- Зачем знать алгоритмы

Содержание
- 2. Who is Mr. Aksenov?
- 4. честно листал все!
- 5. не прочитал ни одной :(
- 7. делал веб-сайты и веб-движок
- 9. делал игры и 3D движок
- 12. делаю поисковой движок
- 13. free open source search
- 14. free :(
- 16. что могу рассказать?
- 17. как устроены всякие движки
- 19. на пальцах, не по книжке! (см. “не читатель”)
- 20. про движок СУБД (любой)
- 21. Система Управления Базой Данных
- 22. данные – это таблицы. из строк
- 24. строки – нужно где-то хранить
- 27. это, кстати, данные – без индексов
- 28. добавляем PK, и брюки превращаются…
- 31. почему так? разные стратегии хранения строк
- 32. MyISAM – в порядке поступления (в конец файла)
- 33. InnoDB – хранит постранично, внутри странички – в порядке PK
- 34. (InnoDB, после добавления PK)
- 35. MyISAM – “обычное” хранение InnoDB – т.н. “кластерное”
- 36. умеем хранить – теперь нужно быстро искать!
- 37. SELECT * FROM users WHERE id=123
- 38. SELECT * FROM users WHERE lastname=‘Pupkin’
- 39. SELECT * FROM users WHERE lastname LIKE ‘Pu%’
- 40. SELECT * FROM goods WHERE MATCH(‘ipod’) ORDER BY price ASC
- 41. SELECT * FROM users WHERE sex=‘F’ AND age>=18 AND age
- 43. как выполнять запрос?
- 44. полный перебор? мееедленно
- 45. нас спасут…
- 47. индексы! алгоритмы уже спешат на помощь!
- 48. смысл любого вида индекса?
- 49. быстрый поиск по ключу(-ам)
- 55. видов индексов – тоже много
- 56. hash index
- 57. R-tree index
- 58. full-text index
- 59. индекс общего назначения – типично B-tree
- 60. поиск – по равенству, диапазону (чисел, строк, и т.п.)
- 61. дискует – страничками (хорошо!)
- 62. используется – всеми
- 67. используется несмотря ни на что!!!
- 68. как устроено?
- 69. (B-дерево; странички; масштаб 1:72)
- 70. два вида страничек
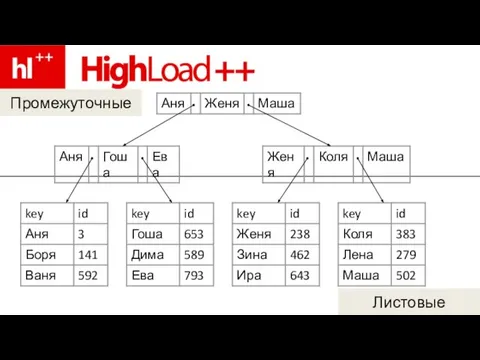
- 71. Промежуточные = ключи + указатели на другие странички { key1, ptr1, key2, ptr2, …, keyN }
- 72. Листовые = ключи + соотв-е им данные (eg. row_offset) { key1, data1, key2, data2, … }
- 73. Промежуточные Листовые
- 74. почему все используют этот ужас?!
- 75. во-1х – легко искать по ключу
- 76. пример – ищем Зину
- 83. ура – Зина нашлась!!!
- 84. хорошо – поиск работает…
- 85. …но он чё, всегда такой резкий?
- 87. – В жизни – под 1000 (а не 3) записей на страничку – Два уровня страничек
- 88. почему все используют этот ужас?!
- 89. во-2х – легко обновлять
- 90. странички обычно НЕ полны
- 91. вставляем…
- 92. вставляем…
- 93. вставляем… оп-па, некуда!!
- 94. создаем новую страничку
- 95. создаем новую страничку
- 96. …и суем “ее” в родителя
- 97. это все – тоже трогаем max 2-3 странички
- 99. B-tree Kung Fu!!!
- 100. вернемся к запросам?
- 101. SELECT * FROM users WHERE id=123 1. “Ищем Зину” (rowoffset по id=123) 2. seek(rowoffset) в файле
- 102. усложним – добавим условий
- 103. SELECT * FROM users WHERE sex=‘F’ AND age>=18 AND age
- 104. индекс “в лоб” по sex?
- 107. они ВСЕ подходят по условию ‘F’!
- 109. …и нам надо прочитать с диска (!) 5,000,000+ строк…
- 110. …и для каждой лично проверить паспорт и age>=18 and age
- 112. неселективный индекс – косяк и западло!
- 113. sex=‘F’ AND age>=18 AND age
- 114. но – вдруг это мужики?!
- 115. мужики нам не нужны!!!
- 116. либо опять читать ненужные строки (мужиков) – либо…
- 117. покрывающий (covering) индекс по обоим полям
- 119. список нужных строк – ясен сразу
- 120. чтений с диска – минимум скорости – максимум
- 121. бонус – сортировка по age
- 122. кстати, про сортировку…
- 123. SELECT * FROM users WHERE sex=‘F’ AND age>=18 AND age
- 124. как выполнять? есть варианты
- 126. налево – read_index(WHERE) + read_rows + sort_rows(ORDER)
- 127. индекс данные сортировка результат
- 128. read_index – мало и быстро
- 129. 10K*( 1+4+8 bytes ) = 130 KB 5-10 ms/seek, 50+ MB/s read
- 130. read_random_rows – медленно! 10K*5-10 ms/seek = 50-100 sec…
- 131. sort_rows – обычно быстро 10K*0.1-1 KB/row = 1-10 MB (in RAM)
- 132. мораль – все зло от random rows!
- 133. (еще от sort_rows, если их много)
- 135. … sex=‘F’ AND age>=18 AND age
- 136. направо – read_fat_index(WHERE) + sort_index(ORDER) + LIMIT + read_less_rows + sort_rows
- 137. нужен утолщенный INDEX ( sex, age, hotness )
- 138. вместе с поиском по sex, age – сразу узнаем hotness (+40 KB)
- 139. sort ( 10K * [ hotness, rowptr ] )
- 140. read_rows – почти не нужен (10 строк результата…)
- 141. sort_rows – вообще не нужен
