- Статистика в аналитической химии

Содержание
- 2. Определение понятия процесса измерения. Статистика в аналитической химии Химия, и в частности аналитическая химия, как и
- 3. Статистика в аналитической химии Использование статистики в химических, клинических и фармацевтических лабораториях является обычным делом. Поскольку
- 4. Если мы проводим эксперимент, то мы почти всегда получаем результат с погрешностью. Почему мы не получаем
- 5. Статистика в аналитической химии При оценивании величины систематической погрешности предполагается проводить эксперимент большое количество раз. Это
- 6. Иллюстрация систематической погрешности Статистика в аналитической химии 1. Производитель пипетки утверждает тот факт, что произведенная им
- 7. Статистика в аналитической химии Случайные и систематические ошибки в аналитической химии вызываются множеством различных причин. Вот
- 8. Статистика в аналитической химии Если отбросить ошибку пробоотбора, как непосредственно не относящуюся к методу анализа, то
- 9. Статистика в аналитической химии
- 10. Статистика в аналитической химии
- 11. Статистика в аналитической химии Основные статистические понятия в аналитическом измерении (генеральная совокупность и выборка, среднее, дисперсия
- 12. Статистика в аналитической химии Мера центральной тенденции любой выборки - это число, характеризующее выборку по уровню
- 13. Статистика в аналитической химии Медиана представляет собой срединное значение данных, расположенных в восходящем порядке. Если имеется
- 14. Статистика в аналитической химии Среднее Выборочное среднее (арифметическое среднее) это результат суммирования всех результатов и деления
- 15. Статистика в аналитической химии Среднее из n данных выбранных случайно из нормально распределенной популяции с μ
- 16. Статистика в аналитической химии Реальные данные могут быть нормально распределены, но часто распределение содержит данные, которые
- 17. Статистика в аналитической химии Стандартное отклонение и дисперсия Разброс генеральной совокупности, демонстрируемый «тучностью» колоколообразной кривой измеряется
- 18. Статистика в аналитической химии Относительное стандартное отклонение Относительное стандартное отклонение (RSD), известное также как коэффициент вариации
- 19. Статистика в аналитической химии В математической статистике есть так называемая центральная предельная теорема, которая гласит о
- 20. Статистика в аналитической химии
- 21. Статистика в аналитической химии Несколько огорчает наличие корня квадратного от n в уравнениях . Этот корень
- 22. Статистика в аналитической химии Доверительные интервалы и доверительные пределы Стандартное отклонение среднего говорит нам однозначно о
- 23. Статистика в аналитической химии Строгий расчет границ доверительного интервала случайной величины возможен лишь в предположении, что
- 24. Статистика в аналитической химии Параметры этой функции μ и σ характеризуют: μ - положение максимума кривой,
- 25. Статистика в аналитической химии Численные значения коэффициентов пропорциональности t были впервые рассчитаны английским математиком В.Госсетом, подписывавшим
- 26. Статистика в аналитической химии Величина меньше, чем s(x) (среднее точнее единичного). Для серии из n значений
- 27. Зачем нужно проводить испытание гипотез? Статистика в аналитической химии Неизменно помни, что природа - не бог,
- 28. Одним из применений анализа полученных данных является возможность дать ответы на вопросы о качестве данных или
- 29. Статистическая значимость, или так называемый Р - уровень значимости - это основной результат проверки статистической гипотезы.
- 30. Статистика в аналитической химии
- 31. Статистика в аналитической химии Проверка гипотез обычно проходит следующие этапы: 1. Определение используемой статистической модели. Здесь
- 32. Статистика в аналитической химии Односторонние и двусторонние критерии проверки значимости Если цель исследования состоит том, чтобы
- 33. Статистика в аналитической химии Статистические критерии - это инструмент, для того чтобы иметь возможность ответить на
- 34. Статистика в аналитической химии Если же есть дополнительная информация, например, из предшествующих экспериментов, на основании которой
- 35. Статистика в аналитической химии Выбор подходящего статистического метода для проверки гипотезы Критерий t-Стьюдента для одной выборки
- 36. Статистика в аналитической химии Критерий t-Стьюдента для зависимых выборок Этот метод позволяет проверить гипотезу о том,
- 38. Статистика в аналитической химии Что такое метод ANOVA ? ANOVA (Analysis of Variance) – это дисперсионный
- 39. Статистика в аналитической химии Однофакторный ANOVA В однофакторном ANOVA имеются уровни исследуемого фактора с повторными результатами
- 40. Статистика в аналитической химии Конкретная планировка представления данных ANOVA в межлабораторных сличительных испытаниях
- 41. Статистика в аналитической химии Этапы в вычислении ANOVA таковы:
- 42. Статистика в аналитической химии
- 43. Статистика в аналитической химии Таким образом, результат расчетов представляют в виде следующей таблицы где N- общее
- 44. Статистика в аналитической химии Остаточный средний квадрат является оценкой средней дисперсии результатов в пределах каждого уровня
- 45. Статистика в аналитической химии Матрица данных в этом случае будет иметь пять колонок (каждая пипетка) и
- 46. Статистика в аналитической химии Проверка на нормальность распределения данных Многие статистические параметры, используемые химиками – аналитиками,
- 47. Статистика в аналитической химии Критерий согласия Пирсона (χ2) применяют для проверки гипотезы о соответствии эмпирического распределения
- 48. Статистика в аналитической химии Далее определяют вспомогательные данные для расчета наблюдаемого критерия согласия Пирсона χ2 .
- 49. Статистика в аналитической химии
- 50. Статистика в аналитической химии Критерий Шапиро-Уилка. Этот критерий является одним из наиболее мощных в большинстве случаев.
- 51. Статистика в аналитической химии Этот критерий применяется, когда выборка содержит малое количество наблюдений (n≤30). Рассмотрим алгоритм
- 52. Статистика в аналитической химии
- 53. Статистика в аналитической химии Имеется и полезная графическая процедура для испытания нормальности набора данных, которая может
- 54. Статистика в аналитической химии Если данные распределены нормально, то график должен быть линеен. Очевидно, что выпавшие
- 55. Статистика в аналитической химии Ранкит-график первичной обработки данных Очевидно, что точка 0.9083 М не является частью
- 56. Статистика в аналитической химии Повтор ранкит-теста для данных с первым удаленным выпавшим значением
- 57. Статистика в аналитической химии Завершающий ранкит-тест
- 58. Статистика в аналитической химии Очевидно, что точки-данные 0.092, 0.0936, 0.1177, 0.1219, 0.1222, и 0.1556 являются выпавшими
- 59. Статистика в аналитической химии Тесты на выпавшие значения Выпавшее значение, есть значение, которое не принадлежит распределению,
- 60. Статистика в аналитической химии Результат применения Excell для выполнения теста Грубба рассмотрим на следующем примере: Было
- 61. Статистика в аналитической химии
- 62. Статистика в аналитической химии Так как Gsuspect > Gcritical значение 16.65 мг/г является выпавшим и может
- 63. Статистика в аналитической химии Односторонний t - тест Систематическая погрешность в аналитической методике должна быть определена
- 64. ПРИМЕР : Содержание фтора в зубной пасте согласно метода измеряется с использованием ионселективного электрода. Выполнение измерения
- 65. Статистика в аналитической химии
- 66. Приписанное значение лежит непосредственно за 95% доверительного интервала, что дает нам возможность предположить, что имеется значимая
- 67. Статистика в аналитической химии Парный t - тест В некоторых случаях у нас нет такой роскоши,
- 68. Статистика в аналитической химии a атомно-абсорбционная спектрофотометрия. bКомплексонометрическое титрование.
- 69. Статистика в аналитической химии Вероятность того, что между методиками нет разницы, рассчитанная по представленным данным, составляет
- 70. Статистика в аналитической химии Наиболее часто используемые тесты однородности дисперсий двух и более выборок данных При
- 71. Статистика в аналитической химии
- 72. Статистика в аналитической химии
- 73. Статистика в аналитической химии Анализ однородности дисперсий по Бартлетту Назначение. Проверка гипотезы о принадлежности нескольких дисперсий
- 74. Статистика в аналитической химии Если рассчитанное значение χ2 больше или равно критическому значению, взятому с уровнем
- 75. Статистика в аналитической химии
- 76. Статистика в аналитической химии ANOVA в Excel Excel предлагает три варианта применения ANOVA посредством его надстройки
- 77. Статистика в аналитической химии
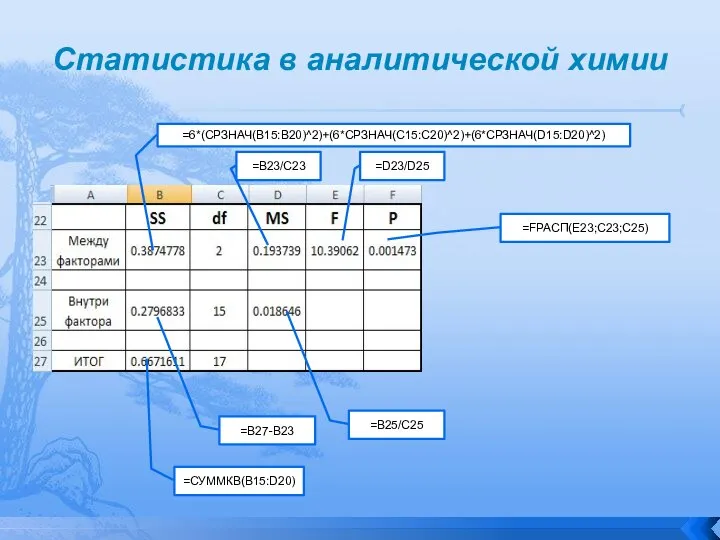
- 78. Статистика в аналитической химии
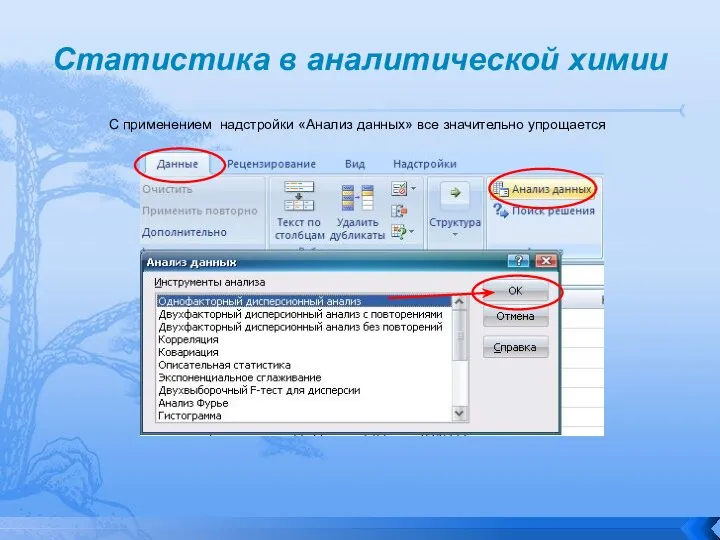
- 79. Статистика в аналитической химии C применением надстройки «Анализ данных» все значительно упрощается
- 80. Статистика в аналитической химии
- 81. Статистика в аналитической химии Результат с применением надстройки «Анализ данных»
- 82. Статистика в аналитической химии Таким образом значение F составляет 10.39062 с ассоциированной вероятностью 0.001473. Так как
- 83. Статистика в аналитической химии Реализация метода ANOVA с использованием статистических программых продуктов Minitab16 и Statistica 6.0
- 84. Статистика в аналитической химии
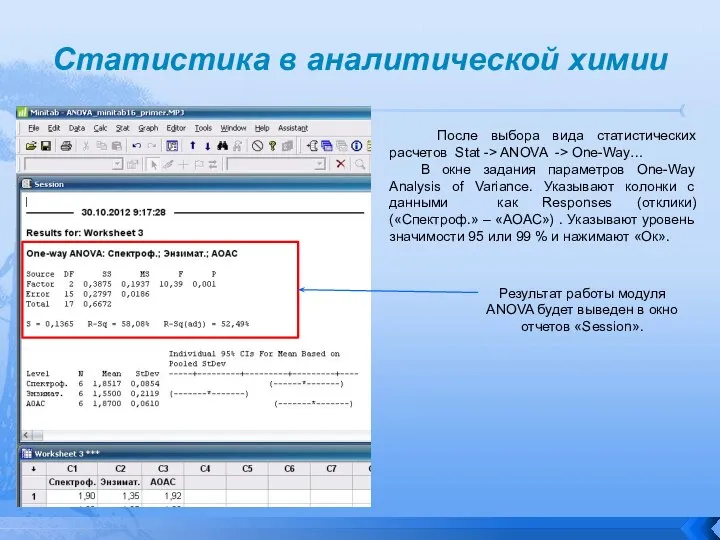
- 85. Статистика в аналитической химии После выбора вида статистических расчетов Stat -> ANOVA -> One-Way… В окне
- 86. Статистика в аналитической химии Результат работы модуля ANOVA будет выведен в окно отчетов «Session».
- 87. Статистика в аналитической химии Рассмотрим реализацию ANOVA с помощью Minitab 16 с набором даннных Unstacked (расположенных
- 88. Статистика в аналитической химии
- 89. Статистика в аналитической химии Результат работы модуля ANOVA будет выведен в окно отчетов «Session». После выбора
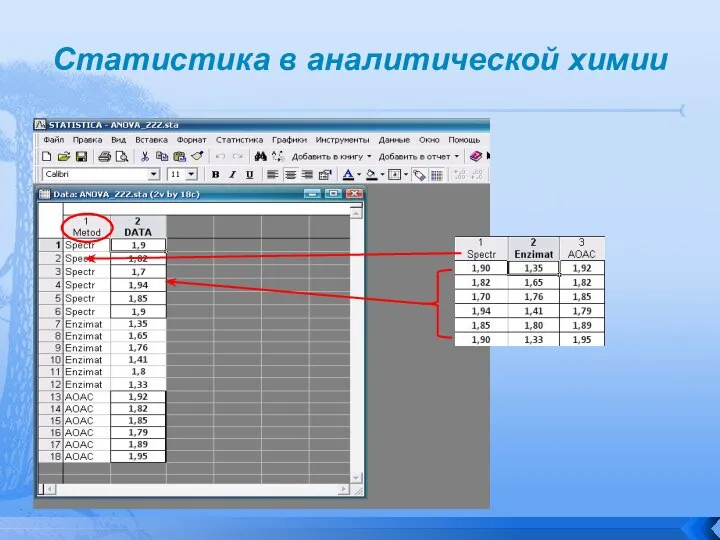
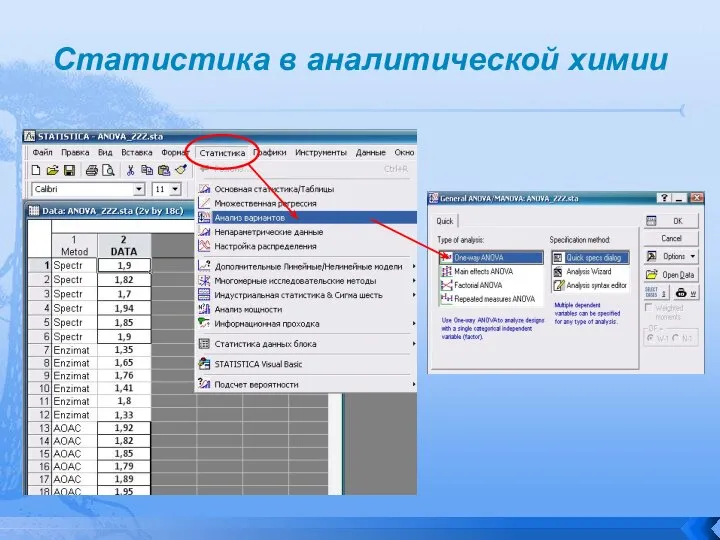
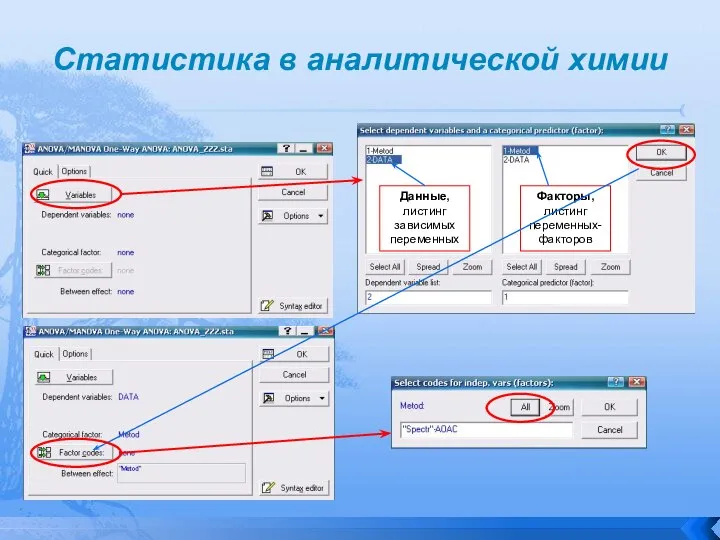
- 90. Статистика в аналитической химии Рассмотрим реализацию ANOVA с помощью Statistica 6.0 . Эта программа работает с
- 91. Статистика в аналитической химии
- 92. Статистика в аналитической химии
- 93. Статистика в аналитической химии
- 94. Статистика в аналитической химии
- 95. Статистика в аналитической химии * это непараметрический аналог парного критерия Стьюдента (t-критерий для зависимых выборок)
- 96. Статистика в аналитической химии Чтобы автоматизировать вычисление критических значений статистики W, необходимо определить свою пользовательскую функцию,
- 97. Статистика в аналитической химии Двухвыборочный критерий Вилкоксона Назначение. Проверка гипотезы о равенстве средних двух независимых выборок.
- 98. Статистика в аналитической химии
- 99. Статистика в аналитической химии Критерий T- Вилкоксона для парных наблюдений (одновыборочный критерий Вилкоксона, критерий знаковых рангов)
- 100. Статистика в аналитической химии Примечание. Данный критерий устойчив к умеренным отклонениям от принятых предпосылок. Критерий Вилкоксона
- 101. Статистика в аналитической химии
- 102. Статистика в аналитической химии Калибровка является сердцем химического анализа и процесса посредством которого отклик прибора (в
- 103. Статистика в аналитической химии Любое конкретное измерение (уi) будет подвержено погрешностям измерения, таким образом: Уі =
- 104. Статистика в аналитической химии Эти коэффициенты оценивают действительную функцию, ограниченную неминуемым разбросом, который возникает во время
- 105. Статистика в аналитической химии Стандартные отклонения могут быть вычислены и для коэффициентов : Стандартное отклонение определяемой
- 106. Статистика в аналитической химии Рассмотрим возможность реализации вышеприведенных расчетов в Excell на примере определения содержания нитрит-иона
- 107. Статистика в аналитической химии Для реализации вышеприведенных расчетов в Excell необходимо воспользоваться функцией-массивом – «ЛИНЕЙН» из
- 108. Статистика в аналитической химии После вызова функции «ЛИНЕЙН» появится окно задания необходимых входных диапазонов данных
- 109. Статистика в аналитической химии После вызова функции «ЛИНЕЙН» и задания необходимых данных, для корректного вывода расчетных
- 110. Статистика в аналитической химии Соответствие полученных данных функции «ЛИНЕЙН» параметрам линейной регрессии
- 111. Статистика в аналитической химии Получение расширенных параметров линейной регрессии, согласно ISO 11095:1996 «Linear calibration using reference
- 112. Статистика в аналитической химии
- 113. Статистика в аналитической химии
- 114. Статистика в аналитической химии Метод контроля стабильности калибровки, согласно ГОСТ Р ИСО 11095-2007 Если функция калибровки
- 115. Отбирают m RM так, чтобы соответствующие им принятые значения заполняли диапазон значений, характерных для нормальных режимов
