- Винников Олег

Содержание
- 2. Почему NoSQL Особенности NoSQL решений Модели данных NoSQL Масштабирование MongoDB
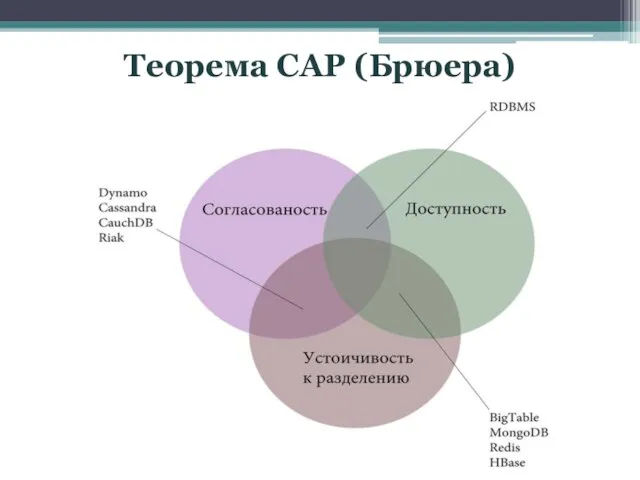
- 3. Теорема CAP (Брюера)
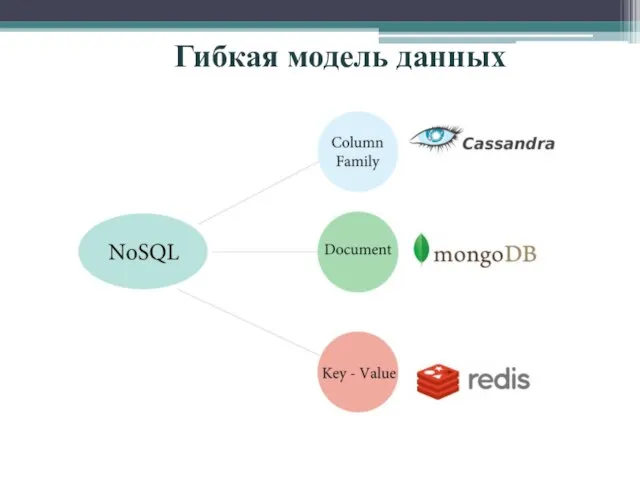
- 4. Гибкая модель данных
- 5. Twitter – генерирует 2 Петабайта/год Большие данные Google – обрабатывает 24 Петабайта/день Facebook – 1.5 Петабайта
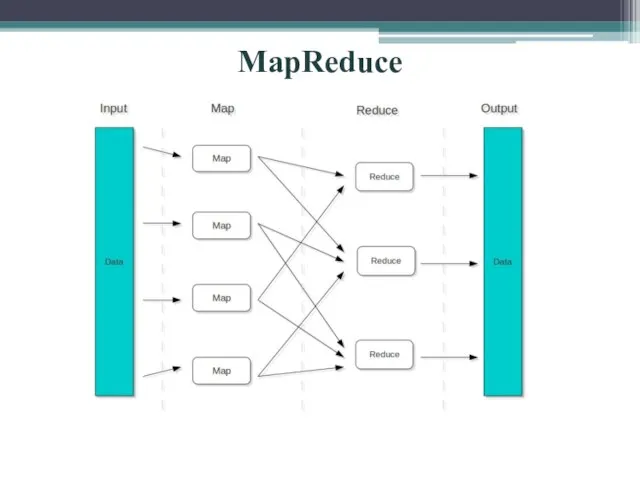
- 6. MapReduce
- 7. Счет, пожалуйста! Enterprise – 27.500$/процессор Parallel DW– 38.500$/процессор Parallel DW– 11 серверов/22 процессора Enterprise - 8.500$/сервер
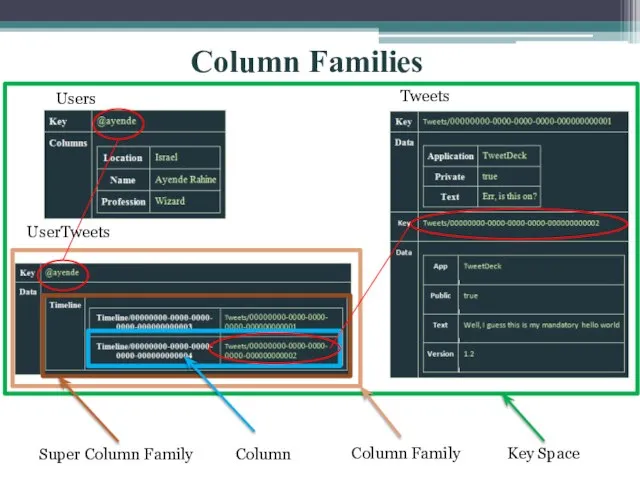
- 8. Column Families Super Column Family Column Column Family Key Space Users UserTweets Tweets
- 9. Асинхронная запись данных Отказоустойчивость при разделении Решения поддержки согласованности Слабая согласованность
- 10. Key – Value Databases Простейщая структура данных Низкие задержки Виртуальная память = хранилище
- 11. Типы : Строки, Списки, Хэши Собственная виртуальная подсистема Устойчивость
- 12. Репликация Redis Клиент Мастер Слейв Слейв Чтение Слейв Слейв Запись Чтение Чтение
- 13. Документы (BSON), Коллекции Отображение файлов в память Индексы (внутренние, по массиву) Агрегация (MapReduce)
- 14. Искусство масштабирования MongoDB
- 15. Сильная согласованность Клиент Слейв Слейв Запись Чтение Мастер Мастер Слейв
- 16. Слабая согласованность Клиент Мастер Слейв Слейв Запись Чтение Чтение Чтение
- 17. Шардинг – быстрый старт 1. Запустить сервер с метаданными и роутер 2. Включить шардинг 4. Добавлять
- 18. Шардинг и репликация
- 20. Скачать презентацию