- 142. PROFIT?
- 143. не панацея – даже в теории
- 144. INDEX ( sex, age, hotness ) WHERE sex=‘F’ ORDER BY hotness LIMIT 10
- 145. в теории – обработать 50% индекса затем – прочитать 10 строк (пф!)
- 146. INDEX ( sex, age, hotness ) 1M rows, ~20 MB, 50% = ~10 MB
- 147. INDEX ( sex, age, hotness ) WHERE sex=‘F’ AND hotness>0 ORDER BY age LIMIT 10
- 148. в теории – читаем индекс линейно – пока не заполним limit
- 149. что на практике?
- 150. welcome to real world
- 151. CREATE TABLE usertest ( id INTEGER PRIMARY KEY NOT NULL, sex ENUM ('m','f'), age INTEGER NOT
- 152. 500,000 записей 56 MB данных (.ibd файл) 32 MB innodb_buffer_pool age \in [18.. 80] hotness \in
- 153. mysql> explain select * from usertest where sex='f' and age>=18 and age
- 154. filesort – НЕ про временный файл filesort – про “сортировку строк”
- 155. Using where – проверка условия НЕ по индексу – ?!!
- 156. запрос проще, точно по индексу?
- 157. mysql> explain select * from usertest where sex='f' and age=18 order by hotness desc limit 10
- 158. проверим экспериментально!!!
- 159. mysql> select * from usertest where sex='f' and age>=18 and age select * from usertest where
- 160. причина?
- 161. mysql> explain select * from usertest where sex='f' and age>=18 and age
- 162. MySQL не умеет сортировать элементы индекса :(
- 163. сортировка “по индексу” – только если индекс гарантирует порядок
- 164. 1) в куске индекса sex=F, 18
- 165. 2) optimizer лажанул, 18
- 166. (теория говорит – можно лучше!)
- 167. проверяем дальше!
- 168. mysql> explain select * from usertest where sex='f' order by hotness desc limit 10 \G ...
- 169. и последний запрос
- 170. mysql> explain select * from usertest where sex='f' and hotness>0 order by age asc limit 10
- 171. итого
- 172. теория была оптимистична…
- 173. …реальность внесла коррективы.
- 174. не учли детали реализации
- 175. 1. нету “досортировки” индекса (MySQL specific)
- 176. 2. limit обрабатывается… так себе (MySQL specific)
- 177. 3. optimizer ошибается (везде и у всех)
- 178. про ошибки optimizer и спасительный full-scan
- 179. mysql> select * from usertest where sex='f' order by hotness desc limit 10; ... 10 rows
- 180. 10,000 x 10 ms = 100 sec 100,000 x 1KB / 50 M/s = 2 sec
- 181. мораль: random IO очень плохо (водка яд водка яд водка яд)
- 182. про “обработку” limit
- 183. теория – приоритетная очередь
- 186. технически – heap
- 188. или просто double buffer
- 191. ключевое свойство – в памяти храним только top-N
- 192. LIMIT 10 – надо хранить 10 строк
- 193. LIMIT 130,10 – надо 140
- 194. практика – MySQL vs. LIMIT
- 195. выбрать и отсортировать ВСЕ (*) * – всегда, когда индекс не гарантирует точный порядок
- 196. выбрать OK – избежать нельзя
- 198. сортировать все плохо…
- 200. лишний удар по CPU/RAM/IO :(
- 201. как убирать mysql сортировку?
- 202. строить более другие индексы
- 203. ставить более другой софт
- 204. умеет и “обычный” поиск!
- 205. трюки про WHERE вместо LIMIT (я не пробовал, но говорят, возможно)
- 206. …именно в таком порядке.
- 207. более практический пример?
- 208. импортируем дамп Wikipedia
- 209. XML дамп → 2 толстые таблицы хочется – а) одну б) тонкую!
- 210. INSERT INTO mycontent SELECT t.old_id, p.page_id, UNIX_TIMESTAMP(p.page_touched), p.page_len, p.page_title, COMPRESS(t.old_text) FROM text t, page p WHERE
- 211. mysql> EXPLAIN SELECT t.old_id, ... \G ********************** 1. row ********************** table: page type: ref key: name_title
- 212. что хотим? scan 15 GB text, join 0.5 GB page
- 213. почему не выходит? … FROM text t, page p WHERE t.old_id=p.page_latest
- 214. решение – index(page_latest)
- 215. еще пришлось STRAIGHT_JOIN (optimizer опять лажанул!)
- 216. результат – 40 минут, включая CREATE INDEX
- 218. так зачем же знать алгоритмы?
- 219. “did we learn something today?”
- 221. как устроено B-дерево
- 222. как работает индекс
- 223. как работают выборки
- 224. зачем нужны full-scans
- 225. как работает сортировка с LIMIT
- 226. чего можно добиться в идеале – в теории
- 227. …и как оно, бывает, не работает – на практике!
- 228. а толку?!
- 229. чего ждать от БД
- 230. чего не ждать
- 231. как и что тестировать
- 232. как объяснять потом результаты
- 234. в итоге – как заставлять таки работать
- 236. …БЫСТРО работать.
- 238. Скачать презентацию


Слайд 4честно листал все!
честно листал все!