- 116. Карты Шухарта Контрольные карты — график изменения параметров выборки, обычно средних и среднеквадратичного отклонения. Различают контрольные
- 117. Карты Шухарта Контрольные карты используются для оценки "контролируемости" или "неконтролируемости" процесса. Эту оценку можно получить: •
- 118. Карты Шухарта КОНТРОЛЬНАЯ КАРТА СРЕДНИХ АРИФМЕТИЧЕСКИХ Если генеральная совокупность имеет нормальное (или близкое к нормальному) распределение
- 119. Карты Шухарта Для построения графика, приведенного на рис., необходимо, чтобы значения μ и σ были известны.
- 120. Карты Шухарта 1. Через равные промежутки времени проводится выборка объемом n и рассчитывается выборочное среднее. 2.
- 121. Карты Шухарта Процедура ведения КК в сущности представляет собой не что иное, как проверку гипотез. Нулевая
- 122. Карты Шухарта Формулы расчета средней линии и границ для карт средних
- 123. Карты Шухарта Контрольные карты для индивидуальных значений (X) В некоторых ситуациях для управления процессами невозможно или
- 124. Карты Шухарта На основе скользящих размахов вычисляют средний скользящий размах R, который используют для построения контрольных
- 125. Карты Шухарта Во время использования карт индивидуальных значений необходимо учитывать тот факт, что : a) карты
- 126. Карты Шухарта
- 127. Карты Шухарта МЕТОД УПРАВЛЕНИЯ И ИНТЕРПРЕТАЦИЯ КОНТРОЛЬНЫХ КАРТ ДЛЯ КОЛИЧЕСТВЕННЫХ ДАННЫХ Система карт Шухарта опирается на
- 128. Статистика в аналитической химии Что такое – «Неопределенность» ? Понятие «неопределенность» (англ. «Uncertainty»), появилось более 30
- 129. Статистика в аналитической химии Рассмотрим теперь, как определяется неопределенность. Согласно EUROCHEM/CITAC Guide “Quantifying Uncertainty in Analytical
- 130. Статистика в аналитической химии Обсуждение погрешностей данное выше известно как "классический подход" к измерению. Он хорошо
- 131. Статистика в аналитической химии Использование «неопределённости» позволяет наглядно решать вопрос о соответствии (или несоответствии) измеренной характеристики
- 132. Графические методы выяснения источников неопределенности Диаграмма Исикавы
- 133. "Причинно-следственная диаграмма" («рыбий скелет») Автор метода: К. Исикава (Япония), 1952 г. Назначение метода Применяется при разработке
- 134. Общие правила построения Прежде чем приступать к построению диаграммы, все участники должны прийти к единому мнению
- 135. Достоинства метода Диаграмма Исикавы позволяет: стимулировать творческое мышление; представить взаимосвязь между причинами и сопоставить их относительную
- 136. Графические методы выяснения источников неопределенности
- 137. Авторы метода: В. Парето (Италия), 1897 г, М. Лоренц (США), 1979 г. Назначение метода Применяется практически
- 138. Общие правила построения диаграммы Парето Решить, какие проблемы (причины проблем) надлежит исследовать, какие данные собирать и
- 139. Достоинства метода Простота и наглядность делают возможным использование диаграммы Парето специалистами, не имеющими особой подготовки. Сравнение
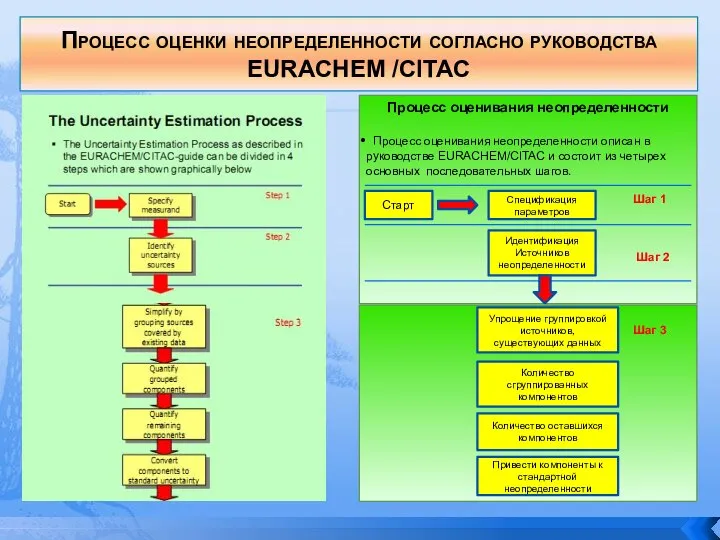
- 140. Процесс оценки неопределенности согласно руководства EURACHEM /CITAC
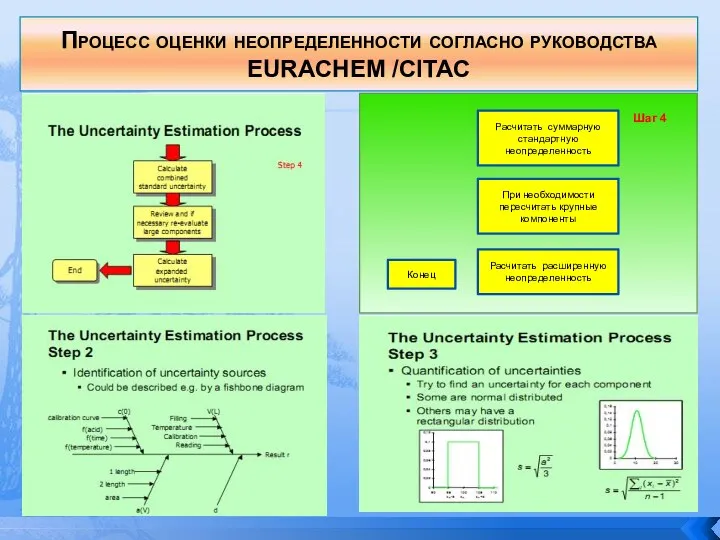
- 141. Процесс оценки неопределенности согласно руководства EURACHEM /CITAC
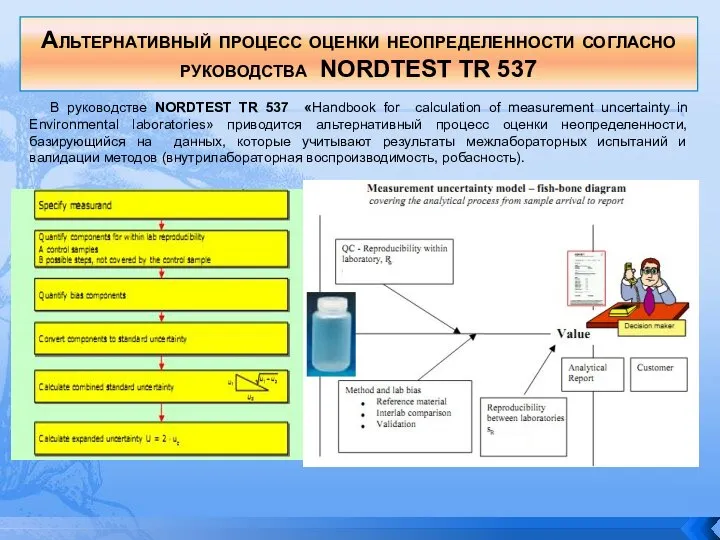
- 142. Альтернативный процесс оценки неопределенности согласно руководства NORDTEST TR 537 В руководстве NORDTEST TR 537 «Handbook for
- 143. Современные методы оценки неопределенности Стандарт ISO/IEC 17025:2006 определяет международное признание результатов испытаний и калибровок лабораториями, получивших
- 144. Современные методы оценки неопределенности Основные термины и положения по оцениванию неопределенности измерений, согласно GUM «Guide to
- 145. Современные методы оценки неопределенности Стандартная неопределенность — неопределенность результата измерений, выраженная как стандартное отклонение. Суммарная стандартная
- 146. Современные методы оценки неопределенности Основные положения концепции неопределенности : 1. Все составляющие неопределенности в результате измерения
- 147. Современные методы оценки неопределенности 5. Интервальной оценкой неопределенности является расширенная неопределенность U, которую получают путем умножения
- 148. Современные методы оценки неопределенности 3. Коэффициенты чувствительности. Расчет их необходим для определения вклада неопределенности каждой входной
- 149. Современные методы оценки неопределенности
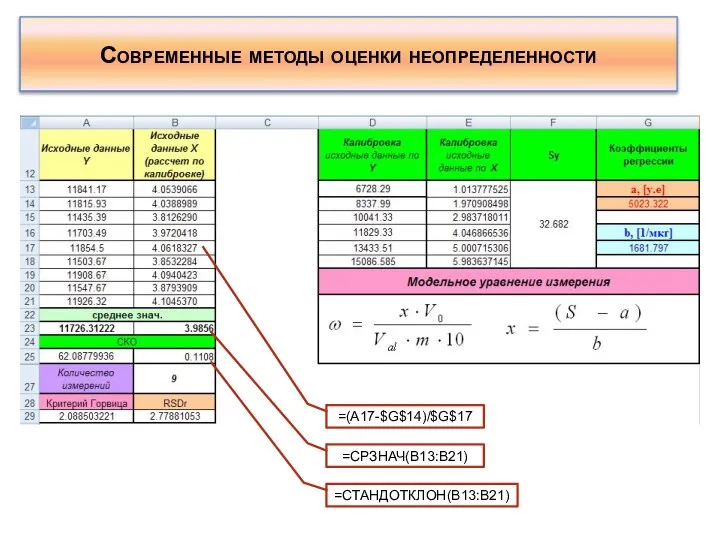
- 150. Современные методы оценки неопределенности Важным фактором корректной оценки неопределенности является составление модельного уравнения. Модельным уравнением является
- 151. Современные методы оценки неопределенности
- 152. Современные методы оценки неопределенности
- 153. Современные методы оценки неопределенности Недостатки подхода GUM к оценке неопределенности В основе общего подхода лежит т.н.
- 154. Современные методы оценки неопределенности Основываясь на указанных недостатках, было предложено применить метод статистического моделирования (метод Монте-Карло)
- 155. Современные методы оценки неопределенности 2. Расчет параметров бюджета неопределенности (расширенной и стандартной суммарной неопределенности, коэффициента охвата)
- 156. Современные методы оценки неопределенности - расширенную неопределенность для заданного уровня доверия. Для получения оценки расширенной неопределенности
- 157. Современные методы оценки неопределенности Схема реализации алгоритма Монте-Карло
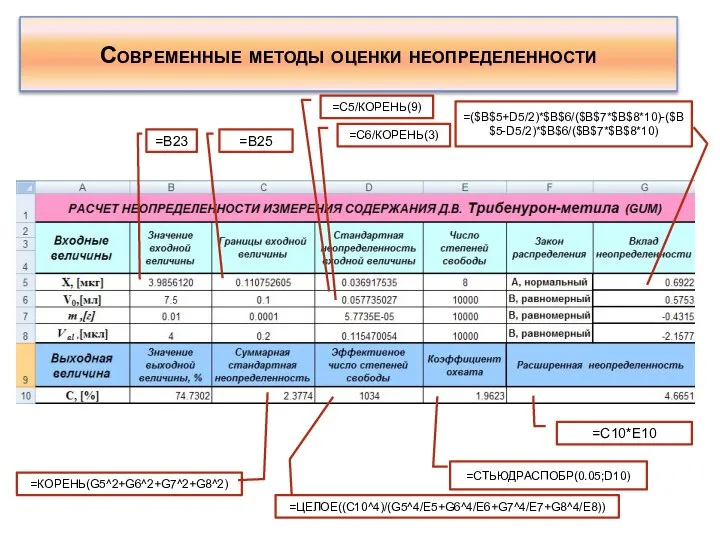
- 158. Современные методы оценки неопределенности При реализации метода Монте-Карло в среде Excell устанавливают надстройку «Анализ данных», в
- 159. Современные методы оценки неопределенности 1. Генерируют массив из 10000 данных входной величины, оцениваемой по типу А.
- 160. Современные методы оценки неопределенности 2. Генерируют массив из 10000 данных входной величины, оцениваемой по типу В.
- 161. Современные методы оценки неопределенности 3. Продолжают генерирование массивов из 10000 данных входных величин, оцениваемых по типу
- 162. Современные методы оценки неопределенности 4. После того как будут сгенерированы все массивы входных величин, в колонке
- 163. Современные методы оценки неопределенности 5. Для получения результата по расчету расширенной неопределенности, скопированные данные в колонке
- 165. Современные методы оценки неопределенности Сколько значимых цифр? Для измерений, проводимых посредством современных приборов, цифры обычно выводятся
- 166. Чтобы дать ответ на этот вопрос следует воспользоваться руководством EURACHEM / CITAC Guide «Use of uncertainty
- 167. Вертикальные линии показывают ±U расширенную неопределенность для каждого результата и связанные кривой указывают на выведенную плотность
- 168. Начало зоны исключения находится в пределах спецификации L плюс значение g, (так называемой предохранительной полосы). Значение
- 169. В некоторых случаях спецификация устанавливает верхний и нижний пределы, например контроля состава. Рис 3 показывает зоны
- 170. Как согласуется погрешность с неопределенностью? Формулы пересчета параметров неопределенности в параметры погрешности :
- 171. Как согласуется погрешность с неопределенностью? Формулы пересчета параметров неопределенности в параметры погрешности :
- 172. Поэтапная валидация метода Валидация - процесс установления характеристик и ограничений метода, идентификации влияний, которые могут изменять
- 173. Поэтапная валидация метода Основополагающим документом по проведению валидации аналитических методов является руководство ЕВРАХЕМ.
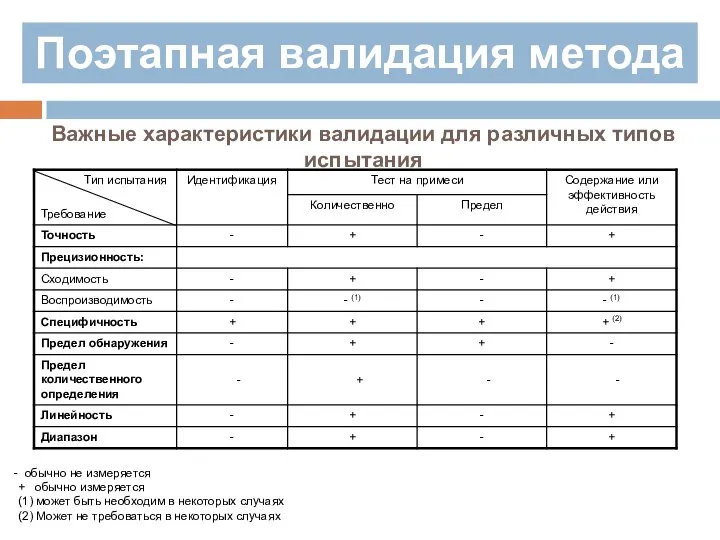
- 174. Поэтапная валидация метода Важные характеристики валидации для различных типов испытания обычно не измеряется + обычно измеряется
- 175. Поэтапная валидация метода Специфичность (Specificity) (Селективность) Руководство ICH Q2A использует термин «специфичность», несмотря на то что,
- 176. Поэтапная валидация метода Например, в случае лекарственного препарата изготовленного из стандартизированого растительного экстракта специфичность аналитической методики
- 177. Поэтапная валидация метода
- 178. Поэтапная валидация метода
- 179. Поэтапная валидация метода В случае лекарственного препарата изготовленного из субстанции, полученной химическим синтезом специфичность аналитической методики
- 180. Поэтапная валидация метода
- 181. Поэтапная валидация метода
- 182. Поэтапная валидация метода Селективность в анализе может принимать две ступени : Качественная — ступень, в которой
- 183. Поэтапная валидация метода Диапазон (Range). Разработка метода измерения предполагает предварительный выбор рабочего диапазона Рабочий диапазон зависит
- 184. Поэтапная валидация метода С целью проверки однородности дисперсий десять раз параллельно измеряют для концентраций на нижнем
- 185. Поэтапная валидация метода Точность (Accuracy) и правильность (Trueness) Точность — близость соглашения между результатом испытания и
- 186. Поэтапная валидация метода 1. Метод с плацебо с нулевым содержанием определяемого компонента. В методе с плацебо
- 187. Поэтапная валидация метода 3. Метод сравнения Сравнение результатов аналитической методики с результатами второй, независимой и провалидированной
- 188. Поэтапная валидация метода
- 189. Поэтапная валидация метода Прецизионность (precision). Прецизионность аналитической методики выражает степень близости (степень дисперсии) между сериями измерений,
- 190. Поэтапная валидация метода Во избежание недоразумений, слово “точность”, которое иногда используется для перевода «precision», должно относиться
- 191. Поэтапная валидация метода Оценка и расчет результатов проводится путем вычисления среднего значения, стандартного отклонения, коэффициента вариации
- 192. Поэтапная валидация метода Пример: Если нормы количественного содержания действующего вещества в фармацевтической субстанции составляют 100 ±
- 193. Поэтапная валидация метода Принятые критерии для точности во многом зависят от типа анализа. Американской ассоциацией аналитической
- 194. Поэтапная валидация метода Для оценивания допустимых пределов сходимости и воспроизводимости иногда прибегают к так называемым критериям
- 195. Поэтапная валидация метода Воспроизводимость Воспроизводимость - это прецизионность в условиях, когда результаты испытания получены одним и
- 196. Поэтапная валидация метода Линейность Линейность аналитической методики доказана, если в выбранном диапазоне применения можно показать прямо
- 197. Поэтапная валидация метода Основные и статистически обоснованные принципы построения и оценивания калибровочных регрессионных зависимостей изложено в
- 198. Поэтапная валидация метода Тест Манделя. Во время статистической проверки на линейность, градуировочные данные используют для расчета
- 199. Поэтапная валидация метода Предел обнаружения (detection limit) Предел обнаружения отдельной аналитической методики представляет собой наименьшее количество
- 200. Поэтапная валидация метода Предел обнаружения (детектирования) для аналитического прибора LOD Предел обнаружения (детектирования) прибора — самое
- 201. Поэтапная валидация метода Для нехроматографических методов предел детектирования, выраженный как концентрация или количество , получают из
- 202. Поэтапная валидация метода Здесь калибровка выполняется с I независимыми калибровочными растворами (включая холостую пробу, если возможно
- 203. Поэтапная валидация метода Возврат (Recovery) Возврат (также употребляются термины «процентная мера правильности», «открываемость», «извлечение», «экстрагируемость».): частное
- 204. Поэтапная валидация метода Определение возврата добавкой активного ингредиента к плацебо (холостой пробе) Прибавьте точно установленное количество
- 205. Поэтапная валидация метода Определение возврата со стандартной добавкой Сделайте гомогенный образец плацебо (холостой пробы). Определите содержание
- 206. Поэтапная валидация метода Робасность Испытание на стабильность: внутрилабораторное исследование для изучения поведения аналитического процесса, когда производятся
- 207. Поэтапная валидация метода
- 208. Поэтапная валидация метода
- 209. Поэтапная валидация метода
- 210. Поэтапная валидация метода
- 211. Поэтапная валидация метода Итак, как же спланировать серии экспериментов для получения исчерпывающего отчета по валидации метода
- 212. Поэтапная валидация метода
- 214. Скачать презентацию
Слайд 2 Определение понятия процесса измерения.
Статистика в аналитической химии
Химия, и в частности
Определение понятия процесса измерения.
Статистика в аналитической химии
Химия, и в частности

Слайд 3Статистика в аналитической химии
Использование статистики в химических, клинических и фармацевтических лабораториях является
Статистика в аналитической химии
Использование статистики в химических, клинических и фармацевтических лабораториях является

Слайд 4Если мы проводим эксперимент, то мы почти всегда получаем результат с погрешностью.
Если мы проводим эксперимент, то мы почти всегда получаем результат с погрешностью.

