- Семантическая сегментация

Содержание
- 2. Наивная классификация Нужно классифицировать каждый пиксель 1 МП на картинку! Что можно сказать про 1 пиксел?
- 3. Наивная классификация Сегментируем картинку, затем классифицируем сегменты Классифицируем каждый пиксель по окрестности
- 4. Пространственная поддержка 50x50 Patch 50x50 Patch По небольшой окрестности зачастую невозможно правильно определить метку Пространственная поддержка
- 5. Построение решения Задача / Данные Элемент Пиксель Сегмент Классификация пикселов / регионов Признаки для классификации Метод
- 6. Цель: 7 геометрических классов Земля Вертикальные стены Плоскости: смотрящие влево (?), Прямо ( ), Направо (?)
- 7. Размеченные данные 300 изображений из гугла
- 8. Признаки Положение
- 9. Сегментация изображений Использование нескольких вариантов сегментации (с разными параметрами) Решение, какие сегменты хорошие, откладывается на потом
- 10. Что мы хотим узнать: Хороший ли это сегмент? Если сегмент хороший, то какая у него метка?
- 11. Классификация … … Для каждого сегмента вычисляется: - P(good segment | data) P(label | good segment,
- 12. Разметка изображений … Размеченные сегментации Размеченные пиксели
- 13. Вероятностная разметка Support Vertical Sky V-Left V-Center V-Right V-Porous V-Solid
- 14. Результат Вход Ручная разметка Результат алгоритма
- 15. Изображения из помещений Вход Ручная разметка Результат
- 16. Рисунки Вход Результат
- 17. Приложение: Automatic Photo Pop-up (SIGGRAPH’05) Изображение Метки
- 18. Automatic Photo Pop-up
- 19. TextonBoost J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context Modeling
- 20. Data and Classes Goal: assign every pixel to a label MSRC-21 database (“void” label ignored for
- 21. Марковские Случайные Поля Независимая классификация Применяем обычный метод классификации (SVM, бустинг и т.д.) Схема Марковских Случайных
- 22. Условные случайные поля МСП для совместной оценки разметки случайных переменных (c), при условии всех данных (x)
- 23. Вывод (Inference) Вывод = поиск наилучшей совместной разметки NP-полная задача в общем случае Argmax-разметка Попарные потенциалы