Слайд 5не прочитал ни одной :(
не прочитал ни одной :(


Слайд 7делал веб-сайты и веб-движок
делал веб-сайты и веб-движок

Слайд 9делал игры и 3D движок
делал игры и 3D движок



Слайд 12делаю поисковой движок
делаю поисковой движок

Слайд 13free open source search
free open source search

Слайд 14<<
free :(
<<
free :(


Слайд 16что могу рассказать?
что могу рассказать?

Слайд 17как устроены всякие движки
как устроены всякие движки


Слайд 19на пальцах, не по книжке!
(см. “не читатель”)
на пальцах, не по книжке!
(см. “не читатель”)

Слайд 20про движок СУБД (любой)
про движок СУБД (любой)

Слайд 21Система Управления
Базой Данных
Система Управления
Базой Данных

Слайд 22данные – это таблицы. из строк
данные – это таблицы. из строк

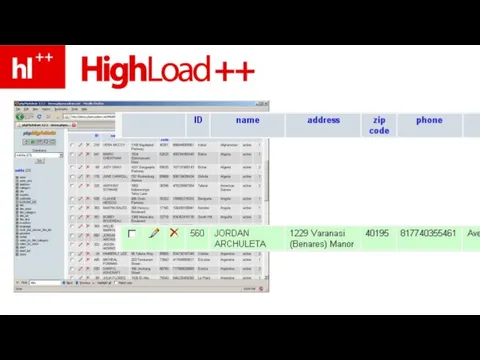
Слайд 24строки – нужно где-то хранить
строки – нужно где-то хранить

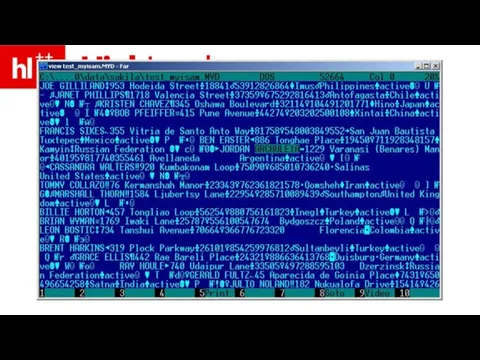
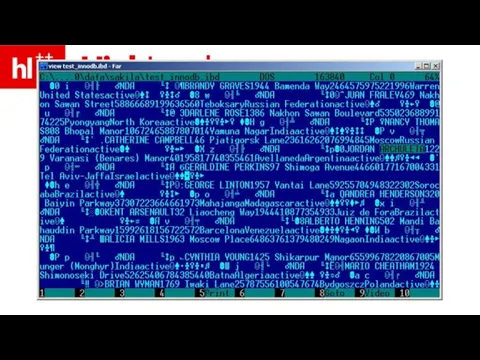
Слайд 27это, кстати, данные – без индексов
это, кстати, данные – без индексов

Слайд 28добавляем PK, и брюки превращаются…
добавляем PK, и брюки превращаются…

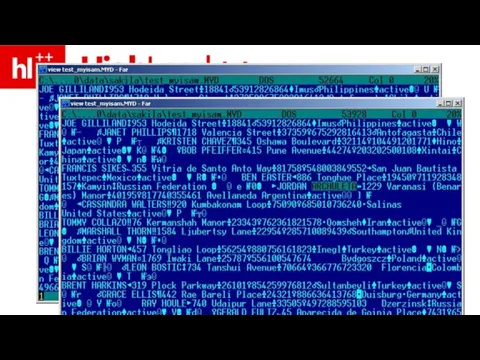
Слайд 31почему так?
разные стратегии хранения строк
почему так?
разные стратегии хранения строк

Слайд 32MyISAM – в порядке поступления
(в конец файла)
MyISAM – в порядке поступления
(в конец файла)

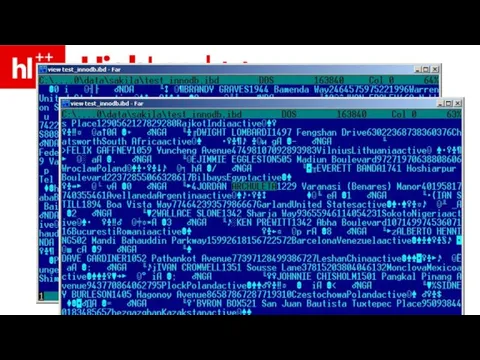
Слайд 33InnoDB – хранит постранично, внутри странички – в порядке PK
InnoDB – хранит постранично, внутри странички – в порядке PK

Слайд 34(InnoDB, после добавления PK)
(InnoDB, после добавления PK)

Слайд 35MyISAM – “обычное” хранение
InnoDB – т.н. “кластерное”
MyISAM – “обычное” хранение
InnoDB – т.н. “кластерное”

Слайд 36умеем хранить –
теперь нужно быстро искать!
умеем хранить –
теперь нужно быстро искать!

Слайд 37SELECT * FROM users WHERE
id=123
SELECT * FROM users WHERE
id=123

Слайд 38SELECT * FROM users WHERE
lastname=‘Pupkin’
SELECT * FROM users WHERE
lastname=‘Pupkin’

Слайд 39SELECT * FROM users WHERE
lastname LIKE ‘Pu%’
SELECT * FROM users WHERE
lastname LIKE ‘Pu%’

Слайд 40SELECT * FROM goods WHERE
MATCH(‘ipod’) ORDER BY price ASC
SELECT * FROM goods WHERE
MATCH(‘ipod’) ORDER BY price ASC

Слайд 41SELECT * FROM users WHERE
sex=‘F’ AND age>=18 AND age<=25
SELECT * FROM users WHERE
sex=‘F’ AND age>=18 AND age<=25


Слайд 43как выполнять запрос?
как выполнять запрос?

