- Ймовірнісне моделювання. Метод статистичних випробувань

Содержание
- 2. Суть методу полягає в тому, що замість опису випадкових явищ аналітичними залежностями проводиться розіграш випадкового явища
- 4. Вирішимо цю задачу методом статистичних випробувань. Процедуру розіграшу реалізуємо підкиданням одночасно чотирьох монет. Якщо монета падає
- 5. Приклад 2. Нехай є деяка ціль, на яку бомбардувальники скидають n бомб. Кожна бомба вражає область
- 6. Накладемо координатну сітку на всю можливу область попадання бомб. Розіграємо n точок - координат попадання бомб.
- 8. Алгоритм методу статистичних випробувань такий: 1. Визначити, що собою являтиме випробування або розіграш. 2. Визначити, яке
- 9. До недоліків методу можна віднести необхідність проведення великої кількості випробувань, щоб отримати результат з заданою точністю.
- 10. Для ефективного розіграшу випадкових величин використовують генератори випадкових чисел. Такі генератори будуються апаратними та програмними методами.
- 11. Один з найбільш поширених способів - використання шумів електронних пристроїв. Якщо на підсилювач не подавати ніякий
- 12. Найбільш поширеними на практиці є програмні генератори. Вони повинні відповідати таким вимогам: генерувати статистично незалежні випадкові
- 13. Лінійні конгруентні генератори. У більшості сучасних програмних генераторів використовується властивість конгруентності, яке полягає в тому, що
- 14. Зазвичай використовується лінійний мультиплікативний конгруентний метод, рекурентне співвідношення для якого має вигляд де a та m
- 15. Одержані за формулою значення Хi належать діапазону 0≤ Хi ≤ m-1 і мають рівномірний дискретний розподіл.
- 16. У мові GPSS World використовується мультиплікативний конгруентний алгоритм Лемера з максимальним періодом, який генерує 2147483647 унікальних
- 17. Перевірка послідовностей випадкових чисел. Статистичні властивості всіх послідовностей випадкових чисел потрібно перевіряти. Для цього використовують критерії.
- 18. Моделювання дискретних випадкових величин. Моделювання подій. Нехай необхідно змоделювати появу деякої події А, ймовірність настання якої
- 19. Дійсно, якщо f(r) – функція густини рівномірно розподіленої випадкової величини r, то Даний метод використовується в
- 20. Моделювання групи несумісних подій. Нехай є група несумісних подій, А1, А2, ..,. Аk. Відомі ймовірності настання
- 21. Якщо одержане число потрапило в інтервал від до , то відбулася подія Аi. Таку процедуру називають
- 22. Моделювання умовної події. Моделювання умовної події А, яке відбувається за умови, що настає подія В з
- 23. Моделювання випадкової дискретної величини. Моделювання випадкової дискретної величини виконується аналогічно моделюванню групи несумісних подій. Дискретна випадкова