- 24. Обзор метода Модель TextonBoost на основе CRF 4-х связанные окрестности Параметры обучаются независимо Вывод GraphCut VS
- 25. Форма и текстура (Shape & Texture) Первая и главная компонента модели Текстоны Фильтруем изображение банком фильтров
- 26. Моделирование формы Шаг 1: получили карту текстонов Шаг 2: Фильтры формы (Shape Filters) Для каждого текстона
- 27. Фильтры формы Пара: Отклики v(i, r, t) Большие области обеспечивают большую пространственную поддержку Рассчет через интегральные
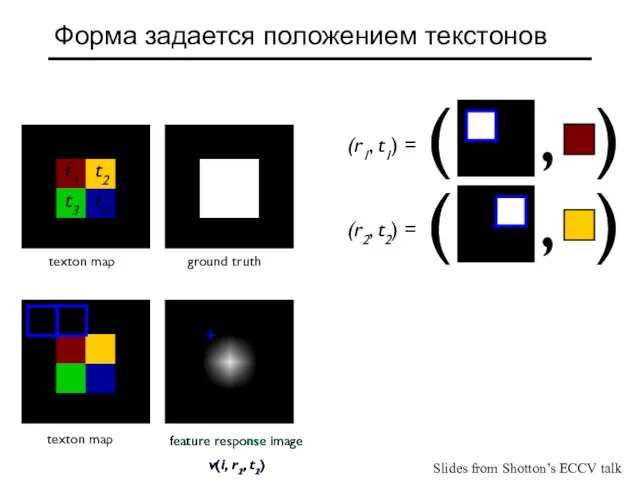
- 28. feature response image v(i, r1, t1) feature response image v(i, r2, t2) Форма задается положением текстонов
- 29. summed response images v(i, r1, t1) + v(i, r2, t2) Форма задается положением текстонов ( ,
- 30. Обучение Используется бустинг Обычный бустинг Для каждого пикселя Для каждой возможной маски Для каждого текстона Считаем
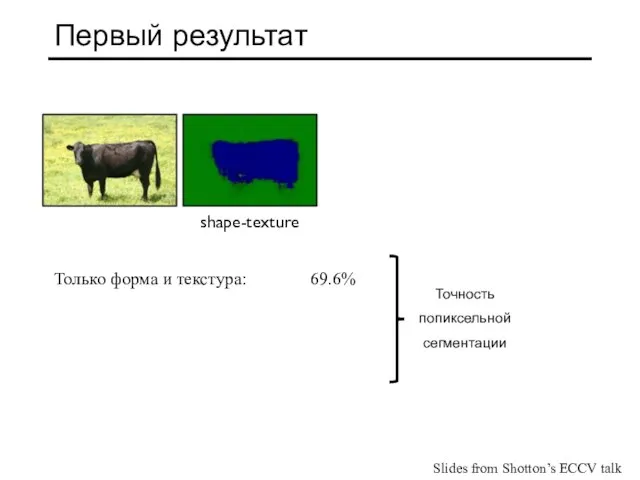
- 31. Первый результат Только форма и текстура: 69.6% shape-texture Точность попиксельной сегментации Slides from Shotton’s ECCV talk
- 32. Уточняем разметку Добавляем границы Потенциал границ Используем попарные потенциалы для определения и подчеркивания границ Идея: Если
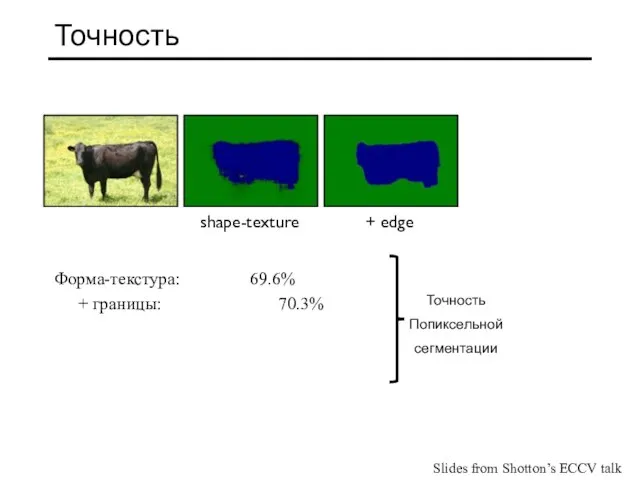
- 33. Точность Форма-текстура: 69.6% + границы: 70.3% shape-texture + edge Точность Попиксельной сегментации Slides from Shotton’s ECCV
- 34. Положение объектов Положение Нормализуем координаты по всем изображениям Посчитываем частоту появления объектов в данной точке изображения
- 35. Моделирование цвета Цвет Обучаем модель цвета только по изображению Идея Используем классификацию по другим признакам как
- 36. Общий результат Форма и текстура: 69.6% + границ: 70.3% + цвет: 72.0% + положение: 72.2% shape-texture
- 37. Результаты Successes
- 38. Ошибки
- 40. Скачать презентацию
Слайд 2Наивная классификация
Нужно классифицировать каждый пиксель
1 МП на картинку!
Что можно сказать про
Наивная классификация
Нужно классифицировать каждый пиксель
1 МП на картинку!
Что можно сказать про