Слайд 44полный перебор? мееедленно
полный перебор? мееедленно

Слайд 45нас спасут…
нас спасут…


Слайд 47индексы!
алгоритмы уже спешат на помощь!
индексы!
алгоритмы уже спешат на помощь!

Слайд 48смысл любого вида индекса?
смысл любого вида индекса?

Слайд 49быстрый поиск по ключу(-ам)
быстрый поиск по ключу(-ам)






Слайд 55видов индексов – тоже много
видов индексов – тоже много

Слайд 56hash index
hash index

Слайд 57R-tree index
R-tree index

Слайд 58full-text index
full-text index

Слайд 59индекс общего назначения – типично B-tree
индекс общего назначения – типично B-tree

Слайд 60поиск – по равенству, диапазону
(чисел, строк, и т.п.)
поиск – по равенству, диапазону
(чисел, строк, и т.п.)

Слайд 61дискует – страничками
(хорошо!)
дискует – страничками
(хорошо!)

Слайд 62используется – всеми
используется – всеми





Слайд 67используется несмотря ни на что!!!
используется несмотря ни на что!!!

Слайд 68как устроено?
как устроено?

Слайд 69(B-дерево; странички; масштаб 1:72)
(B-дерево; странички; масштаб 1:72)

Слайд 70два вида страничек
два вида страничек

Слайд 71Промежуточные = ключи + указатели на другие странички
{ key1, ptr1, key2, ptr2,
Промежуточные = ключи + указатели на другие странички
{ key1, ptr1, key2, ptr2,

Слайд 72Листовые = ключи + соотв-е им данные (eg. row_offset)
{ key1, data1, key2,
Листовые = ключи + соотв-е им данные (eg. row_offset)
{ key1, data1, key2,

Слайд 73Промежуточные
Листовые
Промежуточные
Листовые
Слайд 74почему все используют этот ужас?!
почему все используют этот ужас?!

Слайд 75во-1х – легко искать по ключу
во-1х – легко искать по ключу

Слайд 76пример – ищем Зину
пример – ищем Зину

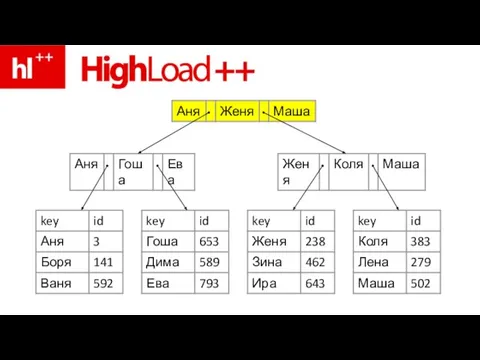
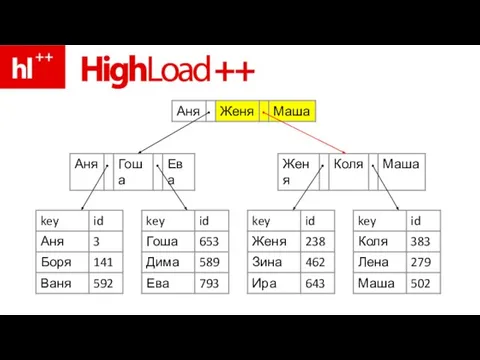
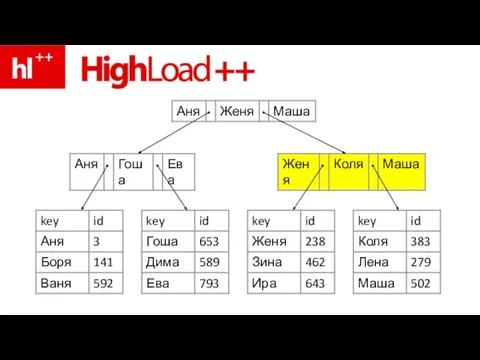
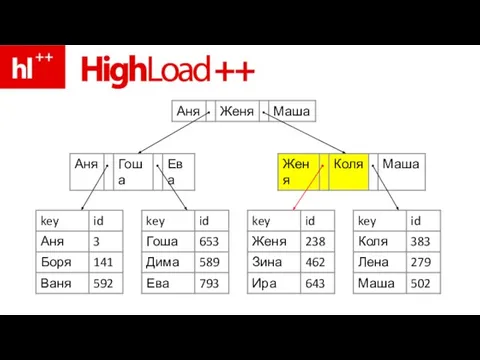
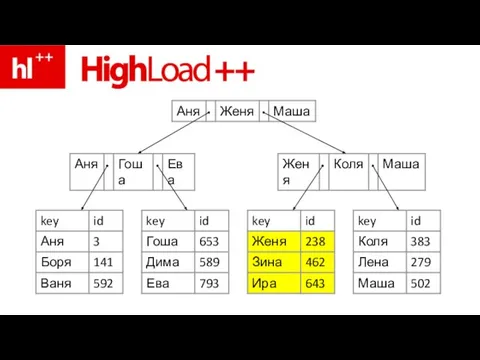

Слайд 83ура – Зина нашлась!!!
ура – Зина нашлась!!!

Слайд 84хорошо – поиск работает…
хорошо – поиск работает…

Слайд 85…но он чё, всегда такой резкий?
…но он чё, всегда такой резкий?


