- Классификация технологий параллельного программирования - MPI: обзор возможностей

Содержание
- 2. Классификация технологий параллельного программирования (ТТП) 1. Технологии параллельного программирования (ТПП) обычно реализуются как расширения традиционных языков
- 3. Классификация технологий параллельного программирования (ТПП) Во всех случаях цель ТПП – организовать выполнение задачи пользователя в
- 4. Что такое MPI Message Passing Interface – одна из популярных технологий для организации параллельных вычислений. MPI
- 5. Структура MPI Главные составляющие MPI Коммуникатор (группа процессов плюс контекст взаимодействия) Типы передаваемых данных (всегда передаем
- 6. Процедуры MPI повторение и дополнение пройденного на семинарах «ПРОЖИТОЧНЫЙ МИНИМУМ» MPI_Init инициализация параллельной части программы MPI_Finalize
- 7. Операции “Point-to-Point”: асинхронный обмен MPI_Isend: Передача сообщения, аналогичная MPI_Send, однако возврат происходит сразу после инициализации процесса
- 8. Операции MPI “Point-to-Point”: Объединение запросов на взаимодействие Несколько запросов на прием и/или передачу могут объединяться вместе
- 9. Коллективные операции MPI В операциях коллективного взаимодействия процессов участвуют все процессы коммуникатора. Соответствующая процедура должна быть
- 11. Группы и коммуникаторы В MPI существуют широкие возможности для операций над группами процессов и коммуникаторами. Это
- 12. Операции с группами процессов Новые группы можно создавать как на основе уже существующих групп, так и
- 13. Операции с коммуникаторами Коммуникатор предоставляет возможность независимых обменов данными в отдельной группе. Каждой группе процессов может
- 14. Виртуальные топологии Топология – механизм сопоставления процессам некоторого коммуникатора альтернативной схемы адресации. Топология используется программистом для
- 15. Виртуальные топологии: декатрова топология Декартова топология MPI_Cart_create: Создание коммуникатора, обладающего декартовой топологией, из процессов существующего коммуникатора
- 16. Виртуальные топологии: топология графа MPI_Graph_create. Создание на основе существующего коммуникатора нового коммуникатора с топологией графа с
- 17. Пересылка разнотипных данных Под сообщением в MPI понимается массив однотипных данных, расположенных в последовательных ячейках памяти.
- 18. Пересылка разнотипных данных: Производные типы данных Производные типы данных создаются во время выполнения программы с помощью
- 19. Пересылка разнотипных данных: Производные типы данных Таким образом, последовательность элементов данных в производном типе может отличаться
- 21. Скачать презентацию
Слайд 2Классификация технологий параллельного программирования (ТТП)
1. Технологии параллельного программирования (ТПП) обычно реализуются
Классификация технологий параллельного программирования (ТТП)
1. Технологии параллельного программирования (ТПП) обычно реализуются

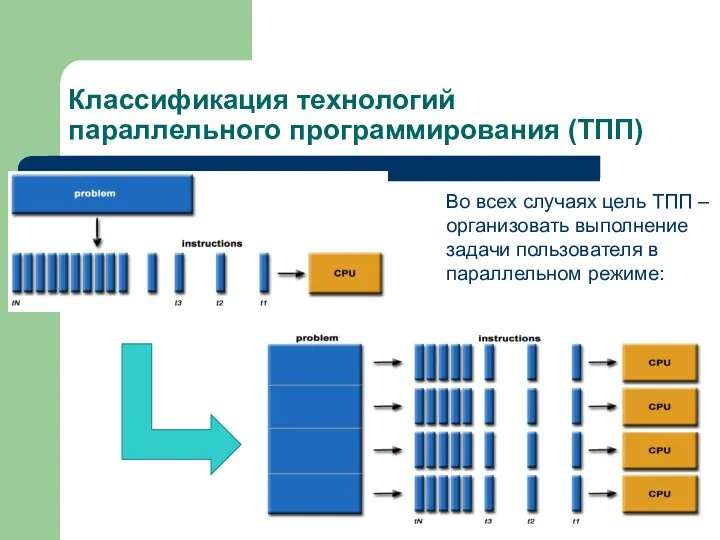
Слайд 3Классификация технологий параллельного программирования (ТПП)
Во всех случаях цель ТПП – организовать выполнение
Классификация технологий параллельного программирования (ТПП)
Во всех случаях цель ТПП – организовать выполнение
Слайд 4Что такое MPI
Message Passing Interface – одна из популярных технологий для организации
Что такое MPI
Message Passing Interface – одна из популярных технологий для организации