- 24. Геометричний розподіл. Для моделювання випадкової величини Х з геометричним розподілом необхідно задати таблицю її значень та
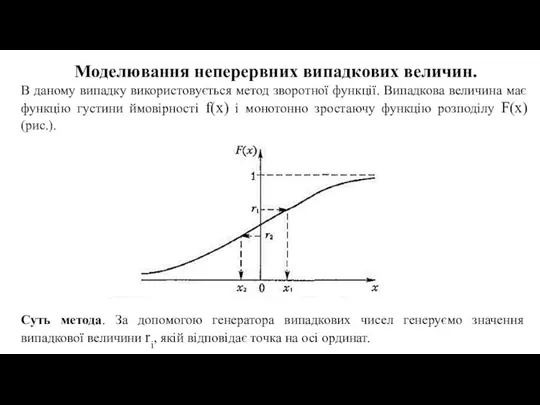
- 27. Моделювання неперервних випадкових величин. В даному випадку використовується метод зворотної функції. Випадкова величина має функцію густини
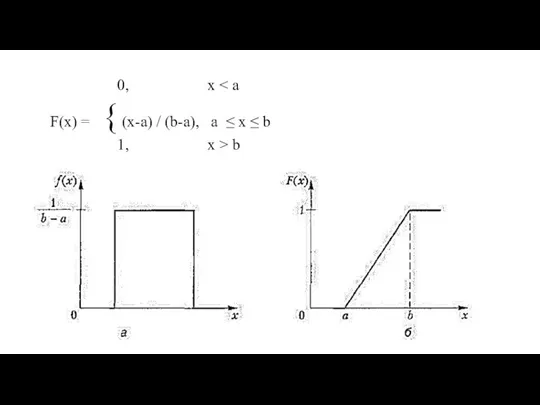
- 30. 0, x F(x) = { (x-a) / (b-a), a ≤ x ≤ b 1, x >
- 32. У мові GPSS такий розподіл часто використовується в блоках Advance для моделювання затримки проходження інформації або
- 35. Пуассонівський потік. Розглянемо моделювання пуассонівского потоку з інтенсивністю λ, основна властивість якого полягає в тому, що
- 36. Для пуассонівского потоку інтервали часу між надходженнями двох сусідніх вимог мають експонентний закон розподілу. Тому для
- 37. де tj – j-й проміжок часу між надходженнями двох сусідніх вимог, - середнє значення проміжку часу
- 38. Нормальний розподіл. Випадкова величина Х має нормальний розподіл (розподіл Гауса), якщо її густина розподілу ймовірностей описується
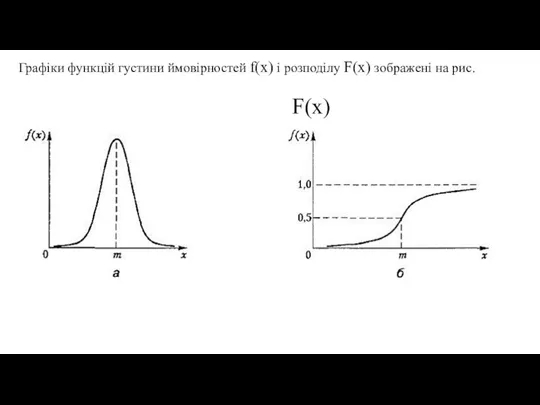
- 39. Графіки функцій густини ймовірностей f(x) і розподілу F(x) зображені на рис. F(x)
- 40. Збір статистичних даних для отримання оцінок характеристик випадкових величин. Основними елементами, з сукупності яких складається імовірнісна
- 41. - ймовірності настання деякої події; - математичного очікування випадкової величини; - дисперсії випадкової величини; - коефіцієнтів
- 42. Для оцінки математичного очікування випадкової величини використовується середнє значення де хi – i-а реалізація випадкової величини.
- 43. Безпосередньо використовувати ці формули для обчислення дисперсії складно, оскільки середнє значення змінюється в міру накопичення хi,
- 44. Для випадкових величин ξ та η з можливими значеннями хk, yk оцінка корреляційного момента визначається так:
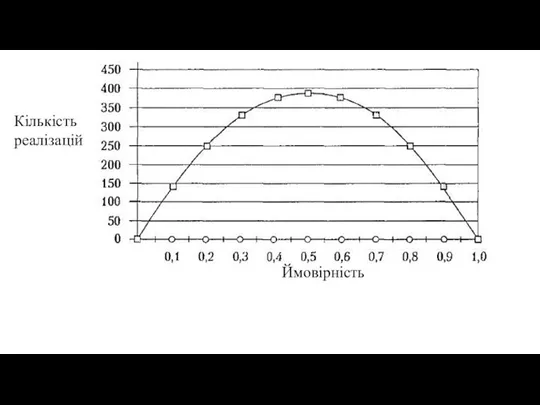
- 45. Визначення кількості реалізацій Точність оцінювання параметрів системи, які отримують під час обробки результатів моделювання, залежить від
- 46. Статистична оцінка також є випадковою величиной, тому вона буде відрізнятися від а, тобто |a - |
- 47. Оцінка ймовірності. Припустимо, що метою моделювання є оцінка ймовірності настання деякої події А, яка визначає стан
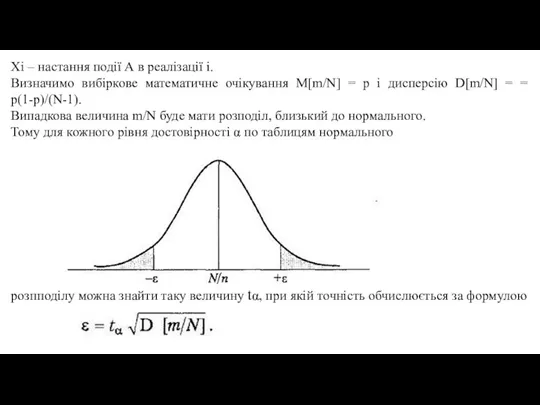
- 48. Xi – настання події А в реалізації i. Визначимо вибіркове математичне очікування M[m/N] = p і
- 49. Якщо α = 0.95, то tα = 1.96, а якщо α = 0.003, то tα =
- 50. З останньої формули видно, що при p = 1 або p = 0, кількість реалізацій, які
- 51. Кількість реалізацій Ймовірність
- 53. Скачать презентацию