Слайд 3Наивная классификация
Сегментируем картинку, затем классифицируем сегменты
Классифицируем каждый пиксель по окрестности
Наивная классификация
Сегментируем картинку, затем классифицируем сегменты
Классифицируем каждый пиксель по окрестности

Слайд 4Пространственная поддержка
50x50 Patch
50x50 Patch
По небольшой окрестности зачастую невозможно правильно определить метку
Пространственная поддержка
Необходимо
Пространственная поддержка
50x50 Patch
50x50 Patch
По небольшой окрестности зачастую невозможно правильно определить метку
Пространственная поддержка
Необходимо

Слайд 5Построение решения
Задача / Данные
Элемент
Пиксель
Сегмент
Классификация пикселов / регионов
Признаки для классификации
Метод классификации (бустинг,
Построение решения
Задача / Данные
Элемент
Пиксель
Сегмент
Классификация пикселов / регионов
Признаки для классификации
Метод классификации (бустинг,

Слайд 6Цель: 7 геометрических классов
Земля
Вертикальные стены
Плоскости: смотрящие влево (?), Прямо ( ), Направо
Цель: 7 геометрических классов
Земля
Вертикальные стены
Плоскости: смотрящие влево (?), Прямо ( ), Направо

Слайд 7Размеченные данные
300 изображений из гугла
Размеченные данные
300 изображений из гугла

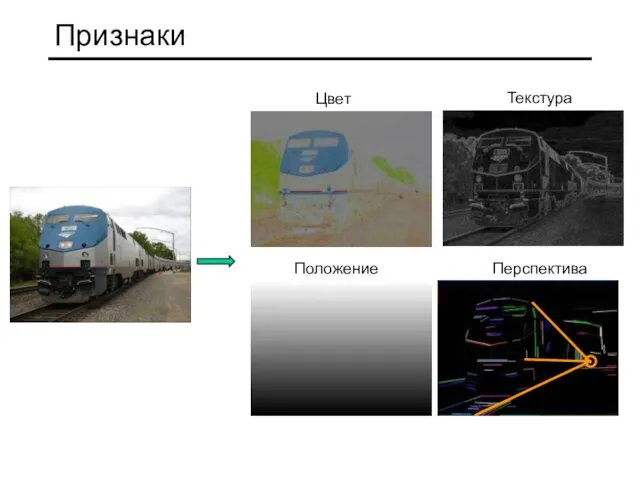
Слайд 8Признаки
Положение
Признаки
Положение
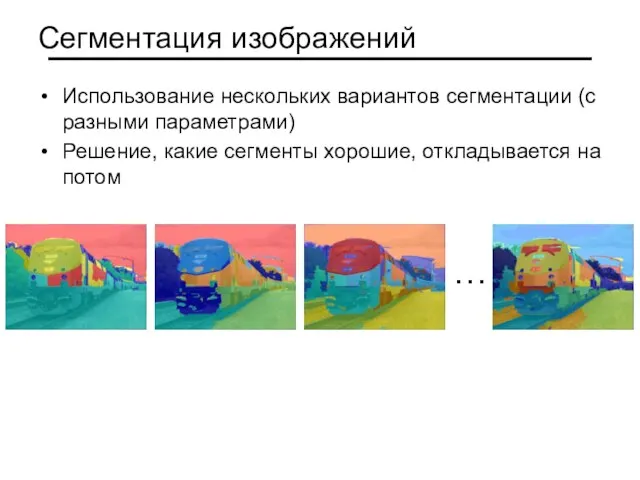
Слайд 9Сегментация изображений
Использование нескольких вариантов сегментации (с разными параметрами)
Решение, какие сегменты хорошие, откладывается
Сегментация изображений
Использование нескольких вариантов сегментации (с разными параметрами)
Решение, какие сегменты хорошие, откладывается
Слайд 10Что мы хотим узнать:
Хороший ли это сегмент?
Если сегмент хороший, то какая у
Что мы хотим узнать:
Хороший ли это сегмент?
Если сегмент хороший, то какая у

