят
SOM (Карты Кохенена)
Практическое использование
Данные представляют некоторую поверхность, требуется сократить размерность
Хорошо подходят

Слайд 36Задание №2
Каждому будут выданы
Данные (3 набора)
Алгоритмы классификации, реализованные в MatLab
Требуется
Для каждого
Задание №2
Каждому будут выданы
Данные (3 набора)
Алгоритмы классификации, реализованные в MatLab
Требуется
Для каждого

Слайд 37Содержание отчета
Применявшиеся методы
Список
Алгоритм, по которому оценивались алгоритмы и выбирались параметры
Результаты в виде
Графиков
Таблиц
Выводы
Содержание отчета
Применявшиеся методы
Список
Алгоритм, по которому оценивались алгоритмы и выбирались параметры
Результаты в виде
Графиков
Таблиц
Выводы

 Планировка кухни
Планировка кухни 30 червня 2011 року м. Київ, УНЦПД РЕЗУЛЬТАТИ МОНІТОРИНГУ ІНФОРМАЦІЙНОГО НАПОВНЕННЯ ОФІЦІЙНИХ ВЕБ-СТОРІНОК МІСЦЕВИХ ДЕРЖАВНИХ АДМІНІ
30 червня 2011 року м. Київ, УНЦПД РЕЗУЛЬТАТИ МОНІТОРИНГУ ІНФОРМАЦІЙНОГО НАПОВНЕННЯ ОФІЦІЙНИХ ВЕБ-СТОРІНОК МІСЦЕВИХ ДЕРЖАВНИХ АДМІНІ Структура информационного обеспечения процесса обучения
Структура информационного обеспечения процесса обучения Ударно-тяговые приборы
Ударно-тяговые приборы Одномерные массивы. Вставка и удаление элемента
Одномерные массивы. Вставка и удаление элемента Презентация на тему Деятельность римских юристов
Презентация на тему Деятельность римских юристов Морской транспорт
Морской транспорт Актив. Экономика и финансы проекта
Актив. Экономика и финансы проекта HR В УПРАВЛЕНЧЕСКОЙ КОМАНДЕ: роли, функции, формы взаимодействия с менеджментом
HR В УПРАВЛЕНЧЕСКОЙ КОМАНДЕ: роли, функции, формы взаимодействия с менеджментом Работа с источником
Работа с источником Презентация на тему Обучение грамоте 1 класс "Знакомство со звуком а, буквой А"
Презентация на тему Обучение грамоте 1 класс "Знакомство со звуком а, буквой А" В гости на Креатиду
В гости на Креатиду Бокс и борьба как основные виды силовых состязаний
Бокс и борьба как основные виды силовых состязаний ХРАНИЛИЩЕ БЕСЦЕННЫХ РЕЛИКВИЙ
ХРАНИЛИЩЕ БЕСЦЕННЫХ РЕЛИКВИЙ Подготовка учащихсяк ЕГЭ по математике
Подготовка учащихсяк ЕГЭ по математике Новогоднее мероприятие в стиле «Фильм! Фильм ! Фильм!»
Новогоднее мероприятие в стиле «Фильм! Фильм ! Фильм!» Деревянная архитектура. Рисунок карандашом
Деревянная архитектура. Рисунок карандашом А. П. Чехов «Ионыч»
А. П. Чехов «Ионыч» Оптимизация документооборота на предприятияхжелезнодорожного транспорта
Оптимизация документооборота на предприятияхжелезнодорожного транспорта Формы получения смешанного образования
Формы получения смешанного образования Освоение космоса и условия жизни на космическом корабле
Освоение космоса и условия жизни на космическом корабле Презентация Беларусь
Презентация Беларусь Откуда произошло название наших улиц
Откуда произошло название наших улиц Презентация на тему ДНК и РНК - нуклеиновые кислоты
Презентация на тему ДНК и РНК - нуклеиновые кислоты Loving Hut. Контент-план
Loving Hut. Контент-план Японская мифология
Японская мифология Сторителлинг Пишем с пользой!
Сторителлинг Пишем с пользой! Африка: ФГП и характер поверхности материка
Африка: ФГП и характер поверхности материка