Слайд 4Вирішимо цю задачу методом статистичних випробувань.
Процедуру розіграшу реалізуємо підкиданням одночасно чотирьох
Вирішимо цю задачу методом статистичних випробувань.
Процедуру розіграшу реалізуємо підкиданням одночасно чотирьох

Слайд 5Приклад 2. Нехай є деяка ціль, на яку бомбардувальники скидають n бомб.
Приклад 2. Нехай є деяка ціль, на яку бомбардувальники скидають n бомб.

Слайд 6Накладемо координатну сітку на всю можливу область попадання бомб.
Розіграємо n точок
Накладемо координатну сітку на всю можливу область попадання бомб.
Розіграємо n точок


Слайд 8Алгоритм методу статистичних випробувань такий:
1. Визначити, що собою являтиме випробування або розіграш.
2.
Алгоритм методу статистичних випробувань такий:
1. Визначити, що собою являтиме випробування або розіграш.
2.

Слайд 9До недоліків методу можна віднести необхідність проведення великої кількості випробувань, щоб отримати
До недоліків методу можна віднести необхідність проведення великої кількості випробувань, щоб отримати

Слайд 10Для ефективного розіграшу випадкових величин використовують генератори випадкових чисел.
Такі генератори будуються
Для ефективного розіграшу випадкових величин використовують генератори випадкових чисел.
Такі генератори будуються

Слайд 11Один з найбільш поширених способів - використання шумів електронних пристроїв.
Якщо на
Один з найбільш поширених способів - використання шумів електронних пристроїв.
Якщо на

Слайд 12Найбільш поширеними на практиці є програмні генератори.
Вони повинні відповідати таким вимогам:
генерувати
Найбільш поширеними на практиці є програмні генератори.
Вони повинні відповідати таким вимогам:
генерувати

Слайд 13Лінійні конгруентні генератори.
У більшості сучасних програмних генераторів використовується властивість конгруентності, яке полягає
Лінійні конгруентні генератори.
У більшості сучасних програмних генераторів використовується властивість конгруентності, яке полягає

Слайд 14Зазвичай використовується лінійний мультиплікативний конгруентний метод, рекурентне співвідношення для якого має вигляд
де
Зазвичай використовується лінійний мультиплікативний конгруентний метод, рекурентне співвідношення для якого має вигляд
де

Слайд 15Одержані за формулою значення Хi належать діапазону 0≤ Хi ≤ m-1 і
Одержані за формулою значення Хi належать діапазону 0≤ Хi ≤ m-1 і

Слайд 16У мові GPSS World використовується мультиплікативний конгруентний алгоритм Лемера з максимальним періодом,
У мові GPSS World використовується мультиплікативний конгруентний алгоритм Лемера з максимальним періодом,

Слайд 17Перевірка послідовностей випадкових чисел.
Статистичні властивості всіх послідовностей випадкових чисел потрібно перевіряти.
Для
Перевірка послідовностей випадкових чисел.
Статистичні властивості всіх послідовностей випадкових чисел потрібно перевіряти.
Для

Слайд 18Моделювання дискретних випадкових величин.
Моделювання подій. Нехай необхідно змоделювати появу деякої події А,
Моделювання дискретних випадкових величин.
Моделювання подій. Нехай необхідно змоделювати появу деякої події А,

Слайд 19Дійсно, якщо f(r) – функція густини рівномірно розподіленої випадкової величини r, то

Слайд 20Моделювання групи несумісних подій.
Нехай є група несумісних подій, А1, А2, ..,.
Моделювання групи несумісних подій.
Нехай є група несумісних подій, А1, А2, ..,.