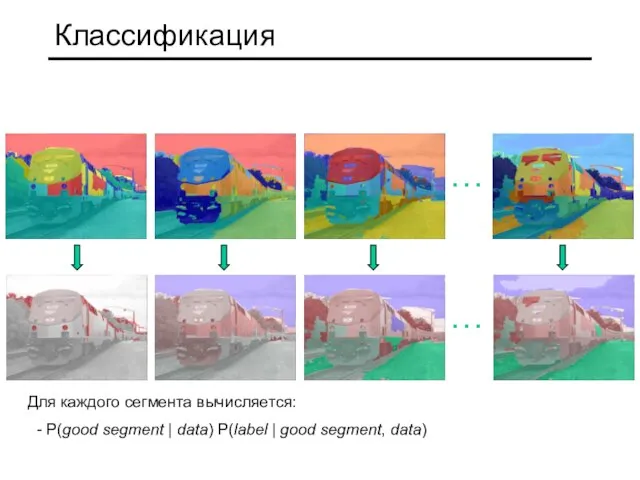
Слайд 11Классификация
…
…
Для каждого сегмента вычисляется:
- P(good segment | data) P(label | good
Классификация
…
…
Для каждого сегмента вычисляется:
- P(good segment | data) P(label | good
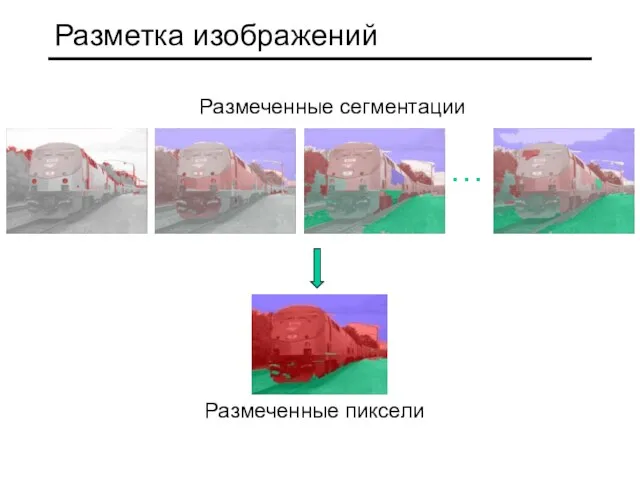
Слайд 12Разметка изображений
…
Размеченные сегментации
Размеченные пиксели
Разметка изображений
…
Размеченные сегментации
Размеченные пиксели
Слайд 13Вероятностная разметка
Support
Vertical
Sky
V-Left
V-Center
V-Right
V-Porous
V-Solid
Вероятностная разметка
Support
Vertical
Sky
V-Left
V-Center
V-Right
V-Porous
V-Solid

Слайд 14Результат
Вход
Ручная разметка
Результат алгоритма
Результат
Вход
Ручная разметка
Результат алгоритма

Слайд 15Изображения из помещений
Вход
Ручная разметка
Результат
Изображения из помещений
Вход
Ручная разметка
Результат

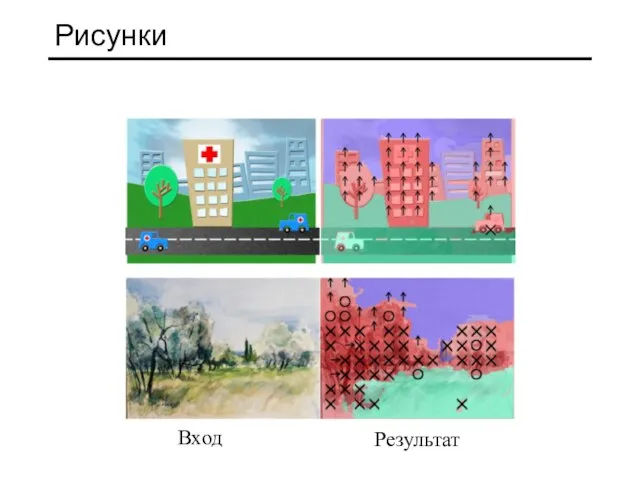
Слайд 16Рисунки
Вход
Результат
Рисунки
Вход
Результат
Слайд 17Приложение: Automatic Photo Pop-up (SIGGRAPH’05)
Изображение
Метки
Приложение: Automatic Photo Pop-up (SIGGRAPH’05)
Изображение
Метки

Слайд 18Automatic Photo Pop-up
Automatic Photo Pop-up

Слайд 19TextonBoost
J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape
TextonBoost
J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape

Слайд 20Data and Classes
Goal: assign every pixel to a label
MSRC-21 database (“void” label
Data and Classes
Goal: assign every pixel to a label
MSRC-21 database (“void” label

Слайд 21Марковские Случайные Поля
Независимая классификация
Применяем обычный метод классификации (SVM, бустинг и т.д.)
Схема Марковских
Марковские Случайные Поля
Независимая классификация
Применяем обычный метод классификации (SVM, бустинг и т.д.)
Схема Марковских