Слайд 87– В жизни – под 1000 (а не 3) записей на страничку
–
– В жизни – под 1000 (а не 3) записей на страничку –

Слайд 88почему все используют этот ужас?!
почему все используют этот ужас?!

Слайд 89во-2х – легко обновлять
во-2х – легко обновлять

Слайд 90странички обычно НЕ полны
странички обычно НЕ полны

Слайд 91вставляем…
вставляем…

Слайд 92вставляем…
вставляем…

Слайд 93вставляем… оп-па, некуда!!
вставляем… оп-па, некуда!!

Слайд 94создаем новую страничку
создаем новую страничку

Слайд 95создаем новую страничку
создаем новую страничку

Слайд 96…и суем “ее” в родителя
…и суем “ее” в родителя

Слайд 97это все – тоже трогаем max 2-3 странички
это все – тоже трогаем max 2-3 странички


Слайд 99B-tree Kung Fu!!!
B-tree Kung Fu!!!

Слайд 100вернемся к запросам?
вернемся к запросам?

Слайд 101SELECT * FROM users WHERE id=123
1. “Ищем Зину” (rowoffset по id=123)
2. seek(rowoffset)
SELECT * FROM users WHERE id=123
1. “Ищем Зину” (rowoffset по id=123)
2. seek(rowoffset)

Слайд 102усложним – добавим условий
усложним – добавим условий

Слайд 103SELECT * FROM users WHERE
sex=‘F’ AND age>=18 AND age<=25
SELECT * FROM users WHERE
sex=‘F’ AND age>=18 AND age<=25

Слайд 104индекс “в лоб” по sex?
индекс “в лоб” по sex?



Слайд 107они ВСЕ подходят по условию ‘F’!
они ВСЕ подходят по условию ‘F’!


Слайд 109…и нам надо прочитать с диска (!) 5,000,000+ строк…
…и нам надо прочитать с диска (!) 5,000,000+ строк…

Слайд 110…и для каждой лично проверить паспорт и age>=18 and age<=25?!
…и для каждой лично проверить паспорт и age>=18 and age<=25?!


Слайд 112неселективный индекс –
косяк и западло!
неселективный индекс –
косяк и западло!

Слайд 113sex=‘F’ AND age>=18 AND age<=25
индекс “по лбу” по age?
sex=‘F’ AND age>=18 AND age<=25
индекс “по лбу” по age?
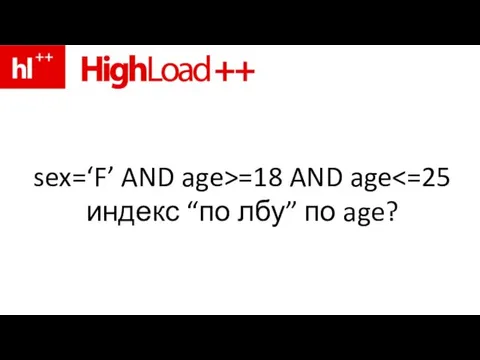
Слайд 114но – вдруг это мужики?!
но – вдруг это мужики?!
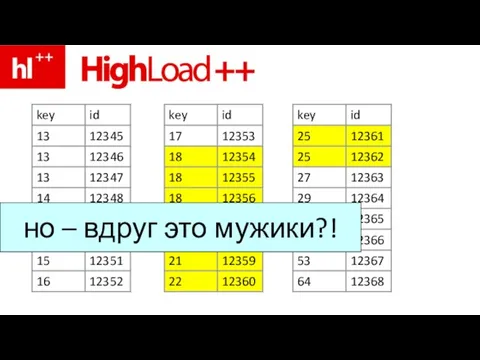
Слайд 115мужики нам не нужны!!!
мужики нам не нужны!!!

Слайд 116либо опять читать ненужные строки (мужиков) – либо…
либо опять читать ненужные строки (мужиков) – либо…

Слайд 117покрывающий (covering) индекс
по обоим полям
покрывающий (covering) индекс
по обоим полям

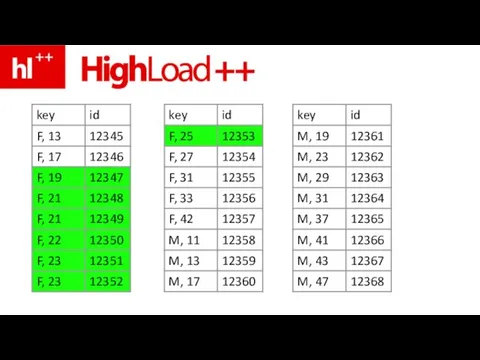
Слайд 119список нужных строк – ясен сразу
список нужных строк – ясен сразу

Слайд 120чтений с диска – минимум
скорости – максимум
чтений с диска – минимум
скорости – максимум

Слайд 121бонус – сортировка по age
бонус – сортировка по age

Слайд 122кстати, про сортировку…
кстати, про сортировку…

Слайд 123SELECT * FROM users WHERE
sex=‘F’ AND age>=18 AND age<=25
ORDER BY hotness DESC
SELECT * FROM users WHERE sex=‘F’ AND age>=18 AND age<=25 ORDER BY hotness DESC

Слайд 124как выполнять? есть варианты
как выполнять? есть варианты


Слайд 126налево – read_index(WHERE) + read_rows + sort_rows(ORDER)
налево – read_index(WHERE) + read_rows + sort_rows(ORDER)

Слайд 127индекс
данные
сортировка
результат
индекс
данные
сортировка
результат

Слайд 128read_index – мало и быстро
read_index – мало и быстро

Слайд 12910K*( 1+4+8 bytes ) = 130 KB
5-10 ms/seek, 50+ MB/s read
10K*( 1+4+8 bytes ) = 130 KB
5-10 ms/seek, 50+ MB/s read

Слайд 130read_random_rows – медленно!
10K*5-10 ms/seek = 50-100 sec…
read_random_rows – медленно!
10K*5-10 ms/seek = 50-100 sec…

Слайд 131sort_rows – обычно быстро
10K*0.1-1 KB/row = 1-10 MB (in RAM)
sort_rows – обычно быстро
10K*0.1-1 KB/row = 1-10 MB (in RAM)

Слайд 132мораль – все зло от random rows!
мораль – все зло от random rows!