Слайд 5Статистика в аналитической химии
При оценивании величины систематической погрешности предполагается проводить эксперимент большое
Статистика в аналитической химии
При оценивании величины систематической погрешности предполагается проводить эксперимент большое

Слайд 6Иллюстрация систематической погрешности
Статистика в аналитической химии
1. Производитель пипетки утверждает тот факт, что
Иллюстрация систематической погрешности
Статистика в аналитической химии
1. Производитель пипетки утверждает тот факт, что

Слайд 7Статистика в аналитической химии
Случайные и систематические ошибки в аналитической химии вызываются множеством
Статистика в аналитической химии
Случайные и систематические ошибки в аналитической химии вызываются множеством

Слайд 8Статистика в аналитической химии
Если отбросить ошибку пробоотбора, как непосредственно не относящуюся к
Статистика в аналитической химии
Если отбросить ошибку пробоотбора, как непосредственно не относящуюся к

Слайд 9Статистика в аналитической химии
Статистика в аналитической химии
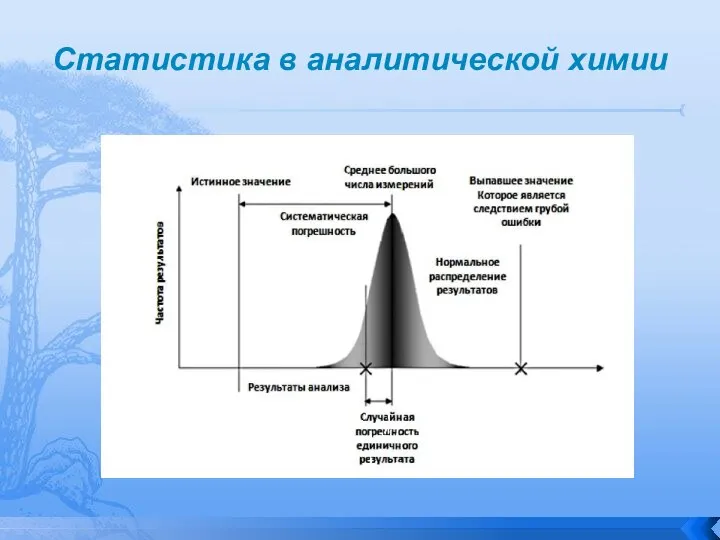
Слайд 10Статистика в аналитической химии
Статистика в аналитической химии
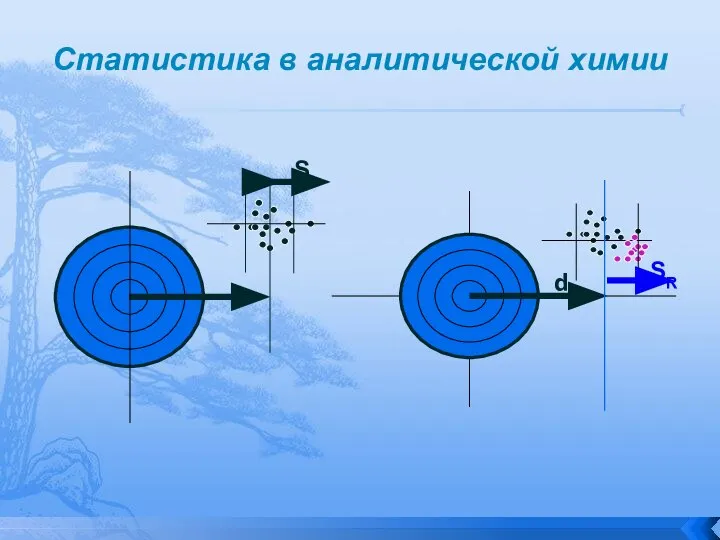
Слайд 11Статистика в аналитической химии
Основные статистические понятия в аналитическом измерении (генеральная совокупность и
Статистика в аналитической химии
Основные статистические понятия в аналитическом измерении (генеральная совокупность и

Слайд 12Статистика в аналитической химии
Мера центральной тенденции любой выборки - это число, характеризующее
Статистика в аналитической химии
Мера центральной тенденции любой выборки - это число, характеризующее

Слайд 13Статистика в аналитической химии
Медиана представляет собой срединное значение данных, расположенных в восходящем
Статистика в аналитической химии
Медиана представляет собой срединное значение данных, расположенных в восходящем

Слайд 14Статистика в аналитической химии
Среднее
Выборочное среднее (арифметическое среднее) это результат суммирования всех результатов
Статистика в аналитической химии
Среднее
Выборочное среднее (арифметическое среднее) это результат суммирования всех результатов

Слайд 15Статистика в аналитической химии
Среднее из n данных выбранных случайно из нормально распределенной
Статистика в аналитической химии
Среднее из n данных выбранных случайно из нормально распределенной
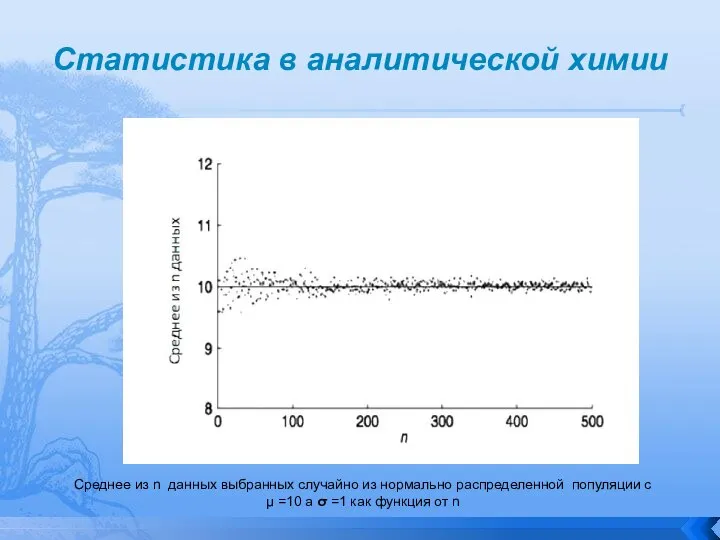
Слайд 16Статистика в аналитической химии
Реальные данные могут быть нормально распределены, но часто распределение
Статистика в аналитической химии
Реальные данные могут быть нормально распределены, но часто распределение

Слайд 17Статистика в аналитической химии
Стандартное отклонение и дисперсия
Разброс генеральной совокупности, демонстрируемый «тучностью» колоколообразной
Статистика в аналитической химии
Стандартное отклонение и дисперсия
Разброс генеральной совокупности, демонстрируемый «тучностью» колоколообразной

Слайд 18Статистика в аналитической химии
Относительное стандартное отклонение
Относительное стандартное отклонение (RSD), известное также как
Статистика в аналитической химии
Относительное стандартное отклонение
Относительное стандартное отклонение (RSD), известное также как

Слайд 19Статистика в аналитической химии
В математической статистике есть так называемая центральная предельная теорема,
Статистика в аналитической химии
В математической статистике есть так называемая центральная предельная теорема,

Слайд 20Статистика в аналитической химии
Статистика в аналитической химии
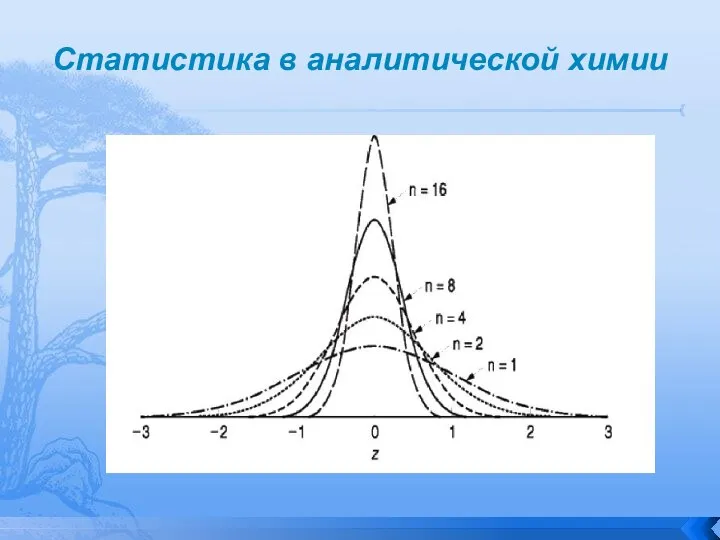
Слайд 21Статистика в аналитической химии
Несколько огорчает наличие корня квадратного от n в уравнениях
Статистика в аналитической химии
Несколько огорчает наличие корня квадратного от n в уравнениях

Слайд 22Статистика в аналитической химии
Доверительные интервалы и доверительные пределы
Стандартное отклонение среднего говорит нам
Статистика в аналитической химии
Доверительные интервалы и доверительные пределы
Стандартное отклонение среднего говорит нам

Слайд 23Статистика в аналитической химии
Строгий расчет границ доверительного интервала случайной величины возможен лишь
Статистика в аналитической химии
Строгий расчет границ доверительного интервала случайной величины возможен лишь

Слайд 24Статистика в аналитической химии
Параметры этой функции μ и σ характеризуют: μ -
Статистика в аналитической химии
Параметры этой функции μ и σ характеризуют: μ -

Слайд 25Статистика в аналитической химии
Численные значения коэффициентов пропорциональности t были впервые рассчитаны английским
Статистика в аналитической химии
Численные значения коэффициентов пропорциональности t были впервые рассчитаны английским

Слайд 26Статистика в аналитической химии
Величина меньше, чем s(x) (среднее точнее единичного). Для серии
Статистика в аналитической химии
Величина меньше, чем s(x) (среднее точнее единичного). Для серии

Слайд 27Зачем нужно проводить испытание гипотез?
Статистика в аналитической химии
Неизменно помни, что природа -
Зачем нужно проводить испытание гипотез?
Статистика в аналитической химии
Неизменно помни, что природа -

Слайд 28Одним из применений анализа полученных данных является возможность дать ответы на вопросы
Одним из применений анализа полученных данных является возможность дать ответы на вопросы

Слайд 29Статистическая значимость, или так называемый Р - уровень значимости - это основной
Статистическая значимость, или так называемый Р - уровень значимости - это основной

Слайд 30Статистика в аналитической химии
Статистика в аналитической химии
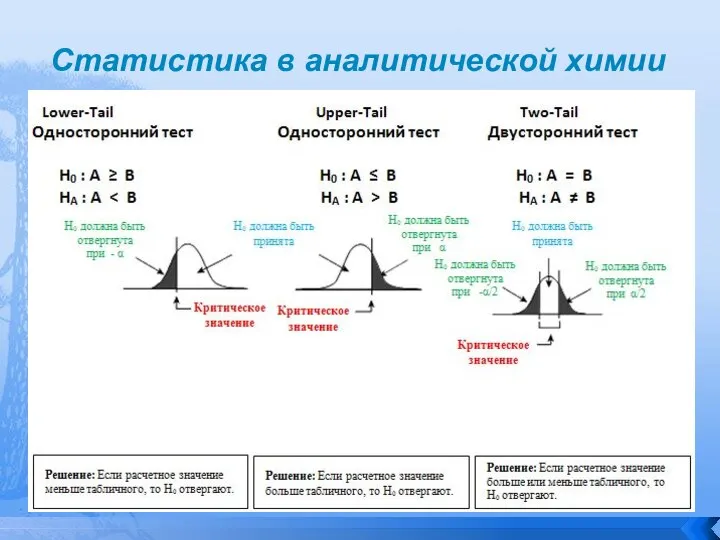
Слайд 31Статистика в аналитической химии
Проверка гипотез обычно проходит следующие этапы:
1. Определение используемой
Статистика в аналитической химии
Проверка гипотез обычно проходит следующие этапы:
1. Определение используемой

Слайд 32Статистика в аналитической химии
Односторонние и двусторонние критерии проверки значимости
Если цель исследования
Статистика в аналитической химии
Односторонние и двусторонние критерии проверки значимости
Если цель исследования

Слайд 33Статистика в аналитической химии
Статистические критерии - это инструмент, для того чтобы иметь
Статистика в аналитической химии
Статистические критерии - это инструмент, для того чтобы иметь

Слайд 34Статистика в аналитической химии
Если же есть дополнительная информация, например, из предшествующих экспериментов,
Статистика в аналитической химии
Если же есть дополнительная информация, например, из предшествующих экспериментов,

Слайд 35Статистика в аналитической химии
Выбор подходящего статистического метода для проверки гипотезы
Критерий t-Стьюдента для
Статистика в аналитической химии
Выбор подходящего статистического метода для проверки гипотезы
Критерий t-Стьюдента для

Слайд 36Статистика в аналитической химии
Критерий t-Стьюдента для зависимых выборок
Этот метод позволяет проверить
Статистика в аналитической химии
Критерий t-Стьюдента для зависимых выборок
Этот метод позволяет проверить

Слайд 38Статистика в аналитической химии
Что такое метод ANOVA ?
ANOVA (Analysis of Variance) –
Статистика в аналитической химии
Что такое метод ANOVA ?
ANOVA (Analysis of Variance) –

Слайд 39Статистика в аналитической химии
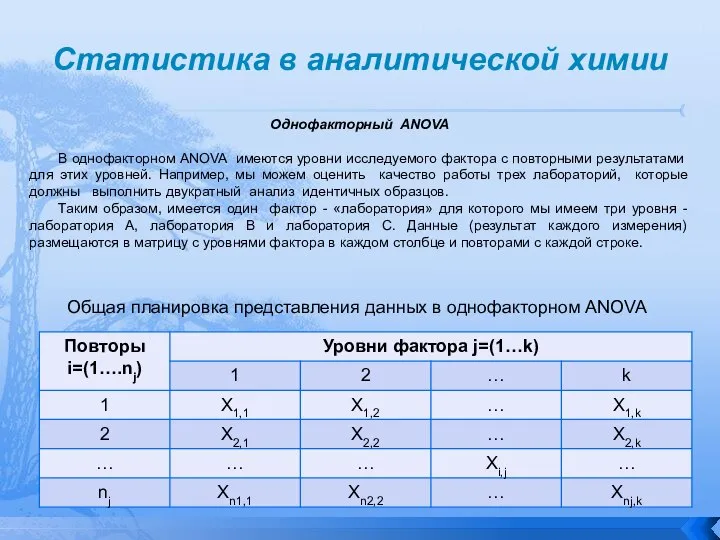
Однофакторный ANOVA
В однофакторном ANOVA имеются уровни исследуемого фактора с
Статистика в аналитической химии
Однофакторный ANOVA
В однофакторном ANOVA имеются уровни исследуемого фактора с
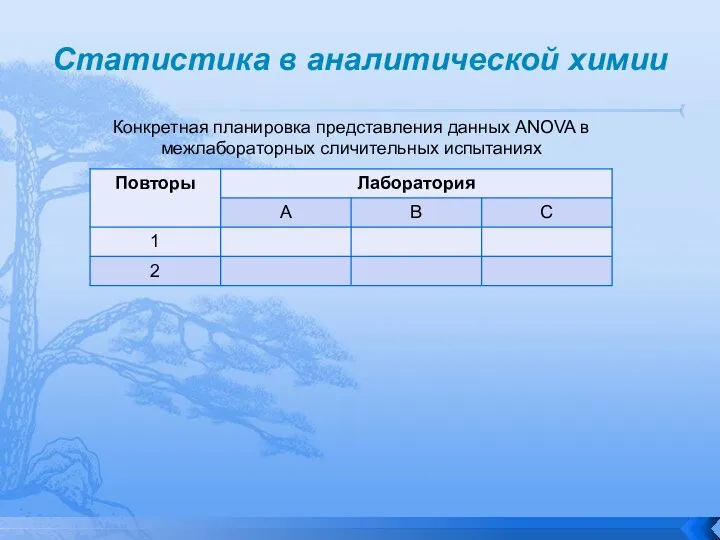
Слайд 40Статистика в аналитической химии
Конкретная планировка представления данных ANOVA в межлабораторных сличительных испытаниях
Статистика в аналитической химии
Конкретная планировка представления данных ANOVA в межлабораторных сличительных испытаниях
Слайд 41Статистика в аналитической химии
Этапы в вычислении ANOVA таковы:
Статистика в аналитической химии
Этапы в вычислении ANOVA таковы:

Слайд 42Статистика в аналитической химии
Статистика в аналитической химии

Слайд 43Статистика в аналитической химии
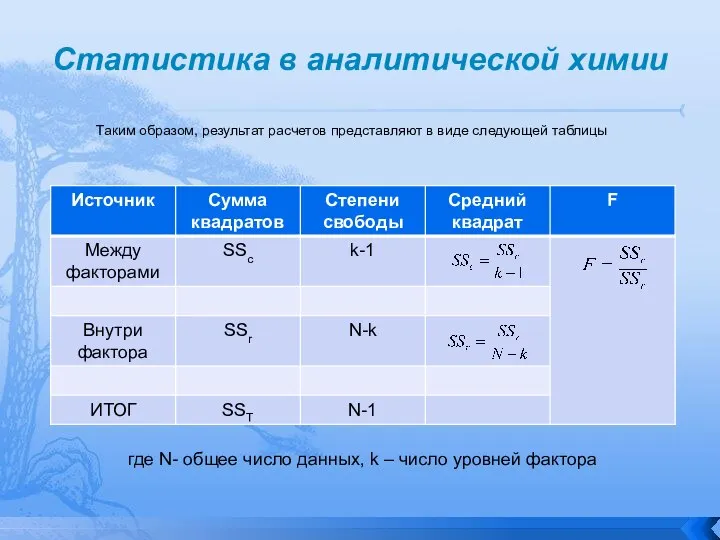
Таким образом, результат расчетов представляют в виде следующей таблицы
где
Статистика в аналитической химии
Таким образом, результат расчетов представляют в виде следующей таблицы
где
Слайд 44Статистика в аналитической химии
Остаточный средний квадрат является оценкой средней дисперсии результатов в
Статистика в аналитической химии
Остаточный средний квадрат является оценкой средней дисперсии результатов в