Слайд 21
Якщо одержане число потрапило в інтервал від до , то відбулася подія
Аi.
Якщо одержане число потрапило в інтервал від до , то відбулася подія
Аi.

Слайд 22Моделювання умовної події.
Моделювання умовної події А, яке відбувається за умови, що
Моделювання умовної події.
Моделювання умовної події А, яке відбувається за умови, що

Слайд 23Моделювання випадкової дискретної величини.
Моделювання випадкової дискретної величини виконується аналогічно моделюванню групи несумісних
Моделювання випадкової дискретної величини.
Моделювання випадкової дискретної величини виконується аналогічно моделюванню групи несумісних

Слайд 24Геометричний розподіл.
Для моделювання випадкової величини Х з геометричним розподілом необхідно задати таблицю
Геометричний розподіл.
Для моделювання випадкової величини Х з геометричним розподілом необхідно задати таблицю



Слайд 27Моделювання неперервних випадкових величин.
В даному випадку використовується метод зворотної функції. Випадкова
Моделювання неперервних випадкових величин.
В даному випадку використовується метод зворотної функції. Випадкова


Слайд 30 0, x < a
F(x) = { (x-a) / (b-a), a
0, x < a
F(x) = { (x-a) / (b-a), a

Слайд 32У мові GPSS такий розподіл часто використовується в блоках Advance для моделювання
У мові GPSS такий розподіл часто використовується в блоках Advance для моделювання



Слайд 35Пуассонівський потік.
Розглянемо моделювання пуассонівского потоку з інтенсивністю λ, основна властивість якого полягає
Пуассонівський потік.
Розглянемо моделювання пуассонівского потоку з інтенсивністю λ, основна властивість якого полягає

Слайд 36Для пуассонівского потоку інтервали часу між надходженнями двох сусідніх вимог мають експонентний
Для пуассонівского потоку інтервали часу між надходженнями двох сусідніх вимог мають експонентний

Слайд 37де tj – j-й проміжок часу між надходженнями двох сусідніх вимог,
де tj – j-й проміжок часу між надходженнями двох сусідніх вимог,

Слайд 38Нормальний розподіл.
Випадкова величина Х має нормальний розподіл (розподіл Гауса), якщо її густина
Нормальний розподіл.
Випадкова величина Х має нормальний розподіл (розподіл Гауса), якщо її густина

Слайд 39Графіки функцій густини ймовірностей f(x) і розподілу F(x) зображені на рис.
F(x)
Графіки функцій густини ймовірностей f(x) і розподілу F(x) зображені на рис.
F(x)
Слайд 40Збір статистичних даних для отримання оцінок характеристик випадкових величин.
Основними елементами, з сукупності
Збір статистичних даних для отримання оцінок характеристик випадкових величин.
Основними елементами, з сукупності

Слайд 41- ймовірності настання деякої події;
- математичного очікування випадкової величини;
- дисперсії випадкової величини;
-
- ймовірності настання деякої події;
- математичного очікування випадкової величини;
- дисперсії випадкової величини;
-

Слайд 42Для оцінки математичного очікування випадкової величини використовується середнє значення
де хi – i-а реалізація випадкової
Для оцінки математичного очікування випадкової величини використовується середнє значення
де хi – i-а реалізація випадкової

Слайд 43Безпосередньо використовувати ці формули для обчислення дисперсії складно, оскільки середнє значення змінюється
Безпосередньо використовувати ці формули для обчислення дисперсії складно, оскільки середнє значення змінюється