Слайд 5Структура MPI
Главные составляющие MPI
Коммуникатор (группа процессов плюс контекст взаимодействия)
Типы передаваемых данных
Структура MPI
Главные составляющие MPI
Коммуникатор (группа процессов плюс контекст взаимодействия)
Типы передаваемых данных

Слайд 6Процедуры MPI
повторение и дополнение пройденного на семинарах
«ПРОЖИТОЧНЫЙ МИНИМУМ»
MPI_Init инициализация параллельной части программы
MPI_Finalize завершение
Процедуры MPI
повторение и дополнение пройденного на семинарах
«ПРОЖИТОЧНЫЙ МИНИМУМ»
MPI_Init инициализация параллельной части программы
MPI_Finalize завершение

Слайд 7Операции “Point-to-Point”:
асинхронный обмен
MPI_Isend: Передача сообщения, аналогичная MPI_Send, однако возврат происходит сразу после
Операции “Point-to-Point”:
асинхронный обмен
MPI_Isend: Передача сообщения, аналогичная MPI_Send, однако возврат происходит сразу после

Слайд 8Операции MPI “Point-to-Point”:
Объединение запросов на взаимодействие
Несколько запросов на прием и/или передачу могут
Операции MPI “Point-to-Point”:
Объединение запросов на взаимодействие
Несколько запросов на прием и/или передачу могут

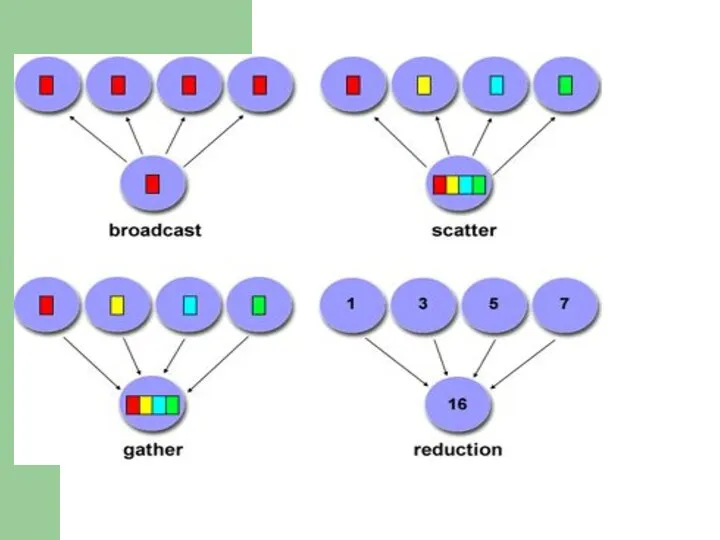
Слайд 9Коллективные операции MPI
В операциях коллективного взаимодействия процессов участвуют все процессы коммуникатора. Соответствующая
Коллективные операции MPI
В операциях коллективного взаимодействия процессов участвуют все процессы коммуникатора. Соответствующая

Слайд 11Группы и
коммуникаторы
В MPI существуют широкие возможности для операций над группами процессов
Группы и
коммуникаторы
В MPI существуют широкие возможности для операций над группами процессов

Слайд 12Операции с группами
процессов
Новые группы можно создавать как на основе уже существующих
Операции с группами
процессов
Новые группы можно создавать как на основе уже существующих

Слайд 13Операции с
коммуникаторами
Коммуникатор предоставляет возможность независимых обменов данными в отдельной группе. Каждой
Операции с
коммуникаторами
Коммуникатор предоставляет возможность независимых обменов данными в отдельной группе. Каждой