Слайд 45Статистика в аналитической химии
Матрица данных в этом случае будет иметь пять колонок
Статистика в аналитической химии
Матрица данных в этом случае будет иметь пять колонок

Слайд 46Статистика в аналитической химии
Проверка на нормальность распределения данных
Многие статистические параметры, используемые химиками
Статистика в аналитической химии
Проверка на нормальность распределения данных
Многие статистические параметры, используемые химиками

Слайд 47Статистика в аналитической химии
Критерий согласия Пирсона (χ2) применяют для проверки гипотезы о
Статистика в аналитической химии
Критерий согласия Пирсона (χ2) применяют для проверки гипотезы о

Слайд 48Статистика в аналитической химии
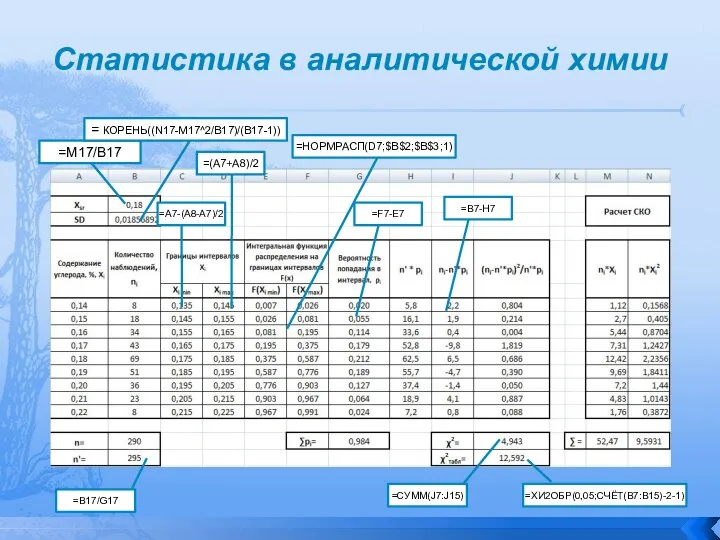
Далее определяют вспомогательные данные для расчета наблюдаемого критерия согласия
Статистика в аналитической химии
Далее определяют вспомогательные данные для расчета наблюдаемого критерия согласия

Слайд 49Статистика в аналитической химии
Статистика в аналитической химии
Слайд 50Статистика в аналитической химии
Критерий Шапиро-Уилка.
Этот критерий является одним из наиболее мощных
Статистика в аналитической химии
Критерий Шапиро-Уилка.
Этот критерий является одним из наиболее мощных

Слайд 51Статистика в аналитической химии
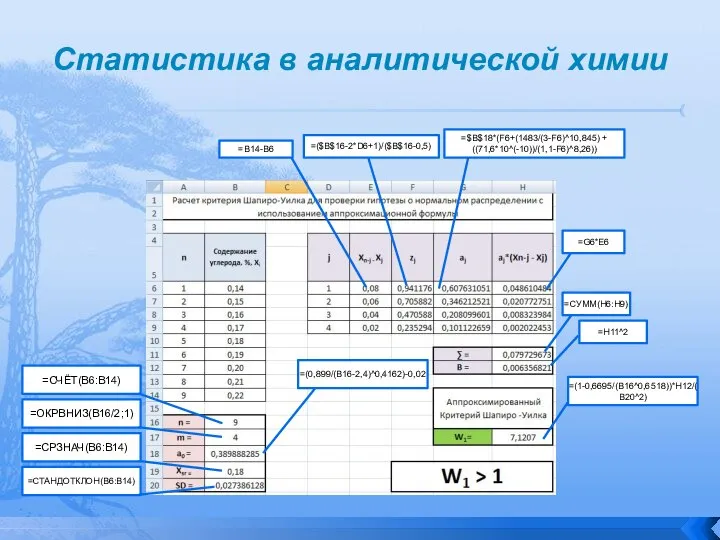
Этот критерий применяется, когда выборка содержит малое количество
Статистика в аналитической химии
Этот критерий применяется, когда выборка содержит малое количество

Слайд 52Статистика в аналитической химии
Статистика в аналитической химии
Слайд 53Статистика в аналитической химии
Имеется и полезная графическая процедура для испытания нормальности набора
Статистика в аналитической химии
Имеется и полезная графическая процедура для испытания нормальности набора

Слайд 54Статистика в аналитической химии
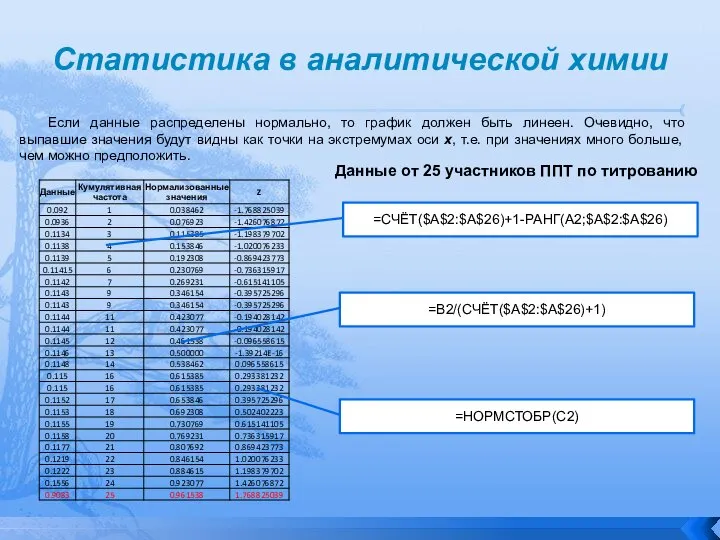
Если данные распределены нормально, то график должен быть линеен.
Статистика в аналитической химии
Если данные распределены нормально, то график должен быть линеен.
Слайд 55Статистика в аналитической химии
Ранкит-график первичной обработки данных
Очевидно, что точка 0.9083 М не
Статистика в аналитической химии
Ранкит-график первичной обработки данных
Очевидно, что точка 0.9083 М не

Слайд 56Статистика в аналитической химии
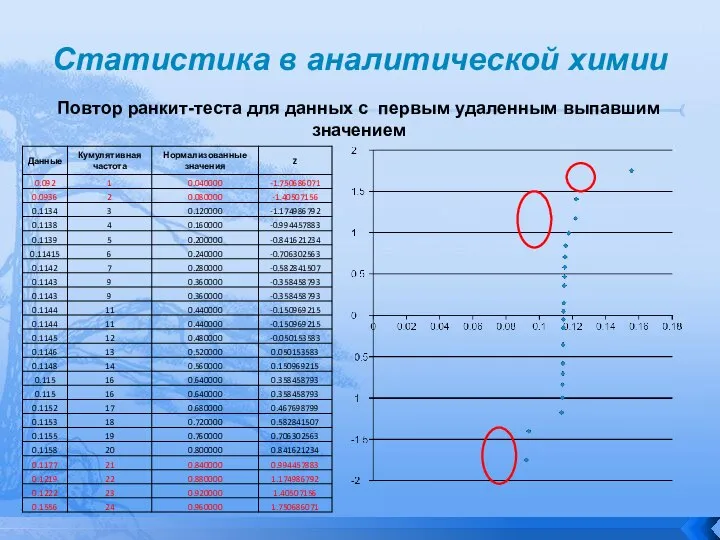
Повтор ранкит-теста для данных с первым удаленным выпавшим значением
Статистика в аналитической химии
Повтор ранкит-теста для данных с первым удаленным выпавшим значением
Слайд 57Статистика в аналитической химии
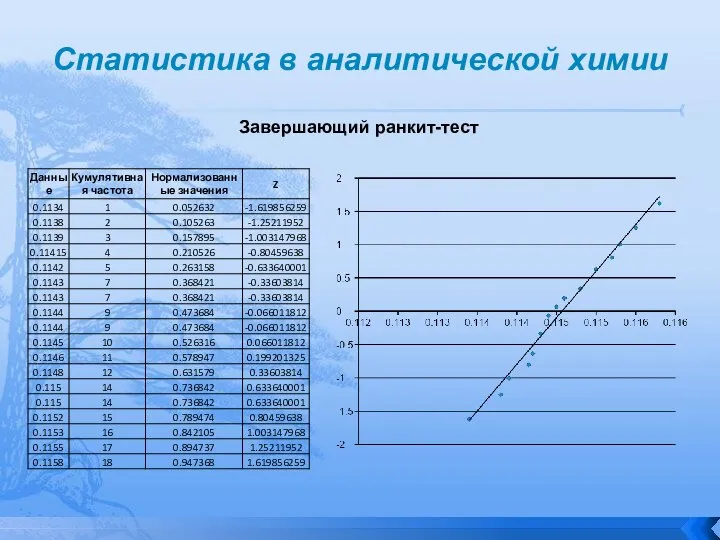
Завершающий ранкит-тест
Статистика в аналитической химии
Завершающий ранкит-тест
Слайд 58Статистика в аналитической химии
Очевидно, что точки-данные 0.092, 0.0936, 0.1177, 0.1219, 0.1222, и
Статистика в аналитической химии
Очевидно, что точки-данные 0.092, 0.0936, 0.1177, 0.1219, 0.1222, и

Слайд 59Статистика в аналитической химии
Тесты на выпавшие значения
Выпавшее значение, есть значение, которое не
Статистика в аналитической химии
Тесты на выпавшие значения
Выпавшее значение, есть значение, которое не

Слайд 60Статистика в аналитической химии
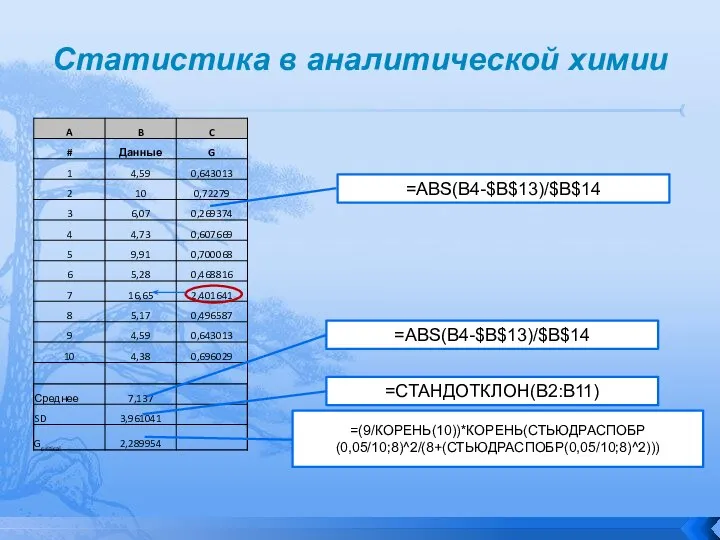
Результат применения Excell для выполнения теста Грубба рассмотрим на
Статистика в аналитической химии
Результат применения Excell для выполнения теста Грубба рассмотрим на

Слайд 61Статистика в аналитической химии
Статистика в аналитической химии
Слайд 62Статистика в аналитической химии
Так как Gsuspect > Gcritical значение 16.65 мг/г является
Статистика в аналитической химии
Так как Gsuspect > Gcritical значение 16.65 мг/г является

Слайд 63Статистика в аналитической химии
Односторонний t - тест
Систематическая погрешность в аналитической методике
Статистика в аналитической химии
Односторонний t - тест
Систематическая погрешность в аналитической методике

Слайд 64ПРИМЕР :
Содержание фтора в зубной пасте согласно метода измеряется с использованием ионселективного
ПРИМЕР :
Содержание фтора в зубной пасте согласно метода измеряется с использованием ионселективного

Слайд 65Статистика в аналитической химии
Статистика в аналитической химии
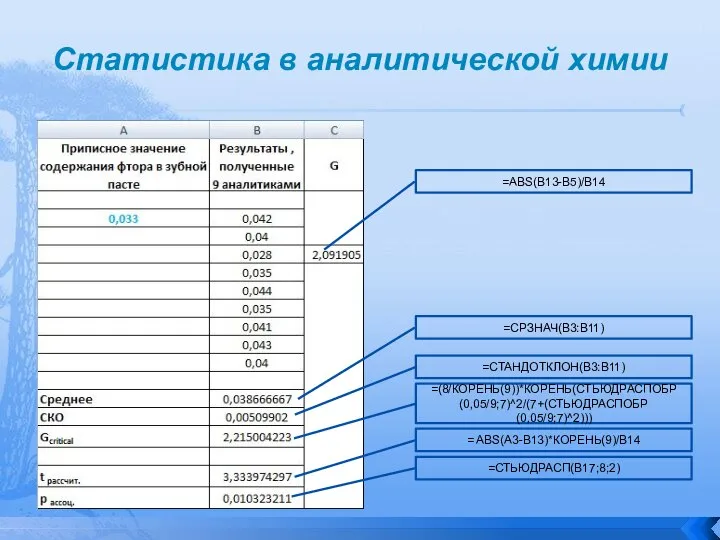
Слайд 66Приписанное значение лежит непосредственно за 95% доверительного интервала, что дает нам возможность
Приписанное значение лежит непосредственно за 95% доверительного интервала, что дает нам возможность

Слайд 67Статистика в аналитической химии
Парный t - тест
В некоторых случаях у нас
Статистика в аналитической химии
Парный t - тест
В некоторых случаях у нас

Слайд 68Статистика в аналитической химии
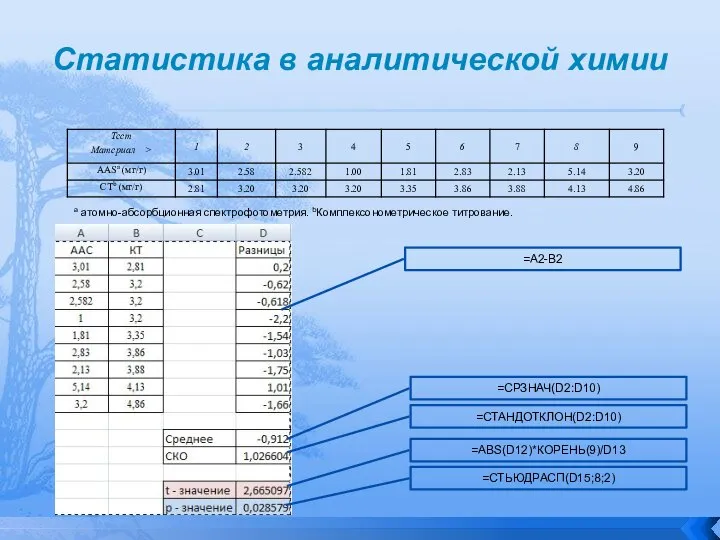
a атомно-абсорбционная спектрофотометрия. bКомплексонометрическое титрование.
Статистика в аналитической химии
a атомно-абсорбционная спектрофотометрия. bКомплексонометрическое титрование.
Слайд 69Статистика в аналитической химии
Вероятность того, что между методиками нет разницы, рассчитанная по
Статистика в аналитической химии
Вероятность того, что между методиками нет разницы, рассчитанная по

Слайд 70Статистика в аналитической химии
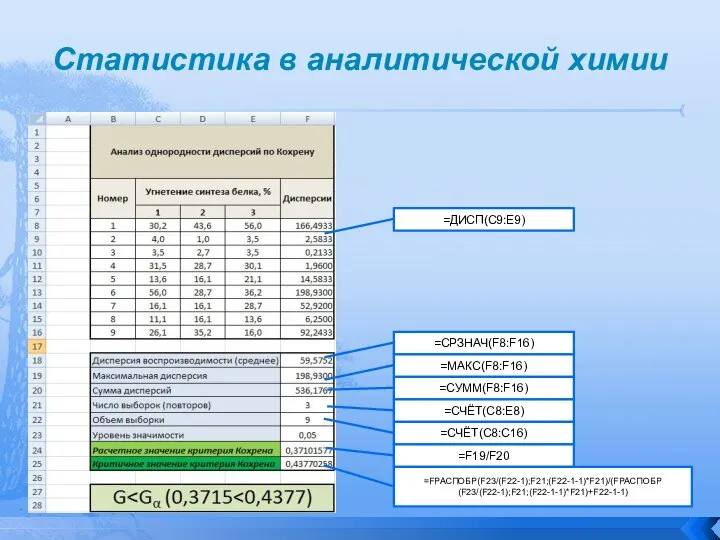
Наиболее часто используемые тесты однородности дисперсий двух и более
Статистика в аналитической химии
Наиболее часто используемые тесты однородности дисперсий двух и более

Слайд 71Статистика в аналитической химии
Статистика в аналитической химии

Слайд 72Статистика в аналитической химии
Статистика в аналитической химии
Слайд 73Статистика в аналитической химии
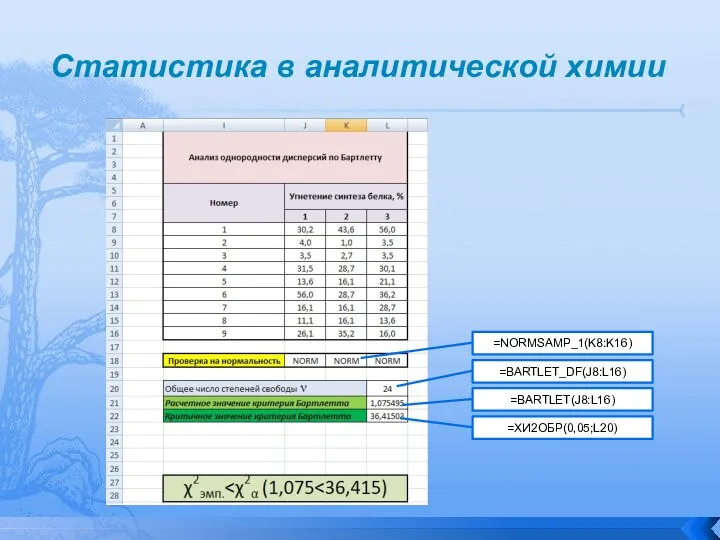
Анализ однородности дисперсий по Бартлетту
Назначение. Проверка гипотезы о
Статистика в аналитической химии
Анализ однородности дисперсий по Бартлетту
Назначение. Проверка гипотезы о

Слайд 74Статистика в аналитической химии
Если рассчитанное значение χ2 больше или равно критическому значению,
Статистика в аналитической химии
Если рассчитанное значение χ2 больше или равно критическому значению,

Слайд 75Статистика в аналитической химии
Статистика в аналитической химии
Слайд 76Статистика в аналитической химии
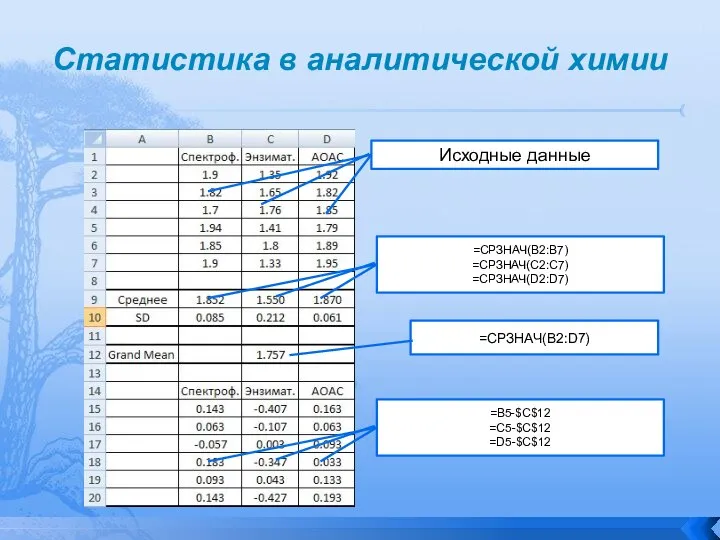
ANOVA в Excel
Excel предлагает три варианта применения ANOVA
Статистика в аналитической химии
ANOVA в Excel
Excel предлагает три варианта применения ANOVA