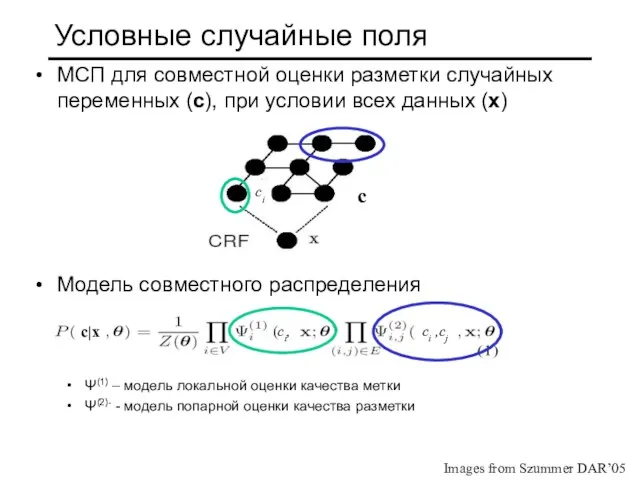
Слайд 22Условные случайные поля
МСП для совместной оценки разметки случайных переменных (c), при условии
Условные случайные поля
МСП для совместной оценки разметки случайных переменных (c), при условии
Слайд 23Вывод (Inference)
Вывод = поиск наилучшей совместной разметки
NP-полная задача в общем случае
Argmax-разметка
Попарные
Вывод (Inference)
Вывод = поиск наилучшей совместной разметки
NP-полная задача в общем случае
Argmax-разметка
Попарные

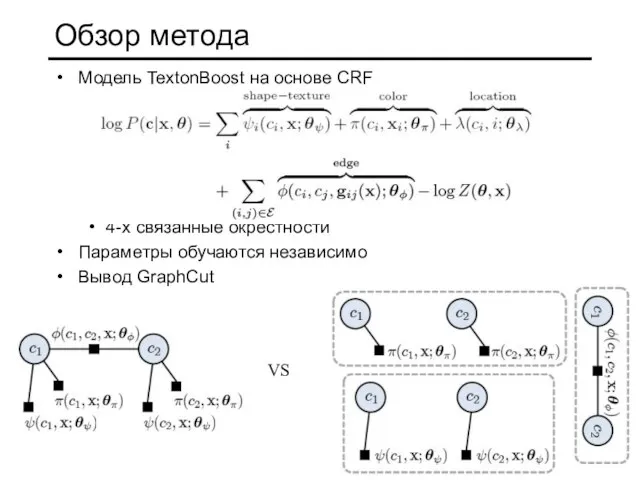
Слайд 24Обзор метода
Модель TextonBoost на основе CRF
4-х связанные окрестности
Параметры обучаются независимо
Вывод GraphCut
VS
Обзор метода
Модель TextonBoost на основе CRF
4-х связанные окрестности
Параметры обучаются независимо
Вывод GraphCut
VS
Слайд 25Форма и текстура (Shape & Texture)
Первая и главная компонента модели
Текстоны
Фильтруем изображение банком
Форма и текстура (Shape & Texture)
Первая и главная компонента модели
Текстоны
Фильтруем изображение банком

Слайд 26Моделирование формы
Шаг 1: получили карту текстонов
Шаг 2: Фильтры формы (Shape Filters)
Для каждого
Моделирование формы
Шаг 1: получили карту текстонов
Шаг 2: Фильтры формы (Shape Filters)
Для каждого