Слайд 133(еще от sort_rows, если их много)
(еще от sort_rows, если их много)


Слайд 135… sex=‘F’ AND age>=18 AND age<=25
ORDER BY hotness DESC LIMIT 10
… sex=‘F’ AND age>=18 AND age<=25
ORDER BY hotness DESC LIMIT 10

Слайд 136направо – read_fat_index(WHERE) + sort_index(ORDER) + LIMIT + read_less_rows + sort_rows
направо – read_fat_index(WHERE) + sort_index(ORDER) + LIMIT + read_less_rows + sort_rows

Слайд 137нужен утолщенный
INDEX ( sex, age, hotness )
нужен утолщенный
INDEX ( sex, age, hotness )

Слайд 138вместе с поиском по sex, age – сразу узнаем hotness (+40 KB)
вместе с поиском по sex, age – сразу узнаем hotness (+40 KB)

Слайд 139sort ( 10K * [ hotness, rowptr ] )
sort ( 10K * [ hotness, rowptr ] )
![sort ( 10K * [ hotness, rowptr ] )](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/395172/slide-138.jpg)
Слайд 140read_rows – почти не нужен
(10 строк результата…)
read_rows – почти не нужен
(10 строк результата…)

Слайд 141sort_rows – вообще не нужен
sort_rows – вообще не нужен

Слайд 142PROFIT?
PROFIT?

Слайд 143не панацея – даже в теории
не панацея – даже в теории

Слайд 144INDEX ( sex, age, hotness )
WHERE sex=‘F’ ORDER BY hotness LIMIT 10
INDEX ( sex, age, hotness )
WHERE sex=‘F’ ORDER BY hotness LIMIT 10

Слайд 145в теории – обработать 50% индекса
затем – прочитать 10 строк (пф!)
в теории – обработать 50% индекса
затем – прочитать 10 строк (пф!)

Слайд 146INDEX ( sex, age, hotness )
1M rows, ~20 MB, 50% = ~10
INDEX ( sex, age, hotness ) 1M rows, ~20 MB, 50% = ~10

Слайд 147INDEX ( sex, age, hotness )
WHERE sex=‘F’ AND hotness>0 ORDER BY age
INDEX ( sex, age, hotness ) WHERE sex=‘F’ AND hotness>0 ORDER BY age

Слайд 148в теории – читаем индекс линейно –
пока не заполним limit
в теории – читаем индекс линейно –
пока не заполним limit

Слайд 149что на практике?
что на практике?

Слайд 150welcome to real world
welcome to real world

Слайд 151CREATE TABLE usertest (
id INTEGER PRIMARY KEY NOT NULL, sex ENUM ('m','f'),
age
CREATE TABLE usertest ( id INTEGER PRIMARY KEY NOT NULL, sex ENUM ('m','f'), age

Слайд 152500,000 записей
56 MB данных (.ibd файл)
32 MB innodb_buffer_pool
age \in [18.. 80]
hotness \in
500,000 записей 56 MB данных (.ibd файл) 32 MB innodb_buffer_pool age \in [18.. 80] hotness \in

Слайд 153mysql> explain select * from usertest
where sex='f' and age>=18 and age<=25
order by
mysql> explain select * from usertest where sex='f' and age>=18 and age<=25 order by
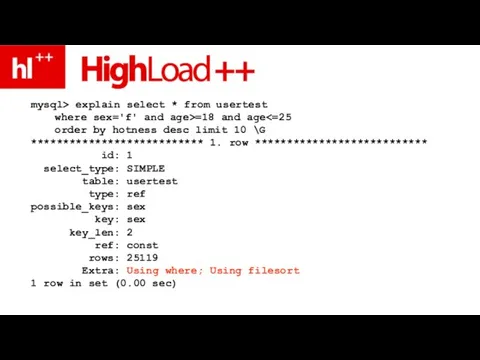
Слайд 154filesort – НЕ про временный файл
filesort – про “сортировку строк”
filesort – НЕ про временный файл
filesort – про “сортировку строк”

Слайд 155Using where – проверка условия НЕ по индексу – ?!!
Using where – проверка условия НЕ по индексу – ?!!

Слайд 156запрос проще, точно по индексу?
запрос проще, точно по индексу?

Слайд 157mysql> explain select * from usertest
where sex='f' and age=18
order by hotness desc
mysql> explain select * from usertest where sex='f' and age=18 order by hotness desc
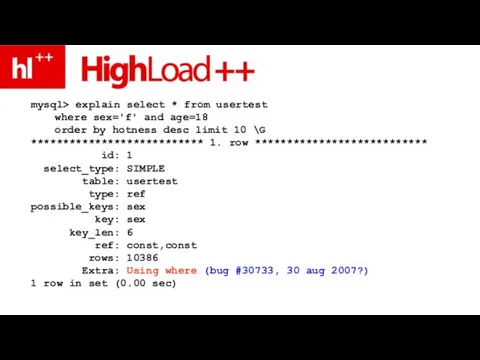
Слайд 158проверим экспериментально!!!
проверим экспериментально!!!