Слайд 77Статистика в аналитической химии
Статистика в аналитической химии
Слайд 78Статистика в аналитической химии
Статистика в аналитической химии
Слайд 79Статистика в аналитической химии
C применением надстройки «Анализ данных» все значительно упрощается
Статистика в аналитической химии
C применением надстройки «Анализ данных» все значительно упрощается
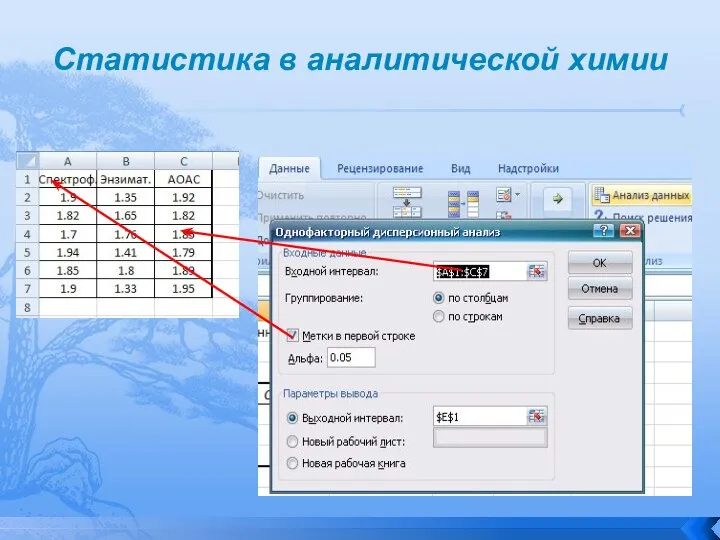
Слайд 80Статистика в аналитической химии
Статистика в аналитической химии
Слайд 81Статистика в аналитической химии
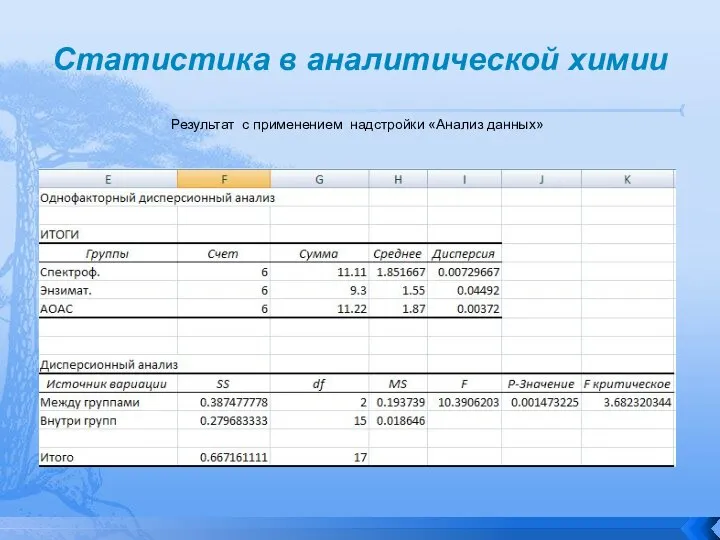
Результат с применением надстройки «Анализ данных»
Статистика в аналитической химии
Результат с применением надстройки «Анализ данных»
Слайд 82Статистика в аналитической химии
Таким образом значение F составляет 10.39062 с ассоциированной вероятностью
Статистика в аналитической химии
Таким образом значение F составляет 10.39062 с ассоциированной вероятностью

Слайд 83Статистика в аналитической химии
Реализация метода ANOVA с использованием статистических программых продуктов Minitab16
Статистика в аналитической химии
Реализация метода ANOVA с использованием статистических программых продуктов Minitab16

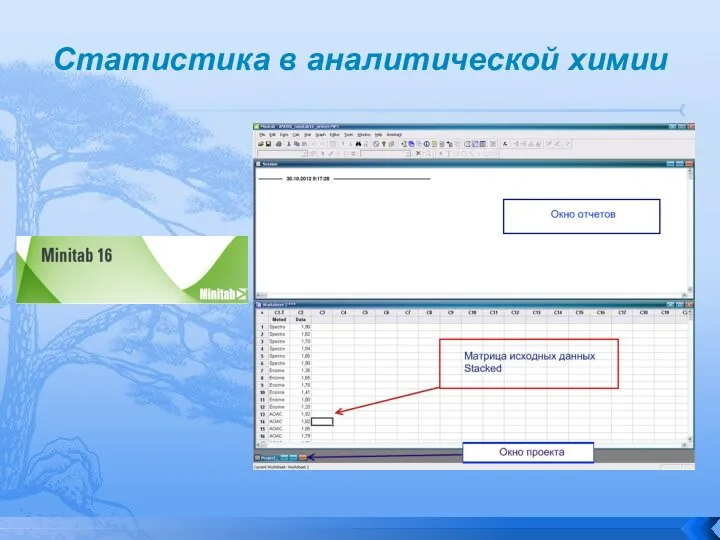
Слайд 84Статистика в аналитической химии
Статистика в аналитической химии
Слайд 85Статистика в аналитической химии
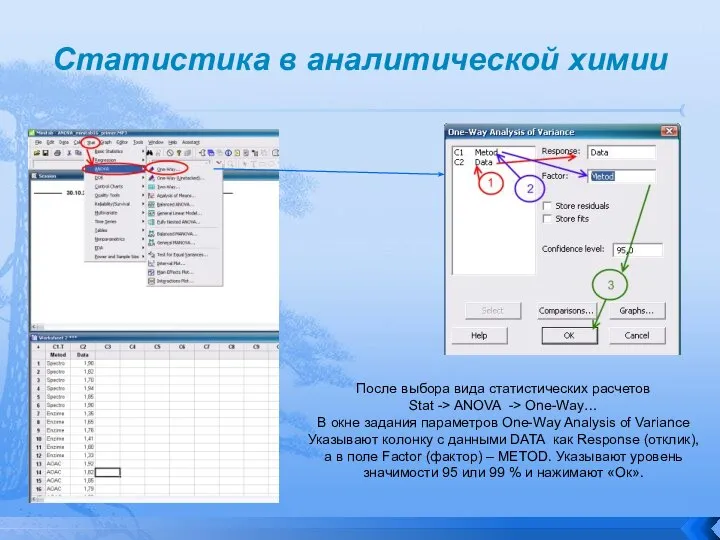
После выбора вида статистических расчетов
Stat -> ANOVA ->
Статистика в аналитической химии
После выбора вида статистических расчетов
Stat -> ANOVA ->
Слайд 86Статистика в аналитической химии
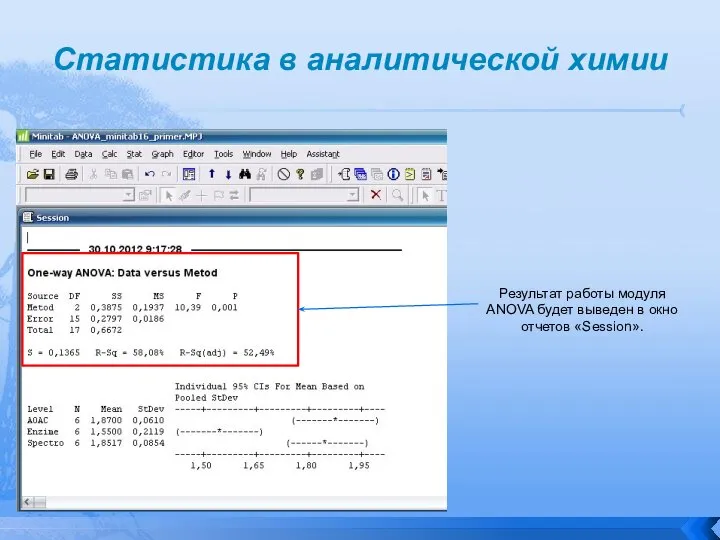
Результат работы модуля ANOVA будет выведен в окно отчетов
Статистика в аналитической химии
Результат работы модуля ANOVA будет выведен в окно отчетов
Слайд 87Статистика в аналитической химии
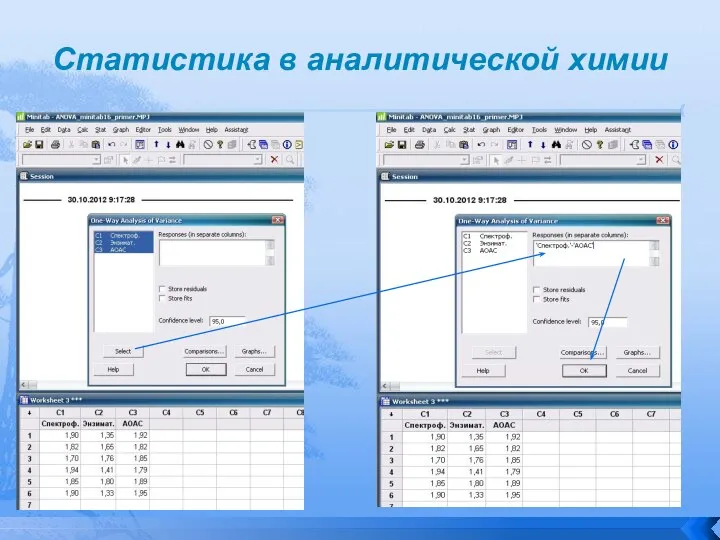
Рассмотрим реализацию ANOVA с помощью Minitab 16 с набором
Статистика в аналитической химии
Рассмотрим реализацию ANOVA с помощью Minitab 16 с набором

Слайд 88Статистика в аналитической химии
Статистика в аналитической химии
Слайд 89Статистика в аналитической химии
Результат работы модуля ANOVA будет выведен в окно отчетов
Статистика в аналитической химии
Результат работы модуля ANOVA будет выведен в окно отчетов
Слайд 90Статистика в аналитической химии
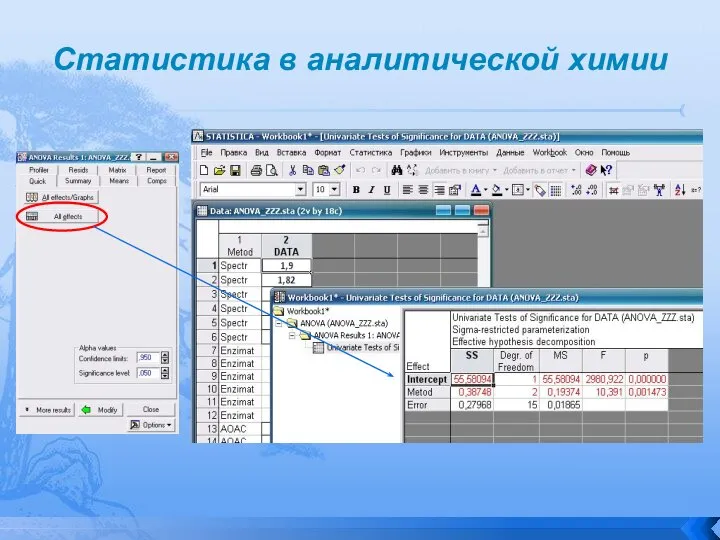
Рассмотрим реализацию ANOVA с помощью Statistica 6.0 . Эта
Статистика в аналитической химии
Рассмотрим реализацию ANOVA с помощью Statistica 6.0 . Эта

Слайд 91Статистика в аналитической химии
Статистика в аналитической химии
Слайд 92Статистика в аналитической химии
Статистика в аналитической химии
Слайд 93Статистика в аналитической химии
Статистика в аналитической химии
Слайд 94Статистика в аналитической химии
Статистика в аналитической химии
Слайд 95Статистика в аналитической химии
* это непараметрический аналог парного критерия Стьюдента (t-критерий для
Статистика в аналитической химии
* это непараметрический аналог парного критерия Стьюдента (t-критерий для

Слайд 96Статистика в аналитической химии
Чтобы автоматизировать вычисление критических значений статистики W, необходимо определить
Статистика в аналитической химии
Чтобы автоматизировать вычисление критических значений статистики W, необходимо определить

Слайд 97Статистика в аналитической химии
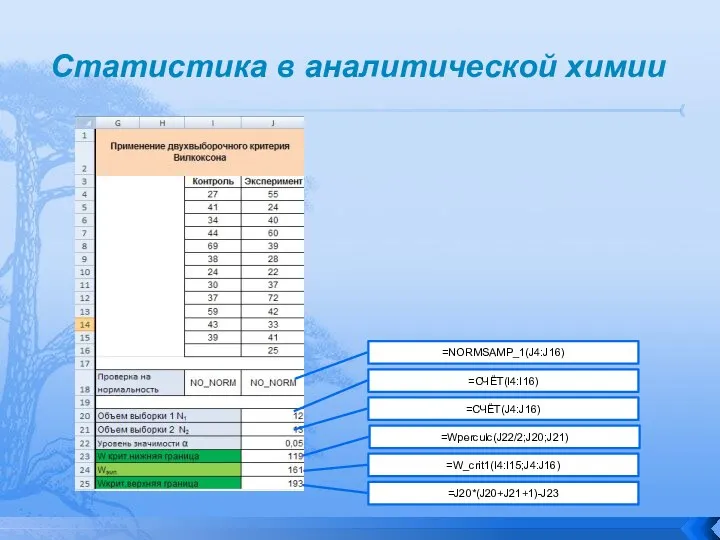
Двухвыборочный критерий Вилкоксона
Назначение. Проверка гипотезы о равенстве средних
Статистика в аналитической химии
Двухвыборочный критерий Вилкоксона
Назначение. Проверка гипотезы о равенстве средних

Слайд 98Статистика в аналитической химии
Статистика в аналитической химии
Слайд 99Статистика в аналитической химии
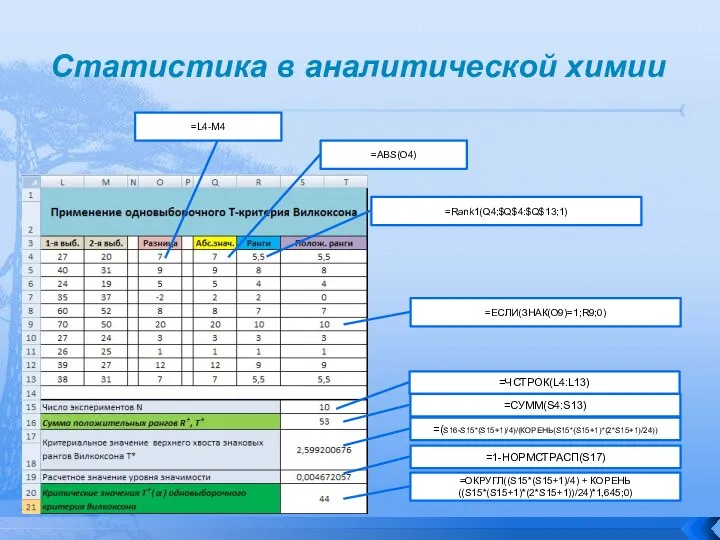
Критерий T- Вилкоксона для парных наблюдений (одновыборочный критерий Вилкоксона,
Статистика в аналитической химии
Критерий T- Вилкоксона для парных наблюдений (одновыборочный критерий Вилкоксона,

Слайд 100Статистика в аналитической химии
Примечание. Данный критерий устойчив к умеренным отклонениям от принятых
Статистика в аналитической химии
Примечание. Данный критерий устойчив к умеренным отклонениям от принятых

Слайд 101Статистика в аналитической химии
Статистика в аналитической химии
Слайд 102Статистика в аналитической химии
Калибровка является сердцем химического анализа и процесса посредством которого
Статистика в аналитической химии
Калибровка является сердцем химического анализа и процесса посредством которого

Слайд 103Статистика в аналитической химии
Любое конкретное измерение (уi) будет подвержено погрешностям измерения, таким
Статистика в аналитической химии
Любое конкретное измерение (уi) будет подвержено погрешностям измерения, таким

Слайд 104Статистика в аналитической химии
Эти коэффициенты оценивают действительную функцию, ограниченную неминуемым разбросом, который
Статистика в аналитической химии
Эти коэффициенты оценивают действительную функцию, ограниченную неминуемым разбросом, который

Слайд 105Статистика в аналитической химии
Стандартные отклонения могут быть вычислены и для коэффициентов :
Стандартное
Статистика в аналитической химии
Стандартные отклонения могут быть вычислены и для коэффициентов :
Стандартное