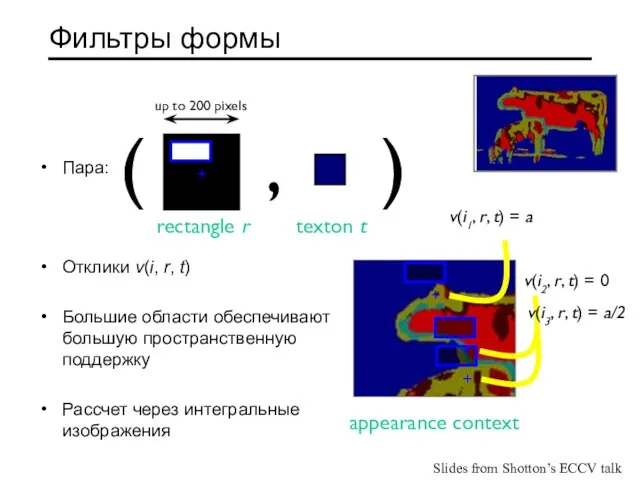
Слайд 27Фильтры формы
Пара:
Отклики v(i, r, t)
Большие области обеспечивают большую пространственную поддержку
Рассчет через интегральные
Фильтры формы
Пара:
Отклики v(i, r, t)
Большие области обеспечивают большую пространственную поддержку
Рассчет через интегральные
Слайд 28feature response image
v(i, r1, t1)
feature response image
v(i, r2, t2)
Форма задается положением текстонов
texton
feature response image
v(i, r1, t1)
feature response image
v(i, r2, t2)
Форма задается положением текстонов
texton
Слайд 29summed response images
v(i, r1, t1) + v(i, r2, t2)
Форма задается положением текстонов
(
,
)
(r1,
summed response images
v(i, r1, t1) + v(i, r2, t2)
Форма задается положением текстонов
(
,
)
(r1,

Слайд 30Обучение
Используется бустинг
Обычный бустинг
Для каждого пикселя
Для каждой возможной маски
Для каждого текстона
Считаем признак
Ускоренная версия
Для
Обучение
Используется бустинг
Обычный бустинг
Для каждого пикселя
Для каждой возможной маски
Для каждого текстона
Считаем признак
Ускоренная версия
Для
Слайд 31Первый результат
Только форма и текстура: 69.6%
shape-texture
Точность
попиксельной
сегментации
Slides from Shotton’s ECCV talk
Первый результат
Только форма и текстура: 69.6%
shape-texture
Точность
попиксельной
сегментации
Slides from Shotton’s ECCV talk
Слайд 32Уточняем разметку
Добавляем границы
Потенциал границ
Используем попарные потенциалы для определения и подчеркивания границ
Идея:
Если метки
Уточняем разметку
Добавляем границы
Потенциал границ
Используем попарные потенциалы для определения и подчеркивания границ
Идея:
Если метки

Слайд 33Точность
Форма-текстура: 69.6%
+ границы: 70.3%
shape-texture
+ edge
Точность
Попиксельной
сегментации
Slides from Shotton’s ECCV talk
Точность
Форма-текстура: 69.6%
+ границы: 70.3%
shape-texture
+ edge
Точность
Попиксельной
сегментации
Slides from Shotton’s ECCV talk
Слайд 34Положение объектов
Положение
Нормализуем координаты по всем изображениям
Посчитываем частоту появления объектов в данной точке
Положение объектов
Положение
Нормализуем координаты по всем изображениям
Посчитываем частоту появления объектов в данной точке

Слайд 35Моделирование цвета
Цвет
Обучаем модель цвета только по изображению
Идея
Используем классификацию по другим признакам как
Моделирование цвета
Цвет
Обучаем модель цвета только по изображению
Идея
Используем классификацию по другим признакам как

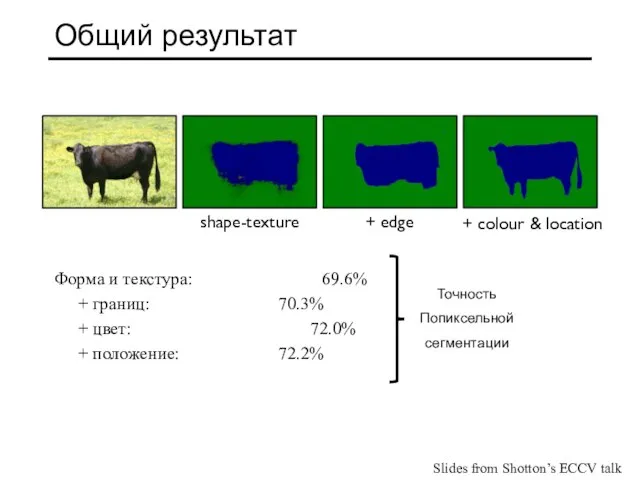
Слайд 36Общий результат
Форма и текстура: 69.6%
+ границ: 70.3%
+ цвет: 72.0%
+ положение: 72.2%
shape-texture
+ edge
+
Общий результат
Форма и текстура: 69.6%
+ границ: 70.3%
+ цвет: 72.0%
+ положение: 72.2%
shape-texture
+ edge
+
Слайд 37Результаты
Successes
Результаты
Successes