Слайд 3Теорема CAP (Брюера)
Теорема CAP (Брюера)
Слайд 4Гибкая модель данных
Гибкая модель данных
Слайд 5Twitter – генерирует 2 Петабайта/год
Большие данные
Google – обрабатывает 24 Петабайта/день
Facebook – 1.5
Twitter – генерирует 2 Петабайта/год
Большие данные
Google – обрабатывает 24 Петабайта/день
Facebook – 1.5

Слайд 6MapReduce
MapReduce
Слайд 7Счет, пожалуйста!
Enterprise – 27.500$/процессор
Parallel DW– 38.500$/процессор
Parallel DW– 11 серверов/22 процессора
Enterprise - 8.500$/сервер
Счет, пожалуйста!
Enterprise – 27.500$/процессор
Parallel DW– 38.500$/процессор
Parallel DW– 11 серверов/22 процессора
Enterprise - 8.500$/сервер

Слайд 8Column Families
Super Column Family
Column
Column Family
Key Space
Users
UserTweets
Tweets
Column Families
Super Column Family
Column
Column Family
Key Space
Users
UserTweets
Tweets
Слайд 9Асинхронная запись данных
Отказоустойчивость при разделении
Решения поддержки согласованности
Слабая согласованность
Асинхронная запись данных
Отказоустойчивость при разделении
Решения поддержки согласованности
Слабая согласованность

Слайд 10Key – Value Databases
Простейщая структура данных
Низкие задержки
Виртуальная память = хранилище
Key – Value Databases
Простейщая структура данных
Низкие задержки
Виртуальная память = хранилище

Слайд 11Типы : Строки, Списки, Хэши
Собственная виртуальная подсистема
Устойчивость
Типы : Строки, Списки, Хэши
Собственная виртуальная подсистема
Устойчивость

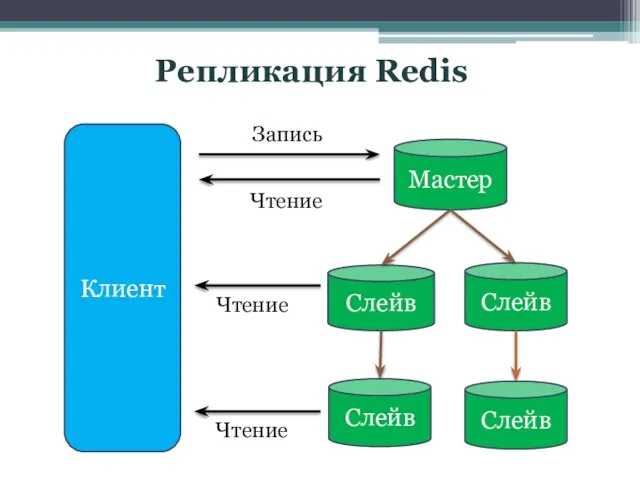
Слайд 12Репликация Redis
Клиент
Мастер
Слейв
Слейв
Чтение
Слейв
Слейв
Запись
Чтение
Чтение
Репликация Redis
Клиент
Мастер
Слейв
Слейв
Чтение
Слейв
Слейв
Запись
Чтение
Чтение
Слайд 13Документы (BSON), Коллекции
Отображение файлов в память
Индексы (внутренние, по массиву)
Агрегация (MapReduce)
Документы (BSON), Коллекции
Отображение файлов в память
Индексы (внутренние, по массиву)
Агрегация (MapReduce)