Слайд 106Статистика в аналитической химии
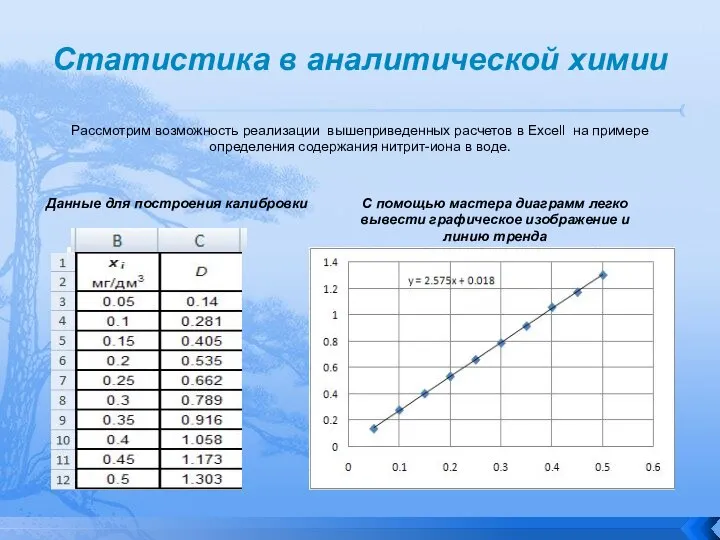
Рассмотрим возможность реализации вышеприведенных расчетов в Excell на примере
Статистика в аналитической химии
Рассмотрим возможность реализации вышеприведенных расчетов в Excell на примере
Слайд 107Статистика в аналитической химии
Для реализации вышеприведенных расчетов в Excell необходимо воспользоваться функцией-массивом
Статистика в аналитической химии
Для реализации вышеприведенных расчетов в Excell необходимо воспользоваться функцией-массивом
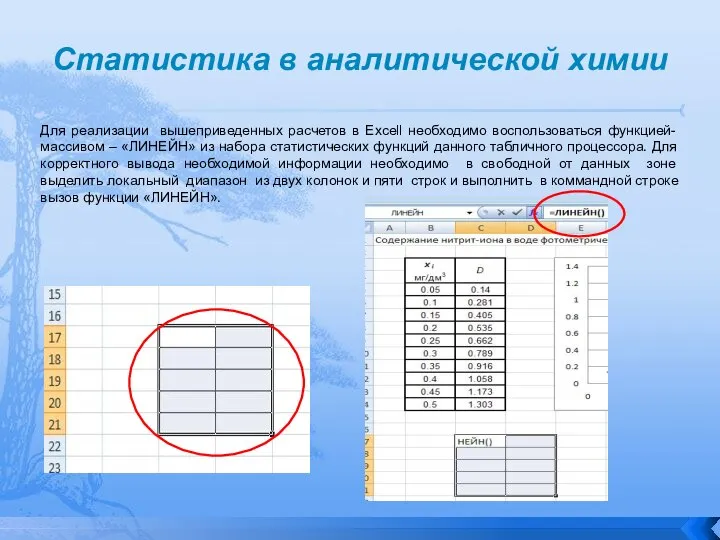
Слайд 108Статистика в аналитической химии
После вызова функции «ЛИНЕЙН» появится окно задания необходимых входных
Статистика в аналитической химии
После вызова функции «ЛИНЕЙН» появится окно задания необходимых входных
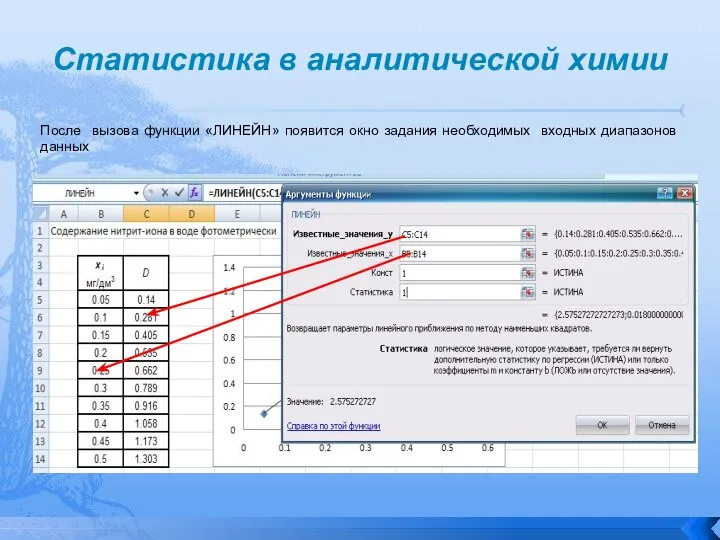
Слайд 109Статистика в аналитической химии
После вызова функции «ЛИНЕЙН» и задания необходимых данных, для
Статистика в аналитической химии
После вызова функции «ЛИНЕЙН» и задания необходимых данных, для
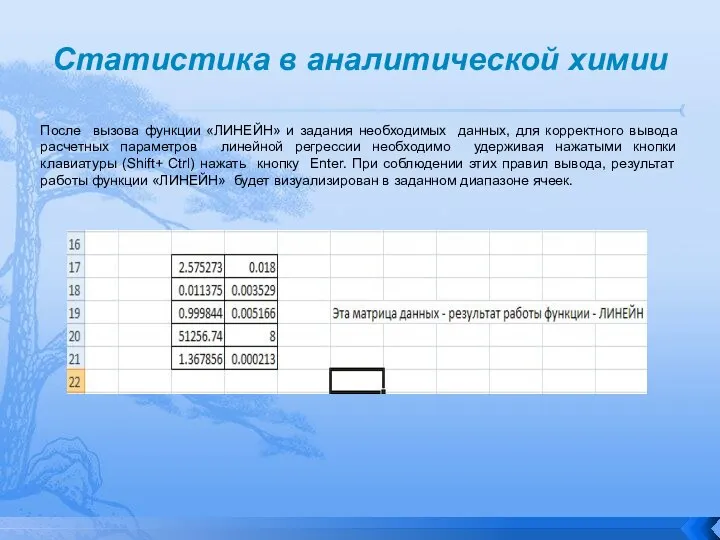
Слайд 110Статистика в аналитической химии
Соответствие полученных данных функции «ЛИНЕЙН» параметрам линейной регрессии
Статистика в аналитической химии
Соответствие полученных данных функции «ЛИНЕЙН» параметрам линейной регрессии

Слайд 111Статистика в аналитической химии
Получение расширенных параметров линейной регрессии, согласно ISO 11095:1996 «Linear
Статистика в аналитической химии
Получение расширенных параметров линейной регрессии, согласно ISO 11095:1996 «Linear
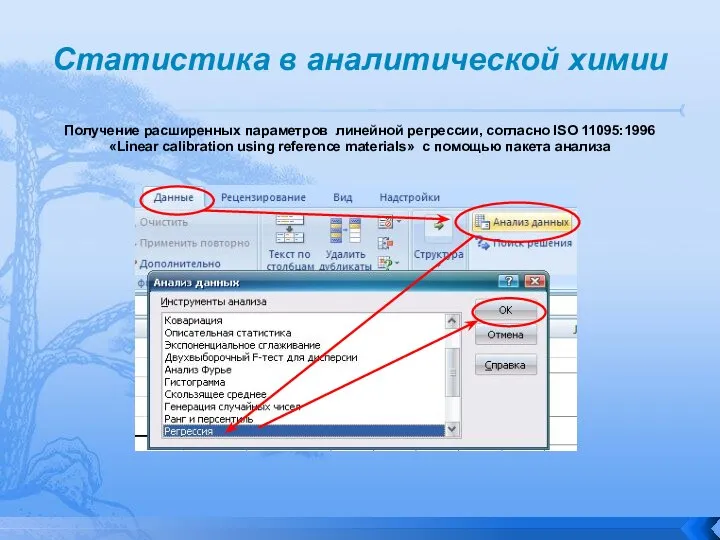
Слайд 112Статистика в аналитической химии
Статистика в аналитической химии
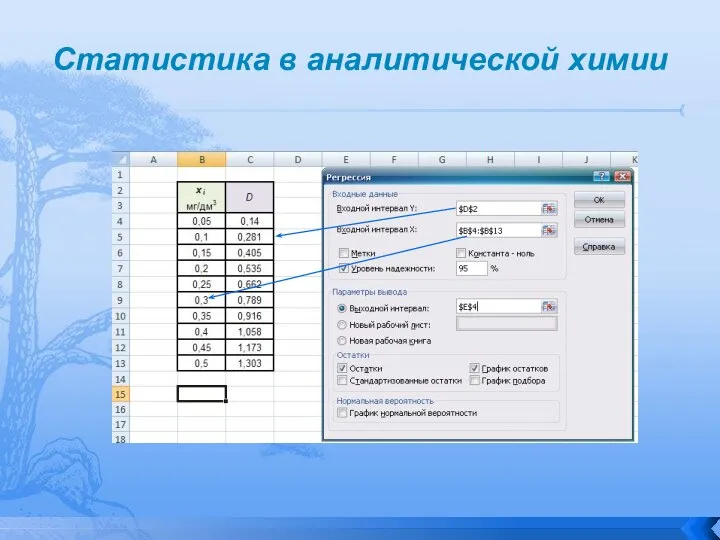
Слайд 113Статистика в аналитической химии
Статистика в аналитической химии
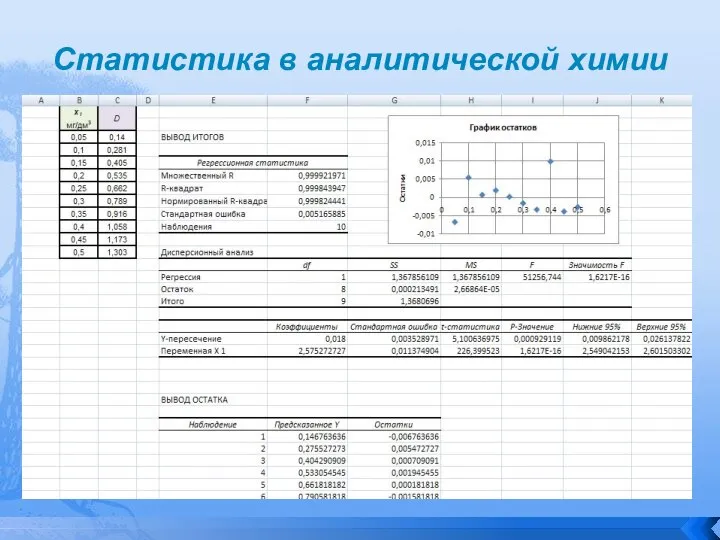
Слайд 114Статистика в аналитической химии
Метод контроля стабильности калибровки, согласно ГОСТ Р ИСО
Статистика в аналитической химии
Метод контроля стабильности калибровки, согласно ГОСТ Р ИСО

Слайд 115Отбирают m RM так, чтобы соответствующие им принятые значения заполняли диапазон значений,
Отбирают m RM так, чтобы соответствующие им принятые значения заполняли диапазон значений,

Слайд 116Карты Шухарта
Контрольные карты — график изменения параметров выборки, обычно средних и среднеквадратичного отклонения.
Карты Шухарта
Контрольные карты — график изменения параметров выборки, обычно средних и среднеквадратичного отклонения.

Слайд 117Карты Шухарта
Контрольные карты используются для оценки "контролируемости" или "неконтролируемости" процесса. Эту оценку
Карты Шухарта
Контрольные карты используются для оценки "контролируемости" или "неконтролируемости" процесса. Эту оценку

Слайд 118Карты Шухарта
КОНТРОЛЬНАЯ КАРТА СРЕДНИХ АРИФМЕТИЧЕСКИХ
Если генеральная совокупность имеет нормальное (или близкое
Карты Шухарта
КОНТРОЛЬНАЯ КАРТА СРЕДНИХ АРИФМЕТИЧЕСКИХ
Если генеральная совокупность имеет нормальное (или близкое

Слайд 119Карты Шухарта
Для построения графика, приведенного на рис., необходимо, чтобы значения μ и σ были известны. Их
Карты Шухарта
Для построения графика, приведенного на рис., необходимо, чтобы значения μ и σ были известны. Их

Слайд 120Карты Шухарта
1. Через равные промежутки времени проводится выборка объемом n и рассчитывается
Карты Шухарта
1. Через равные промежутки времени проводится выборка объемом n и рассчитывается

Слайд 121Карты Шухарта
Процедура ведения КК в сущности представляет собой не что иное, как
Карты Шухарта
Процедура ведения КК в сущности представляет собой не что иное, как

Слайд 122Карты Шухарта
Формулы расчета средней линии и границ для карт средних
Карты Шухарта
Формулы расчета средней линии и границ для карт средних

Слайд 123Карты Шухарта
Контрольные карты для индивидуальных значений (X)
В некоторых ситуациях для управления
Карты Шухарта
Контрольные карты для индивидуальных значений (X)
В некоторых ситуациях для управления

Слайд 124Карты Шухарта
На основе скользящих размахов вычисляют средний скользящий размах R, который используют
Карты Шухарта
На основе скользящих размахов вычисляют средний скользящий размах R, который используют

Слайд 125Карты Шухарта
Во время использования карт индивидуальных значений необходимо учитывать тот факт, что
Карты Шухарта
Во время использования карт индивидуальных значений необходимо учитывать тот факт, что

Слайд 126Карты Шухарта
Карты Шухарта

Слайд 127Карты Шухарта
МЕТОД УПРАВЛЕНИЯ И ИНТЕРПРЕТАЦИЯ КОНТРОЛЬНЫХ КАРТ ДЛЯ КОЛИЧЕСТВЕННЫХ ДАННЫХ
Система карт
Карты Шухарта
МЕТОД УПРАВЛЕНИЯ И ИНТЕРПРЕТАЦИЯ КОНТРОЛЬНЫХ КАРТ ДЛЯ КОЛИЧЕСТВЕННЫХ ДАННЫХ
Система карт

Слайд 128Статистика в аналитической химии
Что такое – «Неопределенность» ?
Понятие «неопределенность» (англ. «Uncertainty»),
Статистика в аналитической химии
Что такое – «Неопределенность» ?
Понятие «неопределенность» (англ. «Uncertainty»),

Слайд 129Статистика в аналитической химии
Рассмотрим теперь, как определяется неопределенность. Согласно EUROCHEM/CITAC Guide “Quantifying
Статистика в аналитической химии
Рассмотрим теперь, как определяется неопределенность. Согласно EUROCHEM/CITAC Guide “Quantifying

Слайд 130Статистика в аналитической химии
Обсуждение погрешностей данное выше известно как "классический подход" к
Статистика в аналитической химии
Обсуждение погрешностей данное выше известно как "классический подход" к

Слайд 131Статистика в аналитической химии
Использование «неопределённости» позволяет наглядно решать вопрос о соответствии (или
Статистика в аналитической химии
Использование «неопределённости» позволяет наглядно решать вопрос о соответствии (или

Слайд 132Графические методы выяснения источников неопределенности
Диаграмма Исикавы
Графические методы выяснения источников неопределенности
Диаграмма Исикавы
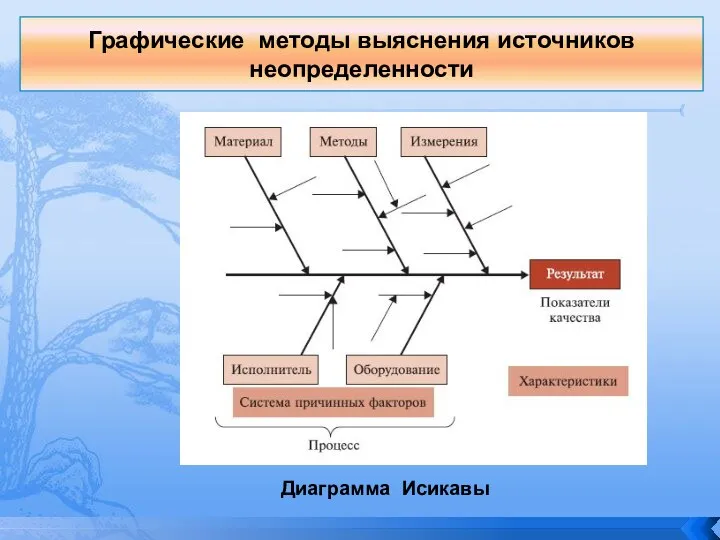
Слайд 133"Причинно-следственная диаграмма" («рыбий скелет»)
Автор метода: К. Исикава (Япония), 1952 г.
Назначение метода
Применяется
"Причинно-следственная диаграмма" («рыбий скелет»)
Автор метода: К. Исикава (Япония), 1952 г.
Назначение метода
Применяется

Слайд 134Общие правила построения
Прежде чем приступать к построению диаграммы, все участники должны прийти
Общие правила построения
Прежде чем приступать к построению диаграммы, все участники должны прийти

Слайд 135Достоинства метода
Диаграмма Исикавы позволяет:
стимулировать творческое мышление;
представить взаимосвязь между причинами и сопоставить их
Диаграмма Исикавы позволяет:
стимулировать творческое мышление;
представить взаимосвязь между причинами и сопоставить их

Слайд 136Графические методы выяснения источников неопределенности
Графические методы выяснения источников неопределенности
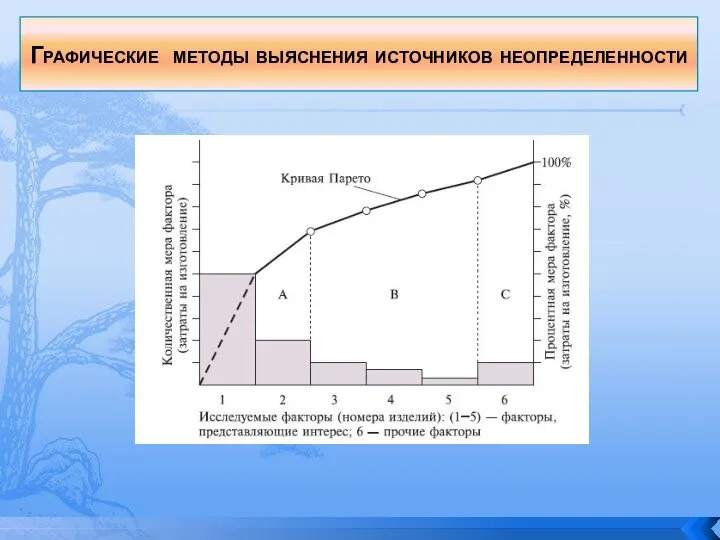
Слайд 137Авторы метода: В. Парето (Италия), 1897 г, М. Лоренц (США), 1979 г.
Назначение
Авторы метода: В. Парето (Италия), 1897 г, М. Лоренц (США), 1979 г.
Назначение

Слайд 138Общие правила построения диаграммы Парето
Решить, какие проблемы (причины проблем) надлежит исследовать, какие
Общие правила построения диаграммы Парето
Решить, какие проблемы (причины проблем) надлежит исследовать, какие

Слайд 139Достоинства метода
Простота и наглядность делают возможным использование диаграммы Парето специалистами, не имеющими
Достоинства метода
Простота и наглядность делают возможным использование диаграммы Парето специалистами, не имеющими

Слайд 140Процесс оценки неопределенности согласно руководства EURACHEM /CITAC
Процесс оценки неопределенности согласно руководства EURACHEM /CITAC
Слайд 141Процесс оценки неопределенности согласно руководства EURACHEM /CITAC
Процесс оценки неопределенности согласно руководства EURACHEM /CITAC
Слайд 142Альтернативный процесс оценки неопределенности согласно руководства NORDTEST TR 537
В руководстве NORDTEST TR
Альтернативный процесс оценки неопределенности согласно руководства NORDTEST TR 537
В руководстве NORDTEST TR
Слайд 143Современные методы оценки неопределенности
Стандарт ISO/IEC 17025:2006 определяет международное признание результатов испытаний и
Современные методы оценки неопределенности
Стандарт ISO/IEC 17025:2006 определяет международное признание результатов испытаний и

Слайд 144Современные методы оценки неопределенности
Основные термины и положения по оцениванию неопределенности измерений, согласно
Современные методы оценки неопределенности
Основные термины и положения по оцениванию неопределенности измерений, согласно

Слайд 145Современные методы оценки неопределенности
Стандартная неопределенность — неопределенность результата измерений, выраженная как стандартное
Современные методы оценки неопределенности
Стандартная неопределенность — неопределенность результата измерений, выраженная как стандартное

Слайд 146Современные методы оценки неопределенности
Основные положения концепции неопределенности :
1. Все составляющие неопределенности в
Современные методы оценки неопределенности
Основные положения концепции неопределенности :
1. Все составляющие неопределенности в

Слайд 147Современные методы оценки неопределенности
5. Интервальной оценкой неопределенности является расширенная неопределенность U, которую
Современные методы оценки неопределенности
5. Интервальной оценкой неопределенности является расширенная неопределенность U, которую

Слайд 148Современные методы оценки неопределенности
3. Коэффициенты чувствительности. Расчет их необходим для определения вклада
Современные методы оценки неопределенности
3. Коэффициенты чувствительности. Расчет их необходим для определения вклада

Слайд 149Современные методы оценки неопределенности
Современные методы оценки неопределенности

Слайд 150Современные методы оценки неопределенности
Важным фактором корректной оценки неопределенности является составление модельного уравнения.
Современные методы оценки неопределенности
Важным фактором корректной оценки неопределенности является составление модельного уравнения.