Слайд 44Для випадкових величин ξ та η з можливими значеннями хk, yk оцінка

Слайд 45Визначення кількості реалізацій
Точність оцінювання параметрів системи, які отримують під час обробки результатів
Визначення кількості реалізацій
Точність оцінювання параметрів системи, які отримують під час обробки результатів

Слайд 46Статистична оцінка також є випадковою величиной, тому вона буде відрізнятися від а,
Статистична оцінка також є випадковою величиной, тому вона буде відрізнятися від а,

Слайд 47Оцінка ймовірності.
Припустимо, що метою моделювання є оцінка ймовірності настання деякої події А,
Оцінка ймовірності.
Припустимо, що метою моделювання є оцінка ймовірності настання деякої події А,

Слайд 48Xi – настання події А в реалізації i.
Визначимо вибіркове математичне очікування M[m/N]
Xi – настання події А в реалізації i.
Визначимо вибіркове математичне очікування M[m/N]
Слайд 49Якщо α = 0.95, то tα = 1.96, а якщо α =
Якщо α = 0.95, то tα = 1.96, а якщо α =

Слайд 50З останньої формули видно, що при p = 1 або p =
З останньої формули видно, що при p = 1 або p =

Слайд 51
Кількість
реалізацій
Ймовірність
Кількість
реалізацій
Ймовірність
 Основные вопросы и задачи формирования электронного правительства в субъектах Российской Федерации
Основные вопросы и задачи формирования электронного правительства в субъектах Российской Федерации Ціннісні орієнтації підлітка
Ціннісні орієнтації підлітка Подведение итогов реализации мероприятий базовыми школами в соответствии с РЦП
Подведение итогов реализации мероприятий базовыми школами в соответствии с РЦП Университетский лицей представляет
Университетский лицей представляет ОЛЕГ САМОЙЛОВ
ОЛЕГ САМОЙЛОВ Пейзажная лирика Ф.И.Тютчева
Пейзажная лирика Ф.И.Тютчева Экология в искусстве
Экология в искусстве Нашествие Персидских войск на Элладу (5 класс)
Нашествие Персидских войск на Элладу (5 класс) Физика и здоровье
Физика и здоровье Основы промышленной автоматизации
Основы промышленной автоматизации  MTV Upgrade. Статистика
MTV Upgrade. Статистика Взаимодействие детского сада и семьи в процессе социально-нравственного воспитания детей дошкольного возраста.
Взаимодействие детского сада и семьи в процессе социально-нравственного воспитания детей дошкольного возраста. Раскрой цельнокроеного платья
Раскрой цельнокроеного платья Урок – экспедиция в страну «Лексики и Фразеологии»
Урок – экспедиция в страну «Лексики и Фразеологии» Задания для 6 класса
Задания для 6 класса Бетон и железобетон
Бетон и железобетон 7 период развития соц.работы
7 период развития соц.работы Презентация на тему Атмосфера
Презентация на тему Атмосфера  Презентация на тему Живопись Голландии
Презентация на тему Живопись Голландии НОВЫЕ ПОСТУПЛЕНИЯ ЛИТЕРАТУРЫ
НОВЫЕ ПОСТУПЛЕНИЯ ЛИТЕРАТУРЫ ЛОГОПЕДИЧЕСКИЙ МАССАЖ ПРИ РАЗЛИЧНЫХ РЕЧЕВЫХ НАРУШЕНИЯХ
ЛОГОПЕДИЧЕСКИЙ МАССАЖ ПРИ РАЗЛИЧНЫХ РЕЧЕВЫХ НАРУШЕНИЯХ Как накормить акул пера
Как накормить акул пера Бамблби
Бамблби Профессиональная деятельность учителя русского языка и литературы МОУ «Средняя общеобразовательная школа №3 п.Советский» Мухино
Профессиональная деятельность учителя русского языка и литературы МОУ «Средняя общеобразовательная школа №3 п.Советский» Мухино Система профориентации и основные её направления
Система профориентации и основные её направления Презентация продукта
Презентация продукта Презентация на тему Ребенок и право
Презентация на тему Ребенок и право Закон радиоактивного распада
Закон радиоактивного распада