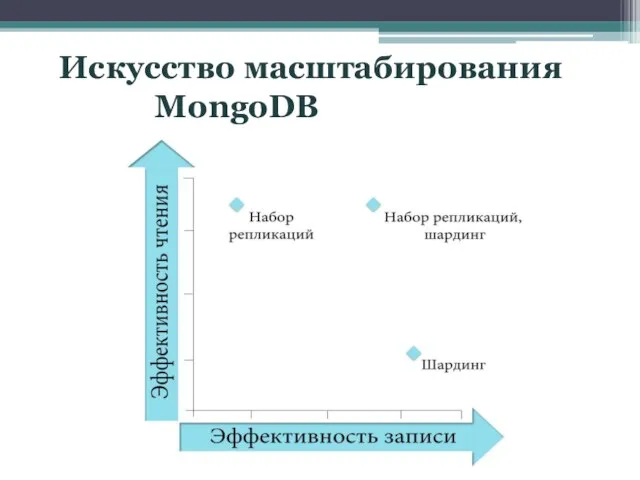
Слайд 14Искусство масштабирования
MongoDB
Искусство масштабирования
MongoDB
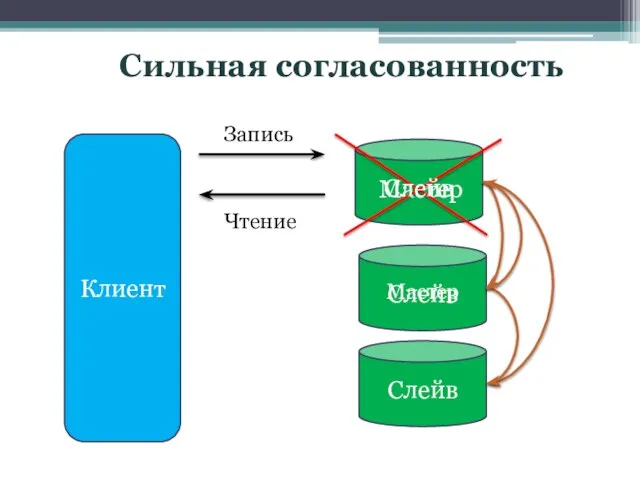
Слайд 15Сильная согласованность
Клиент
Слейв
Слейв
Запись
Чтение
Мастер
Мастер
Слейв
Сильная согласованность
Клиент
Слейв
Слейв
Запись
Чтение
Мастер
Мастер
Слейв
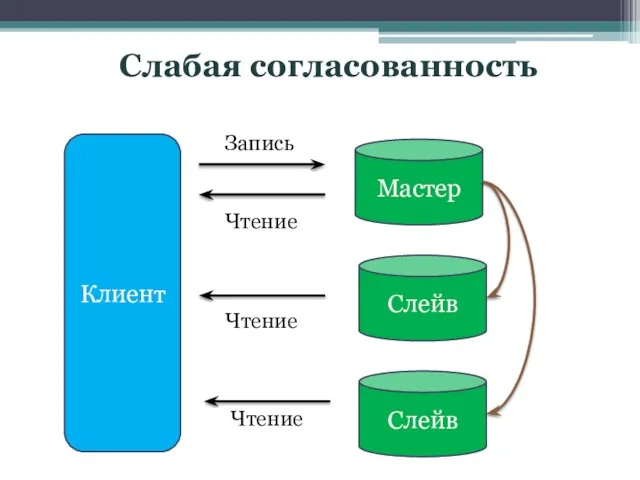
Слайд 16Слабая согласованность
Клиент
Мастер
Слейв
Слейв
Запись
Чтение
Чтение
Чтение
Слабая согласованность
Клиент
Мастер
Слейв
Слейв
Запись
Чтение
Чтение
Чтение
Слайд 17Шардинг – быстрый старт
1. Запустить сервер с метаданными и роутер
2. Включить
Шардинг – быстрый старт
1. Запустить сервер с метаданными и роутер
2. Включить