Слайд 159mysql> select * from usertest where sex='f' and
age>=18 and age<=25
order by hotness
mysql> select * from usertest where sex='f' and age>=18 and age<=25 order by hotness

Слайд 160причина?
причина?

Слайд 161mysql> explain select * from usertest
where sex='f' and age>=18 and age<=25
order by
mysql> explain select * from usertest where sex='f' and age>=18 and age<=25 order by
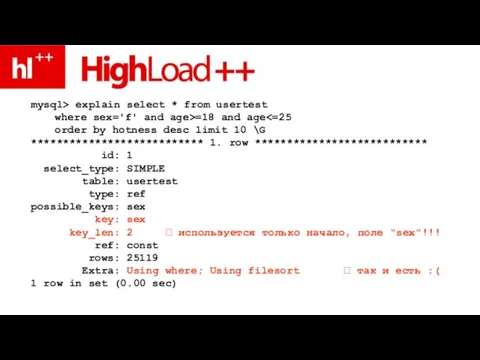
Слайд 162MySQL не умеет сортировать элементы индекса :(
MySQL не умеет сортировать элементы индекса :(

Слайд 163сортировка “по индексу” – только если индекс гарантирует порядок
сортировка “по индексу” – только если индекс гарантирует порядок

Слайд 1641) в куске индекса sex=F, 18<=age<=25
порядок hotness desc НЕ гарантирован
1) в куске индекса sex=F, 18<=age<=25
порядок hotness desc НЕ гарантирован

Слайд 1652) optimizer лажанул, 18<=age<=25
считается НЕ по индексу (а могло бы)
2) optimizer лажанул, 18<=age<=25
считается НЕ по индексу (а могло бы)

Слайд 166(теория говорит – можно лучше!)
(теория говорит – можно лучше!)

Слайд 167проверяем дальше!
проверяем дальше!

Слайд 168mysql> explain select * from usertest
where sex='f' order by hotness desc limit
mysql> explain select * from usertest where sex='f' order by hotness desc limit

Слайд 169и последний запрос
и последний запрос

Слайд 170mysql> explain select * from usertest where sex='f' and hotness>0 order by
mysql> explain select * from usertest where sex='f' and hotness>0 order by

Слайд 171итого
итого

Слайд 172теория была оптимистична…
теория была оптимистична…

Слайд 173…реальность внесла коррективы.
…реальность внесла коррективы.

Слайд 174не учли детали реализации
не учли детали реализации

Слайд 1751. нету “досортировки” индекса
(MySQL specific)
1. нету “досортировки” индекса
(MySQL specific)

Слайд 1762. limit обрабатывается… так себе
(MySQL specific)
2. limit обрабатывается… так себе
(MySQL specific)

Слайд 1773. optimizer ошибается
(везде и у всех)
3. optimizer ошибается
(везде и у всех)

Слайд 178про ошибки optimizer и спасительный full-scan
про ошибки optimizer и спасительный full-scan

Слайд 179mysql> select * from usertest where sex='f' order by hotness desc limit
mysql> select * from usertest where sex='f' order by hotness desc limit

Слайд 18010,000 x 10 ms = 100 sec
100,000 x 1KB / 50 M/s
10,000 x 10 ms = 100 sec 100,000 x 1KB / 50 M/s

Слайд 181мораль: random IO очень плохо
(водка яд водка яд водка яд)
мораль: random IO очень плохо
(водка яд водка яд водка яд)

Слайд 182про “обработку” limit
про “обработку” limit

Слайд 183теория – приоритетная очередь
теория – приоритетная очередь



Слайд 186технически – heap
технически – heap


Слайд 188или просто double buffer
или просто double buffer


Слайд 191ключевое свойство –
в памяти храним только top-N
ключевое свойство –
в памяти храним только top-N

Слайд 192LIMIT 10 – надо хранить 10 строк
LIMIT 10 – надо хранить 10 строк

Слайд 193LIMIT 130,10 – надо 140
LIMIT 130,10 – надо 140

Слайд 194практика – MySQL vs. LIMIT
практика – MySQL vs. LIMIT

Слайд 195выбрать и отсортировать ВСЕ (*)
* – всегда, когда индекс не гарантирует точный
выбрать и отсортировать ВСЕ (*)
* – всегда, когда индекс не гарантирует точный

Слайд 196выбрать OK – избежать нельзя
выбрать OK – избежать нельзя


Слайд 198сортировать все плохо…
сортировать все плохо…


Слайд 200лишний удар по CPU/RAM/IO :(
лишний удар по CPU/RAM/IO :(

Слайд 201как убирать mysql сортировку?
как убирать mysql сортировку?

Слайд 202строить более другие индексы
строить более другие индексы

Слайд 203ставить более другой софт
ставить более другой софт

Слайд 204умеет и “обычный” поиск!
умеет и “обычный” поиск!

Слайд 205трюки про WHERE вместо LIMIT
(я не пробовал, но говорят, возможно)
трюки про WHERE вместо LIMIT
(я не пробовал, но говорят, возможно)

Слайд 206…именно в таком порядке.
…именно в таком порядке.

Слайд 207более практический пример?
более практический пример?

Слайд 208импортируем дамп Wikipedia
импортируем дамп Wikipedia

Слайд 209XML дамп → 2 толстые таблицы
хочется – а) одну б) тонкую!
XML дамп → 2 толстые таблицы
хочется – а) одну б) тонкую!