Слайд 151Современные методы оценки неопределенности
Современные методы оценки неопределенности
Слайд 152Современные методы оценки неопределенности
Современные методы оценки неопределенности
Слайд 153Современные методы оценки неопределенности
Недостатки подхода GUM к оценке неопределенности
В основе общего подхода
Современные методы оценки неопределенности
Недостатки подхода GUM к оценке неопределенности
В основе общего подхода

Слайд 154Современные методы оценки неопределенности
Основываясь на указанных недостатках, было предложено применить метод статистического
Современные методы оценки неопределенности
Основываясь на указанных недостатках, было предложено применить метод статистического

Слайд 155Современные методы оценки неопределенности
2. Расчет параметров бюджета неопределенности (расширенной и стандартной суммарной
Современные методы оценки неопределенности
2. Расчет параметров бюджета неопределенности (расширенной и стандартной суммарной

Слайд 156Современные методы оценки неопределенности
- расширенную неопределенность для заданного уровня доверия. Для
Современные методы оценки неопределенности
- расширенную неопределенность для заданного уровня доверия. Для

Слайд 157Современные методы оценки неопределенности
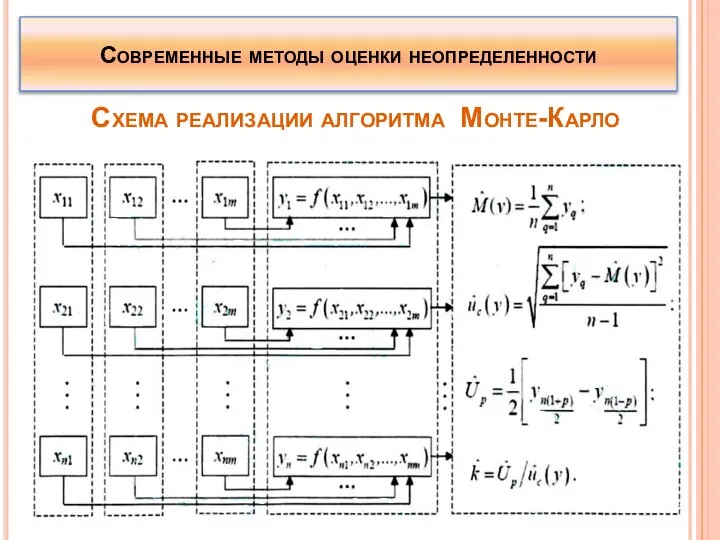
Схема реализации алгоритма Монте-Карло
Современные методы оценки неопределенности
Схема реализации алгоритма Монте-Карло
Слайд 158Современные методы оценки неопределенности
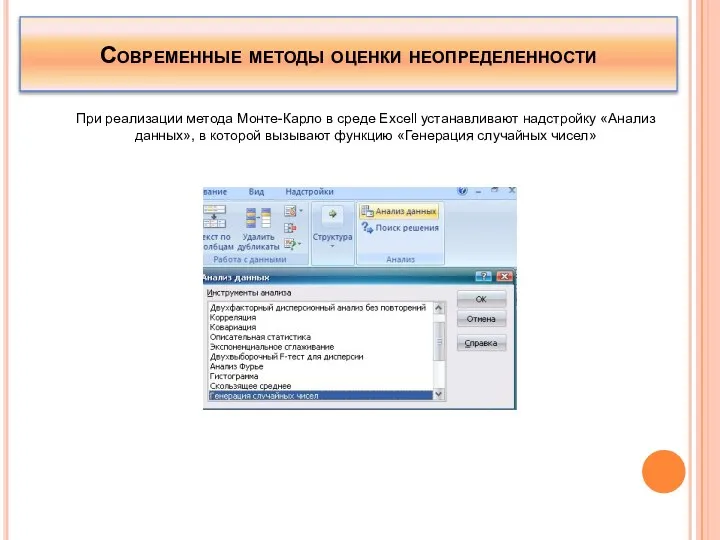
При реализации метода Монте-Карло в среде Excell устанавливают надстройку
Современные методы оценки неопределенности
При реализации метода Монте-Карло в среде Excell устанавливают надстройку
Слайд 159Современные методы оценки неопределенности
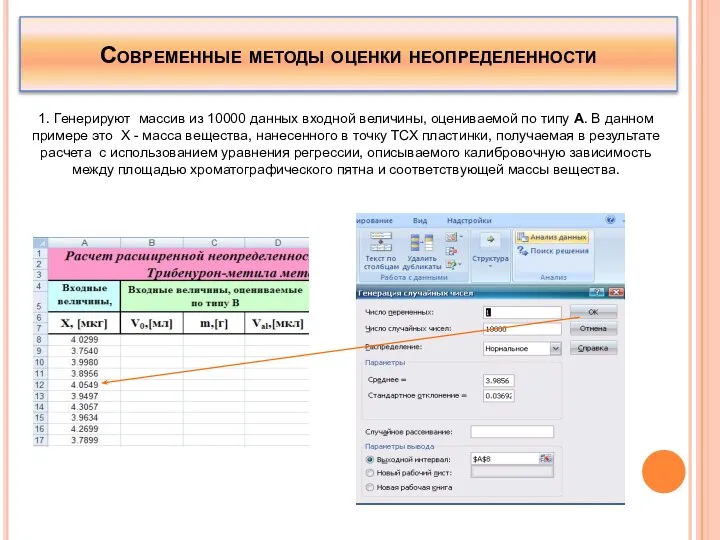
1. Генерируют массив из 10000 данных входной величины, оцениваемой
Современные методы оценки неопределенности
1. Генерируют массив из 10000 данных входной величины, оцениваемой
Слайд 160Современные методы оценки неопределенности
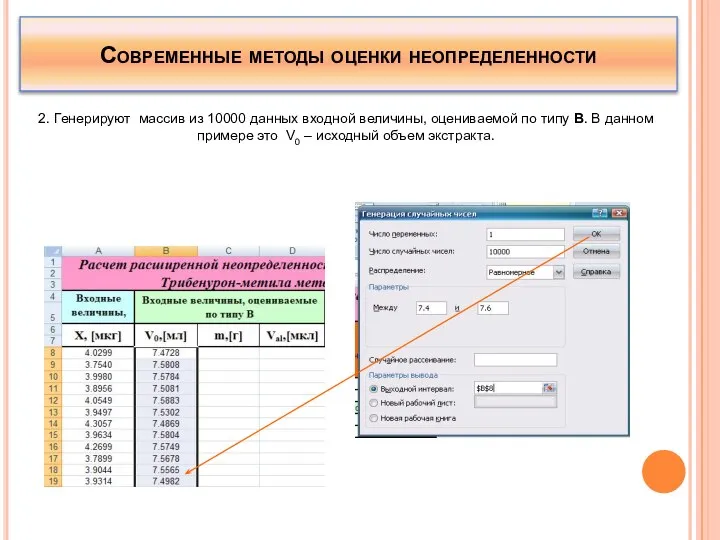
2. Генерируют массив из 10000 данных входной величины, оцениваемой
Современные методы оценки неопределенности
2. Генерируют массив из 10000 данных входной величины, оцениваемой
Слайд 161Современные методы оценки неопределенности
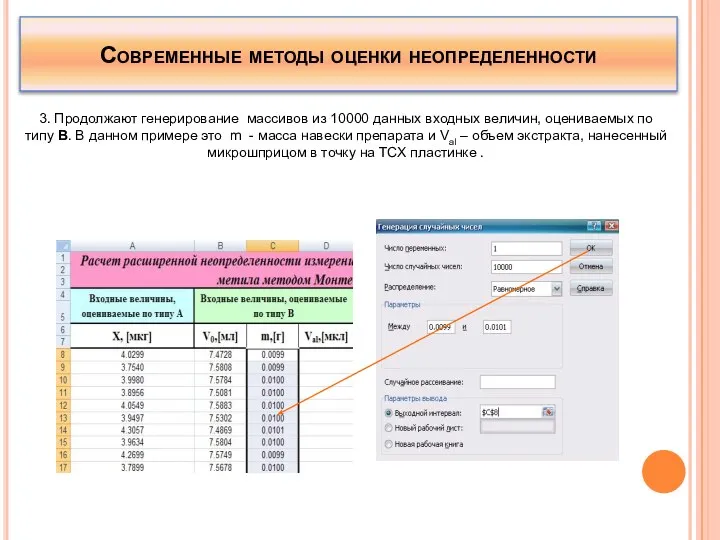
3. Продолжают генерирование массивов из 10000 данных входных величин,
Современные методы оценки неопределенности
3. Продолжают генерирование массивов из 10000 данных входных величин,
Слайд 162Современные методы оценки неопределенности
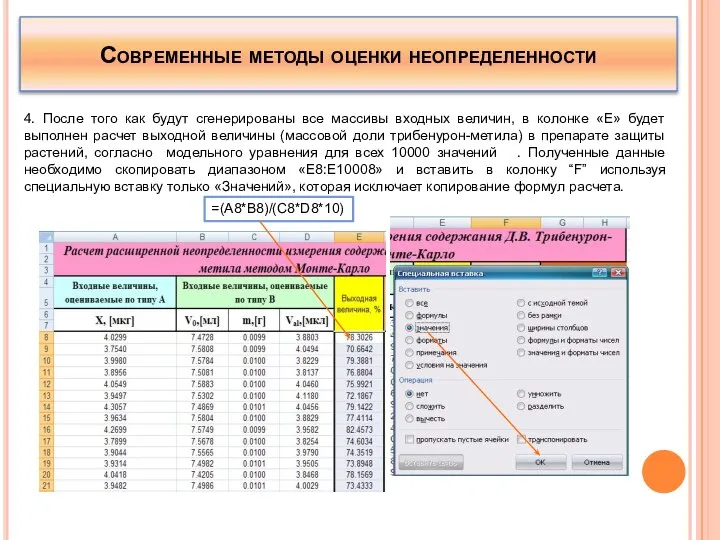
4. После того как будут сгенерированы все массивы входных
Современные методы оценки неопределенности
4. После того как будут сгенерированы все массивы входных
Слайд 163Современные методы оценки неопределенности
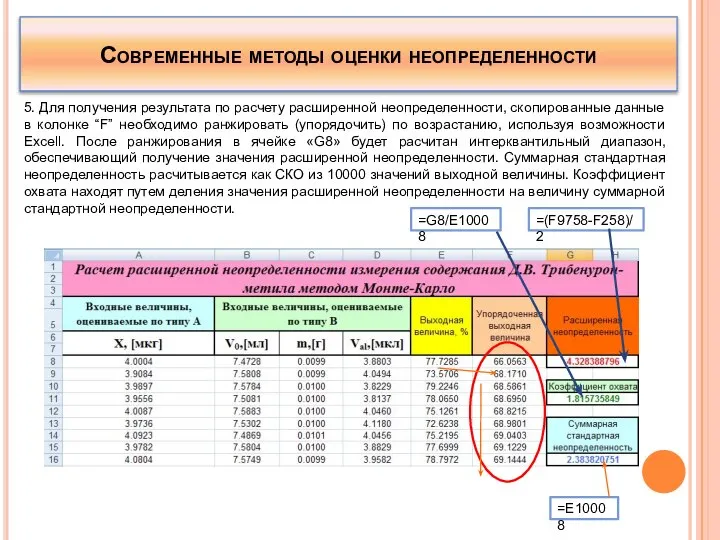
5. Для получения результата по расчету расширенной неопределенности, скопированные
Современные методы оценки неопределенности
5. Для получения результата по расчету расширенной неопределенности, скопированные

Слайд 165Современные методы оценки неопределенности
Сколько значимых цифр?
Для измерений, проводимых посредством современных приборов, цифры
Современные методы оценки неопределенности
Сколько значимых цифр?
Для измерений, проводимых посредством современных приборов, цифры

Слайд 166Чтобы дать ответ на этот вопрос следует воспользоваться руководством EURACHEM / CITAC
Чтобы дать ответ на этот вопрос следует воспользоваться руководством EURACHEM / CITAC

Слайд 167Вертикальные линии показывают ±U расширенную неопределенность для каждого результата и связанные кривой
Вертикальные линии показывают ±U расширенную неопределенность для каждого результата и связанные кривой

Слайд 168Начало зоны исключения находится в пределах спецификации L плюс значение g, (так
Начало зоны исключения находится в пределах спецификации L плюс значение g, (так

Слайд 169В некоторых случаях спецификация устанавливает верхний и нижний пределы, например контроля состава.
Рис
В некоторых случаях спецификация устанавливает верхний и нижний пределы, например контроля состава.
Рис

Слайд 170Как согласуется погрешность с неопределенностью?
Формулы пересчета параметров неопределенности в параметры погрешности :
Как согласуется погрешность с неопределенностью?
Формулы пересчета параметров неопределенности в параметры погрешности :

Слайд 171Как согласуется погрешность с неопределенностью?
Формулы пересчета параметров неопределенности в параметры погрешности :
Как согласуется погрешность с неопределенностью?
Формулы пересчета параметров неопределенности в параметры погрешности :

Слайд 172Поэтапная валидация метода
Валидация - процесс установления характеристик и ограничений метода, идентификации влияний,
Поэтапная валидация метода
Валидация - процесс установления характеристик и ограничений метода, идентификации влияний,

Слайд 173Поэтапная валидация метода
Основополагающим документом по проведению валидации аналитических методов является руководство ЕВРАХЕМ.
Поэтапная валидация метода
Основополагающим документом по проведению валидации аналитических методов является руководство ЕВРАХЕМ.

Слайд 174Поэтапная валидация метода
Важные характеристики валидации для различных типов испытания
обычно не измеряется
Поэтапная валидация метода
Важные характеристики валидации для различных типов испытания
обычно не измеряется
Слайд 175Поэтапная валидация метода
Специфичность (Specificity) (Селективность)
Руководство ICH Q2A использует термин «специфичность», несмотря на
Поэтапная валидация метода
Специфичность (Specificity) (Селективность)
Руководство ICH Q2A использует термин «специфичность», несмотря на

Слайд 176Поэтапная валидация метода
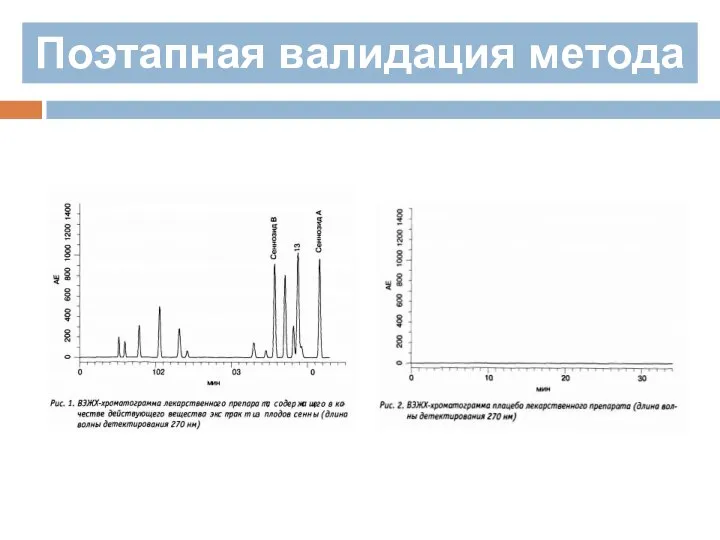
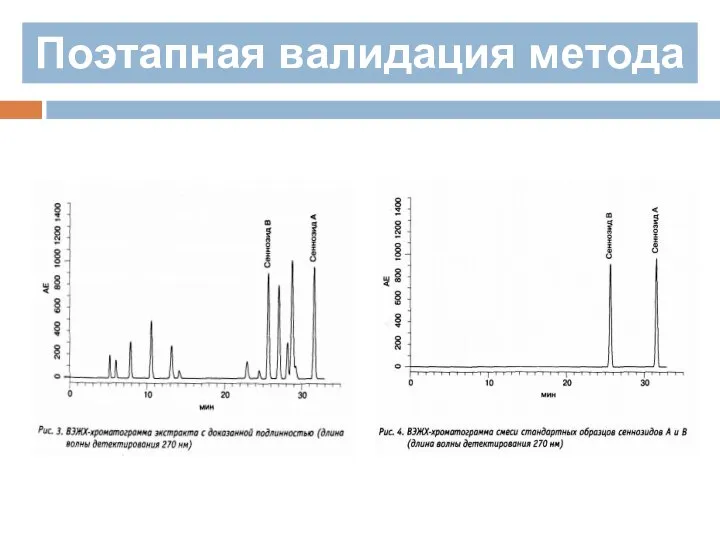
Например, в случае лекарственного препарата изготовленного из стандартизированого растительного экстракта
Поэтапная валидация метода
Например, в случае лекарственного препарата изготовленного из стандартизированого растительного экстракта

Слайд 177Поэтапная валидация метода
Поэтапная валидация метода
Слайд 178Поэтапная валидация метода
Поэтапная валидация метода
Слайд 179Поэтапная валидация метода
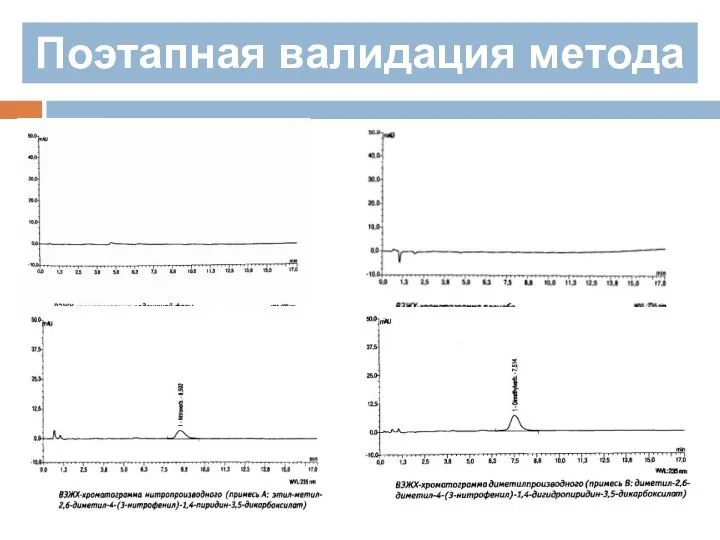
В случае лекарственного препарата изготовленного из субстанции, полученной химическим синтезом
Поэтапная валидация метода
В случае лекарственного препарата изготовленного из субстанции, полученной химическим синтезом

Слайд 180Поэтапная валидация метода
Поэтапная валидация метода
Слайд 181Поэтапная валидация метода
Поэтапная валидация метода
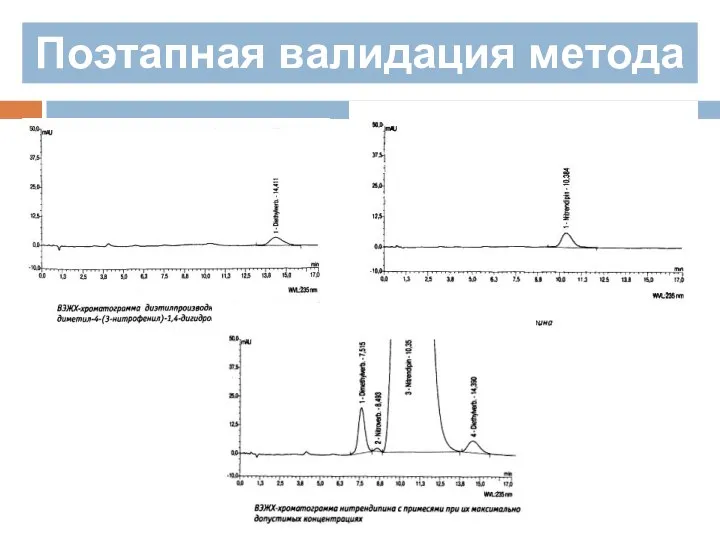
Слайд 182Поэтапная валидация метода
Селективность в анализе может принимать две ступени :
Качественная — ступень,
Поэтапная валидация метода
Селективность в анализе может принимать две ступени :
Качественная — ступень,