Слайд 18Шардинг и репликация
Шардинг и репликация
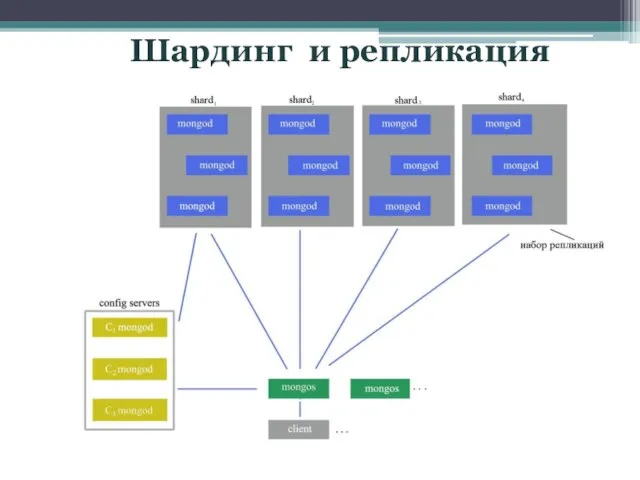
 Модульная структурасистемы ITAS
Модульная структурасистемы ITAS Инвестор, новый уровень
Инвестор, новый уровень Разработка и изготовление ансамбля коллекции женской одежды Butterfly
Разработка и изготовление ансамбля коллекции женской одежды Butterfly Илья Муромец и Соловей-разбойник
Илья Муромец и Соловей-разбойник Времена года. Лабораторная работа №5
Времена года. Лабораторная работа №5 «СОРОК МГНОВЕНИЙ НАЕДИНЕ С КОРНЕМ СТЕПЕНИ n»
«СОРОК МГНОВЕНИЙ НАЕДИНЕ С КОРНЕМ СТЕПЕНИ n» «Регион 74 в составе Российской Федерации».
«Регион 74 в составе Российской Федерации». Правовая информация для несовершеннолетних и их родителей
Правовая информация для несовершеннолетних и их родителей Дальневосточная пожарно-спасательная академия
Дальневосточная пожарно-спасательная академия Воспитательный потенциал современного образования:вызов родительской общественности
Воспитательный потенциал современного образования:вызов родительской общественности СТРЕССОВЫЕ СИТУАЦИИ НА РАБОЧЕМ МЕСТЕ
СТРЕССОВЫЕ СИТУАЦИИ НА РАБОЧЕМ МЕСТЕ Винсент Ван Гог. Подсолнухи
Винсент Ван Гог. Подсолнухи Аккумуляторная мотопила stihl gta 26
Аккумуляторная мотопила stihl gta 26 Китай
Китай Об использовании новых организационных форм медицинского обеспечения и оценки результатов новой системы оплаты труда
Об использовании новых организационных форм медицинского обеспечения и оценки результатов новой системы оплаты труда Татарское декоративно-прикладное искусство
Татарское декоративно-прикладное искусство Буквы Ч,ч, обозначающие звук [ч’]
Буквы Ч,ч, обозначающие звук [ч’] Разрезы в аксонометрических проекциях
Разрезы в аксонометрических проекциях Чему учил китайский мудрец Конфуций
Чему учил китайский мудрец Конфуций Порядок обращения за страховой пенсией по случаю потери кормильца
Порядок обращения за страховой пенсией по случаю потери кормильца Презентация на тему Шолохов «Донские рассказы»
Презентация на тему Шолохов «Донские рассказы» 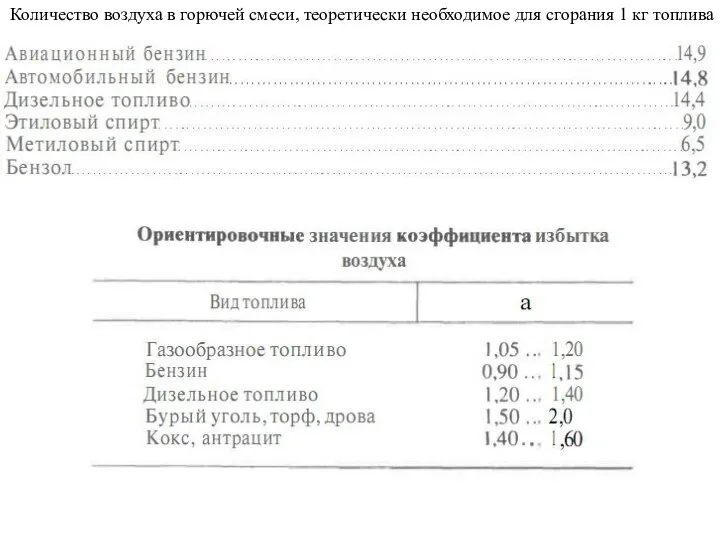 Сгорание топлива. Октановое число
Сгорание топлива. Октановое число Налоговый потенциал
Налоговый потенциал Влияние плавания на здоровье человека
Влияние плавания на здоровье человека Топочные устройства ПК
Топочные устройства ПК Иллюстрационный материал к реферату на тему: Эмпирическая школа управления
Иллюстрационный материал к реферату на тему: Эмпирическая школа управления Can you swim?
Can you swim? МОДЕЛИ УПРАВЛЕНИЯ ЗАПАСАМИ МОДЕЛИ УПРАВЛЕНИЯ ЗАПАСАМИ
МОДЕЛИ УПРАВЛЕНИЯ ЗАПАСАМИ МОДЕЛИ УПРАВЛЕНИЯ ЗАПАСАМИ