Слайд 210INSERT INTO mycontent
SELECT t.old_id, p.page_id, UNIX_TIMESTAMP(p.page_touched), p.page_len, p.page_title, COMPRESS(t.old_text)
FROM text t, page
INSERT INTO mycontent SELECT t.old_id, p.page_id, UNIX_TIMESTAMP(p.page_touched), p.page_len, p.page_title, COMPRESS(t.old_text) FROM text t, page

Слайд 211mysql> EXPLAIN SELECT t.old_id, ... \G
********************** 1. row **********************
table: page
type:
mysql> EXPLAIN SELECT t.old_id, ... \G ********************** 1. row ********************** table: page type:

Слайд 212что хотим?
scan 15 GB text, join 0.5 GB page
что хотим?
scan 15 GB text, join 0.5 GB page

Слайд 213почему не выходит?
… FROM text t, page p WHERE t.old_id=p.page_latest
почему не выходит?
… FROM text t, page p WHERE t.old_id=p.page_latest

Слайд 214решение – index(page_latest)
решение – index(page_latest)

Слайд 215еще пришлось STRAIGHT_JOIN
(optimizer опять лажанул!)
еще пришлось STRAIGHT_JOIN
(optimizer опять лажанул!)

Слайд 216результат – 40 минут, включая CREATE INDEX
результат – 40 минут, включая CREATE INDEX


Слайд 218так зачем же знать алгоритмы?
так зачем же знать алгоритмы?

Слайд 219“did we learn something today?”
“did we learn something today?”


Слайд 221как устроено B-дерево
как устроено B-дерево

Слайд 222как работает индекс
как работает индекс

Слайд 223как работают выборки
как работают выборки

Слайд 224зачем нужны full-scans
зачем нужны full-scans

Слайд 225как работает сортировка с LIMIT
как работает сортировка с LIMIT

Слайд 226чего можно добиться в идеале – в теории
чего можно добиться в идеале – в теории

Слайд 227…и как оно, бывает, не работает – на практике!
…и как оно, бывает, не работает – на практике!

Слайд 228а толку?!
а толку?!

Слайд 229чего ждать от БД
чего ждать от БД

Слайд 230чего не ждать
чего не ждать

Слайд 231как и что тестировать
как и что тестировать

Слайд 232как объяснять потом результаты
как объяснять потом результаты


Слайд 234в итоге –
как заставлять таки работать
в итоге –
как заставлять таки работать


Слайд 236…БЫСТРО работать.
…БЫСТРО работать.

 Государственное пенсионное страхование: источники финансирования, субъекты, виды и размеры выплат, органы управления
Государственное пенсионное страхование: источники финансирования, субъекты, виды и размеры выплат, органы управления Формирование эмоционального настроя
Формирование эмоционального настроя Презентация по обществознанию на тему _Правовое государство_ (9 класс)
Презентация по обществознанию на тему _Правовое государство_ (9 класс) Презентация на тему: Педагогическая рефлексия как основа профессионального и личностного роста педагога
Презентация на тему: Педагогическая рефлексия как основа профессионального и личностного роста педагога Презентация на тему Toys
Презентация на тему Toys Как гармонично совместить общественную работу и семью
Как гармонично совместить общественную работу и семью Логические основы ЭВМ
Логические основы ЭВМ Иван Сергеевич Тургенев«Бежин луг».
Иван Сергеевич Тургенев«Бежин луг». Гражданское право
Гражданское право Санкт-Петербургский государственный экономический университет. Направление Международный бизнес
Санкт-Петербургский государственный экономический университет. Направление Международный бизнес Менеджмент качества
Менеджмент качества Пудель
Пудель ATP. Лекция 4. Spanning Tree
ATP. Лекция 4. Spanning Tree Российский союз промышленников и предпринимателей Развитие пенсионных систем в в Российской Федерации (Сочи, 2 - 4 октября 2006 г.) Н
Российский союз промышленников и предпринимателей Развитие пенсионных систем в в Российской Федерации (Сочи, 2 - 4 октября 2006 г.) Н Marketing research process
Marketing research process Словообразование имен прилагательных с помощью суффиксов
Словообразование имен прилагательных с помощью суффиксов История брюк
История брюк Общее знакомство с растениями
Общее знакомство с растениями Marketing tricks
Marketing tricks Вступая в ряды учеников средней школы, торжественно клянусь: 1. У доски стоять как лучший вратарь, не пропуская ни одного вопроса. 2.
Вступая в ряды учеников средней школы, торжественно клянусь: 1. У доски стоять как лучший вратарь, не пропуская ни одного вопроса. 2.  The big bang theory
The big bang theory Особливості ментальності базових ТІМ Представники ІV-ї квадри
Особливості ментальності базових ТІМ Представники ІV-ї квадри Последние годы жизни императора. Личность Петра 1
Последние годы жизни императора. Личность Петра 1 МЕЖДУНАРОДНЫЙ МОЛОДЕЖНЫЙИННОВАЦИОННЫЙ ФОРУМ В СИБИРИ«ИНТЕРРА’10»
МЕЖДУНАРОДНЫЙ МОЛОДЕЖНЫЙИННОВАЦИОННЫЙ ФОРУМ В СИБИРИ«ИНТЕРРА’10» Реализм в романе
Реализм в романе  ЗАЩИТА ПРАВ ПАЦИЕНТОВ
ЗАЩИТА ПРАВ ПАЦИЕНТОВ Фасад здания
Фасад здания Презентация на тему Буква Э (1 класс)
Презентация на тему Буква Э (1 класс)