Слайд 14Виртуальные топологии
Топология – механизм сопоставления процессам некоторого коммуникатора альтернативной схемы адресации.
Топология
Виртуальные топологии
Топология – механизм сопоставления процессам некоторого коммуникатора альтернативной схемы адресации.
Топология

Слайд 15Виртуальные топологии:
декатрова топология
Декартова топология
MPI_Cart_create: Создание коммуникатора, обладающего декартовой топологией, из процессов существующего
Виртуальные топологии:
декатрова топология
Декартова топология
MPI_Cart_create: Создание коммуникатора, обладающего декартовой топологией, из процессов существующего

Слайд 16Виртуальные топологии:
топология графа
MPI_Graph_create. Создание на основе существующего коммуникатора нового коммуникатора с топологией
Виртуальные топологии:
топология графа
MPI_Graph_create. Создание на основе существующего коммуникатора нового коммуникатора с топологией

Слайд 17Пересылка разнотипных данных
Под сообщением в MPI понимается массив однотипных данных, расположенных в
Пересылка разнотипных данных
Под сообщением в MPI понимается массив однотипных данных, расположенных в

Слайд 18Пересылка разнотипных данных:
Производные типы данных
Производные типы данных создаются во время выполнения программы
Пересылка разнотипных данных:
Производные типы данных
Производные типы данных создаются во время выполнения программы

Слайд 19Пересылка разнотипных данных:
Производные типы данных
Таким образом, последовательность элементов данных в производном типе
Пересылка разнотипных данных:
Производные типы данных
Таким образом, последовательность элементов данных в производном типе

 Методы обеспечивающие безопасность информации
Методы обеспечивающие безопасность информации Роль информатики и информационных технологий в современном мире
Роль информатики и информационных технологий в современном мире Информация и свойства информации
Информация и свойства информации Язык программирования Python
Язык программирования Python Microgrid на основе технологии blockchain
Microgrid на основе технологии blockchain Понятие как форма мышления. Урок 12
Понятие как форма мышления. Урок 12 The internet
The internet MapInfo Professional: назначение и возможности
MapInfo Professional: назначение и возможности Общие сведения о языке программирования Паскаль
Общие сведения о языке программирования Паскаль Разработка интернет-магазина на базе CMS OpenCar
Разработка интернет-магазина на базе CMS OpenCar История внедрения и перспективы применения компьютерных технологий в современной медицине и практике
История внедрения и перспективы применения компьютерных технологий в современной медицине и практике Briefing designers
Briefing designers Golem Forge
Golem Forge Проектная деятельность студентов
Проектная деятельность студентов Инженерная и компьютерная графика. Лекция 1
Инженерная и компьютерная графика. Лекция 1 Методология , структура и преимущество ERP – систем, смысл новой идеологии CSRP, расширенное управление
Методология , структура и преимущество ERP – систем, смысл новой идеологии CSRP, расширенное управление Опрос аудитории паблика OH MY HYPE
Опрос аудитории паблика OH MY HYPE Настройка шаблона
Настройка шаблона Компьютерные сети
Компьютерные сети SMM специалист с нуля
SMM специалист с нуля Основы использования новых информационных технологий в управленческой деятельности. Лекция № 2-2019
Основы использования новых информационных технологий в управленческой деятельности. Лекция № 2-2019 Палитры цветов в системах цветопередачи RGB, CMYK и HSB
Палитры цветов в системах цветопередачи RGB, CMYK и HSB Текстовый редактор MS-WORD
Текстовый редактор MS-WORD Виды компьютерных систем
Виды компьютерных систем Информационная система диагностики оборудования электродегидратора
Информационная система диагностики оборудования электродегидратора Подпись в МФЦ
Подпись в МФЦ Дискретная математика. Переводы из двоичной
Дискретная математика. Переводы из двоичной Локальные компьютерные сети (интерактивный плакат)
Локальные компьютерные сети (интерактивный плакат)