Слайд 183Поэтапная валидация метода
Диапазон (Range).
Разработка метода измерения предполагает предварительный выбор рабочего диапазона
Рабочий
Поэтапная валидация метода
Диапазон (Range).
Разработка метода измерения предполагает предварительный выбор рабочего диапазона
Рабочий

Слайд 184Поэтапная валидация метода
С целью проверки однородности дисперсий десять раз параллельно измеряют для
Поэтапная валидация метода
С целью проверки однородности дисперсий десять раз параллельно измеряют для

Слайд 185Поэтапная валидация метода
Точность (Accuracy) и правильность (Trueness)
Точность — близость соглашения между результатом
Поэтапная валидация метода
Точность (Accuracy) и правильность (Trueness)
Точность — близость соглашения между результатом

Слайд 186Поэтапная валидация метода
1. Метод с плацебо с нулевым содержанием определяемого компонента.
В методе
Поэтапная валидация метода
1. Метод с плацебо с нулевым содержанием определяемого компонента.
В методе

Слайд 187Поэтапная валидация метода
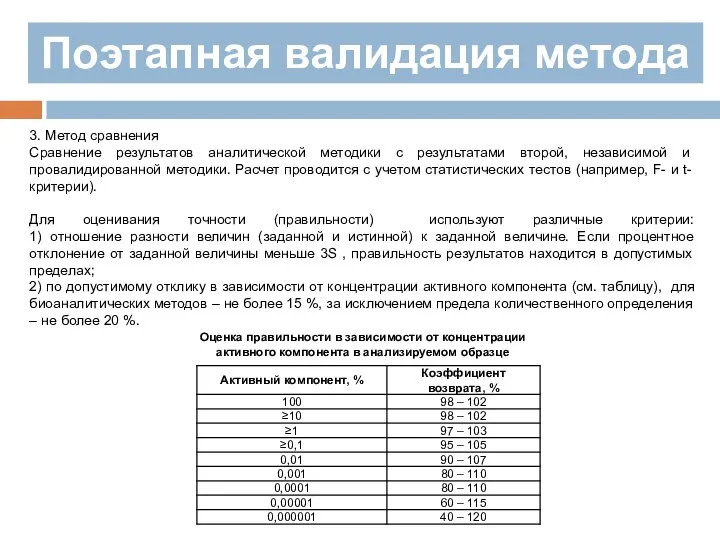
3. Метод сравнения
Сравнение результатов аналитической методики с результатами второй, независимой
Поэтапная валидация метода
3. Метод сравнения
Сравнение результатов аналитической методики с результатами второй, независимой
Слайд 188Поэтапная валидация метода
Поэтапная валидация метода
Слайд 189Поэтапная валидация метода
Прецизионность (precision).
Прецизионность аналитической методики выражает степень близости (степень дисперсии) между
Поэтапная валидация метода
Прецизионность (precision).
Прецизионность аналитической методики выражает степень близости (степень дисперсии) между

Слайд 190Поэтапная валидация метода
Во избежание недоразумений, слово “точность”, которое иногда используется для перевода
Поэтапная валидация метода
Во избежание недоразумений, слово “точность”, которое иногда используется для перевода

Слайд 191Поэтапная валидация метода
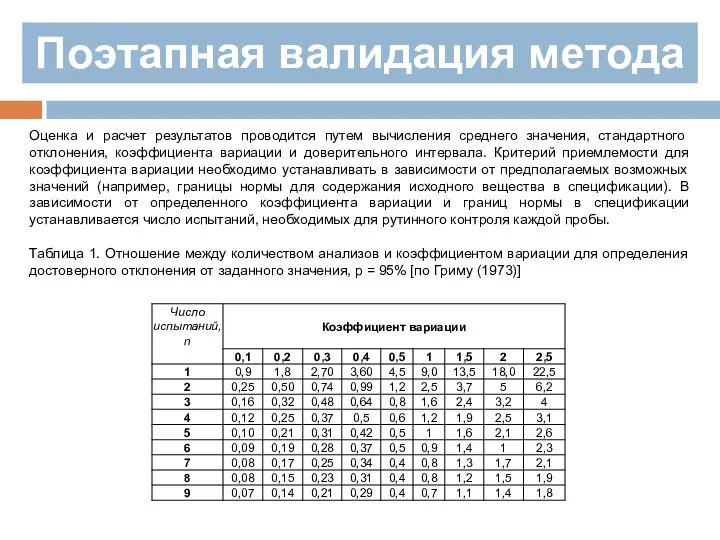
Оценка и расчет результатов проводится путем вычисления среднего значения, стандартного
Поэтапная валидация метода
Оценка и расчет результатов проводится путем вычисления среднего значения, стандартного
Слайд 192Поэтапная валидация метода
Пример: Если нормы количественного содержания действующего вещества в фармацевтической субстанции
Поэтапная валидация метода
Пример: Если нормы количественного содержания действующего вещества в фармацевтической субстанции

Слайд 193Поэтапная валидация метода
Принятые критерии для точности во многом зависят от типа анализа.
Поэтапная валидация метода
Принятые критерии для точности во многом зависят от типа анализа.
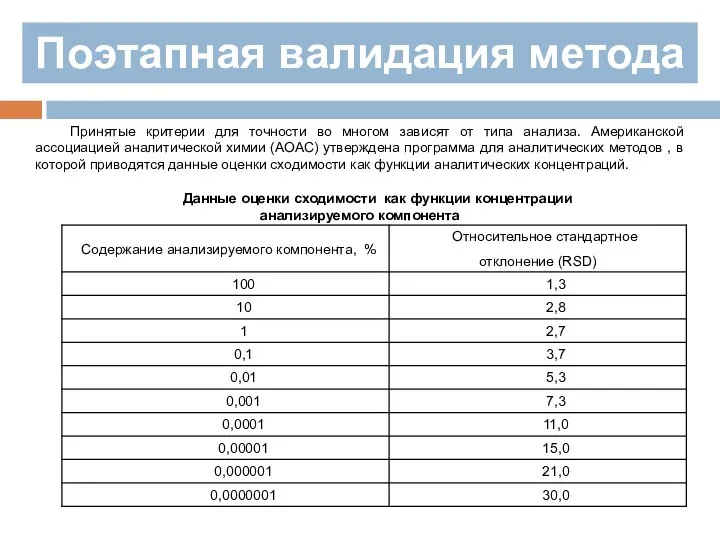
Слайд 194Поэтапная валидация метода
Для оценивания допустимых пределов сходимости и воспроизводимости иногда прибегают к
Поэтапная валидация метода
Для оценивания допустимых пределов сходимости и воспроизводимости иногда прибегают к

Слайд 195Поэтапная валидация метода
Воспроизводимость
Воспроизводимость - это прецизионность в условиях, когда результаты испытания получены
Поэтапная валидация метода
Воспроизводимость
Воспроизводимость - это прецизионность в условиях, когда результаты испытания получены

Слайд 196Поэтапная валидация метода
Линейность
Линейность аналитической методики доказана, если в выбранном диапазоне применения можно
Поэтапная валидация метода
Линейность
Линейность аналитической методики доказана, если в выбранном диапазоне применения можно

Слайд 197Поэтапная валидация метода
Основные и статистически обоснованные принципы построения и оценивания калибровочных регрессионных
Поэтапная валидация метода
Основные и статистически обоснованные принципы построения и оценивания калибровочных регрессионных

Слайд 198Поэтапная валидация метода
Тест Манделя. Во время статистической проверки на линейность, градуировочные данные
Поэтапная валидация метода
Тест Манделя. Во время статистической проверки на линейность, градуировочные данные

Слайд 199Поэтапная валидация метода
Предел обнаружения (detection limit)
Предел обнаружения отдельной аналитической методики представляет
Поэтапная валидация метода
Предел обнаружения (detection limit)
Предел обнаружения отдельной аналитической методики представляет

Слайд 200Поэтапная валидация метода
Предел обнаружения (детектирования) для аналитического прибора LOD
Предел обнаружения (детектирования)
Поэтапная валидация метода
Предел обнаружения (детектирования) для аналитического прибора LOD
Предел обнаружения (детектирования)

Слайд 201Поэтапная валидация метода
Для нехроматографических методов предел детектирования, выраженный как концентрация или количество
Поэтапная валидация метода
Для нехроматографических методов предел детектирования, выраженный как концентрация или количество

Слайд 202Поэтапная валидация метода
Здесь калибровка выполняется с I независимыми калибровочными растворами (включая холостую
Поэтапная валидация метода
Здесь калибровка выполняется с I независимыми калибровочными растворами (включая холостую

Слайд 203Поэтапная валидация метода
Возврат (Recovery)
Возврат (также употребляются термины «процентная мера правильности», «открываемость», «извлечение»,
Поэтапная валидация метода
Возврат (Recovery)
Возврат (также употребляются термины «процентная мера правильности», «открываемость», «извлечение»,

Слайд 204Поэтапная валидация метода
Определение возврата добавкой активного ингредиента к плацебо (холостой пробе)
Прибавьте точно
Поэтапная валидация метода
Определение возврата добавкой активного ингредиента к плацебо (холостой пробе)
Прибавьте точно

Слайд 205Поэтапная валидация метода
Определение возврата со стандартной добавкой
Сделайте гомогенный образец плацебо (холостой пробы).
Поэтапная валидация метода
Определение возврата со стандартной добавкой
Сделайте гомогенный образец плацебо (холостой пробы).

Слайд 206Поэтапная валидация метода
Робасность
Испытание на стабильность: внутрилабораторное исследование для изучения поведения аналитического процесса,
Поэтапная валидация метода
Робасность
Испытание на стабильность: внутрилабораторное исследование для изучения поведения аналитического процесса,

Слайд 207Поэтапная валидация метода
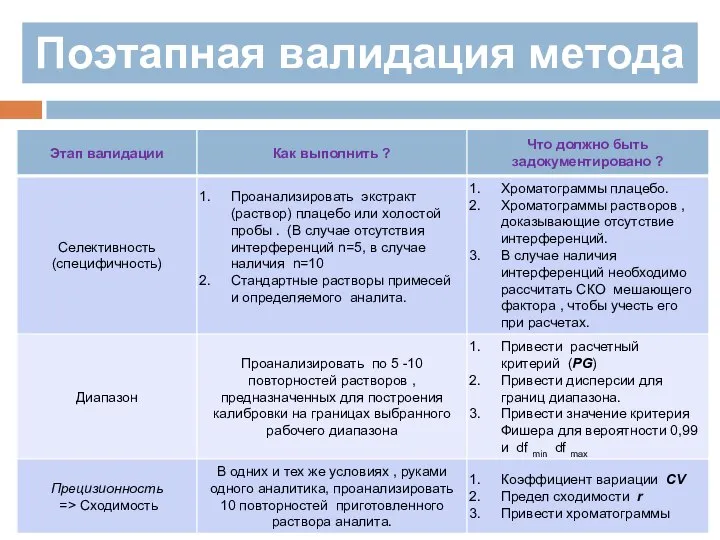
Поэтапная валидация метода
Слайд 208Поэтапная валидация метода
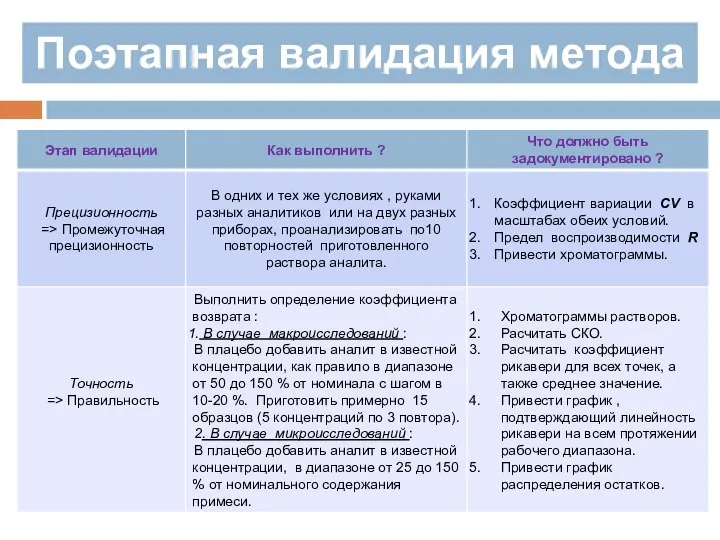
Поэтапная валидация метода
Слайд 209Поэтапная валидация метода
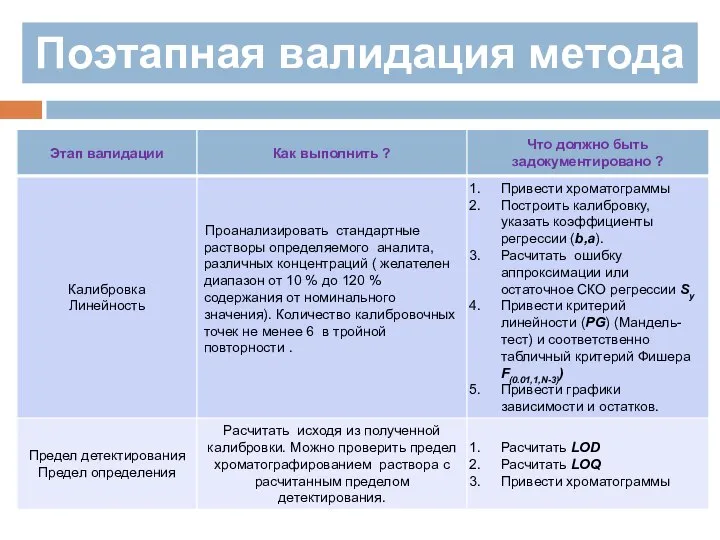
Поэтапная валидация метода
Слайд 210Поэтапная валидация метода
Поэтапная валидация метода
Слайд 211Поэтапная валидация метода
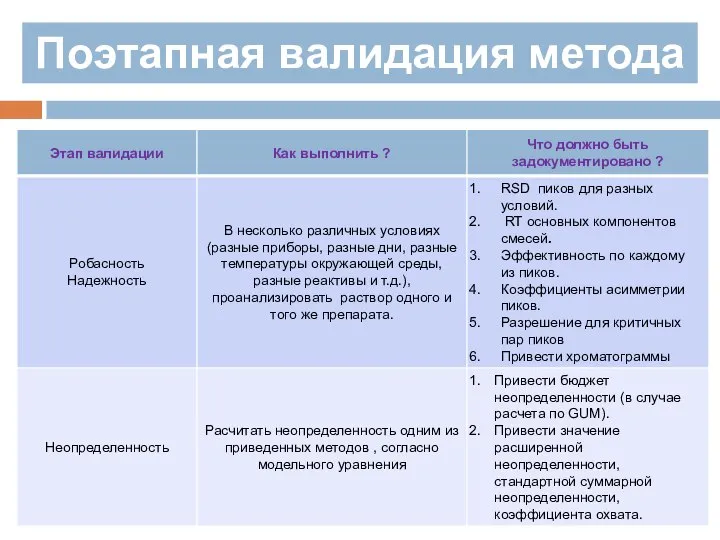
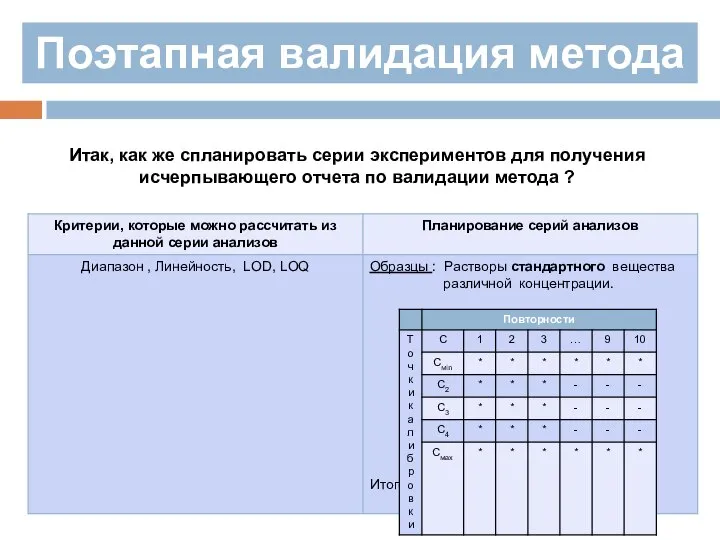
Итак, как же спланировать серии экспериментов для получения исчерпывающего отчета
Поэтапная валидация метода
Итак, как же спланировать серии экспериментов для получения исчерпывающего отчета
Слайд 212Поэтапная валидация метода
Поэтапная валидация метода
 Стирол - важнейшее производное бензола
Стирол - важнейшее производное бензола Химические реакции (2)
Химические реакции (2) Изомерия органических соединений. Лекция 2
Изомерия органических соединений. Лекция 2 Систематизация знаний по периодической системе химических элементов
Систематизация знаний по периодической системе химических элементов Физические и химические свойства алкинов
Физические и химические свойства алкинов Непредельные углеводороды: алкены и алкины
Непредельные углеводороды: алкены и алкины Кислоты
Кислоты Галогены
Галогены Получение карбоновых кислот
Получение карбоновых кислот Степень окисления
Степень окисления Задачи химической кинетики
Задачи химической кинетики Микроэмульсия. Микроэмульсияның макроэмулсиядан айырмашылығы
Микроэмульсия. Микроэмульсияның макроэмулсиядан айырмашылығы Презентация на тему Химия и стирка
Презентация на тему Химия и стирка  Типы химических реакций
Типы химических реакций Образование и получение веществ
Образование и получение веществ Стекло. Определение стекла
Стекло. Определение стекла Химические реакции. по фазовому составу
Химические реакции. по фазовому составу Постулаты Онзагера
Постулаты Онзагера Химическая связь
Химическая связь Карбоновые кислоты
Карбоновые кислоты Изменения, происходящие с веществами
Изменения, происходящие с веществами Химический опыт с горением борноэтилового эфира
Химический опыт с горением борноэтилового эфира Олигосахариды и полисахариды
Олигосахариды и полисахариды ZhK_Prezentatsia_1
ZhK_Prezentatsia_1 Получение галогеноалканов
Получение галогеноалканов Кремень. Нахождение в природе
Кремень. Нахождение в природе Техника безопасности при работе в химическом кабинете
Техника безопасности при работе в химическом кабинете α-Аминокислоты. Биологически важные реакции α-аминокислот. Строение пептидов и белков (Лекция 26)
α-Аминокислоты. Биологически важные реакции α-аминокислот. Строение пептидов и белков (Лекция 26)