Слайд 38Ошибки
Ошибки

 Этапы консультирования
Этапы консультирования Presentation_of_Uzbekistan_RU-03-2022
Presentation_of_Uzbekistan_RU-03-2022 Война России в союзе с Австрией против Наполеона
Война России в союзе с Австрией против Наполеона Процесс запуска изменений. InterimConsult
Процесс запуска изменений. InterimConsult ТОПОГРАФИЧЕСКАЯ АНАТОМИЯ И ОПЕРАТИВНАЯ ХИРУРГИЯ ЛИЦА
ТОПОГРАФИЧЕСКАЯ АНАТОМИЯ И ОПЕРАТИВНАЯ ХИРУРГИЯ ЛИЦА  Тема 7-8 (7.1., 7.2) Понятие об инновационном проекте
Тема 7-8 (7.1., 7.2) Понятие об инновационном проекте Презентация на тему Презентация учителя-дефектолога
Презентация на тему Презентация учителя-дефектолога Рисуем мимозу
Рисуем мимозу СОВРЕМЕННЫЕ МЕТОДЫ СТОИМОСТНО-ОРИЕНТИРОВАННОГО УПРАВЛЕНИЯ ПРЕДПРИЯТИЕМ
СОВРЕМЕННЫЕ МЕТОДЫ СТОИМОСТНО-ОРИЕНТИРОВАННОГО УПРАВЛЕНИЯ ПРЕДПРИЯТИЕМ Что же есть человек?
Что же есть человек? Жизнь на Земле
Жизнь на Земле 2022-04-04_GIA-9_normat_dok
2022-04-04_GIA-9_normat_dok КОНДИЦИОНЕРЫ АВТОНОМНЫЕ ДЛЯ АТОМНЫХ ЭЛЕКТРОСТАНЦИЙ КСА – 6,5/25 1КСА – 6,5/25
КОНДИЦИОНЕРЫ АВТОНОМНЫЕ ДЛЯ АТОМНЫХ ЭЛЕКТРОСТАНЦИЙ КСА – 6,5/25 1КСА – 6,5/25 Презентация на тему Трансгенные продукты
Презентация на тему Трансгенные продукты ПРОГРАММА ИНФОРМАТИЗАЦИИ ОБРАЗОВАТЕЛЬНОГО УЧЕРЕЖДЕНИЯ
ПРОГРАММА ИНФОРМАТИЗАЦИИ ОБРАЗОВАТЕЛЬНОГО УЧЕРЕЖДЕНИЯ День защитника Отечества
День защитника Отечества Создать плакат реклам кампании
Создать плакат реклам кампании  Общие требования и правила оформления текстов. Лексические средства научного произведения
Общие требования и правила оформления текстов. Лексические средства научного произведения Мир психологии
Мир психологии Торговый Дом Дианна-Юг
Торговый Дом Дианна-Юг Взаимодействие органов исполнительной власти региона и органов местного самоуправления в сфере образовательной политики
Взаимодействие органов исполнительной власти региона и органов местного самоуправления в сфере образовательной политики Новогодний натюрморт
Новогодний натюрморт бойцовский клуб воин
бойцовский клуб воин Растения, которые мы едим
Растения, которые мы едим Что такое телеканал Успех? Это тематический канал платного ТВ с круглосуточным вещанием по всей России, странам СНГ и Балтии Наши з
Что такое телеканал Успех? Это тематический канал платного ТВ с круглосуточным вещанием по всей России, странам СНГ и Балтии Наши з Внеклассная массовая работа как средство эстетического воспитания учащихся
Внеклассная массовая работа как средство эстетического воспитания учащихся Презентация на тему История создания книги и библиотеки
Презентация на тему История создания книги и библиотеки Культура России XVII века
Культура России XVII века